データ解析を行う上でデータの性質を知ることは欠かせません.データの性質を知ること自体が価値を持つこともありますし,正しい前処理の方法やモデルを選択する為にもデータの性質を知らなければいけません.
カテゴリー型の変数なら分布や従属変数との関係などの簡単な統計量を調べるだけでも多くのことがわかります.

しかし自然言語データの場合は全く同じ文章が2度現れることはまずありません.文章を単語単位に分解して考えようとしても,単語の種類が膨大なため,データ探索は一筋縄ではいきません.

自然言語データの探索法は色々ありますが,今回の記事ではその中でも
- 教師ありデータと相性が良い
- 間違った解釈に至りづらい
- 数学的にエレガントな
探索法である**Collective Matrix Factorization (CMF)**について紹介します.
要約
- 自然言語データは高次元なので,次元を削減することが解釈の第一歩である
- 次元を削減する際にコンテキストを考慮することが大切になる.
- CMFは教師データを活用しながらトピックを抽出するので,教師データがある場合の自然言語データの探索法として有効である
理論
言語データを効果的に探索するために,以下の2つの方針をとります:
-
次元を減らす
大抵のコーパスでは単語の種類は膨大ですが,人間が一度に処理できるデータの総量に限界があります.このような高次元データを探索する為には次元を削減することが必須です.今回は何らかの方法で単語をグループ化して分析しよう,というのが次元削減の基本的な方針になります. -
単語のコンテキストが明らかにする
単語はコンテキストによって意味が変わってきます.例えば「驚き」という単語は
「この監督からこんなにひどい作品が出てきたことに驚きました」
「突然現れるゾンビに驚きました」
「最後の結末にはいい意味で驚きました」
と,コンテキストに応じてポジティブにもネガティブにもなり得ます.単純に「驚き」という単語が低評価のレビューでよく登場することがわかっても,どういうコンテキストで使われているかも合わせて見ないとデータに対する知見は得られません.
これを元に考えると,単語をよく一緒に登場するもの同士でまとめ,コンテキストに応じてグループ化するのがデータを探索する上での自然な方針であることがわかると思います.例えば新聞記事でコンテキストに応じてグループ化しようとすると,「スポーツ」に関する単語(「メダル」「投手」など)同士や「政治」に関する単語(「選挙」「与党」)同士がおそらくまとまります.つまり,コンテキストに応じて単語をグループ化すると文章の裏にある潜在的な「トピック」が自然と出てきます.そのため,コンテキストに応じて単語をグループ化する手法はtopic modelingの手法と呼ばれます.
Topic Modelingは広大な研究分野なのでその手法を全てここでカバーするのは不可能です.今回はCMFと比較するために,CMFと関係が深い代表的な手法であるNon-negative Matrix Factorization(NMF)を紹介します.
NMF (Non-negative Matrix Factorization)
自然言語処理の分野ではドキュメントと単語の関係をterm-document matrix(各行があるドキュメント内に出現した単語の出現回数の情報を持っている行列)で表すことが一般的です.それぞれのドキュメントは出現する単語の分布によって表現されます.

もしそれぞれのドキュメントが潜在的なトピックを持つならば,全てのドキュメントはトピックの分布によっても表現できるはずです(以下のトピック「データ分析」「Python」「自然言語処理」は仮想的に名づけたもので,実際にこういうトピックが出てくるとは限りません).

そして各トピックはまた単語の分布を持ちます.
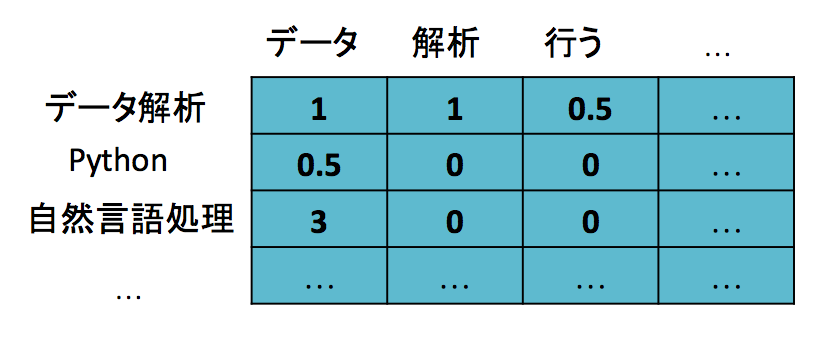
つまり,term-document matrixは各ドキュメントでのトピックの分布で重み付けされた各トピックの単語分布の和として表せるはずです.

