Japanese English
- English -
1. Introduction
In this article, I'd like to share with you the quantization workflow I've been working on for six months. This is the output of know-how for converting Tensorflow checkpoints (.ckpt/.meta), FreezeGraph (.pb), saved_model (.pb), keras_model (.h5), Tensorflow.js models, and PyTorch checkpoints (.pth) into quantization models for Tensorflow Lite. Since Tensorflow was upgraded from v1.x to v2.x, it is necessary to take special steps to absorb the differences between the versions, and I often feel that there is a lack of material to start the conversion. Tensorflow, Tensorflow Lite, Keras, ONNX, PyTorch, and OpenVINO(OpenCV) are all used in combination.
I work hard on the quantization of the Neural Network every day. I'm using a lighter model to mass produce a quantized model with the goal of making fast reasoning without a GPU on edge terminals such as the RaspberryPi4. As an example, I did 8-bit integer quantization of the model, and the result of multistage inference between two models using only RaspberryPi4 CPU is shown in the following video. Two quantization models, Object Detection (MobileNetV2-SSDLite dm=0.5) and Head Pose Estimation, are run in series.
If you find the video too small to watch, **[PINTO_model_zoo](https://github.com/PINTO0309/PINTO_model_zoo#sample3---head-pose-estimation-multi-stage-inference-with-multi-model)** has an enlarged sample GIF, which can be viewed over Wi-Fi or wired.Head Pose Estimation の RaspberryPi4 CPU only + Tensorflow Lite + 4 Threads はかなりうまくいきました。 2段階推論にも関わらずサクサクの 13 FPS です。 発想力が足りないため見苦しいオッサンの顔でテストしてしまったことをお許しください。 あ〜、久々に達成感🤪https://t.co/hIwxA8eAZC
— Super PINTO (@PINTO03091) April 27, 2020
2. Table of contents
1. Introduction
2. Table of contents
3. Environment
4. Procedure
4-1. Check the model's INPUT and OUTPUT names and types, and change the batch size and type
4-1-1. In the case of a Tensorflow checkpoint
4-1-2. In the case of Tensorflow Freeze_Graph
4-1-3. In the case of Tensorflow saved_model
4-1-4. In the case of Tensorflow/Keras .h5/.json
4-2. Various quantization procedures
4-2-1. Quantization from a Tensorflow checkpoint (.ckpt)
4-2-1-1. Generating .meta from .index and .data-00000-of-00001
4-2-1-2. Generate Freeze_Graph from checkpoint (.meta)
4-2-1-3. Generate a saved_model from Freeze_Graph
4-2-1-4. Weight Quantization from saved_model (weight-only quantization)
4-2-1-5. Integer Quantization from saved_model (8-bit integer quantization)
4-2-1-6. saved_model to Full Integer Quantization (all 8-bit integer quantization)
4-2-1-7. Float16 Quantization from saved_model (Float16 quantization)
4-2-1-8. Full Integer Quantization to EdgeTPU convert
4-2-2. Quantization from a Tensorflow checkpoint (.meta)
4-2-3. Quantization from Tensorflow Freeze_Graph (.pb)
4-2-4. Quantization from Tensorflow saved_model (.pb)
4-2-5. Quantization from Tensorflow/Keras (.h5/.json)
4-2-5-1. Weight Quantization from .h5/.json (weight quantization)
4-2-5-2. Generating the calibration data set
4-2-5-3. Integer Quantization from .h5/.json (8-bit integer quantization)
4-2-5-4. Full Integer Quantization from .h5/.json (all 8-bit integer quantization)
4-2-5-5. Float16 Quantization from .h5/.json (Float16 quantization)
4-2-5-6. Full Integer Quantization to EdgeTPU convert
4-2-6. Quantization from a model for Tensorflow.js
4-2-6-1. Advance preparation
4-2-6-2. Generating a saved_model from Tensorflow.js
4-2-6-3. Import saved_model generated by Tensorflow v2.x into Tensorflow v1.x and process the input shape
4-2-6-4. Installation of Tensorflow v2.2.0
4-2-6-5. Weight Quantization from saved_model (Weight-only quantization)
4-2-6-6. Integer Quantization from saved_model (8-bit integer quantization)
4-2-6-7. Full Integer Quantization from saved_model (All 8-bit integer quantization)
4-2-6-8. Float16 Quantization from saved_model (Float16 quantization)
4-2-6-9. Full Integer Quantization to EdgeTPU convert
4-2-7. Quantize the model generated by the TensorFlow Object Detection API
4-2-7-1. Generating a .pb file with Post-Process
4-2-7-2. Weight Quantization from Freeze_Graph (Weight-only quantization)
4-2-7-3. Integer Quantization from Freeze_Graph (8-bit integer quantization)
4-2-7-4. Full Integer Quantization from Freeze_Graph (All 8-bit integer quantization)
4-2-7-5. Float16 Quantization from Freeze_Graph (Float16 quantization)
4-2-7-6. Full Integer Quantization to EdgeTPU convert
4-2-8. Quantize models containing operations that are not supported by Tensorflow Lite but are supported by Tensorflow
4-2-8-1. Generate Mask-RCNN Inception V2 .pb file
4-2-8-2. Weight Quantization of Mask-RCNN Inception V2 (Weight-only quantization)
4-2-8-3. Float16 Quantization in Mask-RCNN Inception V2 (Float16 quantization)
4-2-8-4. Running a model with Flex Delegate (Tensorflow Select Ops) enabled
4-2-9. Quantization from a model for PyTorch
4-2-9-1. Advance preparation (PyTorch->ONNX)
4-2-9-2. ONNX->Keras conversion by onnx2keras
4-2-9-3. Weight Quantization from saved_model (Weight-only quantization)
4-2-9-4. Integer Quantization from saved_model (8-bit integer quantization)
4-2-9-5. Full Integer Quantization from saved_model (All 8-bit integer quantization)
4-2-9-6. Float16 Quantization from saved_model (Float16 quantization)
4-2-9-7. Full Integer Quantization to EdgeTPU convert
4-2-10. Quantization of MediaPipe's model BlazeFace(.tflite)
4-2-10-1. Build flatc and download schema.fbs
4-2-10-2. Download MediaPipe's BlazeFace model (.tflite)
4-2-10-3. Converting BlazeFace(.tflite) to saved_model(.pb)
4-2-10-4. Weight Quantization from saved_model (weight-only quantization)
4-2-10-5. Integer Quantization from saved_model (8-bit integer quantization)
4-2-10-6. Full Integer Quantization from saved_model (All 8-bit integer quantization)
4-2-10-7. Float16 Quantization from saved_model (Float16 quantization)
4-2-10-8. Full Integer Quantization to EdgeTPU convert
4-3. Performance benchmarks for the quantization model (.tflite)
4-3-1. Building the TFLite Model Benchmark Tool
4-3-2. Options for the TFLite Model Benchmark Tool
4-3-3. Benchmark example of a model that includes only standard Tensorflow Lite operations (No XNNPACK, 4 Threads)
4-3-4. Benchmark example of a model that includes only standard Tensorflow Lite operations (XNNPACK available, 4 Threads)
4-3-5. Benchmark examples of models with non-standard Tensorflow Lite operations (Flex enabled, no XNNPACK, 4 Threads)
4-3-6. Benchmark examples of models with non-standard Tensorflow Lite operations (Flex enabled, with XNNPACK, 4 Threads)
4-3-7. Execution log sample of Benchmark_Tool
3. Environment
- Tensorflow-GPU v1.15.2
- Tensorflow v2.1.0, v2.2.0 or tf-nightly
- Accelerated and Tuned Python API Tensorflow Lite
- PyTorch
- Caffe
- OpenVINO 2020.2
- OpenCV 4.2
- onnx2keras
- Netron
- RaspberryPi4 + Ubuntu aarch64
4. Procedure
4-1. Check the model's INPUT and OUTPUT names and types, and change the batch size and type
This is the hardest and most time-consuming first step. The amount of effort depends on the pattern of the conversion.
4-1-1. In the case of a Tensorflow checkpoint
This pattern does not provide Freeze_Graph or saved_model. The quickest way to follow this pattern is to read or run the sample code for the Inference Test. Using Netron or Tensorflow's official visualization tools (Tensorboard or summarize_graph), it is not impossible to see the structure of the model, but the visualization fails because a lot of operations required for training are left in the file, or even if it is possible to visualize, the graph is too huge and it is difficult to find the INPUT and OUTPUT.
Now, let's check the INPUT/OUTPUT of the White-box-Cartoonization model that actually animates the live action as an example. In order to describe the various elements comprehensively, I have deliberately selected a high difficulty model with many moves this time. Note that you need to install Tensorflow v1.15.2 of the v1.x system to work on this model. If you have already installed Tensorflow v2.x, you need to uninstall it temporarily and install the v1.x system again. Alternatively, you can work in a Docker environment with Tensorflow already installed without polluting the environment.

Just in case, when I check the checkpoint that is offered. Yes, for some reason, kindly only the .meta file is not committed, is it? It's normal for people to lose motivation drastically at this point. That's right. If you started reading this article, you are not an ordinary person. Anyway, since it will not be a particular problem to proceed with the work, we will proceed as it is.
First of all, read cartoonize.py, the logic for the inference test. Then, let's look at the contents of the cartoonize() method, which is called right after main() at the beginning of the program. In the case of a simple, beginner-friendly test code, it only takes a minute to get to the INPUT definition part. Tensorflow's input operations are defined using placeholder. However, upon closer inspection, the "name" attribute is not defined. In this case, you can name your own name because it will make the subsequent conversion and confirmation work difficult. Also, the definition of the tensor is tainted with None. In the case of quantization, it is essential that the input resolution is fixed. Therefore, the input resolution is replaced by a fixed value. This time, I chose 720x720.
def cartoonize(load_folder, save_folder, model_path):
input_photo = tf.placeholder(tf.float32, [1, None, None, 3]) #<--- This is INPUT
network_out = network.unet_generator(input_photo)
final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3)
all_vars = tf.trainable_variables()
gene_vars = [var for var in all_vars if 'generator' in var.name]
saver = tf.train.Saver(var_list=gene_vars)
def cartoonize(load_folder, save_folder, model_path):
input_photo = tf.placeholder(tf.float32, [1, 720, 720, 3], name='input') #<--- This is INPUT
network_out = network.unet_generator(input_photo)
final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3)
all_vars = tf.trainable_variables()
gene_vars = [var for var in all_vars if 'generator' in var.name]
saver = tf.train.Saver(var_list=gene_vars)
The following is a note about placeholder in quantization.
1. N (batch size), H (height), W (width) and C (RGB channel) must all be fixed with integer values.
2. When defined by NCHW (channel-first), it should be defined or converted by NHWC (channel-last).
3. The type of placeholder should be tf.float32 (most models are defined in tf.uint8)
4. tf.cast operation does not support quantization operations and should be removed if possible.
By the way, the reason why it is 720x720 this time is because it is described in the logic of the preprocessing part of the image as follows, the operation to resize so that it does not go under 720 pixels in height and width. It seems that there is a limit to the size that can be specified depending on the model, so you have to read all the logic for inference tests or training logic. The White-box-Cartoonization gave an error and could not be deduced if the resolution was smaller than 720x720. If you don't want to read the logic, try repeatedly to see how small the resolution can be.
def resize_crop(image):
h, w, c = np.shape(image)
if min(h, w) > 720:
if h > w:
h, w = int(720*h/w), 720
else:
h, w = 720, int(720*w/h)
image = cv2.resize(image, (w, h),
interpolation=cv2.INTER_AREA)
h, w = (h//8)*8, (w//8)*8
image = image[:h, :w, :]
return image
Since many of the published models deal with images, a placeholder is defined for a uint8 type that takes an RGB value of 0-255, as shown below. In most cases, the next step in placeholder is to convert the type to float32 with a tf.cast operation. As mentioned above, tf.cast is an error when quantizing, so you should remove it at this time. When you actually run the inference, the image data read by OpenCV or Pillow will be of type uint8, so you need to cast it to type Float32 just before the business logic hands over the image to Tensorflow.
input_photo = tf.placeholder(tf.uint8, [1, 720, 720, 3], name='input')
casted_photo = tf.cast(input_photo, tf.float32)
input_photo = tf.placeholder(tf.float32, [1, 720, 720, 3], name='input')
Now let's look up the name of OUTPUT. The inference test logic of this model White-box-Cartoonization is so simple that the final OUTPUT was defined just below the INPUT definition line. The name of the variable is final_out, politely. There are two ways to look up the name of an OUTPUT without using Netron, summarize_graph or Tensorboard.
1. Digging deeper into the program and visually identifying the end of the model structure
2. Anyway, run a test run and find out the name of the final operation in the debug print
Since I'm a person who loves to cut corners, I took the method of 2.
def cartoonize(load_folder, save_folder, model_path):
input_photo = tf.placeholder(tf.float32, [1, 720, 720, 3], name='input')
network_out = network.unet_generator(input_photo)
final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3) #<--- Here's an OUTPUT
print("input_photo.name =", input_photo.name) #<--- Added one line for debug printing of INPUT name.
print("input_photo.shape =", input_photo.shape) #<--- Added one more line for debug printing of INPUT shapes.
print("final_out.name =", final_out.name) #<--- Added one line for the debug print of OUTPUT name.
print("final_out.shape =", final_out.shape) #<--- Added one line for debug printing of OUTPUT shape.
all_vars = tf.trainable_variables()
gene_vars = [var for var in all_vars if 'generator' in var.name]
saver = tf.train.Saver(var_list=gene_vars)
When I ran the program for the inference test, the names and shapes of the INPUT and OUTPUT are output in the debug print I added earlier. Apparently, the name of the OUTPUT is add_1:0. Also, it seems that the name and shape of placeholder, which I modified earlier, are correctly reflected.
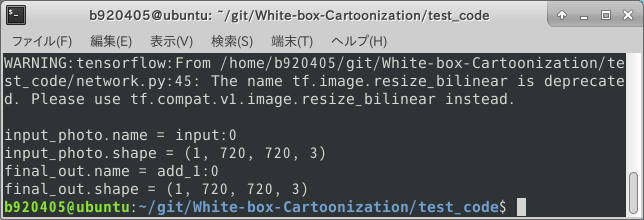
This concludes the procedure for checking INPUT/OUTPUT names in a checkpoint model. I'll explain how to generate .meta, and I'll explain how to generate Freeze_Graph and saved_model in the steps that follow.
4-1-2. In the case of Tensorflow Freeze_Graph
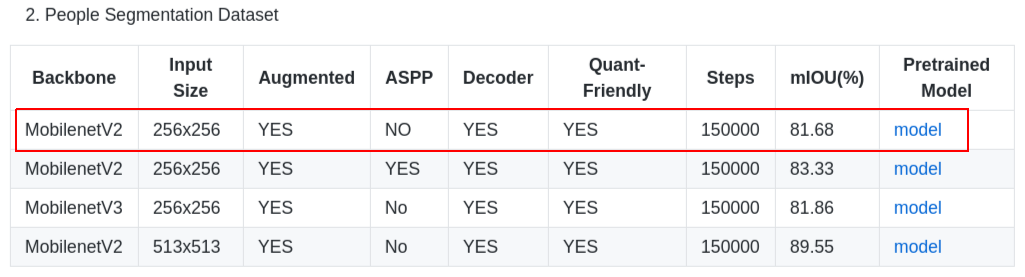
This is a working pattern when the model is provided in Freeze_Graph (.pb) format. It is very easy to identify the name of INPUT/OUTPUT in this case. Let's check the model of Semantic Segmentation Mobile-DeeplabV3-plus (MobileNetV2) for example.

First, download the Freeze_Graph (.pb) file from the above repository. The only thing to note here is that models with special treatment such as ASPP will fail to quantize, so you should only get a model with a simple structure as possible.
When using the command line to download materials from Google Drive, it is necessary to bypass the confirmation dialog, so you can download by executing the 3-line command as shown below.
