はじめに
前回の投稿から約8ヶ月、世の中はAdvent Calenderで賑わっているようですが普通に投稿します。
今回はKerasというバックエンドにTensorflowとTheanoを選べるディープラーニングライブラリを使っています。
解く問題
TensorFlowでキルミーアイコン686枚によるキルミー的アニメ絵分類参照。
と思ったらちゃんと書いてなかった。
http://killmebaby.tv/special_icon.html
このキルミーアイコン686枚をyasuna, sonya, agiri, botsu, yasuna&sonya, othersの6つのクラスに分類します。データ準備などは上記投稿を参照。
実装
今回はコードをGithubにあげました。
kerasおよびその他必要なライブラリをインストールすればだれでもキルミーに限らない画像分類がたのしめるかもしれません。
https://github.com/domkade/kill_me_learning
前処理とかモデル評価用のプログラムも混じっているのでごちゃごちゃしていますが、kerasによるモデル定義と学習はkmb_train.pyの以下の部分だけです。短い!すごい!
model = Sequential()
model.add(Convolution2D(32, 3, 3, border_mode='valid',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
#
# 中略
#
model.add(Dense(NUM_CLASSES))
model.add(Activation('softmax'))
rmsplop = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
model.compile(loss='categorical_crossentropy', optimizer=rmsplop, metrics=['accuracy'])
# training
hist = model.fit(x_train, y_train,
batch_size=BATCH_SIZE,
verbose=1,
nb_epoch=EPOCH,
validation_data=(x_test, y_test))
以下とても適当な説明です。
- model.addっていっぱい書いてあるところは
https://keras.io/ja/getting-started/sequential-model-guide/
の、VGG風のCNN:からぱくってきたコードです。最後の層をNUM_CLASSES(分類したいクラス数)にします。 - 損失関数は勾配を見つけるパワーが強いと誰かから聞いた気がするrmsplopを使っています。
- model.compileでmetrics=['accuracy']を設定すると各epochで正答率が出ます。
- model.fitをよぶと実際に学習をはじめますが、戻り値に各epochでの学習データに対するlossやaccuracyが入ってるので便利です。この実装では戻り値histをつかいグラフを出力します。
- model.fitのvalidation_dataにテストデータを与えておくと、各epochでのテストデータに対するlossやaccuracyも出るので評価に大変便利です。テストデータの分割がめんどうな方は、validation_split=0.2と指定すると、学習データの後ろ20%をテストデータとして使ってくれますのでこちらも大変便利です。
使い方
GithubのREADMEに書くべきですが気が向いたら書きます。それまでここに最低限の使い方を書きます。
- dataディレクトリ以下の構造を参考に分類したい画像データをいれます。最初に入ってるデータはいらないので消してください。
-
rm ./list/*でlistディレクトリ以下の.lstファイルを消します。自分で編集してもいいですがdataフォルダに正しくデータがおいてあれば次のステップで勝手に.lstファイルがつくられます。 -
python kml_train.pyで学習をします。listの中身がなければ、dataの中身を乱数でtrain:test=8:2にわけて.lstをつくります。ちなみにlistの中身があればそのリストを使いますので前回と同じ学習・テストデータの組でやりたい場合などに便利です。学習は、lossとaccuracyを出力しながら行われます。終わるとkml_[日付].modelとgraph_[日付].pngを出力します。 -
python kml_test.py --model kml_201612xxxxxxxx.modelとやると、どのテストデータがどのくらいの確率で各クラスに分類されるのかが出力されます。
学習
dataをキルミーアイコンに置き換えてkml_train.pyで学習させます。
10epochぐらいで以下のような感じ。
Epoch 10/100
549/549 [==============================] - 1s - loss: 0.7665 - acc: 0.7250 - val_loss: 1.1086 - val_acc: 0.7737
100epochで以下のような感じ。
Epoch 100/100
549/549 [==============================] - 1s - loss: 0.1359 - acc: 0.9818 - val_loss: 2.1398 - val_acc: 0.8029
学習データに対する誤差lossは小さくなり、正解率accは上がっていますが、テストデータに対する正解率val_accはあんまり変わらず、テストデータに対する誤差val_lossはむしろ大きくなっています。
出力されたグラフを見てみます。
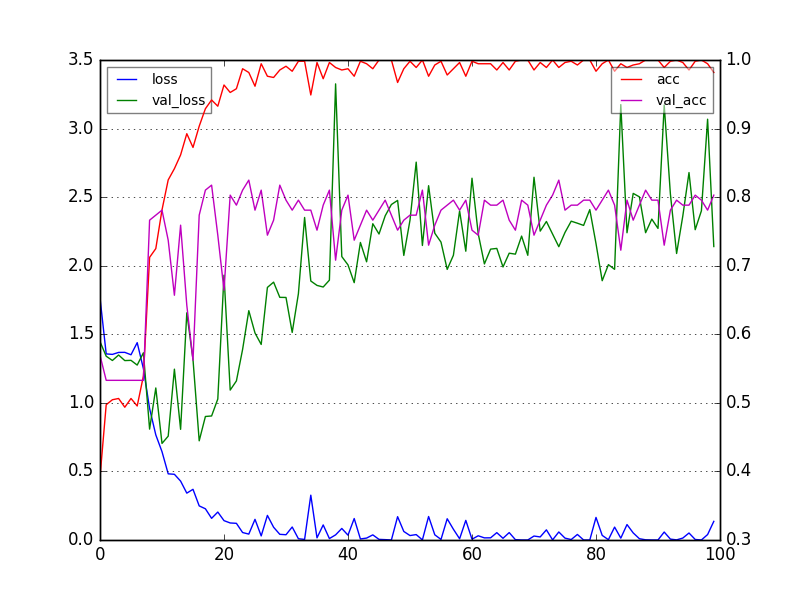
ガタガタでわかりづらいですが、10epochあたりから緑(val_loss)が青(loss)に沿わなくなってるのがたぶん過学習です。そのあたりからマゼンタ(val_acc)も赤(acc)に沿わなくなってます。
評価
学習したモデルをつかい、kml_test.pyでどの画像があたってるか外れてるか見てみます。全体を見た感じではやすなとソーニャの分類は大体できてるようです。この二人のデータが大部分を占めるので当然といえば当然です。
いくつか間違いの例をみていきます。
./data_kmb/yasuna/11_042.png
Incorrect...
answer: yasuna
predict: agiri
others: 0.00 botsu: 0.00 sonya: 0.00 yasuna: 0.00 agiri: 1.00 yasuna&sonya: 0.00