これはterm-document matrixの行列分解によってトピックが得られるということに他なりません.
これ以降,term-document matrixを$X$と表記します.NMFは$X$を行列分解することでトピックを発見する手法です.具体的には

とします.ただし,ここで$W$と$H$は共に負の値を持たないという制約をつけます.これはあるドキュメントが「野球」のトピックを-2保持している,というのは意味がわからないからです.これがNMFのN(non-negative)の由来です.
この手法の欠点は必ずしも調べたい事柄と関係のあるトピックが出てくる保証がないということです.例えばPythonユーザーはどういうQiita記事を高く評価しているかを調べたいとします.Python関連の単語の中でもいくつかの異なるグループ(e.g. Django,FlaskといったWeb関連のものとPandas,Numpyみたいなデータ解析関連のもの)があり,それぞれのグループごとにユーザー層も異なるはずなので,トピックに分解したときにはなるべくこれらのトピックは分離してほしいです.しかし,例えばPython関連の記事が全体の中であまり多くなかった場合にはこれらのトピックは全てPython関連のものとしてまとめられてしまうかもしれません.
この問題に対処するために教師データ(例えばQiita記事の評価)を活用して,調べたい事柄に関するトピックが出てくるようにするのがCMFです.
CMF (Collective Matrix Factorization)
トピックと教師データの目的変数が関係を持つなら,トピックの分布から目的変数を予測できるはずです.文章と教師ラベルを格納する行列を$Y$とすると,このとき$Y$は文章のトピックの分布を表す行列と各トピックの目的変数への寄与を持つ重み行列の積で近似できるはずです.つまり,これもまた行列分解の問題として考えることができるということです.