$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1VF5yMz_tIkTOVfgmIgg7tPAJJEEcZ49B" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1VF5yMz_tIkTOVfgmIgg7tPAJJEEcZ49B" -o deeplab_v3_plus_mnv2_decoder_256.pb
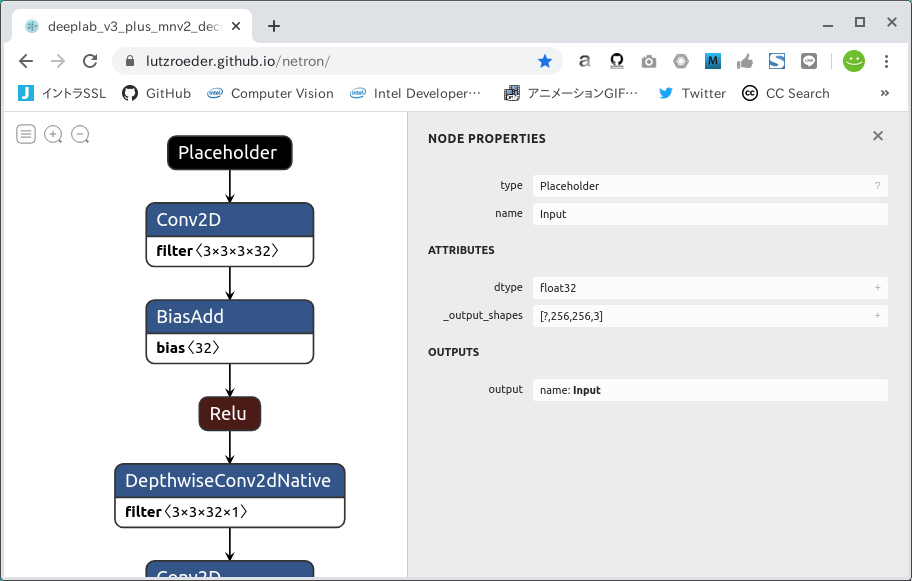
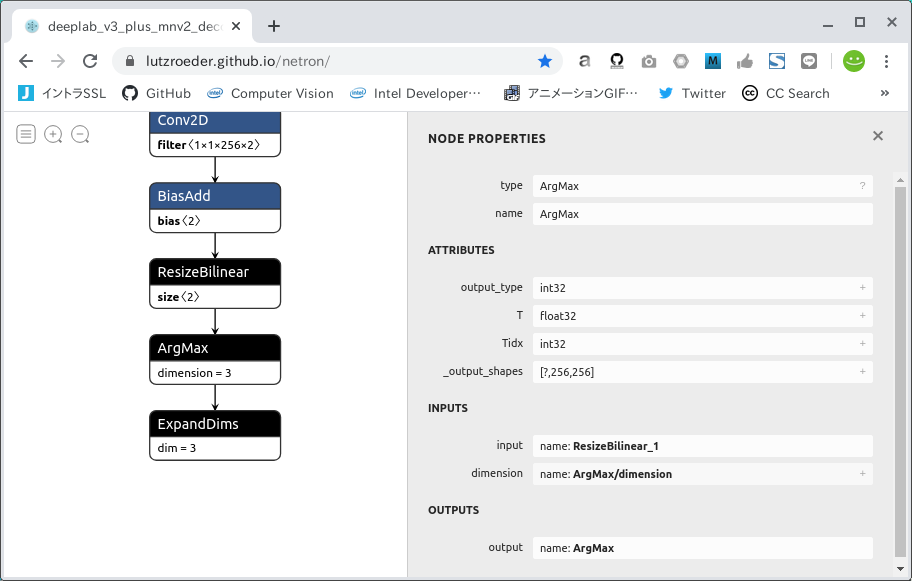
Check the structure of the model you have downloaded. There is a super useful site called Netron, which you can access first.
https://lutzroeder.github.io/netron/

"Open Model..." button and open the file deeplab_v3_plus_mnv2_decoder_256.pb which was downloaded earlier. The names of INPUT/OUTPUT are immediately known. INPUT is Input, shape and type is Float32 [?, 256, 256, 3], OUTPUT is ArgMax, shape and type is Float32 [?, 256, 256, 3], OUTPUT is ArgMax, and the shape and type is Float32 [?, 256, 256]. At first glance, you may think that ExpandDims is appropriate for the final OUTPUT, but in fact, it's not a problem if you select ArgMax, which is almost the same as Semantic Segmentation's model. Also, the ? part of the shape is synonymous with None in variable batches. However, this is not a problem for the quantization operation without immobilization. It is automatically converted to 1 when performing the quantization of the subsequent work.
Now, the work up to this point has been too easy, hasn't it? Let's increase the level of difficulty a bit more. Next, let's try the following Python implementation of Tensorflow.js, based on Posenet v1.
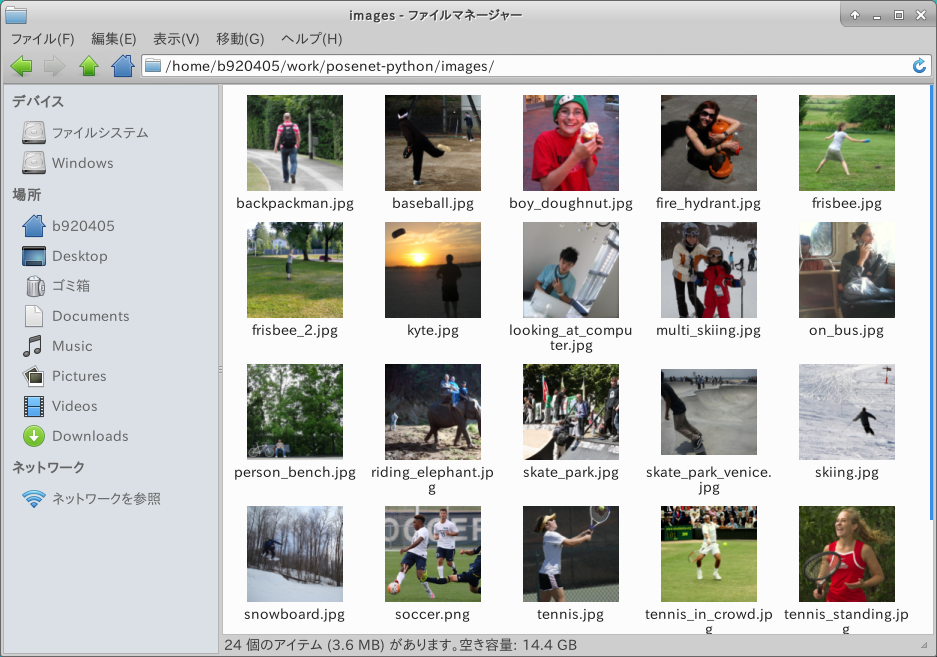
First, Clone the repository to get the Freeze_Graph and issue the following command. The argument of --image_dir can be any folder path where there is a human image file. I created a folder called images and put 24 images of people in it.
Convert a Tensorflow.js model to a Tensorflow model. The following processes require the introduction of Tensorflow v1.15.2.
$ sudo pip3 uninstall tensorboard-plugin-wit tb-nightly \
tf-estimator-nightly tensorflow-gpu \
tensorflow tf-nightly tensorflow_estimator
$ sudo pip3 install tensorflow-gpu==1.15.2
$ git clone https://github.com/rwightman/posenet-python.git
$ cd posenet-python
$ python3 image_demo.py \
--model 101 \
--image_dir ./images \
--output_dir ./output
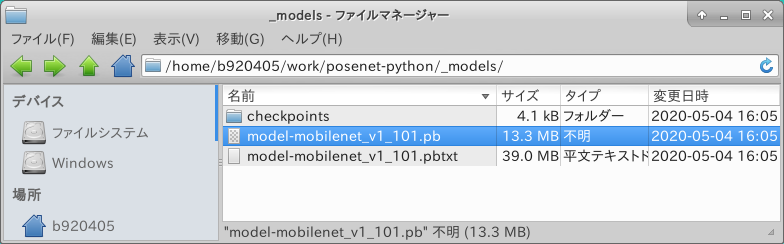
When the process is finished, three types of checkpoints, .pb and .pbtxt will be created under the folder _models.
It's based on MobileNetV1, so the accuracy is not very good. As an aside, the repository at the URL linked at the top of this article has already committed the high-precision, slow Posenet v2 quantization model, converted on a ResNet50 basis.

The figure below shows the results of the Posenet v2 inference to the same image from the ResNet50 backbone version. It's hard to tell, but the accuracy seems to have improved slightly.

Now, let's visualize the .pb file using Netron as before. Freeze_Graph (.pb) has a name, type and shape name=image Float32 [1, ?, ?, 3] for name, type and shape. As it is, the quantization operation will fail. I will now explain how to convert the INPUT shape of a model whose H (height) and W (width) are 'None' with Freeze_Graph. Note that this procedure can only be performed with Tensorflow v1.x and does not work equally well for all models.
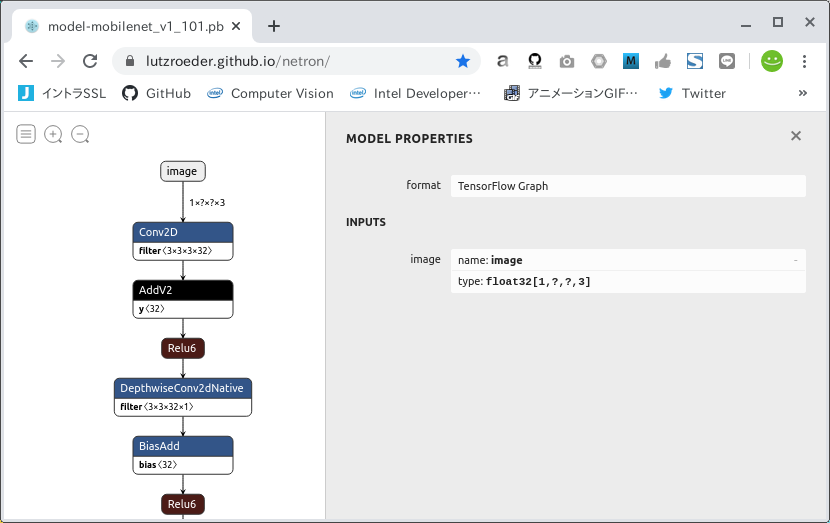
This section describes a program to convert the shape of the INPUT of Freeze_Graph. The general flow is as follows.
1. Defines a placeholder with a shape to be set after conversion.
2. Load a Freeze_Graph that you already have at hand.
3. Import the placeholder defined in 1.
4. ( Check the debug print to make sure placholder is captured correctly )
5. Remove all unnecessary Node with TransformGraph, a Tensorflow v1.x-based tool.
6. Output a processed Freeze_Graph to a .pb file.
### tensorflow-gpu==1.15.2
import tensorflow as tf
from tensorflow.tools.graph_transforms import TransformGraph
with tf.compat.v1.Session() as sess:
# shape=[1, ?, ?, 3] -> shape=[1, 513, 513, 3]
# name='image' specifies the placeholder name of the converted model
inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 513, 513, 3], name='image')
with tf.io.gfile.GFile('./model-mobilenet_v1_101.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
# 'image:0' specifies the placeholder name of the model before conversion
tf.graph_util.import_graph_def(graph_def, input_map={'image:0': inputs}, name='')
print([n for n in tf.compat.v1.get_default_graph().as_graph_def().node if n.name == 'image'])
# Delete Placeholder "image" before conversion
# see: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms
# TransformGraph(
# graph_def(),
# input_op_name,
# output_op_names,
# conversion options
# )
optimized_graph_def = TransformGraph(
tf.compat.v1.get_default_graph().as_graph_def(),
'image',
['heatmap','offset_2','displacement_fwd_2','displacement_bwd_2'],
['strip_unused_nodes(type=float, shape="1,513,513,3")'])
tf.io.write_graph(optimized_graph_def, './', 'model-mobilenet_v1_101_513.pb', as_text=False)
See Graph Transform Tool for specifications and usage of TransformGraph. Execute the created INPUT shape conversion program. The shape of the INPUT of the Freeze_Graph model-mobilenet_v1_101_513.pb generated after program execution is assumed to be [1, 513, 513, 3]. If you want to convert it to a slightly smaller shape, just change it like shape=[1, 257, 257, 3].
$ python3 replacement_of_input_placeholder_float32_mobilenet.py
Check the shape of the generated model-mobilenet_v1_101_513.pb with Netron.
This is the end of the procedure to find INPUT/OUTPUT names in a Freeze_Graph model and to convert a Freeze_Graph shape.
4-1-3. In the case of Tensorflow saved_model
If the model is provided in the saved_model (.pb) format, this is the pattern. Again, it is very easy to identify the name of the INPUT/OUTPUT. So far, however, I don't see many examples of pre-trained models being offered in this format. This time, let's check the names of INPUT and OUTPUT based on the following Head Pose Estimation.
First, please clone the repository.
$ git clone https://github.com/yinguobing/head-pose-estimation.git
$ cd head-pose-estimation/assets
If you display a saved_model with a very large number of operators with the Web version of Netron, a warning is displayed as shown below, and it may take more than 5 minutes to render.
In the case of the proprietary version, it is displayed as shown below.
So, if you want to check saved_model format INPUT/OUTPUT easily, you can use standard command saved_model_cli. Since there is a folder called pose_model under the assets folder and saved_model.pb is deployed underneath it, run an analysis command on the pose_model folder directly underneath the assets folder.
$ saved_model_cli show --dir pose_model --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['predict']:
The given SavedModel SignatureDef contains the following input(s):
inputs['image'] tensor_info:
dtype: DT_UINT8
shape: (-1, -1, -1, 3)
name: image_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['output'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 136)
name: layer6/final_dense:0
Method name is: tensorflow/serving/predict
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['image'] tensor_info:
dtype: DT_UINT8
shape: (-1, -1, -1, 3)
name: image_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['output'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 136)
name: layer6/final_dense:0
Method name is: tensorflow/serving/predict
Looking at the definition of signature_def['serving_default'], the INPUT is defined as image Uint8[-1, -1, -1, 3] and the OUTPUT as output Float32[-1, 136]. As in the previous example, N (batch size), H (height), and W (width) of the INPUT are set to -1, so the signature needs to be rewritten. (-1 is synonymous with ? and None). Rather than my half-hearted explanation, the following article Summary of SavedModel - Qiita - t_shimmura is very helpful, so please see it. In addition, if you want to talk only about Head Pose Estimation, the training script and the export script to saved_model are described in the following repository.
For saved_model, we have only described how to use the saved_model_cli command to check the structure. I'll touch on this later in the process along with the checkpoint -> saved_model or Freeze_Graph -> saved_model conversion scripts.
4-1-4. In the case of Tensorflow/Keras .h5/.json
If the model is provided in Keras (.h5/.json) format, this is the pattern.
For example, to check the names of INPUTs and OUTPUTs based on the above repository, you will need a .json file after the training as shown below.
model = Model(inputs=xxxx,outputs=yyyy)
# model save
model_json = model.to_json()
open(model_path + 'model.json', 'w').write(model_json)
model.save_weights(model_path + 'weights.h5')
If you open the above example model.json with Netron, you can visualize it as shown below.
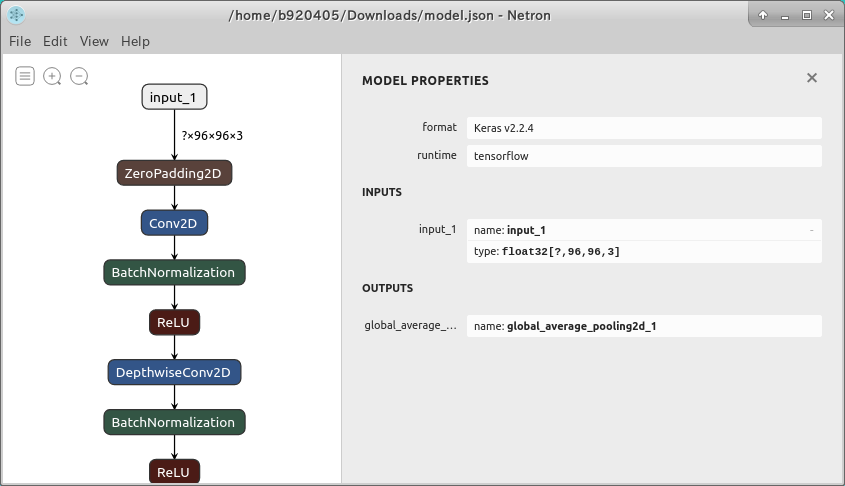
However, the syntax of Keras is very simple, so it would be faster to look directly at the program structure of the model.
