はじめに
この記事は、dwango advent calenderの12日目の記事です!
今年に入ってから、自分の担当しているプロダクトではDataDogを利用してシステムの監視を行なっています。
DataDogを導入したキッカケの一つとして、Terraformで監視設定を構成管理配下に置いてコード化したい!ということがありました。
同じ設定をGUIでぽちぽちするのはなかなかに辛いですし、ドキュメントを書き続けるのも辛いので、すでにAWSのインフラ環境構築で行なっていることと同じようなフローでコード化が行えるのは魅力の一つでした。
ということで、今回は簡単なサンプルコードと共に、TerraformとDataDogで始めるMonitoring as Code入門したいと思います。
事前に必要な作業
- AWSアカウント、アクセスキー/シークレットキーの準備
- 1インスタンスぽこっと立ち上げます
- terraformのインストール
- 今回は0.11.x系を対象に
- tfenvが便利
- DataDogの API Key, Application Keyの払い出し
- ここからぽちぽちと
- DataDogのslack Integration連携
- こちらを参考に
Terraform DataDog Providerでは何を操作できるのか
2017/12現在、TerraformのDataDog Providerでは以下のリソースの操作を行うことができます。
- downtime
- monitor
- timeboard
- ダッシュボードのうち、timeboardの設定(Screenboardはまだできないっぽい?)
- user
- ユーザー周りの設定
- 今年導入された、read-onlyユーザーには未対応な模様
- ユーザー周りの設定
この記事では、入門ということで、monitorのみ設定します。
コードはこちらにあげてあります。
AWS環境の立ち上げ
-
- 上記のリポジトリをgit clone後、下記のようなコマンドでインスタンスに登録するkey_pair用の秘密鍵/公開鍵を作成します
※AWS構築時のアクセスキーやプロファイルの設定については割愛します
- 上記のリポジトリをgit clone後、下記のようなコマンドでインスタンスに登録するkey_pair用の秘密鍵/公開鍵を作成します
$ cd aws/
$ ssh-keygen -t rsa -N "" -f batsion
$ mv batsion batsion.pem
-
- secret.tfvars.templateをコピーし、作成した公開鍵とagentのインストール時に利用するDataDogのAPI Keysを埋めます
$ cp secret.tfvars.template secret.tfvars
$ vim secret.tfvars
bastion_public_key = "実際の公開鍵"
datadog_api_key = "実際のAPI Key"
-
- terraformを実行し、VPC作成〜インスタンス作成まで行います(apply時にapproveを求められるので
yesを入力
- terraformを実行し、VPC作成〜インスタンス作成まで行います(apply時にapproveを求められるので
# terraform provider取り込み
$ terraform init
# plan実行
$ terraform plan -var-file=secret.tfvars
# apply実行
$ terraform apply -var-file=secret.tfvars
以上で監視対象のインスタンスが作成されました。
追加されるとこんな感じにDataDogの方に現れます。

DataDogの監視設定追加
さて、続けてmonitor設定の追加を行います。
-
- secret.tfvars.templateをコピーし、DataDogのAPI Keys, Application Keysを埋めます
$ cp secret.tfvars.template secret.tfvars
$ vim secret.tfvars
datadog_api_key = "実際のAPI Key"
datadog_app_key = "実際のApplication Key"
-
- terraformを実行し、monitor作成まで行います(AWSの時同様にapply時にapproveを求められるので
yesを入力
- terraformを実行し、monitor作成まで行います(AWSの時同様にapply時にapproveを求められるので
# terraform provider取り込み
$ terraform init
# plan実行
$ terraform plan -var-file=secret.tfvars
# apply実行
$ terraform apply -var-file=secret.tfvars
以上でmonitor設定の追加が行われました。
今回はsystem.cpu.user(インスタンスのCPU usertime)の5分平均が50%以上であればwarnnig、60%以上であればcriticalとし、事前に設定したslackチャンネルに通知するようにしています。
これらは、variable.tf にてデフォルト値が設定指定あるので、変更したい場合は適宜変更してみてください。
※例えば下記のように
datadog_monitor_slack_channel = "slack-system-alert"
datadog_monitor_cpu_usertime_thresholds_warning = "60"
datadog_monitor_cpu_usertime_thresholds_critical = "70"
アラートテストを行う
さて、監視がうまくいってるかどうか確認、ということで作成したインスタンスにログインし、インスタンスに負荷を適当にかけてみます
※デフォルトのSecurity Groupでは、サンプルということでどこからでもSSHが可能なようにしているため、batsion_ingress_cidr_blocksの値を適宜変更すると安全かもしれません
# ログイン
$ ssh -i bastion.pem ec2-user@[インスタンス EIP]
# 負荷をかける
$ yes >> /dev/null &
上記を実施後、しばらくすると下記のようにアラートが飛んできます!
