タイムスタンプ
初回投稿日:2020年06月26日
最終更新日:2020年07月18日
対象読者
この投稿は、ちょうど20年ほど前にソフトウェアエンジニアとしてのピークを迎えていた当時30歳くらいの自分自身に宛てて書いた手紙です。
したがって、この内容は個人的なものであり、くたびれた老兵の戯言であり、ピントがずれ時代を捉えきれておらず、網羅的でもなければ他者には通じないアナロジーに溢れていて、多くの方にとって役に立たないばかりか、酷い勘違いや致命的な間違いを含んでいるかもしれません。
とは言うものの、現在の私のように、今もなお 20 年前の知見や思考パターンが生活のベースになっている方、新しい知識や用語は押さえているもののそれが今一つ自身の血肉になっていないと感じている方、最近の技術トレンドを押さえたいけれど情報の洪水に溺れそうになり何から手を付ければいいかわからないという方にとっては、あるいはこの記事が役に立つようなことがあるかもしれません。
何について書いた記事か
この記事は、偏差値 50 の平均的なソフトウェア技術者として今後 20 年間生計を立てていく上で、今、私自身が学んでおいた方が良いと思われる事柄を列挙し、それらの学習環境を Windows PC に導入する方法を記し、気になったところは実際に触ってみてその所感を述べたものです。
具体的には以下のようなものになります。
目次
1. プラットフォームの構築
1.1. BIOS と Windows の設定
1.2. VirtualBox
1.3. Vagrant
1.4. CentOS
1.5. RLogin
2. ポピュラーなプログラミング言語
2.1. C / C++
2.2. Java
2.3. JavaScript
2.4. Ruby
2.5. Python
3. モダンなプログラミング言語
3.1. TypeScript
3.2. Haskell
3.3. Go
3.4. Rust
4. 作業を助けてくれる道具
4.1. Git
4.2. Vim
5. 身だしなみを整えるための道具
5.1. React (Hooks with TypeScript)
5.2. Bootstrap
5.3. Font Awesome
前提条件
上述のとおり、これは当時の自分自身に宛てて書いた手紙なので、この記事を読み進めるにあたり、コンピュータ・サイエンスに関する当時の私と同程度の知識が必要となるでしょう。
具体的には以下のようなものになります。
- Java など、静的型付きの手続き型オブジェクト指向プログラミング言語を触ったことがある。
- HTML や CSS や JavaScript のコードを書いたことがある。
- UNIX クローン OS を触ったことがある。具体的には echo, cat, pwd, ls, grep, vi などを使ったことがあり、パイプライン / リダイレクト / ワイルドカード展開などコマンドライン・インタプリタの基本的な知識を持っている。
- TCP/IP に関する基礎的な知識を持っている。
また、本稿で使用するハードウェアおよびオペレーティング・システムは以下のとおりです。
- HW: ThinkPad X1 Extreme
- OS: Windows 10 x64 Version 1903
はじめに
現在、西暦2020年。
これは50代前半である「俺」が、西暦2000年頃の「お前」に宛てて書いた手紙だ。
当時のお前は30代前半で、技術者としてちょうどピークを迎えている頃だ。
その頃からお前は、向いていないと思いながらもマネジメントに手を出し始め、居心地の良い技術的な現場から少しづつ離れていくことになる。
その後お前は、仕事という大義名分のもとに物静かで良心的な部下を激しく罵倒したり、「Win-Win」という都合の良い言葉でビジネスパートナーに無理難題を押し付けたり、そうやってたくさんの人々を傷つけていく一方、顧客や上司の前でヘラヘラ笑いながら長いものに巻かれて生きているうちに、いつの間にか名ばかりの取締役となり、株主へのアリバイ作りを考え続けること以外では誰かに必要とされる手応えを感じることができないつまらない人間に成り下がってしまうんだ。
当時のお前は、定年までの雇用が保証された会社で働いた後、引退後は悠々自適な年金生活でも送るのだろうと漠然と考えていたが、現実はだいぶ違っている。
幸いなことに大切な家族もいるし、少数ではあるが信頼できる友人もいる。
とはいうものの、この先、年金だけで生活できる見通しなど立っていないし、そんなものは貰えない時代が来ると考えた方が良さそうだ。また、仮に貰えたとしてもそれで充分なはずはなく、それを補うための金が貯まっているわけでもない。もちろんこれから貯まる見込みもない。
そんな将来を見据えて俺は、「円という価値」を貯める代わりに「知識という価値」を活用することで生きてゆくことを決意し、もう一度エンジニアに返り咲くことにしたんだ。
そう、これは、
西暦 2020 年代 に 50 代の俺が、
西暦 2040 年代 の 70 代になっても通用する技術者でいるために、
今学ぶべきことは何か?
そのための準備として何をすればよいのか?
せめて世の中の平均的な偏差値 50 のプログラマになるためにどうすればよいか?
俺が導いたその答えを、
西暦 2000 年代 の 30 代のお前に教えてやるために書いた手紙だ。
1. プラットフォームの構築
さて、お前が生きている時代の20年後、西暦2020年の世の中はどうなっていると思う?
今の若い奴らは何というか、予想に反してものすごくカッコいい。。
最近、w.o.d. という 3 ピース・バンドの楽曲 を聴いたんだが、ギターのブラッシング・ノイズといい、ゴリゴリのベースといい、スティックのショルダーで叩く豪快なハイハットといい、ロック・ミュージックは現在進行形だ。
幼い頃、親父に「お前も大人になったら分かるさ」と言われただろう?
もちろん、わかったこともたくさんあるが、未だにわからないこともたくさんあるんだ。そんな俺を今の若い奴らの音楽は勇気づけてくれるし楽しませてくれる。もの凄い時代だ。
音楽だけじゃない。
オープン・ソース・ソフトウェア文化が定着した現代では、ソフトウェア開発ツールはほとんど無償で提供されているし、学習のための質の高い情報が無償で手に入る時代になっている。
預言者が多すぎて情報の洪水に飲み込まれてしまいそうになるが、モチベーションの高い若者にとっては(もちろん俺のような老いぼれにも)、とても恵まれた時代になっている。
OSS 文化の中心を担っているのは Linux であり、Free BSD や Net BSD の話はあまり聞かれなくなった。そして、お前の想定どおり、どんなにグラフィカル・ユーザ・インターフェースが進化しようとも、UNIX 系 OS のコマンドライン・インタプリタである shell (Bash) は、現在も現役バリバリの優秀なツールである。
だから、これらの無償のツールを利用するために、お前は自分の Windows システムに Linux を導入することになるが、現代ではそのために補助記憶装置のパーティションを切り直したり、ブートローダを導入する必要はない。
お前の使う Thinkpad と Windows には仮想化システムが組み込まれており、ホスト OS である Windows に、ゲスト OS として Linux を迎え入れることができるのだ。
仮想化の方法はいろいろあるようだが、今回は VirtualBox + Vagrant で仮想環境を構築することにしよう。
1.1. BIOS と Windows の設定
ハードウェア: ThinkPad X1 Extreme
OS: Windows 10 x64 Version 1903
お前の使っている Thinkpad に "IBM" のロゴが刻印されていないことに驚いたか? でもこれはバッタもんじゃないから安心しろ。Thinkpad は、今もなお "大和" の名が付く場所で開発が続けられている。「和魂洋才」が「和魂漢才」になったというわけだ。
まずは BIOS だ。
Thinkpad の BIOS 設定を以下のとおり変更すれば良い。
[Security] ->
[Intel Virtualization Echnology] または
[Intel VT-d Feature] のいずれかを Enabled にする。
設定を保存して再起動したら、Windows で以下の設定をすれば完了だ。
[コントロールパネル] ->
[プログラムと機能] ->
[Windows 機能の有効化または無効化] ->
[仮想マシンプラットフォーム] のチェックを外す。
参考サイト
Lenovo サポート - Virtualization Technology (VT-X)を有効にするにはThinkPad 以外のハードウェアでもそれほど違いはないはずだし、ネットワークを検索すればすぐに良い情報が見つかるだろう。
1.2. VirtualBox の導入
VirtualBox は、PC と連携して Windows 上に ハードウェア環境をエミュレートしてくれるソフトウェアだ。ホスト OS の Windows から見ればひとつのアプリケーションに過ぎないが、VirtualBox 上で動作するゲスト OS(今回は Linux を導入)からは、通常のハードウェアで動いているのとあまり違いがないように見えるというわけだ。
導入は特に難しくないが、後述の Vargrant がサポートしている VirtualBox のバージョンを確認しておいた方が良いだろう。
Vagrant Docs (Providers/VirtualBox)
1.2.1. インストール
以下のサイトから VirtualBox 6.1 をダウンロードする。
VirtualBox.org
ダウンロードした VirtualBox-6.1.4-136177-Win.exe を実行する。
今回は、以下の変更以外はデフォルトのままとしたが、このあたりは好みで設定すれば良いだろう。
- デスクトップにショートカットを作らないようにする
- Quick Launch Bar にショートカットを作らないようにする
なお、インストール中に oracle corporation ユニバーサルシリアルバスコントローラのインストールを許可するかどうか尋ねられたら「許可」すればよい。
1.3. Vagrant の導入
Vagrant は、VirtualBox などで構築した仮想マシンに、構成済みの OS イメージを簡単に導入できるようサポートしてくれるソフトウェアだ。Gentoo Linux のような、すべてのソフトウェアをそのマシン用に最適化するなどといった細かい調整をすることができない代わりに、Vagrant はまるで、棚からお気に入りのアルバムを取り出して CD プレーヤーにセットするような感覚で、OS 環境を仮想マシンに導入したり、逆に取り出したりすることができるものだ。
1.3.1. インストール
以下のサイトから Vagrant 2.2.7 (Windows 64bit) をダウンロードする。
Vagrant by HashiCorp
ダウンロードした vagrant_2.2.7_x86_64.msi を実行する。
- Windows Defender SmartScreen の警告が表示されたら、[詳細情報] -> [実行] を選択。
- インストールオプションはすべてデフォルトのまま
1.4. CentOS 8 の導入
ゲスト OS の Linux のディストリビューションは、 CentOS の最新バージョンである 8 を入れることにしよう。
CentOS は Red Hat Enterprise Linux のクローンで、有償サポートのない Red Hat だと思っておけば良いだろう。ちなみに Debian GNU/Linux の派生である Ubuntu も人気のあるディストリビューションだ。
導入する OS は、今回のようなプログラミング言語の勉強が目的であれば、CentOS でも Ubuntu でも他のディストリビューションでも何でも良いと思う。パッケージのインストール方法くらいしか違いはないだろう。
1.4.1. インストール
コマンドプロンプトを起動し、仮想環境用に適当なディレクトリを作成する。
C:\ANY-DIR> mkdir YOUR-VM-DIR
C:\ANY-DIR> dir YOUR-VM-DIR
先ほどインストールした Vagrant のバージョンを確認する。
C:\ANY-DIR\YOUR-VM-DIR> vagrant version
Installed Version: 2.2.7
Latest Version: 2.2.7
CentOS 8 のイメージを導入する。
(イメージファイルはカレントディレクトリ配下に作成される)
C:\ANY-DIR\YOUR-VM-DIR> vagrant init bento/centos-8
Vagrant で導入可能な VirtualBox 用の VM イメージは以下で検索可能。
Discover Vagrant Boxes (Provider - VirtualBox)
インストールした CentOS 8 を起動する。
C:\ANY-DIR\YOUR-VM-DIR> vagrant up
Bringing machine 'default' up with 'virtualbox' provider...
今回は VM イメージを一つしか導入していないため ID パラメータを省略しているが、ID を省略した場合はカレントディレクトリの Vagrantfile の内容に従って VM イメージ(今回は bento/centos-8)が立ち上がる。
次に Vagrant が管理する VM イメージの一覧を表示してみる。
C:\ANY-DIR\YOUR-VM-DIR> vagrant global-status
id name provider state directory
------------------------------------------------------------------------
5411d90 default virtualbox running C:/ANY-DIR/YOUR-VM-DIR
state が running になっていることが確認できたので、ここで一度 CentOS 8 を停止する。
C:\ANY-DIR\YOUR-VM-DIR> vagrant halt
==> default: Attempting graceful shutdown of VM...
次に、ホスト OS (Windows 10) から TCP/IP でアクセスできるよう、ゲスト OS (CentOS 8) へ IP アドレスを割り当てる。テキストエディタで Vagrantfile を開き、
C:\ANY-DIR\YOUR-VM-DIR> notepad Vagrantfile
以下の行のコメントアウトを外して、ファイルを上書き保存する。
(IP アドレスは環境に合わせて適当に変更すれば良いだろう)
# config.vm.network "private_network", ip: "192.168.33.10"
↓
config.vm.network "private_network", ip: "192.168.33.10"
改めて CentOS 8 を起動する。
C:\ANY-DIR\YOUR-VM-DIR> vagrant up
Bringing machine 'default' up with 'virtualbox' provider...
ホスト OS (Windows 10) 上で ネットワークのルーティング・テーブルを確認してみる。
C:\ANY-DIR\YOUR-VM-DIR> route print
...
IPv4 ルート テーブル
===========================================================================
アクティブ ルート:
ネットワーク宛先 ネットマスク ゲートウェイ インターフェイス メトリック
...
192.168.33.0 255.255.255.0 リンク上 192.168.33.1 281
...
ルーティングテーブルに、宛先が 192.168.33.0/24 のエントリが記されていることが確認できた。
これでホストOS (Windows10) から、ゲストOS (CentOS 8) への接続ができるはずなので、Vagrant の ssh 機能を利用して接続してみる。
接続先となるゲスト OS (CentOS 8) の id を確認したら、
C:\ANY-DIR\YOUR-VM-DIR> vagrant global-status
id name provider state directory
------------------------------------------------------------------------
5411d90 default virtualbox running C:/ANY-DIR/YOUR-VM-DIR
Vagrant の ssh クライアント機能を使って接続してみる。
C:\ANY-DIR\YOUR-VM-DIR> vagrant ssh 5411d90
...
[vagrant@localhost ~]$
無事ログインできた。
接続できたついでに、ここでゲストOS (CentOS 8) に、DNS のリゾルバの設定をしておく。
今回は Google のパブリック DNS を登録しておこう。
/etc/sysconfig/network-scripts/ifcfg-eth0 を vi で開いて、
[vagrant@localhost ~]$ sudo vi /etc/sysconfig//network-scripts/ifcfg-eth0
末尾に以下の 2 行を追記して保存する。
DNS1=8.8.8.8
DNS2=8.8.4.4
名前解決できるかどうか確認し、
[vagrant@localhost ~]$ ping www.google.com
PING www.google.com (172.217.161.68) 56(84) bytes of data.
問題ないのでログアウトする。
[vagrant@localhost ~]$ exit
logout
Connection to 127.0.0.1 closed.
1.5. RLogin の導入
Vagrant の ssh クライアント機能はちょっと使い勝手が悪いので、ホストOS (Windows 10) に RLogin を導入するが、ターミナルソフトであれば何でも良いと思う。
1.5.1. インストール
以下のサイトから「実行プログラム(64bit)」のリンクをクリックして zip ファイルをダウンロードする。
Nanno SoftLibrary RLogin
インストーラは付いていない。zip を解凍すると実行形式ファイル RLogin.exe が展開されるので、これを適当なディレクトリに入れておく。
ちなみに、RLogin で 192.168.33.10 へ接続する際はパスワード認証が必要になるが、初期値は以下のとおりである。
user: vagrant
pass: vagrant
これでプラットフォームの構築は終了だ。
この後の作業はすべてゲスト OS (Cent OS) に RLogin (または他のターミナル・ソフトウェア) で ssh 接続している前提で書いている。
2. ポピュラーなプログラミング言語
ここでは、比較的ポピュラーなプログラミング言語の環境を作り、簡単なプログラムを書いて動かしていく。
今更感があるかもしれないが、これらの言語もこの空白の20年の間に進化しているため、今後、いろいろ確認したいことも出てくるだろう。
2.1. C / C++
お前は解ってくれると思うが、C は Bob Dylan であり、 C++ は The Beatles のようなものだ。
2020 年になってもプレイリストに入れておくのがマナーというものだろう。
2.1.1. インストール
まずはインストール可能なパッケージを確認する。
$ dnf search gcc-c++
====================================== Name Exactly Matched: gcc-c++ =======================================
gcc-c++.x86_64 : C++ support for GCC
gcc-c++.x86_64 : C++ support for GCC
========================================== Name Matched: gcc-c++ ===========================================
gcc-toolset-9-gcc-c++.x86_64 : C++ support for GCC version 9
C++ support for GCC をインストール。
$ sudo dnf install gcc-c++
...
Complete!
$ gcc --version
gcc (GCC) 8.3.1 20190507 (Red Hat 8.3.1-4)
お決まりのコードをコンパイル、実行してみる。
$ mkdir ~/learn_c
$ cd ~/learn_c
$ echo '
> #include <stdio.h>
> int main() { printf("hello, world\n"); }
> ' > hello.c
$ gcc hello.c -o hello
$ ./hello
hello, world
オーケー。次に C++ だ。
$ mkdir ~/learn_cpp
$ cd ~/learn_cpp
$ echo '
> #include <iostream>
> using namespace std;
> int main() { cout << "hello, world" << endl; }
> ' > hello.cpp
$ g++ hello.cpp -o hello
$ ./hello
hello, world
こちらも問題ないようだ。
2.1.2. この後に学ぶこと
おそらく俺が今後 C / C++ を積極的に書くようなことはないと思うが、逆にスルーし続けることもないだろうと思う。C++ も古い言語のままという訳ではなく日々進化している。例えば、ISO により 2011 年に承認された C++11 という国際規格では、この記事の後半に登場する Rust で採用されている変数束縛やムーブセマンティクスの概念が導入されている。
2.2. Java
次はお前にとって一番因縁のある言語 Java だ。
今思うと Java は、なんというか、あのアイルランドから羽ばたき巨大バンドにまでのし上がった 4 人組 U2 のようだ。
お前は驚くかもしれないが、Sun Microsystems は 2010 年に Oracle に吸収合併された。
そしてちょっとややこしいのだが、Oracle JDK は 2019 年にライセンス条項が変更されているため、今回は OpenJDK という OSS 版の JDK をインストールすることにする。
2.2.1. インストール
まずはインストール可能なパッケージを確認する。
なんと最新バージョンは 11 だ (Oracle JDK の最新は 14)。
$ dnf search java-11
================================================ Name Matched: java-11 ================================================
java-11-openjdk.x86_64 : OpenJDK Runtime Environment 11
java-11-openjdk-src.x86_64 : OpenJDK Source Bundle 11
java-11-openjdk-demo.x86_64 : OpenJDK Demos 11
java-11-openjdk-devel.x86_64 : OpenJDK Development Environment 11
java-11-openjdk-jmods.x86_64 : JMods for OpenJDK 11
java-11-openjdk-javadoc.x86_64 : OpenJDK 11 API documentation
java-11-openjdk-headless.x86_64 : OpenJDK Headless Runtime Environment 11
java-11-openjdk-javadoc-zip.x86_64 : OpenJDK 11 API documentation compressed in single archive
OpenJDK Development Environment 11 をインストール。
$ sudo dnf install java-11-openjdk-devel
...
Complete!
2.2.2. 検証
コンパイル、実行してみる。
$ mkdir ~/learn_java
$ cd ~/learn_java
$ echo '
> public class HelloWorld {
> public static void main(String[] args) {
> System.out.println("hello, world");
> }
> }
> ' > HelloWorld.java
$ javac HelloWorld.java
$ java HelloWorld
hello, world
インストールに問題ないことが確認できたので、次に、この空白の20年間で Java がどんな進化を遂げたのかを簡単に確認する。
2.2.3. Java SE 5.0 の追加機能を試す
これは Microsoft の C# を意識したのだと思うが、2004 年にリリースされた Java5 の目玉は Autoboxing と Generics だろう。
まずは Autoboxing を検証してみる。
public class Autoboxing {
public static void main(String[] args) {
Integer obj = 1;
System.out.println("obj:" + obj);
int num = obj;
System.out.println("num:" + num);
}
}
$ javac -Xlint Autoboxing.java
$ java Autoboxing
obj:1
num:1
ちなみに、Integer obj = new Integer(1); のような書き方は推奨されないようで、コンパイル時に Warning が出る。
次に Generics だが、まあこれは C++ で言うところの Template だ。
今回はメソッドのジェネリクスを検証してみる。
public class Generics {
private static <T> T getAny(T t) {
return t;
}
public static void main(String[] args) {
int n = 1;
System.out.println("n: " + getAny(n));
Double d = 1.0;
System.out.println("d: " + getAny(d));
String s = "string";
System.out.println("s: " + getAny(s));
}
}
[~/learn_java]$ javac Generics.java
[~/learn_java]$ java Generics
n: 1
d: 1.0
s: string
2.2.4. Java SE 8 の追加機能を試す
2014 年 の Java8 の目玉はなんと言ってもラムダ式 と Stream API だろう。
これにより Java でもトレンドを意識した簡素な表現ができるようになったわけだが、クラスから切り離して振舞いを定義することができない Java のメソッドを高階関数のように扱うために考えられたのが「関数型インターフェース」なのだろう。
以下のとおり、①の伝統的な書き方に比べて②のラムダ式ではとても簡素に表現できる。
また、正直、③はエラーになるだろうと思って試しに書いたものだったのだが、なんとコンパイルが通ってしまった。他の言語での表現と同じように、メソッド・ブロックだけでなく return と セミコロンも省略でき、ラムダ式の右辺で評価された値がメソッドの戻り値になるようだ。
public class Lambda {
private interface FuncTypeIF {
public abstract String extra(String s);
}
public static void main(String[] args) {
FuncTypeIF funcTypeObj;
funcTypeObj = new FuncTypeIF() { //
public String extra(String s) { //