If you want to change the shape of the input tensor, the QA of Keras -Transfer Learning - Change Input Tensor Shape is helpful. The easiest way seems to be to redefine an empty model with only a different INPUT size and re-transfer only the weights.
inputs = Input((None, None, 3))
.....
model = Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='mean_squared_error')
model.load_weights('my_model_name.h5')
inputs2 = Input((512, 512, 3))
....
model2 = Model(inputs=[inputs2], outputs=[outputs])
model2.compile(optimizer='adam', loss='mean_squared_error')
model2.set_weights(model.get_weights())
4-2. Various quantization procedures
In this section I will try to quantize the various models into various patterns. In order to adapt the procedure to any situation, please be forgiven that there is some duplication of content in each section, and that some procedures are not necessary for quantization at the shortest distance.
4-2-1. Quantization from a Tensorflow checkpoint (.ckpt)
Let's quantize a model that animates a live action, White-box-Cartoonization, as an example. As described in 4-1-1. In the case of a Tensorflow checkpoint, the trained checkpoint in this model is released in a special state where only .meta does not exist. There are three normal checkpoints, .index .data-00000-of-00001 .meta, but this one is missing one file. I'm going to explain this procedure from the point of view of creating .meta, but this is only under the special circumstance that .meta doesn't exist, and it's not necessary unless you have to. Please take this as an example only. Of the steps described below, 4-2-1-2. Generate Freeze_Graph from checkpoint (.meta) is performed with Tensorflow v1.15.2 due to model constraints, and 4-2-1-3. Generate a saved_model from Freeze_Graph to 4-2-1-7. Float16 Quantization from saved_model (Float16 quantization) is performed with the latest Tensorflow v1.2.2.x or tf-nightly to support the latest operators and avoid bugs in Tensorflow itself.
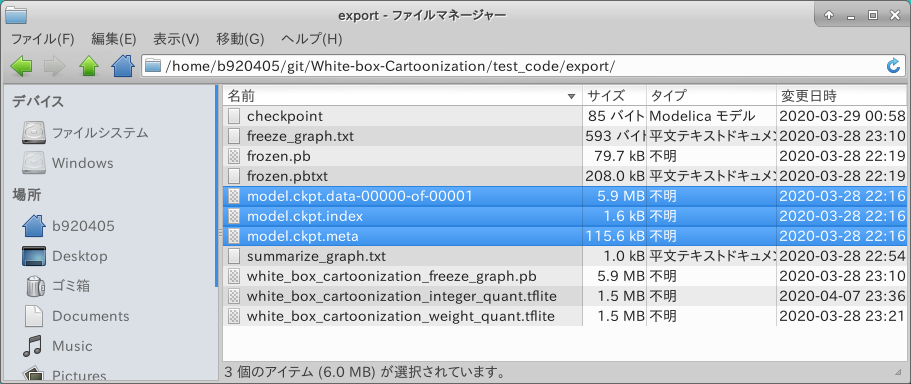
4-2-1-1. Generating .meta from .index and .data-00000-of-00001
.index .data-00000-of-00001 .meta This step is not necessary if three types of checkpoints are provided: .index .data-00000-of-00001 .meta This section describes how to create .meta from .index and .data-00000-of-00001. I use the test code of White-box-Cartoonization as much as possible. Here's how the modified logic works
1. checkpoint Create a folder export for temporary output.
2. Build a model.
3. Debug printing the name and shape of INPUT/OUTPUT.
4. Restore the checkpoint.
5. Immediately save to the export folder.
def cartoonize(load_folder, save_folder, model_path):
input_photo = tf.placeholder(tf.float32, [1, None, None, 3])
network_out = network.unet_generator(input_photo)
final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3)
all_vars = tf.trainable_variables()
gene_vars = [var for var in all_vars if 'generator' in var.name]
saver = tf.train.Saver(var_list=gene_vars)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
sess.run(tf.global_variables_initializer())
saver.restore(sess, tf.train.latest_checkpoint(model_path))
def cartoonize(load_folder, save_folder, model_path):
import sys
import shutil
shutil.rmtree('./export', ignore_errors=True)
input_photo = tf.placeholder(tf.float32, [1, 720, 720, 3], name='input')
network_out = network.unet_generator(input_photo)
final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3)
print("input_photo.name =", input_photo.name)
print("input_photo.shape =", input_photo.shape)
print("final_out.name =", final_out.name)
print("final_out.shape =", final_out.shape)
all_vars = tf.trainable_variables()
gene_vars = [var for var in all_vars if 'generator' in var.name]
saver = tf.train.Saver(var_list=gene_vars)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
sess.run(tf.global_variables_initializer())
saver.restore(sess, tf.train.latest_checkpoint(model_path))
saver.save(sess, './export/model.ckpt')
sys.exit(0)
Let's run it.
$ python3 cartoonize.py
Three types of checkpoints, .index .data-00000-of-00001 .meta, have been successfully generated.
- Go to Table of contents -
4-2-1-2. Generate Freeze_Graph from checkpoint (.meta)
Now let's create a Freeze_Graph from a checkpoint. Let's take the .meta file we just created and create a Freeze_Graph. Here is a sample of the modified cartoonize method. However, it's OK to cut and run the new part of the file in a separate .py file.
def cartoonize(load_folder, save_folder, model_path):
import sys
#import shutil
#shutil.rmtree('./export', ignore_errors=True)
#input_photo = tf.placeholder(tf.float32, [1, 720, 720, 3], name='input')
#network_out = network.unet_generator(input_photo)
#final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3)
#print("input_photo.name =", input_photo.name)
#print("input_photo.shape =", input_photo.shape)
#print("final_out.name =", final_out.name)
#print("final_out.shape =", final_out.shape)
#all_vars = tf.trainable_variables()
#gene_vars = [var for var in all_vars if 'generator' in var.name]
#saver = tf.train.Saver(var_list=gene_vars)
#config = tf.ConfigProto()
#config.gpu_options.allow_growth = True
#sess = tf.Session(config=config)
#sess.run(tf.global_variables_initializer())
#saver.restore(sess, tf.train.latest_checkpoint(model_path))
#saver.save(sess, './export/model.ckpt')
#sys.exit(0)
graph = tf.get_default_graph()
sess = tf.Session()
saver = tf.train.import_meta_graph('./export/model.ckpt.meta')
saver.restore(sess, './export/model.ckpt')
tf.train.write_graph(sess.graph_def, './export', 'white_box_cartoonization_freeze_graph.pbtxt', as_text=True)
tf.train.write_graph(sess.graph_def, './export', 'white_box_cartoonization_freeze_graph.pb', as_text=False)
sys.exit(0)
Let's run it.
$ python3 cartoonize.py
The white_box_cartoonization_freeze_graph.pb has been successfully generated.
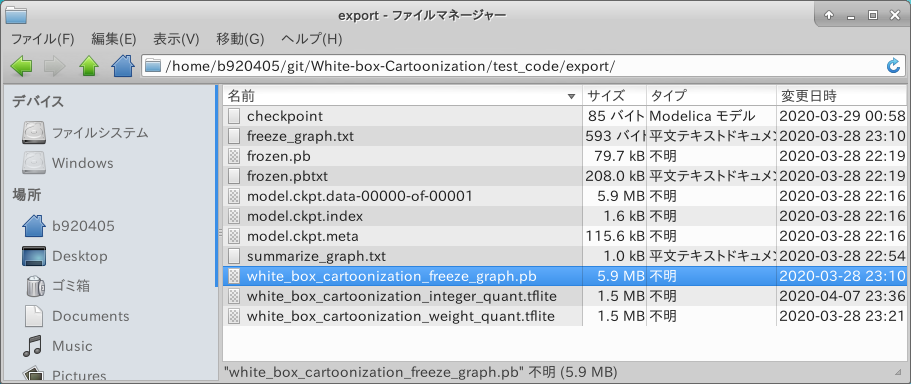
Checking the structure with Netron doesn't seem to be a problem.
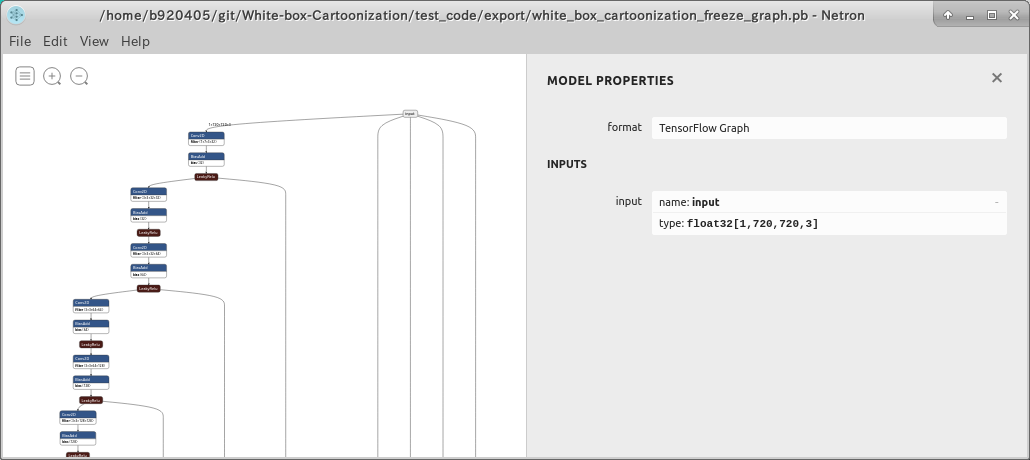
4-2-1-3. Generate a saved_model from Freeze_Graph
Generate a saved_model from Freeze_Graph. It is written to work for both Tensorflow v1.x and Tensorflow v2.x. For input_name= and outputs=, specify the names of INPUT and OUTPUT specified in 4-1-1. In the case of a Tensorflow checkpoint. It can probably be used for any model, as long as you know the names of the INPUT and OUTPUT, and have Freeze_Graph at hand.
import tensorflow as tf
import os
import shutil
from tensorflow.python import ops
def get_graph_def_from_file(graph_filepath):
tf.compat.v1.reset_default_graph()
with ops.Graph().as_default():
with tf.compat.v1.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
return graph_def
def convert_graph_def_to_saved_model(export_dir, graph_filepath, input_name, outputs):
graph_def = get_graph_def_from_file(graph_filepath)
with tf.compat.v1.Session(graph=tf.Graph()) as session:
tf.import_graph_def(graph_def, name='')
tf.compat.v1.saved_model.simple_save(
session,
export_dir,# change input_image to node.name if you know the name
inputs={input_name: session.graph.get_tensor_by_name('{}:0'.format(node.name))
for node in graph_def.node if node.op=='Placeholder'},
outputs={t.rstrip(":0"):session.graph.get_tensor_by_name(t) for t in outputs}
)
print('Graph converted to SavedModel!')
tf.compat.v1.enable_eager_execution()
input_name="input"
outputs = ['add_1:0']
shutil.rmtree('./saved_model', ignore_errors=True)
convert_graph_def_to_saved_model('./saved_model', './white_box_cartoonization_freeze_graph.pb', input_name, outputs)
"""
$ saved_model_cli show --dir saved_model --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['input'] tensor_info:
dtype: DT_FLOAT
shape: (1, 720, 720, 3)
name: input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['add_1'] tensor_info:
dtype: DT_FLOAT
shape: (1, 720, 720, 3)
name: add_1:0
Method name is: tensorflow/serving/predict
"""
Let's run it.
$ python3 freeze_the_saved_model.py
It was successfully generated.
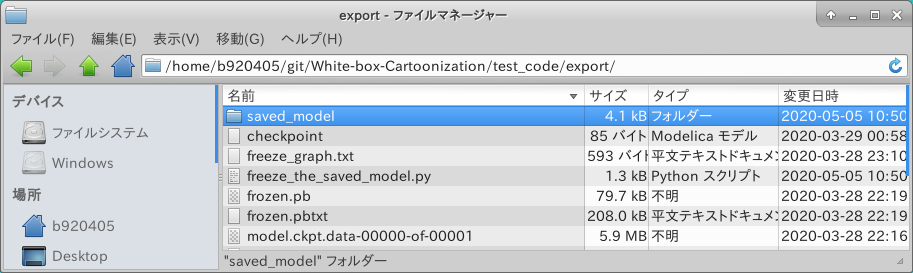
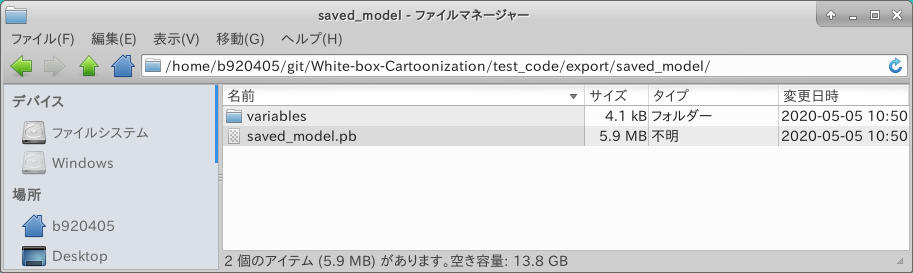
Let's check the structure of saved_model. It seems to have worked out well.
$ saved_model_cli show --dir saved_model --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['input'] tensor_info:
dtype: DT_FLOAT
shape: (1, 720, 720, 3)
name: input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['add_1'] tensor_info:
dtype: DT_FLOAT
shape: (1, 720, 720, 3)
name: add_1:0
Method name is: tensorflow/serving/predict
4-2-1-4. Weight Quantization from saved_model (weight-only quantization)
Finally, the main topic is quantization. Create a program that does Weight Quantization from saved_model and generates a .tflite that can work with Tensorflow Lite.
import tensorflow as tf
tf.compat.v1.enable_eager_execution()
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./saved_model')
converter.experimental_new_converter = True #<--- Not necessary if you are using Tensorflow v2.2.x or later.
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('./white_box_cartoonization_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - white_box_cartoonization_weight_quant.tflite")
Execute it.
$ python3 weight_quantization.py
It's been generated safely. The file size has been reduced to a quarter of the original Freeze_Graph. It is important to note at this point that even if the file size is reduced by a quarter, it does not mean that the inference performance is four times faster. You need to understand that quantization of weights only means mere compression of file size. It depends on the environment in which the inference is performed, but as an example, if you want to improve performance when performing inference on the RaspberryPi4 CPU, you need to perform 4-2-1-5. Integer Quantization from saved_model (8-bit integer quantization) in the next section.

4-2-1-5. Integer Quantization from saved_model (8-bit integer quantization)
Create a program that does a Integer Quantization from a saved_model and generates a .tflite that can work with Tensorflow Lite. In case of Integer Quantization, it is necessary to give the image data for calibration in the process of converting the number of Float32 to UInt8. If possible, it would be better to use the images used during training, but this time I used a dataset that I can easily prepare on hand. If you write tfds.load(...), Google deploys datasets for training in Tensorflow Datasets on the cloud, so it will be downloaded automatically. You only need to do the download once, and I recommend that you change download=True to download=False for the second and subsequent runs. The sample logic below is set to automatically download the Pascal-VOC 2007 image dataset, but if you want to use other image datasets, you can find them in the left pane of the Tensorflow Datasets Catalog page. Most image datasets are available, but some may need to be downloaded manually due to copyright or sensitive images. (e.g., a dataset of face images). Among the various quantization operations, this Integer Quantization shows the best performance when performing inference on the RaspberryPi4 CPU alone. If you are interested, please click here 3. TFLite Model Benchmark. Here are the benchmark results for Ubuntu 19.10 aarch64 on RaspberryPi4 using the Integer Quantization model. Also, the benchmark results of Post-training quantization with TF2.0 Keras - nb.o's Diary - Nextremer_nb_o here are very helpful. Very importantly, since the number of operations that support quantization is increasing all the time, I recommend using the latest Tensorflow (Tensorflow v2.2.x / tf-nightly) for Integer Quantization and the Full Integer Quantization operations described below.
