機械学習・DeepLearningにおけるハイパーパラメータサーチをもっと簡単に・高度にするモジュールを作ったので、紹介します。
-
このモジュールが役に立ちそうな人
- ハイパーパラメータサーチとそれに伴う周辺の作業をできるだけ簡単にしたい人。
- 高度なサーチアルゴリズムを手軽に試したい人。
-
できること
- scikit-learnライクなシンプルインターフェースでハイパーパラメータサーチに加えて以下が実行可能。
- ログの管理
- ログの可視化
- 特徴量選択
- scikit-learnには搭載されていない以下のアルゴリズムをサポート。
- ベイズ最適化 (GpyOpt)
- 遺伝的アルゴリズム
- Sequential Model Based Global Optimization (Hyperopt)
- scikit-learnライクなシンプルインターフェースでハイパーパラメータサーチに加えて以下が実行可能。
なぜ作ったか?
機械学習・DeepLearningをするにあたって、避けて通れないハイパーパラメータサーチ。これをやっていると、以下のように思うことがありませんか?
- サーチのログ管理とその可視化も、サーチクラスのなかでやって欲しい!
- サーチのクラスに含まれていないことが多く、自分で組まなければならない。
- ハイパーパラメータサーチのついでに、特徴量選択をやって欲しい!
- これもサーチのクラスに含まれていないことが多い。
- ベイズ最適化や遺伝的アルゴリズムなどの高度なアルゴリズムを試したい!
- それぞれをサポートするライブラリはあるものの、インターフェースがまちまちなので、気軽に試せない。
実際にこれをやろうとすると、それなりの量のコードを書かなければなりません。
「これらを5行くらいで書けないものか?」と思い、cvopt (cross validation optimizer)というpythonモジュールを作ってみました。
Quick start: 5行で書いてみた
param_distributions ={"C": search_numeric(0, 3, "float"), "tol" : search_numeric(0, 4, "float"),
"penalty": search_category(['l1', 'l2'])}
opt = SimpleoptCV(estimator=LogisticRegression(), param_distributions=param_distributions,
backend="bayesopt")
opt.fit(Xtrain, ytrain, feature_groups=[0,0,0,1,1])
... 流石に5行だと無理がありますね。
ただ普通に書くよりは大分シンプルになっています。
インストール
pipでインストールできます。
pip install Gpy
pip install cvopt
使い方
1. サーチ in scikit-learn
ここでは例として、scikit-learnのLogisticRegression(表形式データに対する分類)のサーチを行います。なおログをnotebook上で可視化したい場合、bokehというライブラリを内部で使うので、事前に以下を実行します。
from bokeh.io import output_notebook
output_notebook()
1.1. ハイパーパラメータの設定
数値パラメータはsearch_numeric、カテゴリカルパラメータはsearch_categoryという関数を使って、範囲を設定します。
param_distributions = {
"C": search_numeric(0.01, 3.0, "float"), # サーチ範囲min, max, 変数のタイプ("int" or "float")
"tol" : search_numeric(0.0001, 0.001, "float"),
"penalty": search_category(['l1', 'l2']), # サーチ対象カテゴリのリスト
"class_weight" : search_category([None, "balanced"]),
}
また上記以外にもいくつかの設定方法が可能です。サンプルnotebookに記載があります。
1.2. 特徴量選択の設定 (オプション)
特徴量選択は特徴量のグループ:feature_group毎に選択するか否かをサーチします。
特徴量選択をする際には、このグループをどう分けるかを指定する必要があります。
グループを分ける方法は、例えばデータソースの違いや特徴量エンジニアリング方法の違いがあります。
feature_groupの例
データが5個の特徴量(カラム)を持っていて、以下のようにfeature_groupを設定したいとします。
