疑問
http://d.hatena.ne.jp/naoya/20080122/1200960926 の記事のnanosleep()で1[ms]のスリープのプログラムを手元のPCで走らせてみたとこと,
- もともとの記事: 約4[ms]間隔になる
- 手元: 約1.1[ms]間隔になる
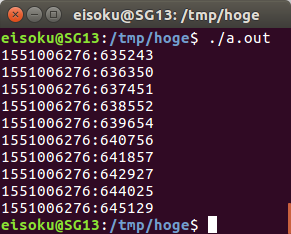
のように結果が異なった.
もともとの記事によると,タイマ割り込みの短い周期よりも短い精度は出せないとのことなので,タイマ割り込みの周期がもともとの記事と手元で違うのかと思って,https://srad.jp/~Livingdead/journal/508234 を参考にして,cat /boot/config-`uname -r` | grep '^CONFIG_HZ='をしてみたところ,以下のように手元のPCのタイマ割り込みの周期はもともとの記事と同じく4[ms]であった.

なんで4[ms]でなくて1.1[ms]になったのかが分からなかった+これが1[ms]ではなく1.1[ms]であるのであれば,学生のときに使っていたロボットの制御器( https://github.com/fkanehiro/hrpsys-base )の周期はどうやってRTCを(2.2[ms]とかではなくて)2[ms]周期で動かせられていたのだろうかというのが気になった.ので,いろいろ調べたことを備忘録としてまとめる.
http://d.hatena.ne.jp/kibayos/20090914/1252912209 には最近は事情が変わっとも書いてあるが,どう変わったかは書いていなく,そこを知りたい.
そういえば当時もよく分かっていなかったし,本当に(2.1[ms]とかではなくて)2[ms]で回っていたのかどうかは確認した記憶はない.
ちなみに,当時(2015年ごろ)は実機でhrpsys-baseを使うときはubuntu 12.04のlowlatency kernelを使っていた.自分の理解が正しければgenericと違ってlowlatencyはタイマ割り込みが4[ms]から1[ms]になっているkernelであって,タイマ割り込みが多めという差分があると捉えている.
使っているCPUは
model name : Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz
STEP1. とりあえず自分でもコードを書いてみていろいろ試してみた
# include <fstream>
# include <thread>
# include <iostream>
# include <vector>
int main() {
constexpr size_t loop_num = 10000;
constexpr std::array<long, 7> nano_sec_array{0, 10, 100, 1000, 1000 * 10, 1000 * 100, 1000 * 1000};
std::ofstream outputfile("/tmp/log.csv", std::ios::out);
for (const long& nano_sec : nano_sec_array) {
std::array<std::chrono::system_clock::time_point, loop_num> time_array;
for (size_t i = 0; i < loop_num; ++i) {
std::this_thread::sleep_for(std::chrono::nanoseconds(nano_sec));
time_array[i] = std::chrono::system_clock::now();
}
for (size_t i = 1; i < loop_num; ++i) {
const std::chrono::nanoseconds actual_duration = time_array[i] - time_array[i - 1];
if (i != 1) outputfile << " ";
outputfile << actual_duration.count();
}
outputfile << std::endl;
}
}
これは,std::this_thread::sleep_forで0[ns],10[ns], 100[ns], 1000[ns] == 1[us], 1000 * 10[ns] == 10[us], 1000 * 100 == 100[us], 1000 * 1000 == 1000[us] == 1[ms]だけsleepさせたときにかかった時間をstd::chrono::system_clock::nowで計測したものを/tmp/log.csvに出力するプログラムになる.
