みなさま、こんにちは。
最近、クロスドメインレコメンドに取り組む機会がありまして、「よろしく!」みたいな感じになったものの、どうやってやるんだ?????となりその過程でそこそこ調べ物をしました。
この記事はその調べ物の供養です。安らかに眠ってほしいと思います。
TL;DR
- クロスドメインをどうやればいいのか取り組むにあたって調べた内容の供養です
- 実データでの検証もしました
- PopularItemsに負けることすらあり、クロスドメインレコメンドはとても難しい
前半が説明パート、後半が実験してみた結果報告パートです。
前半が結構冗長になってしまったので、後半で使ったコードを置いているリポジトリのURLを予め貼っておきます。ご活用ください〜。
リポジトリ-> https://github.com/fufufukakaka/cross-domain-recommend-survey
0. そもそもクロスドメインレコメンドとは
クロスドメインレコメンドというのは調べて初めて気付いたのですが、英語でも全然まとまっている文献がないです。転移学習とかそういう文脈と一緒になってるからだと思います。
ちなみにqiitaでも全く記事がないです。出てくるのはクロスドメインリクエスト(AjaxとかCORSとかそういう文脈)でした。
一番まとまっているのは2014年のRecSysチュートリアルです。

この記事も主にこのスライドをなぞりつつ省きつつという形で進めていきます。ちょいちょい実際のスライドを引用して貼っていきます。
さて、このスライドによればクロスドメインレコメンドとは「ソースドメインの情報をターゲットドメインに転移させて(knowledge transfer)、レコメンドを行うこと」とされています。
クロスドメインレコメンドの歴史はとても浅く、2002年に初めて文献に登場したようです。2005年からちらほら言及が出始めて2007年にいくつか論文が出てきたって感じですね。レコメンドという文脈におけるクロスドメインの歴史はまだまだ浅いです。

1. ドメインの定義
ドメインがそもそも何を指すのか、ですが大きく「アイテムの種類の違い」・「ユーザの種類の違い」に分けられます。
[具体例]
- アイテムの種類... movielensにおける映画ジャンル、やECサイトにおける本と音楽
- ユーザの種類... 頻度の違うユーザ(超アクティブユーザとほぼ休眠ユーザ)、アクションしているサービスが違うユーザ
わりと解釈次第でドメインの違いは考えられそうですね。僕は大雑把に分布が違いそうだなと思ったら違うドメインになりそうくらいの理解をしています。
スライドによると、Attribute・Type・Item・System という4つに分類されておりまして、一番論文でよく出てくるのはItemレベルのクロスドメインを扱ったものだそうです。MovieLensがやけに出てくるところからも、やっぱりレコメンドのデータセット王者はMovielensって感じがしますね...

自分のやりたいクロスドメインレコメンドがどれに当たるかを考えた上で「これはあまり論文なさそう」とか「結構見つかりそう」とかの指針立てに使えそうな数字ですね〜。
2. クロスドメインの状況の分類
さて、クロスドメインが定義できたところで、次は「ソースドメインとターゲットドメインがどういう関係性になっているか」も考えないといけません。
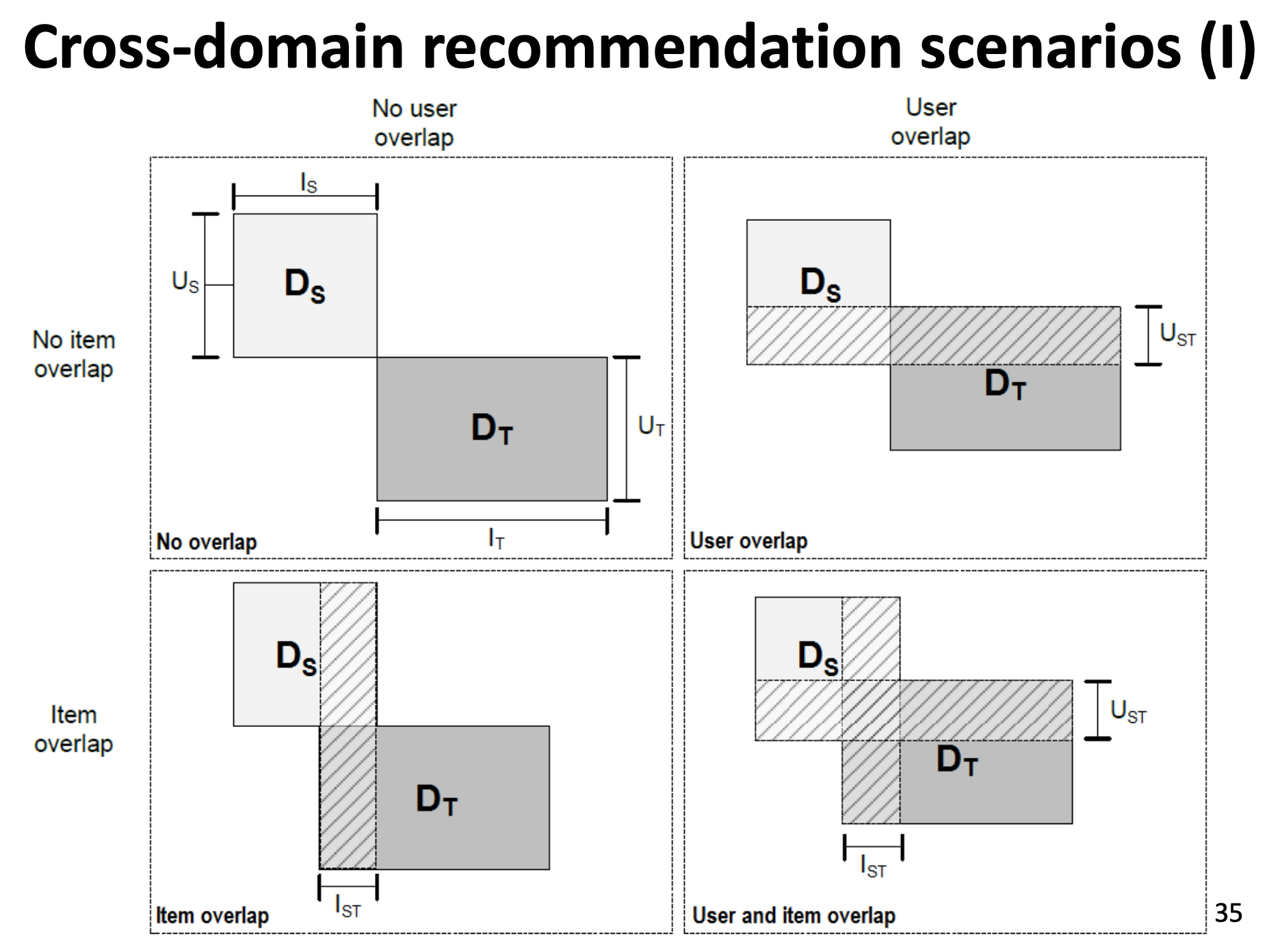
その「シナリオ」は全部で4つあります。
- ユーザもアイテムも重なっているものがない(
No Overlap) - ユーザだけ重なっている(
User Overlap) - アイテムだけ重なっている(
Item Overlap) - ユーザもアイテムも重なっている(
User and Item Overlap)
シナリオごとにどんな手法が使えるか、効果的なのかが変わってくるので注意が必要です。論文を読むときに「こいつはどういうシナリオに対する手法を提案しているのか?」に気をつけながら読むと良さそうです。
ちなみに、当たり前ですが重なりが大きければそれだけ転移がしやすくなり難易度が下がります。
3. どんな手法でクロスドメインレコメンドをするか
さて、そろそろ本題に近づいてきました。「クロスドメインレコメンドってどうやるの?」パートです。
クロスドメインは、要するにknowledge transferをどうやるかってことで、大まかに2つに分けられます。
- Linking/Aggregating Knowledge... 集約して扱う
- Sharing/Transfering Knowledge... 別々に扱ったあと、転移させる
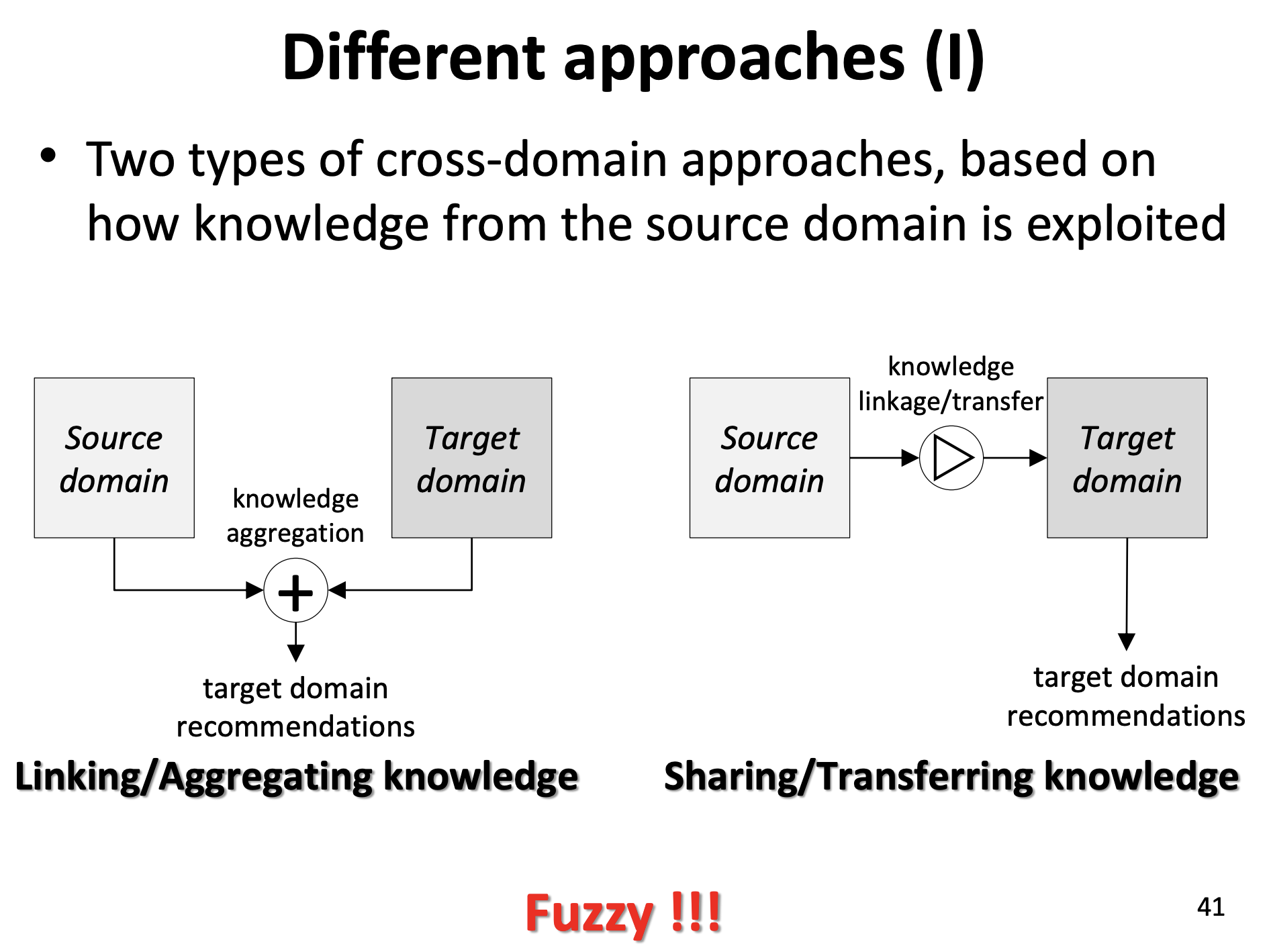
さて、これだけだとスライドにもあるように「曖昧すぎる!!!」ですね。具体的にどうやるかでいうと、それぞれ更に小さい分類になります。

それぞれ具体的な例などを混ぜつつ説明していきます。
a. Linking/Aggregating Knowledge
1. Merging User Preference
ソース・ターゲットドメイン両方のrating matrixをまとめあげて、一つのrating matrixにして single-domainテクニックを使うなど、のようなまとめあげる手法です。
2. Mediating User Modeling Data
各ドメインでユーザ・アイテムベクトルを得た後、ターゲットドメインにアクションしていないユーザに対しては、ソースドメインでのk近傍ユーザ(ターゲットドメインでアクションしている人たち)を獲得し、それらk近傍ユーザのターゲットドメインに対するレコメンド結果の平均を、対象ユーザへのレコメンドとします。k近傍で説明しましたが、どんな手法で mediate するかは色々バリエーションがあります。
(有料だったので中身を読めていませんが、チュートリアルスライド内での紹介的には多分これがk近傍でmediateするタイプのもののはず... Cross-Domain Mediation in Collaborative Filtering)
3. Combining Recommendations
