はじめに
皆さんTableauでダッシュボードを作るとき、データソースの準備で困ったことはありませんか?
手作業だと時間がかかり、更新も面倒になります。そこで本シリーズでは、e-StatのAPIを使ってPythonで統計データを機械的に取得・整形し、最終的にTableauで可視化するまでをステップごとに解説します。
- 第1回 Pythonによるe-Statからのデータ取得(今回)
- 第2回 取得したデータの加工
- 第3回 Tableauによるダッシュボード作成
第1回は「データ取得編」です。 ここではe-Statにある、国勢調査 / 令和2年国勢調査 / 就業状態等基本集計 からe-Stat APIを使って 「都道府県名」「性別」「産業」「年齢階層」「就業者数」を抽出し、CSVに整形するまでを実践コード付きで紹介します。
アカウント作成やAPIキーの発行からJSON構造の確認、分類コード→ラベルのマッピング、そしてCSV出力までをコードを通してご紹介したいと思います。
1.APIキーの取得の順序
APIリクエストに用いるAPIキーを取得します。入手したAPIキーは厳重に管理してください。
手順は以下の通りです。
-
e-Stat公式サイトにアクセスしてユーザー登録を行います。
e-Stat公式サイト:政府統計の総合窓口 -
ログイン後、マイページ > API機能(アプリケーションID発行)を開きます。
-
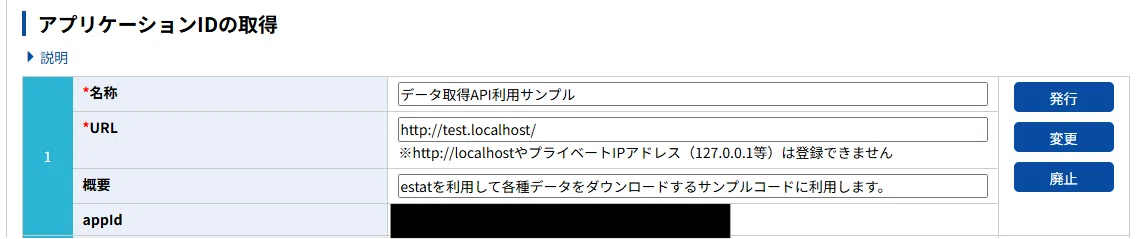
下記情報を入力してアプリケーションIDを発行します。
- 名称:API機能を利用するアプリケーション名(システム名等)
- URL:アプリケーションのURL(※公開サイトで利用しない場合は[http://test.localhost/]等を入力してください。)
- 概要:アプリケーション(システム)の概要
取得したAPIキーは厳重に管理してください。
2.APIリクエストURLの取得
取得したい統計データに対して、APIリクエストを行うリクエストURLを取得します。
手順は次の通りです。
-
利用したい統計データをe-Stat上で探します。
今回は下記、統計データを利用します。
国勢調査 / 令和2年国勢調査 / 就業状態等基本集計 -
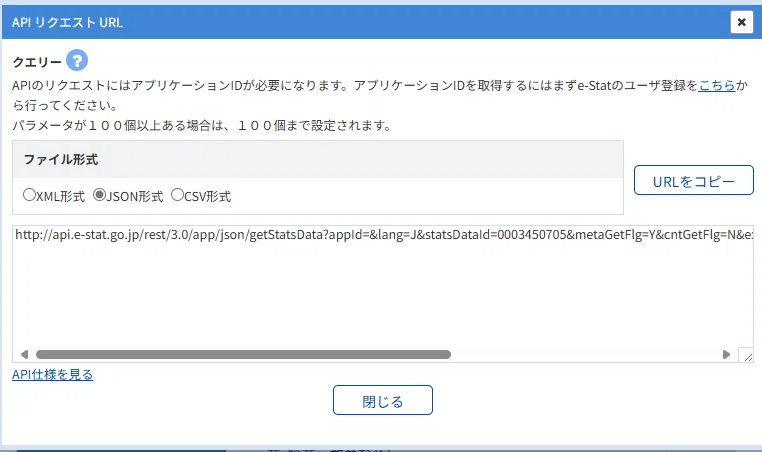
APIリクエストURLを取得します。
統計表ページで「API」ボタンを押すと下記ダイヤログが表示されますので、JSON形式のURLを取得します。
3.JSON構造の確認
取得したURLとパラメータを使ってGETリクエストを行い、レスポンスからJSON構造を確認します。全国データであれば量が少なく応答も早いので、cdArea='00000' を利用します。
-
エンドポイント
http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData
-
主要パラメータ
- appId:API ※1.APIキーの取得の順序で取得したAPIキー
- statsDataId:取得する統計表ID
- metaGetFlg:CLASS_INF を取得するか否か
- cdArea:対象エリア
下記に実際のコードを記載します。
import requests, json
URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData"
params = {
"cdArea":"00000", #"00000"は、全国データ
"appId": "APIキー", # 実運用では環境変数や設定ファイルから読み込むこと(鍵は公開しない)
"lang": "J",
"statsDataId": "0003450705", #取得する統計表ID
"metaGetFlg": "Y", #CLASS_INF を取得するか否か
"cntGetFlg": "N",
"explanationGetFlg": "Y",
"annotationGetFlg": "Y",
"sectionHeaderFlg": "1",
"replaceSpChars": "0"
}
r = requests.get(URL, params=params)
r.raise_for_status()
resp = r.json()
print(json.dumps(resp["GET_STATS_DATA"]["STATISTICAL_DATA"], ensure_ascii=False, indent=2))
実際にリクエストを投げ、レスポンスに STATISTICAL_DATA > CLASS_INF(分類の定義) と DATA_INF > VALUE(観測値) が含まれていることを確認します。
-
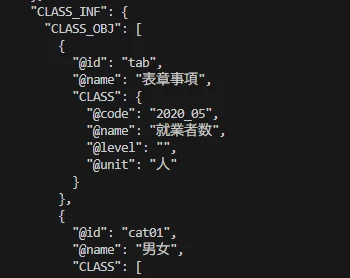