これをg++ -std=c++11 test_1.cpp -o test_1 && ./test_1して
import csv
import matplotlib.pyplot as plt
result = []
with open('/tmp/log.csv', 'r') as f:
reader = csv.reader(f, delimiter=' ')
for row in reader:
result.append([int(r) for r in row])
num = len(result)
f, (axes) = plt.subplots(num, 1, sharex=True)
target_list = [0, 10, 100, 1000, 1000 * 10, 1000 * 100, 1000 * 1000]
for i, ax in enumerate(axes):
ax.plot(range(len(result[i])), [x for x in sorted(result[i])], 'o', c='r')
ax.plot(range(len(result[i])), [x for x in result[i]], '+', c='g')
ax.hlines([target_list[i]], 0, len(result[i]))
ax.set_title(str(target_list[i]) + " [ns]")
for ax in axes:
ax.grid()
ax.set_ylabel('[nano sec]')
plt.show()
で可視化すると,以下のようになった.
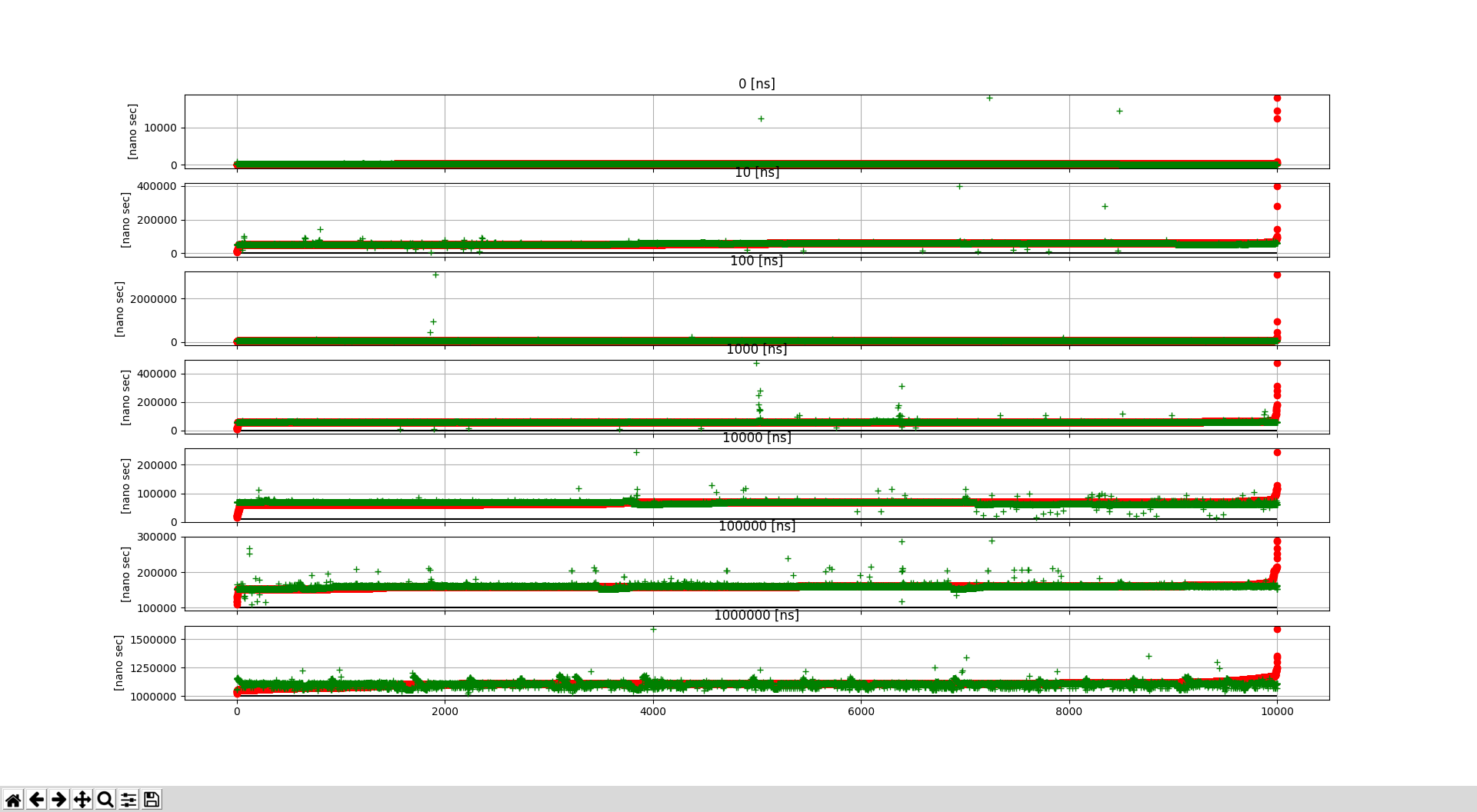
ばらつきがあるので,平均あたりを可視化すると以下のようになった.