return "***" + s + "***"; // ①伝統的な表現
} //
}; //
System.out.println(funcTypeObj.extra("foo"));
funcTypeObj = s -> { //
return "!!!" + s + "!!!"; // ②ラムダでの表現
}; //
System.out.println(funcTypeObj.extra("bar"));
funcTypeObj = s -> "???" + s + "???"; // ③更に簡素なラムダ
System.out.println(funcTypeObj.extra("baz"));
}
}
[~/learn_java]$ javac Lambda.java
[~/learn_java]$ java Lambda
***foo***
!!!bar!!!
???baz???
ちなみに、もう一つ驚いたことがあった。
以下のコードで変数 extraStr を final 指定していないにも関わらずコンパイルが通ったのだ。これはもしやクロージャ的な挙動をするのではないかと期待して、このコードのコメント部分を外したものを改めてコンパイルしてみたのだが、extraStr は実質的に final でなければならないと怒られてしまった。
public class Lambda2 {
private interface FuncTypeIF {
public abstract String extra(String s);
}
public static void main(String[] args) {
String extraStr; // <- final 指定していない
FuncTypeIF funcTypeObj;
extraStr = "***";
funcTypeObj = s -> extraStr + s + extraStr;
// extraStr = "!!!"; // <- このコメントを外すとコンパイルエラー
System.out.println(funcTypeObj.extra("foo"));
}
}
続いて Stream API だが、これは大体想定どおりの動きをすることがわかった。
まあ、このコードをお前が 20 年前に目にしていたらきっと感動したことだろう。
import java.util.List;
import java.util.Arrays;
public class Stream {
public static void main(String[] args) {
Integer[] numArray = {1, 2, 3, 4, 5, 6, 7, 8};
List<Integer> numList = Arrays.asList(numArray);
int result = numList.stream()
.map(n -> n * n) // それぞれの要素を2乗して
.filter(n -> n % 2 == 0) // 偶数のものだけ集めて
.reduce((r, v) -> r + v) // たたみ込む
.get();
System.out.println("result:" + result);
}
}
$ javac Stream.java
$ java Stream
result:120
2.2.5. Java SE 10 の追加機能を試す
最後に 2018 年の Java10 で追加されたローカル変数の型推論機能を確認してみる。
java で var なんてお前は笑うかもしれないが、長い型名を使うときなどは確かに楽かもしれない。
public class TypeInference {
public static void main(String[] args) {
var i = 1;
var s = "two";
var d = Double.valueOf(3);
System.out.println(i + s + d);
}
}
$ javac TypeInference.java
$ java TypeInference
1two3.0
2.2.6. この後に学ぶこと
やはり 20 年という時間はすごい。ラムダとか var とかを最初に知ったときは、 Java らしくないし、わざわざ流行りに乗らなくてもいいんじゃないかと感じたが、思ったよりずっと良かった。
まあ、今回はまだ表面をなぞっただけで、他にも Java8 のアノテーションや、Java9 の module, JShell, Flow API など、まだまだ学ばなければならないことだらけだが、今はこのくらいにしておこう。
あと、これは投稿後にこの記事を読んだ wx257osn2 さん が Java SE 7 で導入された try-with-resources 文について教えてくれたんだが、なるほどこれは重要だ。
これを使うことで try-finally で感じるストレスはかなり軽減されるだろう。
2.3. JavaScript
さて、ここで JavaScript のご登場だ。そう。当時お前が苦手にしていたアイツだ。
Google と Node.js のおかげで、今や JavaScript は大スターだ。
粗野でやんちゃだった JavaScript は、まるで Malcolm McLaren にプロデュースされた The Sex Pistols のように大きく羽ばたき、もはや一大文化になっている。
2.3.1. インストール
インストール可能なパッケージを確認する。
$ dnf search nodejs
======================================= Name Exactly Matched: nodejs =======================================
nodejs.x86_64 : JavaScript runtime
nodejs.x86_64 : JavaScript runtime
=========================================== Name Matched: nodejs ===========================================
nodejs-docs.noarch : Node.js API documentation
nodejs-docs.noarch : Node.js API documentation
nodejs-devel.x86_64 : JavaScript runtime - development headers
nodejs-nodemon.noarch : Simple monitor script for use during development of a node.js app
nodejs-packaging.noarch : RPM Macros and Utilities for Node.js Packaging
JavaScript runtime をインストールする。
$ sudo dnf install nodejs
...
Complete!
2.3.2. 検証
インストールできたようなので、まずはインタプリタを触ってみよう。
$ node
Welcome to Node.js v12.16.1.
Type ".help" for more information.
> const hello = () => "hello, world"
> console.log(hello())
hello, world
> .exit
$
上記のとおり、今や猫も杓子も「アロー!アロー!」と、H を発音できないフランス人のように挨拶する時代だ。
JavaScript (ECMAScript) は、2015 年の ES6 からアロー関数が使えるようになっている。
2.3.3. サーバープログラム
次に簡単な HTTP サーバのプログラムを書いて動かしてみよう。
$ node << EOF
require("http").createServer((req, res) => {
res.writeHead(200, {"Content-Type": "text/plain"});
res.end("hello, world");
}).listen(18080);
EOF
ホストOS (Windows 10) の Web ブラウザで http://192.168.33.10:18080/ にアクセスすればこのプログラムのレスポンスを確認できる。お前は衝撃を受けただろうが、JavaScript でサーバサイドのコードを書く日がくるなんて、俺にとっても感慨深いものがある。
2.3.4. 今どきの JavaScript
Java の Stream API で書いたのと同じコードを JavaScript で書いてみる。
$ node
> [1,2,3,4,5,6,7,8].map(n => n*n).filter(n => n%2===0).reduce((r,v) => r+v)
120
> .exit
ちょっとしたコードをこうやって実際に書いてみると、動的型付き言語のカジュアルさは魅力的だ。
まるで "No thinking! Just feeling!" とでも言われているようだ。
2.3.5. この後に学ぶこと
他にも ES6 では、お前にもなじみ深いクラスベースの考え方が導入され「継承」が扱えるようになったり、2017 年の ES8 では非同期関数も導入されている。
また Node.js に付属するパッケージ・マネージャの npm は今や必須のツールだし、HTTP クライアント側で動かすコードを書くなら Babel も知っておく必要があるだろう。
まあ後述の TypeScript も含めて、俺が今後どんな言語を使うにせよ、Web で UI をやる限り JavaScript からは逃れられないということだ。
2.4. Ruby
次は、お前も一目置いていた Ruby だ。
日本生まれの Ruby は、例えるなら、お前にとっての 浅井健一 のような存在だろう。
ちょっと話は逸れるが、お茶の水女子大学に同姓同名の先生がいて、OCaml を使ったデザインレシピの本を書いている。
プログラミングの基礎 浅井健一著
Ruby は Rails という MVC フレームワークの登場でいつの間にか人気者になっていたが、今は少し下火のようだ。
でもやはり国産は良い。あの MIDI は最初の規格から40年近くを経てバージョン 2.0 の話が持ち上がってるし、お前の時代に一世を風靡した ITRON は最近は元気がなくなってしまったが、後継の T-Kernel は「はやぶさ 2 」という探査機の制御に使われていて、小惑星で採取したサンプルを背負い、現在、地球を目指して絶賛凱旋中だ。
かつて広重や北斎が西洋の印象派達にダゲレオタイプに立ち向かう勇気を与えたように、 川久保玲 と 山本耀司 がヨーロッパに喧嘩をふっかけモード界をゲームチェンジさせたように、同じ風景、同じ気候、同じ文化に育まれた人たちが良いものを生み出し世界中で評価され親しまれているというのは、本当に心に染み入るものがある。
だからやはり Ruby は手元に置いておきたい。そういうことだ。
2.4.1. インストール
他の言語と同様に dnf を使ってインストールしても良いのだが、Ruby では rbenv や RVM などのサードパーティ製ツールを使って、異なるバージョンのインタプリタを同居させ、プロジェクトごとに切り替えて使う方法が一般的なようだ。
Ruby オフィシャルサイト
ruby-lang.org - Rubyのインストール
ということで、rbenv を使ってインストールしてみよう。
2.4.1.1. Git のインストール
rbenv は GitHub に置かれているのでまずは Git をインストールする。
詳しいことは後述するが、まあ何というか、Git は RCS や CVS のような構成管理ツールで、世界中の多くのプロジェクトが GitHub という Web サービス上に Git のリポジトリを作って、そこでソースコードを公開するのが一般的になっている。
$ sudo dnf -y install git
...
Complete!
$ git --version
git version 2.18.2
2.4.1.2. rbenv のインストール
rbenv は Ruby のバージョンを切り替えるツールだ。
GitHub 上の rbenv のリポジトリの複製をローカル環境へコピーする。
(cvs checkout のようなものだ)
$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv
~/.bash_profile の末尾に以下を追記して、
export PATH="$HOME/.rbenv/bin:$PATH"
eval "$(rbenv init -)"
パスを通す。
$ source ~/.bash_profile
2.4.1.3. ruby-build のインストール
ruby-build は rbenv のプラグインで、Ruby をインストールするために必要なので、これをインストールする。
$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build
2.4.1.4. openssl-devel と readline-devel のインストール
Ruby のインストールに必要なパッケージのようなので、これらをインストールする。
$ sudo dnf install openssl-devel readline-devel
...
Complete!
2.4.1.5. Ruby のインストール
rbenv install --list で確認すると最新は 2.7.0 のようなので、これをインストールして、
$ rbenv install -v 2.7.0
確認する。
$ rbenv versions
* 2.7.0 (set by /home/yourname/.rbenv/version)
2.4.2. 検証
Java や JavaScript と同じプログラムを書いて動かしてみる。
$ irb
irb(main):001:0> (1..8).map{|n| n*n}.select{|n| n%2==0}.inject{|r,v| r+v}
=> 120
irb(main):002:0> exit
$
【2020年7月18日追記】
これは投稿後にこの記事を読んだ scivola さん が、上記コードのもっと Ruby らしい(しかも効率の良い)書き方を教えてくれたんだが、以下がそのコードだ。
(1..8).select(&:even?).map{ |n| n * n }.sum
&:even? は select{|n| n%2==0} のシンタックスシュガーだ。
これは &:method 形式の構文で、以下のような条件が揃った場合に使うことができる。
- ブロックに渡す引数 (上記の場合は n) が 1 つだけ
- method が n のメソッド (n.method) である
- method の引数がない
- ブロック内で、この method を呼び出す以外の処理がない
また、sum も inject{|r,v| r+v} のシンタックスシュガーで、このようなメソッドが用意されているところも とても Ruby らしいと思う。
なお、教えてくれたコードは select と map が入れ替わっているが、俺が書いた時には、この方が効率が良いということに気づかなかった。
ここではあまり深掘りしないが、Ruby は、! や ? を使ったメソッド名(しかもスネークケース)や、モンキーパッチ、ダックタイピング、ミックスインなど確かに書いていて楽しい言語だと思う。ただ俺のような誘惑に弱い人間にとっては、いかに簡素に書くかを追求しているうちに、プログラミングという問題解決のための手段がいつの間にかそれ自体を楽しむという目的になってしまいそうで怖い。
2.4.3. この後に学ぶこと
とは言うものの、今後 Rails を使う可能性は否定できないし、評判の良い無償の教材もあるので、いつでも勉強できるようにしておきたい。
公式ドキュメント
Ruby 2.7.0 リファレンスマニュアル評判の良い無償の教材
Ruby on Rails チュートリアル
2.5. Python
次は Python だ。
そう。お前が紀伊国屋書店で手に取ったオライリーの、あの表紙のネズミがニシキヘビに捕食されることを想像して切ない気持ちになり、そっと棚に戻したアイツだ。
実は 2012 年に、あの Google が深層学習という新しいアルゴリズムを使って、コンピュータに猫を認識させてしまったんだ。シュレーディンガー以降最大級とも言える、この猫を巻き込んだ大事件はその後、一大 AI ブームを巻き起こし、AI 関連のライブラリが豊富な Python が注目されるようになったんだ。
そういう意味では、そうだな Python は、 The Edge 以降、ギターでお前に大きな衝撃をもたらした Radiohead の Jonny Greenwood ようなものかもしれない。
2.5.1. インストール
Python 3.6 をインストールする。
$ sudo dnf -y install python36
...
Complete!
Python の魅力は、何と言ってもその豊富なパッケージだろうということで、今回は Python に付属する pip というパッケージマネージャを使って、SciPy.org のトップページ に載っている以下のパッケージをインストールしてみる。
| パッケージ | 読み | 機能 |
|---|---|---|
| NumPy | ナムパイ | 多次元配列パッケージ |
| Pandas | パンダズ | データ構造分析パッケージ |
| Matplotlib | マットプロットリブ | 2次元プロットパッケージ |
| SciPy | サイパイ | 科学技術計算パッケージ |
Python の膨大なパッケージはここで検索することができる。
Python Package Index
なお、ライブラリはグローバルにインストールすることもできるが、先々、依存関係などで苦労したくないので、ホーム・ディレクトリ配下にインストールすることにする。
pip はローカル指定すると、$PYTHONUSERBASE で指定したパスへパッケージをダウンロードするようだ。以下のコマンドでそれを確認することができる。
$ python3 -m site --user-base
/home/yourname/.local
うーん。ホームディレクトリ直下の .local というディレクトリが使われるのは嫌なので、これを変更しよう。
$ mkdir -p ~/learn_python/.local
$ echo 'export PYTHONUSERBASE=~/learn_python/.local' >> ~/.bash_profile
$ source ~/.bash_profile
$ python3 -m site --user-base
/home/yourname/learn_python/.local
よし。これで準備完了だ。
それではまず NumPy をインストールする。
[~]$ pip3 install --user numpy
...
Successfully installed numpy-1.18.4
続いて Pandas をインストールする。
[~]$ pip3 install --user pandas
...
Successfully installed pandas-1.0.3
Matplotlib をインストールする。
[~]$ pip3 install --user matplotlib
...
Successfully installed kiwisolver-1.2.0 matplotlib-3.2.1
ん? kiwisolver とやらもインストールされている。どうやら依存するパッケージも一緒にインストールしてくれるようだ。
SciPy をインストールする。
[~]$ pip3 install --user scipy
...
Successfully installed scipy-1.4.1
2.5.2. 検証
まずは Java, JavaScript, Ruby と同じコードを書いて動かしてみる。
$ python3
>>> sum([n*n for n in range(9) if n*n%2==0])
120
>>> exit()
Ruby の map と select (Java や JavaScript では map と filter) は、Python ではこのように「リスト内包表記」で表現することができる。
もしこの数学の「集合」のような表記法にピンとこなければ、お前の知っている唯一の非手続き型言語である SQL と比較してみると良いだろう。
-- Confirmed with MySQL 5.7
SELECT sum (n*n)
FROM (
SELECT 1 AS n FROM dual UNION
SELECT 2 AS n FROM dual UNION
SELECT 3 AS n FROM dual UNION
SELECT 4 AS n FROM dual UNION
SELECT 5 AS n FROM dual UNION
SELECT 6 AS n FROM dual UNION
SELECT 7 AS n FROM dual UNION
SELECT 8 AS n FROM dual
) AS range_9
WHERE mod (n*n, 2) = 0
この DML 文のサブクエリをシンプルに range_9 に置き換えれば、Python のリスト内包表記と似ていると感じるはずだ。
Python : sum( [n*n for n in range(9) if n*n % 2 == 0])
SQL : SELECT sum (n*n) FROM range_9 WHERE mod(n*n , 2) = 0
なお、SQL の実行結果を確認できる無償の Web サービスもある。恵まれた時代だ。
SQL 確認サービス
SQL Fiddle
DB-Fiddle
次に、先ほどインストールしたライブラリを使ったコードを書いて動かしてみる。
以下のコードは、
- 日本郵便が提供する郵便番号データ (ken_all.zip) をダウンロードし、
- そこからアーカイブメンバの CSV 形式データ (KEN_ALL.CSV) を取り出し、
- Pandas を使って同じ名前を持つ市区町村を抽出する処理を、
ローカルファイルに展開せずにメモリ上で実行するものだ。
import urllib.request, zipfile, io, pandas as pd
URL = "https://www.post.japanpost.jp/zipcode/dl/kogaki/zip/ken_all.zip"
res = urllib.request.urlopen(URL).read()
zip = zipfile.ZipFile(io.BytesIO(res))
csv = zip.open("KEN_ALL.CSV").read()
all = pd.read_csv(io.BytesIO(csv), encoding="shift-jis", header=None)
cities = all[[6, 7]].drop_duplicates().rename(columns={6: "都道府県", 7: "市区町村"})
result = cities[cities.duplicated(subset="市区町村", keep=False)]
print(result)
$ python3 duplicate_city_names.py
都道府県 市区町村
3517 北海道 伊達市
22408 福島県 伊達市
40523 東京都 府中市
103128 広島県 府中市
例外は考慮していないが、この程度の処理ならあまり難しく考えずに9行程度で手軽に書ける。
そう。お前の時代のようにグルグル回す必要はない。そういう時代はもう終わったのだ。
2.5.3. この後に学ぶこと
この言語は今旬だということもあり、触る機会もそれなりに多くなるかもしれない。また、今後、ちょっとしたデータ分析などで Python を活用したくなることもあるだろう。その辺りを踏まえ、この言語に少し慣れておいた方が良いかもしれない。
3. モダンなプログラミング言語
ここでは、現時点でまだ普及しているとは言えないが、次世代の標準になるポテンシャルを秘めている言語、もしくは次世代の標準へ大きな影響を与えるであろう言語について取り上げる。
3.1. TypeScript
これをモダンな言語と呼んで良いかどうかわからないが、ひと言で言えば静的型付きの、洗練された JavaScript だ。
そういった意味で TypeScript は、ロンドン・パンク時代からモッズ・スーツをスタイリッシュに着こなしていた Paul Weller と言えるだろう。
TypeScript で書いたコードは最終的に JavaScript に変換されて利用される。
このようにある高水準言語を他の高水準言語へ変換する処理系をトランスパイラ(トランスコンパイラ)と呼ぶらしい。ES6/7 を ES5 へ変換する babel もそうだな。
TypeScript を使うことで、お前が苦手としていた JavaScript の、メソッド・シグネチャを見ても何のことかわからず、まるで写真無しメニューで料理を注文しなきゃならないような、あの恐怖が多少は解消されるかもしれない。
3.1.1. インストール
TypeScript は Node.js のパッケージとして提供されているので、 npm を使ってインストールするが、ストレージを贅沢に使える現代ではプロジェクトごとに別々の環境を用意するのが一般的なようだ。ということで TypeScript のトランスパイラとコマンドライン・インタプリタをホーム・ディレクトリ配下のローカル環境へインストールすることにする。
まずはディレクトリを作成する。
$ mkdir ~/learn_ts
$ cd ~/learn_ts
Node.js では、各プロジェクトの構成を package.json で管理するので、次にそれを初期化(package.json を新規作成)する。
$ npm init -y
$ ls
package.json
TypeScript のトランスパイラと対話型インタプリタをインストールする。
$ npm install --save ts-node typescript
$ ls
node_modules package.json package-lock.json
node_modules というディレクトリにパッケージがインストールされたようだ。node_modules/.bin にコマンドが格納されている。
$ ls node_modules/.bin/
tsc ts-node ts-node-script ts-node-transpile-only ts-script tsserver
また --save オプションを付けたので、package.json に以下のようなエントリが追記されている。別の環境へ package.json を持っていき $ npm install と打てば、package.json の構成に従って、各パッケージのバージョン等も含め、同じ環境が自動的に作成されるというわけだ。便利な時代だ。
{
"name": "learn_ts",
...
"dependencies": {
"ts-node": "^8.10.1",
"typescript": "^3.8.3"
}
}
3.1.2. 検証
対話型インタプリタを実行する。
npx コマンドを使えば node_modules/.bin/ へパスを通す必要はない。
$ npx ts-node
> const s: string = "hello, world!"
> console.log(s)
hello, world!
> .exit
$
ソースコードを指定して実行する。
$ mkdir src
$ cd src/
$ echo '
> const echo = (s: string): string => s;
> console.log(echo("hello, world"));
> ' > HelloWorld.ts
$ npx ts-node HelloWorld.ts
hello, world
トランスパイルする。
$ npx tsc HelloWorld.ts
$ ls
HelloWorld.js HelloWorld.ts
$ cat HelloWorld.js
var echo = function (s) { return s; };
console.log(echo("hello, world"));
ん? const が var に、アロー関数が通常の関数式になっている。。
$ npx tsc --help
Version 3.8.3
Syntax: tsc [options] [file...]
...
