はじめに
これは、 ドワンゴ Advent Calendar 2019の22日目の記事です。
2年前にTerraformとDataDogで始めるMonitoring as Code入門という記事を書きました。
あれから2年経ち、レガシーな監視システムをDatadogとPagerDutyをメインに利用しつつ、マイグレーションしていくプロジェクトを担当しています。
レガシーな監視システムは、とてもよくできていたのですが、10年以上選手のシステムだったこともあり、現代のシステム構成に対応しにくかったり、暗黙知がたくさんあったりし、置き換えることになりました。
ただ単純に置き換えるだけでは、既存の各社内サービスの監視に影響が出てしまうため、なるべく互換性を保つようにしつつ、レガシーなシステムでよくなかったところを改善しつつ、置き換えを行っています。
※2019年3月あたりからスタートし、2000ホスト以上レガシー監視システムで監視されてたホスト数も、2019年12月現在で残り1/4程度まで進んでいます。
構成図
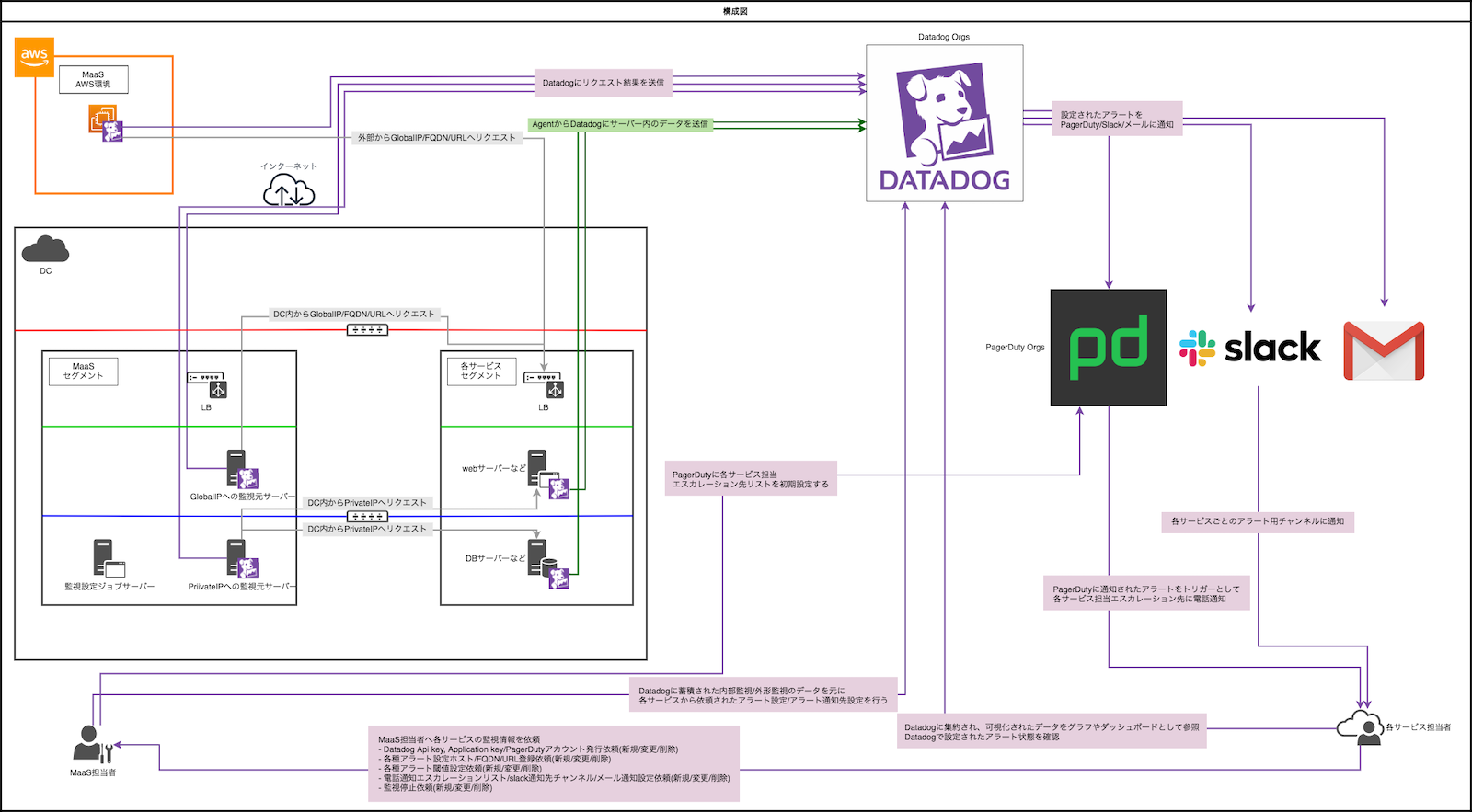
ざっくりした構成図としては上記の通りです。
内部監視
緑の矢印でDatadogに向かっている部分です。
Datadog Agentを各サービスの各ホストにインストールしてもらい、各ホストのOSやミドルウェアのメトリクスをDatadogに集約し、そのメトリクスのデータを元に内部監視のアラート設定を行っています。
ここでいう内部監視とは、OSの各リソース(CPU/memory/disk/etc...)に閾値を設けたり、プロセスダウンを検知したりと、ホストの中からデータを取得しないとわからないようなものを監視しています。
Datadog Agentのインストールはとても簡単に行えるのですが、デフォルトではネットワークやswapなど、OS関連のIntegrationが弱いため、社内向けAnsible Role/インストールスクリプト/ドキュメントを作成したりしています。
外形監視
灰色の矢印で各サービスに向かっている部分です。
各サービスのURLやIPアドレス/portをHTTP check/TCP checkを用いて監視し、メトリクスを取得、Datadogへ送っています。
DatadogにはSyntheticsという外形監視のサービスもありますが、今回の監視システムを構築し始めた際にはまだリリース前だったことと、ACLがかかっているような社内向けのAPIなどの監視が行えないため、自前でパブリッククラウド/プライベートクラウドそれぞれの環境にて構築しました。
エンドユーザーから参照できるようなページやAPIは、パブリッククラウド/プライベートクラウド両方から、社内向けのページやAPIはプライベートクラウドのみから監視しています。
また、レガシー監視システムにも存在していたこともあり、PrivateIPへの外形監視を行う環境も用意しています。
構成管理
本題の構成管理です。
表題の通り、AnsibleとTerraformを使い分けて利用しています。
Ansible
外形監視環境の構成管理として主に利用しています。
また、プライベートクラウドのVM作成/削除を行うためのAnsible Roleも社内で開発していることもあり、それを利用してプライベートクラウドのVM作成〜OS設定〜Datadog Agentを含めたミドルウェアの設定や、アラート設定向けの検証環境構築などを行っています。
パブリッククラウド/プライベートクラウドをなるべく透過的に扱えるようにしているのですが、今回は割愛します。
その他にも、内部監視のところで触れましたが、Datadog標準で足らないようなOS関連Integrationを最初から有効にしたり、標準のタグ設計済みなAnsible Role(社内向けAnsible Galaxy)も作成していたりします。
Terraform
下記で利用しています。
- パブリッククラウドでの外形監視環境構築(AWS Provider)
- 外形監視/内部監視アラート設定(Datadog Provider)
- 各サービス向けダッシュボードテンプレート+リスト(Datadog Provider)