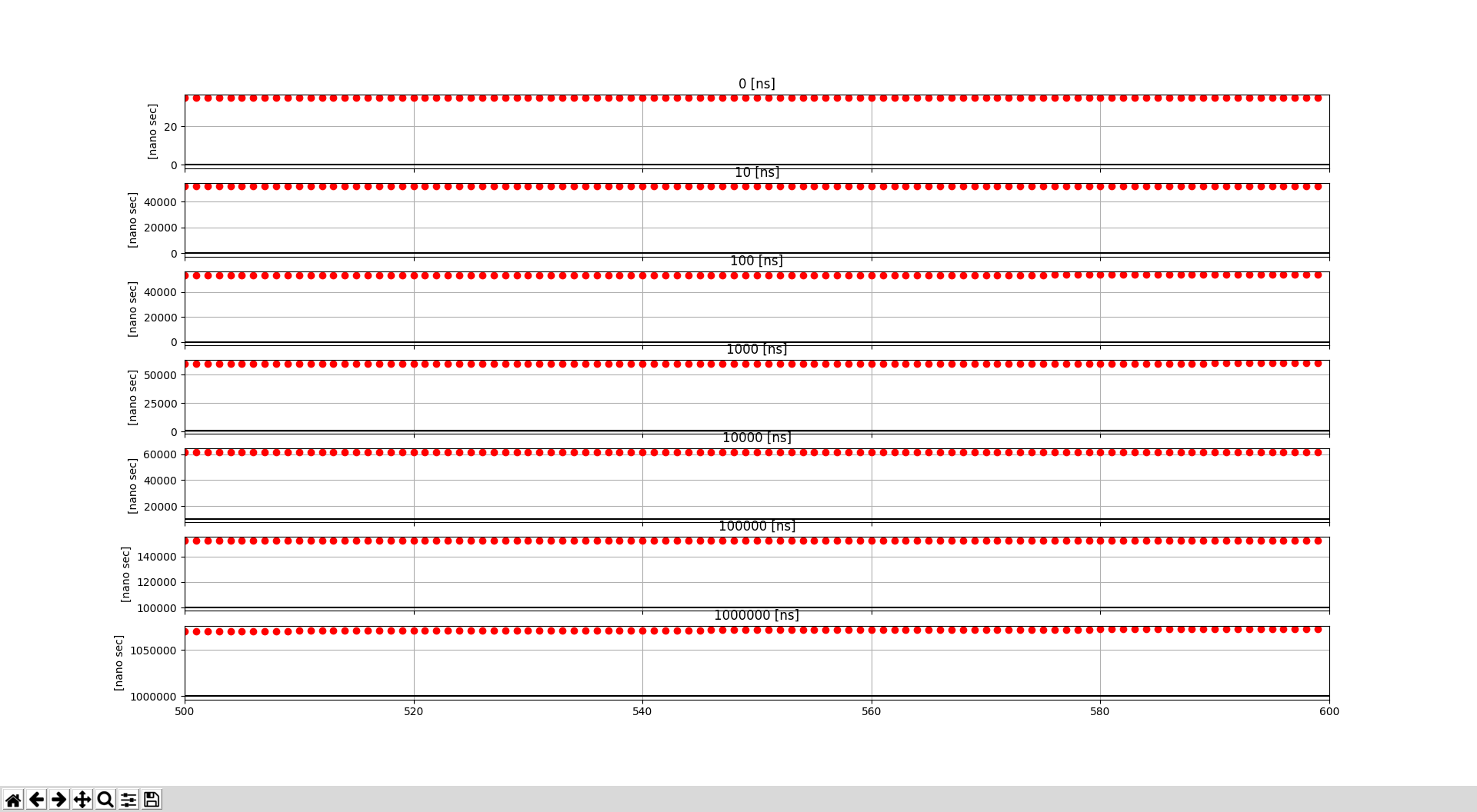
平均あたりのざっくりの結果としては
| target sleep time[ns] | actual sleep time[ns] |
|---|---|
| 0 | 36 |
| 10 | 52000 = 52 * 10^3 |
| 100 | 53000 = 53 * 10^3 |
| 1000 | 60000 = 60 * 10^3 |
| 10000 | 62000 = 62 * 10^3 |
| 100000 | 152000 = 152 * 10^3 |
| 1000000 | 1070000 = 1070 * 10^3 |
| 2000000 | 2100000 = 2100 * 10^3 |
| 10000000 | 10100000 = 10100 * 10^3 |
となった.
