はじめに
ディープラーニング技術が身近になり、ググってみると色々なものを画像認識させるサンプルがたくさん見つかるようになりました。
結果が分かりやすくて見ていて楽しいので、n番煎じながら自分も何か認識させてみたくなったのですが、動物とか好きな女優さんとかを認識させるのはみんなやってるので、別のネタでやりたい。
ということで、**鉄道車両の画像を学習データとして、入力画像に写っている車両の形式をディープラーニング技術で当てさせてみました。**もっとも、レベル感は電車に興味を持ち始めた小さい子供と同程度だと思いますが。
↓このような車両の画像を入力して「E231系500番台」と当てさせることを目指します。

開発環境
- Ubuntu 18.04
- Python 3.6.9
- TensorFlow 2.1.0 (CPU)
問題設定
与えられた鉄道車両の外装写真に対して、5つの選択肢の中から1つを当てるようなニューラルネットワークのモデルを学習してみましょう!
今回はJR東日本の車両形式のうち、東京近郊で走っている5種類を対象とします。人間が見れば帯の色などでパッと判別できますが、どの部分が車両なのかを計算機に分からせるのは大変かもしれません。
車両画像の例
ここの画像は自前です。
(1) E231系500番台(山手線)
(2) E233系0番台(中央線快速・青梅線・五日市線)

(3) E233系1000番台(京浜東北・根岸線)

(4) E233系8000番台(南武線)

(5) E235系0番台(山手線の新型車)

データ集め
こちらの記事を参考にしました。
TensorFlowで画像認識「〇〇判別機」を作る - Qiita
Google画像検索で出てきた画像を自動ダウンロードさせます。
pip install google_images_download
googleimagesdownload -k 山手線
googleimagesdownload -k 中央線快速
googleimagesdownload -k E235
:
:
集めた画像の中で、車両の外装が写っている写真だけを使います。以下のような画像は使いません。
- 車両が写っていない画像(路線図や駅舎だけが写っているなど)
- 複数の車両・編成が写っている画像
- 内装の写真
- 鉄道模型
- CG画像
いろいろなキーワードで試して、最終的に1形式あたり100枚以上の画像を集めます。今回は5種類で合計540枚となりました。
全然数が足りなそうですが、これでも結構大変なんですよ…。キーワードを変えても同じ画像しかヒットしなかったりとか。
次に、集めた画像を、クラスごとにフォルダに分けて配置します。
- images/
- E231-yamanote/
- E231系500番台(山手線)の画像 115枚
- E233-chuo/
- E233系0番台(中央線快速など)の画像 124枚
- E233-keihintohoku/
- E233系1000番台(京浜東北・根岸線)の画像 75枚
- E233-nanbu/
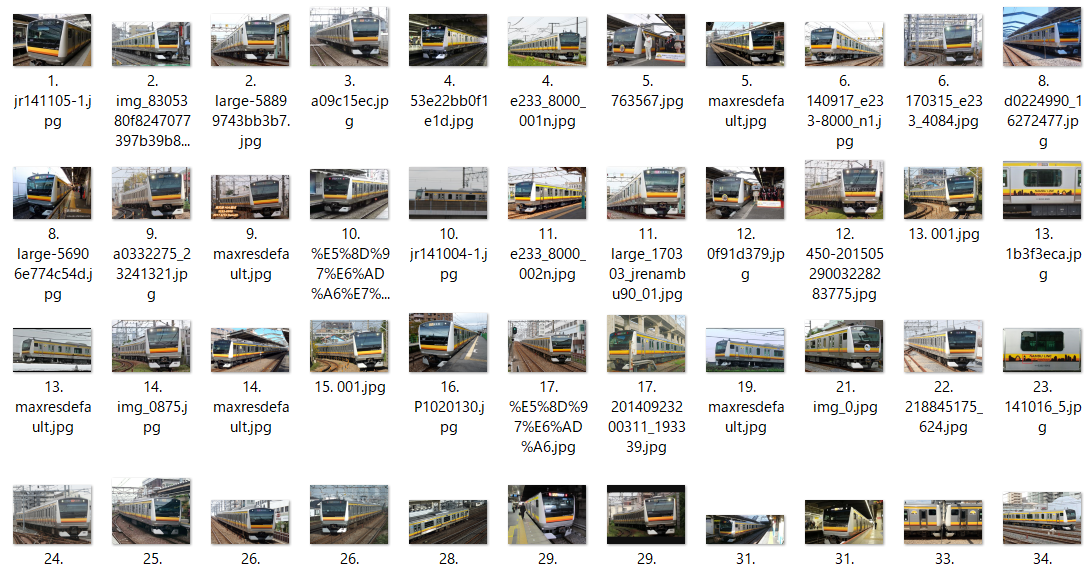
- E233系8000番台(南武線)の画像 101枚
- E235-yamanote/
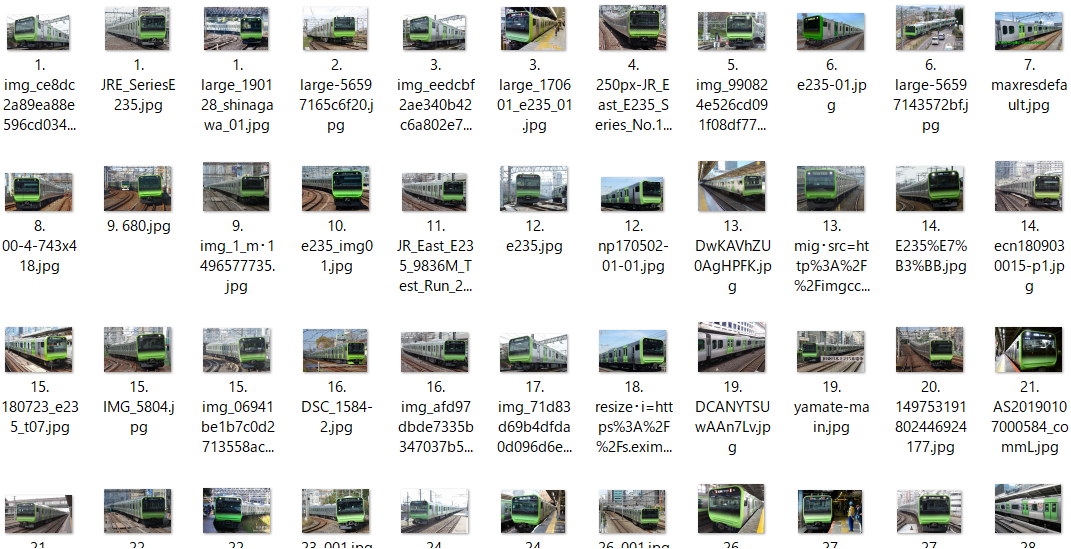