The flow of processing in representative_dataset_gen() is as follows.
1. Convert the data acquired by Tensorflow Datasets to Numpy
2. Resize the image size to INPUT size 720x720
3. Normalize image data to the range from -1 to 1
4. To match the shape of the INPUT [1, 720, 720, 3], add one dimension for batch size to the beginning of the image data in [720, 720, 3]
5. Return one image
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (720, 720))
image = image / 127.5 - 1
image = image[np.newaxis,:,:,:]
yield [image]
tf.compat.v1.enable_eager_execution()
raw_test_data, info = tfds.load(name="voc/2007",
with_info=True,
split="validation",
data_dir="~/TFDS",
download=True)
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./saved_model')
converter.experimental_new_converter = True #<--- Not necessary if you are using Tensorflow v2.2.x or later.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./white_box_cartoonization_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - white_box_cartoonization_integer_quant.tflite")
Let's run it.
$ python3 integer_quantization.py
It's been generated safely.
4-2-1-6. saved_model to Full Integer Quantization (all 8-bit integer quantization)
The notes and logic structure are almost the same as Integer Quantization and are omitted. Now let's write a program to execute Full Integer Quantization.
※ Unfortunately, as of 05/05/2020, the operation Div in the model of White-box-Cartoonization does not support Full Integer Quantization, so the script below will abort. However, other models that do not include Div work fine, so I'll describe the logic on the premise that it can be diverted to other models.
The .tflite file generated by Full Integer Quantization is the file you will need to generate the model for EdgeTPU. The performance of CPU inference on RaspberryPi4 is exactly the same as the Integer Quantization model.
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (720, 720))
image = image / 127.5 - 1
image = image[np.newaxis,:,:,:]
yield [image]
tf.compat.v1.enable_eager_execution()
raw_test_data, info = tfds.load(name="voc/2007",
with_info=True,
split="validation",
data_dir="~/TFDS",
download=False)
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./saved_model')
converter.experimental_new_converter = True #<--- Not necessary if you are using Tensorflow v2.2.x or later.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./white_box_cartoonization_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Full Integer Quantization complete! - white_box_cartoonization_full_integer_quant.tflite")
4-2-1-7. Float16 Quantization from saved_model (Float16 quantization)
Generates a GPU-optimized Float16 quantization model suitable for operations. The program is described below.
import tensorflow as tf
tf.compat.v1.enable_eager_execution()
# Float16 Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./saved_model')
converter.experimental_new_converter = True #<--- Not necessary if you are using Tensorflow v2.2.x or later.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('./white_box_cartoonization_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Float16 Quantization complete! - white_box_cartoonization_float16_quant.tflite")
Execute it.
$ python3 float16_quantization.py
It seems to have been generated safely.
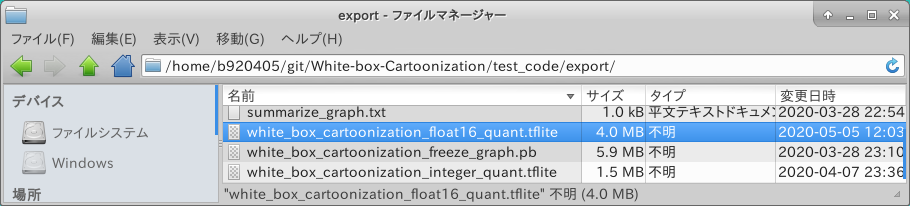
4-2-1-8. Full Integer Quantization to EdgeTPU convert
These are the steps that can be taken if Full Integer Quantization is successful. Perform model compilation for use with Google Coral EdgeTPU. It will abort if it contains unsupported or poorly implemented operations. It is my opinion, but the compiler is still unstable.
Edge TPU Compiler can be deployed according to Edge TPU Compiler here.
$ edgetpu_compiler -s white_box_cartoonization_full_integer_quant.tflite
Incidentally, the latest compiler 2.1.302470888 is said to support efficient reasoning on multi-TPU. Currently, only C++ APIs are provided, which is a burden for me as a Python user. I've owned three of them...![]()

@iwatake2222 was one of the first to implement Pipeline at this repository.

- Go to Table of contents -
4-2-2. Quantization from a Tensorflow checkpoint (.meta)
Same as 4-2-1-2. Generate Freeze_Graph from checkpoint (.meta) to 4-2-1-8. Full Integer Quantization to EdgeTPU convert. Change the image dataset used for calibration according to the characteristics of the model.
4-2-3. Quantization from Tensorflow Freeze_Graph (.pb)
4-2-1-3. Generate a saved_model from Freeze_Graph to 4-2-1-8. Full Integer Quantization to EdgeTPU convert. Change the image dataset used for calibration according to the characteristics of the model.
4-2-4. Quantization from Tensorflow saved_model (.pb)
4-2-1-4. Weight Quantization from saved_model (weight-only quantization) to 4-2-1-8. Full Integer Quantization to EdgeTPU convert Change the image dataset used for calibration according to the characteristics of the model.
4-2-5. Quantization from Tensorflow/Keras (.h5/.json)
If the model is provided in Keras' .h5 and .json formats, this is the pattern. This time we'll use Faster-Grad-CAM as an example. The older Tensorflows up to Tensorflow v1.x and Tensorflow v2.1 seem to have an OOM bug (Out of Memory) in Keras quantization, so it is recommended to introduce Tensorflow v2.2.0 or tf-nightly to work with them.
Thankfully, all the material needed for quantization is committed, except for the image dataset needed for calibration.
I will use it to generate the missing calibration dataset.
4-2-5-1. Weight Quantization from .h5/.json (weight quantization)
You can do Weight Quantization immediately because the material is available. First, we clone the repository.
$ git clone https://github.com/shinmura0/Faster-Grad-CAM.git
$ cd Faster-Grad-CAM/model
The following is the program to execute Weight Quantization. The difference between the quantization pattern from the previous Tensorflow checkpoint is the difference between the loading part of the model and weights and the method for conversion. TFLiteConverter has the ability to pass a weight-loaded model object as is.
1. model = tf.keras.models.model_from_json(open('model.json').read())
2. model.load_weights('weights.h5')
3. tf.lite.TFLiteConverter.from_keras_model(model)
import tensorflow as tf
tf.compat.v1.enable_eager_execution()
# Weight Quantization - Input/Output=float32
# INPUT = input_1 (float32, 1 x 96 x 96 x 3)
# OUTPUT = block_16_expand_relu, global_average_pooling2d_1
model = tf.keras.models.model_from_json(open('model.json').read())
model.load_weights('weights.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.experimental_new_converter = True #<--- Not necessary if you are using Tensorflow v2.2.x or later.
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('./weights_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - weights_weight_quant.tflite")
Let's run it.
$ python3 weight_quantization.py
It seems to have been generated safely.
- Go to Table of contents -
4-2-5-2. Generating the calibration data set
Clone a dataset image for calibration from @karaage0703's repository. Faster-Grad-CAM's trained models are trained with this gu dataset. It's tedious to go through all the disparate images, so I'll use the subsequent steps to pack them into one file.
$ wget https://github.com/karaage0703/janken_dataset.git
$ cd gu
Create a program to pack Numpy into binary format files.
from PIL import Image
import os, glob
import numpy as np
dataset = []
files = glob.glob("*.JPG")
for file in files:
image = Image.open(file)
image = image.convert("RGB")
data = np.asarray(image)
dataset.append(data)
dataset = np.array(dataset)
np.save("janken_dataset", dataset)
Now, let's give it a go.
$ python3 image_to_npy.py
It seems to have been generated without incident.
- Go to Table of contents -
4-2-5-3. Integer Quantization from .h5/.json (8-bit integer quantization)
The method of Integer Quantization is almost the same as the previous method, except that it is handled slightly differently.
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
raw_test_data = np.load('janken_dataset.npy')
for image in raw_test_data:
image = tf.image.resize(image, (96, 96))
image = image / 255
calibration_data = image[np.newaxis, :, :, :]
yield [calibration_data]
tf.compat.v1.enable_eager_execution()
# Integer Quantization - Input/Output=float32
# INPUT = input_1 (float32, 1 x 96 x 96 x 3)
# OUTPUT = block_16_expand_relu, global_average_pooling2d_1
model = tf.keras.models.model_from_json(open('model.json').read())
model.load_weights('weights.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.experimental_new_converter = True #<--- Not necessary if you are using Tensorflow v2.2.x or later.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./weights_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - weights_integer_quant.tflite")
Let's run it.
$ python3 integer_quantization.py
It seems to have been generated without incident.
- Go to Table of contents -
4-2-5-4. Full Integer Quantization from .h5/.json (all 8-bit integer quantization)
Write a program to do Full Integer Quantization.
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
raw_test_data = np.load('janken_dataset.npy')
for image in raw_test_data:
image = tf.image.resize(image, (96, 96))
image = image / 255
calibration_data = image[np.newaxis, :, :, :]
yield [calibration_data]
tf.compat.v1.enable_eager_execution()
# Integer Quantization - Input/Output=float32
# INPUT = input_1 (float32, 1 x 96 x 96 x 3)
# OUTPUT = block_16_expand_relu, global_average_pooling2d_1
model = tf.keras.models.model_from_json(open('model.json').read())
model.load_weights('weights.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.experimental_new_converter = True #<--- Tensorflow v2.2.x以降を使用している場合は不要
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./weights_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Full Integer Quantization complete! - weights_full_integer_quant.tflite")
Let's run it.
$ python3 full_integer_quantization.py
It seems to have been generated without incident.
- Go to Table of contents -
4-2-5-5. Float16 Quantization from .h5/.json (Float16 quantization)
Write a program to do Float16 Quantization.
import tensorflow as tf
tf.compat.v1.enable_eager_execution()
# Weight Quantization - Input/Output=float32
# INPUT = input_1 (float32, 1 x 96 x 96 x 3)
# OUTPUT = block_16_expand_relu, global_average_pooling2d_1
model = tf.keras.models.model_from_json(open('model.json').read())
model.load_weights('weights.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.experimental_new_converter = True #<--- Not necessary if you are using Tensorflow v2.2.x or later.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('./weights_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Float16 Quantization complete! - weights_float16_quant.tflite")
Let's run it.
$ python3 float16_quantization.py
It seems to have been generated safely.
- Go to Table of contents -
4-2-5-6. Full Integer Quantization to EdgeTPU convert
A model with Full Integer Quantization is used to generate a model with EdgeTPU support.
$ edgetpu_compiler -s weights_full_integer_quant.tflite
Edge TPU Compiler version 2.1.302470888
Model compiled successfully in 359 ms.
Input model: weights_full_integer_quant.tflite
Input size: 1.00MiB
Output model: weights_full_integer_quant_edgetpu.tflite
Output size: 1.06MiB
On-chip memory used for caching model parameters: 1014.00KiB
On-chip memory remaining for caching model parameters: 6.78MiB
Off-chip memory used for streaming uncached model parameters: 0.00B
Number of Edge TPU subgraphs: 1
Total number of operations: 71
Operation log: weights_full_integer_quant_edgetpu.log
Model successfully compiled but not all operations are supported by the Edge TPU. A percentage of the model will instead run on the CPU, which is slower. If possible, consider updating your model to use only operations supported by the Edge TPU. For details, visit g.co/coral/model-reqs.
Number of operations that will run on Edge TPU: 68
Number of operations that will run on CPU: 3
Operator Count Status
DEPTHWISE_CONV_2D 17 Mapped to Edge TPU
DEQUANTIZE 2 Operation is working on an unsupported data type
MEAN 1 Mapped to Edge TPU
ADD 10 Mapped to Edge TPU
QUANTIZE 1 Operation is otherwise supported, but not mapped due to some unspecified limitation
PAD 5 Mapped to Edge TPU
CONV_2D 35 Mapped to Edge TPU
It seems to have been generated safely.
- Go to Table of contents -
4-2-6. Quantization from a model for Tensorflow.js
Now it's time to tackle a more challenging task. Quantize Posenet V2 ResNet50 for Tensorflow.js, which was recently released by Google. To begin with, the code for checkpoint and training isn't published, so it's a tricky task. This is the repository from which to check. You will need to switch between Tensoflow v2.1.0 and Tensorflow v1.15.2. If you don't want to go through the trouble, please use PINTO_model_zoo, which is already committed with all patterns converted to the quantized model.

- Go to Table of contents -
4-2-6-1. Advance preparation
$ sudo pip3 uninstall tensorboard-plugin-wit tb-nightly \
tf-estimator-nightly tensorflow-gpu \
tensorflow tf-nightly tensorflow_estimator
$ sudo pip3 install tensorflow==2.1.0
$ git clone https://github.com/patlevin/tfjs-to-tf.git
$ cd tfjs-to-tf
$ sudo pip3 install . --no-deps
$ cd ..
$ git clone https://github.com/atomicbits/posenet-python.git
$ cd posenet-python
$ mkdir -p output
4-2-6-2. Generating a saved_model from Tensorflow.js
Create a saved_model by the following command. By specifying stride, it is possible to generate a model that balances accuracy and speed. You must save one or more sample images in the folder path specified in the argument of --image_dir in advance. Let's run it.
$ python3 image_demo.py \
--model resnet50 \
--stride 16 \
--image_dir ./images \
--output_dir ./output
Generating saved_model output stride with 16 created saved_model under tf_models/posenet/resnet50_float/stride16/.
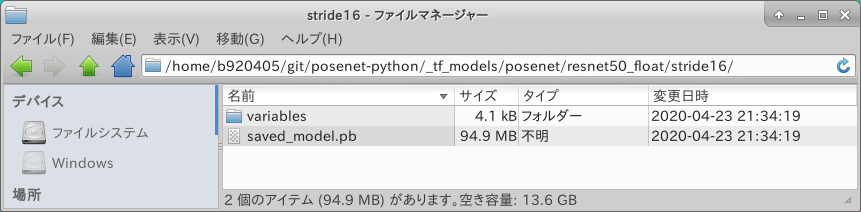
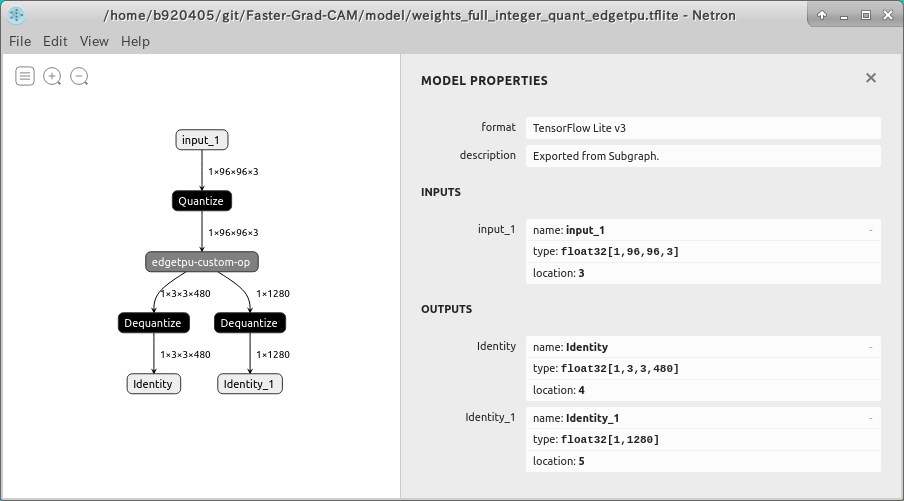
Check the structure with Netron. I know that INPUT is sub_2, but the shape is Float32 [1, ?, ?, 3]. As it is, the quantization will fail. I'm going to make another adjustment here.
※Actually, you can fix the INPUT shape of sub_2 in tfjs_models/posenet/resnet50_float/stride16/model-stride16.json just by modifying and re-converting the INPUT shape by hand. However, I'm going to go a long way just to explain the special processing for importing and processing Tensorflow v2 saved_model with Tensorflow v1.x.

- Go to Table of contents -
4-2-6-3. Import saved_model generated by Tensorflow v2.x into Tensorflow v1.x and process the input shape
Import saved_model into Tensorflow v1.15.2 and process the input shape. The only reason I use Tensorflow v1.15.2 is because I want to use the TransformGraph tool.