また、役割が違うこともあり、それぞれ別リポジトリで管理しています。
本当はPagerDutyのエスカレーションリストやサービス設定もTerraformで行う想定でしたが、工数と初期設定後は各サービスに設定変更をお任せする運用としていることから、今回は見送りました(できること自体は検証していたので個人的には残念でした。。。)
アラート設定用Terraformについて
Datadogのアラート設定はAnsibleでもできるのですが、Ansibleの場合、アラートの閾値変更やアラートを絞り込みするためのタグの追加など変更にどうしても弱いため、Terraformを選択しています。
ステート管理としては、ディレクトリ分割方式を取っていたりします。
自分がワークスペースよりも慣れているのもありますが、各サービスのステートやアラート項目単位で作成しているmodules有無、各サービスごとにtfenvでTerraformのバージョン管理もしやすくなる、といった感じが選択ポイントでした。
ディレクトリ構成
リポジトリ全体としては下記のようにしています。
├── credentials # 秘匿情報管理リポジトリへのgit submodule(Datadog API key/Application keyなど)
├── modules # アラート項目単位で共通化したterraform moduleディレクトリ
│ ├── external_privateip # 外形監視(PrivateIP)用ディレクトリ
│ │ ├── http_check # 外形監視(PrivateIP)/http_checkを利用したHTTP監視用ディレクトリ
│ │ ├── ssl_cert # 外形監視(PrivateIP)/SSL証明書監視用ディレクトリ
│ │ └── tcp_check # 外形監視(PrivateIP)/tcp_checkを利用したTCP監視用ディレクトリ
│ ├── external_globalip # 外形監視(GlobalIP/プライベートクラウド)用ディレクトリ
│ │ ├── http_check # 外形監視(GlobalIP/プライベートクラウド)/http_checkを利用したHTTP監視用ディレクトリ
│ │ ├── ssl_cert # 外形監視(GlobalIP/プライベートクラウド)/SSL証明書監視用ディレクトリ
│ │ └── tcp_check # 外形監視(GlobalIP/プライベートクラウド)/tcp_checkを利用したTCP監視用ディレクトリ
│ ├── external_internet # 外形監視(GlobalIP/パブリッククラウド)用ディレクトリ
│ │ ├── http_check # 外形監視(GlobalIP/パブリッククラウド)/http_checkを利用したHTTP監視用ディレクトリ
│ │ ├── ssl_cert # 外形監視(GlobalIP/パブリッククラウド)/SSL証明書監視用ディレクトリ
│ │ └── tcp_check # 外形監視(GlobalIP/パブリッククラウド)/tcp_checkを利用したTCP監視用ディレクトリ
│ └── internal # 内部監視用ディレクトリ
│ ├── cpu # 以下、監視項目単位で階層化
│ ├── hostdown
│ ├── disk
│ ├── inode
│ ├── la
│ ├── live_process_down
│ ├── memory
│ ├── mysql_replication_delay
│ ├── mysql_replication_error
│ ├── ntp_offset
│ ├── reboot
│ ├── swap
│ └── uptime
├── orgs
│ ├── orgsA # Datadog org Aに設定されるアラート用ディレクトリ
│ │ ├── serviceA_prod_external # service Aの外形監視アラート用ディレクトリ
│ │ ├── serviceA_prod_internal # service Aの内部監視アラート用ディレクトリ