-t VERSION, --target VERSION Specify ECMAScript target version: 'ES3' (default), 'ES5', 'ES2015', 'ES2016', 'ES2017', 'ES2018', 'ES2019', 'ES2020', or 'ESNEXT'.
デフォルトでは ES3 に変換されるようだ。しかも、ES6 以降は ES2015 の表記が正しいのか。。
$ npx tsc --target ES2015 HelloWorld.ts
$ cat HelloWorld.js
const echo = (s) => s;
console.log(echo("hello, world"));
なるほど。。いろいろ勉強になる。。
3.1.3. Union Type と ?. および ?? 演算子を試す
共用型は宣言時に複数の型を指定できるもので、例えば value: number | string のように宣言すると、 value には number 型または string 型の値を代入できる。
これ使えば関数オーバーロードのようなことができそうだが、今回は ?. 演算子と組み合わせた null 検査を試してみる。
function wow(s: string | null): string { // ① string または null だけを許容
return s?.trim()?.toUpperCase() + "!"; // ② ?. 演算子を使って null をやり過ごす
}
console.log(wow("hello "));
console.log(wow(null));
①で仮引数 s を共用型とし、string または null を許容するようにしたが、TypeScript はデフォルトで変数への null/undefined の代入を許してしまうようなので、後でトランスパイル時に null/undefined の代入を許さないよう --strictNullChecks オプションを指定することとする。
②で ?. 演算子を使っているが、 s?.trim() のように使うと、s が null 値ではない場合だけ trim() をコールしてくれるようだ。
トランスパイルして実行してみる。
$ npx tsc --strictNullChecks GuardTest.ts
$ node GuardTest.js
HELLO!
undefined!
ん? s が null 値の場合は s?.trim() が null ではなく undefined として評価されるようだ。
変換後の JavaScript を確認してみる。
$ cat GuardTest.js
function wow(s) {
var _a;
return ((_a = s === null || s === void 0 ? void 0 : s.trim()) === null || _a === void 0 ? void 0 : _a.toUpperCase()) + "!"; // ②
}
console.log(wow("hello "));
console.log(wow(null));
なるほど。。 void 演算子は undefined がグローバル変数だった悪しき時代の先人たちの知恵だったようで、右辺の内容に関わらず常に「undefined の即値」を返すらしい。
ということで、 ?. 演算子は左辺が null の場合は undefined と評価されることがわかったが、いずれにせよこれを使えば文字列操作のメソッド・チェーンなどで、 null チェックがシンプルに書けることがわかった。
続けて ?? 演算子を試してみる。
function wow(s: string | null): string {
return (s??"").trim().toUpperCase() + "!";
}
console.log(wow("hello "));
console.log(wow(null));
s??"" は、s が null の場合は "" と評価されるようだが、 ?? は . より結合の優先順位低いようなので、カッコで括ってこれをトランスパイルし実行してみる。
npx tsc --strictNullChecks GuardTest2.ts
[~/learn_ts/src]$ node GuardTest2.js
HELLO!
!
この西暦2020年のコーディングスタイルは、お前が見たら羨ましがるだろうな。
?. と ?? は TypeScript 3.7 で導入されたようだ。
TypeScript 3.7
3.1.4. Tuple を試す
次はタプルを試してみる。
タプルは C++11 でも採用され、これも近年のトレンドのようだが、TypeScript ではタプルを、要素数と各要素の型が固定された配列として扱っている。
$ npx ts-node
> let member: [string, number, number] = ["Paul", 180, 60]
> console.log(member)
[ 'Paul', 180, 60 ]
だが、例えば座標など同一型データの組を表現するには良いかもしれないが、異なる型の組を作れたとしても、今一つ使いどころが思い浮かばない。
型チェックとは何だろうか?
型チェックは、プログラミングで気を付けるべき要素の 1 つに過ぎない。
上記のような目的なら、タプルではなくクラスを定義し、プロパティや引数に名前を付け、それらの意味がわかるようにすべきだろう。
class Member {
name : string // 名前
height: number // 身長
weight: number // 体重
constructor(name : string,
height: number,
weight: number) {
this.name = name
this.height = height
this.weight = weight
}
show() {
const msg: string = `name:${this.name},\
height:${this.height}cm,\
weight:${this.weight}kg`
console.log(msg)
}
}
let member = new Member("Paul", 180, 60)
member.show()
それでは意味付けとは何だろうか?
名前を付ければ充分なのか?
例えば height (身長)の単位は何だろうか? メートルか?、センチメートルか?、フィートか?
単位がわかったとして精度はどうだろうか? 整数か?、小数第一位か二位か?
他に気を付けるべきことはないだろうか?
このような事を考えていくと、あまり考えずに書かれた より強い型付けの TypeScript のプログラムより、 よく考えて書かれた 弱い型付けの JavaScript のプログラムの方がまだヒューマンエラーによるソフトウェア故障は起きにくいのではないか。
// TypeScript 静的で 強い型付け 型安全
let member: [string, number, number] = ["Paul", 180, 60]
// JavaScript 動的で 弱い型付け 型安全ではない
let member = { // バンドメンバーの身体情報
name : "Paul", // 名前 NotNull 有効パターン: ^[A-Z][a-zA-Z \.]{1,19}$
height: 180.0, // 身長 NotNull 単位:cm 精度: 小数第1位まで 有効範囲: 50.0cm <= h < 300.0cm
weight: 60.0, // 体重 Nullable 単位:kg 制度: 小数第2位まで 有効範囲: 8.00kg <= w < 400.00kg
}
また、型安全とは何だろうか?
落ちることなく何カ月も不正データを垂れ流し続ける 事前バインディングの TypeScript コード よりも、タイプエラーで停止してしまう 実行時バインディングの JavaScript コード の方が問題の影響範囲が狭く対処が楽な場合もあるだろう。
近年、プログラミング言語の進化によりお前の時代より高品質なプログラムを作りやすい状況にはなってきているとはいえ、俺の時代になってもなお、どんな道具を使うかよりプログラマがどう向き合うかの方がずっと大切だということに変わりはない。
3.1.5. この後に学ぶこと
この言語は今後何かと使う機会も増えてくるだろうし、同じプログラムを同じプログラマが書く限り JavaScript より TypeScript で書く方が高品質なコードをより短時間で効率的に書くことができるのは間違いない。
なお、後述の React の項でも TypeScript のコーディングをしている。
3.2. Haskell
Haskell のプロジェクトがスタートしたのは、Java が登場するより前の西暦 1990 年だから、これを果たしてモダンなプログラミング言語と呼んでいいのかどうかわからない。
だが、お前が学んできた抽象化の歴史、つまり、
- オペコードという順次実行される記号に名前を付け(ニーモニック)、
- ジャンプ を 選択・反復・呼出 で隠蔽し(構造化プログラミング)、
- 情報と手続きをカプセルに閉じ込めてきた(オブジェクト指向) ← 今ここ
この歴史(お前の頭の中そのもの)は、ノイマン・アーキテクチャの呪縛から逃れ切れていないということであり、Haskell という言語はどうやらこの流れとはちょっと違う文脈で進化してきたようなのだ。
これは日本人であるお前にとって、日本から遠く離れたユーラシア大陸の西端にあるブリテン島が、ゲルマン人の移住によりアングル族の国になる(つまり英語の国になる)より前、更に、ローマ人に侵攻され属州ブリタニアになる(つまりラテン語の国になる)より前の時代に、鉄製の武器を操るケルト人が支配していた国(つまりケルト語派の国)だった時代から脈々と受け継がれる文化を理解しようとするのと似ているかもしれない。
そういう意味でお前にとって Haskell は、あのスコットランドやアイルランドなどの「ケルトの血」をロックに注ぎ込んだ The Waterboys の Mike Scott と言えるだろう。
さて、この関数型というカテゴリーで括られた言語群は、近年、お前が慣れ親しんできた手続き型言語にとてつもない影響を与えていて、関数型言語風の機能追加はもはやコモディティ化していると言えるかもしれない。
そんなパラダイムチェンジを産んだ関数型の中で特に人気がありそうな言語を挙げてみても、
| 関数型言語 | 型付け | 純粋 | 評価戦略 | 特徴を一言で強引に |
|---|---|---|---|---|
| Haskell | 静的 | 純粋 | 原則遅延 | モナド |
| OCaml (ML系) | 静的 | 非純粋 | 原則先行 | ML+OOP |
| Scala | 静的 | 非純粋 | 原則先行 | OOP(JVM) |
| Scheme (Lisp系) | 動的 | 非純粋 | 原則先行 | 型なし |
純粋関数型と呼ばれ遅延評価が基本の Haskell は独特な立ち位置にあるようだ。
3.2.1. インストール
Haskell には Haskell Platform というオール・イン・ワン・パッケージもあるようだが、現在は The Haskell Tool Stack というビルドツールを使うのが主流のようなので、こちらをインストールしてコンパイラなどの環境をビルドしていく。
Stack インストール・マニュアル
The Haskell Tool Stack - Stack How to install
Stack をインストールする。
$ curl -sSL https://get.haskellstack.org | sh
...
Stack has been installed to: /usr/local/bin/stack
新規プロジェクトを(デフォルトテンプレートを元に)作成する。
$ mkdir ~/learn_haskell
$ cd ~/learn_haskell/
$ stack new my-project
...
All done.
$ ls
my-project
$ cd my-project/
セットアップする。
(必要に応じてコンパイラ等がインストールされる)
$ stack setup
...
$ ls ~/.stack/programs/x86_64-linux/ghc-tinfo6-8.8.3/bin/
ghc ghc-8.8.3 ghci ghci-8.8.3 ghc-pkg ghc-pkg-8.8.3 haddock haddock-ghc-8.8.3 hp2ps hpc hsc2hs runghc runghc-8.8.3 runhaskell
$
プロジェクトをビルドする。
$ stack build
...
Registering library for my-project-0.1.0.0..
対話型インタプリタのプロンプトを設定する。
$ echo ':set prompt "ghci> "' >> ~/.ghci
3.2.2. 検証
対話型インタプリタを確認する。
$ stack ghci
ghci> putStrLn "hello, world"
hello, world
ghci> :quit
Leaving GHCi.
コンパイラを確認する。
$ echo 'main = putStrLn "hello, world"' > hello_world.hs
$ stack ghc hello_world.hs
$ ls
hello_world hello_world.hi hello_world.hs hello_world.o
$ ./hello_world
hello, world
3.2.3. パターンマッチングとは何か
Haskell には、パターンマッチングシステムというおもしろい機構がある。
これはお前が知っている正規表現による文字列のパターンマッチングの話とはちょっと違っていて、どちらかというとメソッドオーバーロードのようなものと考えるとしっくりくるかもしれない。
例えば、以下の Haskell のプログラムは、「階乗」を再帰で表現したものだ。
-- パターンマッチング
fact 0 = 1 -- ① 引数の値が 0 の場合
fact n = n * fact(n - 1) -- ② 引数の値が それ以外 の場合
main = print(fact 8) -- => 40320
同じように、「階乗」の再帰処理を Java でやると以下のようになる。
public class Factorial {
public static int fact(int n) { // Haskell のパターンマッチングの箇所
if (n == 0) return 1; // ① 引数の値が 0 の場合
else return n * fact(n - 1); // ② 引数の値が それ以外 の場合
}
public static void main(String[] argv) {
System.out.println(fact(8)); // => 40320
}
}
上記①②がパターンマッチングの箇所だが、Haskell では、Java のこの static メソッドの内側でやっている分岐を外に出して、以下のようにしているイメージだ。
public class Factorial {
// ↓Haskell のパターンマッチング風(コンパイルエラー)
public static int fact(int 0) { return 1; }
public static int fact(int n) { return n * fact(n - 1); }
public static void main(String[] argv) {
System.out.println(fact(8));
}
}
もちろんこれはコンパイルエラーになるので動かない。
だが、Haskell の パターンマッチングシステムは、Java のメソッドシグネチャが「 メソッド名 と 引数の型 でメソッドを一意に定めている」ところを、「 メソッド名 と 引数の型 と 値 でメソッドを一意に定める」ようにし、その上でオーバーロードメソッドのように扱うものと考えることができそうだ。
また、関数型風味のフレーバーを取り込んでいる、他の手続き型・動的型付き言語で同じコードを書くと以下のようになる。
JavaScript での「階乗」の再帰表現
fact = n => n === 0 ? 1 : n * fact(n - 1);
console.log(fact(8)); // => 40320
Ruby での「階乗」の再帰表現
fact = lambda {|n| n == 0 ? 1 : n * fact.call(n - 1)}
puts fact.call 8 # => 40320
Python での「階乗」の再帰表現
fact = lambda n : 1 if n == 0 else n * fact(n - 1)
print(fact(8)) # => 40320
どれもラムダ式(またはアロー関数)を使って短く書けるが、Python の 3 項演算子が他と順序が違う点を除けば、まあ似たり寄ったりだ。
ここで、上記 JavaScript のコードを Haskell のパターンマッチング風に変えてみる。
// fact 関数: この宣言は無くても良いが fact_n の
// 中からコールされているので念のため
let fact;
// Haskell 風の関数
fact_0 = () => 1;
fact_n = n => n * fact (n - 1);
// パターンマッチング関数
fact = n => {
if (n === 0) return fact_0 ( );
else return fact_n (n);
}
console.log(fact(8)); // => 40320
これを Haskell のコードと並べてみると以下のようになる。
| 処理 | Haskell | JavaScript |
|---|---|---|
| 引数が 0 の場合 | fact 0 = 1 | fact_0 = ( ) => 1; |
| 引数が それ以外の場合 | fact n = n * fact(n - 1) | fact_n = n => n * fact (n - 1); |
| パターンマッチング | -- コンパイラが考えてくれる | fact = n => { if (n === 0) return fact_0 ( ); else return fact_n (n); } |
| 結果を標準出力へ | main = print(fact 8) | console.log(fact(8)); |
これだけでは大した違いはないかもしれないが、このパターンマッチングの恩恵は、プログラムの規模が大きくなるにつれジャブのように効いてきて、最終的にコード量に大きな差が出るのかもしれない。
3.2.4. 型クラスとは何か
Haskell の型システムには「型クラス」という考え方がある。
対話型インタプリタ ghci で :t コマンドを使うと関数(演算子)の型を確認することができるので、これを使って 演算子 + の型を調べてみる。
$ stack ghci
ghci> :t (+)
(+) :: Num a => a -> a -> a
俺たちには見慣れない表現だが、この Num は「型クラス」と呼ばれ、Java の Generics で言うところの <T> と同じように ある型 を表している。
そしてこの表現 (+) :: Num a => a -> a -> a は、「+ 演算子は Num 型クラスのインスタンス(Int や Float などの型)の引数を 2 つ取り、同型の戻り値を返す」という意味になるので、C++ で例えるなら、以下の関数宣言(演算子オーバーロード宣言)と同じように考えて良いだろう。
Num operator+ (const Num& n1, const Num& n2);
演算子を定義できない Java だと以下のような感じだ。
public static Num add(Num n1, Num n2);
そしてこの Num 型クラスについて ghci の :i コマンドで調べてみると、この型クラスには、
- +, -, * などのメソッド
- Int, Float, Double などのインスタンス
があることがわかる。
ghci> :i Num
class Num a where
(+) :: a -> a -> a
(-) :: a -> a -> a
(*) :: a -> a -> a
...
instance Num Int -- Defined in ‘GHC.Num’
instance Num Float -- Defined in ‘GHC.Float’
instance Num Double -- Defined in ‘GHC.Float
クラスにしろ、インスタンスにしろ、メソッドにしろ、お前にとっては馴染み深い言葉ばかりだが、オブジェクト指向のそれとはちょっと意味が違っている。
混乱してしまいそうだが、Haskell では「型クラス」のインスタンスは「型」だ。
例えば Java では Integer は Number の サブクラス であり、インスタンスではない。
| Java | クラス | インスタンス | メソッド |
|---|---|---|---|
| 呼称: | クラス ↑ サブクラス |
オブジェクト | メソッド |
| 具体例: | java.lang.Number ↑ (サブクラス) Integer Float Double |
(abstract) ↑ (サブクラスのオブジェクト) Integer.valueOf(1) Float.valueOf(2.0) Double.valueOf(3.0) |
intValue() floatValue() doubleValue() |
だが、Haskell の Int は Num の インスタンス である。サブクラスではない。
| Haskell | クラス | インスタンス | メソッド |
|---|---|---|---|
| 呼称: | 型クラス ↑ サブ 型クラス |
型 | 関数 (演算子) |
| 具体例: |
Num ↑ (サブ 型クラス) なし |
Int Float Double |
+ - * abs |
この Int について更に調べてみると、
ghci> :i Int
data Int = ghc-prim-0.5.3:GHC.Types.I# ghc-prim-0.5.3:GHC.Prim.Int#
-- Defined in ‘ghc-prim-0.5.3:GHC.Types’
instance Eq Int -- Defined in ‘ghc-prim-0.5.3:GHC.Classes’
instance Ord Int -- Defined in ‘ghc-prim-0.5.3:GHC.Classes’
instance Enum Int -- Defined in ‘GHC.Enum’
instance Num Int -- Defined in ‘GHC.Num’
...
Int 型が Num 意外にも、Eq, Ord, Enum などの型クラスのインスタンスであることがわかる。
Eq は等価性があるかどうか( == や != で比較できるかどうか)、Ord は順序付けられるかどうか( > や < などで大小の比較ができるかどうか)、Enum は列挙できるかどうか( 1, 2, 3... や 'a', 'b', 'c'... のように列挙でき、前後の値を取り出せるかどうか)を定義する型クラスである。
このように Haskell は異なる型の似たような性質をあぶり出し、「型クラス」というものにまとめているんだ。俺は TypeScript の項で「型とは何か?」みたいなことを偉そうに書いたが、 Haskell という言語は、俺たちが考えている以上にこの「型」というものを深く深く掘り下げ、徹底的に向き合っているということだ。
3.2.5. 遅延評価とは何か
評価戦略。
これをお前が知っている言語のサブルーチンコールで考えてみると、
- C でそれは「値渡し」のことだった。
(データや関数のアドレスを示すポインタを渡す場合も「値渡し」だ) - C++ では「値渡し」の他に「参照渡し」ができた。
(参照渡しとポインタの値渡しは表現が違うだけでやってることは同じだ) - Java は「値渡し」だ。
(参照型オブジェクトの場合は、C/C++のポインタの値渡しとやってることは同じ)
このような感じになるが、まあこれらはすべて「先行評価」という評価戦略を取っている。
それでは Haskell の「遅延評価」とは何だろうか。
遅延評価とは「必要になるまで式が評価されない」ということのようだが、リテラルも、変数も、演算子も、関数も、それを含む式がロードされた際に直ちに評価されないようにするには、それを評価する関数を渡しておき、必要になったら呼び出してもらえば良いのではないだろうか。
それを確認するために、ここでは「遅延評価とは関数渡しである」という仮説を立てて JavaScript でシミュレートしてみる。
// 遅延評価の検証プログラム
const TAB = 2; // 1階層あたりのTAB幅
let LEV = 0; // 現在の階層レベル
const indent = () => " ".repeat(LEV*TAB); // 現在の階層レベルのインデント
const log = (...a) => console.log(...a); // コンソール出力
// f:funcName:str p:params:str[] r:retval:str
const sigFunc = (f,p ) => f+"("+p.join()+")"; // "f(p1, p2, p3...)"
const msgCall = (f,p ) => indent()+"=> " +sigFunc(f,p); // コール直後のメッセージ
const msgRet = (f,p,r) => indent()+"<= "+r+" : "+sigFunc(f,p); // リターン直前のメッセージ
const notifyCall = (f,p ) =>{log(msgCall(f,p)); LEV++;}; // コール直後の通知
const notifyRet = (f,p,r) =>{LEV--; log(msgRet(f,p,r));}; // リターン直前の通知
// コマンドのラッパー funcName:str, params:str[], callback:Func
const wrap = (funcName, params, callback) => {
notifyCall(funcName, params); // コール直後の通知
params = params.map(param=>param()); // パラメータを評価
const retval = callback(...params); // ファンクションの実行
notifyRet(funcName, params, retval); // リターン直前の通知
return retval;
}
// コマンドの定義 wrap( funcName, params,callback )
const LT5 = ( ) => ()=> wrap( LT5.name, [ ], ( )=>5 ); // リテラルの 5
const LT3 = ( ) => ()=> wrap( LT3.name, [ ], ( )=>3 ); // リテラルの 3
const NEG = (a ) => ()=> wrap( NEG.name, [a ], (a )=>-a ); // 単項マイナス演算子
const VAR = (a ) => ()=> wrap( VAR.name, [a ], (a )=>a ); // 変数
const ADD = (a,b) => ()=> wrap( ADD.name, [a,b], (a,b)=>a+b ); // 加算演算子
const ABS = (a ) => ()=> wrap( ABS.name, [a ], (a )=>a<0?-a:a ); // 絶対値関数
const DSP = (a ) => wrap( DSP.name, [a ], (a )=>log(a) ); // 表示関数
// コマンドリストに従って実行
const exec = cmdList => cmdList.forEach(cmd=>{ log("LOAD:",cmd); eval(cmd); });
const cmdList = [
"let N // let n",
"N = NEG( LT5() ) // n = -5",
"DSP( ABS( ADD( VAR(N), LT3() ) ) ) // print(abs(n + 3))",
];
log("------------ Lazy Evaluation ---------");
exec(cmdList);
上記プログラムは以下のようなことを行っている。
