はじめに
本記事は、長崎県の産業構造を分析・可視化する全3回シリーズの第2回です。 前回の第1回では、e-StatのAPIを利用してデータの取得を行いました。まだご覧になっていない方は、まずそちらからご覧ください。
第1回では e-Stat の API を使い、「都道府県名」「性別」「産業」「年齢階層」「就業者数」のCSV を取得しました。しかし、その CSV をそのまま Tableau に読み込むと、集約行(総数・再掲・全国)や産業の結合表記(例:「農業・林業」)と内訳(例:「うち農業」)が混在し、二重集計や差分計算が必要になります。結果として、ダッシュボードの応答性や信頼性が低下する可能性があります。
そこで第2回では、Tableau 側で集計する方針を維持しつつ、可視化が速く・分かりやすくなるように前処理を行います。Tableau Prepを利用することで解決できるシーンもありますが、ライセンスや自動化が容易でないパターンもあるので、データ取得の流れでPython内で実施します。
1. データの問題点
第1回で出力した CSV を見ると、次のような問題があります。
主な問題点
-
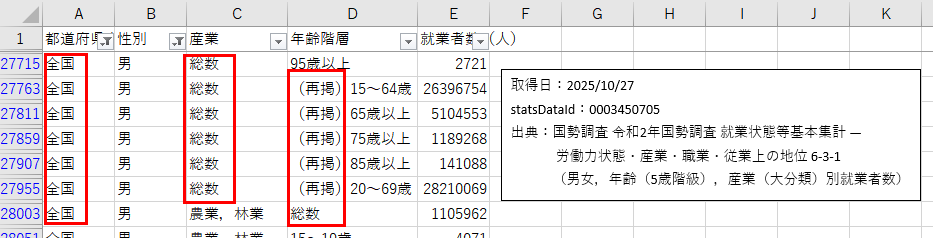
集約行が混在している
「総数」「(再掲)」「全国」などが主要列に混ざると、Tableau にそのまま渡したときにノイズや二重集計の原因になります。
-
結合表記と内訳表記が混在している
「農業・林業」などの結合ラベルと「うち農業」のような内訳が同一グループで混ざると、Tableau 側で毎回差分計算を行う必要があり、応答性が悪化します。

前処理を行うことで、これらの問題点を解消することができます。
2. 前処理で行うこと・行わないこと
データの前処理には、ラベル正規化やマスタ作成、事前集計などさまざまな選択肢があります。今回は、Tableau での探索性を保ちつつ、公開時の応答性を確保するための最小限の処理にフォーカスします。
行うこと
- 「総数」「再掲」「全国」を含む集約行を削除する。
- 「農業・林業」などの結合表記と「うち農業」が揃う場合、「農業」「林業」に分割する。
行わないこと(今回の方針)
- 注記の展開や欠損の自動補完は行わない。(今回のデータでは欠損が来ない前提)
- ラベル正規化やマスタ作成は行わない。(表記は同じで来る前提)
- SUM などの集計計算は Tableau 側で行う。
3. なぜ Python で行削除・分割を行うのか
Tableau で処理を行わず、Pyhonで事前に前処理を行うことで以下のメリットがあります。
-
パフォーマンスの改善
ランタイムでの差分計算や文字列判定を削減することで、フィルタ操作やViz切替時の応答速度が向上します。 -
一貫性と再現性の担保
分割ルールをコードとして保存しておくことで、処理を常に同じ手順で再現できます。
また、処理ロジックの説明や将来の修正も容易になります。 -
自動化による運用負荷の軽減
定期バッチに組み込むことで、データ取得→前処理→出力をすべて自動で実行できます。
4. 処理アルゴリズム
今回実装するコードの処理手順は以下のようになります。
処理手順
-
読み込み直後に集約行を削除します。
「都道府県名」「性別」「産業」「年齢階層」の列のいずれかに「総数」「再掲」「全国」が含まれる行を削除します。 -
都道府県名・性別・年齢階層ごとにグループ処理を行います。
グループ内に「結合ラベル(例:農業・林業)」があり、同グループに「うち農業」行がある場合は次の処理を行います。- combined_val = 結合ラベル行の就業者数合計
- agr_val = 「うち農業」行の就業者数合計
- 農業行 = agr_val(「うち農業」を「農業」に名称変更して保持)
- 林業行 = combined_val − agr_val(新規行を追加)
- 結合ラベル行は削除(置換扱い)
片方だけ存在する場合は、そのまま残します。
-
全グループ処理後、全件を単一 CSV に出力します。
※今回のデータでは注記・欠損・負値は存在しないため、それらの例外処理は含めていません。
5. 実装(コード例)
以下のコードを実行すると、集約行の削除と「農業、林業」の分割を行い、Tableauで集計しやすい CSV に整形します。
import os
import re
import pandas as pd
# ---- 設定 ----
IN_PATH = "input/employment_by_prefecture_industry_age.csv" # 入力CSV
OUT_PATH = "out/employment_cleaned.csv" # 出力CSV
ROW_DROP_KEYWORDS = ["総数", "再掲", "全国"] # 行削除キーワード
COMBINED_PATTERNS = ["農業,林業", "農業,林業", "農業・林業", "農林業"] # 結合ラベル候補
AGR_MARKER = "うち農業" # 農業行判定用
CHECK_COLUMNS = ["都道府県名", "性別", "産業", "年齢階層"] # チェック対象列
os.makedirs(os.path.dirname(OUT_PATH) or ".", exist_ok=True)
# ---- 読み込み ----
df = pd.read_csv(IN_PATH, encoding="utf-8-sig")
# ---- 集約行の削除 ----
existing_check_cols = [c for c in CHECK_COLUMNS if c in df.columns]
if not existing_check_cols:
raise SystemExit(f"None of check columns found in input: {CHECK_COLUMNS}")