a.1とa.2はなくてもできますが、この手法はユーザとアイテムの両方がドメインでまたがっている必要があります。両方のドメインそれぞれでレコメンドを出した後、それらの予測値をマージして対象ユーザへのレコメンドを出します。
(movielensを対象にしたcombineアプローチの一例。Distributed Collaborative Filtering with Domain Specialization)
4. Linking Domains
主にターゲットドメインに対するレコメンドのみを行いますが、その計算を行う際にソースドメイン・外部知識を制約条件に入れて、ターゲットドメインのレコメンドのカバレッジ・精度をあげようという感じのものです。
(ソースドメインからターゲットドメインへのリンク予測を行ってドメインをリンクさせようとするやつ Transfer Learning for Collective Link Prediction in Multiple Heterogenous Domains)
b. Sharing/Transfering Knowledge
1. Sharing Latent Features
a.4の Linking Domainsとちょっと似ていますが(個人的な意見)、ターゲットドメインへのレコメンドをソースドメインから持ってきたlatent factorをシェアすることで行うというものです(これはadaptiveな手法で、collectiveに行うものとして同時に解くというものもあります)。
ユーザとアイテムが重なっていて、ratingパターンだけが違うシナリオであれば、同時に解く感じの手法が使えます。
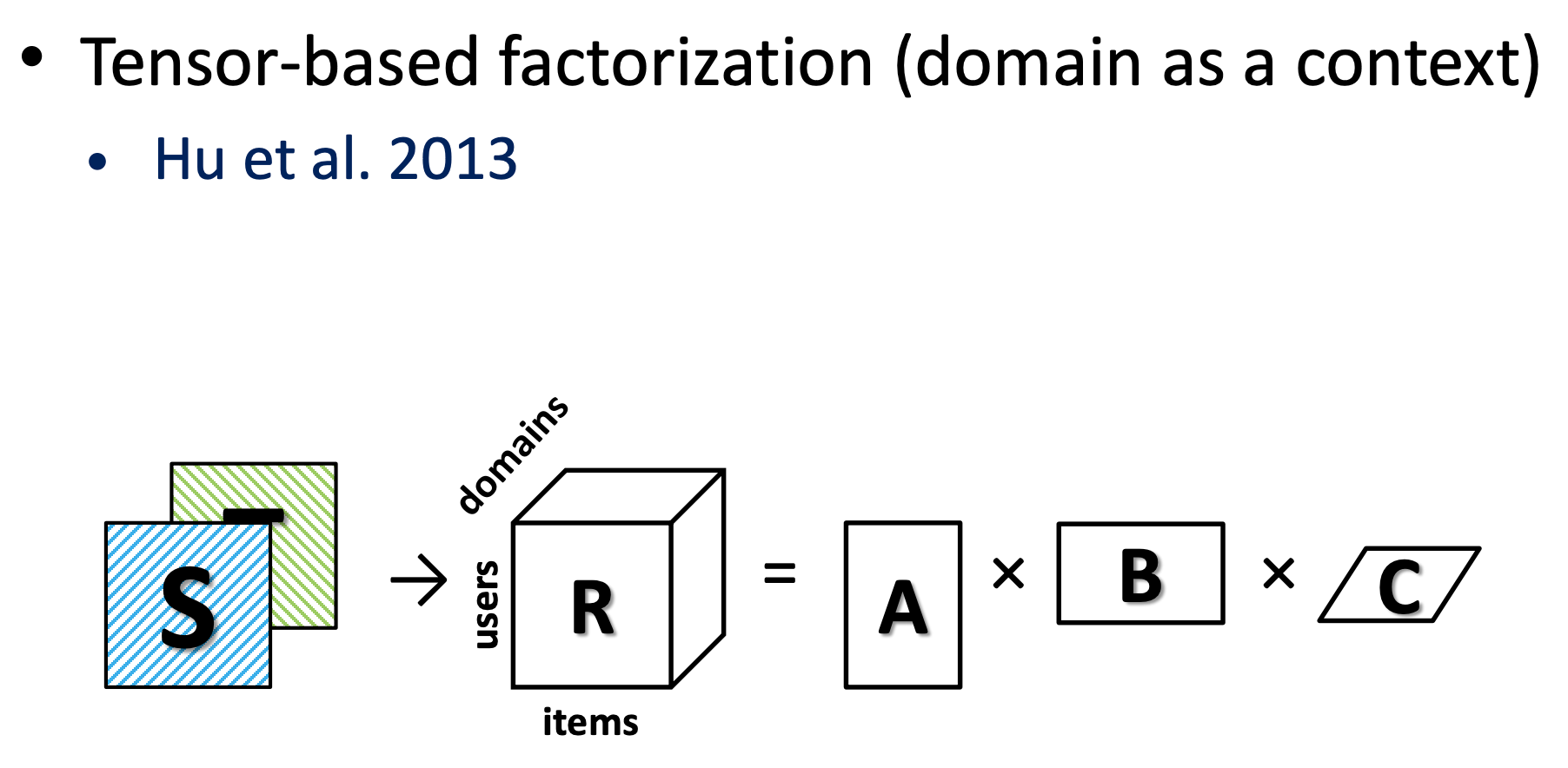
ユーザだけ被っている場合に使える手法としては ドメイン部分をコンテキストに含めた tensor-based factorizationなどがあります。(Personalized Recommendation via Cross-Domain Triadic Factorization)
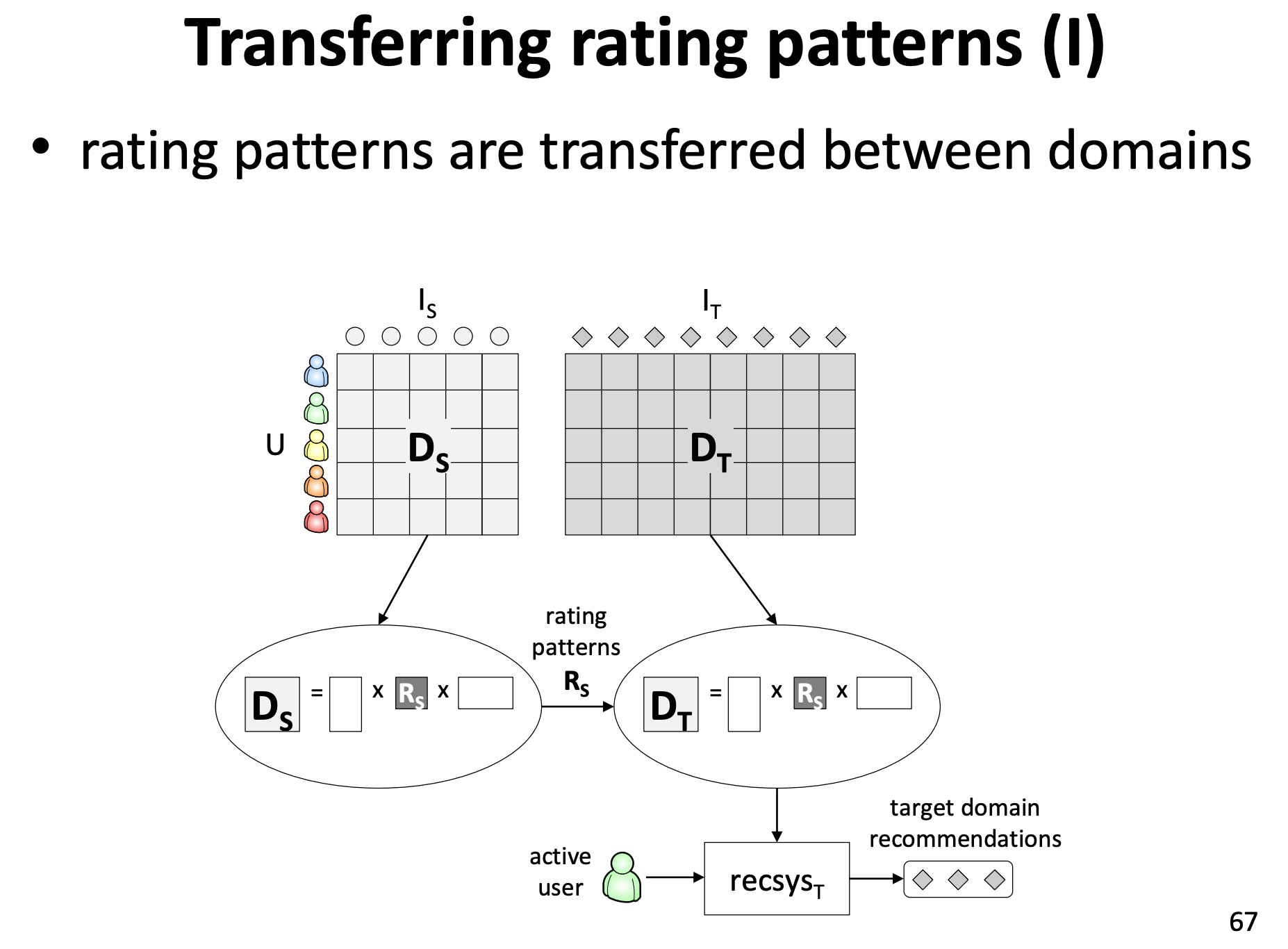
2. Transferring Rating Patterns
ユーザもアイテムも重なっているものがないけど、という場合にはこの手法が使えます。
両ドメインのrating matrixを同時にクラスタリングして(co-clustering)、同じクラスタに属する、などの情報を使ってターゲットドメインへのレコメンドを行います。(Can Movies and Books Collaborate? Cross-Domain Collaborative Filtering for Sparsity Reduction)
4. 実際にクロスドメインレコメンドをやってみよう
さて、ここまで長々説明してまいりましたが、実際にやっていってみましょう。
今回扱うデータは
- MovieLens(20M)のActionジャンルとAdventureジャンル... ユーザとアイテムがオーバーラップしているデータ(https://grouplens.org/datasets/movielens/20m/)
- AmazonレビューデータセットのBookとMovies... ユーザのみオーバーラップしているデータ(http://jmcauley.ucsd.edu/data/amazon/)
という感じでやっていきます。
扱う手法は基本的にMatrix Factorization(ALS)をベースにして
-
Aggregate... 2つのドメインのrating matrixをまとめて一つのrating matrixにする -
K-Neighbor Mediate... k近傍のユーザのレコメンドの結果を平均して、コールドユーザへのレコメンドとする -
Collective Matrix Factorization...a.4_Linking Domainsかb.1_Sharing Latent Featuresのどっちに分類するか分からないんですが、ソースドメインの情報を制約条件として使うターゲットドメインへのMatrix Factorization -
Transfer User Vector(CCA)... (多分Sharing Latent Featuresに分類されると思うのですが)CCAでソースドメインからターゲットドメインにユーザベクトルを写像するものを学習します -
Transfer User Vector(Neural Net)... こちらはCCAの代わりにいい感じのニューラルネットで写像関数を学習します
という感じです。
リポジトリ→ https://github.com/fufufukakaka/cross-domain-recommend-survey
以下、コードを交えつつどんな感じで実際にやったのかを見ていきます。
4.1 Aggregate
ここではMovieLensでやったものをコード例として示します。Aggregate以外でも必要になるデータの準備からつらつらと書いています。
# %%
from tqdm import tqdm
import pandas as pd
from scipy import sparse
import numpy as np
import implicit # 今回、ALSはこのライブラリで計算を行います
# %%
# データの準備
# read
movies = pd.read_csv("data/ml-20m/movies.csv")
ratings = pd.read_csv("data/ml-20m/ratings.csv")
# join
ratings_joined = pd.merge(ratings, movies)
# actionジャンルとadventureジャンルを含む映画に対するratingのみ取り出す
action_adventure_ratings = ratings_joined.query("genres.str.contains('Action') or genres.str.contains('Adventure')",