- JavaScript の
let n; n = -5; print(abs(n + 3));に見立てた独自のコマンド群を実行する。 - 独自コマンドは、リテラル、変数、演算子、関数をすべて FUNC(a, b) のような形で表現する。
(例えば、加算演算子 + は ADD(a,b)、数値リテラル 3 は、LT3() のように) - コマンドが評価される直前と直後にログを出力する。
(コマンド名、渡されたパラメータ、戻り値などを表示) - 各コマンドは wrap 関数で包み、コールバックで呼び出してもらうようにする。
- wrap 関数は、コマンド実行の前後にログを出力する。
- wrap 関数は、コマンド実行の直前にそのコマンドに渡された引数を評価する。
(関数渡しなので、引数である「関数」を実行する)
- ほとんどのコマンド(遅延評価のコマンド)は、呼び出されても直ちに自身の処理を実行せず、それを実行するための関数を返すようにする。
- 例えば、数値リテラル 5 をシミュレートする LT5() は、以下のように、呼び出されると「5 を返す関数」を返す。
LT5 = () => ()=> wrap( LT5.name, [], ()=>5)
- 引数の評価値を即座に必要とするコマンドは、呼び出されたら自身に渡されたパラメータを直ちに評価して自身の処理を実行するようにする。
- 例えば、DSP (console.log() に相当)は、以下のように、呼び出されると直ちに処理を実行する。
-
DSP = (a) => wrap( DSP.name, [a], (a)=>log(a))
(DSP() には、LT5() にはある wrap の前の ()=> がない)
このプログラムを実行すると以下のようになる。
$ node lazy.js
------------ Lazy Evaluation ---------
LOAD: let N // let n
LOAD: N = NEG( LT5() ) // n = -5
LOAD: DSP( ABS( ADD( VAR(N), LT3() ) ) ) // print(abs(n + 3))
=> DSP(()=> wrap( ABS.name, [a ], (a )=>a<0?-a:a ))
=> ABS(()=> wrap( ADD.name, [a,b], (a,b)=>a+b ))
=> ADD(()=> wrap( VAR.name, [a ], (a )=>a ),()=> wrap( LT3.name, [ ], ( )=>3 ))
=> VAR(()=> wrap( NEG.name, [a ], (a )=>-a ))
=> NEG(()=> wrap( LT5.name, [ ], ( )=>5 ))
=> LT5()
<= 5 : LT5()
<= -5 : NEG(5)
<= -5 : VAR(-5)
=> LT3()
<= 3 : LT3()
<= -2 : ADD(-5,3)
<= 2 : ABS(-2)
2
<= undefined : DSP(2)
注目すべきは、 N = NEG( LT5() ) がロードされても、NEG(単項マイナス演算子のシミュレート)も、 LT5() もまだ評価されないということだ。
次の行のステートメント DSP( ABS( ADD( VAR(N), LT3() ) ) ) で DSP() が呼び出されると、ラッパー関数 wrap() 内で param=>param() が実行され、これをトリガーにしてカッコの外側から内側に向かって param=>param() が連鎖していき、ようやく一つ前の行の LT5() までたどり着くことになる。
また、このプログラムは各コマンドに渡されたパラメータを表示するようにしているが、カッコの外側から内側に向かう「往路」では、=> の右側に表示されるパラメータがまだ評価前の「関数」であることがわかる。そして「復路」では、<= の右側に表示されるパラメータが評価後の「値」となっている。
それでは、プログラムを少しだけ変えて、先行評価もシミュレートしてみる。
// 先行評価の検証プログラム
const TAB = 2; // 1階層あたりのTAB幅
let LEV = 0; // 現在の階層レベル
const indent = () => " ".repeat(LEV*TAB); // 現在の階層レベルのインデント
const log = (...a) => console.log(...a); // コンソール出力
// f:funcName:str p:params:str[] r:retval:str
const sigFunc = (f,p ) => f+"("+p.join()+")"; // "f(p1, p2, p3...)"
const msgCall = (f,p ) => indent()+"=> " +sigFunc(f,p); // コール直後のメッセージ
const msgRet = (f,p,r) => indent()+"<= "+r+" : "+sigFunc(f,p); // リターン直前のメッセージ
const notifyCall = (f,p ) =>{log(msgCall(f,p)); LEV++;}; // コール直後の通知
const notifyRet = (f,p,r) =>{LEV--; log(msgRet(f,p,r));}; // リターン直前の通知
// コマンドのラッパー funcName:str, params:str[], callback:Func
const wrap = (funcName, params, callback) => {
notifyCall(funcName, params); // コール直後の通知
//params = params.map(param=>param()); // パラメータを評価
const retval = callback(...params); // ファンクションの実行
notifyRet(funcName, params, retval); // リターン直前の通知
return retval;
}
// コマンドの定義 wrap( funcName, params,callback )
const LT5 = ( ) => wrap( LT5.name, [ ], ( )=>5 ); // リテラルの 5
const LT3 = ( ) => wrap( LT3.name, [ ], ( )=>3 ); // リテラルの 3
const NEG = (a ) => wrap( NEG.name, [a ], (a )=>-a ); // 単項マイナス演算子
const VAR = (a ) => wrap( VAR.name, [a ], (a )=>a ); // 変数
const ADD = (a,b) => wrap( ADD.name, [a,b], (a,b)=>a+b ); // 加算演算子
const ABS = (a ) => wrap( ABS.name, [a ], (a )=>a<0?-a:a ); // 絶対値関数
const DSP = (a ) => wrap( DSP.name, [a ], (a )=>log(a) ); // 表示関数
// コマンドリストに従って実行
const exec = cmdList => cmdList.forEach(cmd=>{ log("LOAD:",cmd); eval(cmd); });
const cmdList = [
"let N // let n",
"N = NEG( LT5() ) // n = -5",
"DSP( ABS( ADD( VAR(N), LT3() ) ) ) // print(abs(n + 3))",
];
log("------------ Eager Evaluation ---------");
exec(cmdList);
遅延評価プログラムとの実質的な違いは 2 点だけだ。
- 1 つは、wrap() 関数内の
params = params.map(param=>param());をコメントアウトしていること。
(先行評価は関数渡しではなく、引数が渡される時点で既に param の評価が終わっているため、param=>param()は実行しない) - もう 1 つは、コマンドの作り方が、遅延評価の DSP() と同じように ()=> を付けない形になっていることだ。例えば、絶対値コマンド ABS() では以下のような違いになる。
遅延評価: const ABS = (a) =>()=>wrap( ABS.name, [a], (a)=>a<0?-a:a );
先行評価: const ABS = (a) => wrap( ABS.name, [a], (a)=>a<0?-a:a );
(先行評価は関数渡しではないので ()=> を外す)
先行評価プログラムの実行結果は以下のようになる。
$ node eager.js
------------ Eager Evaluation ---------
LOAD: let N // let n
LOAD: N = NEG( LT5() ) // n = -5
=> LT5()
<= 5 : LT5()
=> NEG(5)
<= -5 : NEG(5)
LOAD: DSP( ABS( ADD( VAR(N), LT3() ) ) ) // print(abs(n + 3))
=> VAR(-5)
<= -5 : VAR(-5)
=> LT3()
<= 3 : LT3()
=> ADD(-5,3)
<= -2 : ADD(-5,3)
=> ABS(-2)
<= 2 : ABS(-2)
=> DSP(2)
2
<= undefined : DSP(2)
見てすぐに気づくのは、遅延評価の時のような深いインデントがまったくなく、実にフラットなことである。
また、遅延評価の時とは違い、 N = NEG( LT5() ) がロードされると、NEG(単項マイナス演算子のシミュレート)と LT5() が直ちに評価されていて、次の行のステートメント DSP( ABS( ADD( VAR(N), LT3() ) ) ) でも、カッコの内側から外側に向かって評価されていることがわかる。
また、遅延評価の時とは違い、コマンドが呼び出された直後のパラメータ( => の右側に表示されるパラメータ)が、「関数」ではなく「値」となっている。
さて、実はこの遅延評価の仮説が正しいかどうかを Haskell のプログラムにデバッグログを仕込んで確認したかったのだが今回それができなかった。関数内にログ出力を書くだけで済むと思い簡単に考えていたのだが、それをやると「それは関数じゃないよ!」と Haskell コンパイラに叱られてしまうのだ。
どうやら他の言語で最初に学ぶ 'hello world' のようなプログラム(I/O を伴うなど副作用のある、または純粋ではない、または参照透過ではないプログラム)を、きちんと理解した上で Haskell に走らせるには、ファンクタ、アプリケーティブ、モノイド、モナドなどといった概念を基本的なところからきちんと学ばねばならないようだ。
遅延評価のプログラムを書きながら、関数も演算子も変数もそしてリテラルさえも「そんなものに本質的な違いはないんだよ!」と言われているような気持ちにさせられる一方、方や俺が同じものと考えていた I/O を伴うコードと伴わないコードについては「それはまったく別物なんだよ!」と言われてしまう。
これまでいろんなプログラミング言語を触ってきたが、データ型や変数宣言、分岐やループやサブルーチンコールなどの作法が少しわかれば、まあ適当に書いていてもなんとかなった。
だが、この Haskell という言語はそれらとはちょっとばかり違うようだ。
それはまるで、若かったころ The Alarm の アルバム 'Change' のウェールズ語バージョンを手にし、英語バージョンとはまるで異なるその歌詞をまったく理解できずに狼狽えた、あの時のあの気持ちを思い出させてくれるのだ。
| The Alarm | 英語版 | ウェールズ語 (ケルト語派)版 |
|---|---|---|
| Album | Change (The Alarm) | Newid (The Alarm) |
| Track 1. | Sold Me Down the River | Gwerthoch Fi I Lawr Yr Afon |
| Track 2. | The Rock | Y Craig |
| Track 3. | Devolution Workin' Man Blues | Datganoli Y Falen Gweithiwr |
| Track 4. | Love Don't Come Easy | Dydi Cariad Byth Yn Hawdd |
| Track 5. | Hardland | Hiraeth |
だが、思い出してほしい。あの重々しいウェールズ語の響きが楽曲の雰囲気をガラリと変え、原曲とは一味も二味も違う荘厳さと荒々しさを醸し出していたことを。そしてあの作品がお前のオールタイム・フェイバリット・アルバムになったことを。
Haskell はそんな期待を抱かせてくれる言語だ。
3.2.6. この後に学ぶこと
恐らく今後仕事で Haskell のプログラムを書くことはほとんどないと思われるが、この言語から学べることはたくさんありそうだし、それはきっと他の言語でも応用できることだろう。だから基本的なところから少しづつ学んでおくのが良さそうだ。
3.3. Go
この言語のバージョン 1.0 がリリースされたのが 2012 年だから、正真正銘「モダンな言語」と言っていいだろう。ところがこの言語で書かれたコードを見てみると、ステートメント・ターミネータ(セミコロン)のない「すっきりとした C 言語」のように見え、どこか懐かしさを感じるのだ。
そういう意味で Go 言語は、ギター、ピアノ、チェロなど生楽器を主体としたミニマル構成で現代的な音を奏でる The Luminners と言っていいだろう(2012 年に衝撃のデビューを飾り Bob Dylan の再来と言われた Jake Bugg と迷ったが、最終的に The Luminners とした)。
3.3.1. インストール
パッケージを確認する。
$ dnf search golang
============================================ Name Exactly Matched: golang =============================================
golang.x86_64 : The Go Programming Language
...
Golang core compiler tools の詳細を確認する。
$ dnf info golang.x86_64
Last metadata expiration check: 1:51:39 ago on Tue 19 May 2020 05:32:34 AM UTC.
Installed Packages
Name : golang
Version : 1.12.12
Release : 4.module_el8.1.0+271+e71148fc
Architecture : x86_64
Size : 6.9 M
Source : golang-1.12.12-4.module_el8.1.0+271+e71148fc.src.rpm
Repository : @System
From repo : AppStream
Summary : The Go Programming Language
URL : http://golang.org/
License : BSD and Public Domain
Description : The Go Programming Language.
$
golang 1.12.12 をインストールする。
$ sudo dnf install -y golang-bin.x86_64
...
Complete!
$
$ go version
go version go1.12.12 linux/amd64
それにしてもパッケージ管理ツールによるバイナリパッケージのインストールは楽だ。ソースコードビルドで依存関係のエラーが発生しネットで調べても問題を解決できず途方に暮れていた時代が嘘のようだ。
3.3.2. 検証
テンポラリ・コンパイルによる実行を確認する。
$ mkdir ~/learn_go
$ cd ~/learn_go/
$ echo '
> package main
> import "fmt"
> func main() { fmt.Println("hello, world") }
> ' > hello.go
$ go run hello.go
hello, world
コンパイルして実行する。
$ go build hello.go
$ ls
hello hello.go
$ ./hello
hello, world
3.3.3. ポインタを試す
Glaong は C/C++ や Java と構文が似ているので取っつきやすいのではないかと思っていたが、 前置++演算子 が使えなかったり、 後置++演算子 は使えるが i++ が式として評価されなかったり、ポインタと整数の加減算ができなかったりと、いろいろ違いも多い。
そしてコードを少し書き始めてみると、いろいろと不安な箇所が出てくる。
その一つがポインタの扱いで、例えば次のようなコードがコンパイルを通ってしまうのだ。
package main
import "fmt"
func getLocalVarPointer() *int {
n := 3
return &n // (1)
}
func main() {
p := getLocalVarPointer()
fmt.Printf("p:%p, *p:%d\n", p, *p)
}
$ go run check_pointer.go
p:0xc000070010, *p:3
上記コードの (1) の箇所は、C/C++ を経験したお前が見たら驚愕するはずだ。
C/C++ では static ではないローカル変数は、コールスタック上に確保される自動変数だ。関数の終了とともに消えてしまう未来のない変数のポインタを返すなど、職業プログラマが一番書いてはいけないコードのひとつだ。
だが、Golang のローカル変数は、まるでクロージャの自由変数のように、関数の終了後もどこかしらから参照されている限り生存期間が延ばされるようだ。
これに慣れてしまうと C/C++ に戻れなくなってしまうのではないか。
3.3.4. 代入の挙動を試す
コードを書いていて不安になる要因はポインタだけではない。
変数への代入を行う際、 = 演算子 の左辺に対して、右辺の実体がコピーされるのか、実体への参照がコピーされるのかがわからなくなるのだ。
例えば、C 言語では、 a = b とすれば b の値がコピーされ、 a = &b とすれば b の居場所であるアドレスがコピーされた。
C++ では「参照」という機能が導入され、 a = b とした際に、a が参照型変数 (int& 型など) の場合は、実質的には b のアドレスがコピーされるが、プログラマから見れば a をポインタではなく通常の (int 型など) の変数のように、 b のエイリアスとして扱うことができた。
そして Java にはポインタも参照も導入されなかった。a = b とした際に、プリミティブ型であれば値がコピーされ、参照型であれば実質的にはアドレスがコピーされた(お前も知っているとおり、例えば Java で 参照型を引数として渡した場合の挙動は、C++ の参照とは違い代入元の変数そのものに影響を与えることはなく、どちらかというと C/C++ のポインターの「値渡し」に近い挙動となる)。
Golang を触ってみて、このあたりの挙動がわからず不安になったので、次のようなコードを書いて確認してみた。
package main
import "fmt"
// 構造体の代入の挙動を調べる
func checkStruct() {
fmt.Println("----- 構造体の代入を検証")
x := struct { name string; age int }{ "Wesley", 37 }
y := x // (1) 構造体の代入は実体が複製される
y.name = "Jeremiah" // yの内容変更がxへ影響を与えない
fmt.Printf("&x.name:%p, x.name:%s\n",&x.name, x.name)
fmt.Printf("&y.name:%p, y.name:%s\n",&y.name, y.name)
fmt.Println()
}
// 配列の代入の挙動を調べる
func checkArray() {
fmt.Println("----- 配列の代入を検証")
x := [5]int {1,2,3,4,5} //要素数指定->配列
y := x // (2) 配列の代入は実体が複製される
y[2] = 0 // yの内容変更がxへ影響を与えない
fmt.Printf("x:%v, &x[0]:%p, len(x):%d, cap(x)%d\n", x, &x[0], len(x), cap(x))
fmt.Printf("y:%v, &y[0]:%p, len(y):%d, cap(y)%d\n", y, &y[0], len(y), cap(y))
fmt.Println()
}
// スライスの代入の挙動を調べる
func checkSlice() {
fmt.Println("----- スライスの代入を検証")
x := []int {1,2,3,4,5 } // 要素数省略->スライス
y := x // (3) スライスの代入は参照が複製される
y[2] = 0 // yの内容変更が x へ影響を与える
fmt.Printf("x:%v, &x[0]:%p, len(x):%d, cap(x)%d\n", x, &x[0], len(x), cap(x))
fmt.Printf("y:%v, &y[0]:%p, len(y):%d, cap(y)%d\n", y, &y[0], len(y), cap(y))
fmt.Println()
}
func main() {
checkStruct()
checkArray()
checkSlice()
}
$ go run check_assignment.go
----- 構造体の代入を検証
&x.name:0xc000068020, x.name:Wesley
&y.name:0xc000068040, y.name:Jeremiah
----- 配列の代入を検証
x:[1 2 3 4 5], &x[0]:0xc00007a060, len(x):5, cap(x)5
y:[1 2 0 4 5], &y[0]:0xc00007a090, len(y):5, cap(y)5
----- スライスの代入を検証
x:[1 2 0 4 5], &x[0]:0xc00007a120, len(x):5, cap(x)5
y:[1 2 0 4 5], &y[0]:0xc00007a120, len(y):5, cap(y)5
コードの (1) の箇所では「構造体」、(2) では「配列」をコピーしているが、どちらも実体がコピーされている。ただ、(3) のスライスでは実体ではなく参照がコピーされていることがわかる。
まとめると次のようになる。
| データ型 | y = x の挙動 | Java との比較 |
|---|---|---|
| 構造体 | y へ x の実体がコピーされる | Java と異なる |
| 配列 | y へ x の実体がコピーされる | Java と異なる |
| スライス | y へ 「x が参照する実体への参照」 がコピーされる |
一見 Java と同じ |
Java に慣れたお前が Golang を書く時は上記のことに注意すれば良いだろう。
また、Golang の特徴であるスライスは、動的配列として使えすごく便利そうではあるが、見た目が配列にそっくりなのに配列とは挙動が異なるため注意が必要だ。
また、スライスはこれ以外にもちょっと癖があり Java の配列とは異なる挙動となるため、コードを書いて検証してみる。
3.3.5. スライスの挙動を試す (shift / pop)
スライスは配列のシフト(先頭要素の削除)やポップ(終端要素の削除)、プッシュ(末尾に新しい要素を追加)などができるが、まずはシフトとポップを確認する。
package main
import "fmt"
func printSlice(msg string, x, y []string) {
fmt.Println(msg)
xv := fmt.Sprintf("%v", x)
yv := fmt.Sprintf("%v", y)
fmt.Printf("x:%-11s, &x[0]:%p, &x[1]:%p, len(x):%d, cap(x)%d\n", xv, &x[0], &x[1], len(x), cap(x))
fmt.Printf("y:%-11s, &y[0]:%p, &y[1]:%p, len(y):%d, cap(y)%d\n", yv, &y[0], &y[1], len(y), cap(y))
fmt.Println()
}
// スライスの shift/pop のチェック
func checkSliceShiftAndPop() {
fmt.Println("----- スライスの shift/pop を検証")
x := []string { "a", "b", "c", "d", "e" }
y := x
printSlice("(1)", x, y) // (1)
y = y[1:]
printSlice("(2)", x, y) // (2)
y = y[:3]
printSlice("(3)", x, y) // (3)
y[1] = "C"
printSlice("(4)", x, y) // (4)
}
func main() {
checkSliceShiftAndPop()
}
$ go run check_slice_shiftpop.go
----- スライスの shift/pop を検証
(1)
x:[a b c d e], &x[0]:0xc000076000, &x[1]:0xc000076010, len(x):5, cap(x)5
y:[a b c d e], &y[0]:0xc000076000, &y[1]:0xc000076010, len(y):5, cap(y)5
(2)
x:[a b c d e], &x[0]:0xc000076000, &x[1]:0xc000076010, len(x):5, cap(x)5
y:[b c d e] , &y[0]:0xc000076010, &y[1]:0xc000076020, len(y):4, cap(y)4
(3)
x:[a b c d e], &x[0]:0xc000076000, &x[1]:0xc000076010, len(x):5, cap(x)5
y:[b c d] , &y[0]:0xc000076010, &y[1]:0xc000076020, len(y):3, cap(y)4
(4)
x:[a b C d e], &x[0]:0xc000076000, &x[1]:0xc000076010, len(x):5, cap(x)5
y:[b C d] , &y[0]:0xc000076010, &y[1]:0xc000076020, len(y):3, cap(y)4
このプログラムでは、(2) の直前の y = y[1:] でシフト操作(先頭要素の削除)を、(3) の直前の y = y[:3] でポップ操作(終端要素の削除)を行っている。またプログラムで表示している len(x) は x の要素数を表し、 cap(x) は x のキャパシティを表している(Golang では、スライスの拡張時に備えて、スライスが参照する実体(配列)の容量を、予めスライスの見かけ上の要素数より多めに確保することがあり、キャパシティとはその容量のこという)。
ここで注目すべきは以下の 4 点だ。
- シフト操作
y = y[1:]の後の (2) の箇所で、x[1] のアドレスと y[0] のアドレスが同じであること - (2) の箇所で len(y) と cap(y) が 5 から 4 に減っていること
- ポップ操作
y = y[:3]の後の (3) の箇所で、len(y) が 3 に減っているが、cap(y) が 4 のままであること - 要素値変更
y[1] = "C"の後の (4) の箇所で、 y[1] への変更が x[2] へも反映されていること
このことから、スライスのシフトやポップ操作時に背後で以下のようなことが行われていると想定できる。
以下の図に示すように、x のスライス(赤枠)が生成される時に、その裏側で実体の配列(青枠)が生成される。ここではこの青枠部分をエンティティ (Entity) と呼ぶことにする。この時のキャパシティ (cap) はスライスのサイズ (len) と同じ 5 である。