# ここを修正:pd.re.escape -> re.escape
pattern = "|".join(map(lambda s: re.escape(s), ROW_DROP_KEYWORDS))
mask_any = df[existing_check_cols].astype(str).apply(lambda col: col.str.contains(pattern, na=False)).any(axis=1)
df = df[~mask_any].reset_index(drop=True)
print(f"Dropped rows where any of {existing_check_cols} contains any of: {ROW_DROP_KEYWORDS}")
# ---- 必須列チェック ----
required_cols = ["都道府県名", "産業", "就業者数(人)"]
for col in required_cols:
if col not in df.columns:
raise SystemExit(f"Required column missing: {col}")
# ---- 分割関数 ----
def split_agri_forest(group):
combined_mask = group["産業"].isin(COMBINED_PATTERNS)
agr_mask = group["産業"].str.contains(AGR_MARKER, na=False)
if combined_mask.any() and agr_mask.any():
combined_val = group.loc[combined_mask, "就業者数(人)"].sum(min_count=1)
agr_val = group.loc[agr_mask, "就業者数(人)"].sum(min_count=1)
agr_row = group.loc[agr_mask].iloc[0].copy()
agr_row["産業"] = "農業"
agr_row["就業者数(人)"] = int(agr_val) if not pd.isna(agr_val) else None
forest_val = None
if not (pd.isna(combined_val) or pd.isna(agr_val)):
forest_val = combined_val - agr_val
if not pd.isna(forest_val):
forest_val = int(forest_val)
forest_row = agr_row.copy()
forest_row["産業"] = "林業"
forest_row["就業者数(人)"] = forest_val
other_rows = group.loc[~(combined_mask | agr_mask)].copy()
out = pd.DataFrame([agr_row, forest_row])
if not other_rows.empty:
out = pd.concat([out, other_rows], ignore_index=True)
return out.reset_index(drop=True)
else:
return group.reset_index(drop=True)
# ---- グルーピングと処理 ----
group_keys = ["都道府県名", "性別", "年齢階層"]
results = []
for keys, grp in df.groupby(group_keys, sort=False):
processed = split_agri_forest(grp)
results.append(processed)
df_out = pd.concat(results, ignore_index=True)
# ---- 出力 ----
df_out.to_csv(OUT_PATH, index=False, encoding="utf-8-sig")
print(f"Saved cleaned data to {OUT_PATH}")
print("処理完了")
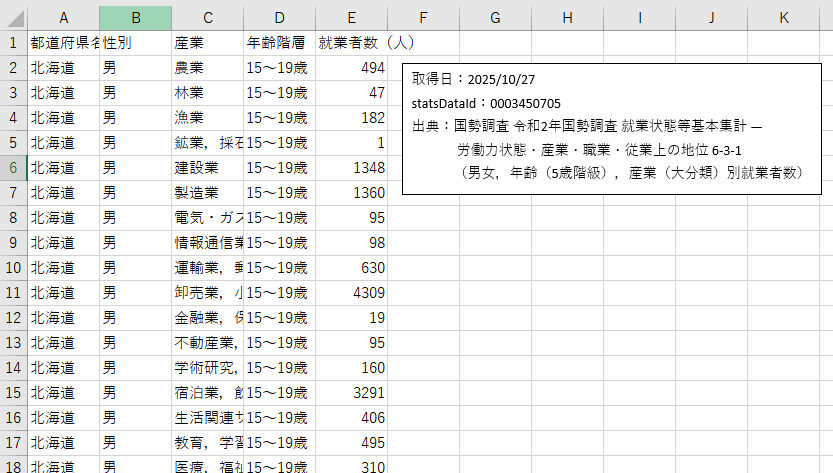
出力を見ると集計行の削除、農業・林業の分割を行った結果のCSVが出力されていることが確認できます。
6. Tableauで集計するメリット・デメリット
今回は、Tableauで集計しやすいように加工したことで、Tableau 標準の SUM 集計 をそのまま利用でき、操作性と応答性を両立できます。
一方で、実運用では表示粒度や定型指標がすでに確定している場合、Tableau 側で毎回重い集計を行うと応答が遅くなることがあります。そのため、可用性(柔軟さ) と パフォーマンス(速度) のバランスをとりながら、必要に応じて事前集計を準備しておくことが重要です。
メリット
-
分析者が集計軸や計算フィールドを自由に変更でき、仮説検証が早くなる。
-
一時的・探索的な分析に強くなる。
デメリット
-
データ量やフィルタの組み合わせによって集計処理に時間がかかる場合がある。
-
複数の作成者やダッシュボードがある場合、集計ルールの統一が難しくなる。
-
公開環境では抽出(.hyper)やサーバー容量の調整が必要になり、運用負荷が増える。
運用のベストプラクティス
探索段階では Tableau 側で集計を行うことで、柔軟に分析します。その後、公開段階で表示粒度や指標が確定したら、その単位に合わせた事前集計データを用意することで可用性とパフォーマンスを両立できます。
最後に
今回は、不要行の削除と産業カテゴリ「農業、林業」の分割を行い、Tableauで扱いやすい CSV を出力しました。次回はこのデータを Tableau に取り込み、ダッシュボードを作成します。次回もお楽しみに。