ゾンビーベイベーのときのやすなを100%あぎりさんだといっています。色からの判断をしているためでしょうか。たしかにこの髪の色は完全にあぎりさんです。
./data_kmb/yasuna&sonya/02_018.png
Incorrect...
answer: yasuna&sonya
predict: yasuna
others: 0.01 botsu: 0.00 sonya: 0.28 yasuna: 0.71 agiri: 0.00 yasuna&sonya: 0.00

やすな&ソーニャをやすなかソーニャのどっちかで迷っています。逆エビ固めで二人が絡み合っているためでしょうか?このような間違い方はほかになかったので興味深いです。
./data_kmb/yasuna/10_054.png
Incorrect...
answer: yasuna
predict: others
others: 0.80 botsu: 0.00 sonya: 0.16 yasuna: 0.04 agiri: 0.00 yasuna&sonya: 0.00

マスクをつけたやすなをその他の画像と間違えた例です。後ろの雷が目立つためその他の画像っぽいと判断してしまった気持ちはわかる気はしますが、それ以外の可能性としてやすなっぽさ4%でソーニャっぽさ16%と判断したのは謎です。
このように、間違え方がわかるので割と楽しいです。しかし、どうやったら正解させられるようになるのかはまったくわかりません。
全体としては、正解率8割ぐらいあるのでなかなかです。Libellioを使った先行研究のほうが正解率9割とよさそうに見えますが、これは先行研究では6クラスに分類できないものはデータセットから省いてるためだと推測します。
http://oribeyasuna.hatenablog.com/entry/2015/07/19/095248
今後の課題
- 過学習が発生しているっぽいのでなんとかしたい。ノイズが少ないとか、ネットワークの表現力が高すぎとかが原因と推測しますがなんとかなるものでしょうか。というか解消して正解率8割を超えるのかもわかりません。
- データセットを686枚より多くしたい。アニメやマンガから拾ってくるしかなさそうですが、そういった画像を学習に使うのは著作権的にホワイトに近いグレーというはなしをききました。よくわかりませんので2期をやってまた1巻の売れた枚数だけアイコンを公開してくれるとうれしいです。
- Webアプリとして公開したい。公開するとニューラルネットをいじめる画像を入力してくれるひとがいるらしく、また新しいことが見えてくるかもしれません。
つづく。