次に、y に x が代入される(下図)。この時 y のスライス(赤枠)が生成されるが、エンティティは x と同じものを参照している。

次に、シフト操作 (y = y[1:]) により y の先頭要素が削除される(下図)。
だが、実際にはエンティティは何も変わっておらず、スライス側(緑部分)が右側にずれたような形となっている。そしてこの時当然 len(y) は 5 から 4 に減るが、実体のエンティティに変化がなく末尾に余裕がない状態なので cap(y) も小さくなり 4 になっている。

続いて、ポップ操作 (y = y[:3]) により y の終端要素が削除される(下図)。
len は 4 から 3 に減ったが、この時もエンティティは何も変わっておらず、スライスの末尾にひとつ余裕がある形となり cap は減らずに 4 のままだ。

最後に、代入操作 (y[1] = "C") により、スライス y の左から 2 番目の要素 y[1] の値が変更される(下図の緑部分)。
そしてこれによりエンティティが変更された(青部分)ことにより、同じ要素を参照している x[2] に反映 (reflection) されている。

3.3.6. スライスの挙動を試す (push)
次にプッシュ(末尾に新しい要素を追加)を検証する。
package main
import "fmt"
func printSlice(msg string, x, y []string) {
fmt.Println(msg)
xv := fmt.Sprintf("%v", x)
yv := fmt.Sprintf("%v", y)
fmt.Printf("x:%-15s, &x[0]:%p, &x[1]:%p, len(x):%d, cap(x)%d\n", xv, &x[0], &x[1], len(x), cap(x))
fmt.Printf("y:%-15s, &y[0]:%p, &y[1]:%p, len(y):%d, cap(y)%d\n", yv, &y[0], &y[1], len(y), cap(y))
fmt.Println() }
// スライスの push(append) のチェック
func checkSlicePush() {
fmt.Println("----- スライスの push(append) を検証")
x := []string { "a", "b", "c", "d", "e" }
y := x
y[1] = "B"
printSlice("(1)", x, y) // (1)
x = append(x, "F")
printSlice("(2)", x, y) // (2)
y[3] = "D"
printSlice("(3)", x, y) // (3)
y = x
x = append(x, "G")
y[3] = "D"
printSlice("(4)", x, y) // (4)
}
func main() {
checkSlicePush()
}
$ go run check_slice_push.go
----- スライスの push(append) を検証
(1)
x:[a B c d e] , &x[0]:0xc000076000, &x[1]:0xc000076010, len(x):5, cap(x)5
y:[a B c d e] , &y[0]:0xc000076000, &y[1]:0xc000076010, len(y):5, cap(y)5
(2)
x:[a B c d e F] , &x[0]:0xc000078000, &x[1]:0xc000078010, len(x):6, cap(x)10
y:[a B c d e] , &y[0]:0xc000076000, &y[1]:0xc000076010, len(y):5, cap(y)5
(3)
x:[a B c d e F] , &x[0]:0xc000078000, &x[1]:0xc000078010, len(x):6, cap(x)10
y:[a B c D e] , &y[0]:0xc000076000, &y[1]:0xc000076010, len(y):5, cap(y)5
(4)
x:[a B c D e F G], &x[0]:0xc000078000, &x[1]:0xc000078010, len(x):7, cap(x)10
y:[a B c D e F] , &y[0]:0xc000078000, &y[1]:0xc000078010, len(y):6, cap(y)10
Golang ではスライスのプッシュ操作を append() という関数で行う。
このプログラムでは、(2) の直前の x = append(x, "F") と (4) の少し前の x = append(x, "G") でプッシュ操作(末尾に新しい要素を追加)が行われている。
ここで注目すべきは以下の 5 点だ。
- append() という関数は、第 1 引数でスライスを渡し、戻り値でもスライスを受け取る使い方をするということ
- x へのプッシュ操作
x = append(x, "F")の後の (2) の箇所で、x[0] や x[1] のアドレスが (1) の時点から変化していること - (2) の箇所で len(x) が 1つ増え 6 になるが、 cap(x) が 10 になっているということ
- (2) と同じ x へのプッシュ操作なのに、
x = append(x, "G")の後の (4) の箇所では、x[0] や x[1] のアドレスが (3) の時点から変化していないこと - (3) と (4) の直前にスライス y に対して
y[3] = "D"という同じ操作をしているが、(3) では x 側に反映されず (4) では x に反映されていること
このことから、スライスのプッシュ操作時に背後で以下のようなことが行われていると想定できる。
シフトやポップ操作の時と同様、x のスライス(赤枠)が生成される時に、その裏側で実体の配列(青枠)が生成される。この時のキャパシティ (cap) はスライスのサイズ (len) と同じ 5 である(下図)。

次に y に x が代入される(下図)。この時 y のスライス(赤枠)が生成されるが、エンティティは x と同じものを参照している。

その後 y[1] に "B" が代入され、これが x[1] にも反映する(下図)。

次に x 側のプッシュ操作が行われる(下図)。この時 Entity のキャパシティが 5 で満杯であるため cap:10 の新しいエンティティが生成され(青枠)、スライス x はこれを参照するようになる(赤枠)。また、プッシュ操作により x の末尾に新しい要素が一つ追加され(緑部分)len(x) は 6 になる。また、元のエンティティを参照したままの y には、 x へのこの操作は反映されない (non-reflection)。