$ sudo pip3 uninstall tensorboard-plugin-wit tb-nightly \
tf-estimator-nightly tensorflow-gpu \
tensorflow tf-nightly tensorflow_estimator
$ sudo pip3 install tensorflow==1.15.2
The following is a program to change the input shape of saved_model. Replace the name sub_2 with the name image, while changing the input shape to [1, ?, ?, 3] to [1, 513, 513, 3], while replacing the name sub_2 with the name image. If you want to change the input form to a smaller form, you need to change 513 to 257. The part that is slightly different from the program introduced so far is that the logic to read the .pb file is slightly changed in order to import saved_model generated by Tensorflow v2.x into Tensorflow v1.x.
### tensorflow-gpu==1.15.2
import sys
import tensorflow as tf
from tensorflow.tools.graph_transforms import TransformGraph
from tensorflow.python.platform import gfile
from tensorflow.core.protobuf import saved_model_pb2
from tensorflow.python.util import compat
with tf.compat.v1.Session() as sess:
# shape=[1, ?, ?, 3] -> shape=[1, 513, 513, 3]
# name='image' specifies the placeholder name of the converted model
inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 513, 513, 3], name='image')
#inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 385, 385, 3], name='image')
#inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 321, 321, 3], name='image')
#inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 257, 257, 3], name='image')
#inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 225, 225, 3], name='image')
with gfile.FastGFile('_tf_models/posenet/resnet50_float/stride32/saved_model.pb', 'rb') as f:
data = compat.as_bytes(f.read())
sm = saved_model_pb2.SavedModel()
sm.ParseFromString(data)
if 1 != len(sm.meta_graphs):
print('More than one graph found. Not sure which to write')
sys.exit(1)
# 'image:0' specifies the placeholder name of the model before conversion
tf.graph_util.import_graph_def(sm.meta_graphs[0].graph_def, input_map={'sub_2:0': inputs}, name='')
print([n for n in tf.compat.v1.get_default_graph().as_graph_def().node if n.name == 'image'])
# Delete Placeholder "image" before conversion
# see: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms
# TransformGraph(
# graph_def(),
# input_name,
# output_names,
# conversion options
# )
optimized_graph_def = TransformGraph(
tf.compat.v1.get_default_graph().as_graph_def(),
'image',
['float_heatmaps','float_short_offsets','resnet_v1_50/displacement_fwd_2/BiasAdd','resnet_v1_50/displacement_bwd_2/BiasAdd'],
['strip_unused_nodes(type=float, shape="1,513,513,3")'])
tf.io.write_graph(optimized_graph_def, './', 'posenet_resnet50_32_513.pb', as_text=False)
with gfile.FastGFile('_tf_models/posenet/resnet50_float/stride32/saved_model.pb', 'rb') as f:
data = compat.as_bytes(f.read())
sm = saved_model_pb2.SavedModel()
sm.ParseFromString(data)
if 1 != len(sm.meta_graphs):
print('More than one graph found. Not sure which to write')
sys.exit(1)
Let's run it.
$ python3 replacement_of_input_placeholder_float32_resnet.py
It seems to have been generated safely.
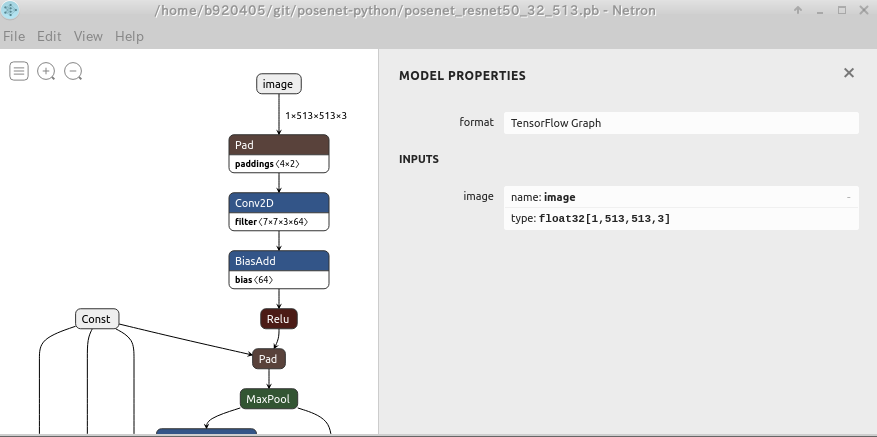
- Go to Table of contents -
4-2-6-4. Installation of Tensorflow v2.2.0
Change Tensorflow v1.15.2 to Tensorflow v2.2.0 before quantization.
$ sudo pip3 uninstall tensorboard-plugin-wit tb-nightly \
tf-estimator-nightly tensorflow-gpu \
tensorflow tf-nightly tensorflow_estimator
$ sudo pip3 install tensorflow==2.2.0
4-2-6-5. Weight Quantization from saved_model (Weight-only quantization)
The quantization procedure from here on is the same as the previous one. The program for quantization is described below.
### tensorflow==2.2.0
import tensorflow as tf
import numpy as np
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_225')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_225_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_16_225_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_257')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_257_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_16_257_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_321')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_321_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_16_321_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_385')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_385_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_16_385_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_513')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_513_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_16_513_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_225')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_225_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_32_225_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_257')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_257_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_32_257_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_321')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_321_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_32_321_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_385')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_385_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_32_385_weight_quant.tflite")
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_513')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_513_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - posenet_resnet50_32_513_weight_quant.tflite")
4-2-6-6. Integer Quantization from saved_model (8-bit integer quantization)
The method of Integer Quantization is the same as before. The images used for the calibration data set are 100 images with only people in them.
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
from PIL import Image
import os
import glob
## Generating a calibration data set
def representative_dataset_gen():
folder = ["images"]
image_size = 225
raw_test_data = []
for name in folder:
dir = "./" + name
files = glob.glob(dir + "/*.jpg")
for file in files:
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
image = np.asarray(image).astype(np.float32)
image = image[np.newaxis,:,:,:]
raw_test_data.append(image)
for data in raw_test_data:
yield [data]
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_225')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_225_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_16_225_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_257')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_257_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_257_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_321')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_321_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_321_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_385')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_385_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_385_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_513')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_513_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_513_integer_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_225')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_225_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_32_225_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_257')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_257_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_257_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_321')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_321_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_321_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_385')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_385_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_385_integer_quant.tflite")
# # Integer Quantization - Input/Output=float32
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_513')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_513_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_513_integer_quant.tflite")
4-2-6-7. Full Integer Quantization from saved_model (All 8-bit integer quantization)
The method of Full Integer Quantization is the same as before. The images used for the calibration data set are 100 images with only people in them.
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
from PIL import Image
import os
import glob
## Generating a calibration data set
def representative_dataset_gen():
folder = ["images"]
image_size = 225
raw_test_data = []
for name in folder:
dir = "./" + name
files = glob.glob(dir + "/*.jpg")
for file in files:
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
image = np.asarray(image).astype(np.float32)
image = image[np.newaxis,:,:,:]
raw_test_data.append(image)
for data in raw_test_data:
yield [data]
# Integer Quantization - Input/Output=uint8
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_225')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_225_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_16_225_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_257')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_257_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_257_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_321')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_321_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_321_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_385')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_385_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_385_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_513')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_16_513_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_16_513_full_integer_quant.tflite")
# Integer Quantization - Input/Output=uint8
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_225')
converter.experimental_new_converter = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_225_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_32_225_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_257')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_257_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_257_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_321')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_321_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_321_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_385')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_385_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_385_full_integer_quant.tflite")
# # Integer Quantization - Input/Output=uint8
# converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_513')
# converter.optimizations = [tf.lite.Optimize.DEFAULT]
# converter.representative_dataset = representative_dataset_gen
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# converter.inference_input_type = tf.uint8
# converter.inference_output_type = tf.uint8
# tflite_quant_model = converter.convert()
# with open('posenet_resnet50_32_513_full_integer_quant.tflite', 'wb') as w:
# w.write(tflite_quant_model)
# print("Integer Quantization complete! - posenet_resnet50_32_513_full_integer_quant.tflite")
4-2-6-8. Float16 Quantization from saved_model (Float16 quantization)
The method of Float16 Quantization is the same as before.
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
from PIL import Image
import os
import glob
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_225')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_225_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_16_225_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_257')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_257_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_16_257_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_321')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_321_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_16_321_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_385')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_385_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_16_385_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_16_513')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_16_513_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_16_513_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_225')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_225_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_32_225_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_257')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_257_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_32_257_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_321')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_321_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_32_321_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_385')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_385_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_32_385_float16_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_posenet_resnet50_32_513')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('posenet_resnet50_32_513_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - posenet_resnet50_32_513_float16_quant.tflite")
4-2-6-9. Full Integer Quantization to EdgeTPU convert
The method of compiling EdgeTPU is the same as the previous method.
$ edgetpu_compiler -s posenet_resnet50_16_225_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_16_257_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_16_321_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_16_385_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_16_513_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_32_225_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_32_257_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_32_321_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_32_385_full_integer_quant.tflite
$ edgetpu_compiler -s posenet_resnet50_32_513_full_integer_quant.tflite
4-2-7. Quantize the model generated by the TensorFlow Object Detection API
What's with the Tensorflow Object Detection API? If you want to know more, please see this article I made Object Detection Tools and the following repositories: Object Detection API library of TensorFlow - Karaage San. It's very helpful.

The method of training with the Object Detection API is pretty clear in the above article, so I won't go into it here, but I will explain how to quantize the generated model as a model with Post-Process added to it to improve performance. Use Tensorflow v1.15.2.
Assume you have a MobileNetV2-SSDLite checkpoint at hand that has been cloned https://github.com/tensorflow/models.git and trained for 44,548 STEPs using the Object Detection API.
4-2-7-1. Generating a .pb file with Post-Process
Execute the following command to output a Freeze_Graph with post-processing added.
$ cd ${HOME}/models/research
$ export PYTHONPATH=`pwd`:`pwd`/slim:$PYTHONPATH
$ mkdir -p export
$ python3 object_detection/export_tflite_ssd_graph.py \
--pipeline_config_path=pipeline.config \
--trained_checkpoint_prefix=model.ckpt-44548 \
--output_directory=export \
--add_postprocessing_op=True
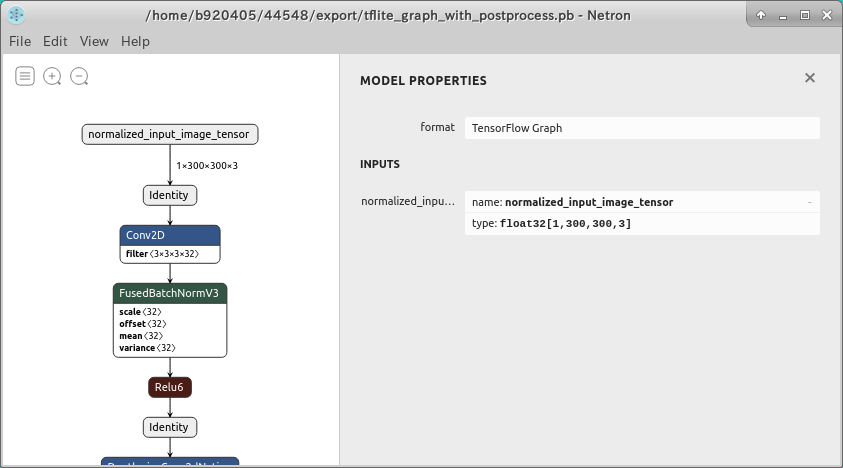
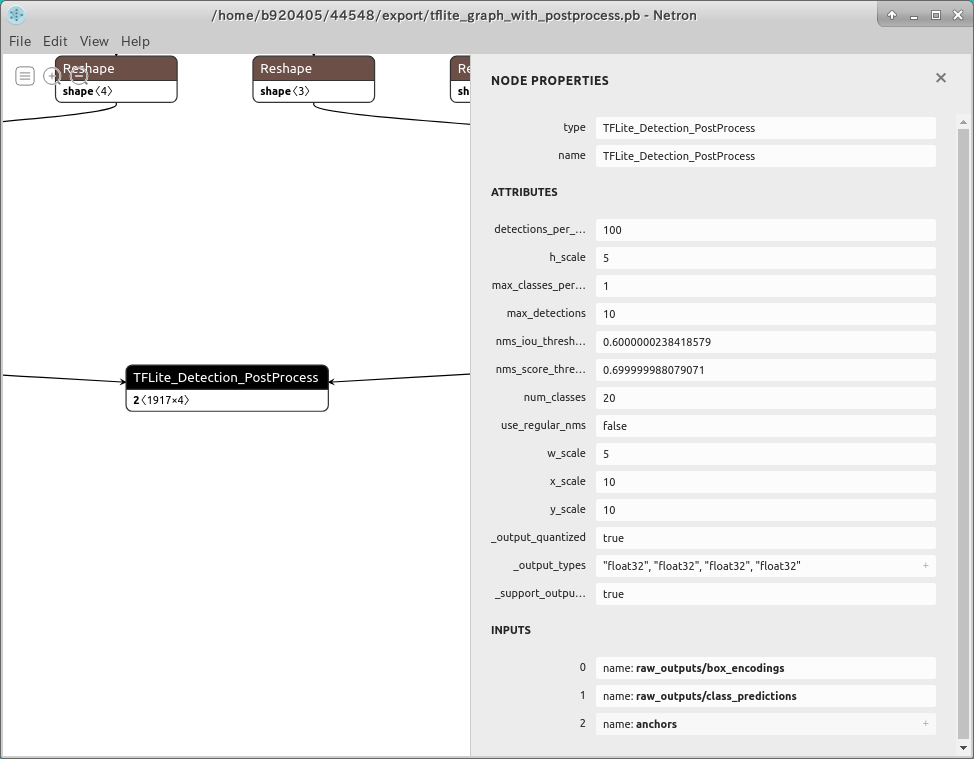
TFLite_Detection_PostProcess is a custom operation.
4-2-7-2. Weight Quantization from Freeze_Graph (Weight-only quantization)
I won't do anything special, but here are some points to consider when quantizing.
1. Using the Tensorflow v1.x API from_frozen_graph
2. For .pb files containing custom operations, converter.allow_custom_ops = True
import tensorflow as tf
tf.compat.v1.enable_eager_execution()
# Weight Quantization - Input/Output=float32
graph_def_file="tflite_graph_with_postprocess.pb"
input_arrays=["normalized_input_image_tensor"]
output_arrays=['TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1',
'TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3']
input_tensor={"normalized_input_image_tensor":[1,300,300,3]}
converter = tf.lite.TFLiteConverter.from_frozen_graph(graph_def_file, input_arrays,
output_arrays,input_tensor)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
converter.allow_custom_ops = True
tflite_quant_model = converter.convert()
with open('./ssdlite_mobilenet_v2_voc_300_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - ssdlite_mobilenet_v2_voc_300_weight_quant.tflite")
Let's run it.
$ python3 weight_quantization.py
It seems to have been generated safely.
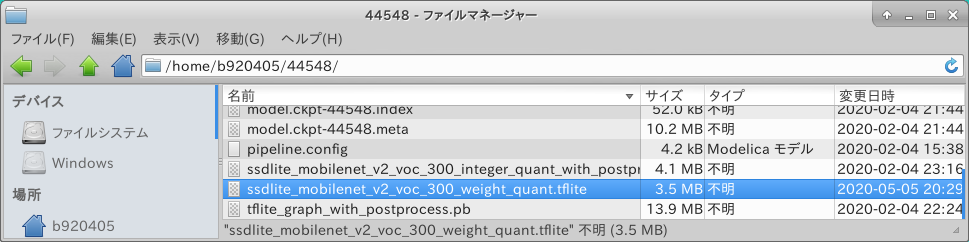
- Go to Table of contents -
4-2-7-3. Integer Quantization from Freeze_Graph (8-bit integer quantization)
It is almost identical to Weight Quantization.
