背景
今月からプロトアウトスタジオというスクールに入り、Qiita記事投稿の課題が出ました。
もともとnoteやはてなブログでブログは書いたことはありましたが、Qiitaへの投稿は初。
普段は1回あたり1000文字書くなどの基準を作っていましたが、Qiita記事はどれぐらい書いたら平均的なんだろうか。
ということで調べてみました。
調査対象
どうせなら色々分析してみたいので、記事本文の文字数以外の要素も取り出してみました。
・タイトル文字数
・タグ数
・本文文字数
・コード挿入回数(コードの文字数を取り出すロジックが難しくて断念)
・セクション数
・セクション当たりの本文文字数
・LGTM数
・コメント数
"node.js"という単語を含む記事5000件をQiitaAPIで取り出してcsvに成形、jupyter notebookで可視化・分析という作戦でいきました。
環境
node v12.18.2
Visual Studio Code 1.47.1
jupyter-notebook 6.0.3
python 3.7.6
サンプルコード
//package require
const axios = require("axios");
const fs = require("fs");
const csvStr = require("csv-stringify/lib/sync");
//QiitaAPIでデータ取得・csvに出力
async function getArticle(query) {
//csvに変換する用list
let outcsv = [];
let columns = ["タイトル","タイトル文字数","タグ数","本文文字数","コード挿入回数","セクション数","セクションあたりの文字数","LGTM数","コメント数"];
outcsv.push(columns);
//検索用パラメータ
var PAGE_MAX = 50;
for (PAGE = 1;PAGE<=PAGE_MAX;PAGE++){
//GETリクエスト
var PER_PAGE = 100;
let response = await axios.get("https://qiita.com/api/v2/items?page=" + PAGE + "&per_page=" + PER_PAGE+"&query="+encodeURIComponent(query));
for (i =0 ; i<PER_PAGE ; i++) {
//一レコードの情報格納list
let record = [];
//欲しい要素
var title_name = response["data"][i]["title"];
var title_len = response["data"][i]["title"].length;
var tag = response["data"][i]["tags"].length;
var body = response["data"][i]["rendered_body"].replace(/<("[^"]*"|'[^']*'|[^'">])*>/g,'').length;
var code = (response["data"][i]["rendered_body"].match(/code-frame/g)||[]).length;
var section = (response["data"][i]["rendered_body"].match(/<h1>|<h2>|<h3>/g)||[]).length;
var body_ratio = section == 0 ? body : Math.round(body / section); //section=0の人はsection=1とみなして計算
var like = response["data"][i]["likes_count"];
var comment = response["data"][i]["comments_count"];
//listに格納
record.push(title_name,title_len,tag,body,code,section,body_ratio,like,comment);
outcsv.push(record);