ここで注目したいことが 2 点ほどある。
- 1 つ目はこの append() という関数が
newslice = append(oldslice, item)の形でスライスを戻り値として受け取らなければならない理由は、上図のように新たに Entity が生成されスライスが再構成される(ことがある)からだと考えられる。変数 oldslice は古いスライス(上図の薄いグレー部分)を参照したままなのだ。 - 2 つ目は、エンティティが満杯の状態で append() が実行されると、何らかのアルゴリズムに従って cap が余裕を持って増やされることだ。ここでは 5 -> 10 の 2 倍となっている。
その後、y[3] に対して "D" が代入されるが、x はもはや別のエンティティを参照しているため、x 側へは反映されず x[3] は "d" のままだ(下図)。

そして変数 y へ x が代入される(下図)。
再構成された y (赤枠)は x と同じ新しいエンティティを参照するようになり、元のエンティティはどこからも参照されなくなる(いずれ消えると考えられる)。

その後、再び x へのプッシュ操作が行われる(下図)が、今度は Line 4 の時とは違い、エンティティのキャパシティに余裕がある (cap:10) ため、x のスライスは再構成されず末尾に新しい要素が追加されるだけだ(緑枠)。そして、x へのこの操作は y には反映されない。

最後に y[3] に対して "D" が代入される(下図)。これは Line 5 と同じ操作であるが、x 側から見た結果は異なっている。同じエンティティを参照しているため、Line 5 の時とは異なり x[3] にもこれが反映されている。

このように Golang のスライスへのプッシュ操作 (append) は、状況によりミュータブルだったりイミュータブルだったりする。安全性だけを考えるならイミュータブルな方がメリットが大きいが、パフォーマンス低下を考えるとそういうわけにもいかないということだ。
そして、お前が Golang を書く際は、Java の java.util.List インターフェースでやっていたような、複数の箇所からスライスを参照する使い方はすべきではなく、常に単一のアクセサなどを介して要素を取り出したり追加したりすべきだ。
3.3.7. ポリモーフィズムを試す
「複数戻り値」や、「関数オーバーロードの非サポート」など Golang の特徴はいろいろあるが、特に気になるのはオブジェクト指向へのその独特なアプローチの仕方だ。
例えば java のオブジェクト指向は、クラスによる中央集権システムだ。フィールドもメソッドもクラスという元首の統治下に置かれる。だからクラスを見ればデータとメソッドについて知ることができた。
class T {
int field1; // フィールドはクラス T の統治下
method1 {} // メソッドはクラス T の統治下
method2 {} // メソッドはクラス T の統治下
}
だが Golang のメソッドはロックバンドのファンダムみたいなものだ。
「型」というバンドに対して勝手にファンとして名乗り出た、運営側の統治から自由な者たちが「メソッド」という存在だ。
type T struct {
field1 int // フィールドは構造体 T の統治下
}
func (t T) method1() {} // メソッドは T の統治からは自由
func (t T) method2() {} // メソッドは T の統治からは自由
インターフェースもちょっと変わっている。
Java の場合は、クラスが「このインターフェースを実装していますよ」と宣言する必要がある。
だが Glang のインターフェースは、ダックタイピング的に処理されるんだ。
実装を宣言しなくとも、同じメソッドを揃えていればインターフェースとして処理される。
interface X { method1(); } // インターフェース(I/F) X
class Y implements X { method1(){} } // クラス Y は I/F X の実装を宣言している
class Z { method1(){} } // クラス Z は I/F X の実装を宣言していない
X x1 = new Y(); // <- Y が X の実装を宣言しているので OK
X x2 = new Z(); // <- Z が X の実装を宣言していないのでコンパイルエラー
type X interface { method1() } // インターフェース(I/F) X
type Y struct {} // 構造体 Y は I/F X のことに触れていない
type Z struct {} // 構造体 Z も I/F X のことに触れていない
func (y Y) method1(){} // 構造体 Y の メソッドも I/F X のことに触れていない
func (z Z) method1(){} // 構造体 Z の メソッドも I/F X のことに触れていない
var x1 X = Y {} // 構造体 Y は method1() を実装しているので OK
var x2 X = Z {} // 構造体 Z は method1() を実装しているので OK
これらを考慮して Golang でポリモーフィズムをどのように実現できるのか、コードを書いて試してみる。
3.3.7.1. プログラムの概要
ポリモーフィズムの題材としてはベクタ系グラフィック・ソフトウェアの実装が分かりやすいと思うが、ここではコンソールをキャンバスとする文字ベースの簡単なドロープログラムを書くこととする。
プログラムの構成は以下のとおりだ。
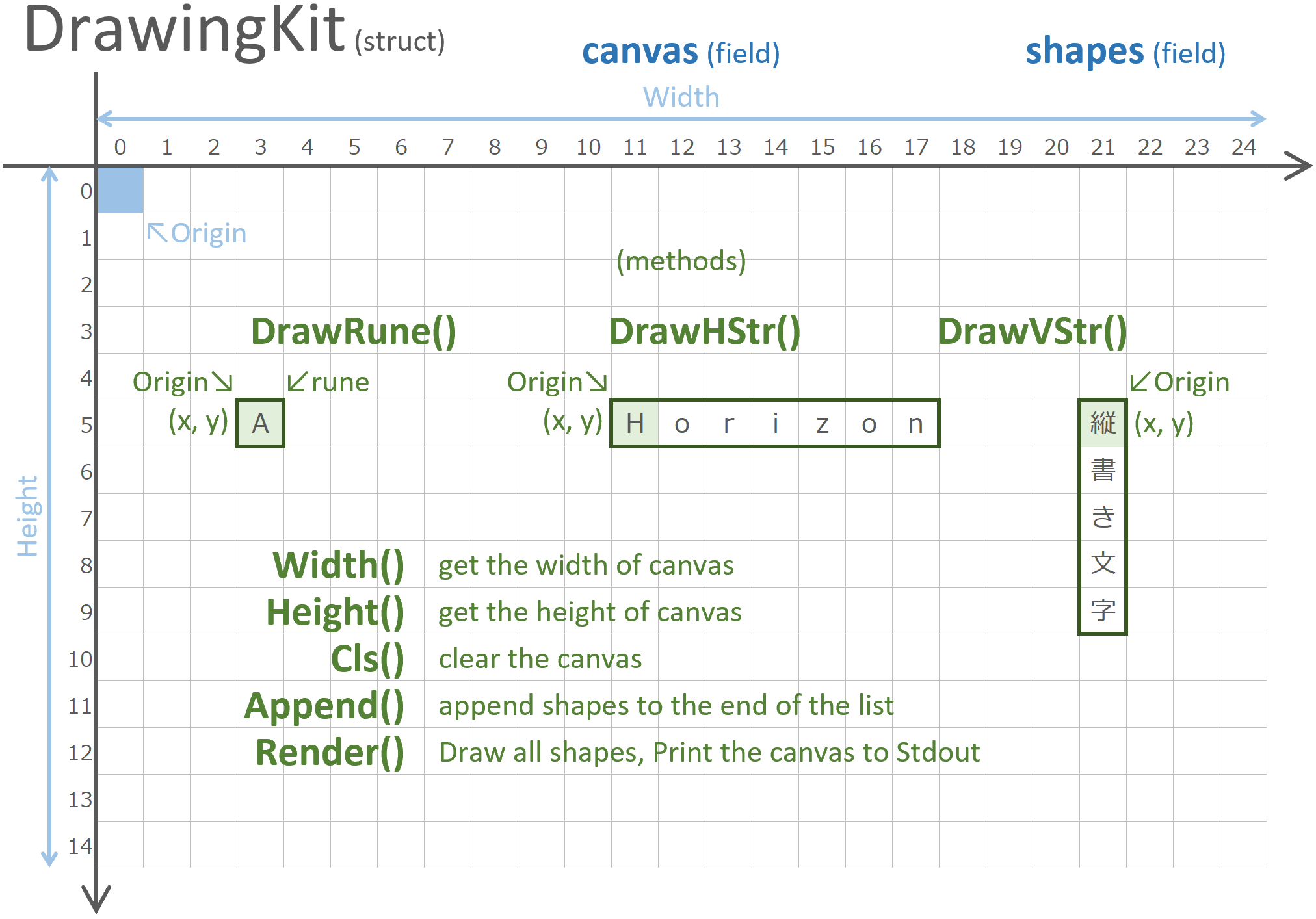
- 構造体 DrawingKit はフィールドとして、描画空間の canvas と、描画オブジェクトのリスト shapes を持っている
- canvas は幅 width と高さ height を持っており、この座標空間はスクリーンの左上を原点 (Origin) とする。
- キャンバスの最小単位は文字 (Rune) であり、ここには JIS X 0208 文字セット(いわゆる全角文字)の等幅フォントが描画されることを期待している。
- DrawingKit はキャンバスに描画するための基本的なメソッドとして以下を持っている。
- DrawRune() 任意の座標に 1 文字描画する。
- DrawHStr() 任意の座標に 1 行の文字列を水平に描画する。
- DrawVStr() 任意の座標に 1 行の文字列を垂直に描画する。
- Width() キャンバスの幅を得る
- Height() キャンバスの高さを得る
- Cls() キャンバスをクリアする(空白文字で埋め尽くす)
- Append() シェイプ・インターフェース(後述)を追加する
- Render() すべてのシェイプ・インターフェースを描画し標準出力へ出力する
3.3.7.2. インターフェースの設計
また、DrawingKit はシェイプ・インターフェース (Interface Shape) を用意し、拡張描画機能を外部で実装できるようにする。
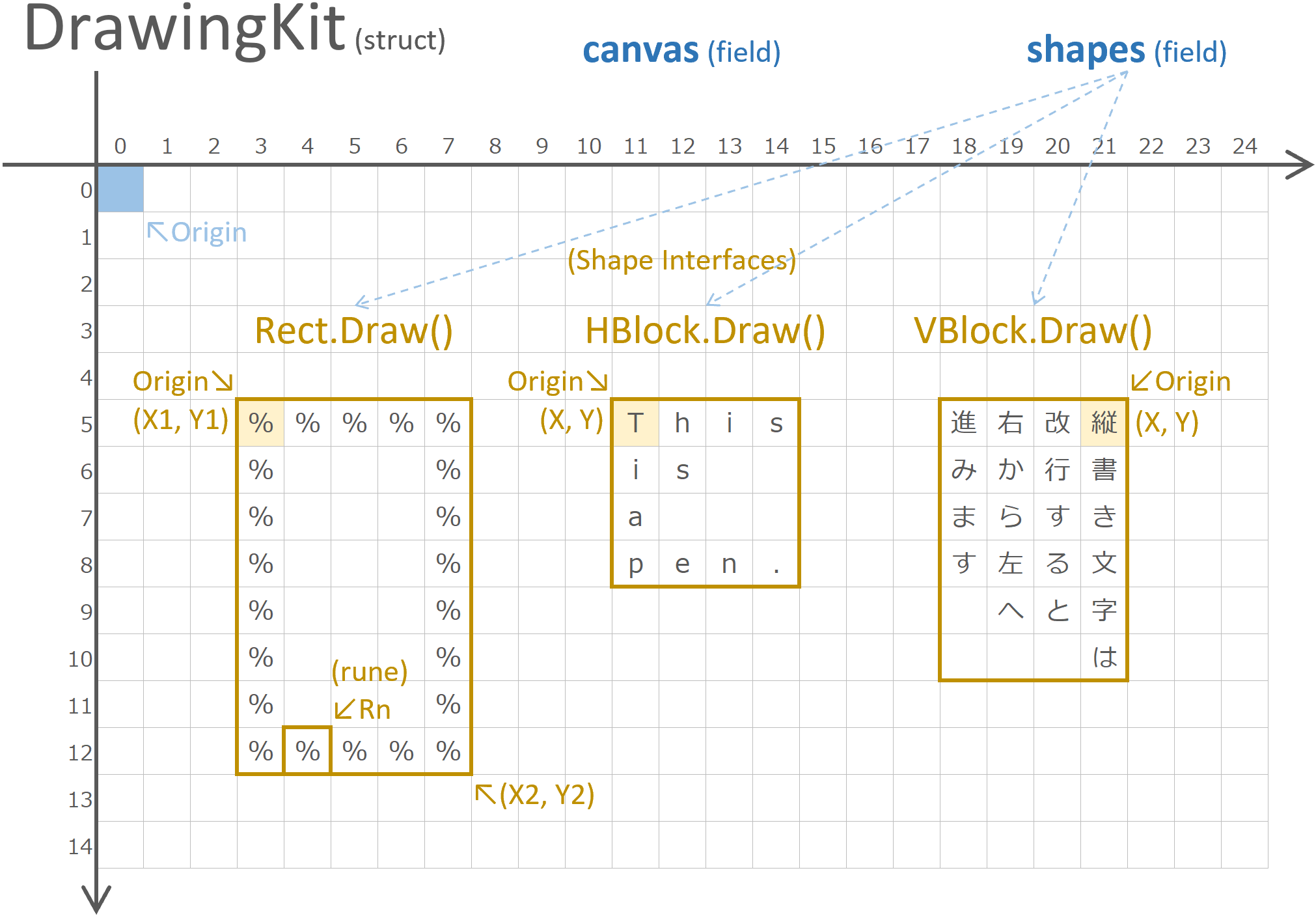
本プログラムでは、シェイプ・インターフェースとして以下の 3 つを用意する。
また、これらのオブジェクトはすべて、シェイプ・インターフェースとして必要な Draw() メソッドを持つ。
- Rect 任意の文字で中抜きの矩形を描く
- HBlock 複数行文字列のブロックを横書きに描く
(行内は左から右、改行で上から下へ移動) - VBlock 複数行文字列のブロックを縦書きに描く
(行内は上から下、改行で右から左へ移動)
3.3.7.3. プログラムコード
具体的なプログラムは以下のとおりだ。
package main
import ( "bufio"; "fmt"; "io"; "strings" )
// 数値を比較して小さい方を先に返す
func minmax(a, b int) (min, max int) {
if a < b { return a, b }
/*else*/ { return b, a }
}
// io.Reader (テキストデータの) を文字列スライスへ
func ior2ss(ior io.Reader) ([]string, error) {
var ss []string
sc := bufio.NewScanner(ior) // 指定された io.Reader のスキャナを生成
for sc.Scan() { ss = append(ss, sc.Text()) } // スキャンしたすべての行をスライスへ投入
return ss, sc.Err()
}
// 文字(ルーン)の2次元スライスを作る
func makeRune2DA(w int, h int) [][]rune {
tda := make([][]rune, h)
for i := 0; i < h; i++ {
tda[i] = make([]rune, w)
}
return tda
}
// シェイプインターフェース
type Shape interface { Draw(c *DrawingKit) } // (1) インターフェース
// ドローイングキット
// 文字で構成された描画空間 (等幅フォントの全角文字を想定)
type DrawingKit struct {
canvas [][]rune // キャンバス (文字の2次元スライス)
shapes []*Shape // シェイプ群
}
// ドローイングキットを生成する
func NewDrawingKit(w int, h int) *DrawingKit {
kit := new(DrawingKit) // ドローイングキットは、
kit.canvas = makeRune2DA(w, h) // キャンバスと、
kit.shapes = []*Shape {} // そこに描画するシェイプ群を持つ
kit.Cls()
return kit
}
// キャンバスの幅と高さを得る
func (kit *DrawingKit) Width () int { return len(kit.canvas[0]) }
func (kit *DrawingKit) Height() int { return len(kit.canvas) }
// キャンバスをクリアする
func (kit *DrawingKit) Cls() {
for i := 0; i < kit.Height(); i++ {
for j := 0; j < kit.Width(); j++ {
kit.canvas[i][j] = ' ' // JIS X 0208 文字セットの空白文字で埋める
}
}
}
// シェイプを追加する
func (kit *DrawingKit) Append(shape *Shape) {
kit.shapes = append(kit.shapes, shape)
}
// すべてのシェイプをキャンバスへ描画して標準出力へ
func (kit *DrawingKit) Render() {
kit.Cls()
for _, shape := range kit.shapes { (*shape).Draw(kit) } // (2) ポリモーフィズム
for _, line := range kit.canvas { fmt.Println(string(line)) }
}
// キャンバスに点を打つ (一文字書く)
func (kit *DrawingKit) DrawRune(x int, y int, r rune) {
if r < ' ' { return; } // 制御文字は描画しない
if x < 0 { return; } // キャンバスの
if y < 0 { return; } // 外に飛び出した
if x >= kit.Width() { return; } // 文字は
if y >= kit.Height(){ return; } // 描画しない
kit.canvas[y][x] = r
}
// キャンバスに水平線を引く (文字列を左から右へ書く)
func (kit *DrawingKit) DrawHStr(x int, y int, s string) {
for i, r := range []rune(s) { kit.DrawRune(x + i, y, r) }
}
// キャンバスに垂直線を引く (文字列を上から下へ書く)
func (kit *DrawingKit) DrawVStr(x int, y int, s string) {
for i, r := range []rune(s) { kit.DrawRune(x, y + i, r) }
}
// 横書きの文章ブロックを描くシェイプ (左から右へ。改行したら下へ) (3) I/F を実装する構造体
type HBlock struct { X int; Y int; S string }
func (b *HBlock) Draw(kit *DrawingKit) {
ior := strings.NewReader(b.S)
ss,_ := ior2ss(ior)
for i, s := range ss { kit.DrawHStr(b.X, b.Y + i, s) }
}
// 縦書きの文章ブロックを描くシェイプ(上から下へ。改行したら左へ) (4) I/F を実装する構造体
type VBlock struct { X int; Y int; S string }
func (b *VBlock) Draw(kit *DrawingKit) {
ior := strings.NewReader(b.S)
ss,_ := ior2ss(ior)
for i, s := range ss { kit.DrawVStr(b.X - i, b.Y, s) }
}
// 2点を頂点とする矩形を描くシェイプ (2点と描画する1文字を指定) (5) I/F を実装する構造体
type Rect struct { X1 int; Y1 int; X2 int; Y2 int; Rn rune }
func (r *Rect) Draw(kit *DrawingKit) {
x1, x2 := minmax(r.X1, r.X2)
y1, y2 := minmax(r.Y1, r.Y2)
s := string([]rune{r.Rn})
hs := strings.Repeat(s, x2 - x1 + 1)
kit.DrawHStr(x1, y1, hs)
kit.DrawHStr(x1, y2, hs)
vs := strings.Repeat(s, y2 - y1 + 1)
kit.DrawVStr(x1, y1, vs)
kit.DrawVStr(x2, y1, vs)
}
const vScripts =`
招待状
拝啓 青葉が薫る頃となりました
皆様方にはお変わりなくお過ごしのことと存じます
このたび わたしたちは音楽会をすることになりました
バンドが初めて出会った思い出のレストランにて
日頃からお付き合いをいただいております皆様をお招きし
ささやかではありますがパ|ティ|を開きたいと思います
お忙しいなか恐縮ではございますが
ぜひご出席くださいますよう
お願い申し上げます
なお 立食パ|ティ|となりますので
平服でおいでいただければ幸いです
敬具
令和二年六月吉日
ザ・ルミニア|ズ
ウェスリ|・シュルツ
ジェレマイア・フレイテス
ネイラ・ペカレック
`
const hScripts =`
American
forlk rock band
based in
denver,Colorado
The Lumineers
`
func main() {
var kit *DrawingKit = NewDrawingKit(33, 30) // ドローイングキット
var vBlock Shape = &VBlock {31, 2, vScripts } // 縦書きの文のシェイプ
var hBlock Shape = &HBlock { 3, 20, hScripts } // 横書きの文のシェイプ
var frame1 Shape = &Rect { 0, 0, 32, 29, '*' } // 外側フレームのシェイプ
var frame2 Shape = &Rect { 2, 20, 18, 27, '・' } // 内側フレームのシェイプ
kit.Append(&vBlock)
kit.Append(&hBlock)
kit.Append(&frame1)
kit.Append(&frame2)
kit.Render() // 描画する
}
3.3.7.4. ポリモーフィズムの実現箇所
Golang でのポリモーフィズムの実現箇所は、上記コードの、
- (1)
type Shape interface { Draw(c *DrawingKit) }
ここで Shape インターフェースを定義している。 Shape インターフェースは DrawingKit へのポインタを引数とする Draw() メソッドを実装していなければならない。 - (2)
(*shape).Draw(kit)
ここでポリモーフィズムを行っている。具体的には、Shape インターフェースを持つ異なる型に対して、それぞれがどのような振舞いをするのかがわからないまま、同じ呼び出し方をしている。 - (3)
func (b *HBlock) Draw(kit *DrawingKit)
ここで「横書きブロックのデータ型」に、Shape インターフェースとして必要な Draw() メソッドを実装している。 - (4)
func (b *VBlock) Draw(kit *DrawingKit)
「縦書きブロックのデータ型」へも Shape インターフェースとしての実装をしている。 - (5)
func (r *Rect) Draw(kit *DrawingKit)
「矩形データ型」にも Shape インターフェースとしての実装をしている。
実行結果は以下のとおりだ。
$ go run drawing_kit.go
*********************************
* *
* ネジウ ザ 令 敬 平な おぜお さ日バ こ 皆拝 招 *
* イェェ ・ 和 具 服お 願ひ忙 さ頃ン の 様啓 待 *
* ラレス ル 二 で いごし やかド た 方 状 *
* ・マリ ミ 年 お立 申出い からが び に青 *
* ペイ| ニ 六 い食 し席な でお初 は葉 *
* カア・ ア 月 でパ 上くか は付め わ おが *
* レ・シ | 吉 い| げだ恐 あきて た 変薫 *
* ッフュ ズ 日 たテ まさ縮 り合出 し わる *
* クレル だィ すいで まい会 た り頃 *
* イツ け| まは すをっ ち なと *
* テ れと すご がいた は くな *
* ス ばな よざ パた思 音 おり *
* 幸り うい |だい 楽 過ま *
* いま ま テい出 会 ごし *
* です す ィての を した *
* すの が |おレ す の *
* で をりス る こ *
* 開まト こ と *
* ・・・・・・・・・・・・・・・・・ きすラ と と *
* ・American ・ た皆ン に 存 *
* ・forlk rock band・ い様に な じ *
* ・based in ・ とをて り ま *
* ・denver,Colorado・ 思お ま す *
* ・ ・ い招 し *
* ・The Lumineers ・ まき た *
* ・・・・・・・・・・・・・・・・・ すし *
* *
*********************************
実際に書いてみて思うのは、Golang のメソッドやインターフェースを扱うには慣れが必要だろうということだ。メソッドオーバーロードが出来ない点や、クラス継承ができない点、識別子の可視性を大文字始まりかどうかどうかで決めるルールも含めて、どのような設計パターンに落とし込むのが良いか、書いていて戸惑うことが多かった。まあ、このあたりは良いライブラリやフレームワークに触れることで少しづつコツを掴めるようになっていくだろう。
3.3.8. goroutine を試す
Golang の大きな売りの一つは、言語名を冠した非同期通信機構 goroutine だろう。
今回これを試すにあたって「野うさぎと穴うさぎ」をモチーフにした簡単なプログラムを書くことにする。
「野うさぎ (Hare)」はイソップ寓話の「ウサギとカメ (The Tortoise and the Hare)」に登場するアイツのことで、「穴うさぎ (Rabbit)」は「ピーターラビットのおはなし (The Tale of Peter Rabbit)」の主人公のアイツのことだ。
3.3.8.1. プログラムの概要
この「野うさぎ (Hare)」と「穴うさぎ (Rabbit)」をモチーフにして、以下のような構成のプログラムを考えてみる。
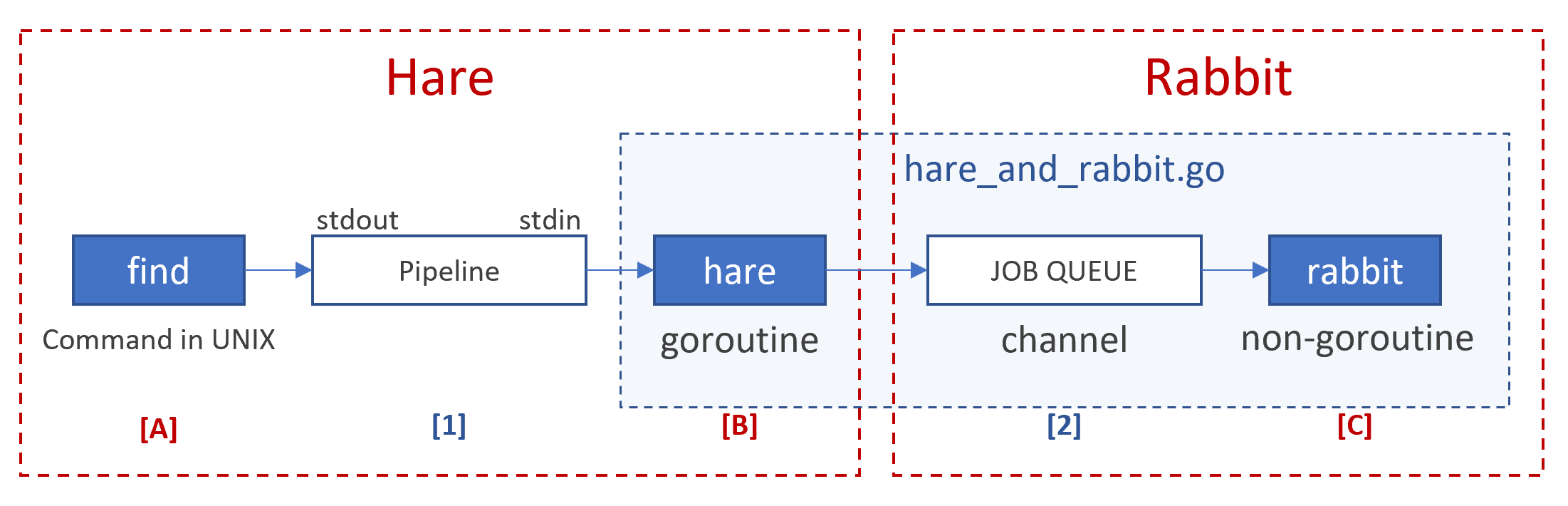
Golang で書くプログラム (hare_and_rabbit.go) は上図の青枠の部分 ([B]~[C]) であるが、全体としては以下のようになっている。
- 活発な野うさぎ (Hare) は山々をめぐり、木の実を採ってきては穴ぐらに放り込む。
(ディレクトリツリーからテキストファイルを探してきてジョブキューに投入する)-
[A]UNIX 系 OS コマンドの find がファイルを検索し標準出力へパスのリストを出力する。 -
[1]UNIX 系 OS のパイプライン (標準出力を次のコマンドの標準入力へつなぐ) 。 -
[B]標準入力のファイル(パス)リストを元にひとつづつファイルを読み込み、読み込んだファイルをジョブキューに投入する (goroutine) 。
-
- 穴ぐらは、入り口から奥の部屋まで続く細いトンネルになっている。
-
[2]ジョブキュー。チャンネル機能 (Golang のスレッド間通信のための媒体) を使ったサイズ 100 のバッファ。
-
- まじめな穴うさぎ (Rabbit) は、穴ぐらの奥のキッチンで木の実を料理する。
-
[C]ジョブキューからファイルを取り出しては、ファイルを行単位で比較・ソートし、各ファイルの最終行の先頭数文字を表示する (goroutine ではなく、メイン関数と同じスレッド) 。
-
3.3.8.2. プログラムの使用例
なお、出来上がったプログラムは以下のような使い方を想定している。
$ # カレントディレクトリ配下の ruby ファイルを探し、各ファイルをソート・最終行を表示する
$ find ~/ -type f -name '*.rb'| ./hare_and_rabbit
(Hare) --> rubygems_plugin.rb #(野うさぎ) 穴ぐらに投入
rubygems_plugin.rb --> (Rabbit) begin... #(穴うさぎ) 調理開始
rubygems_plugin.rb --> (Rabbit) => [Done] if defined #(穴うさぎ) 調理終了
(Hare) --> rbconfig.rb
rbconfig.rb --> (Rabbit) begin...
(Hare) --> jacobian.rb
(Hare) --> ludcmp.rb
rbconfig.rb --> (Rabbit) => [Done] module RbC
(Hare) --> math.rb
...
ちなみに、上図のパイプライン [1] やジョブキュー [2] は、本稿でもいくつか書いた、他言語の list.map().select().reduce() などのメソッドチェーンと使い方は似ているが、ひとつ大きな違いがある。
メソッドチェーンは単一スレッド内の逐次処理であるため前工程が完了しないと次のフェーズへは進まない。だが、パイプライン [1] や今回の非同期処理で使うジョブキュー [2] は、前工程が終了する前に次工程が開始するため、全体としてのリードタイム短縮が期待できる。
3.3.8.3. プログラムコード
プログラムは以下のとおりだ。
package main
import ( "bufio"; "fmt"; "io"; "os"; "path/filepath"; "sort"; "strings" )
// io.Reader (テキストデータの) を文字列スライスへ
func ior2ss(ior io.Reader) ([]string, error) {
var ss []string
sc := bufio.NewScanner(ior) // 指定された io.Reader のスキャナを生成
for sc.Scan() { ss = append(ss, sc.Text()) } // スキャンしたすべての行をスライスへ投入
return ss, sc.Err()
}
// テキストファイルを読み込んで文字列スライスへ
func tf2ss(path string) ([]string, error) {
file, err := os.Open(path) // 指定されたテキストをオープン
if err != nil { return nil, err }
defer file.Close() // ファイルクローズの予約
return ior2ss(file) // ior2ss へ委譲
}
// 文字列スライスの最後の要素を取り出す
func lastItem(ss []string) string {
if len(ss) > 0 { return ss[len(ss)-1] } // スライスの最後の要素を返す
/*else*/ { return "" } // 空のスライスは "" を返す
}
// 文字列の最初の数文字を取り出す
func head(s string, n int) string {
if len(s) > n { return s[0:n] }
/*else*/ { return s }
}
// 文字列整形 (長すぎる場合は切り、短い場合は空白を埋める)
func alignLen(s string, n int) string {
slen := len(s)
switch {
case slen > n : return head(s, n) // nより長い場合は切る
case slen < n : return s + strings.Repeat(" ", n - slen) // 短い場合は空白を埋める
default : return s
}
}
// 文字列スライスから最後の要素の最初の数文字を取り出す
func headOfLastLine(ss []string, n int) string {
last := lastItem(ss) // 最後の要素の
return head(last, n) // 先頭の数文字
}
// 通知関連関数群
const gPre = " " // 接頭辞
const gIntr = " --> (Rabbit) " // 接合時
func hareNotifyQueued(path string) { // 野ウサギの通知 (キュー投入時)
pre := "(Hare) --> "
file := filepath.Base(path)
fmt.Println(pre + file)
}
func rabbitNotifySortBegin(path string) { // 穴ウサギの通知 (ソート開始前)
file := filepath.Base(path)
file_h := alignLen(file,20)
suf := gIntr + " begin..."
fmt.Println(gPre + file_h + suf)
}
func rabbitNotifySortDone(tf *TextFile) { // 穴ウサギの通知 (ソート終了後)
file := filepath.Base(tf.Path)
file_h := alignLen(file, 20)
intr := gIntr + "=> [Done] "
body_h := headOfLastLine(tf.Body, 20)
fmt.Println(gPre + file_h + intr + body_h)
}
func printStderr(err error) { // 標準エラー出力へメッセージ送出
fmt.Fprintln(os.Stderr, err.Error())
}
// テキストファイル構造体 (パス名とファイルの内容)
type TextFile struct { Path string; Body []string }
// 野ウサギの実装 (テキストファイルをキューへ投入)
func hare(que chan *TextFile) {
sc := bufio.NewScanner(os.Stdin) // 標準入力のスキャナを取り出し
for sc.Scan() { // スキャン (EOF までループ)
path := sc.Text() // 1行取り出す (パス名)
body, err := tf2ss(path) // このパスのフィルの内容を取り出す
if err == nil { // (A) 例外ハンドリング
que <- &TextFile{ path, body } // (1) キューへ投入 (キューが満杯ならブロック)
hareNotifyQueued(path) // 通知
} else {
printStderr(err) // (B) 例外処理 permission denied など
}
}
close(que) // (2) キューを閉じる
}
// 穴ウサギの実装(キューから取り出したテキストファイルをソート)
func rabbit(que chan *TextFile) {
for {
tf, ok := <-que // (3) キューから読み出し (キューが空ならブロック)
if !ok { break; } // (4) キューが閉じられていれば終了
rabbitNotifySortBegin(tf.Path) // ソート前通知
sort.Strings(tf.Body) // ファイルの各行を比較してソート
rabbitNotifySortDone(tf) // ソート後の通知
}
}
// メイン
func main() {
que := make(chan *TextFile, 100) // (5) キューを作る (バッファサイズ 100)
go hare(que) // (6) 野ウサギに仕事を依頼 (goroutine)
rabbit (que) // (7) 穴ウサギに仕事を依頼 (通常のルーチン)
}
3.3.8.4. 非同期処理の実現箇所
上記プログラムの非同期関連の記述は以下のとおりだ。
- (1)
que <- &TextFile{ path, body }
野うさぎ (Hare) の処理。<-演算子を使い、読み込んだファイルを、引数で渡された que に投入している。この時、もし que が満杯 (チャンネルのバッファサイズ上限に達した状態) なら、ここで処理はブロックされる。 - (2)
close(que)
野うさぎ (Hare) の処理。標準入力がクローズされたので、処理を終え que をクローズしている。チャンネルがクローズされると、通信先の goroutine はそれを知ることができる。 - (3)
tf, ok := <-que
穴うさぎ (Rabbit) の処理。<-演算子を使い、キューから情報を取り出している。 que が空の場合は、ここで処理がブロックされる。 - (4)
if !ok { break; }
穴うさぎ (Rabbit) の処理。 (3) でキューからの読み出しを試行し、戻り値 (変数 ok) が false の場合は、通信先がクローズされているため、ここでループを抜けて関数全体の処理を終了する。 - (5)
que := make(chan *TextFile, 100)
メイン関数内。バッファサイズ 100 のチャンネルを生成し、これを本プログラムの que としている。 - (6)
go hare(que)
メイン関数内。野うさぎ (Hare) を goroutine (非同期ルーチン) としてコールしている。非同期なためこの関数コールはブロックされない。 - (7)
rabbit (que)
メイン関数内。穴うさぎ (Rabbit) を non-goroutine (同期ルーチン) としてコールしている。通常の関数コールなので、関数の処理が終了するまで処理はブロックされる。
プログラムの実行結果は以下のとおりだ。
...
(Hare) --> paragraph.rb
darkfish.rb --> (Rabbit) => [Done] require 'rdoc/genera
json_index.rb --> (Rabbit) begin... # (1)
(Hare) --> parser.rb
(Hare) --> pre_process.rb
(Hare) --> raw.rb
(Hare) --> regexp_handling.rb
(Hare) --> rule.rb
(Hare) --> to_ansi.rb
(Hare) --> to_bs.rb
(Hare) --> to_html.rb
(Hare) --> to_html_crossref.rb
(Hare) --> to_html_snippet.rb
(Hare) --> to_joined_paragraph.rb
(Hare) --> to_label.rb
json_index.rb --> (Rabbit) => [Done] rescue LoadError # (2)
...
ちなみに、穴うさぎ (Rabbit) は、(1) の通知を終えてから (2) の通知をするまでの間、(sort.Strings 関数内で) I/Oを伴わない処理しかしていないと思われるが、この間に複数回の野うさぎ (Hare) によるキュー投入が行われている。コア数が豊富な環境ではなんとも言えないが、プロセスの CPU 割り当てを絞ったら、どのようなタイミングでコンテキスト・スイッチが行われるのか気になるところだ。
また、今回の趣旨からは外れるが、上記コードの (A) (B) の箇所で例外ハンドリングを行っている。
お前の時代は、言語に搭載された例外処理機構の try ブロックに処理を包み込めばたちまち幸せになれると信じられていた。でもブロックが大きくなるとエラーを捉えるのが難しくなり、エラーを細かく補足しようとすると今度はインデントが深くなってプログラムの見通しが悪くなるという悪循環から逃げ切ることはできなかった。
Golang は、try/catch による例外補足を止め、代わりに複数戻り値を言語仕様に盛り込んだ。どちらにしても業務で書くコードの大半は例外のハンドリングになるわけだから、それでプログラミングが楽になることはないだろう。しかしながら、呼び出し先がどんな例外をスローするかについて呼び出し元が無関心でいるよりも、戻り値として返されるエラーを常に意識しなければならないという状況が、あるいは少しでもシステム障害の可能性を予見しやすい状況になればいいと思う。
3.3.9. この後に学ぶこと
Golang は今後いろいろと使う機会も増えてくるかもしれないので、言語の基本的な機能を押さえておく必要があるだろう。
また Web フレームワークなどに慣れておくのが良さそうだが、デファクトになっているようなものはまだないようだ。どれをやっても良いと思うが、このあたりを学んでおこうと思う。。
3.4. Rust
Rust の 1.0 版がリリースされたのが 2015 年だから、これは正真正銘モダンな言語と言ってもいいだろう。だが Rust で書かれたコードを見ると、セミコロンがほぼ不要な Golang などと比べ、ステートメント・ターミネータの ; 、 ジェネリクスの < や > 、 ライフライムパラメータの ' などが込み入っているように見えお世辞にもすっきりしているとは言えない。一方で、関数型言語が備える数多くの機能や、Option<T> 型による NULL 安全機構、 Result<T, E> 型による例外ハンドリング、そして中でも他の言語であまり例のない「所有権の移動」や「借用」という概念がガベージコレクタに頼らないメモリ安全を可能にしており、これがおそらく最も Rust らしい点であろう。
Rust を見ていると、 The Strokes を思い出す。一見古めかしいのに、初めて聴くようなミックスバランス。そんな楽曲で構成されたデビューアルバムは斬新だったし、シンプルこの上ないのに聴けば聴くほどよく練り込まれていると感じるツインギターアレンジは本当に俺を驚かせたものだ。
3.4.1. インストール
公式サイトのドキュメントに従ってインストールする。
公式サイトのインストールガイド
Install Rust
$curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
...
Rust is installed now. Great!
...
Rust はローカル環境の ~/.cargo へインストールされ、 ~/.cargo/env ($PATHを設定してるだけ)が用意されているのでそれを実行する。
$ cat ~/.cargo/env
export PATH="$HOME/.cargo/bin:$PATH"
$ source ~/.cargo/env
そして ~/.bash_profile には上記 env の内容と同じ以下の 1 行が追記されている。
$ cat ~/.bash_profile
...
export PATH="$HOME/.cargo/bin:$PATH"
3.4.2. 検証
$ mkdir -p ~/learn_rust/hello_world
$ cd ~/learn_rust/hello_world/
$ echo '
> fn main() {
> println!("hello, world");
> }
> ' > hello_world.rs
$ rustc hello_world.rs
$ ./hello_world
hello, world
Rust には cargo というパッケージ・マネージャが標準で搭載されているので、これを使って新規プロジェクトを作りビルドしてみる。
$ cd ~/learn_rust/
$ cargo new hello_cargo
Created binary (application) `hello_cargo` package
$ cd hello_cargo/
$ cargo run
Compiling hello_cargo v0.1.0 (/home/yourname/learn_rust/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/hello_cargo`
Hello, world!
なんと hello, world のソースコードが勝手に準備されている。
3.4.3. サンプルプログラムを作る
この Rust は新しい概念が導入されているということもあり、ネットで関連情報を読んでいるだけだとなかなか要領がつかめないので、実際にプログラムを書きながら慣れていく方が早そうだ。
そこで、今回は、画像ファイルを読み込み、それを色付きのテキスト (1文字を 1 ピクセルに見立てたHTML) へ変換するプログラムを作ることにする。
3.4.4. プログラムの概要
具体的には、例えば以下のような画像を、