- E235系0番台(山手線の新型車)の画像 125枚
- E231-yamanote/
実際に集まった画像
(1) E231系500番台(山手線)
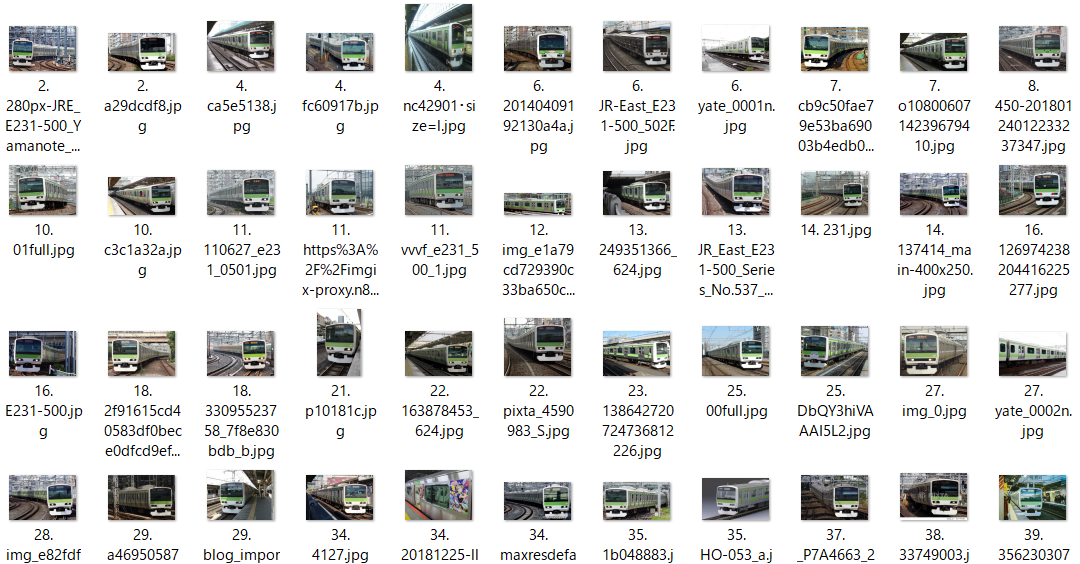
(2) E233系0番台(中央線快速・青梅線・五日市線)
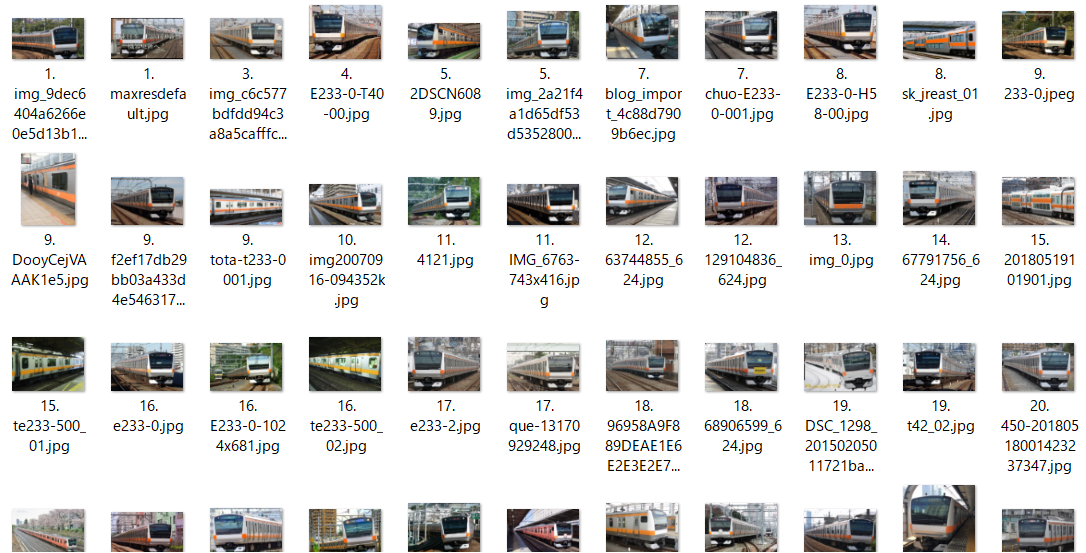
(3) E233系1000番台(京浜東北・根岸線)

(4) E233系8000番台(南武線)
(5) E235系0番台(山手線)
モデル学習のコード
さて、画像が準備できたらいよいよ学習です。
基本的には以下の記事の内容を参考にしました。
GPUを使ってVGG16をFine Tuningして、顔認識AIを作って見た - Qiita
今回の各形式は色が全然違う(山手線は2つありますが見た目がかなり違う)ので、女優さんの顔を識別するよりは簡単なタスクではないかと思いますが、それでもわずか500枚程度の画像では厳しいでしょう。
このデータの少なさに対処するため、VGG16の学習済みモデルを利用してファインチューニングを行います。VGG16のモデルはTensorFlow (Keras) から別途パッケージのインストールなしに利用できます。
Keras:VGG16、VGG19とかってなんだっけ?? - Qiita
VGG16は鉄道車両とは関係ない1000クラスの画像分類を行うモデルですが、学習されている重みが画像の識別に有効な特徴量を表現していると考え、出力に近い層だけを今回のタスクに合わせて取り替えて学習してしまいます。それによって最初のモデルの学習データとは全く関係ない識別問題が解けるようになるらしい。あら不思議。
入力を128×1281のカラー画像とし、VGG16のモデルを通した後に、全結合層256ユニット・Dropout・全結合層(出力層)5ユニットを付けます。
今回追加した全結合層と、VGG16の出力層に最も近いConv2D-Conv2D-Conv2Dの部分の重みだけを学習させ、残りのConv2D層は学習済みのパラメータから動かしません。
入力画像は、各所で紹介されているように ImageDataGenerator で拡大縮小や左右反転といったゆらぎを与えて学習に使います。元画像は500枚程度ですが、各エポックで毎回異なるゆらぎが与えられるので、それでデータを水増ししたことになるようです。
Python - Keras ImageDataGeneratorについて|teratail
import tensorflow as tf
from tensorflow.keras.layers import Dense, Input, Flatten, Dropout
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.models import Model
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# 学習設定
batch_size = 32
epochs = 30
# 特徴量の設定
# classesはサブフォルダの名前に合わせる
classes = ["E231-yamanote", "E233-chuo", "E233-keihintohoku", "E233-nanbu", "E235-yamanote"]