engine='python').reset_index(drop=True)
# %%
# sparse matrixに変換するための準備
# 元のidとsparse matrix変換後のidの対応を取るために辞書を作る
# userid
userid_unique = pd.Series(action_adventure_ratings["userId"].unique())
index_userid_dict = userid_unique.to_dict()
# inverse
userid_index_dict = dict(map(reversed, index_userid_dict.items()))
# itemid
itemid_unique = pd.Series(action_adventure_ratings["movieId"].unique())
index_itemid_dict = itemid_unique.to_dict()
# inverse
itemid_index_dict = dict(map(reversed, index_itemid_dict.items()))
action_adventure_ratings["user_id"] = action_adventure_ratings["userId"].map(userid_index_dict)
action_adventure_ratings["item_id"] = action_adventure_ratings["movieId"].map(itemid_index_dict)
# reindexしたidを使って、アイテムとジャンルの対応が取れるdictを作る
itemid_genres_dict = action_adventure_ratings[['item_id', 'genres']].set_index('item_id')['genres'].to_dict()
今回はソースドメインとターゲットドメインを一つのrating matrixとして扱います。なので全部まとめてsparse matrixへ。
# %%
# build sparse matrix
item_id_values = action_adventure_ratings["item_id"].values
user_id_values = action_adventure_ratings["user_id"].values
rating_values = action_adventure_ratings["rating"].values
X = sparse.csr_matrix(
(rating_values, (user_id_values, item_id_values)))
split_train_validation_cold_start_user_wise (RecSys2019BestPaperのリポジトリにあった分割関数)を使って、testにいるユーザがtrainにアイテムがない状態がないように分割します。
# %%
from lib.recommend_util import split_train_validation_cold_start_user_wise
X_train, X_test = split_train_validation_cold_start_user_wise(X, verbose=True, cold_items=2, full_train_percentage=0.2)
trainデータが作れたのでこれを使ってALSを実行。
np.random.seed(42)
model = implicit.als.AlternatingLeastSquares(factors=100)
# item,userの向きにする必要があるのでtranspose
model.fit(X_train.transpose())
# rating matrixを予測
predicted_ratings = np.dot(model.user_factors, model.item_factors.T)
testデータから、評価用の辞書を作成します。
# 評価用辞書の作成(ターゲットドメインはadventure)
test_adventure_pos_items_dict = {}
for i in tqdm(range(X_test.shape[0])):
rated_items = X_train[i, :].indices
# trainでadventureにアクションしていないユーザを選ぶ
if len([v for v in rated_items if 'Adventure' in itemid_genres_dict[v]]) == 0:
# 且つX_testの中でstoreしているアイテムが0以上のユーザを選ぶ
if X_test[i, :].nnz > 0:
test_items = []
selected_user_ratings = X_test[i, :]
value_indices = selected_user_ratings.indices
sorted_indices = np.argsort(-X_test[i, :].toarray())[0]
# X_testの中でvalueがあるアイテムのジャンルがadventureの場合に
# それを評価対象データに追加する
for v in sorted_indices[:len(value_indices)]:
if 'Adventure' in itemid_genres_dict[v]:
test_items.append(v)
if len(test_items) > 0:
test_adventure_pos_items_dict[i] = test_items
最後に、予測したrating matrixから、testデータのユーザに対してターゲットドメイン(adventureジャンル)のアイテムを推薦し、その精度をndcgで測ります。
from lib.recommend_util import ndcg
# 評価する
# ndcg@kでk各種
ndcgs = {