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (300, 300))
image = image[np.newaxis,:,:,:]
image = image - 127.5
image = image * 0.007843
yield [image]
tf.compat.v1.enable_eager_execution()
raw_test_data, info = tfds.load(name="voc/2007", with_info=True,
split="validation", data_dir="~/TFDS", download=False)
# Integer Quantization - Input/Output=float32
graph_def_file="tflite_graph_with_postprocess.pb"
input_arrays=["normalized_input_image_tensor"]
output_arrays=['TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1',
'TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3']
input_tensor={"normalized_input_image_tensor":[1,300,300,3]}
converter = tf.lite.TFLiteConverter.from_frozen_graph(graph_def_file, input_arrays,
output_arrays,input_tensor)
converter.allow_custom_ops=True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./ssdlite_mobilenet_v2_voc_300_integer_quant_with_postprocess.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - ssdlite_mobilenet_v2_voc_300_integer_quant_with_postprocess.tflite")
4-2-7-4. Full Integer Quantization from Freeze_Graph (All 8-bit integer quantization)
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (300, 300))
image = image[np.newaxis,:,:,:]
image = image - 127.5
image = image * 0.007843
yield [image]
tf.compat.v1.enable_eager_execution()
raw_test_data, info = tfds.load(name="voc/2007", with_info=True,
split="validation", data_dir="~/TFDS", download=False)
# Full Integer Quantization - Input/Output=float32
graph_def_file="tflite_graph_with_postprocess.pb"
input_arrays=["normalized_input_image_tensor"]
output_arrays=['TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1',
'TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3']
input_tensor={"normalized_input_image_tensor":[1,300,300,3]}
converter = tf.lite.TFLiteConverter.from_frozen_graph(graph_def_file, input_arrays,
output_arrays,input_tensor)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.allow_custom_ops=True
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8,tf.lite.OpsSet.SELECT_TF_OPS]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./ssdlite_mobilenet_v2_voc_300_full_integer_quant_with_postprocess.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Full Integer Quantization complete! - ssdlite_mobilenet_v2_voc_300_full_integer_quant_with_postprocess.tflite")
4-2-7-5. Float16 Quantization from Freeze_Graph (Float16 quantization)
import tensorflow as tf
tf.compat.v1.enable_eager_execution()
# Float16 Quantization - Input/Output=float32
graph_def_file="tflite_graph_with_postprocess.pb"
input_arrays=["normalized_input_image_tensor"]
output_arrays=['TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1',
'TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3']
input_tensor={"normalized_input_image_tensor":[1,300,300,3]}
converter = tf.lite.TFLiteConverter.from_frozen_graph(graph_def_file, input_arrays,
output_arrays,input_tensor)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
converter.allow_custom_ops = True
tflite_quant_model = converter.convert()
with open('./ssdlite_mobilenet_v2_voc_300_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Float16 Quantization complete! - ssdlite_mobilenet_v2_voc_300_float16_quant.tflite")
4-2-7-6. Full Integer Quantization to EdgeTPU convert
$ edgetpu_compiler -s ssdlite_mobilenet_v2_voc_300_full_integer_quant_with_postprocess.tflite
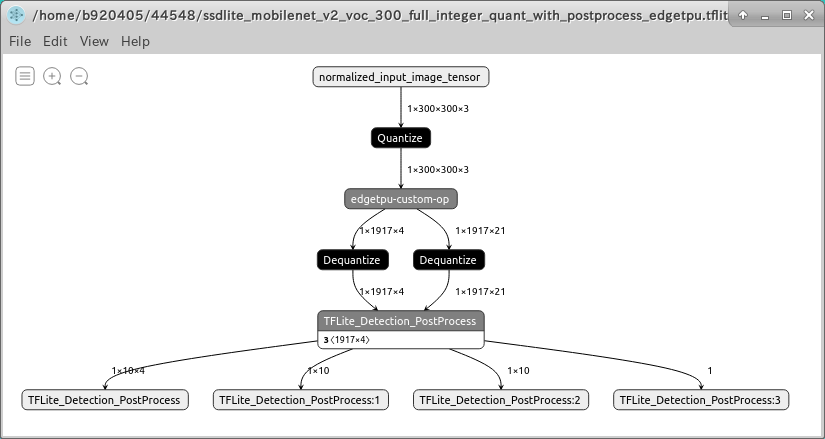
4-2-8. Quantize models containing operations that are not supported by Tensorflow Lite but are supported by Tensorflow
The operators implemented in Tensorflow Lite are not exactly the same as those in Tensorflow itself, and a significant amount of them remain unimplemented. Unfortunately, the models that have been implemented in Tensorflow for a long time have been difficult to convert all of them to Tensorflow Lite. However, with the Flex Delegate delegate function implemented around the end of last year, it is now possible to offload processing to the main body of Tensorflow if there is an operator not yet implemented in Tensorflow Lite. The implementation doesn't seem to be perfect yet, and some models don't allow Integer Quantization, and there is only a C++ API and no Python API. The recognition is not so high, but I think that it is a convenient function which can expand the range of model utilization casually for engineers who can implement it in C++.
Here is an example of Mask-RCNN Inception V2. Unfortunately, Mask-RCNN Inception V2 does not support Integer Quantization and Full Integer Quantization at this time. You also need to implement Tensorflow v2.2.0 or tf-nightly to perform this procedure.

1. https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md#coco-trained-models
2. http://download.tensorflow.org/models/object_detection/mask_rcnn_inception_v2_coco_2018_01_28.tar.gz
4-2-8-1. Generate Mask-RCNN Inception V2 .pb file
I will proceed on the assumption that the Tensorflow Object Detection API is in place. First, download the Mask-RCNN Inception V2 checkpoint from the official website and convert it to Freeze_Graph using the Object Detection API script.
https://github.com/matterport/Mask_RCNN/issues/563
https://github.com/PINTO0309/TensorflowLite-flexdelegate
$ cd ~/Downloads
$ wget http://download.tensorflow.org/models/object_detection/mask_rcnn_inception_v2_coco_2018_01_28.tar.gz
$ tar -zxvf mask_rcnn_inception_v2_coco_2018_01_28.tar.gz
$ cd ${HOME}/models/research
$ export PYTHONPATH=`pwd`:`pwd`/slim:$PYTHONPATH
$ mkdir -p ${HOME}/Downloads/mask_rcnn_inception_v2_coco_2018_01_28/export
$ sudo pip3 uninstall tensorboard-plugin-wit tb-nightly \
tf-estimator-nightly tensorflow-gpu \
tensorflow tf-nightly tensorflow_estimator
$ sudo pip3 install tensorflow==2.2.0
$ python3 object_detection/export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path=${HOME}/Downloads/mask_rcnn_inception_v2_coco_2018_01_28/pipeline.config \
--trained_checkpoint_prefix=${HOME}/Downloads/mask_rcnn_inception_v2_coco_2018_01_28/model.ckpt \
--output_directory=${HOME}/Downloads/mask_rcnn_inception_v2_coco_2018_01_28/test \
--input_shape=1,256,256,3 \
--write_inference_graph=True
$ python3 object_detection/export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path=${HOME}/Downloads/mask_rcnn_inception_v2_coco_2018_01_28/pipeline.config \
--trained_checkpoint_prefix=${HOME}/Downloads/mask_rcnn_inception_v2_coco_2018_01_28/model.ckpt \
--output_directory=${HOME}/Downloads/mask_rcnn_inception_v2_coco_2018_01_28/test \
--input_shape=1,512,512,3 \
--write_inference_graph=True
4-2-8-2. Weight Quantization of Mask-RCNN Inception V2 (Weight-only quantization)
The points of this work are as follows.
1. Tensorflow v2.2.0-rc0 or higher is installed
2. tf.lite.OpsSet.SELECT_TF_OPS is specified in converter.target_spec.supported_ops
### tensorflow==2.2.0
import tensorflow as tf
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./saved_model')
converter.experimental_new_converter = True
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS]
tflite_quant_model = converter.convert()
with open('./mask_rcnn_inception_v2_coco_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - mask_rcnn_inception_v2_coco_weight_quant.tflite")
4-2-8-3. Float16 Quantization in Mask-RCNN Inception V2 (Float16 quantization)
The point of the work is the same as Weight Quantization.
### tensorflow==2.2.0
import tensorflow as tf
# Float16 Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./saved_model')
converter.experimental_new_converter = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS]
converter.target_spec.supported_types = [tf.float16]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./mask_rcnn_inception_v2_coco_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Float16 Quantization complete! - mask_rcnn_inception_v2_coco_float16_quant.tflite")
4-2-8-4. Running a model with Flex Delegate (Tensorflow Select Ops) enabled
Unfortunately, I don't have the skills to implement in C++. However, I made an effort to implement and even got ENet to work, including Tensorflow Lite's non-supported operations. The contents are a mess, but you can find the wreckage in this repository TensorflowLite-flexdelegate. You need to build Tensorflow Lite to enable the Flex feature. Please see the above repository for more information.
4-2-9. Quantization from a model for PyTorch
Lately, I feel like there are more and more interesting models and projects of PyTorch implementations. Here's an example of how to convert a PyTorch model to a Tensorflow Lite quantized model. Here I try to convert the PyTorch model of 3D Multi-Person Pose Estimation to a quantized model of Tensorflow Lite. This 3D PoseEstimation (Multi-Person) by OpenVINO + Corei7 CPU only [14 FPS-18 FPS] - Qiita - PINTO is the original story. You need Tensorflow v2.2.0 to perform this work.
Let me make use of the models and converters published below.3D PoseEstimation+OpenVINO+Corei7 CPU only+720p USB Camera [推論スピード 18 FPS相当]
— Super PINTO (@PINTO03091) March 21, 2020
yukihiko-chan には勝てません。 が、CPU onlyかつHD 画質でこのパフォーマンスが出ます。 録画とUI表示にパフォーマンスを持って行かれています。 3Dモデリングはきついと思います。https://t.co/rvZC00Olrl
 **[- Go to Table of contents -](#2-table-of-contents)**
**[- Go to Table of contents -](#2-table-of-contents)**
4-2-9-1. Advance preparation (PyTorch->ONNX)
An overview of PyTorch's quantization workflow is provided below.
1. Clone open_model_zoo
2. Download a public model using downloader.py from open_model_zoo
3. Converting a PyTorch model to an ONNX model using converter.py** of **open_model_zoo** ( Standard features of PyTorch **torch.onnx._export(...)** It's probably OK) 4. Convert a Keras model to **saved_model** 5. Convert a Keras model to **saved_model** 6. Quantize **saved_model`
$ git clone https://github.com/opencv/open_model_zoo.git
$ cd open_model_zoo/tools/downloader
$ ./downloader.py --name human-pose-estimation-3d-0001
$ ./converter.py --name human-pose-estimation-3d-0001
A part of the structure of the ONNX model is shown in the figure below.
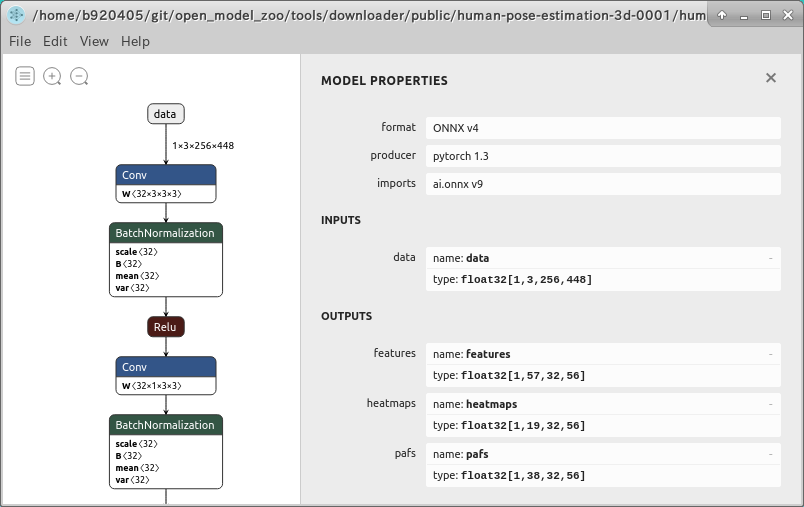
- Go to Table of contents -
4-2-9-2. ONNX->Keras conversion by onnx2keras
First, install Tensorflow v2.2.0 and onnx2keras.
$ sudo pip3 uninstall tensorboard-plugin-wit tb-nightly \
tf-estimator-nightly tensorflow-gpu \
tensorflow tf-nightly tensorflow_estimator
$ sudo pip3 install tensorflow==2.2.0
$ sudo pip3 install onnx2keras
Next, here's the program to convert the ONNX model to the Keras model, and then to saved_model
import onnx
from onnx2keras import onnx_to_keras
import tensorflow as tf
import shutil
onnx_model = onnx.load('human-pose-estimation-3d-0001.onnx')
k_model = onnx_to_keras(onnx_model=onnx_model, input_names=['data'], change_ordering=True)
shutil.rmtree('saved_model', ignore_errors=True)
tf.saved_model.save(k_model, 'saved_model')
Let's run it.
$ python3 onnx_to_keras.py
It seems to have been generated safely. Once you've come this far, it's no different from the quantization procedure you've been working on so far.
- Go to Table of contents -
4-2-9-3. Weight Quantization from saved_model (Weight-only quantization)
### tensorflow=2.2.0
import tensorflow as tf
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
# converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS]
tflite_quant_model = converter.convert()
with open('human_pose_estimation_3d_0001_256x448_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - human_pose_estimation_3d_0001_256x448_weight_quant.tflite")
4-2-9-4. Integer Quantization from saved_model (8-bit integer quantization)
The image data set for the calibration is 100 images extracted from Pascal-VOC 2007, which contains only the images of people.
### tensorflow==2.2.0
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
for image in raw_test_data:
image = tf.image.resize(image, (256, 448))
image = image[np.newaxis,:,:,:]
image = image - 127.5
image = image * 0.007843
yield [image]
raw_test_data = np.load('calibration_data_img.npy', allow_pickle=True)
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('human_pose_estimation_3d_0001_256x448_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - human_pose_estimation_3d_0001_256x448_integer_quant.tflite")
4-2-9-5. Full Integer Quantization from saved_model (All 8-bit integer quantization)
### tensorflow==2.2.0
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
for image in raw_test_data:
image = tf.image.resize(image, (256, 448))
image = image[np.newaxis,:,:,:]
image = image - 127.5
image = image * 0.007843
yield [image]
raw_test_data = np.load('calibration_data_img.npy', allow_pickle=True)
# Full Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('human_pose_estimation_3d_0001_256x448_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Full Integer Quantization complete! - human_pose_estimation_3d_0001_256x448_full_integer_quant.tflite")
4-2-9-6. Float16 Quantization from saved_model (Float16 quantization)
### tensorflow==2.2.0
import tensorflow as tf
# Float16 Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('human_pose_estimation_3d_0001_256x448_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Float16 Quantization complete! - human_pose_estimation_3d_0001_256x448_float16_quant.tflite")
4-2-9-7. Full Integer Quantization to EdgeTPU convert
Compile to the EdgeTPU model using the Full Integer Quantization model.
$ edgetpu_compiler -s human_pose_estimation_3d_0001_256x448_full_integer_quant.tflite
The operator Elu, which appears early in the model, does not support quantization, resulting in a very disappointing EdgeTPU model. However, some of the early stages have managed to be converted to support EdgeTPU.
- Go to Table of contents -
4-2-10. Quantization of MediaPipe's model BlazeFace(.tflite)
Here I quantize a model called BlazeFace, published by Google in a project called MediaPipe. This will be the most challenging pattern in the quantization workflow to date. In the first place, not all checkpoint, Freeze_Graph, and saved_model are provided, but only .tflite. The conversion procedure is as follows.