num_classes = len(classes)
img_width, img_height = 128, 128
feature_dim = (img_width, img_height, 3)
# ファイルパス
data_dir = "./images"
# === 画像の準備 ===
datagen = ImageDataGenerator(
rescale=1.0 / 255, # 各画素値は[0, 1]に変換して扱う
zoom_range=0.2,
horizontal_flip=True,
validation_split=0.1
)
train_generator = datagen.flow_from_directory(
data_dir,
subset="training",
target_size=(img_width, img_height),
color_mode="rgb",
classes=classes,
class_mode="categorical",
batch_size=batch_size,
shuffle=True)
validation_generator = datagen.flow_from_directory(
data_dir,
subset="validation",
target_size=(img_width, img_height),
color_mode="rgb",
classes=classes,
class_mode="categorical",
batch_size=batch_size)
# 画像数を取得し、1エポックのミニバッチ数を計算
num_train_samples = train_generator.n
num_validation_samples = validation_generator.n
steps_per_epoch_train = (num_train_samples-1) // batch_size + 1
steps_per_epoch_validation = (num_validation_samples-1) // batch_size + 1
# === モデル定義 ===
# 学習済みのVGG16モデルをベースに、出力層だけを変えて学習させる
# block4_poolまでのパラメータは学習させない
vgg16 = VGG16(include_top=False, weights="imagenet", input_shape=feature_dim)
for layer in vgg16.layers[:15]:
layer.trainable = False
# 今回のモデルを構築
layer_input = Input(shape=feature_dim)
layer_vgg16 = vgg16(layer_input)
layer_flat = Flatten()(layer_vgg16)
layer_fc = Dense(256, activation="relu")(layer_flat)
layer_dropout = Dropout(0.5)(layer_fc)
layer_output = Dense(num_classes, activation="softmax")(layer_dropout)
