(なんでキルミーベイベーってタグがあるんだ…)
前回の投稿で、Ubuntuの環境をつくったので、
TensorFlowのDeep MNIST for Expertsを大体そのまま使ってキルミーベイベーのキャラを判定するコードを書いてみました。
※TensorFlow公開されたの去年の11月だからもう半年たつんですね…
参考にしたページ
今回使った画像セットは例の686枚です。
http://killmebaby.tv/special_icon.html
全体の方針・キルミーアイコンの分類とかはkill_me_learningの先人である方が書かれたこちらの記事を参考にさせていただきました。
kill_me_learning (4) Labellioを用いたキルミーベイベーアイコン686枚によるキルミーベイベー的画像分類
サンプルネットワークへの画像の変換・入力の方法はこちらを参考にさせていただきました。
TensorFlowでアニメゆるゆりの制作会社を識別する
背景
キルミーベイベーとは、
- BD1巻が686枚しか売れなかったから同じ枚数のTwitterのアイコンを公開した
- ベスト盤CDとBDBOXは結構売れてYahoo!のトップニュースにこの記事が載った
- 3人しかいないメインキャラの中の人の一人が捕まったり釈放されたりした
などなど、不死鳥のように復活したかと思ったらまた死んだみたいな感じで世間を騒がせて(?)いる、ババーンなどでも謎の知名度がある、まんがタイムきららキャラットで連載中のカヅホ先生による4コマ漫画です。
僕の中でも、ニコ生一挙放送で気まぐれに立ち寄ったら頭にナイフを3本くらい刺されたような衝撃を受けたあの日から、キルミーに対する情熱の火は衰えることを知りません。本放送じゃねーのかよ。
それでもDeep Learningでの画像認識は、キルミストの端くれとして、最初はキルミーでやるぞって決めてたので今回やりました。
データ準備
例の686枚をkill_me_learningの方針通り、やすな、ソーニャ、あぎり、没キャラ、やすなとソーニャ、その他の6分類で分けて、それぞれyasuna, sonya, agiri, botsu, yasuna&sonya, othersってディレクトリに分けて置きました。キルミーへの情熱を原動力に手作業でやりました。
オサレなシルエットとか、二人以上写ってて、やすなとソーニャに分類できないものは全部その他に入れました。一斗缶やすなとか、かぼちゃあぎりさんとかはそれぞれのキャラに分類してみました。鳥避け装備はその他です。このへんは適当です。
実装
前提
環境導入ははてなの方の記事で済んでるので、この記事に貼ったコードをベースに差分を説明していきます。
最短手順でtensorflowのDeep MNISTサンプルを実行
画像の読み込みにOpen CVを使うので、以下を参考に入れました。
UbuntuにPython版OpenCVをインストール
独自のデータセット読み込み
画像を読み込む部分を最初に書きます。参考にしたゆるゆり識別では画像ファイル名とラベルの組を作って読み込んでますが、今回は分類ごとにディレクトリ分けが済んでいて、ディレクトリ毎に同じラベルをつければいいだけなので、pythonだけでファイル一覧取得からラベル作成までやります。
./data配下にyasuna, sonya, agiri, botsu, yasuna&sonya, othersがあるのを想定しています。
train_imageとtrain_labelに画像データとラベルデータを格納するのは同じです。
import os
import numpy as np
import cv2
NUM_CLASSES = 6 # 分類するクラス数
IMG_SIZE = 28 # 画像の1辺の長さ
# 画像のあるディレクトリ
train_img_dirs = ['yasuna', 'sonya', 'agiri', 'botsu', 'yasuna&sonya', 'others']
# 学習画像データ
train_image = []
# 学習データのラベル
train_label = []
for i, d in enumerate(train_img_dirs):
# ./data/以下の各ディレクトリ内のファイル名取得
files = os.listdir('./data/' + d)
for f in files:
# 画像読み込み
img = cv2.imread('./data/' + d + '/' + f)
# 1辺がIMG_SIZEの正方形にリサイズ
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
# 1列にして
img = img.flatten().astype(np.float32)/255.0
train_image.append(img)
# one_hot_vectorを作りラベルとして追加
tmp = np.zeros(NUM_CLASSES)
tmp[i] = 1
train_label.append(tmp)
# numpy配列に変換
train_image = np.asarray(train_image)
train_label = np.asarray(train_label)
cv2.imreadで読み込んだデータは、最初、
[[[R, G, B], [R, G, B], ..., [R, G, B]],
[[R, G, B], [R, G, B], ..., [R, G, B]],
...,
[[R, G, B], [R, G, B], ..., [R, G, B]]]
みたいな、x・yの座標に対してRGB値がそれぞれある、3次元の配列になってますが、ネットワークに入力するときは一列じゃないといけないので一列にします。ネットワークの最初でまたこの3次元構造にもどります。多分。
ラベルの方も、6つに分類するんだったら6次元で一個だけ1のベクトルじゃないといけないので、たとえばyasunaに対しては、[1, 0, 0, 0, 0, 0]、othersに対しては[0, 0, 0, 0, 0, 1]みたいな配列を作って登録してます。
こう書いておけば、いちおうディレクトリに画像を追加するだけで学習セットの強化ができるはずです。
ネットワーク定義
Deep MNISTサンプルのネットワークをほぼそのまま利用できますが、画像がグレースケールからRGBに、分類が10個から6個になったことにより、一部変数を変える必要があります。