'ndcg5': [],
'ndcg10': [],
'ndcg20': [],
'ndcg50': [],
'ndcg100': []
}
for userid, pos_itemid in tqdm(test_adventure_pos_items_dict.items()):
pos_itemid = np.array(pos_itemid)
# 予測した評価値の中でadventureのアイテムを持ってくる
sorted_indices = np.array([v for v in np.argsort(-predicted_ratings[userid, :]) if 'Adventure' in itemid_genres_dict[v]])
ndcgs['ndcg5'].append(ndcg(sorted_indices[:5], pos_itemid))
ndcgs['ndcg10'].append(ndcg(sorted_indices[:10], pos_itemid))
ndcgs['ndcg20'].append(ndcg(sorted_indices[:20], pos_itemid))
ndcgs['ndcg50'].append(ndcg(sorted_indices[:50], pos_itemid))
ndcgs['ndcg100'].append(ndcg(sorted_indices[:100], pos_itemid))
print(f"ndcg@5: {np.mean(ndcgs['ndcg5'])}")
print(f"ndcg@10: {np.mean(ndcgs['ndcg10'])}")
print(f"ndcg@20: {np.mean(ndcgs['ndcg20'])}")
print(f"ndcg@50: {np.mean(ndcgs['ndcg50'])}")
print(f"ndcg@100: {np.mean(ndcgs['ndcg100'])}")

という感じで、一連の流れを見てみました。
ndcg@5で0.11ということで、クロスドメインレコメンドにしては予想よりも高い数値が出ました。 MovieLensは一つのアイテムに複数のジャンルがつき、ActionとAdventureはかぶっていることがかなりたくさんあるので、クロスドメインの問題設定としては簡単な部類に入るので、こんなもんかなという感想です。
というか、MovieLensをクロスドメインの問題として解くことがあまりない(Aggregate自体は通常のレコメンドとなんら変わらないですが)。
今回はスコアまで示しましたが、スコアは最後に表でドンと示すこととし、以降はあくまで流れを追う形で進めていきます。
4.2 K-Neighbor Mediate
ここからは前項とはかぶらない部分のみコードを紹介します。
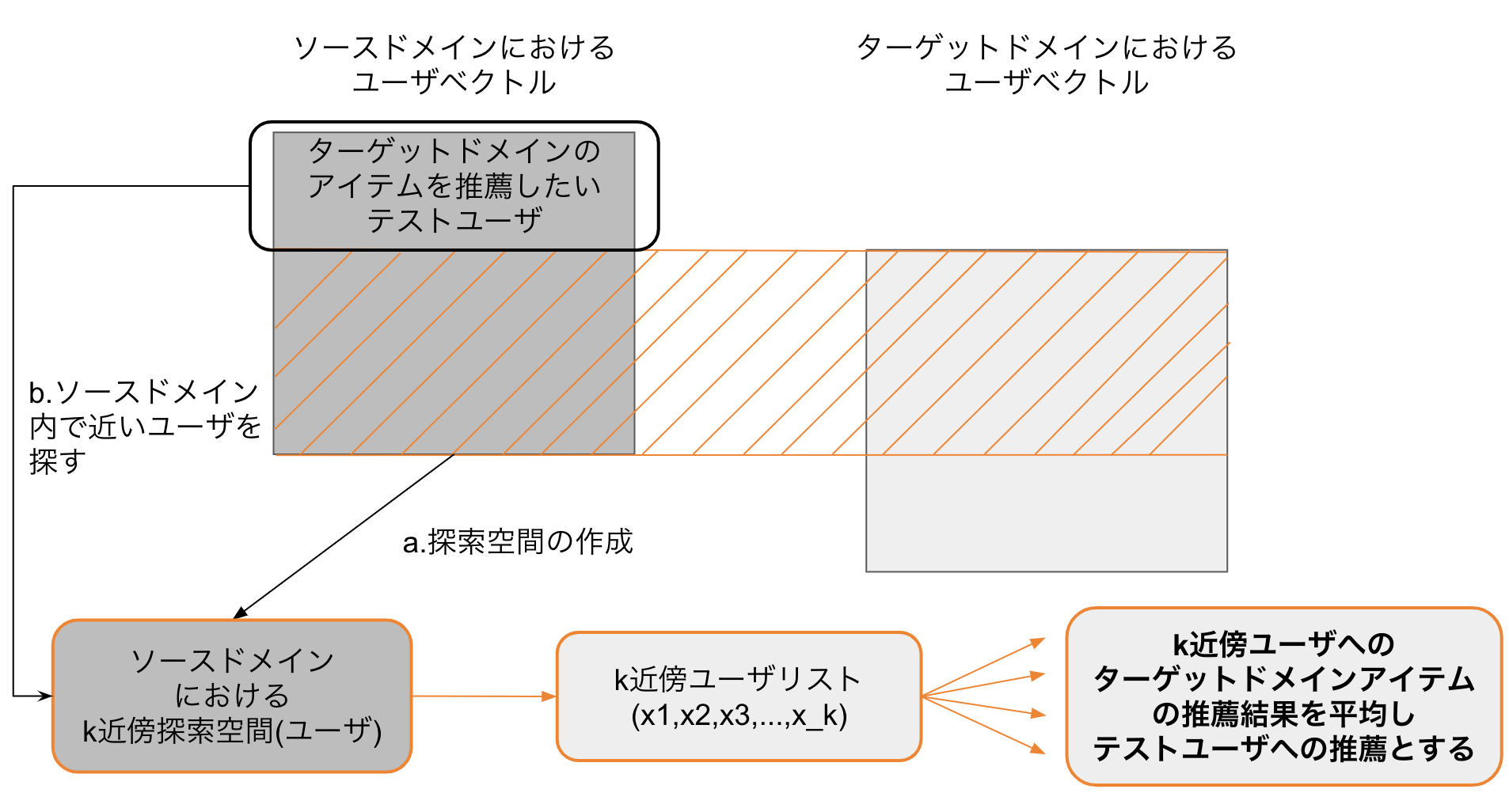
k近傍を使ってどうクロスドメインレコメンドするかですが、
- ソースドメイン、ターゲットドメインでALSを行い、各ドメインにおけるユーザベクトルを獲得
- ソースドメイン・ターゲットドメイン両方にアクションしているユーザを集めて、ソースドメインにおけるユーザベクトルを用いてk近傍探索空間を作成
- テストユーザ(testデータでターゲットドメインにアクションしていないが、trainデータでソースドメインにはアクションしている)らについて、ソースドメインで近いk近傍ユーザを上述した探索空間から得る
- それらk近傍ユーザはターゲットドメインにもアクションしているので推薦が出せる。これら推薦結果の平均を、最終的に推薦したいテストユーザへの推薦とする。
文字にするとこんな感じで、絵にすると以下のようになります。
# trainデータをそれぞれのドメインのみのデータに限定する
# actionの列
action_columns = [v for v in range(X_train.shape[1]) if 'Action' in itemid_genres_dict[v]]
# adventureの列
adventure_columns = [v for v in range(X_train.shape[1]) if 'Adventure' in itemid_genres_dict[v]]
# 選んだカラムに応じてとってくる
action_train = X_train[:, action_columns]
adventure_train = X_train[:, adventure_columns]
# それぞれにアクションしていないユーザを削る
# 全ユーザと、削ったあとでの対応関係を辞書として持っておく(ここでは割愛)
action_train_selected = action_train[action_train.getnnz(1)>0]
adventure_train_selected = adventure_train[adventure_train.getnnz(1)>0]
...
# それぞれで行列分解
np.random.seed(42)
action_ALS = implicit.als.AlternatingLeastSquares(factors=100)
action_ALS.fit(action_train_selected.transpose())
adventure_ALS = implicit.als.AlternatingLeastSquares(factors=100)
adventure_ALS.fit(adventure_train_selected.transpose())
# ソースドメイン(actionジャンル)でk近傍ユーザ探索空間を作る
from sklearn.neighbors import NearestNeighbors
neigh = NearestNeighbors()
neigh.fit(action_ALS.user_factors)
k近傍探索空間ができたら、近いユーザを求めていきます。今回はk=10とします。
(ソースドメインとターゲットドメインで、matrixのshapeが異なり同じindexではないので、ちょいちょいそれに対処するようなコードが入っています。)