model = Model(layer_input, layer_output)
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer=SGD(lr=1e-3, momentum=0.9),
metrics=["accuracy"])
# === 学習 ===
cp_cb = ModelCheckpoint(
filepath="weights.{epoch:02d}-{loss:.4f}-{val_loss:.4f}.hdf5",
monitor="val_loss",
verbose=1,
mode="auto")
reduce_lr_cb = ReduceLROnPlateau(
monitor="val_loss",
factor=0.5,
patience=1,
verbose=1)
history = model.fit(
train_generator,
steps_per_epoch=steps_per_epoch_train,
epochs=epochs,
validation_data=validation_generator,
validation_steps=steps_per_epoch_validation,
callbacks=[cp_cb, reduce_lr_cb])
# === 正解率の推移出力 ===
plt.plot(range(1, len(history.history["accuracy"]) + 1),
history.history["accuracy"],
label="acc", ls="-", marker="o")
plt.plot(range(1, len(history.history["val_accuracy"]) + 1),
history.history["val_accuracy"],
label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.savefig("accuracy.png")
plt.show()
学習の推移
30エポック回して、学習データ・検証データでの正解率の推移はこんな感じになりました。
GPUなしのノートPCでCPUをぶん回して(4コアフル稼働で)学習させましたが、1エポックが1分程度でしたので、全部で30分程度で終わっています。
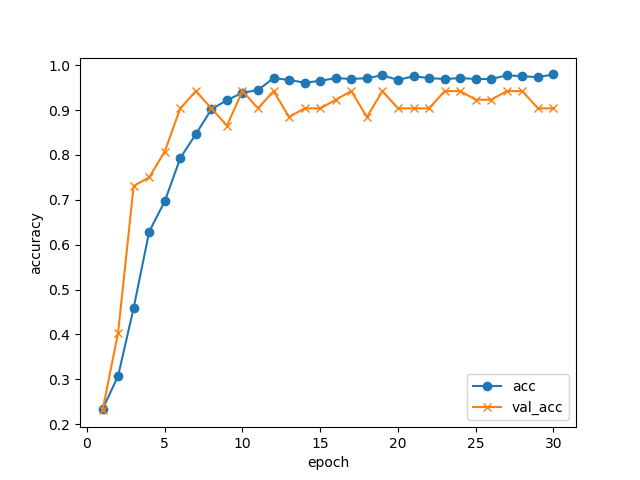
10エポックあたりで検証データの正解率は止まっていますが、5択問題で正解率94%まで来ています。データが少ない割にはよく頑張りましたね!
ModelCheckpoint の機能により、各エポック終了ごとにモデルを自動的に保存しています。今回、検証データの損失が最も小さかったのは17エポック目のモデル weights.17-0.1049-0.1158.hdf5 だったので、これを識別に使います。
import numpy as np
print(np.argmin(history.history["val_loss"]) + 1)
# 17(毎回変わる可能性があります)
注意点
Optimizerを SGD としていますが、これを Adam などにするとうまく収束してくれません。
これは、おそらくファインチューニングだからだと思われます。詳しくは以下の記事で。
