※ 2019/04/07 追記: 問題設定を少し修正し、実験をやり直しました。
※ 2019/04/19 追記: モデルを少し変更し、実験をやり直しました。
この記事は何
せっかく Pythonで学ぶ強化学習 をざっと読んだので、手を動かしてみる大作戦です。
FlappyBird という数年前に話題になったゲームがあり、それを強化学習を用いて学習していきたいと思います。
目標は満点である264点を安定して取ることです。
のんびり動かしてみつつ、色々やったことを記録していこうと考えています ![]()
- FlappyBird で強化学習の練習 その0: 環境編
- FlappyBird で強化学習の練習 その1: DQN
- FlappyBird で強化学習の練習 その2: Double DQN
- FlappyBird で強化学習の練習 その3: DQN + Dueling network <- これ
本記事では、DQN に Dueling network という手法を組み合わせました。
勉強しつつ書いてるので、何か誤りなどあればコメントいただけると助かります ![]()
実装は jupyter notebook 上で行っており、 今回のコードはこちらです。
リポジトリはこちら: cfiken/flappybird-try
目次
- Dueling network とは
- FlappyBird の結果
- 実装の紹介
- まとめ
Dueling network とは
Dueling Network とは、Dueling Network Architectures for Deep Reinforcement Learning というタイトルで Ziyu Wang ら DeepMind のメンバーによって2015年に発表された手法です。
強化学習の方法には手を加えず、基本的な学習の方法も変えずに、モデルの構造だけ少し変えることで性能を向上させて、 Atari 2600 で新たな SOTA を記録しました。
概要
DQN では、次のように、パラメータ $\boldsymbol{\theta}$ を持つNNモデルを使って出力画像の状態 $s_t$ から、ある状態 $s_t$ でのある行動 $a$ の価値である Q 値を計算していました。
\begin{align}
Q\left(s_{t}, a \right) &= f(s_t; \boldsymbol{\theta}) \,\,\,\, (f\mathrm{: neural \, network \, model})
\end{align}
ここで Q は、状態 $s_t$ の価値である $V(s_t)$ と、状態 $s_t$ の時にとるある行動 $a$ の良さである advantage $A(s_t, a)$ を使って次のように書くこともできます。
\begin{align}
Q\left(s_{t}, a \right) &= V(s_t) + A(s_t, a)
\end{align}
Dueling network は、NNモデルにより直接 Q を予測していたところを、 $V(s_t)$ と $A(s_t, a)$ をそれぞれ予測し、Q を計算するというアーキテクチャのネットワークです。
下記図1の、上が DQN での例、下が Duering network の例になっています。
convolution layer まではネットワークを共有しつつ、dense layer から分岐してそれぞれの値を出力し、最後に図中で緑のところで計算により Q を出しています。
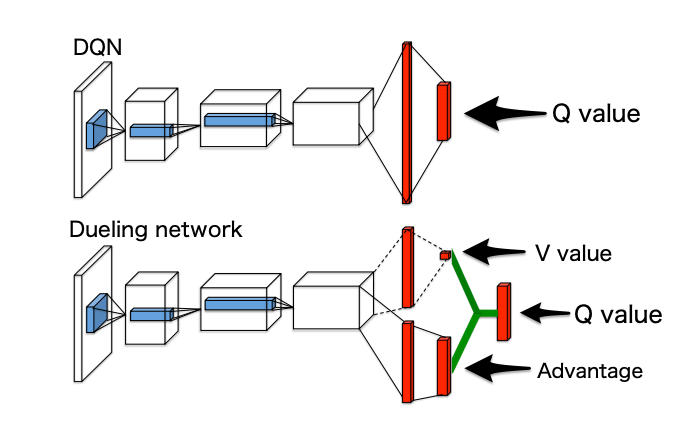
図1: [1]の Figure 1 を引用し、黒文字で説明を足したもの(元々論文にあったのは図のみ)
また、結果として単に Q を見るだけでなく、ある状態での価値 V とその時の各行動の良さ A を得ることができるようになるので、次のような可視化ができるようになりました。
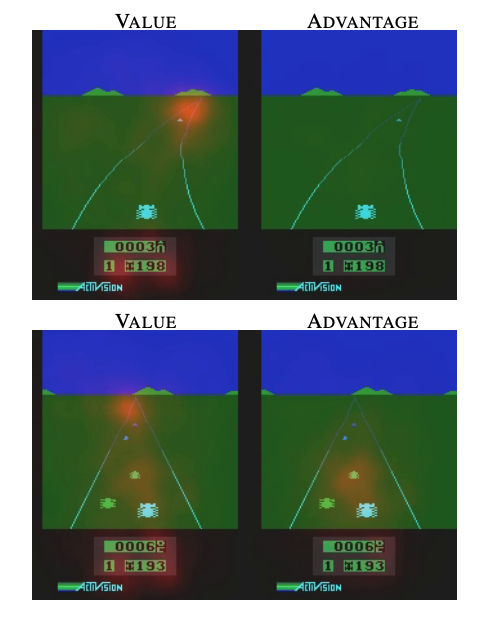
図2: [1] Figure 2 を引用
このゲームは自機(画面中央下)が障害物に当たらないように進むゲームです。図の上下は単に異なるタイムステップを取ったものです。
ゲーム画像の上に「ネットワークがどこを見ているか」を 赤で示した図になっています。左が Value (V), 右が Advantage で、それぞれ推定をするためによく見ているエリアを赤で表していると考えることが出来ます。
見て分かる通り、Value は道の奥の方や、障害物が近いときは自機周辺を見ているのに対して、Advantage は障害物が近いときだけその周りを強く見ています。
障害物が遠い時はどの行動をとっても価値には影響が少なく、障害物が近いときは特定の行動を取らないとゲームオーバーになってしまう(ため注視する)、というのが Advantage として得られているのが分かります。
また、論文では Dueling network と、ここまでに出た Double DQN や Prioritized Experience Replay などと組み合わせて更に良い結果を出していました(Prioritized Experience Replay と組み合わせたものが SOTA 更新)。
Advantage について