https://stackoverflow.com/questions/18071664/stdthis-threadsleep-for-and-nanoseconds や http://charette.no-ip.com:81/programming/2013-08-05_Sleeping/ にある結果ともだいたい一致している.唯一0[ns]のときだけ異なるが,実行時にstraceしてみると0nsのときはnanosleepのsystem callが呼ばれていないため,どこかで0のときの仕様が変わっただけだと思われる.
つまり,nanosleepのsystem callに50[us]くらいかかるということが分かった.
さて,もともとの疑問では,1[ms] = 10^6[ns]だけsleepさせたときに,実際には1.1[ms]だけsleepsしてしまうのはなんでだろうということだったが,上記の結果もそうなっている.
STEP2. tickとスケジューリングの関係性を理解する
の図が一番分かりやすかった.
上述したnanosleepのsystem callが時間がかかっているのは,上のリンクの図の緑色の上から下,下から上にかかる時間のことになる.
STEP3. gettimeofdayがマイクロ秒オーダー精度でる理由
- https://www.valinux.co.jp/technologylibrary/document/linuxkernel/timer0002/ の「2. Wall clock と monotonic clock」の図
- http://www.argv.org/~chome/blog/noisefactory/2008/02/gettimeofday.html
が分かりやすい.
msオーダーのタイマ割り込みのtickのカウントだけではなく,nsオーダーのHWタイマーが持つより細かい値も利用しているためである.
HWタイマに関しては https://cpplover.blogspot.com/2012/05/100.html が詳しく,これによると,Understanding the Linux Kernelを読むとより分かるらしい.
また, http://www.rcps.jp/doku.php?id=linux:linux-kernel も最近の事情が書いてあって分かりやすい.
STEP4. busy wait vs sleepの精度
の答えによると,sleepだとthreadをlockしないので,負荷によってはsleep状態からの復帰を延期されてしまいうるから精度が出づらい,と書いてある.
STEP4. jitterについて
の答えが大ヒントかもしれない.
# include <thread>
int main() {
constexpr size_t loop_num = 1000;
for (size_t i = 0; i < loop_num; ++i) {
std::this_thread::sleep_for(std::chrono::nanoseconds(1000 * 1000));
}
}
のように1[ms]のsleepを1000回するようにして,time ./test-jitter.outすると
real 0m1.111s
user 0m0.004s
sys 0m0.024s
となって,やはり1回の1[ms]のsleepあたりに0.1[ms]の誤差が載っているが,time sudo schedtool -R -p 99 -e ./test-jitter.outすると
real 0m1.063s
user 0m0.012s
sys 0m0.012s
のように誤差が0.06[ms]まで減った.
nice --20も含めて試して比較したものが以下.