(提供元: Pixabay )
以下のような HTML へ変換するものだ。

(Web ブラウザに表示されたコンテンツをラスタライズしたもの)
ちなみに、この HTML はフォントのみで書かれているため、ブラウザで拡大表示しても以下のようにディティールが崩れることはない。

コマンドラインの仕様は以下のとおりとする。
| 項目 | 内容 |
|---|---|
| 使用法 | コマンドラインで以下のように使う。 glyph <image> <templ> <txmsg> <dest-width> [<charset>] |
| glyph | コマンド名 |
| <image> | 元になる画像ファイルのパス |
| <templ> | HTML のテンプレートファイルのパス |
| <txmsg> | ピクセルに見立てる文章が書かれたファイルのパス |
| <dest-width> | 出力する HTML の横幅(文字数)を定める正の整数。なお、高さ(文字数)については、この横幅と画像の縦横比から自動算出する。 |
| [<charset>] | 文字セット "ascii" (ASCII 文字集合。いわゆる半角英数字) または "jis208" (JIS X 0208 文字集合。いわゆる全角日本語文字) を指定(省略可能)。 "ascii" が指定された場合、<txmsg> で示されるファイルに ASCII 文字集合以外の文字があれば削除する。ただし、全角英数字など ASCII に変換可能な文字については削除せずに対応する文字に置き換える。 "jis208" が指定された場合も同様。 なお、 ascii が指定された場合はフォントの縦横比が 2:1 であるとみなし高さ方向の文字数を半分にするが、"jis208" の場合は 1:1 とみなし高さ方向の文字数を変更しない。 |
そしてコマンドライン引数に指定するテンプレートファイル <templ> の具体的なイメージは以下のとおりだ。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset ="utf-8">
<title>[Title]</title>
<link rel ="stylesheet"
href="https://fonts.googleapis.com/css2?family=IBM+Plex+Mono:wght@700&display=swap" >
<!--
href="https://fonts.googleapis.com/css2?family=Ubuntu+Mono:wght@400;700&display=swap" >
href="https://fonts.googleapis.com/css2?family=VT323&display=swap" >
-->
<style>
body {
font-family:'IBM Plex Mono', monospace;
line-height:1.1em;
/*
font-family:'Ubuntu Mono', monospace;
line-height:0.9em;
font-family:'VT323', monospace;
line-height:0.7em;
*/
letter-spacing:-0.05em;
background:#000;
white-space:nowrap
}
i {
font-style: normal
}
</style>
</head>
<body>
@@body@@
</body>
</html>
上記テンプレートファイルの概要は以下のとおり。
- <head> 要素でフォントを指定している。
- フォントは、表示結果がブラウザ環境に左右されないよう Google fonts を利用している。
- <link> 要素と <style> 要素で 3 種類のフォントを指定している(うち 2 つはコメントアウト) 。
- 出力するコンテンツが等幅フォントでの表示を想定しているため、3 種類のフォントはすべて Monospace カテゴリから選択している。
- <style> 要素内で、<body> 要素に対して
- line-height で行間の調整をしている(縦方向)。
- letter-spacing で文字間の調整をしている(横方向)。
- background を黒くしている(一番見栄えが良いと思われる)。
- white-space: nowrap で文字が意図しない箇所で改行されるのを防いでいる。
- また、本プログラムは出力する 1 文字ごとのフォントカラーを <i> 要素で包んで Style 指定しているため、<style> 要素内で <i> 要素に対して font-style を normal に指定している(<i> 要素は一般的にイタリック体で表示されるため、これを防ぐ目的)。
- <body> 内に プレースホルダ
@@body@@を書いている。プログラムはこのプレースホルダを <i> 要素の羅列に置き換える。
また、コマンドライン引数に指定するテキストメッセージファイル <txmsg> は一般的なテキストファイルで良いので、今回は Wikipedia から以下の文章を引用した。
The Strokes are an American rock band from Manhattan, New York.
Formed in 1998, the band is composed of singer Julian Casablancas,
guitarists Nick Valensi and Albert Hammond Jr., bassist Nikolai
Fraiture, and drummer Fabrizio Moretti. They are one of the most
prominent bands of the garage rock and post-punk revivals, aiding
in the resurgence of indie rock in New York City.
...
(引用元: Wikipedia )
このファイルは一般的なテキストファイルで良いが、以下のことに注意する必要がある。
- フォントの横幅を揃えるために、英字のみ(または日本語のみ)にするなど文字セットを統一した方が良い。
- UTF-8 で記載する。Rust は UTF-8 以外の文字コードとの相性があまり良くないようだ。
3.4.5. プロジェクトの作成
まずは cargo new コマンドで新規プロジェクトを作成する。
$ cd ~/learn_rust
$ cargo new glyph
$ cd glyph
今回は外部のライブラリを使うため、Cargo.toml ファイルの末尾に以下を追記する。
...
[dependencies]
image = "0.23.5"
num = "0.3.0"
regex = "1.3.9"
Rust のライブラリはクレートという単位で管理される。Crate というのは「梱包用の箱」のことで、Cargo (貨物) を構成するパーツというわけだ。
今回は上記のとおり 3 つのクレートを指定するのだが、Cargo.toml に追記した後にプロジェクトをビルドすると、これらのライブラリが自動的インストールされる。
そして今回利用するクレートの概要は以下のとおり。
| クレート | 概要 | 利用する機能 | ライブラリ提供サイト |
|---|---|---|---|
| image 0.23.5 | 画像ライブラリ | RgbImage など | crates.io/image |
| num 0.3.0 | 数値ライブラリ | lcm(最小公倍数関数) | crates.io/num |
| regex 1.3.9 | 正規表現ライブラリ | Regex | crates.io/regex |
3.4.6. モジュール分割
今回のプログラムはソースコードを分割しているので、そのディレクトリ構成を以下に示す。
glyph
├── Cargo.toml ........ プロジェクトファイル
└── src ............... ソース・ディレクトリ
├── areav.rs ...... 画像縮小処理
├── cmdln.rs ...... コマンドライン処理
├── glyph.rs ...... HTML の body 生成処理
├── main.rs ....... メイン
├── templ.rs ...... テンプレートファイル処理
├── txmsg.rs ...... テキストメッセージファイル処理
└── util .......... ユーティリティ・ディレクトリ
├── mod.rs .... ユーティリティ関数群
└── tests.rs .. ユーティリティ関数群のテスト
モジュールの構成方法はいくつかあるが、今回は 2 つの方法を用いている。
-
<module_name>.rs
cmdln.rs などのように、ソースコードファイル名をモジュール名にする方法。 -
<module_name>/mod.rs
util/mod.rs などのように、モジュール名のディレクトリを作り、その配下に mod.rs というソースコードファイルを作る方法。
3.4.7. メイン処理 (src/main.rs)
今回のプログラムの起点となる main.rs は以下のとおりだ。
mod util;
mod cmdln;
mod templ;
mod txmsg;
mod glyph;
mod areav;
use cmdln::Args;
use templ::Templ;
use txmsg::Txmsg;
use glyph::Glyph;
// HTML を標準出力へ
fn print_html() -> Result<String, String> {
let args = Args::new()?; // コマンドライン引数を取得
let templ = Templ::new(&args.templ)?; // HTMLテンプレートを読み込み初期化
let txmsg = Txmsg::new(&args.txmsg, args.charset)?; // テキストメッセージを読み込み初期化
let glyph = Glyph::new(&args.image)?; // 元になる画像を読み込み初期化
templ.print_head(); // HTMLのヘッダを出力
glyph.print_body(&txmsg, args.width, args.charset); // HTMLの本体を出力
templ.print_tail(); // HTMLのテールを出力
Ok("Completed!".to_string())
}
// メイン関数
fn main() {
match print_html() { // HTMLの出力
Ok (msg) => eprintln!("{}", msg), // 処理完了メッセージ
Err(err) => eprintln!("{}", err), // エラーメッセージ
}
}
上記プログラムの概要は以下のとおりだ。
- 冒頭の
mod ~で、本プロジェクトで使うモジュールを宣言している。ここに記載したモジュールがビルド時のコンパイル対象となる。 -
print_html()関数内で、コマンドライン引数を処理し、各オブジェクトを初期化した後で HTML を出力している。 -
main()関数内ではprint_html()を呼び出し、正常終了時とエラー発生時のハンドリングを行っている。
3.4.8. Result<T, E>型とパターンマッチング
3.4.8.1. 例外ハンドリングの概要
ここで注目すべきは、関数 print_html() の戻り値の型である Result<T, E> というジェネリックな型引数を持つ列挙型だ。
fn print_html() -> Result<String, String> {
Rust と同じように try catch 機構のない Golang では関数が複数の戻り値を返せるようにすることで例外をハンドリングするが、Rust はそれとは異なるアプローチを取っており、Rust の例外処理ではこの Result<T, E> と Option<T> という型が良く使われているようだ。
Result<T, E> の定義は以下のようになっている。
pub enum Result<T, E> {
Ok(T),
Err(E),
}
Rust の enum は、整数値に名前を付けるだけの C 言語の単純なそれとはちょっと違っており、上記は、以下のいずれかを取り得るという意味になる。
-
Ok(T) :
型 TをOkで包んだ型
ここで T は、成功時に呼び出し元に返したい本来の型のこと。それを Ok に包むことで、呼び出し元へ正常終了したことを伝えることができる。 -
Err(E) :
型 EをErrで包んだ型
ここで E はどんな型でも構わないのだが、他の言語で言うところの Exception や Error のような型と考えれば良いだろう。それを Err で包むことで、呼び出し元に例外が発生したことを伝えることができる。
なお、print_html() 関数の戻り値は Result<String, String> であり、以下のようなことを行っている。
- 正常終了の場合は、正常終了メッセージ(String)を Ok に包んで返す。
- 例外が発生した場合は、例外メッセージ (String)を Err に包んで返す。
3.4.8.2. 例外を受け取る側の処理
そして main() 関数内ではこの戻り値を、Rust のパターンマッチング機構を使ってハンドリングしている。
match print_html() {
Ok (msg) => eprintln!("{}", msg),
Err(err) => eprintln!("{}", err),
}
具体的には print_html() の評価値 Result<String, String>型 を match 式 に渡し、
-
Ok (msg) =>とすることで、String 型変数msg(識別子名は何でも良い)を使って print_html() が正常終了した際のメッセージ (String) を Ok() から取り出し、eprintln!() マクロで標準エラー出力へ書き出している。 -
Err(err) =>とすることで、String 型変数err(識別子名は何でも良い)を使って print_html() で例外が発生した際のメッセージを Err() から取り出し、 eprintln!() マクロで標準エラー出力へ書き出している。
3.4.8.3. 例外を送出する側の処理
print_html() の中では、Args::new()、Templ::new()、Txmsg::new()、Glyph::new() の 4つのメソッドをコールしており、これらの戻り値はいずれも Result<T, String> である。結果が Ok の時の型 T についてはメソッドごとに異なるが、Err の時の型はすべて String だ。 例えば、以下に示すとおり Args::new() の場合、T は Args 型である。
impl Args {
pub fn new() -> Result<Args, String> {
3.4.8.4. ? 演算子 (question mark operator) を使う
そして print_html() 内では、末尾に 演算子 ? を付けてこれらのメソッド呼び出している。
let args = Args::new()?;
let templ = Templ::new(&args.templ)?;
let txmsg = Txmsg::new(&args.txmsg, args.charset)?;
let glyph = Glyph::new(&args.image)?;
演算子 ? の意味は以下のとおりだ。
型 Result<T, E> として評価される式の右側に 演算子 ? を付けると、
- 左辺の式の評価値が Ok(T) の場合
Ok(T) から値 valueを取り出し全体の評価値とする(型はT)。 - 左辺の式の評価値が Err(E) の場合
関数を直ちに終了しErr(E)を返す(型はResult<T, E>)。
これは return Err(E); と同等の動作である。
つまり、 let args = Args::new()?; という 1 行は、以下の 4 行のシンタックスシュガーであり、
let args = match Args::new() {
Ok (v) => v,
Err(e) => return Err(e),
};
更に言うと、? というたった 1 文字の演算子で、以下と同じことをやっているのだ。
{
Ok (v) => v,
Err(e) => return Err(e),
}
Rust にはこの演算子 ? 以外にも、unwrap() や map_err() など、Result<T, E> の便利なメソッドがいろいろ用意されているが、これらについては後で詳しく説明する。
さて、print_html() では、Templ, Txmsg, Glyph という構造体を Args と同じやり方で初期化し、これらのオブジェクトを使って HTML を出力した後で、最後に成功時の戻り値を生成している。
Ok("Completed!".to_string())
なお、Rust では、関数内の最後の式の評価値は、その関数の戻り値となる。よって上記 (1) は下記 (2) と同じ意味である。
return Ok("Completed!".to_string());
また、(1) の書き方をする場合は、ステートメント・ターミネータ ; を付けてはならない(これを付けると式ではなく文となり、1行全体の値を評価できなくなるため)。
3.4.9. コマンドライン引数の処理 (src/cmdln.rs)
コマンドライン引数を処理するモジュール cmdln.rs のコードを以下に示す。
use super::util::msg;
use super::txmsg::Charset;
// コマンドライン引数構造体
pub struct Args {
pub image: String, // 画像ファイルのパス
pub templ: String, // HTML テンプレートファイルのパス
pub txmsg: String, // メッセージファイルのパス
pub width: u32, // 出力画像の横幅(文字数)
pub charset: Charset, // 文字セット
}
// エラーメッセージ群
const USAGE : &str = "Usage: glyph <image> <templ> <txmsg> <dest-width> [<charset>]";
const ERR_WIDTH : &str = "<dest-width> must be a positive integer.";
const ERR_CHARSET: &str = "<charset> must be \"ascii\" or \"jis208\".";
const ERR_ZERO : &str = "ZERO!";
// 正の整数をパースする
fn parse_gt0(s: &str) -> Result<u32, String> {
s.parse::<u32>() // 文字列 -> 32-bit unsigned integer
.map_err(|e| msg(e)) // エラーなら、メッセージを Err で包んで関数を抜ける
.and_then(|n| { // 成功なら、
if n > 0 { Ok (n ) } // 0 より大きければ Ok で包む
else { Err(msg(ERR_ZERO)) } // そうでなければ Err で包む
})
}
// 文字列から Charset 型に変換
fn parse_charset(os: Option<String>) -> Result<Charset, String> {
match os {
None => Ok (Charset::DoNotCare),
Some(s) => match s.as_str() {
"jis208" => Ok (Charset::Jis208),
"ascii" => Ok (Charset::Ascii),
_ => Err(msg(ERR_CHARSET)),
},
}
}
// コマンドライン引数構造体の実装
impl Args {
// コマンドライン引数構造体を生成する
pub fn new() -> Result<Args, String> {
let mut args = std::env::args(); // コマンドライン引数を取得する
let image = args.nth(1).ok_or(msg(USAGE))?; // 第1引数(画像ファイルのパス)を得る。無ければ使用法表示
let templ = args.next().ok_or(msg(USAGE))?; // 第2引数(テンプレートのパス)を得る。(上に同じ)
let txmsg = args.next().ok_or(msg(USAGE))?; // 第3引数(テキストMSG のパス)を得る。(上に同じ)
let width = args.next().ok_or(msg(USAGE))?; // 第4引数(出力時の幅(文字数))を得る。(上に同じ)
let width = parse_gt0(&width).map_err(|_| msg(ERR_WIDTH))?; // 第4引数を正の整数に変換
let charset = args.next(); // 第5引数(キャラクタセット)を得る。(Optionのまま取り出し)
let charset = parse_charset(charset).map_err(|_| msg(ERR_CHARSET))?; // 第5引数を enum に変換
Ok( Args { image, templ, txmsg, width, charset, } ) // 構造体の生成
}
}
3.4.10. 構造体と関連関数の定義
上記コードでは、5 つのコマンドライン引数を格納するために以下のように構造体を定義している。
pub struct Args {
pub image: String, // 画像ファイルのパス
pub templ: String, // HTML テンプレートファイルのパス
pub txmsg: String, // メッセージファイルのパス
pub width: u32, // 出力画像の横幅(文字数)
pub charset: Charset, // 文字セット
}
pub は他の言語で言うところの public と同じなので、pub struct Args {...} とすることにより、モジュールの外側からこの構造体を利用することができるようになる。また、メンバについても pub image: String, などとすることで外部から参照可能となる。
また、構造体のメソッド等については、以下のように構造体の外側で実装する。
impl Args {
pub fn new() -> Result<Args, String> {
...
}
}
Args 構造体は、構造体を新規生成するメソッド Args::new() のみをもつ。
なお、Rust ではこの self を引数に取らないメソッドを 関連関数 (associated function) と呼ぶ(これは他の言語で言うところの 静的メソッド にあたるもの)。
3.4.11. Option<T>型とパターンマッチング
今回のプログラムは、コマンドラインの第 5 引数を「文字セット(Charset)」としており、"ascii" または "jis208" のいずれかを指定できる。また、このパラメータは省略することもできる。
そしてこの第 5 引数は、 cmdln.rs の Args::new() の中で args.next() を使って取得、変数 charset へ束縛してから 関数 parse_charset() に渡しているのだが、この変数 charset の型が Option<String> である(下記)。
let charset = args.next();
let charset = parse_charset(charset).map_err(|_| msg(ERR_CHARSET))?;
Option<T> は、元々、関数型言語 Scala で同等のものが採用されていたようだが、Rust では以下のように定義されている。
pub enum Option<T> {
None,
Some(T),
}
上記は、以下のいずれかを取り得るという意味になる。
- None : 値が無い事を示す。
-
Some(T) :
型 Tの値を持っており、それを示すためにSomeで包んでいる。
例えば、Java などでは参照型の変数に null を代入することで「値を持っていないこと」を表現することがあるが、このような設計は NullPointerException の温床になりかねない。
Rust ではそもそも Null 値が許容されておらず、初期化されていない変数を使おうとするとコンパイルエラーとなるのだが、この Option<T> は「値が無いこと」を表現できるだけでなく、この型の利用者が常に None の可能性を意識しなければならなくなるため、このアプローチはプログラム故障の早期検出に繋がるであろう。
また、Java などでは、プリミティブ型の int は「値が無いこと」を表現できないが、Rust ではこの Option<T> を使うことで、例えば i32 (32ビット符号付整数) に値が無いことを表現可能である。
先に述べたとおり、このプログラムのユーザは、第 5 引数の値として、
- "ascii"
- "jis208"
- 省略
の 3 つのうちいずれか 1 つを選ぶことができるが、上記 args.next() が返す値にそれが反映し、変数 charset に Option<String> 型の値として束縛されることになる。
そしてこの変数 charset の取り得る状態は、
- Some("ascii")
- Some("jis208")
- Some(その他の文字列)
- None
のいずれかである。
そして変数 charset の値は関数 parse_charset() に渡され、関数内で以下のように処理している。
// 文字列から Charset 型に変換
fn parse_charset(os: Option<String>) -> Result<Charset, String> {
match os {
None => Ok (Charset::DoNotCare),
Some(s) => match s.as_str() {
"jis208" => Ok (Charset::Jis208),
"ascii" => Ok (Charset::Ascii),
_ => Err(msg(ERR_CHARSET)),
},
}
}
この関数内では 2 重の match 式が使われ、外側の match 式では、引数 os の値が、
- None の場合:
引数を省略したとみなし、Charset::DoNotCare を Ok に包んで返している - Some(s)の場合:
値 s を内側の match 式にかけ、- s が "ascii" または "jis208" であれば、
対応する列挙型 Charset::Ascii または Charset::Jis208 を Ok に包んで返し、 - それ以外の場合は、
メッセージを Err に包んで返している。
- s が "ascii" または "jis208" であれば、
3.4.11.1. ok_or() を使う
Rust では上述のようなやり方で Option<T> 型のパターンマッチングを行うことができるが、このような書き方ばかりをしていたらタイプ量が増え記述性が損なわれてしまう。そこで Rust では記述量を減らすことができる便利なメソッドが用意されており、ok_or() はその 1 つだ。
例えば、Args::new() の中では、2 番目のコマンドライン引数を以下のように処理している。
let templ = args.next().ok_or(msg(USAGE))?;
先の第 5 引数と同様 args.next() で引数を取得しており、この評価値は Option<String> 型である。ただし、第 5 引数は省略可能なパラメータだったため None の場合の処理を記述したのだが、第 2 引数は省略不可でありこれが省略された場合はエラーとする必要がある。
これを上手く捌くため ok_or() に処理を渡しているのだが、このメソッドは、以下に示すように Option<T> を Result<T, E> に変換するものである。
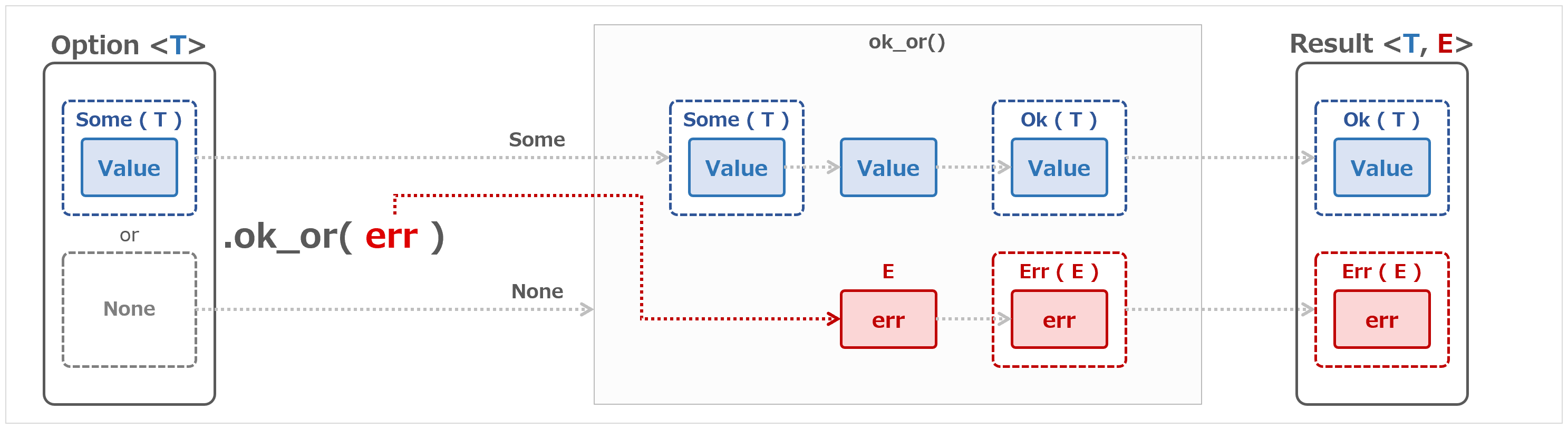
ok_or() は、
-
Option<T>の値が Some(T) だった場合(つまり値がある場合)は、T を Some から取り出し Ok に包んで返す。 - そして None だった場合は、ok_or() に渡された引数(型は何でも良いが上図では E としている)を Err に包んで返す。
上記コードでは 「使用法が書かれた文字列」を ok_or() のパラメタ err として渡している。これにより、args.next() の評価値が Some(T) であっても None であっても、args.next().ok_or() の評価値は Result<T, E> 型となる。
更に末尾に演算子? を付けることにより、
- Okだった場合(つまり Some だった場合)は
Ok から T を取り出してargs.next().ok_or()?全体の評価値は型 Tとなり、これを 変数 templ に束縛、 - Err だった場合(つまり None だった場合)は
直ちに関数を終了しエラメッセージを Err に包んで返すこととなる。
ちなみに、この 1 行をパターンマッチングで実装すると以下のように 8 行の処理となる。
//以下の 1 行と同等の処理を match 式で実装
//let templ = args.next().ok_or(msg(USAGE))?;
// ok_or() と同等の処理
let templ = match args.next() { // args.next() は Option<T> 型
Some(v) => Ok(v),
None => Err(msg(USAGE)),
};
// 演算子 ? と同等の処理
let templ = match templ { // match の右辺の templ は Result<T, E> 型
Ok (v) => v,
Err(e) => return Err(e),
};
これまで説明してこなかったが、Rust では、上記コードのように同じ名前の変数を let で宣言し直すことにより、何度も使いまわすことができる。
まあ、最も Some だった場合に一度 T を Ok に入れてから改めて取り出し直す必要はないので、以下のようにもっとシンプルに書けるわけだが、
let templ = match args.next() {
Some(v) => v,
None => return Err(msg(USAGE)),
};
いずれにせよ、4 行のコードを 1 行にまとめられるメリットは非常に大きいと言えよう。
3.4.11.2. map_err() を使う
Result<T, E> にも記述量を減らすことができる便利なメソッドがあり、モジュール cmdln.rs の関数 parse_gt0() の中で map_err() と and_then() というメソッドを使っている(下記)。
// 正の整数をパースする
fn parse_gt0(s: &str) -> Result<u32, String> {
s.parse::<u32>()
.map_err(|e| msg(e))
.and_then(|n| {
if n > 0 { Ok (n ) }
else { Err(msg(ERR_ZERO)) }
})
}
s.parse::<u32>() は、文字列を u32 型へ変換するメソッドであるが、このメソッドの戻り値は Result<u32, ParseIntError> である。ところが、これを使っている関数の戻り値は Resultu32, String> であるためちょっと都合が悪い。
そこで上記コードでは、parse::<u32> の戻り値に対して、map_err() を適用することにより、ParseIntError が発生した場合にこれを String へ置き換えている。
map_err() はクロージャを引数に取るのだが、上記コードでは |e| msg(e) の部分がこれにあたる。このクロージャの書き方は Ruby のブロックと非常に似ており、ここで ParseIntError 型の引数 e を、util モジュールで定義した関数 msg に渡し String 型に変換している。
map_err() は以下のように振舞う。
map_err() は、この図のとおり、
- Ok(T) の場合は Ok(T) をそのまま返し、
- Err(E) の場合は、Err から E を取り出しクロージャに渡してくれるので、クロージャがこれを F に置き換えて返すと、map_err() がこの F を Err に包んで返してくれる。
s.parse::<u32>().map_err(|e| msg(e)) と同等の処理を match 式で書いたら以下のようになるだろう。
match s.parse::<u32>() {
Ok(v) => Ok(v),
Err(e) => Err(msg(e)),
}
なお、Result<T, E> 型には、map_err() と対になる map() というメソッドがあり、こちらは map_err() とは逆に、Err(E) の場合はそのまま返し、Ok(T) の場合はクロージャにより書き換えられた U (元は T) を Err に包んで返してくれる。
3.4.11.3. and_then() を使う
parse_gt0() の中では、parse::<u32>() の結果に map_err() を適用した後、更に and_then() を適用している。
u32 は符号なし32ビット整数なので、parse::<u32>() というメソッドは負数("-4" など) をエラーとするが "0" は正常にパースする。だが、コマンドラインの第 4 引数である「出力側の横幅」は 1 以上の整数でなければならない。
and_then() を使うとこのような場合に Ok(T) の結果に被せて追加の検査を行うことができる。
そしてこの and_then() は先の map() と非常に似た挙動をとるが、以下のような違いがある。
- map()のクロージャが、T を U に書き換えて 皮がむけたまま U を返すのに対して、
- and_then() のクロージャは T を U に書き換えた後、U を Ok の皮に包んで返す必要がある。
つまり、and_then() のクロージャは Result<T, E> を返す必要があるのだが、これは Ok(U) だけでなく Err(E) を返すこともできるということを示している。
and_then() は以下のように振舞う。
and_then() は、
- Ok の場合、
Ok(T) から取り出した T がクロージャに渡されるので、クロージャはこの T を検査して Ok(U) または Err(F) を返すことができる。 - Err の場合、
クロージャは呼び出されず、そのまま Err(E) が返される。
今回のコードでは以下のように、
.and_then(|n| {
if n > 0 { Ok (n ) }
else { Err(msg(ERR_ZERO)) }
})
Ok(T) の T(文字列がパースされた u32 型の値)を n という変数を介してクロージャが受け取り、クロージャは n が正の場合のみ Ok に包んで返し、それ以外(つまり 0 )の場合は、メッセージを Err に包んで返している。
3.4.12. テンプレートファイルの処理 (src/templ.rs)
テンプレートファイルを読み込み、プレースホルダ @@body@@ の前後をヘッドとテールに切り分けるコードは以下のとおりだ。
use regex::Regex;
use std::fs;
use super::util::msg;
use super::util::join;
// HTML テンプレート構造体
pub struct Templ {
head: String, // ヘッド要素 (プレースホルダ "@@body@@" より前の部分)
tail: String, // テール要素 (プレースホルダ "@@body@@" より後の部分)
}
// エラーメッセージ群
const ERR_CAP_0: &str = "'@@body@@' not found in template file.";
const ERR_CAP_1: &str = "head element not found before '@@body@@' in template file.";
const ERR_CAP_2: &str = "tail element not found after '@@body@@' in template file.";
// HTML テンプレート構造体の実装
impl Templ {
// HTML テンプレート構造体を生成する。
// param テンプレートファイルのパス
pub fn new(path: &str) -> Result<Templ, String> {
let text = &fs::read_to_string(path).map_err(|e| join(path, e))?; // ファイルからテキストを取り出す
const RE: &str = r"(?s)(.*)(?-s)@@body@@(?s)(.*)(?-s)"; // プレースホルダの前後を
let regex = Regex::new(RE).map_err(|e| msg(e) )?; // 取り出すための正規表現を生成
let caps = regex.captures(text).ok_or( msg(ERR_CAP_0) )?; // テキストをキャプチャ
let head = caps.get(1).ok_or( msg(ERR_CAP_1) )?.as_str().to_string(); // ヘッド要素を取り出す
let tail = caps.get(2).ok_or( msg(ERR_CAP_2) )?.as_str().to_string(); // テール要素を取り出す
if head.trim().len() == 0 { return Err( msg(ERR_CAP_1) ) } // ヘッド要素が空ならエラー
if tail.trim().len() == 0 { return Err( msg(ERR_CAP_2) ) } // テール要素が空ならエラー
Ok(Templ{ head, tail })
}
// ヘッド要素を標準出力へ
pub fn print_head(&self) {
println!("{}", self.head);
}
// テール要素を標準出力へ
pub fn print_tail(&self) {
println!("{}", self.tail);
}
}
3.4.13. self を引数に取るメソッド
このコードでは、関連関数 Templ::new() の他に、self を引数に取るいわゆる通常のメソッドを 2 つ定義している。
この print_head() と print_tail() はどちらも、構造体のメンバ (head と tail) の内容を標準出力へ書き出すものだが、構造体への参照 (&self) を引数に取ること以外に特別なことは何もしていない。
3.4.14. 正規表現
Templ::new() の内部で正規表現クレート Regex を用いてプレースホルダ前後の文字列を取得している。
Regex::new() で正規表現を初期化し、captures() メソッドでテキストをキャプチャしてから get() メソッドでマッチした文字列を取得しているだけなので、特別なことはしていない。
1 つだけ言及するとすれば、正規表現の中で指定している s フラグだろうか。
通常、正規表現の . は改行文字以外の任意の1文字を表すが、今回のプログラムでは . を改行文字も含めた任意の1文字としてマッチさせたいので、(?s)(.*)(?-s) のように . を s フラグで囲んでいる(フラグの開始が (?s) でフラグの終了が (?-s))。
3.4.15. ファイル入出力
テキストファイルの入出力についても fs::read_to_string() というお手軽な関数が用意されているので、これにファイルのパスを渡して文字列を取得している。
今回のような用途であれば、ファイルをオープンしたり1行づつ読み込んだりする必要はない。
Rust コンパイラはとてもお堅い印象があるが、標準ライブラリに動的型付き言語のような便利機能が用意されているところも Rust の個性なのかもしれない。
3.4.16. テキストメッセージファイルの処理 (src/txmsg.rs)
本プログラムはピクセルに見立てた文字に色を付けて表示するものだが、その文字情報を格納するテキストメッセージファイルを処理するモジュールのコードは以下のとおりだ。
use std::fs;
use std::slice::Iter;
use super::util::msg;
use super::util::shrink_space;
use super::util::extract_ascii;
use super::util::extract_jis208;
// テキストメッセージ構造体
pub struct Txmsg {
chars: Vec<char>, // 文字のベクタ
}
# [derive(Clone, Copy)]
pub enum Charset { Ascii, Jis208, DoNotCare, }
// テキストメッセージ構造体の実装
impl Txmsg {
// テキストメッセージ構造体を生成する
// param テキストメッセージのパス
pub fn new(path: &str, charset: Charset) -> Result<Txmsg, String> {
let text = &fs::read_to_string(path).map_err(|e| msg(e) )?; // 変換前のテキスト
let mut text = shrink_space(&text); // 空白を詰めて
match charset {
Charset::Ascii => text = extract_ascii(&text), // ASCII のみを抽出
Charset::Jis208 => text = extract_jis208(&text), // JIS X 0208 のみを抽出
Charset::DoNotCare => {},
};
let chars: Vec<char> = text.chars().collect(); // 文字列を文字のベクタへ変換
Ok(Txmsg { chars })
}
// イテレータを取り出す
pub fn iter(&self) -> Iter<char> {
self.chars.iter()
}
}
3.4.17. enum と derive
他の言語で 代入 と呼ばれる操作を Rust では 束縛 と言う。この呼称は関数型言語からの影響を受けているようで、例えば let n = 3; は「値 3 を変数 n へ束縛する」という意味だ。
そしてこの変数束縛の = 演算子は、どの型に使うかによってその意味(セマンティクス)が変わってくる。
具体的には、Copy トレイト が実装されている型なら「コピー」が行われ、そうでない場合は「所有権の移動」が行われる。トレイトとは Java のインターフェースのようなもので、Rust の様々な型は様々なトレイトを実装している。
u = t; というシンタックスのセマンティクスは以下のとおり。
| 型の種類 | セマンティクス |
|---|---|
| Copy トレイトを実装する型 | コピー。 変数 t が束縛する値を別の領域にコピーし、それを変数 u へ束縛する。 |
| Copy トレイトを実装しない型 | 所有権の移動。 変数 t が束縛する値を変数 u へ束縛する。これ以降 変数 t は使用不可。 |
これを Java で例えるとすると、所有権が移ることを除けば = 演算子のコピーセマンティクスは Java のプリミティブ型の「代入」、移動セマンティクスは Java の参照型の代入と似ている。
Rust ではすべてのプリミティブ型には Copy トレイトが実装されているため、プリミティブ型であれば = 演算子のセマンティクスは「コピー」となる。一方、ユーザが定義した型はデフォルトで Copy トレイトが実装される訳ではないので、そのセマンティクスは「移動」となる。
上記コードでは Charset という列挙型を定義しており、そのままでは移動セマンティクスとなってしまい、これでは都合が悪い。そこで、この列挙型に #[derive(Clone, Copy)] というアトリビュートを付けることにより、Copy トレイトの標準的な挙動をコンパイラに「お任せ」で実装している(derive を使わずに自分で実装することも可能)。
3.4.18. Vec とイテレータ
上記コードでは、Txmsg の初期化時に、読み込んだメッセージファイルから連続する空白類(制御文字を含む)を取り除いたり、単一の文字セットに統一するなどの加工を施した文字列を Vec という Rust の動的配列(ヒープ上に確保される)に変換して、そのイテレータをメソッドを介して取り出せるようにしている。
なお、配列や Vec そのものを渡さずにイテレータを取り出せるようにしているのは、利用者側が next() で簡単に1文字づつ取り出せるようにするためである。
3.4.19. 画像縮小処理 (src/areav.rs)
本プログラムの画像縮小処理のコードは以下のとおりだ。
use image::Rgb;
use image::RgbImage;
use num::integer::lcm;
// 面積平均法 (area average method) による計算のパラメータ構造体
// 中間矩形 -> 変換元と変換先の最小公倍数の幅と高さを持つ矩形
pub struct AreaAvarage<'a> {
img : &'a RgbImage, // 変換元のイメージ
smw : u32, // 中間矩形の 幅 が変換元の 幅 の何倍か
smh : u32, // 中間矩形の高さが変換元の高さの何倍か
dmw : u32, // 中間矩形の 幅 が変換先の 幅 の何倍か
dmh : u32, // 中間矩形の高さが変換先の高さの何倍か
dma : u32, // 中間矩形の面積が変換先の面積の何倍か
pub dw : u32, // 変換先の幅
pub dh : u32, // 変換先の高さ
}
// 面積平均法構造体の実装
impl AreaAvarage<'_> {
// 指定された画像を元に面積平均法構造体を新規生成する
// param img 変換元のイメージ
// param dw 変換先の横幅(ピクセル数)
// param ratio 変換先のピクセルの縦横比(1ピクセルの高さが幅の何倍かを示す整数)
pub fn new<'a>(img: &'a RgbImage, dw: u32, ratio: u32) -> AreaAvarage {
let sw = img.width(); // 変換元の幅(ピクセル数)
let lw = lcm(sw, dw); // 変換元と先の最小公倍幅
let smw = lw / sw; // 最小公倍 幅 が変換元の 幅 の何倍か
let dmw = lw / dw; // 最小公倍 幅 が変換先の 幅 の何倍か
let sh = img.height(); // 変換元の高さ(ピクセル数)
let dh = sh * dw / (sw * ratio); // 変換先の高さ(ピクセル数)
let lh = lcm(sh, dh); // 変換元と先の最小公倍高さ
let smh = lh / sh; // 最小公倍高さが変換元の高さの何倍か
let dmh = lh / dh; // 最小公倍高さが変換先の高さの何倍か
let dma = dmw * dmh; // 変換先の1pxに対する最小公倍矩形のpx数(面積比)
AreaAvarage { img, smw, smh, dmw, dmh, dma, dw, dh, }
}
// 面積平均法 (area average method) で変換先の座標の色を決める(1ピクセル分)
// param dx 変換先のピクセルの X 座標
// param dy 変換先のピクセルの Y 座標
pub fn get_rgb(&self, dx:u32, dy:u32) -> Rgb<u8> {
let mut r: u32 = 0; // 赤成分(集計用)
let mut g: u32 = 0; // 緑成分(集計用)
let mut b: u32 = 0; // 青成分(集計用)
for y in 0..self.dmh { // 変換先の1点から
let sy = (dy * self.dmh + y) / self.smh; // 中間矩形を経由して
for x in 0..self.dmw {
let sx = (dx * self.dmw + x) / self.smw; // 変換元の X Y 座標を辿り、
let px = self.img.get_pixel(sx, sy); // そのピクセルを取り出したら
let Rgb([sr, sg, sb]) = *px; // RGBに分解して
r += sr as u32; // それぞれの
g += sg as u32; // 成分を
b += sb as u32; // 集計する
}
}
Rgb([
(r / self.dma) as u8, // それぞれの
(g / self.dma) as u8, // 成分の
(b / self.dma) as u8, // 平均値を返す
])
}
}
3.4.20. 画像縮小アルゴリズム
今回のプログラムはコマンドライン引数で出力側の横幅(文字数)を指定できるようにしている。画像ファイルを変換してピクセルに見立てた文字として出力するため、変換前の画素数に対して変換後の画素数(つまり文字数)を少なくできた方が都合が良いからだ。
このための画像縮小アルゴリズムとして今回はシンプルな面積平均法 (area average method) を使っている。その概要は以下のとおりだ。