term-document matrixと教師ラベルの行列を同時に分解することでより適切なトピックを抽出する手法がCMFです.これを式で表すと以下のようになります.
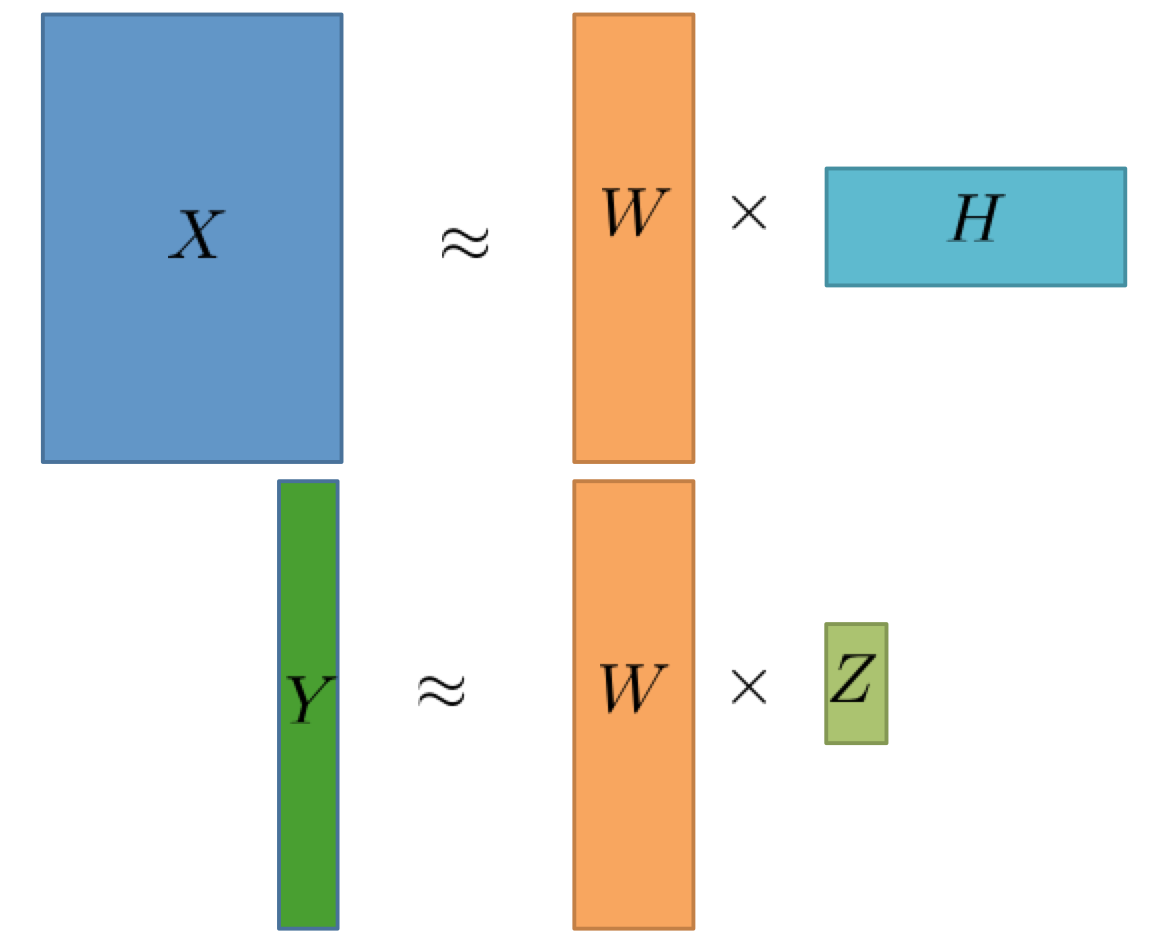
このようにCMFは非常にシンプルかつエレガントな教師データの活用法ですが,実際に適用してみるとかなり効果的であることがわかります.次の章では実際のデータに対してCMFを適用したときにどうなるかを例を通してみていきます.
実践
これらの手法が実際どのような効果を持つのか,例を通して見ていきましょう.
CMFを行う便利なPythonライブラリがなかったので実装しました.以下のコードはレポジトリ内のsampleからコピーしています(sampleはここで見れます).
この例ではKaggleのToxic Commments Classification Challengeのデータを使います.このコンペはWikipediaの編集履歴のテキストを元に悪質なコメントを検出するもので,悪質なコメントにも色々な種類(人種差別,脅迫など)があることが特徴でした.全コメントの中で悪質なものは少数派で,何も危害を与えないコメントが大半を占めています.このデータに対して上記のTopic Modelingの手法を適用した時にどうなるかを見ていきましょう.
まずはデータを読み込みます.
import pandas as pd
import numpy as np
train = pd.read_csv("train.csv")
次に,scikit-learnの便利なモジュールを使ってテキストをterm document matrixに変換します.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=3, max_df=0.9, stop_words="english", binary=True)
X_train = vectorizer.fit_transform(train.head(10000).comment_text)
CMFで使う教師データもnumpy.ndarrayとして取り出します.
label_columns = list(train.columns[2:])
Y_train = train.head(10000)[label_columns].values
まず,NMFを使って分解した時にどうなるかを見ていきましょう.
N_COMPONENTS = 20
from sklearn.decomposition import NMF
nmf = NMF(N_COMPONENTS)
W = nmf.fit_transform(X_train)
H = nmf.components_
分解後,トピックをプリントする関数を定義し,各トピックの上位語を見ていきましょう.
idx_to_word = np.array(vectorizer.get_feature_names())
def print_topics(H, topn=10):
for i, topic in enumerate(H):
print("Topic {}: {}".format(i + 1, ",".join([str(x) for x in idx_to_word[topic.argsort()[-topn:]]])))
print_topics(H)
結果:
Topic 1: used,right,case,said,point,make,fact,way,say,does
Topic 2: tildes,hello,questions,date,welcome,sign,using,editing,pages,help
Topic 3: placed,speedily,guidelines,tag,add,remove,speedy,note,deleted,deletion
Topic 4: message,added,comments,user,wp,comment,discussion,redirect,contribs,talk
Topic 5: pov,history,subject,discussion,good,main,created,needs,section,article
Topic 6: user,said,want,doesn,say,care,understand,need,really,don
Topic 7: considered,editors,users,http,stop,policy,en,wiki,org,wikipedia
Topic 8: bit,new,sounds,hey,feel,thing,really,things,looks,like
Topic 9: let,editor,right,mean,ll,really,going,wanted,say,just
Topic 10: say,wiki,dont,got,thing,didn,want,did,let,know
Topic 11: vandalize,make,stop,pages,continue,edits,editing,blocked,did,edit
Topic 12: post,read,message,delete,links,new,link,discussion,user,page
Topic 13: life,way,really,wiki,person,going,group,world,want,people
Topic 14: way,added,new,lot,ll,work,help,good,hi,thanks
Topic 15: right,way,section,sure,needs,idea,better,good,really,think
Topic 16: reverted,learn,welcome,encyclopedia,sandbox,thank,removed,look,use,want
Topic 17: new,really,utc,got,going,long,good,ll,ve,time
Topic 18: published,references,www,reference,com,http,reliable,information,source,sources
Topic 19: contributions,proposed,issues,policy,deletion,delete,consensus,edits,wp,articles
Topic 20: jpg,uploaded,link,copyright,fair,deleted,thank,used,image,use
荒らし関連のトピック(Topic 11),出典に関するトピック(Topic 18),おそらく画像の権利関連のトピック(Topic 20)などが出現していることがわかります.しかし,どれも悪質なコメントとはあまり関係なさそうです.
ここで,CMFを使って見ましょう.
import pycmf
# alpha(hyperparameter)の計算
xnorm = np.sqrt(X_train.multiply(X_train).sum())
