新たなSSDモデルを作成して検出精度(val_lossとval_acc)と性能(fps)について知見を得たいと思います。
今回は、そもそもVGG16とかVGG19ってどんな性能なのか調査・検証しました。
VGGの名前の由来が気になって、ちょっとググってみました。
※今回これが一番価値ある知識かも
・SONY Neural Network Console でミニ VGGnet を作るによれば、
「名前の由来は、VGGチームが作った、畳み込み13層+全結合層3層=16層のニューラルネットワークということで、VGG-16となっているそうです。」
だそうです(笑)
そして、オリジナルは以下のようです。
・Visual Geometry Group
Department of Engineering Science, University of Oxford
因みに、VGG16は、Caffe-zooだと、まだcaffemodel: VGG_ILSVRC_16_layersと記載されているので、こちらがある意味正式名称でしょう。
そこで今回は、このモデル群をつかって、Cifar10の物体認識を実施して、その性能から新たな知見
・そもそも層の深さと物体認識精度
・そもそも性能の限界は??
というような知見を得るために手を動かそうと思います。
VGGシリーズのモデルって?
以下のような、アーキテクチャを持っています。
説明はいらないと思いますが、一番右がVGG19, 右から二番目がVGG16です。
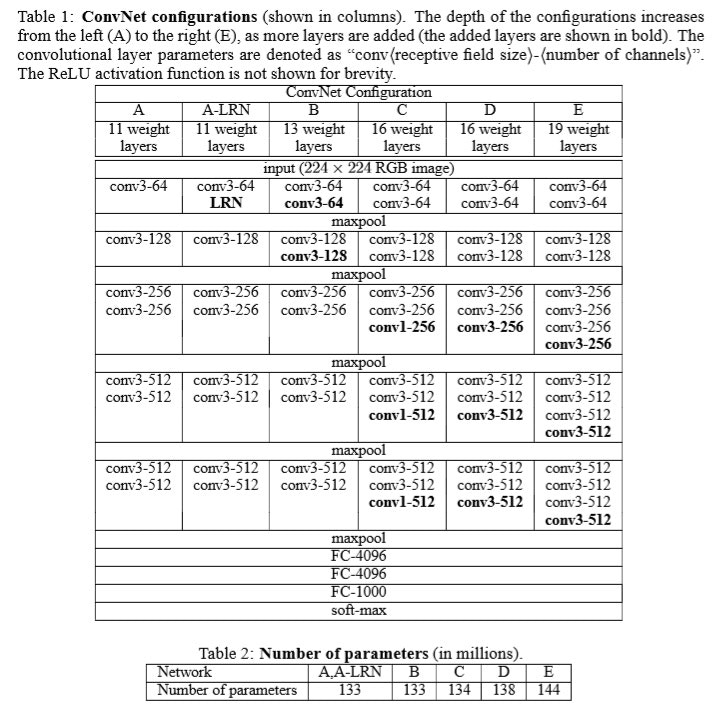
性能は、以下のとおりです。
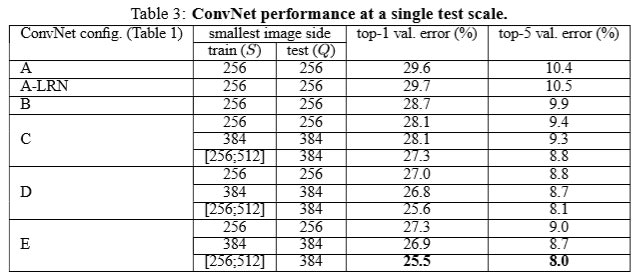
【参考】
①ImageNet: VGGNet, ResNet, Inception, and Xception with Keras
By Adrian Rosebrock on March 20, 2017 in Deep Learning, Machine Learning, Tutorials
②原論文Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan, Andrew Zisserman
(Submitted on 4 Sep 2014 (v1), last revised 10 Apr 2015 (this version, v6))
モデルは、出力してみると以下のとおり、これは上記表のDのVGG16です。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
例えば、単純な使い方コードは以下のとおり
from keras.preprocessing import image
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
import numpy as np
model = VGG16(weights='imagenet', include_top=True)
img_path = '1004.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
model.summary()
preds = model.predict(preprocess_input(x))
print(preds) #学習済1000個のマトリクスで確率出力
results = decode_predictions(preds, top=5)[0] #上位5個出力
for result in results:
print(result)
以下の猫の画像を入力とすると、出力例は以下のとおりです。
('n02119789', 'kit_fox', 0.38026658)
('n02119022', 'red_fox', 0.2352507)
('n02124075', 'Egyptian_cat', 0.1030893)
('n02123159', 'tiger_cat', 0.09078445)
('n02123045', 'tabby', 0.057852905)

【参考】
Keras_Documentation
因みに、上記のモデル使用例って、すべての使用例を読むとFineTuningなど全ての使い方がわかります。また、Keras-teamのVGG16のコード例は以下のとおり
keras / keras / applications / vgg16.py
なお、kit_foxってという人は以下のカテゴリを見てください。これが学習データ依存ってことです?!