[TensorFlow] OptimizerにもWeightがあるなんて - Qiita
車両を識別させる
冒頭に挙げた各画像を、実際に識別させてみましょう。
import sys
def usage():
print("Usage: {0} <input_filename>".format(sys.argv[0]), file=sys.stderr)
exit(1)
# === 入力画像のファイル名を引数から取得 ===
if len(sys.argv) != 2:
usage()
input_filename = sys.argv[1]
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image
# 特徴量の設定
classes = ["E231-yamanote", "E233-chuo", "E233-keihintohoku", "E233-nanbu", "E235-yamanote"]
num_classes = len(classes)
img_width, img_height = 128, 128
feature_dim = (img_width, img_height, 3)
# === モデル読込み ===
model = tf.keras.models.load_model("weights.17-0.1049-0.1158.hdf5")
# === 入力画像の読み込み ===
img = image.load_img(input_filename, target_size=(img_height, img_width))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
# 学習時と同様に値域を[0, 1]に変換する
x = x / 255.0
# 車両形式を予測
pred = model.predict(x)[0]
# 結果を表示する
for cls, prob in zip(classes, pred):
print("{0:18}{1:8.4f}%".format(cls, prob * 100.0))
入出力例
先程の predict.py のコマンドライン引数に画像ファイル名を与えると、識別結果が出力されます。
python3 predict.py filename.jpg
ここで紹介する入力サンプルはすべて自前です。
なお、ここに掲載するために画像の一部を加工していますが、実際の学習・識別時にはオリジナルのまま入力しています。
(1) E231系500番台(山手線)
E231-yamanote 99.9974%
E233-chuo 0.0000%
E233-keihintohoku 0.0000%
E233-nanbu 0.0004%
E235-yamanote 0.0021%
文句なしの正解ですね。
(2) E233系0番台(中央線快速・青梅線・五日市線)
E231-yamanote 0.0023%
E233-chuo 97.3950%
E233-keihintohoku 0.0101%
E233-nanbu 2.5918%
E235-yamanote 0.0009%
これも全く問題なし。
(3) E233系1000番台(京浜東北・根岸線)
駅名標や人が写っていて、機械にとっては識別が難しそうな画像ですが…。