CLASS_INF(分類の定義)※一部抜粋
-
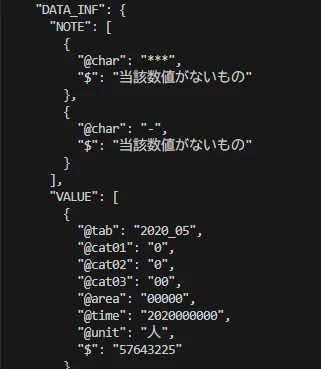
DATA_INF > VALUE(観測値) ※一部抜粋
4.メタデータからマッピングを作る方法
3章の出力を見れば分かるとおり、APIの DATA_INF の VALUE 要素は各観測セルに対して分類コード(例: @cat01, @cat02, @cat03, @area …)で属性を持っています。
これを人が読みやすいラベルに変換するには、CLASS_INF から「コード → 名称」のマップを作成する必要があります。
考え方と実装ポイント
- CLASS_INF 配下には複数のCLASS_OBJやCLASSがあり、それぞれに @id 属性(例: "cat01" が性別、"cat02" が産業など)が付いています。
- 各 CLASS の中に複数の CLASS 要素があり、@code と @name が存在するため、これらを辞書に変換しておくと VALUE のコードを名称に変換できます。
- CLASS_OBJ が入れ子になっているケースもあるため、汎用的に探索して取り出す関数を用意することを推奨します。
以下のコードは、上記のポイントに基づき、CLASS_INF から「コード → 名称」のマップを作成する関数です。
def build_class_map(class_objs, target_id):
"""
class_objs: data["GET_STATS_DATA"]["STATISTICAL_DATA"]["CLASS_INF"]["CLASS_OBJ"]
target_id: 取得したい分類の @id(例: "cat01", "cat02", "cat03", "@area")
戻り値: { code: name, ... }
"""
for cls in class_objs:
if cls.get("@id") == target_id:
# CLASS が直接ある場合
if "CLASS" in cls:
return {c["@code"]: c["@name"] for c in cls["CLASS"]}
# CLASS_OBJ の中に CLASS がまとまっている場合
if "CLASS_OBJ" in cls:
mapping = {}
for obj in cls["CLASS_OBJ"]:
if "CLASS" in obj:
for c in obj["CLASS"]:
mapping[c["@code"]] = c["@name"]
return mapping
return {}
5.実装(コード例)
実際にCLASS_INFで作ったマップを使ってVALUEを整形し、CSVへ出力する実践コード例です。コードを実行するとAPI呼び出し、マッピング、VALUE抽出、CSV出力まで一連の動作を行います。
import requests
import pandas as pd
# --- API設定 ---
URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData"
params = {
"cdArea": ",".join([
"00000","01000","02000","03000","04000","05000","06000","07000",
"08000","09000","10000","11000","12000","13000","14000","15000",
"16000","17000","18000","19000","20000","21000","22000","23000",
"24000","25000","26000","27000","28000","29000","30000","31000",
"32000","33000","34000","35000","36000","37000","38000","39000",
"40000","41000","42000","43000","44000","45000","46000","47000"
]),
"appId": "APIキー",
"lang": "J",
"statsDataId": "0003450705",
"metaGetFlg": "Y",
"cntGetFlg": "N",
"explanationGetFlg": "Y",
"annotationGetFlg": "Y",
"sectionHeaderFlg": "1",
"replaceSpChars": "0"
}
# --- API呼び出し ---
res = requests.get(URL, params=params)
res.raise_for_status()
data = res.json()