| feature index(data col index) | feature group |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 0 |
| 3 | 1 |
| 4 | 1 |
この場合、以下のようにlistを定義します。
feature_groups = [0, 0, 0, 1, 1]
サーチの結果として, feature_group毎に選択したかどうかを表すbooleanが得られます。
feature_groups0: True
feature_groups1: False
この結果は、グループ0の特徴量を選択し、グループ1の特徴量を選択しないという意味になります。
なお
-
feature_groupを設定しない場合、全ての特徴量が使用されます。 -
feature_groupが-1であれば、そのグループの特徴量は必ず選択されます。
1.3. サーチ実行
scikit-learnのCross-validationクラスと同じように実行できます。
estimator = LogisticRegression()
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=0)
opt = SimpleoptCV(estimator, param_distributions,
scoring="roc_auc", # サーチの目的関数
cv=cv, # Cross-validationの設定
max_iter=32, # サーチ回数
n_jobs=3, # Cross-validationの並列実行数
backend="bayesopt", # サーチで使用するアルゴリズム
)
opt.fit(Xtrain, ytrain, feature_groups=feature_groups)
サーチ結果も、scikit-learnのCross-validationクラスと同じように、以下で表示できます。
pd.DataFrame(opt.cv_results_)
1.3.1 アルゴリズムの変更
アルゴリズムはbackendの指定を変えるだけで変更可能です(サーチ範囲の設定などはそのまま流用可能)。
以下のbackendをサポートしています。
-
"bayesopt": ベイズ最適化 (GpyOpt) -
"gaopt": 遺伝的アルゴリズム -
"hyperopt": Sequential Model Based Global Optimization (Hyperopt) -
"randomopt":ランダムサーチ
なおbackendを直接操作するCross-validationクラスも用意しています。
1.3.2 ログの保存と可視化
Cross-validationクラスの定義時にオプションを指定することで、ログの保存と可視化が可能です。
またfit時にvalidation_dataを指定することで、そのデータセットに対するスコアも確認可能です。
opt = SimpleoptCV(estimator, param_distributions,
scoring="roc_auc",
cv=cv,
max_iter=32,
n_jobs=3,
backend="bayesopt",
logdir="./search_usage", # ログの保存ディレクトリ。これが指定されるとログを保存する。
model_id="search_usage", # ログ管理で使用するid。
save_estimator=2, # estimatorの保存設定
# 0: 保存しない
# 1: cvの各foldでfitしたestimatorを保存
# 2: 1に加え、train_data全体でfitしたestimatorを保存
verbose=2, # サーチログの表示設定。
# 0: 非表示
# 1: 最高スコアとサーチ完了時間(推定)をテキストで表示。
# 2: サーチログを可視化して表示
)
opt.fit(Xtrain, ytrain, feature_groups=feature_groups,
validation_data=(Xtest, ytest)) # validation_data
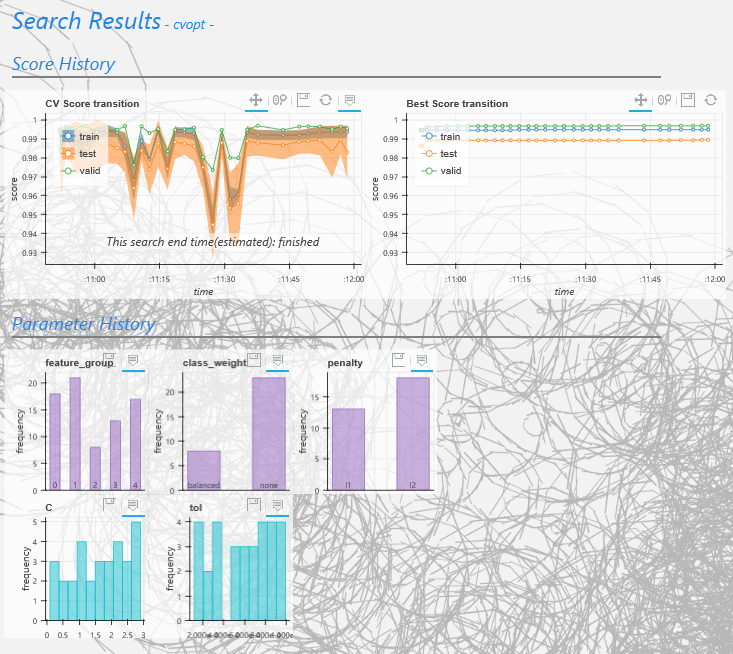
verbose=2だと以下のように、notebook上にパラメータのヒストグラムやサーチ完了時間(推定)が表示されます。ヒストグラムを見ているとアルゴリズムの気持ちがわかるかもしれません...。
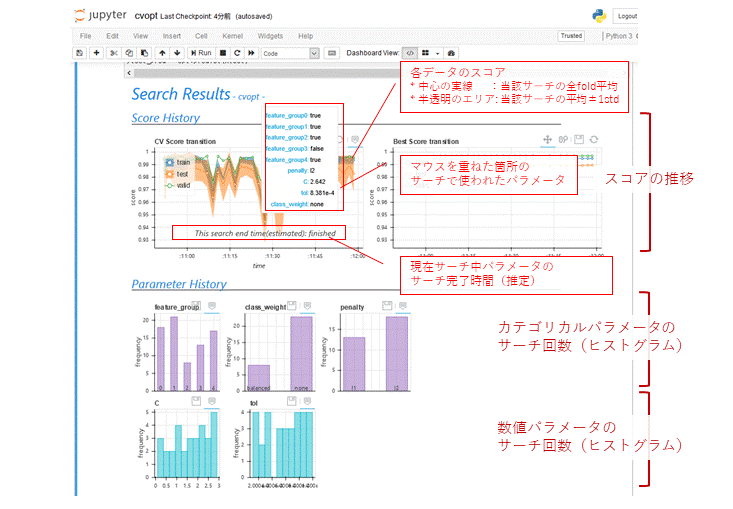
またログはlogdirに以下の構造で保存されます。これらは1つのパラメータがサーチされるたびに更新されるため、不測の事態でサーチが中断されても、そこまでの結果は利用可能です。
なおグラフ(html)は保存時に体裁を整えつつ、サーチ結果をパラメータとして背景を自動生成するようになっています。記事冒頭の画像がそれです。