neighbors_users = {}
# adventure側にアクションしていないユーザについて
for userid in tqdm(test_adventure_pos_items_dict.keys()):
# このuseridはもともとのデータ(movielens)のuserid
try:
# このユーザが、action_ALSにかけたmatrixにおいて何行目なのかを事前に作った辞書から求める
action_user_id = action_train_action_users[userid]
except:
continue
# indexが見つかったらユーザベクトルを求める
action_user_vector = action_ALS.user_factors[action_user_id,:]
# 候補ユーザを得る(これら候補ユーザはactionの次元)
candidate_users = neigh.kneighbors([action_user_vector], 100, return_distance=False)[0][1:]
# もともとのデータ(movielens)の次元に戻す
candidate_users_ = [inverse_action_train_action_users[v] for v in candidate_users]
candidates_ = []
for c in candidate_users_:
# adventure_trainに存在しているかを確認する
if c in adventure_train_action_users:
# 存在しているならneighbors_usersにconcatの次元のuseridで足す
candidates_.append(c)
# 最大10人取得する
neighbors_users[userid] = candidates_[:10]
上記で求めた近傍ユーザを使って推薦を行います。
from lib.recommend_util import ndcg
# neighbors_usersを使って推薦する
ndcgs = {
'ndcg5': [],
'ndcg10': [],
'ndcg20': [],
'ndcg50': [],
'ndcg100': []
}
unknown_count = 0
for userid, pos_items in tqdm(test_adventure_pos_items_dict.items()):
# pos_itemsをadventure_matrixの次元に変換する
pos_items = np.array([adventure_concat_itemid_dict[v] for v in pos_items])
if userid in neighbors_users:
neighs = neighbors_users[userid]
sum_ratings = np.zeros(adventure_predicted_ratings.shape[1])
for v in neighs:
v_adv = adventure_train_action_users[v]
sum_ratings += adventure_predicted_ratings[v_adv, :]
average_ratings = sum_ratings / len(neighs)
# average_ratingsを降順にargsort
sorted_indices = np.array([v for v in np.argsort(-average_ratings)])
ndcgs['ndcg5'].append(ndcg(sorted_indices[:5], pos_items))
ndcgs['ndcg10'].append(ndcg(sorted_indices[:10], pos_items))
ndcgs['ndcg20'].append(ndcg(sorted_indices[:20], pos_items))
ndcgs['ndcg50'].append(ndcg(sorted_indices[:50], pos_items))
ndcgs['ndcg100'].append(ndcg(sorted_indices[:100], pos_items))
else:
unknown_count += 1
# 推薦できないユーザの場合は無条件で0を入れる
ndcgs['ndcg5'].append(0)
ndcgs['ndcg10'].append(0)
ndcgs['ndcg20'].append(0)
ndcgs['ndcg50'].append(0)
ndcgs['ndcg100'].append(0)
4.3 Collective Matrix Factorization
ソースドメインの情報を補助情報的に扱い、ターゲットドメインへのレコメンドを行います。
詳しいことは割愛しますので、以下の情報をご覧ください。
- もともとの論文→ Relational learning via Collective Matrix Factorization
- 今回使ったReference Implementation→ https://github.com/david-cortes/cmfrec
- collective MFに言及しているqiita記事→ Collective Matrix Factorization - 自然言語データのエレガントなデータ探索法 -
予め、ソースドメインでALSを行い、ユーザベクトルを得られているものとします。今回はこれから得られるベクトルをside informationとして使います。
# side informationとしてaction_ALSで得られたベクトルを使う
user_attributes = pd.DataFrame(action_ALS.user_factors)
user_attributes['UserId'] = user_attributes.index
item_attributes = pd.DataFrame(action_ALS.item_factors)