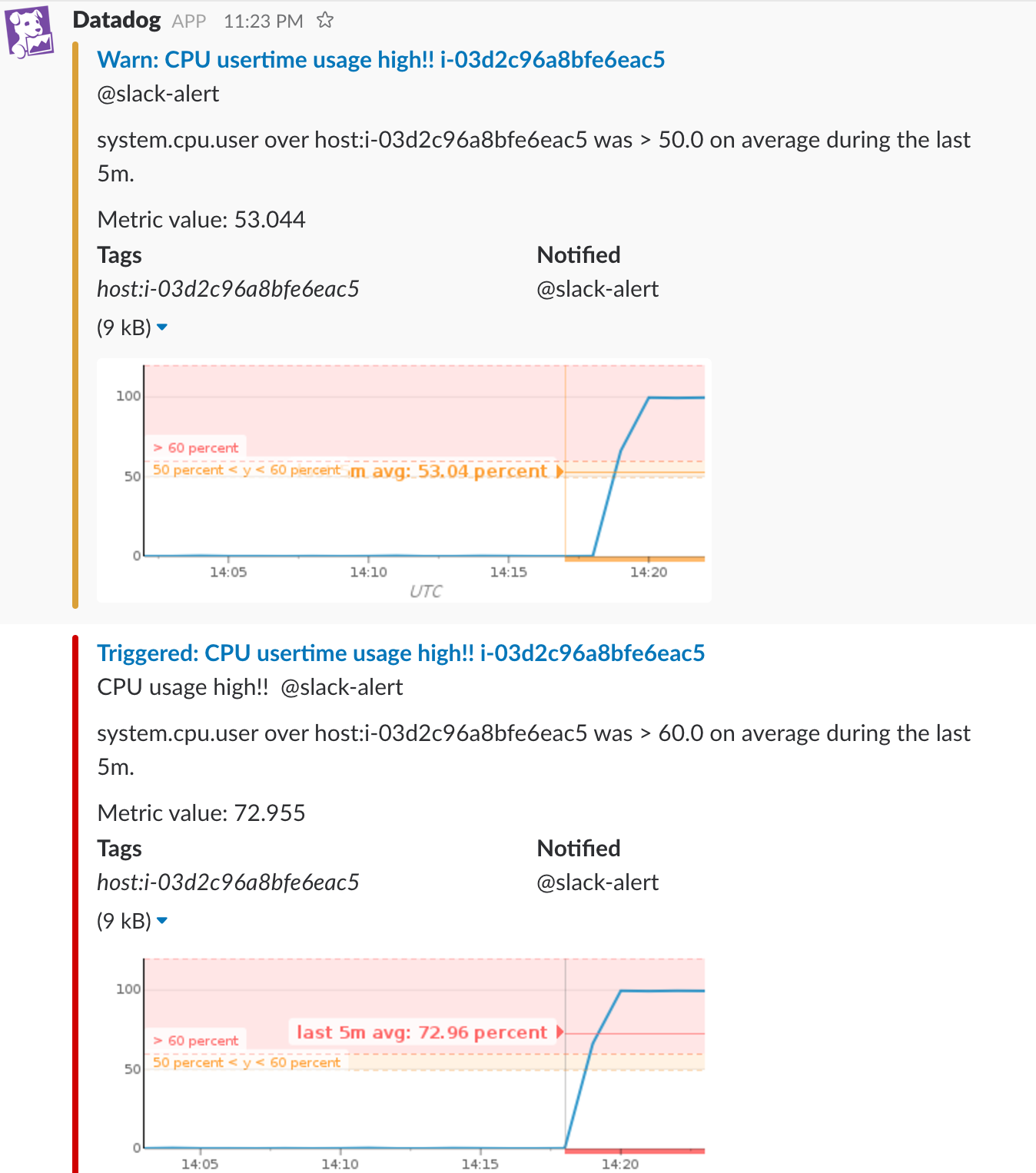
ということで、yesコマンドを停止し、復旧通知を確認して終了です。おつかれさまでした。
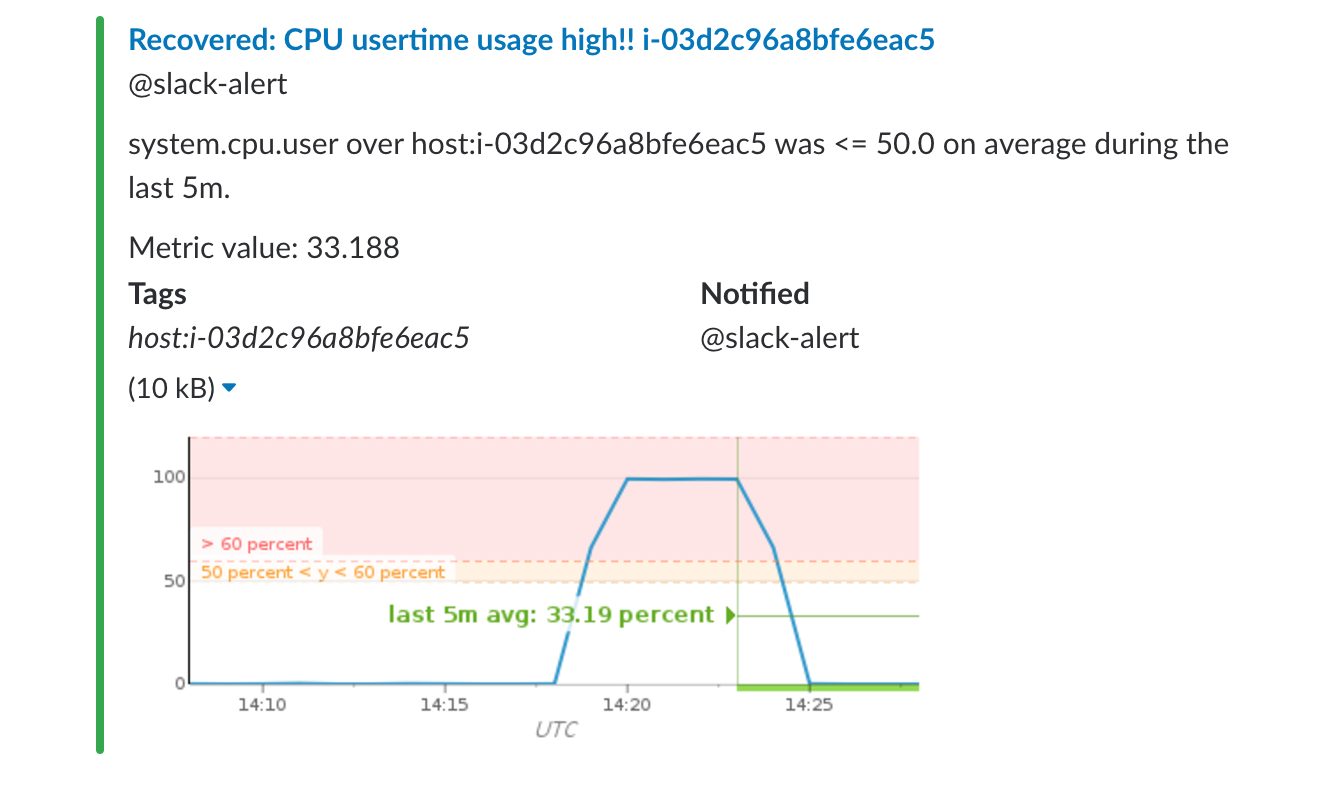
なお、作成したインスタンスはterraform destroy -var-file=secret.tfvarsを実行することで削除可能です。
終わりに
簡単でしたが、Monitoring as Code入門でした。
DataDogには、今回のような簡単な監視だけでなく、他にも様々なメトリクスアラートやもっと高度な機械学習型のアラートが存在するので、よりうまい具合に活用しつつ、Monitoring as Codeを推し進めていきたいな、と思います。