}
}
//csvとして出力
fs.writeFileSync("node.csv", csvStr(outcsv));
}
var query = "node.js";
getArticle(query);
こまごま
記事本文の文字数
var body = response["data"][i]["rendered_body"].replace(/<("[^"]*"|'[^']*'|[^'">])*>/g,'').length;
記事本文の文字数を数えるところはここ。
responseとして返ってくる記事本文にはhtmlタグがビシバシついているので、正規表現を利用してreplaceしています
(参考:https://qiita.com/miiitaka/items/793555b4ccb0259a4cb8 )
コード挿入回数
var code = (response["data"][i]["rendered_body"].match(/code-frame/g)||[]).length;
コードの挿入回数は、htmlタグの<div class = "code-frame">を取り出して回数を数えています。
コード部分を取り出すロジックがあまりに難しく、今回は断念・・・。
いつか挑戦したいところ。
セクションの数
var section = (response["data"][i]["rendered_body"].match(/<h1>|<h2>|<h3>/g)||[]).length;
var body_ratio = section == 0 ? body : Math.round(body / section); //section=0の人はsection=1とみなして計算
セクションはhtmlタグの<h1><h2><h3>を取り出して数えています。
一度も使っていない記事もあり、セクション当たりの文字数が無限大になってしまうようだったので、section=0の場合は本文文字数をそのままbody_ratioに代入するようにしています。
分析
import pandas as pd
//データの読み込み
df = pd.read_csv("node.csv")
//index番目の要素を取り出しヒストグラムを描画
df[df.columns[index]].hist(bins=棒の数,range=(図の左端,図の右端))
//各統計量の算出
df.describe()
//相関係数の算出
df.corr()
//ヒートマップの描画
import seaborn as sns
df_corr = df.corr()
sns.heatmap(df_corr, vmax=1, vmin=-1, center=0)
jupyter notebookで基本的な分析処理を行いました。
機械学習にぶち込んでみたい。
(参考:https://pythondatascience.plavox.info/matplotlib/%E3%83%92%E3%82%B9%E3%83%88%E3%82%B0%E3%83%A9%E3%83%A0 )
結果
タイトル名文字数
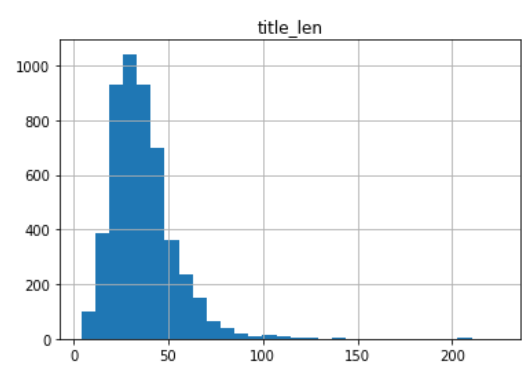
平均:36.3、中央値34.0、最小値4.0、最大値225.0
ざくっと35文字ぐらいが平均のようです。
「結局Qiita記事ってどれぐらい書けばいいのさ」で23文字なのでもう少し長いものが一般的のようです。
225文字ってすごいですね、めちゃめちゃ長い・・・。
タグ数
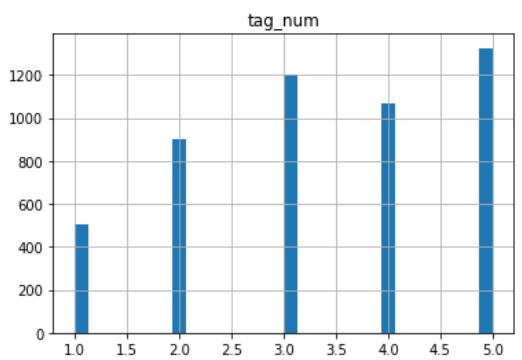
平均:3.4、中央値3.0、最小値1.0、最大値5.0
3個ぐらいが平均的。
これは何となく直感の通りですね。
記事本文
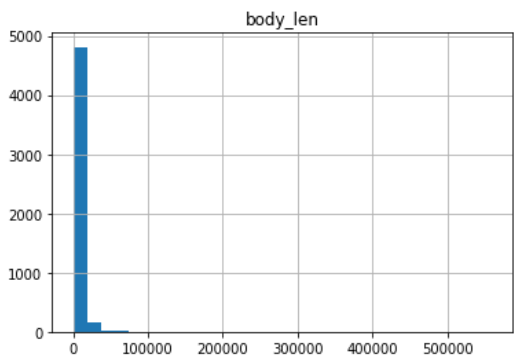
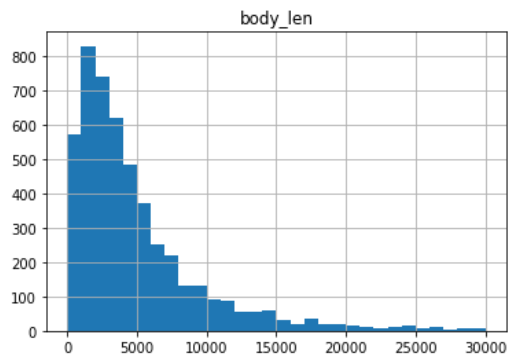
平均5700文字、中央値3540、最小値15.0、最大値559479
上の図が全体像、下の図が右端を30000とした図になっています。
平均が上に引っ張られているようなので、中央値3540文字ぐらいが一般的ということでしょうか。
56万文字の記事・・・作るのに何時間かかるんでしょうか・・・?