E231-yamanote 2.0006%
E233-chuo 0.9536%
E233-keihintohoku 34.9607%
E233-nanbu 6.5641%
E235-yamanote 55.5209%
山手線E235系の確率が高くなりました。条件悪いですし横からの画像ですし、やむを得ないか。
ちなみに、なぜこれだけ横からの画像かというと、たまたま自分で京浜東北線の電車を正面から撮った画像がなかったからです…(汗)
(4) E233系8000番台(南武線)
E231-yamanote 0.1619%
E233-chuo 7.9535%
E233-keihintohoku 0.0309%
E233-nanbu 91.7263%
E235-yamanote 0.1273%
正解の南武線に高い確率をつけましたが、中央線快速と少し迷った様子。もっとも、フォルムはほぼ同じで色違いなだけなのですが、それなら京浜東北線と迷ったっていいのでは。
(5) E235系0番台(山手線)
E231-yamanote 0.0204%
E233-chuo 0.0000%
E233-keihintohoku 0.0027%
E233-nanbu 0.0002%
E235-yamanote 99.9767%
これは問題ないですね。
その他

E231-yamanote 0.2417%
E233-chuo 0.0204%
E233-keihintohoku 2.1286%
E233-nanbu 0.0338%
E235-yamanote 97.5755%
本当は3番目が正解なのですが、山手線の新型車と思ってしまったようです。なぜ。。。

E231-yamanote 47.2513%
E233-chuo 0.0898%
E233-keihintohoku 0.4680%
E233-nanbu 6.5922%
E235-yamanote 45.5986%
2番目が正解なのですが、なぜか山手線を推してきます。単に横からの画像にはE235を推してくる説も?
南武線の確率が少し出ているのは、右端の標識の黄色に反応したのでしょうか(実際どうかはわかりません)。
まとめ
Google画像検索で集めた500枚程度の鉄道車両の画像を使って、5種類の車両形式を識別するモデルを学習してみました。
学習済みのモデル (VGG16) の一部を流用して学習することによって、GPUなしのPCでも30分程度でそこそこ識別できるモデルができたようです。間違えるパターンもありますが、計算リソースとデータ量の割には善戦した方ではないかと思います。意外と手軽に作れて面白かったです。
本気でやるならもっといろいろな方向からの画像データを集めないとダメですし、車両の部分を切り出すとかも必要だと思います。
顔の判別だったらOpenCVなどで顔の切り出しがすぐにできますが、車両の場合は物体検出のアノテーションからでしょうね…。
-
元記事の通り150×150でもよかったのですが、VGG16を通すと画像サイズが縦横それぞれ1/32になるので、32の倍数にしておこうかとなんとなく思った次第です。オリジナルのVGG16学習に使われた224×224だとメモリが足りなくなってしまいました(Windows 10でTensorFlowをうまく動かせず、仮想マシン上のLinuxで動かしているためでしょう)。 ↩