突然 Advantage というものが出てきたので、論文でも Background として説明されている部分を補足します。
ある方策 $\pi$ について、状態価値関数 $V$ と行動価値関数 $Q$ を次のように定義します。
\begin{align}
Q^{\pi}(s, a) &= \mathbb{E} \left[ R_t | s_t = s, a_t = a, \pi \right] \\
V^{\pi} &= \mathbb{E}_{a \sim \pi(s)} \left[ Q^{\pi}(s, a)\right]
\end{align}
ここで、 $R_t$ は割引報酬です。
Advantage は次のように定義します。
A^{\pi}(s, a) = Q^{\pi}(s, a)-V^{\pi}(s)
ここで、V, Q の定義より $\mathbb{E}_{a \sim \pi(s)}\left[A^{\pi}(s, a)\right]=0$ です。
定義から Advantage が表すのは、ある状態における、(状態価値を除いた)特定の行動の良さだと分かります。Q だけを見ていると、値が大きかったときに、「そもそもの状態価値が高く、どの行動をとってもほぼ影響がない」のか、「状態価値は低いが、特定の行動を取ると一気に価値が大きくなる」のかは分かりません。Advantage を導入することにより、図2のように上記を考慮に入れることができるようになります。
Advantage 自体は1993年に Baird が発案したアルゴリズムで、これを用いることで単純な Q-Learning に比べて収束が早くなることが紹介されています。また、A2C や A3C という有名な深層強化学習アルゴリズムでも使われています。
モデルへの適用
Dueling network のアーキテクチャは図1の下図のとおりですが、単純にやると「2つの値に分けて Q を計算しただけ」となってしまうため、ちゃんとそれぞれの値が Value, Advantage を表すものになっているためには少し工夫が必要です。それができれば、モデルの入出力は DQN と変わらないので他は変更はありません。
さて、前節までの説明で、定義より明らかに次のことがわかっていました。
\begin{align}
Q\left(s_{t}, a \right) &= V(s_t) + A(s_t, a) \\
V^{\pi} &= \mathbb{E}_{a \sim \pi(s)} \left[ Q^{\pi}(s, a)\right] \\
\mathbb{E}_{a \sim \pi(s)}\left[A^{\pi}(s, a)\right] &= 0
\end{align}
ここで、 $\pi(s)= a^{*} = \arg \max _{a^{\prime} \in A} Q\left(s, a^{\prime}\right)$ のような決定的な方策を使用すると、状態価値関数 V と Advantage A は、定義より
\begin{align}
V(s) &= Q(s,a^*) \\
A(s,a^*) &= 0
\end{align}
となります。
DQN では、方策として epsilon-greedy 法のような最適な行動を選択をするものを用いるため、同様に考えることができます。
ネットワーク内の Q の計算(図1の緑色の部分)について、「選ばれた行動(≒その時点で最適な行動)についての advantage の推定が 0 になる」ような制約を加えることで、推定するそれぞれの値が真に V や A を表すものとなるようにします。
\begin{align}
Q(s, a)=V(s) + \left(A(s, a)-\max _{a^{\prime} \in|A|} A\left(s, a^{\prime}\right)\right)
\end{align}
こうすることにより、ネットワークのそれぞれの出力 V と A が、本来の意味での状態価値関数と advantage を推定するものになります。
これで良さそうですが、論文によると、 advantage の計算には最終的には下記のような、 max を平均に置き換えたものが使われています。
\begin{align}
Q(s, a) = V(s)+\left(A(s, a)-\frac{1}{|\mathcal{A}|} \sum_{a^{\prime}} A\left(s, a^{\prime}\right)\right)
\end{align}
これにより V や A の本来の意味(上記で考えたもの)とは少し変わってしまうものの、より学習が安定するとして採用されています。
結果
スコアの計算は次のように行います。
- モデルを別々に5回学習する
- それぞれのモデルで50回ずつプレイして、スコア(超えたドカンの数)の平均(と分散)を計算する
- モデル5個のそれぞれの結果の mean, median を比較する
5つのモデルと最終的な結果は次のようになりました。
mean: 54.8200, std: 50.0754
mean: 64.2400, std: 65.3280
mean: 53.3000, std: 54.4218
mean: 64.3600, std: 61.8992
mean: 47.7600, std: 49.5805