1. Build flatc
2. Download schema.fbs
3. Download the model face_detection_front.tflite for BlazeFace.
4. Parse a .tflite into a .json using flatc.
5. Generate a network based on the model structure read from .json in 4. while extracting weights from .tflite
6. Convert to saved_model using the weights and network extracted in 5.
7. Perform various types of quantization.
4-2-10-1. Build flatc and download schema.fbs
$ cd ~
$ git clone https://github.com/google/flatbuffers.git
$ cd flatbuffers
$ cmake -G "Unix Makefiles"
-- The C compiler identification is GNU 7.5.0
-- The CXX compiler identification is GNU 7.5.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Looking for strtof_l
-- Looking for strtof_l - found
-- Looking for strtoull_l
-- Looking for strtoull_l - found
-- `tests/monster_test.fbs`: add generation of C++ code with '--no-includes;--gen-compare'
-- `tests/monster_test.fbs`: add generation of binary (.bfbs) schema
-- `tests/namespace_test/namespace_test1.fbs`: add generation of C++ code with '--no-includes;--gen-compare'
-- `tests/namespace_test/namespace_test2.fbs`: add generation of C++ code with '--no-includes;--gen-compare'
-- `tests/union_vector/union_vector.fbs`: add generation of C++ code with '--no-includes;--gen-compare'
-- `tests/native_type_test.fbs`: add generation of C++ code with ''
-- `tests/arrays_test.fbs`: add generation of C++ code with '--scoped-enums;--gen-compare'
-- `tests/arrays_test.fbs`: add generation of binary (.bfbs) schema
-- `tests/monster_test.fbs`: add generation of C++ embedded binary schema code with '--no-includes;--gen-compare'
-- `tests/monster_extra.fbs`: add generation of C++ code with '--no-includes;--gen-compare'
-- `samples/monster.fbs`: add generation of C++ code with '--no-includes;--gen-compare'
-- `samples/monster.fbs`: add generation of binary (.bfbs) schema
Proceeding with version: 1.12.0.42
-- Configuring done
-- Generating done
-- Build files have been written to: /home/b920405/git/flatbuffers
$ make
Scanning dependencies of target flatc
[ 1%] Building CXX object CMakeFiles/flatc.dir/src/idl_parser.cpp.o
[ 2%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_text.cpp.o
[ 3%] Building CXX object CMakeFiles/flatc.dir/src/reflection.cpp.o
[ 4%] Building CXX object CMakeFiles/flatc.dir/src/util.cpp.o
[ 5%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_cpp.cpp.o
[ 7%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_csharp.cpp.o
[ 8%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_dart.cpp.o
[ 9%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_kotlin.cpp.o
[ 10%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_go.cpp.o
[ 11%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_java.cpp.o
[ 12%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_js_ts.cpp.o
[ 14%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_php.cpp.o
[ 15%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_python.cpp.o
[ 16%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_lobster.cpp.o
[ 17%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_lua.cpp.o
[ 18%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_rust.cpp.o
[ 20%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_fbs.cpp.o
[ 21%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_grpc.cpp.o
[ 22%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_json_schema.cpp.o
[ 23%] Building CXX object CMakeFiles/flatc.dir/src/idl_gen_swift.cpp.o
[ 24%] Building CXX object CMakeFiles/flatc.dir/src/flatc.cpp.o
[ 25%] Building CXX object CMakeFiles/flatc.dir/src/flatc_main.cpp.o
[ 27%] Building CXX object CMakeFiles/flatc.dir/src/code_generators.cpp.o
[ 28%] Building CXX object CMakeFiles/flatc.dir/grpc/src/compiler/cpp_generator.cc.o
[ 29%] Building CXX object CMakeFiles/flatc.dir/grpc/src/compiler/go_generator.cc.o
[ 30%] Building CXX object CMakeFiles/flatc.dir/grpc/src/compiler/java_generator.cc.o
[ 31%] Building CXX object CMakeFiles/flatc.dir/grpc/src/compiler/python_generator.cc.o
[ 32%] Building CXX object CMakeFiles/flatc.dir/grpc/src/compiler/swift_generator.cc.o
[ 34%] Linking CXX executable flatc
[ 34%] Built target flatc
Scanning dependencies of target flathash
[ 35%] Building CXX object CMakeFiles/flathash.dir/src/flathash.cpp.o
[ 36%] Linking CXX executable flathash
[ 36%] Built target flathash
Scanning dependencies of target flatbuffers
[ 37%] Building CXX object CMakeFiles/flatbuffers.dir/src/idl_parser.cpp.o
[ 38%] Building CXX object CMakeFiles/flatbuffers.dir/src/idl_gen_text.cpp.o
[ 40%] Building CXX object CMakeFiles/flatbuffers.dir/src/reflection.cpp.o
[ 41%] Building CXX object CMakeFiles/flatbuffers.dir/src/util.cpp.o
[ 42%] Linking CXX static library libflatbuffers.a
[ 42%] Built target flatbuffers
Scanning dependencies of target generated_code
[ 43%] Run generation: 'samples/monster.bfbs'
[ 44%] Run generation: 'tests/monster_test_generated.h'
[ 45%] Run generation: 'tests/monster_test.bfbs'
[ 47%] Run generation: 'tests/namespace_test/namespace_test1_generated.h'
[ 48%] Run generation: 'tests/namespace_test/namespace_test2_generated.h'
[ 49%] Run generation: 'tests/union_vector/union_vector_generated.h'
[ 50%] Run generation: 'tests/native_type_test_generated.h'
[ 51%] Run generation: 'tests/arrays_test_generated.h'
[ 52%] Run generation: 'tests/arrays_test.bfbs'
[ 54%] Run generation: 'tests/monster_test_bfbs_generated.h'
[ 55%] Run generation: 'tests/monster_extra_generated.h'
[ 56%] Run generation: 'samples/monster_generated.h'
[ 57%] All generated files were updated.
[ 57%] Built target generated_code
Scanning dependencies of target flatsamplebfbs
[ 58%] Building CXX object CMakeFiles/flatsamplebfbs.dir/src/idl_parser.cpp.o
[ 60%] Building CXX object CMakeFiles/flatsamplebfbs.dir/src/idl_gen_text.cpp.o
[ 61%] Building CXX object CMakeFiles/flatsamplebfbs.dir/src/reflection.cpp.o
[ 62%] Building CXX object CMakeFiles/flatsamplebfbs.dir/src/util.cpp.o
[ 63%] Building CXX object CMakeFiles/flatsamplebfbs.dir/samples/sample_bfbs.cpp.o
[ 64%] Linking CXX executable flatsamplebfbs
[ 65%] Built target flatsamplebfbs
Scanning dependencies of target flatsamplebinary
[ 67%] Building CXX object CMakeFiles/flatsamplebinary.dir/samples/sample_binary.cpp.o
[ 68%] Linking CXX executable flatsamplebinary
[ 69%] Built target flatsamplebinary
Scanning dependencies of target flattests
[ 70%] Building CXX object CMakeFiles/flattests.dir/src/idl_parser.cpp.o
[ 71%] Building CXX object CMakeFiles/flattests.dir/src/idl_gen_text.cpp.o
[ 72%] Building CXX object CMakeFiles/flattests.dir/src/reflection.cpp.o
[ 74%] Building CXX object CMakeFiles/flattests.dir/src/util.cpp.o
[ 75%] Building CXX object CMakeFiles/flattests.dir/src/idl_gen_fbs.cpp.o
[ 76%] Building CXX object CMakeFiles/flattests.dir/tests/test.cpp.o
[ 77%] Building CXX object CMakeFiles/flattests.dir/tests/test_assert.cpp.o
[ 78%] Building CXX object CMakeFiles/flattests.dir/tests/test_builder.cpp.o
[ 80%] Building CXX object CMakeFiles/flattests.dir/tests/native_type_test_impl.cpp.o
[ 81%] Building CXX object CMakeFiles/flattests.dir/src/code_generators.cpp.o
[ 82%] Linking CXX executable flattests
[ 91%] Built target flattests
Scanning dependencies of target flatsampletext
[ 92%] Building CXX object CMakeFiles/flatsampletext.dir/src/idl_parser.cpp.o
[ 94%] Building CXX object CMakeFiles/flatsampletext.dir/src/idl_gen_text.cpp.o
[ 95%] Building CXX object CMakeFiles/flatsampletext.dir/src/reflection.cpp.o
[ 96%] Building CXX object CMakeFiles/flatsampletext.dir/src/util.cpp.o
[ 97%] Building CXX object CMakeFiles/flatsampletext.dir/samples/sample_text.cpp.o
[ 98%] Linking CXX executable flatsampletext
[100%] Built target flatsampletext
$ cp flatc ~ && cd ~
$ wget https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/schema/schema.fbs
4-2-10-2. Download MediaPipe's BlazeFace model (.tflite)
$ wget https://github.com/google/mediapipe/tree/master/mediapipe/models/face_detection_front.tflite
4-2-10-3. Converting BlazeFace(.tflite) to saved_model(.pb)
### tensorflow-gpu==1.15.2
# !/usr/bin/env python
# coding: utf-8
import os
import numpy as np
import json
import tensorflow as tf
import shutil
from pathlib import Path
home = str(Path.home())
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
schema = "schema.fbs"
binary = home + "/flatc"
model_path = "face_detection_front.tflite"
output_pb_path = "face_detection_front.pb"
output_savedmodel_path = "saved_model"
model_json_path = "face_detection_front.json"
num_tensors = 176
output_node_names = ['classificators', 'regressors']
def gen_model_json():
if not os.path.exists(model_json_path):
cmd = (binary + " -t --strict-json --defaults-json -o . {schema} -- {input}".format(input=model_path, schema=schema))
print("output json command =", cmd)
os.system(cmd)
def parse_json():
j = json.load(open(model_json_path))
op_types = [v['builtin_code'] for v in j['operator_codes']]
# print('op types:', op_types)
ops = j['subgraphs'][0]['operators']
# print('num of ops:', len(ops))
return ops, op_types
def make_graph(ops, op_types, interpreter):
tensors = {}
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# print(input_details)
for input_detail in input_details:
tensors[input_detail['index']] = tf.compat.v1.placeholder(
dtype=input_detail['dtype'],
shape=input_detail['shape'],
name=input_detail['name'])
for index, op in enumerate(ops):
print('op: ', op)
op_type = op_types[op['opcode_index']]
if op_type == 'CONV_2D':
input_tensor = tensors[op['inputs'][0]]
weights_detail = interpreter._get_tensor_details(op['inputs'][1])
bias_detail = interpreter._get_tensor_details(op['inputs'][2])
output_detail = interpreter._get_tensor_details(op['outputs'][0])
# print('weights_detail: ', weights_detail)
# print('bias_detail: ', bias_detail)
# print('output_detail: ', output_detail)
weights_array = interpreter.get_tensor(weights_detail['index'])
weights_array = np.transpose(weights_array, (1, 2, 3, 0))
bias_array = interpreter.get_tensor(bias_detail['index'])
weights = tf.Variable(weights_array, name=weights_detail['name'])
bias = tf.Variable(bias_array, name=bias_detail['name'])
options = op['builtin_options']
output_tensor = tf.nn.conv2d(
input_tensor,
weights,
strides=[1, options['stride_h'], options['stride_w'], 1],
padding=options['padding'],
dilations=[
1, options['dilation_h_factor'],
options['dilation_w_factor'], 1
],
name=output_detail['name'] + '/conv2d')
output_tensor = tf.add(
output_tensor, bias, name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
elif op_type == 'DEPTHWISE_CONV_2D':
input_tensor = tensors[op['inputs'][0]]
weights_detail = interpreter._get_tensor_details(op['inputs'][1])
bias_detail = interpreter._get_tensor_details(op['inputs'][2])
output_detail = interpreter._get_tensor_details(op['outputs'][0])
# print('weights_detail: ', weights_detail)
# print('bias_detail: ', bias_detail)
# print('output_detail: ', output_detail)
weights_array = interpreter.get_tensor(weights_detail['index'])
weights_array = np.transpose(weights_array, (1, 2, 3, 0))
bias_array = interpreter.get_tensor(bias_detail['index'])
weights = tf.Variable(weights_array, name=weights_detail['name'])
bias = tf.Variable(bias_array, name=bias_detail['name'])
options = op['builtin_options']
output_tensor = tf.nn.depthwise_conv2d(
input_tensor,
weights,
strides=[1, options['stride_h'], options['stride_w'], 1],
padding=options['padding'],
# dilations=[
# 1, options['dilation_h_factor'],
# options['dilation_w_factor'], 1
# ],
name=output_detail['name'] + '/depthwise_conv2d')
output_tensor = tf.add(
output_tensor, bias, name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
elif op_type == 'MAX_POOL_2D':
input_tensor = tensors[op['inputs'][0]]
output_detail = interpreter._get_tensor_details(op['outputs'][0])
options = op['builtin_options']
output_tensor = tf.nn.max_pool(
input_tensor,
ksize=[
1, options['filter_height'], options['filter_width'], 1
],
strides=[1, options['stride_h'], options['stride_w'], 1],
padding=options['padding'],
name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
elif op_type == 'PAD':
input_tensor = tensors[op['inputs'][0]]
output_detail = interpreter._get_tensor_details(op['outputs'][0])
paddings_detail = interpreter._get_tensor_details(op['inputs'][1])
# print('output_detail:', output_detail)
# print('paddings_detail:', paddings_detail)
paddings_array = interpreter.get_tensor(paddings_detail['index'])
paddings = tf.Variable(
paddings_array, name=paddings_detail['name'])
output_tensor = tf.pad(
input_tensor, paddings, name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
elif op_type == 'RELU':
output_detail = interpreter._get_tensor_details(op['outputs'][0])
input_tensor = tensors[op['inputs'][0]]
output_tensor = tf.nn.relu(
input_tensor, name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
elif op_type == 'RESHAPE':
input_tensor = tensors[op['inputs'][0]]
output_detail = interpreter._get_tensor_details(op['outputs'][0])
options = op['builtin_options']
output_tensor = tf.reshape(
input_tensor, options['new_shape'], name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
elif op_type == 'ADD':
output_detail = interpreter._get_tensor_details(op['outputs'][0])
input_tensor_0 = tensors[op['inputs'][0]]
input_tensor_1 = tensors[op['inputs'][1]]
output_tensor = tf.add(input_tensor_0, input_tensor_1, name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
elif op_type == 'CONCATENATION':
output_detail = interpreter._get_tensor_details(op['outputs'][0])
input_tensor_0 = tensors[op['inputs'][0]]
input_tensor_1 = tensors[op['inputs'][1]]
options = op['builtin_options']
output_tensor = tf.concat([input_tensor_0, input_tensor_1],
options['axis'],
name=output_detail['name'])
tensors[output_detail['index']] = output_tensor
else:
raise ValueError(op_type)
def main():
tf.compat.v1.disable_eager_execution()
gen_model_json()
ops, op_types = parse_json()
interpreter = tf.lite.Interpreter(model_path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print(input_details)
print(output_details)
for i in range(num_tensors):
detail = interpreter._get_tensor_details(i)
print(detail)
make_graph(ops, op_types, interpreter)
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
graph = tf.compat.v1.get_default_graph()
# writer = tf.summary.FileWriter(os.path.splitext(output_pb_path)[0])
# writer.add_graph(graph)
# writer.flush()
# writer.close()
with tf.compat.v1.Session(config=config, graph=graph) as sess:
sess.run(tf.compat.v1.global_variables_initializer())
graph_def = tf.compat.v1.graph_util.convert_variables_to_constants(
sess=sess,
input_graph_def=graph.as_graph_def(),
output_node_names=output_node_names)
with tf.io.gfile.GFile(output_pb_path, 'wb') as f:
f.write(graph_def.SerializeToString())
shutil.rmtree('saved_model', ignore_errors=True)
tf.compat.v1.saved_model.simple_save(
sess,
output_savedmodel_path,
inputs={'input': graph.get_tensor_by_name('input:0')},
outputs={
'classificators': graph.get_tensor_by_name('classificators:0'),
'regressors': graph.get_tensor_by_name('regressors:0')
})
if __name__ == '__main__':
main()
"""
$ saved_model_cli show --dir saved_model --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['input'] tensor_info:
dtype: DT_FLOAT
shape: (1, 128, 128, 3)
name: input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['classificators'] tensor_info:
dtype: DT_FLOAT
shape: (1, -1, 1)
name: classificators:0
outputs['regressors'] tensor_info:
dtype: DT_FLOAT
shape: (1, -1, 16)
name: regressors:0
Method name is: tensorflow/serving/predict
"""
$ python3 blazeface_tflite_to_pb.py
4-2-10-4. Weight Quantization from saved_model (weight-only quantization)
### tensorflow==2.2.0
import tensorflow as tf
import numpy as np
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('face_detection_front_128_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - face_detection_front_128_weight_quant.tflite")
$ python3 weight_quantization.py
4-2-10-5. Integer Quantization from saved_model (8-bit integer quantization)
### tensorflow==2.2.0
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
from PIL import Image
import os
import glob
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (128, 128))
image = image[np.newaxis,:,:,:]
image = image - 127.5
image = image * 0.007843
yield [image]
raw_test_data, info = tfds.load(name="the300w_lp", with_info=True, split="train", data_dir="~/TFDS", download=True)
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('face_detection_front_128_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - face_detection_front_128_integer_quant.tflite")
$ python3 integer_quantization.py
4-2-10-6. Full Integer Quantization from saved_model (All 8-bit integer quantization)
### tensorflow==2.2.0
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
from PIL import Image
import os
import glob
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (128, 128))
image = image[np.newaxis,:,:,:]
image = image - 127.5
image = image * 0.007843
yield [image]
raw_test_data, info = tfds.load(name="the300w_lp", with_info=True, split="train", data_dir="~/TFDS", download=False)
# Integer Quantization - Input/Output=uint8
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_quant_model = converter.convert()
with open('face_detection_front_128_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Full Integer Quantization complete! - face_detection_front_128_full_integer_quant.tflite")
$ python3 full_integer_quantization.py
4-2-10-7. Float16 Quantization from saved_model (Float16 quantization)
### tensorflow==2.2.0
import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
from PIL import Image
import os
import glob
# Float16 Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
with open('face_detection_front_128_float16_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Float16 Quantization complete! - face_detection_front_128_float16_quant.tflite")
$ python3 float16_quantization.py
4-2-10-8. Full Integer Quantization to EdgeTPU convert
$ edgetpu_compiler -s face_detection_front_128_full_integer_quant.tflite
4-3. Performance benchmarks for the quantization model (.tflite)
When benchmarking the performance of the generated .tflite file, it is very tedious to write a validation program based on the characteristics of the model every time. So I compiled and used the program for Benchmark, which is published in the official repository of Tensorflow. It is a useful tool to adjust the number of Multi-Threads for inference, and to enable XNNPACK or GPU Delegate in the boot option, which allows you to benchmark against various environments quite easily. Here, I will explain how to build and use it.