│ │ ├── serviceB_prod_external # service Bの外形監視アラート用ディレクトリ
│ │ └── serviceB_prod_internal # service Bの外形監視アラート用ディレクトリ
│ └── verify # Datadogアラート検証用org向けディレクトリ
│ ├── external
│ └── internal
├── scripts # 新規サービス受け入れ時やその他便利スクリプト置き場
└── tests # Pullrequest時のテスト用スクリプト置き場
各サービスのアラート設定は、外形監視と内部監視とステートの管理を分けるようにしています。
理由としては、外形監視の監視元環境は自分たちのチームで管理している関係もあり、閾値調整などが発生するのでなるべく厳密に状態管理をしないといけないわけですが、内部監視のデータ元は各サービスのホストなどであり、閾値調整などの連絡をもらってから変更していると各サービスの開発や運用のスピードを止めかねないため、初期設定のデプロイのみを行い、各アラートの閾値変更などは各サービスにお任せすることにしたためです。
これによって、ステート管理とmodule管理のよさをなるべく得るようにしました。
modules内のファイル例
modules/external_internet/http_check/
├── external_internet_http_check_escalation_message.tpl
├── external_internet_http_check_is_alert_message.tpl
├── external_internet_http_check_is_alert_recovery_message.tpl
├── http_check.tf
└── variables.tf
こんな感じに、通知時のメッセージをテンプレートファイルに外出ししつつ、管理しています。
全てが一緒ではないのですが、色々と悩んでいた時にこちらの記事で着想を得ました。
ありがとうございました。
各サービス用ディレクトリ配下のファイル
下記は例ですが、ざっくりこんな感じにmodule用tfファイルやprovider設定、tfvars管理をしています。
├── serviceA_prod_external
│ ├── .terraform-version
│ ├── common_variables.tf
│ ├── orgsA-secret.tfvars -> ../../../credentials/tfvars/orgsA-secret.tfvars
│ ├── external_privateip_http_check.tf
│ ├── external_privateip_tcp_check.tf
│ ├── external_globalip_http_check.tf
│ ├── external_globalip_ssl_cert.tf
│ ├── external_globalip_tcp_check.tf
│ ├── external_internet_http_check.tf
│ ├── external_internet_ssl_cert.tf
│ ├── external_internet_http_check.tf
│ ├── provider.tf
│ └── serviceA_prod_external.tfvars
└─── serviceA_prod_internal
├── .terraform-version
├── common_variables.tf
├── orgsA-secret.tfvars -> ../../../credentials/tfvars/orgsA-secret.tfvars
├── internal_hostdown.tf
├── internal_disk.tf
├── internal_la.tf
├── internal_live_process_down.tf
├── internal_ntp_offset.tf
├── internal_swap.tf
├── provider.tf
└── serviceA_prod_internal.tfvars