logdir
|-cv_results
| |-{model_id}.csv # サーチ結果(opt.cv_results_)
| ...
|-cv_results_graph
| |-{model_id}.html # サーチ結果(グラフ)
| ...
|-estimators_{model_id}
|-{model_id}_index{search count}_split{fold count} # cvの各foldでfitしたestimator
...
|-{model_id}_index{search count}_test # train_data全体でfitしたestimator
2. サーチ in Keras
cvoptはscikit-learnライクなestimatorに対応しているため、keras.wrappers.scikit_learnなどを使用すれば、Kerasに対するサーチも実行可能です。ここでは例として、KerasClassifier(画像データに対する分類)のサーチを行います。
n_classes = 10
def mk_nw(activation, lr, out_dim):
model = Sequential()
model.add(Conv2D(20, kernel_size=5, strides=1,
activation=activation, input_shape=Xtrain.shape[1:]))
model.add(MaxPool2D(2, strides=2))
model.add(Conv2D(50, kernel_size=5, strides=1, activation=activation))
model.add(MaxPool2D(2, strides=2))
model.add(Flatten())
model.add(Dense(out_dim, activation=activation))
model.add(Dense(n_classes, activation="softmax"))
model.compile(loss="categorical_crossentropy", optimizer=optimizers.SGD(lr=lr))
return model
estimator = KerasClassifier(mk_nw, activation="linear", lr=0.01, out_dim=256, epochs=16, verbose=0)
cvoptをKerasで使用するためには、__scorer__と__saver__の定義が必要です。
2.1 scorerの定義
上記のKerasClassifierはfit時にytrueが1hot形式( (n_samples, n_classes)のマトリクス )であることを前提としますが、predictの返り値ypredはラベル形式( (n_samples, )のベクトル )となります。一方、通常のスコア関数(例えばaccuracy_score(ytrue, ypred))はytrueとypredで同じ形式を前提とするため、KerasClassifierに対し使用するとエラーとなります。
よってこの差を吸収するようなスコア関数scorerを定義する必要があります。この定義にはsklearn.metrics.make_scorerを使用します。
from sklearn.metrics import make_scorer, accuracy_score
def acc(ytrue, ypred):
return accuracy_score(np.argmax(ytrue, axis=1), ypred)
scorer = make_scorer(acc, greater_is_better=True)
2.2 saverの定義
cvoptではestimatorを保存する際に、デフォルトでsklearn.externals.joblib.dumpを使用します。この保存方法はKerasの推奨ではないため、保存関数saverをKeras用に定義します。なおestimatorを保存しない場合、これは不要です。
from keras.models import save_model
def saver(estimator, path):
save_model(estimator.model, path)
# KerasClassifierはKerasClassifier.modelにモデルを保持するので、estimator.modelという指定になります。
2.3 サーチ実行
scorerとsaverを指定する以外は、前述と同じようにサーチが実行可能です。
param_distributions = {
"activation": search_category(["linear", "relu"]),