文字数がピンとこないので、記念すべきピタリ賞を引用しておきます。
・2000文字ピタリ賞
https://qiita.com/keenjoe007/items/c7068c58c63c17388f39
https://qiita.com/lelouch99v/items/3dc11676bb9c23457d41
・3000文字ピタリ賞
https://qiita.com/Ryusuke-Kawasaki/items/87dd43c176a489aa9fa5
・4000文字ピタリ賞
該当なし
・5000文字ピタリ賞
https://qiita.com/seki0809/items/5f831d63146e44dc106a
コード挿入回数
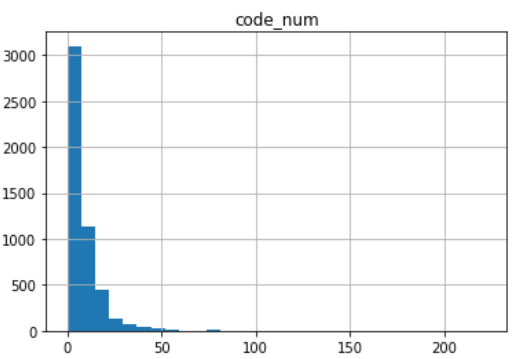
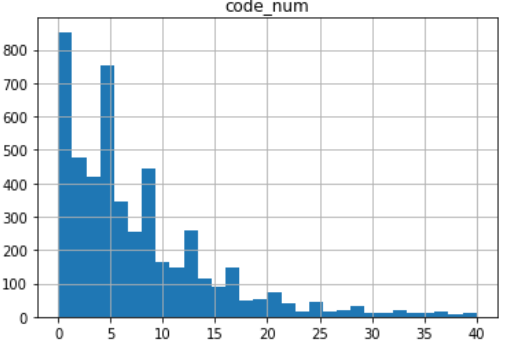
平均8.4、中央値5.0、最小値0、最大値222
こちらも同様に上の図が全体像、下の図が右端を40とした図になっています。
やや平均が上に引っ張られている感覚もしますので、5回ぐらいが一般的でしょうか。
次はコードの文字数についても分析してみたいところ。
セクション数
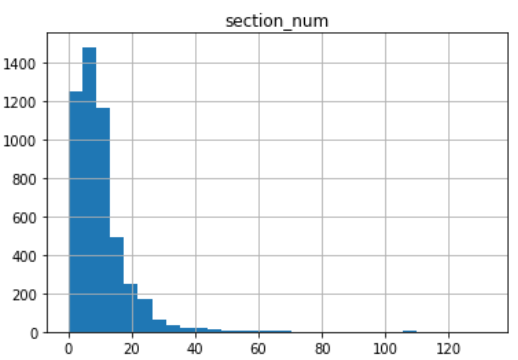
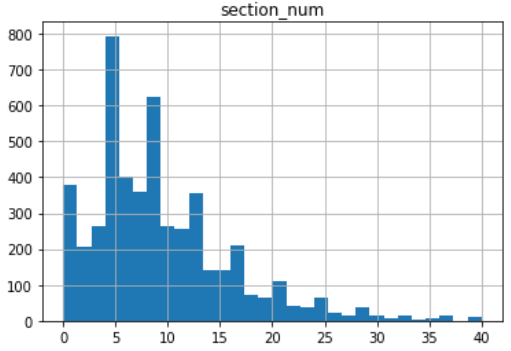
平均9.8、中央値8.0、最小値0、最大値132
こちらも同様に上の図が全体像、下の図が右端を40とした図になっています。
8セクション~9セクションが多いようですね。
h1,h2,h3の割合とかも別に議論してみたいところです。
セクション当たりの文字数
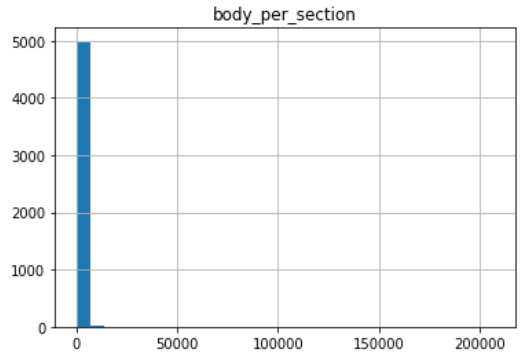
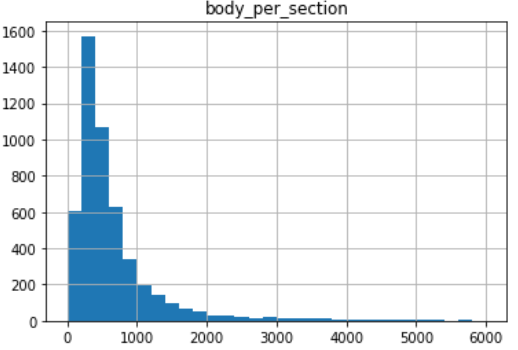
平均738、中央値448、最小値15.0、最大値207108
下の図は右端を6000としています。
450文字ぐらいで1セクションですかねぇ。
こんなにばらつきがあるのは少し予想外でした。