item_attributes['ItemId'] = item_attributes.index
from cmfrec import CMF
# tensorflow<2.0
# モデルを学習
# adventure_ratings_stackedは、予めX_trainを縦持ちに変換したもの
recommender = CMF(k=20, k_main=3, k_user=2, k_item=1, reg_param=1e-4)
recommender.fit(ratings=adventure_ratings_stacked, user_info=user_attributes, item_info=item_attributes,
cols_bin_user=None, cols_bin_item=None)
推薦は recommender.topN(user=userid, n=10) のような形でできるのでこれを使ってndcgを出す、という感じです。
4.4 Transfer User Vector(CCA)
ソースドメインからターゲットドメインにユーザベクトルを変換することを考えます。

変換することができれば、ターゲットドメインのアイテムベクトルとかけわせることでいつものようにrating matrixを予測することができるようになるためです。
この項ではその変換を Canonical Correlation analysis(CCA) で行います。
CCAについてはこちらの記事などが詳しいです。 → 正準相関分析入門
# actionとadventureでoverlapしているユーザで、ベクトルの対応表を作る
overlap_action_user_vectors = []
overlap_adventure_user_vectors = []
count = 0
for u in tqdm(range(X_train.shape[0])):
if u in action_train_action_users and u in adventure_train_action_users:
overlap_action_user_vectors.append(action_ALS_user_vectors[action_train_action_users[u]].tolist())
overlap_adventure_user_vectors.append(adventure_ALS_user_vectors[adventure_train_action_users[u]].tolist())
# CCAの学習をする
from sklearn.cross_decomposition import CCA
np.random.seed(42)
cca = CCA(n_components=100)
cca.fit(overlap_action_user_vectors, overlap_adventure_user_vectors)
CCAでX->Yに対する写像を行いたいときは、CCAで取り出した共通成分に変換->そこからYの次元に戻す、といった感じで写像することが出来ます。
# CCAを使ってadventureの次元に変換する
adventure_user_vector_action_CCA = action_user_vector @ cca.x_weights_ @ cca.y_weights_.T
4.5 Transfer User Vector(Neural Net)
というわけで最後の手法です。が、上述したCCA部分がニューラルネットになるだけです。
モデルアーキテクチャは写像さえできれば何でも良いと思うのですが、今回は ベクトルを受け取ってベクトルを出すイメージとして一番最初に浮かんだAutoEncoderで学習を行います。
# モデルの定義
from keras.layers import Input, Dense
from keras.models import Model, load_model
from keras.callbacks import EarlyStopping, ModelCheckpoint
import tensorflow as tf
from keras import backend as K
np.random.seed(0)
tf.set_random_seed(0)
sess = tf.Session(graph=tf.get_default_graph())
K.set_session(sess)
def build_model(input_dim, output_dim):
inputs = Input(shape=(input_dim,))
encoded = Dense(128, activation='relu')(inputs)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(encoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(output_dim, activation='sigmoid')(decoded)
autoencoder = Model(inputs, decoded)
autoencoder.compile(optimizer='adam', loss='mean_squared_error', metrics=['mae','mse'])
return autoencoder
seed固定だけだとどうしても結果が変動してしまうので、今回のみ10-foldそれぞれのモデルを取り出し、各モデルによるndcgの結果を平均して結果とします。
from sklearn.model_selection import KFold, train_test_split
from sklearn.metrics import mean_squared_error
X = np.array(overlap_action_user_vectors)
y = np.array(overlap_adventure_user_vectors)