COLOR_CHANNELS = 3 # RGB
IMG_PIXELS = IMG_SIZE * IMG_SIZE * COLOR_CHANNELS # 画像のサイズ*RGB
RGB3色のチャンネルを表す定数と、学習画像データの長さを定義する定数を定義します。
x = tf.placeholder(tf.float32, shape=[None, IMG_PIXELS])
y_ = tf.placeholder(tf.float32, shape=[None, NUM_CLASSES])
学習画像データ、学習データのラベルのプレースホルダの形を、それぞれの長さに合わせて定義しなおします。元は28px x 28px x 1色で784でしたが、今回は3色なので3倍の2352になります。
W_conv1 = weight_variable([5, 5, COLOR_CHANNELS, 32])
一層目の重み変数が、1色→32チャネルの形なので、3色→32チャネルの形に変えます。
x_image = tf.reshape(x, [-1, IMG_SIZE, IMG_SIZE, COLOR_CHANNELS])
さっき言ってた、1列で入力した画像データを3次元構造に戻してると思われるところです。ここも1色→3色に変えます。
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
2回めの全結合で、元は10分類でしたが、今回は6分類にするので10を6にします。
他の部分はそのままです。
学習
聞いた話によると学習データをランダムに並び替えてミニバッチで学習させるのが効果的らしいので、今回は686枚をシャッフルし、50枚ずつ与えて一周するのを1ステップとし、それを100回繰り返してみます。2つの配列を同じseedでシャッフルする方法がよくわからなかったのでゴリ押しです。
STEPS = 100 # 学習ステップ数
BATCH_SIZE = 50 # バッチサイズ
for i in range(STEPS):
random_seq = range(len(train_image))
random.shuffle(random_seq)
for j in range(len(train_image)/BATCH_SIZE):
batch = BATCH_SIZE * j
train_image_batch = []
train_label_batch = []
for k in range(BATCH_SIZE):
train_image_batch.append(train_image[random_seq[batch + k]])
train_label_batch.append(train_label[random_seq[batch + k]])
train_step.run(feed_dict={x: train_image_batch, y_: train_label_batch, keep_prob: 0.5})
# 毎ステップ、学習データに対する正答率を表示
train_accuracy = accuracy.eval(feed_dict={
x:train_image, y_: train_label, keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
コード全体像
コメント書いてないので書いたらgithubに上げます。たぶん
最初からソースにコメントしていく形で説明したほうがよかったなと後悔。
実行
学習をやってみると、
step 0, training accuracy 0.575802
step 1, training accuracy 0.638484
step 2, training accuracy 0.653061
step 3, training accuracy 0.705539
step 4, training accuracy 0.71137
step 5, training accuracy 0.699708
step 6, training accuracy 0.725947
step 7, training accuracy 0.730321
step 8, training accuracy 0.746356
step 9, training accuracy 0.752187
step 10, training accuracy 0.776968
step 11, training accuracy 0.782799
step 12, training accuracy 0.817784
step 13, training accuracy 0.817784
step 14, training accuracy 0.862974
step 15, training accuracy 0.848396
step 16, training accuracy 0.858601
step 17, training accuracy 0.874636
step 18, training accuracy 0.880466
step 19, training accuracy 0.890671
step 20, training accuracy 0.900875
...
徐々に学習データに対する正答率が上がってくるのがわかります。step 50くらいで1になりました。学習データに対する正答率はあんまり意味ないですが、ネットワークがキルミーに染まっていくイメージを感じ取れます。
学習の終わったネットワークに対する評価はまた別にやりたいのですが、とりあえず実験として100ステップの学習が完了したネットワークに対して、学習データ(キルミーアイコン)とは別のテストデータとして、原作漫画のやすなとソーニャ(ババーン含)をそれぞれ6枚ずつ与えてみました。コードは割愛しますがテストデータも学習データと同じ形式で読み込んでいるのでディレクトリに置くだけです。
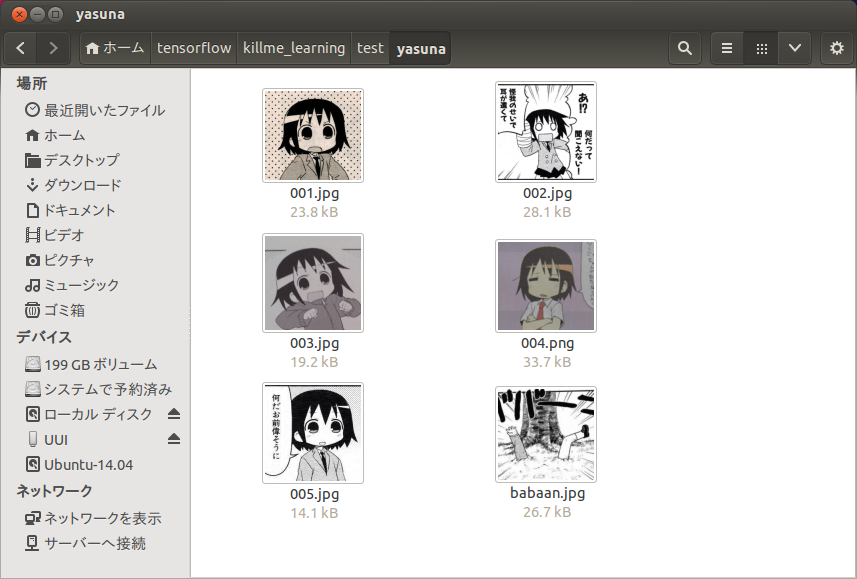
結果は、正答率75%でした。ソーニャちゃんが半分ぐらいしか正解しないようです。なぜかやすなはババーン含め全問正解です。やすな細胞は単純なのか。サンプルにそのまま流しただけにしては、なかなかよい結果ではないでしょうか。もしババーンを判別できなかったら木の下に埋めてもらっても構わないよ
つづく。