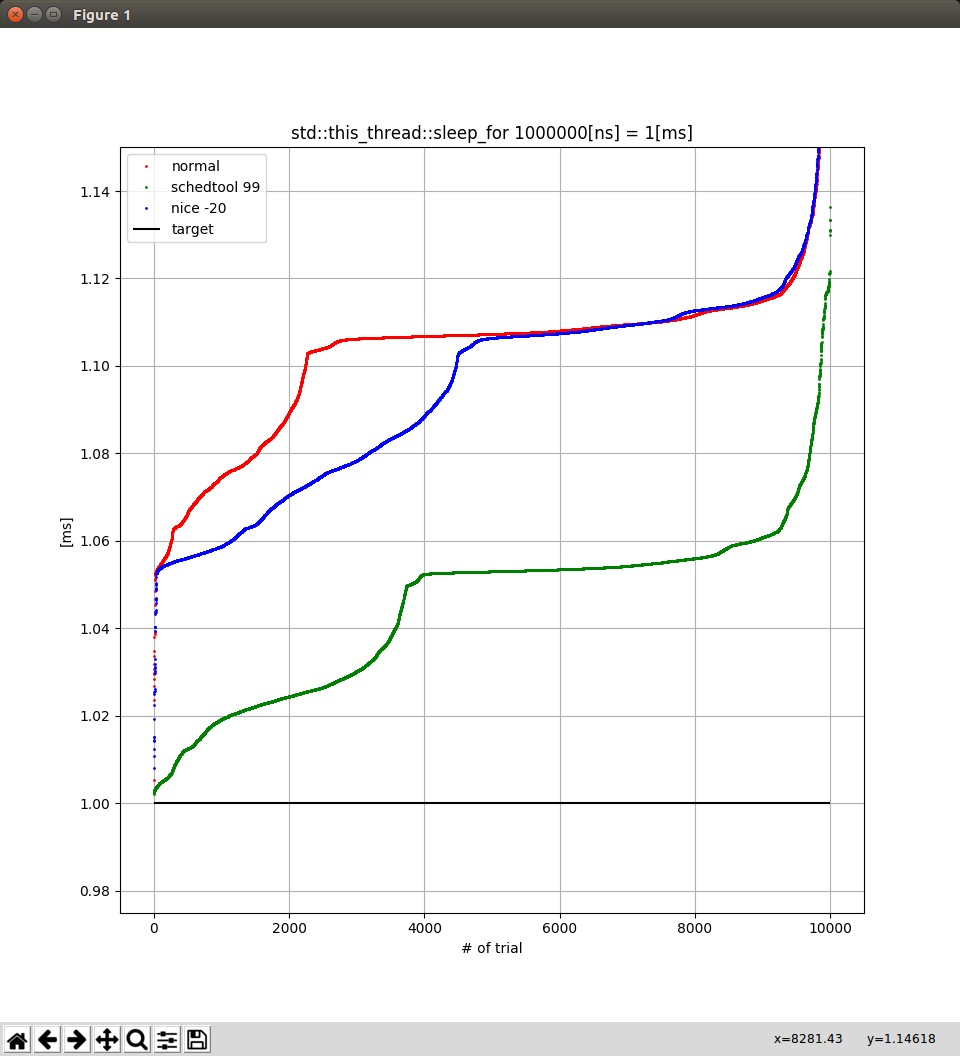
結論
-
元記事では4[ms]だったのに,自分の環境では1.1[ms]と早くなったのは @rauru さんにコメントで教えてもらった
-
0.1[ms] == 100[us]のずれがどこ由来なのかがまだ分かっていない
- nanosleepのsystem call自体は50[us]で,100[us]のsleepまではこの誤差が乗るが,1000[us] = 1[ms]以降は100[us]の誤差が載るようになっていて,その理由が分かっていない
-
どこ由来かは分からないが,誤差が乗るので,小さい一定周期を保つには,busy waitが良い
- sleepだとスレッドの権利を自主的に開放するのに対し,busy waitは自主的には開放しないので,betterということか?