こちらもピンとこなかったのでピタリ賞を載せておきます(四捨五入しているので厳密ではありません)
・300文字ピタリ賞
https://qiita.com/deren2525/items/43386d5d5872967195d4
・400文字ピタリ賞
https://qiita.com/mejileben/items/cbe0608ee43aa1fab258
・500文字ピタリ賞
https://qiita.com/ryokkkke/items/602a35595090e2224fbd
LGTM数
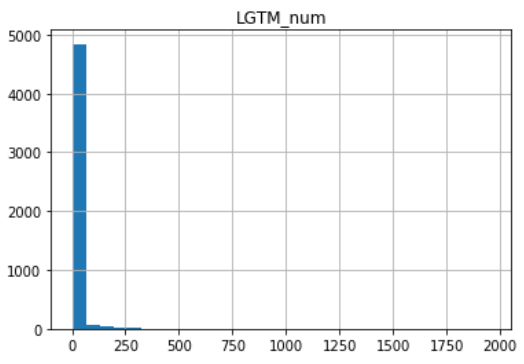
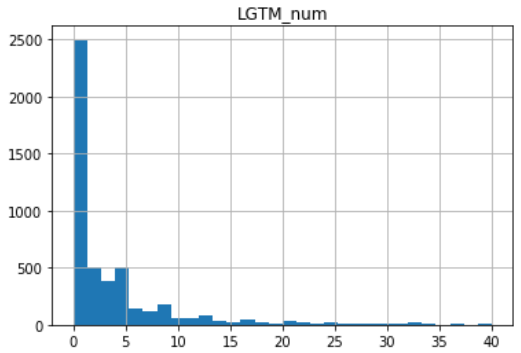
平均13.6、中央値2.0、最小値0.0、最大値1954
下の図は右端を40としています。
中央値2ってことはLGTMを3つもらえたら2500件の上に立てたということになりまするな。
SNS感覚でいいねを期待するのは辞めたほうがよさそうですね。
コメント数
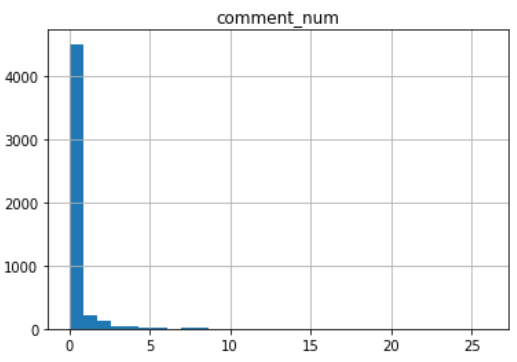
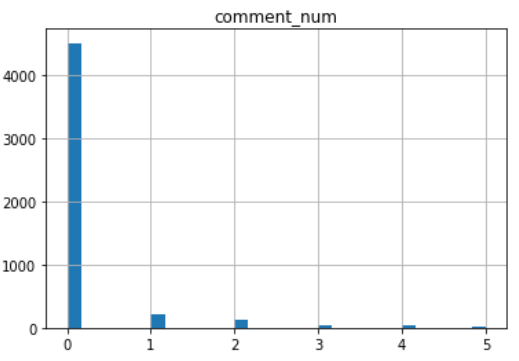
平均0.27、中央値0.0、最小値0.0、最大値26.0
下の図は右端を5にしています(bins=30にしてるので図が疎スギィ)
中央値0ということですが、75%地点も0でした。
コメントも期待するな!ということですね。
各変数間の相関
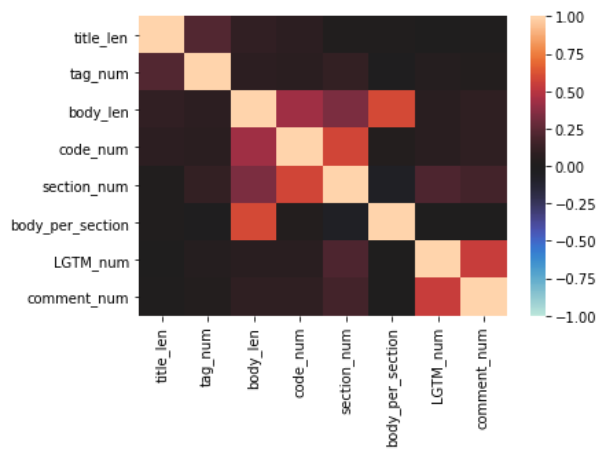
こちらは相関係数を描画したものになります。
本文文字数・コードの挿入回数・セクション数・セクション当たりの文字数に相関がややありそうなのは直感的に妥当そうですね。
LGTMの数とコメント数にやや相関がありそうなのも直観通りです。
ただLGTMの数と他の要素との相関を期待していたものの、どうもあまり相関はなさそう。
分量はLGTMにあまり関与していないということを示唆していますね、結局は内容ということか。