https://github.com/PINTO0309/PINTO_model_zoo#3-tflite-model-benchmark
4-3-1. Building the TFLite Model Benchmark Tool
Below are the steps to prepare only three environments that I can immediately prepare at my fingertips. The rest of the environment is up to everyone to implement.
$ sudo apt-get install python-future
## Bazel for Ubuntu18.04 x86_64 install
$ wget https://github.com/bazelbuild/bazel/releases/download/2.0.0/bazel-2.0.0-installer-linux-x86_64.sh
$ sudo chmod +x bazel-2.0.0-installer-linux-x86_64.sh
$ ./bazel-2.0.0-installer-linux-x86_64.sh
$ sudo apt-get install -y openjdk-8-jdk
## Bazel for RaspberryPi3/4 Raspbian/Debian Buster armhf install
$ wget https://github.com/PINTO0309/Bazel_bin/raw/master/2.0.0/Raspbian_Debian_Buster_armhf/openjdk-8-jdk/install.sh
$ ./install.sh
$ curl -sc /tmp/cookie \
"https://drive.google.com/uc?export=download&id=1LQUSal55R6fmawZS9zZuk6-5ZFOdUqRK" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie \
"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1LQUSal55R6fmawZS9zZuk6-5ZFOdUqRK" \
-o adoptopenjdk-8-hotspot_8u222-b10-2_armhf.deb
$ sudo apt-get install -y ./adoptopenjdk-8-hotspot_8u222-b10-2_armhf.deb
## Bazel for RaspberryPi3/4 Raspbian/Debian Buster aarch64 install
$ wget https://github.com/PINTO0309/Bazel_bin/raw/master/2.0.0/Raspbian_Debian_Buster_aarch64/openjdk-8-jdk/install.sh
$ ./install.sh
$ curl -sc /tmp/cookie \
"https://drive.google.com/uc?export=download&id=1VwLxzT3EOTbhSzwvRF2H4ChTQyTQBt3x" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie \
"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1VwLxzT3EOTbhSzwvRF2H4ChTQyTQBt3x" \
-o adoptopenjdk-8-hotspot_8u222-b10-2_arm64.deb
$ sudo apt-get install -y ./adoptopenjdk-8-hotspot_8u222-b10-2_arm64.deb
## Clone Tensorflow v2.1.0+
$ git clone --depth 1 https://github.com/tensorflow/tensorflow.git
$ cd tensorflow
## Build and run TFLite Model Benchmark Tool
## Flex Delegate disabled version, it only takes a very short time to build.
$ bazel build \
-c opt \
tensorflow/lite/tools/benchmark:benchmark_model
## Flex Delegate valid version, it takes a long time to build.
$ bazel build \
-c opt \
--config=noaws \
--config=nohdfs \
--config=nonccl \
tensorflow/lite/tools/benchmark:benchmark_model_plus_flex
4-3-2. Options for the TFLite Model Benchmark Tool
$ bazel run -c opt tensorflow/lite/tools/benchmark:benchmark_model -- --help
Flags:
--input_layer_value_files= string optional A map-like string representing value file. Each item is separated by ',', and the item value consists of input layer name and value file path separated by ':', e.g. input1:file_path1,input2:file_path2. If the input_name appears both in input_layer_value_range and input_layer_value_files, input_layer_value_range of the input_name will be ignored.
--use_xnnpack=false bool optional use XNNPack
--disable_nnapi_cpu=false bool optional Disable the NNAPI CPU device
--nnapi_accelerator_name= string optional the name of the nnapi accelerator to use (requires Android Q+)
--nnapi_execution_preference= string optional execution preference for nnapi delegate. Should be one of the following: fast_single_answer, sustained_speed, low_power, undefined
--use_nnapi=false bool optional use nnapi delegate api
--use_gpu=false bool optional use gpu
--max_delegated_partitions=0 int32 optional Max partitions to be delegated.
--profiling_output_csv_file= string optional File path to export profile data as CSV, if not set prints to stdout.
--max_profiling_buffer_entries=1024 int32 optional max profiling buffer entries
--enable_op_profiling=false bool optional enable op profiling
--require_full_delegation=false bool optional require delegate to run the entire graph
--allow_fp16=false bool optional allow fp16
--use_legacy_nnapi=false bool optional use legacy nnapi api
--num_runs=50 int32 optional expected number of runs, see also min_secs, max_secs
--input_layer_value_range= string optional A map-like string representing value range for *integer* input layers. Each item is separated by ':', and the item value consists of input layer name and integer-only range values (both low and high are inclusive) separated by ',', e.g. input1,1,2:input2,0,254
--input_layer_shape= string optional input layer shape
--input_layer= string optional input layer names
--graph= string optional graph file name
--warmup_min_secs=0.5 float optional minimum number of seconds to rerun for, potentially making the actual number of warm-up runs to be greater than warmup_runs
--warmup_runs=1 int32 optional minimum number of runs performed on initialization, to allow performance characteristics to settle, see also warmup_min_secs
--output_prefix= string optional benchmark output prefix
--benchmark_name= string optional benchmark name
--num_threads=1 int32 optional number of threads
--run_delay=-1 float optional delay between runs in seconds
--max_secs=150 float optional maximum number of seconds to rerun for, potentially making the actual number of runs to be less than num_runs. Note if --max-secs is exceeded in the middle of a run, the benchmark will continue to the end of the run but will not start the next run.
--min_secs=1 float optional minimum number of seconds to rerun for, potentially making the actual number of runs to be greater than num_runs
4-3-3. Benchmark example of a model that includes only standard Tensorflow Lite operations (No XNNPACK, 4 Threads)
$ bazel run -c opt tensorflow/lite/tools/benchmark:benchmark_model -- \
--graph=${HOME}/work/tensorflow/head_pose_estimator_integer_quant.tflite \
--num_threads=4 \
--warmup_runs=1 \
--enable_op_profiling=true
4-3-4. Benchmark example of a model that includes only standard Tensorflow Lite operations (XNNPACK available, 4 Threads)
$ bazel run -c opt tensorflow/lite/tools/benchmark:benchmark_model -- \
--graph=${HOME}/work/tensorflow/head_pose_estimator_integer_quant.tflite \
--num_threads=4 \
--warmup_runs=1 \
--use_xnnpack=true \
--enable_op_profiling=true
4-3-5. Benchmark examples of models with non-standard Tensorflow Lite operations (Flex enabled, no XNNPACK, 4 Threads)
$ bazel run \
-c opt \
--config=noaws \
--config=nohdfs \
--config=nonccl \
tensorflow/lite/tools/benchmark:benchmark_model_plus_flex -- \
--graph=${HOME}/git/tf-monodepth2/monodepth2_flexdelegate_weight_quant.tflite \
--num_threads=4 \
--warmup_runs=1 \
--enable_op_profiling=true
4-3-6. Benchmark examples of models with non-standard Tensorflow Lite operations (Flex enabled, with XNNPACK, 4 Threads)
$ bazel run \
-c opt \
--config=noaws \
--config=nohdfs \
--config=nonccl \
tensorflow/lite/tools/benchmark:benchmark_model_plus_flex -- \
--graph=${HOME}/git/tf-monodepth2/monodepth2_flexdelegate_weight_quant.tflite \
--num_threads=4 \
--warmup_runs=1 \
--use_xnnpack=true \
--enable_op_profiling=true
4-3-7. Execution log sample of Benchmark_Tool
STARTING!
Min num runs: [50]
Min runs duration (seconds): [1]
Max runs duration (seconds): [150]
Inter-run delay (seconds): [-1]
Num threads: [4]
Benchmark name: []
Output prefix: []
Min warmup runs: [1]
Min warmup runs duration (seconds): [0.5]
Graph: [/home/b920405/work/tensorflow/head_pose_estimator_integer_quant.tflite]
Input layers: []
Input shapes: []
Input value ranges: []
Input layer values files: []
Allow fp16 : [0]
Require full delegation : [0]
Enable op profiling: [1]
Max profiling buffer entries: [1024]
CSV File to export profiling data to: []
Max number of delegated partitions : [0]
Use gpu : [0]
Use xnnpack : [0]
Loaded model /home/b920405/work/tensorflow/head_pose_estimator_integer_quant.tflite
The input model file size (MB): 7.37157
Initialized session in 0.39ms.
Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds.
count=3 first=182671 curr=171990 min=171990 max=182671 avg=176216 std=4636
Running benchmark for at least 50 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
count=50 first=174371 curr=183952 min=173778 max=203173 avg=181234 std=6641
Average inference timings in us: Warmup: 176216, Init: 390, Inference: 181234
Profiling Info for Benchmark Initialization:
============================== Run Order ==============================
[node type] [start] [first] [avg ms] [%] [cdf%] [mem KB] [times called] [Name]
AllocateTensors 0.000 0.058 0.058 100.000% 100.000% 0.000 1 AllocateTensors/0
============================== Top by Computation Time ==============================
[node type] [start] [first] [avg ms] [%] [cdf%] [mem KB] [times called] [Name]
AllocateTensors 0.000 0.058 0.058 100.000% 100.000% 0.000 1 AllocateTensors/0
Number of nodes executed: 1
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
AllocateTensors 1 0.058 100.000% 100.000% 0.000 1
Timings (microseconds): count=1 curr=58
Memory (bytes): count=0
1 nodes observed
Operator-wise Profiling Info for Regular Benchmark Runs:
============================== Run Order ==============================
[node type] [start] [first] [avg ms] [%] [cdf%] [mem KB] [times called] [Name]
QUANTIZE 0.000 0.164 0.166 0.092% 0.092% 0.000 1 [input_image_tensor_int8]:0
CONV_2D 0.166 9.293 9.710 5.358% 5.449% 0.000 1 [conv2d/Relu]:1
MAX_POOL_2D 9.876 0.523 0.547 0.302% 5.751% 0.000 1 [max_pooling2d/MaxPool]:2
CONV_2D 10.423 40.758 41.859 23.097% 28.848% 0.000 1 [conv2d_2/Relu]:3
CONV_2D 52.282 73.752 76.566 42.248% 71.095% 0.000 1 [conv2d_3/Relu]:4
MAX_POOL_2D 128.848 0.259 0.261 0.144% 71.240% 0.000 1 [max_pooling2d_2/MaxPool]:5
CONV_2D 129.109 15.460 16.203 8.940% 80.180% 0.000 1 [conv2d_4/Relu]:6
CONV_2D 145.312 13.194 13.908 7.674% 87.854% 0.000 1 [conv2d_5/Relu]:7
MAX_POOL_2D 159.220 0.043 0.046 0.026% 87.880% 0.000 1 [max_pooling2d_3/MaxPool]:8
CONV_2D 159.266 4.272 4.473 2.468% 90.348% 0.000 1 [conv2d_6/Relu]:9
CONV_2D 163.740 5.437 5.745 3.170% 93.518% 0.000 1 [conv2d_7/Relu]:10
MAX_POOL_2D 169.485 0.029 0.031 0.017% 93.535% 0.000 1 [max_pooling2d_4/MaxPool]:11
CONV_2D 169.516 4.356 4.558 2.515% 96.050% 0.000 1 [conv2d_8/Relu]:12
FULLY_CONNECTED 174.074 6.666 6.992 3.858% 99.908% 0.000 1 [dense/Relu]:13
FULLY_CONNECTED 181.066 0.160 0.167 0.092% 100.000% 0.000 1 [logits/BiasAdd_int8]:14
DEQUANTIZE 181.232 0.001 0.001 0.000% 100.000% 0.000 1 [logits/BiasAdd]:15
============================== Top by Computation Time ==============================
[node type] [start] [first] [avg ms] [%] [cdf%] [mem KB] [times called] [Name]
CONV_2D 52.282 73.752 76.566 42.248% 42.248% 0.000 1 [conv2d_3/Relu]:4
CONV_2D 10.423 40.758 41.859 23.097% 65.344% 0.000 1 [conv2d_2/Relu]:3
CONV_2D 129.109 15.460 16.203 8.940% 74.285% 0.000 1 [conv2d_4/Relu]:6
CONV_2D 145.312 13.194 13.908 7.674% 81.959% 0.000 1 [conv2d_5/Relu]:7
CONV_2D 0.166 9.293 9.710 5.358% 87.316% 0.000 1 [conv2d/Relu]:1
FULLY_CONNECTED 174.074 6.666 6.992 3.858% 91.174% 0.000 1 [dense/Relu]:13
CONV_2D 163.740 5.437 5.745 3.170% 94.344% 0.000 1 [conv2d_7/Relu]:10
CONV_2D 169.516 4.356 4.558 2.515% 96.859% 0.000 1 [conv2d_8/Relu]:12
CONV_2D 159.266 4.272 4.473 2.468% 99.327% 0.000 1 [conv2d_6/Relu]:9
MAX_POOL_2D 9.876 0.523 0.547 0.302% 99.629% 0.000 1 [max_pooling2d/MaxPool]:2
Number of nodes executed: 16
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 8 173.016 95.471% 95.471% 0.000 8
FULLY_CONNECTED 2 7.157 3.949% 99.421% 0.000 2
MAX_POOL_2D 4 0.884 0.488% 99.908% 0.000 4
QUANTIZE 1 0.166 0.092% 100.000% 0.000 1
DEQUANTIZE 1 0.000 0.000% 100.000% 0.000 1
Timings (microseconds): count=50 first=174367 curr=183949 min=173776 max=203169 avg=181231 std=6640
Memory (bytes): count=0
16 nodes observed
Note: as the benchmark tool itself affects memory footprint, the following is only APPROXIMATE to the actual memory footprint of the model at runtime. Take the information at your discretion.
Peak memory footprint (MB): init=0 overall=14.7656
5. Finally
I'm not good at English, so it was very hard for me to write an article in English. Please point out any oddities in the text.