epoch_size = 100
batch_size = 256
es_cb = EarlyStopping(
monitor='val_loss',
patience=10,
verbose=0,
mode='auto')
models = []
rmses_ = []
kf = KFold(n_splits=10, shuffle=True, random_state=42)
count = 0
for train_index, test_index in kf.split(X):
print(f"learning_count: {count}")
count += 1
X_train_vector, X_test_vector = X[train_index], X[test_index]
y_train_vector, y_test_vector = y[train_index], y[test_index]
X_train_vector, X_val_vector, y_train_vector, y_val_vector = train_test_split(X_train_vector, y_train_vector, random_state=42)
model = build_model(X_train_vector.shape[1], y_train_vector.shape[1])
mcheck = ModelCheckpoint(
f'output/ml-20m-model_k_{count}.h5',
monitor='val_loss',
save_best_only=True,
verbose=0
)
model.fit(
X_train_vector,
y_train_vector,
batch_size=batch_size,
epochs=epoch_size,
validation_data=(
X_val_vector,
y_val_vector),
callbacks=[
mcheck,
es_cb],
shuffle=True,
verbose=0)
best_model = load_model(f'output/ml-20m-model_k_{count}.h5')
y_pred = best_model.predict(X_test_vector)
rmse_ = np.sqrt(mean_squared_error(y_pred, y_test_vector))
print('rmse: {}'.format(rmse_))
rmses_.append(rmse_)
models.append(best_model)
ndcg_values = []
for learning_count in range(1,11):
ndcgs = {
'ndcg5': [],
'ndcg10': [],
'ndcg20': [],
'ndcg50': [],
'ndcg100': []
}
best_model = load_model(f'output/ml-20m-model_k_{learning_count}.h5')
for userid, pos_items in tqdm(test_adventure_pos_items_dict.items()):
# pos_itemsをadventure_matrixの次元に変換する
pos_items = np.array([adventure_concat_itemid_dict[v] for v in pos_items])
# useridに対応するユーザベクトル(action)を得る
try:
action_userid = action_train_action_users[userid]
except:
# 推薦できないユーザの場合は無条件で0を入れる
ndcgs['ndcg5'].append(0)
ndcgs['ndcg10'].append(0)
ndcgs['ndcg20'].append(0)
ndcgs['ndcg50'].append(0)
ndcgs['ndcg100'].append(0)
continue
action_user_vector = action_ALS_user_vectors[action_userid, :]
# autoencoderを使ってadventureの次元に変換する
adventure_user_vector_action_AE = best_model.predict(action_user_vector.reshape(1, -1))
# adventureのitemのベクトルと掛け合わせる
adv_predict = np.dot(adventure_user_vector_action_AE, adventure_item_vectors.T)
# sum_ratingsをargsort
sorted_indices = np.array([v for v in np.argsort(-adv_predict)])[0]
ndcgs['ndcg5'].append(ndcg(sorted_indices[:5], pos_items))
ndcgs['ndcg10'].append(ndcg(sorted_indices[:10], pos_items))
ndcgs['ndcg20'].append(ndcg(sorted_indices[:20], pos_items))
ndcgs['ndcg50'].append(ndcg(sorted_indices[:50], pos_items))
ndcgs['ndcg100'].append(ndcg(sorted_indices[:100], pos_items))
ndcg_values.append(ndcgs)
ndcg5 = []
ndcg10 = []
ndcg20 = []
ndcg50 = []
ndcg100 = []
for ndcgs in ndcg_values:
ndcg5.append(np.mean(ndcgs['ndcg5']))
ndcg10.append(np.mean(ndcgs['ndcg10']))