ただLGTM数=0のレコードが多いことが原因の可能性も捨てきれませんね。
結論
タイトル文字数:35文字ぐらい
タグ数:3つ
本文文字数:3500文字ぐらい
コード挿入回数:5回ぐらい
セクション数:8・9セクション
セクション当たりの文字数:450文字ぐらい
LGTM数:2回もらったら万歳
コメント数:1つもらったら万歳
やってみたいこと
本文文字数3500文字となりましたが、中にはコードも入っています。
どれぐらいの割合がコードなのかは気になるところですね。
予想ではやはりコードの部分の方が文字数多い気がしています。
今回はnode.jsをクエリにして記事検索をしましたが、他のクエリも試してみたいですね。
pythonをクエリにしたらどうなるか、音楽をクエリにしたらどうなるかなどなど。
クエリ間でも違いがでてきたら考察しがいがありそうです。
各種最大値をたたき出した記事
今回はnode.jsをクエリとして5000件しかとっていないため、全てのQiita記事における最大値ではありませんのでご承知おきください。
・タイトル文字数225文字(英語だから長いんですね!)
https://qiita.com/PINTO/items/865250ee23a15339d556
・本文文字数559479文字
https://qiita.com/K-Hama/items/5c1d4759fd5cbcf397b2
・コード挿入回数222回 セクション数132個
(文字数一位と思いきや18.2万文字。コードの分量でしょうか)
https://qiita.com/y-bash/items/09575a8e3d85656015bc
・LGTM数1954 コメント数26(純粋にすごい・・・!)
https://qiita.com/akaoni_sohei/items/186121bd9994197aab50
ちなみに
この記事の各パラメータは次の通りです。
タイトル文字数:23文字
タグ数:4
本文文字数:6129文字
コード挿入回数:8回
セクション数:23
セクション当たりの文字数:266文字
LGTM数:0
コメント数:0
ご参考までに!