1000 synsets for Task 2 (same as in ILSVRC2012)
Cifar10の物体認識精度の比較
ここでは、上記モデルをcifar10の物体認識に応用して、このファミリーのそれぞれについて、精度を算出してモデルの性能を比較しました。
前にも実施しましたが、今回は素直にVGGファミリとしてネットワークを作り比較しました。若干、上記の表と異なったモデルも実施したので、モデル名をABCからI,II,...に変更しました。以下の表ではIIIがVGG16、IVがVGG19に対応します。
| 0 | I | II | III | IV | V | VI | |
|---|---|---|---|---|---|---|---|
| conv1-1 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 |
| conv1-2 | 〇 | 〇 | 〇 | 〇 | 〇 | ||
| conv1-3 | 〇 | 〇 | |||||
| conv2-1 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 |
| conv2-2 | 〇 | 〇 | 〇 | 〇 | 〇 | ||
| conv2-3 | 〇 | 〇 | |||||
| conv3-1 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 |
| conv3-2 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | |
| conv3-3 | 〇 | 〇 | 〇 | 〇 | |||
| conv3-4 | 〇 | 〇 | |||||
| conv4-1 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 |
| conv4-2 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | |
| conv4-3 | 〇 | 〇 | 〇 | 〇 | |||
| conv4-4 | 〇 | 〇 | |||||
| conv5-1 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 |
| conv5-2 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | |
| conv5-3 | 〇 | 〇 | 〇 | 〇 | |||
| conv5-4 | 〇 | 〇 |
結果
実は、上記モデルのままだと学習の収束性が悪いので、ここではBatchNormalizationとDropoutを挿入しています。
因みに、BatchNormalizationはVGGファミリーの発表時は発見前でモデルに含まれていませんでした。
【参考】初出論文
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Sergey Ioffe, Christian Szegedy
(Submitted on 11 Feb 2015 (v1), last revised 2 Mar 2015 (this version, v3))
結果は以下の通りで、やはり論文の通りIIIのVGG16とIVのVGG19が精度と学習時のtime/epochを見ると、一番よさそうです。しかし、IIの性能は精度があまり落ちずかつ学習速度が速いので、fpsを稼ぎたい物体検出ではより適切な可能性がありそうです。
| 0 | I | II | III | IV | V | VI | |
|---|---|---|---|---|---|---|---|
| val_acc | 0.6958 | 0.7544 | 0.8816 | 0.8949 | 0.8927 | 0.8656 | 0.8544 |
| time/epoch | 54s | 80s | 87s | 112s | 138s | 148s | 120s |
| params | 6,058 | 11,368 | 11,553 | 16,862 | 22,172 | 22,357 | 17,047 |
まとめ
・今回はVGGファミリーの生い立ちを振り返った
・層の違いによる性能の比較を実施し、論文同様VGG16とVGG19が一番最適な層だという結論を得た
・物体検出では、総合的にはIIの全block2層のモデルがよさそうです。
・この結果を受けて、次回はII及びVGG19による物体検出の精度評価を実施し、VGG16と比較したい
コード(参考)
コードは以下の通りです。
SSD / VGG_family / cifar10_VGG_family.py
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv1_1 (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv1_2 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
batch_normalization_1 (Batch (None, 32, 32, 64) 256
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
conv2_1 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2_2 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
batch_normalization_2 (Batch (None, 16, 16, 128) 512
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 8, 8, 128) 0
_________________________________________________________________
conv3_1 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv3_2 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
conv3_3 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
batch_normalization_3 (Batch (None, 8, 8, 256) 1024
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 4, 4, 256) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 4, 4, 256) 0
_________________________________________________________________
conv4_1 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
conv4_2 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
conv4_3 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
batch_normalization_4 (Batch (None, 4, 4, 512) 2048
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 2, 2, 512) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 2, 2, 512) 0
_________________________________________________________________
conv5_1 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv5_2 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
conv5_3 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
batch_normalization_5 (Batch (None, 2, 2, 512) 2048
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 1, 1, 512) 0
_________________________________________________________________
dropout_5 (Dropout) (None, 1, 1, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 2101248
_________________________________________________________________
activation_1 (Activation) (None, 4096) 0
_________________________________________________________________
dropout_6 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 40970
_________________________________________________________________
activation_2 (Activation) (None, 10) 0
=================================================================
Total params: 16,862,794
Trainable params: 16,859,850
Non-trainable params: 2,944
_________________________________________________________________