ndcg20.append(np.mean(ndcgs['ndcg20']))
ndcg50.append(np.mean(ndcgs['ndcg50']))
ndcg100.append(np.mean(ndcgs['ndcg100']))
print(f"ndcg@5: {np.mean(ndcg5)}")
print(f"ndcg@10 {np.mean(ndcg10)}")
print(f"ndcg@20: {np.mean(ndcg20)}")
print(f"ndcg@50: {np.mean(ndcg50)}")
print(f"ndcg@100: {np.mean(ndcg100)}")
5. 結果と考察
長々やってまいりましたが、これでそれぞれの手法に関する説明ができました〜。ここまでお付き合いいただきありがとうございます。
それでは最後に各手法の結果を見ていきましょう。ベースラインとして、ターゲットドメインにおけるPopular Itemsを置いています。
| movielens(20M,action->adventure) | ndcg@5 | ndcg@10 | ndcg@20 | ndcg@50 | ndcg@100 |
|---|---|---|---|---|---|
| PopularItems | 0.1265 | 0.1811 | 0.2499 | 0.361 | 0.4375 |
| aggregate | 0.1131 | 0.1516 | 0.1971 | 0.2652 | 0.3172 |
| mediate | 0.102 | 0.1246 | 0.1515 | 0.2015 | 0.2528 |
| collective | 0.03 | 0.059 | 0.083 | 0.1235 | 0.1795 |
| CCA | 0.1166 | 0.1513 | 0.1905 | 0.254 | 0.3097 |
| AutoEncoder | 0.1397 | 0.1865 | 0.2329 | 0.2986 | 0.3404 |
| Amazon(book->movies) | ndcg@5 | ndcg@10 | ndcg@20 | ndcg@50 | ndcg@100 |
|---|---|---|---|---|---|
| PopularItems | 0.0095 | 0.0137 | 0.0193 | 0.0275 | 0.0362 |
| aggregate | 0.0087 | 0.0119 | 0.0157 | 0.0223 | 0.028 |
| mediate | 0.0036 | 0.0055 | 0.0081 | 0.0129 | 0.0183 |
| collective | 0.0043 | 0.0071 | 0.0086 | 0.013 | 0.0171 |
| CCA | 0.0052 | 0.0073 | 0.0099 | 0.0148 | 0.0198 |
| AutoEncoder | 0.0072 | 0.0102 | 0.0144 | 0.0212 | 0.0281 |
はい、ということでMovielensはndcg@20から、Amazonレビューデータセットに至ってはndcg@5からPopularItemsに圧倒されてしまいました...
なんでMovielensだと勝ててAmazonだと負けるのかですが、両方のドメインにアクションしているユーザ数の違いが一番大きな差ではないかと思われます。
| Movielens | ratings数 | アイテム数 | ユーザ数 |
|---|---|---|---|
| Action | 5614208 | 3465 | 137967 |
| Adventure | 4380351 | 2286 | 137887 |
| 全体 | 7537026 | 4794 | 138389 |
-> 両ドメインにアクションしているユーザ数... 72029
| Amazon | ratings数 | アイテム数 | ユーザ数 |
|---|---|---|---|
| Book | 8898041 | 367982 | 603668 |
| Movies | 1697533 | 50052 | 123960 |
| 全体 | 10595574 | 418034 | 690240 |
-> 両ドメインにアクションしているユーザ数... 37388
前述したように、Amazonのほうはアイテムは一つのジャンルのみを持ちアイテムの重なりがありません。加えて、両ドメインにアクションしているユーザ数が全体の約5%しかなく、Movielensの約50%の重なり具合と比較するとどうしても難しい問題になっていることが推察できます。
これだけしか重なりがないと、両ドメインにアクションしているユーザから得られたデータでどれだけ推薦を行っても推薦する外のユーザの行動の仕方が、両ドメインにアクションしているユーザとかけ離れていることも考えられます。
ユーザの重なり具合が10%以下になってしまっている場合には、クロスドメインらしいアプローチをしなくともPopularItemsやAggregateなどシンプルなアプローチに留めておくのが安全なのかもしれません。
わざわざニューラルを持ち出してきてPopularItemsに大差で負けたのを確認したときは心臓がなくなるかと思うほど悲しくなりましたが、こうして考察するとまあこんなもんかなという感じですね...とはいえ悲しい![]()
まとめ
- クロスドメインレコメンドのアプローチとして6つを紹介しました(recsysのチュートリアルに沿って)
- 実際に5つのアプローチをMovielens、Amazonのデータセットで検証しました
- ユーザ・アイテムの重なり具合で問題の難易度が変わる(ベースラインにギタギタにされることも十分有り得る)
また別の供養の機会などあれば、そのときまでに別ドメインの組み合わせを試したり、エラー分析をしたり、もうちょっと最新の論文の手法を実装して試してみたりなどに取り組んでみたいなと思う次第です。
示したコードや文章などについて疑問点などありましたらいつでもマサカリをお投げくださいませ(お手柔らかにお願いします...)