各サービスの配下に監視項目単位のmodule呼び出し用tfファイルや閾値や監視先設定の変数を記載したtfvarsを置いています。
ディレクトリ名とtfvarsのファイル名を同じにしているのですが、デプロイスクリプトでのディレクトリ移動やtfvars名指定を楽するためだったりします。
このような構成にして数ヶ月運用してみて
現在、レガシー監視システム設定を各サービスの方々と調整しつつ、アラート設定をマイグレーションしていっているのですが、今回のマイグレーションプロジェクトで初めてTerraformを触った自分のチームメンバーでも自分がレビューするだけでアラートデプロイを行うことができるようになるくらい、moduleやデプロイのフローを標準化できてよかったな、と思っています。
※まだまだ煩雑なところもどうしてもあるので、もっと簡略化したいな、、、とは思いますが。。。
初めて触るメンバーにどうやってランプアップしていくのかは、色んなやり方があるかと思うのですが、今回のチームではドキュメントを提示しつつ、まずは触ってもらってイメージをつけてもらうことから始めました。
参考資料としたのは下記の通りです(アラート用リポジトリのREADMEから抜粋)。
# 参考資料
## Terraform全般
- [公式ドキュメントトップ](https://www.terraform.io/docs/index.html)
- [公式ドキュメントCLI編](https://www.terraform.io/docs/cli-index.html)
- `terraform plan`, `terraform apply` やその他コマンドについて記載されている
- [公式プロバイダードキュメント](https://www.terraform.io/docs/providers/index.html)
- 利用しているDatadogやその他プロバイダーについて記載されている
- [公式設定ファイル仕様ドキュメント(v0.12)](https://www.terraform.io/docs/configuration/index.html)
- [公式設定ファイル仕様ドキュメント(v0.11)](https://www.terraform.io/docs/configuration-0-11/index.html)
- resourceやdata sourceなどの概念、関数などがまとまっている
## Datadog monitor
- [Datadog monitor公式ドキュメント](https://docs.datadoghq.com/ja/monitors/)
- 日本語訳されていなかったりもするので、[英語版](https://docs.datadoghq.com/monitors/)も参考に
- [Terraform Datadog Providerドキュメント](https://www.terraform.io/docs/providers/datadog/index.html)
- [Terraform Datadog Providerリポジトリ](https://github.com/terraform-providers/terraform-provider-datadog/)
- エラーぽいとかそういうときにissue探したりする
## その他記事とか
- 2017年に @eigo-s がかいたもの(チュートリアル的に)
- https://qiita.com/eigo_s/items/637cf7c5fc7993b5bef9
おわりに
2年前に自分が記事を書いた頃よりも、Terraform界隈もDatadogなどでの監視系のコード管理の話も盛り上がっていて、もっともっと自分も勉強していき、自分の担当プロジェクトを改善していかないとな、と思う日々です。
直近では、Datadog Logs周りがDatadog Providerで対応されたので、管理しきれていないDatadog Logsを管理したいなぁ、と考えています。
そしてマイグレーションを完遂すべく、週明けからもお仕事頑張らねば、という感じで終わりにしたいと思います。
ありがとうございました。