pytorch、画像分類
解決したいこと
深層学習初心者で、現在pytorch,githubを用いてCoAtNetによる画像分類を行っているのですが、コードの中のdownsampleが何を表しているのかわかりません。
if sef.downsampleはなにが起こった時に実行されるのでしょうか
コードのurl:https://github.com/chinhsuanwu/coatnet-pytorch/blob/master/coatnet.py
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
発生している問題・エラー
### 該当するソースコード
import torch
import torch.nn as nn
from einops import rearrange
from einops.layers.torch import Rearrange
def conv_3x3_bn(inp, oup, image_size, downsample=False):
stride = 1 if downsample == False else 2
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.GELU()
)
class PreNorm(nn.Module):
def __init__(self, dim, fn, norm):
super().__init__()
self.norm = norm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class SE(nn.Module):
def __init__(self, inp, oup, expansion=0.25):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(oup, int(inp * expansion), bias=False),
nn.GELU(),
nn.Linear(int(inp * expansion), oup, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class MBConv(nn.Module):
def __init__(self, inp, oup, image_size, downsample=False, expansion=4):
super().__init__()
self.downsample = downsample
stride = 1 if self.downsample == False else 2
hidden_dim = int(inp * expansion)
if self.downsample:
self.pool = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
if expansion == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride,
1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
# down-sample in the first conv
nn.Conv2d(inp, hidden_dim, 1, stride, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1,
groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
SE(inp, hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
self.conv = PreNorm(inp, self.conv, nn.BatchNorm2d)
def forward(self, x):
if self.downsample:
return self.proj(self.pool(x)) + self.conv(x)
else:
return x + self.conv(x)
class Attention(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == inp)
self.ih, self.iw = image_size
self.heads = heads
self.scale = dim_head ** -0.5
# parameter table of relative position bias
self.relative_bias_table = nn.Parameter(
torch.zeros((2 * self.ih - 1) * (2 * self.iw - 1), heads))
coords = torch.meshgrid((torch.arange(self.ih), torch.arange(self.iw)))
coords = torch.flatten(torch.stack(coords), 1)
relative_coords = coords[:, :, None] - coords[:, None, :]
relative_coords[0] += self.ih - 1
relative_coords[1] += self.iw - 1
relative_coords[0] *= 2 * self.iw - 1
relative_coords = rearrange(relative_coords, 'c h w -> h w c')
relative_index = relative_coords.sum(-1).flatten().unsqueeze(1)
self.register_buffer("relative_index", relative_index)
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(inp, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, oup),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(
t, 'b n (h d) -> b h n d', h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# Use "gather" for more efficiency on GPUs
relative_bias = self.relative_bias_table.gather(
0, self.relative_index.repeat(1, self.heads))
relative_bias = rearrange(
relative_bias, '(h w) c -> 1 c h w', h=self.ih*self.iw, w=self.ih*self.iw)
dots = dots + relative_bias
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
return out
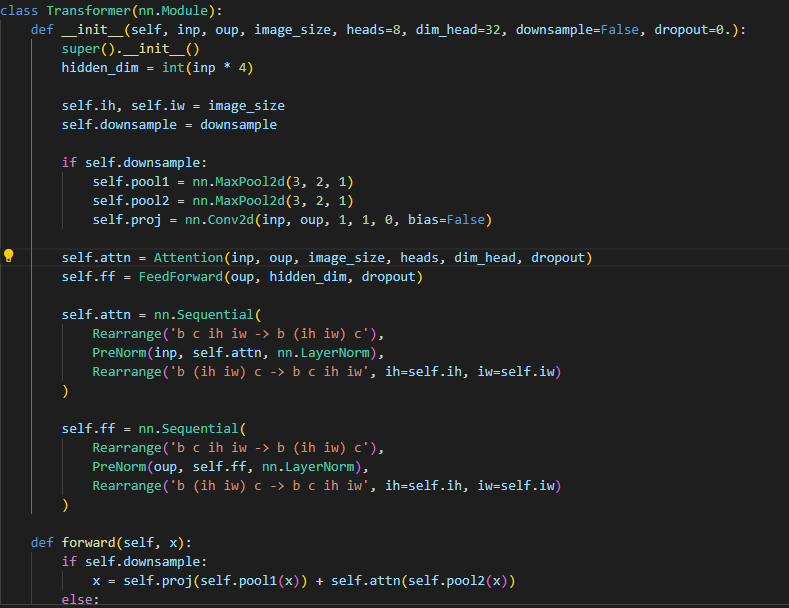
class Transformer(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, downsample=False, dropout=0.):
super().__init__()
hidden_dim = int(inp * 4)
self.ih, self.iw = image_size
self.downsample = downsample
if self.downsample:
self.pool1 = nn.MaxPool2d(3, 2, 1)
self.pool2 = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
self.attn = Attention(inp, oup, image_size, heads, dim_head, dropout)
self.ff = FeedForward(oup, hidden_dim, dropout)
self.attn = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(inp, self.attn, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
self.ff = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(oup, self.ff, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
def forward(self, x):
if self.downsample:
x = self.proj(self.pool1(x)) + self.attn(self.pool2(x))
else:
x = x + self.attn(x)
x = x + self.ff(x)
return x
class CoAtNet(nn.Module):
def __init__(self, image_size, in_channels, num_blocks, channels, num_classes=1000, block_types=['C', 'C', 'T', 'T']):
super().__init__()
ih, iw = image_size
block = {'C': MBConv, 'T': Transformer}
self.s0 = self._make_layer(
conv_3x3_bn, in_channels, channels[0], num_blocks[0], (ih // 2, iw // 2))
self.s1 = self._make_layer(
block[block_types[0]], channels[0], channels[1], num_blocks[1], (ih // 4, iw // 4))
self.s2 = self._make_layer(
block[block_types[1]], channels[1], channels[2], num_blocks[2], (ih // 8, iw // 8))
self.s3 = self._make_layer(
block[block_types[2]], channels[2], channels[3], num_blocks[3], (ih // 16, iw // 16))
self.s4 = self._make_layer(
block[block_types[3]], channels[3], channels[4], num_blocks[4], (ih // 32, iw // 32))
self.pool = nn.AvgPool2d(ih // 32, 1)
self.fc = nn.Linear(channels[-1], num_classes, bias=False)
def forward(self, x):
x = self.s0(x)
x = self.s1(x)
x = self.s2(x)
x = self.s3(x)
x = self.s4(x)
x = self.pool(x).view(-1, x.shape[1])
x = self.fc(x)
return x
def _make_layer(self, block, inp, oup, depth, image_size):
layers = nn.ModuleList([])
for i in range(depth):
if i == 0:
layers.append(block(inp, oup, image_size, downsample=True))
else:
layers.append(block(oup, oup, image_size))
return nn.Sequential(*layers)
def coatnet_0():
num_blocks = [2, 2, 3, 5, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_1():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_2():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [128, 128, 256, 512, 1026] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_3():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_4():
num_blocks = [2, 2, 12, 28, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
if __name__ == '__main__':
img = torch.randn(1, 3, 224, 224)
net = coatnet_0()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_1()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_2()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_3()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_4()
out = net(img)
print(out.shape, count_parameters(net)
1 likes