--- total ---
mean: 56.896, median: 54.820
平均スコアは 56.896, 中央値は 54.820 でした。
相変わらずスコアはブレは大きいですが、平均でも中央値でも DQN より良い結果になりました。
また、前回の Double DQN を組み合わせて dueling network + DDQN でも試したところ、次のように結構悪い結果になりました。
mean: 29.868, median: 25.500
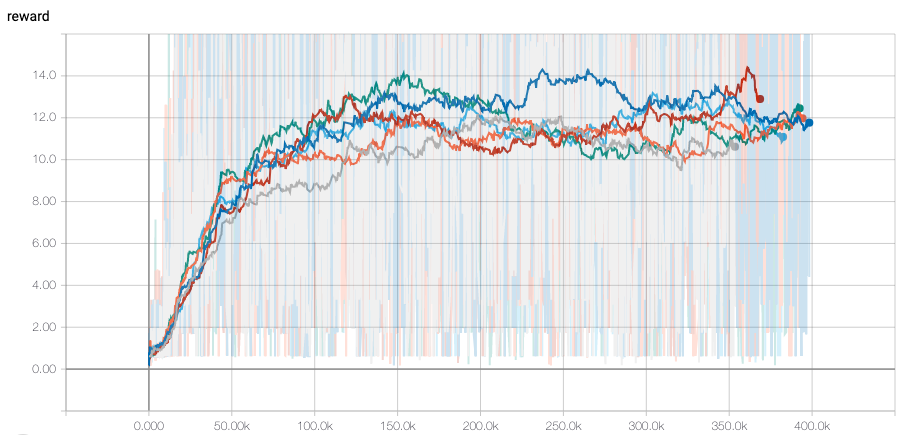
また、学習中の TensorBoard での reward の例です。
分かりづらいですがグレーがDQN, 他が Dueling network です。あんまり大きな変化はなく、少しだけ DQN よりも平均して良いかな?というくらいですね。
実装の紹介
実行時の notebook はこちらです。
元となっている DQN のコードについては前回記事: FlappyBird で強化学習の練習 その1: DQN に紹介しています。
今回は AgentModel 内だけ変更を加えました。図1の通りのネットワーク構成にしつつ、Q を計算しています。
dense layer は、前回までは Q のための1つでしたが、今回は V と A をそれぞれ出力したいので2つあります。 unit 数は、前回までが 256 だったため、今回は 128 を2つにしてパラメータ数が変わらないようにしました。
class AgentModel(tf.keras.Model):
def __init__(self, is_training: bool, num_actions: int):
super(AgentModel, self).__init__()
self.is_training = is_training
k_init = tf.keras.initializers.glorot_normal()
relu = tf.nn.relu
self.conv_01 = tf.keras.layers.Conv2D(32, kernel_size=8, strides=4, kernel_initializer=k_init, activation=relu)
self.conv_02 = tf.keras.layers.Conv2D(64, kernel_size=4, strides=2, kernel_initializer=k_init, activation=relu)
self.conv_03 = tf.keras.layers.Conv2D(64, kernel_size=3, strides=1, kernel_initializer=k_init, activation=relu)
self.flatten = tf.keras.layers.Flatten()
self.dense_v = tf.keras.layers.Dense(128, kernel_initializer=k_init, activation=relu)
self.dense_ad = tf.keras.layers.Dense(128, kernel_initializer=k_init, activation=relu)
self.output_v_layer = tf.keras.layers.Dense(1, kernel_initializer=k_init)
self.output_ad_layer = tf.keras.layers.Dense(num_actions, kernel_initializer=k_init)
def call(self, inputs):
outputs = inputs
outputs = self.conv_01(outputs)
outputs = self.conv_02(outputs)
outputs = self.conv_03(outputs)
outputs = self.flatten(outputs)
output_v = self.dense_v(outputs)
outputs_ad = self.dense_ad(outputs)
output_v = self.output_v_layer(output_v)
outputs_ad = self.output_ad_layer(outputs_ad)
q = output_v + (outputs_ad - tf.reduce_mean(outputs_ad))
return q
def compute_output_shape(self, input_shape):
shape = tf.TensorShape(input_shape).as_list()
return [shape[0], self.num_outputs]
ほかは特に変更ありません ![]()
まとめ
Dueling network + DQN のモデルを作って、FlappyBird をプレイしました。
DQN のみのモデルよりは少し良い結果になりましたが、まだ分散も大きく、安定はしていません。
モデルの内部に少し変更を加えるだけで安定性があがるとのことなので、他のアイディアと組み合わせつつ使っていきたい手法です。