ynorm = np.sqrt((Y_train * Y_train).sum())
alpha = (ynorm / (xnorm + ynorm)) ** 0.75
cmf = pycmf.CMF(N_COMPONENTS,
U_non_negative=True, V_non_negative=True, Z_non_negative=False,
x_link="linear", y_link="logit", alpha=alpha, l1_reg=2., l2_reg=5., max_iter=10,
solver="newton", verbose=True)
U, V, Z = cmf.fit_transform(X_train.T, Y_train)
pycmfはトピックと教師データの予測における重みをプリントしてくれる組み込みのコマンドがあります.これを使ってどういうトピックが抽出できているかを見て見ましょう.
cmf.print_topic_terms(vectorizer)
結果
Topic 1 [-0.047,-0.323,-0.057,-0.469,-0.015,-0.257]: hate,little,hell,life,hey,know,shit,ass,fucking,fuck
Topic 2 [0.139,-3.046,-2.502,-3.067,-2.442,-3.153]: say,wikipedia,like,articles,know,just,time,think,people,don
Topic 3 [-1.022,-0.368,0.075,-0.461,-0.314,-0.382]: non,ask,material,read,reason,article,page,want,wikipedia,deleted
Topic 4 [-5.596,-5.963,-4.806,-6.224,-5.267,-6.076]: don,confirm,accepted,companies,indicate,year,bands,company,tagging,club
Topic 5 [-6.810,-4.408,-6.029,-3.981,-5.526,-4.095]: way,page,wikipedia,right,talk,user,use,section,know,article
Topic 6 [-0.698,-0.271,-0.237,-0.501,-0.341,-0.307]: editors,way,talk,does,article,make,wikipedia,page,questions,like
Topic 7 [-4.465,-3.540,-4.501,-3.125,-4.039,-3.068]: edit,really,page,article,just,think,like,people,know,don
Topic 8 [0.516,0.147,0.988,-0.568,0.920,0.194]: gets,avoid,stupid,right,man,suck,nazi,bitch,faggot,fuck
Topic 9 [2.863,-1.721,1.025,-1.698,0.904,-1.538]: contributing,create,takes,learn,tests,policy,creating,test,message,sandbox
Topic 10 [-0.938,-3.301,-1.568,-4.202,-1.609,-3.610]: deleting,discussion,utc,vandalism,request,blocked,stop,edit,page,talk
Topic 11 [-2.268,-1.443,-1.591,-1.337,-2.139,-1.483]: air,ago,saying,details,small,maybe,came,updated,talking,referred
Topic 12 [3.440,-0.909,1.348,-1.103,2.061,-0.957]: suck,hell,dumb,idiot,stop,shit,ass,stupid,fucking,fuck
Topic 13 [-0.554,-0.394,-0.740,-0.573,-0.644,-0.358]: case,information,page,article,sources,fact,discussion,used,good,think
Topic 14 [0.976,-1.307,-0.466,-1.178,-0.199,-1.252]: editing,welcome,thank,user,time,articles,wikipedia,edit,page,talk
Topic 15 [-4.870,-4.667,-4.735,-4.566,-5.183,-4.632]: people,thank,new,don,just,like,talk,wikipedia,page,article
Topic 16 [-1.534,-1.382,-1.717,-1.267,-1.625,-1.309]: says,free,said,edits,thanks,personal,like,talk,good,article
Topic 17 [3.838,-2.068,0.608,-2.626,0.471,-2.373]: ve,need,blocked,did,make,ll,say,way,think,just
Topic 18 [4.438,0.950,4.930,-0.546,4.690,0.330]: wikipedia,did,right,just,know,people,don,like,fucking,fuck
Topic 19 [-1.471,-1.267,-0.907,-1.223,-1.018,-0.914]: image,ll,add,reliable,list,actually,consider,let,source,article
Topic 20 [1.374,-0.722,2.014,-0.386,1.279,0.080]: wear,proof,public,new,tried,unblock,general,types,unconstructive,fuck
今度はf**kなど,暴言に含まれているような単語が多数出現していることがわかります.また,suckという単語も周囲の単語によって6番目のラベルに対して寄与したりしなかったりと,コンテキスト情報も抽出できていることがわかります.
もちろん,トピックに正しい間違いはありませんが,NMFで抽出するのが難しかった悪質なコメントと関係のあるトピックがCMFでは抽出できていることがわかります.
まとめ
今回の記事では自然言語データの探索の有効な手法の一つであるCMFを紹介し,その過程でNMFやTopic Modelingについても説明しました.もちろん自然言語のデータ探索法は他にもたくさんありますが,この行列分解ベースのシンプルな手法もレパートリーに入れておくだけで次に自然言語データの分析に取り組むときに引き出せる知見の幅が広がると思います.ぜひ皆さんもCMFを活用してみてください.