# --- 分類コード → 名称マップ作成() ---
def build_class_map(class_objs, target_id):
for cls in class_objs:
if cls.get("@id") == target_id:
if "CLASS" in cls:
return {c["@code"]: c["@name"] for c in cls["CLASS"]}
if "CLASS_OBJ" in cls:
mapping = {}
for obj in cls["CLASS_OBJ"]:
if "CLASS" in obj:
for c in obj["CLASS"]:
mapping[c["@code"]] = c["@name"]
return mapping
return {}
class_objs = data["GET_STATS_DATA"]["STATISTICAL_DATA"]["CLASS_INF"]["CLASS_OBJ"]
sex_map = build_class_map(class_objs, "cat01")
industry_map = build_class_map(class_objs, "cat02")
age_map = build_class_map(class_objs, "cat03")
area_map = build_class_map(class_objs, "area")
# --- VALUE抽出 ---
values = data["GET_STATS_DATA"]["STATISTICAL_DATA"]["DATA_INF"]["VALUE"]
rows = []
for v in values:
sex = sex_map.get(v.get("@cat01"), v.get("@cat01"))
industry = industry_map.get(v.get("@cat02"), v.get("@cat02"))
age = age_map.get(v.get("@cat03"), v.get("@cat03"))
area = area_map.get(v.get("@area"), v.get("@area"))
val = v.get("$") or v.get("@value") or v.get("value")
if val in ("", None, "-", "***", "…", "*"):
continue
try:
count = int(str(val).replace(",", ""))
except Exception:
continue
rows.append({
"都道府県名": area,
"性別": sex,
"産業": industry,
"年齢階層": age,
"就業者数(人)": count
})
# --- CSV保存 ---
df = pd.DataFrame(rows)
df.to_csv("employment_by_prefecture_industry_age.csv", index=False, encoding="utf-8-sig")
print("✅ 都道府県別 × 産業別 × 年齢階層別 × 性別の就業者数を 'employment_by_prefecture_industry_age.csv' に保存しました")
出力したCSVを開くと正しくデータが取得できていることが確認できます。取得したデータを公開する際は必ず、取得日、statsDataId、出典を明記するようにしましょう。
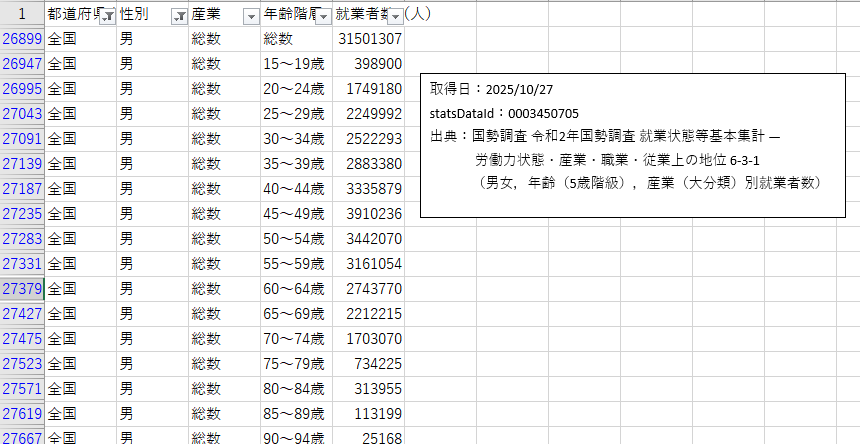
6.実務上の注意点
今回のコードでは考慮していない点もありますが、実際に運用する際は下記にご注意ください。
- APIキー管理:公開リポジトリや記事内でキーを公開しないようにしましょう。
- ページングとレート制御:Pythonで大量のデータをAPI経由で取得する際、「ページングとレート制御」を行い、マナーを守りながら、効率化も実装しましょう。
- メタデータ保存:CLASS_INF を JSON として保存しておくと再利用に便利です。
- ログ:**statsDataId、params、取得日時、レスポンスサイズ、保存ファイル名はログに残しておくと振り返りに便利です。
- ライセンス表示:Vizを作成する際には統計表名、statsDataId、取得日を必ず明記するようにしましょう。
最後に
この第1回では、e-Statのアカウント作成からAPIキーの取得、APIレスポンスの確認、分類コード→ラベルのマッピング、CSV出力までをコードを通して解説しました。ただし、今回取得した CSV はそのままTableauで扱うにはいくつかの課題があります。次回はCSVのデータをTableauで扱うためにきれいに加工していきましょう。
第2回をお楽しみに。