"lr": search_numeric(0.0001, 0.1, "float"),
"out_dim" : search_numeric(124, 512, "int"),
}
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=0)
opt = SimpleoptCV(estimator, param_distributions,
scoring=scorer,
cv=cv,
max_iter=8,
n_jobs=1,
verbose=2,
logdir="./cifar10",
model_id="search_usage",
save_estimator=2,
saver=saver,
backend="hyperopt",
)
opt.fit(Xtrain, ytrain, validation_data=(Xtest, ytest))
2.4 その他注意事項
-
並列処理
cvoptの並列処理はpythonのmultiprocessingで実現しています。一方、Kerasのmultiprocessingによる並列化においては環境依存の問題が存在します(例えばこのissue)。並列化で問題が起きた際には、n_jobsを1にしてみてください。 -
特徴量選択
基本的にKerasはinput_shapeを固定してmodelを定義します。一方、特徴量選択を実行する場合、inputのshapeはその選択により変化します。よってKerasにおいて特徴量選択を使用する場合、input_shapeが入力によって可変になるような実装をする必要があります。 -
Resource exhausted error
gpu環境でサーチを実行するとResource exhaustedエラーが発生することがあります。 このエラーの1つの対策は、特定のタイミングでセッションをクリアすることです。keras.wrappers.scikit_learnを使用する場合、以下のような対策があります。ただしこれを行うとsaverによるモデルの保存ができなくなるので、保存が必要な場合はKerasのcallbackなどを使用する必要があります。
3. ログ利用
3.1 サーチ結果の抽出
cvoptではヘルパー関数を使って、ログからサーチ結果のハイパーパラメータ・特徴量選択結果をささっと抽出できます。
from cvopt.utils import extract_params
estimator_params, feature_params, feature_select_flag = extract_params(
logdir="./search_usage", # ログの保存ディレクトリ
model_id="search_usage", # 抽出対象のid
target_index=0, # 抽出対象のindex(N回目のサーチ結果のindexがN-1になる)
feature_groups=feature_groups, # feature_groups(サーチ時と同じもの)
)
estimator.set_params(**estimator_params) # パラメータのセット
Xtrain_selected = Xtrain[:, feature_select_flag] # 特徴量選択結果の反映
3.2 stackingのためのメタ特徴量生成
estimatorを保存できる仕様にしたので「どうせならKaggleで使用されているstacking用の特徴量を生成できるといいのでは?」と思い、作ってみました。
これをする場合estimatorの保存が必要なので、サーチ実行時にsave_estimatorを2に指定してください。
from cvopt.utils import mk_metafeature
Xtrain_meta, Xtest_meta = mk_metafeature(Xtrain, ytrain,
logdir="./search_usage",
model_id="search_usage",
target_index=0,
cv=cv, # Cross-validationの設定(サーチ時と同じもの)
validation_data=(Xtest, ytest), # fitしていないデータに対するメタ特徴量を生成する場合に指定する。
# (train全体でfitしたestimatorによるメタ特徴量が生成される。)
feature_groups=feature_groups, # feature_groups(サーチ時と同じもの)
estimator_method="predict_proba" # メタ特徴量を生成する際のメソッド
)
3. 参考
おわりに
__5行で書く__というのはちょっと無理がありましたが、ハイパーパラメータサーチとその周辺をシンプルに書けるようにしてみました。
こーゆーものを通して、データサイエンスをどんどんシンプルにしていきたいです。