上図はアルゴリズムを分かりやすくするために、以下のような高さ1の画像を縮小する例とした。
- 変換前 (src) の画像サイズ: 6 x 1 pixel
- 変換後 (dst) の画像サイズ: 4 x 1 pixel
- 101 階調のグレースケール (0 ~ 100%)
図中の lcm は最小公倍数 (Least common multiple) の略のことで、つまり変換前の横幅と変換後の横幅の最小公倍数の横幅を持つ画像(中間画像と呼ぶ)のことだ。これを間に置いて考えることで、変換後のピクセルの平均輝度計算を整数演算のみでできるようにしている。
また、上図の赤字の記号はコード内の構造体メンバ名や変数名でも使っており、以下のような意味である。
- sx : 変換前画像の x 座標
- dx : 変換後画像の x 座標
- smw: 中間画像の横幅が変換前画像の横幅の何倍か
- dmw: 中間画像の横幅が変換後画像の横幅の何倍か
変換後の色の求め方は、上図を下から上へ辿り、例えば dx=0 の色を求める場合は、
- dx = 0 のピクセルにあたる中間画像の x 座標は 0, 1, 2 の 3 つなので、この 3 つの色を求めるために src を辿る。
- 中間画像の x 座標 = 0 のピクセルは、sx = 0 と同じなので、その色は 0 (つまり黒)
- 中間画像の x 座標 = 1 のピクセルは、sx = 0 と同じなので、その色は 0 (つまり黒)
- 中間画像の x 座標 = 2 のピクセルは、sx = 1 と同じなので、その色は 100 (つまり白)
- よって dx = 0 のピクセルの色は、(0 + 0 + 100) / 3 なので 33.3 (つまり 33% グレー)
dx >= 1 も同様に考えれば良い。
また、実際の画像では高さが1というのは現実的ではないが、高さ方向も同じ考え方で求めることができる。
3.4.21. ジェネリックなライフタイム引数
ガベージコレクタ機構とは異なるアプローチを持つ Rust では、メモリ上の値の所有権を単一の変数のみに持たせることにより、所有権を持つ変数がスコープから解放される際に値が破棄される仕組みを備えている。また、所有権を持たない変数も参照(ポインタ)を使って、値を「借用」することができる。
ある値の所有者になれるのはただ一つの変数だけであるが、この値を借用する変数はいくらでも増やすことができる。ここで問題となるのは、所有者がスコープから外れ値が破棄された後にもこれを参照する(借用する)変数が残ってしまうことであるが、Rust ではこのようなダングリングポインタ(無効な参照)が発生しないようコンパイル時に検査が行われる。
上記コードでは、AreaAvarage::new() で RgbImage への参照を引数に取りこれを構造体のメンバ img へそのまま設定しているが、もし他所で生成された RgbImage が破棄されたあとにもこの構造体が残っていたら、構造体メンバから参照する値がダングリングポインタになってしまう。このように RgbImage のライフタイムを曖昧なままにすることを Rust のコンパイラは許さない。
そこでコード内で以下のようにして、RgbImage のライフタイムを明確にしている。
pub struct AreaAvarage<'a> { // (1)
img : &'a RgbImage, // (2)
...
impl<'a> AreaAvarage<'a> { // (3)
pub fn new(img: &'a RgbImage, dw: u32, ratio: u32) -> AreaAvarage { // (4)
- (1) でこの構造体がジェネリックなライフタイム引数を取ることを示している。
- (2) でこの構造体のメンバ img は 'a というライフタイムを持つことを示している。
- (3) でこの構造体の実装でも (2) と同じ 'a というライフタイム変数を使う事を示している。
- (4) で AreaAverage::new() の引数 img が 'a というライフタイムを持つ必要があることを示している。
つまりこれは (4) の引数の img が、少なくとも (2) の構造体メンバの img と同じ期間生存する必要があることを示している。これにより AreaAvarage::new() に渡す引数 img が参照する 値(RgbImage)の生存期間が、AreaAvarage の実体の生存期間よりも短くなるようなコードを書くと、コンパイラがそれを検出しエラーにしてくれるわけだ。
3.4.22. HTML の body 生成処理 (src/glyph.rs)
HTML の body を生成するコードは以下のとおりだ。
use image::open;
use image::Rgb;
use image::RgbImage;
use super::util::enc_html;
use super::util::join;
use super::txmsg::Txmsg;
use super::txmsg::Charset;
use super::areav::AreaAvarage;
// 指定された色と文字で HTML の <i> 要素を作成する
fn i_element(r: u8, g: u8, b: u8, c: char) -> String {
let chr = enc_html(c); // HTML 用の文字へエンコード
let hex = format!("#{:02x}{:02x}{:02x}", r, g, b); // カラーコードの生成
format!("<i style=\"color:{}\">{}</i>", hex, chr) // <i>要素の生成
}
// 文字セットからフォントの縦横比を得る
// フォントの高さが幅の何倍かを示す整数
// (ascii は 2, 日本語は 1 を想定)
fn charset_to_ratio(charset: Charset) -> u32 {
match charset {
Charset::Ascii => 2u32,
Charset::Jis208 => 1u32,
Charset::DoNotCare => 2u32,
}
}
// グリフ構造体
pub struct Glyph {
img: RgbImage, // RGBイメージ
}
// グリフ構造体の実装
impl Glyph {
// 指定されたパスの画像ファイルを元にグリフを新規生成する
// param path 画像ファイルのパス
pub fn new(path: &str) -> Result<Glyph, String> {
Ok(Glyph {
img: open(path).map_err(|e| join(path, e))?.to_rgb(), // 画像ファイルから RgbImage を取り出す
})
}
// HTML BODY を表示する。
// param width 変換先の横幅(変換先の高さは自動算出)
// param charset ascii または jis x 0208
pub fn print_body(&self, txmsg: &Txmsg, width: u32, charset: Charset) {
let ratio = charset_to_ratio(charset);
let areav = AreaAvarage::new(&self.img, width, ratio);
let mut iter = txmsg.iter(); // txmsg のイテレータの初期化。
let mut get_next_char = || { // txmsg から次の文字を取り出すクロージャ。
*iter.next().unwrap_or_else(|| { // イテレータから次の文字を取り出す。もし末尾なら、
iter = txmsg.iter(); // 新たにイテレータを生成し直して
iter.next().unwrap() // 次の文字を取り出す(ローテート)。
})
};
for y in 0..areav.dh { // 変換先の高さ(文字数)分だけ繰り返し
for x in 0..areav.dw { // 変換先の 幅 (文字数)分だけ繰り返し
let Rgb([r, g, b]) = areav.get_rgb(x, y); // 面積平均法で変換先の色を得る
let c = get_next_char(); // 変換先へ出力する文字を得る
let s = i_element(r, g, b, c); // HTML要素に変換
print!("{}", s); // 描画
}
println!("<br>"); // 行の終わり
}
}
}
3.4.23. クロージャ(自由変数を使う)
このコード内では以下のようにクロージャを使っている。
let mut iter = txmsg.iter(); // (1)
let mut get_next_char = || {
*iter.next().unwrap_or_else(|| { // (2)
iter = txmsg.iter();
iter.next().unwrap()
})
};
- (1) で自由変数 iter (イテレータ) を宣言している。
なお、Rust の変数はデフォルトではイミュータブルであるが、ここではミュータブル(書き換え可能)な変数とするために mut を付けて宣言している。 - (2) で (1) の自由変数を使っている。これまで登場したクロージャは自由変数を使わないものだったので、本来の意味でのクロージャではなかったが、ここでは自由変数を使うことにより、まるでオブジェクト指向のオブジェクトのように環境(状態)と振舞いがワンセットになっている。
3.4.24. Option<T> 再び
3.4.24.1. unwrap_or_else() を使う
また上記クロージャ内では、Option<T> 型の便利なメソッド unwrap_or_else() を使っている。
テキストメッセージのイテレータである iter の next() メソッドを使うと次の文字を取り出すことができる(Some に包まれている)が、このメソッドは末尾に達している場合には None を返す。
そこで、ここでは unwrap_or_else() を使う事により、次の文字がある場合は Some(T) の皮を剥いて中身の T を返すようにし、末尾に達し次の文字がない状態 (None) の場合は、イテレータを新たに生成してメッセージの先頭文字を指すようにし(ローテート)、最初の文字を取り出し Some(T) の皮を剥いて中身の T を取り出して返すようにしている。
unwrap_or_else() は以下のように振舞う。
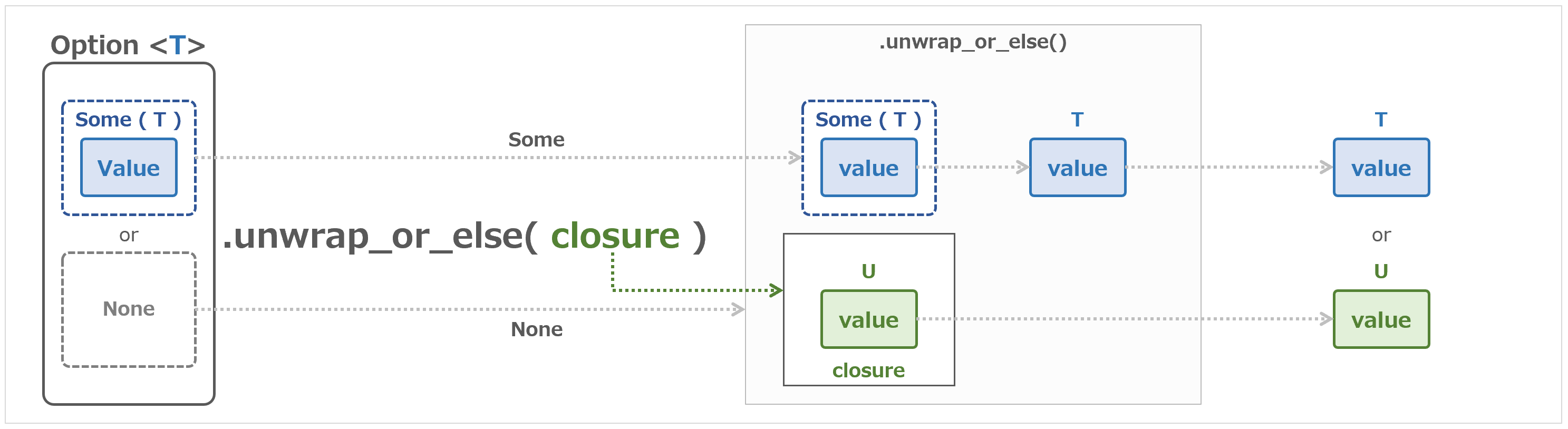
- Some(T) の場合
Some(T) の皮を剥いて T を取り出し返す。 - None の場合
クロージャが返す値 U を返す。
3.4.24.2. unwrap() を使う
上記 iter.next().unwrap_or_else() のクロージャ内でイテレータが末尾に達していた場合は、イテレータを再度生成し直してから iter.next().unwrap() としている。unwrap() は unwrap_or_else() と同様、値がある場合は皮を剥いて取り出した中身を返すが、None だった場合は panic! を起こしてプログラムを強制終了させる。ここでこうしている理由は、イテレータを生成し直して先頭に戻しているにもかかわらず next() で次の文字を取り出すことができないということは明らかにこのプログラムの内部エラーとなるからである。
unwrap() は以下のように振舞う。
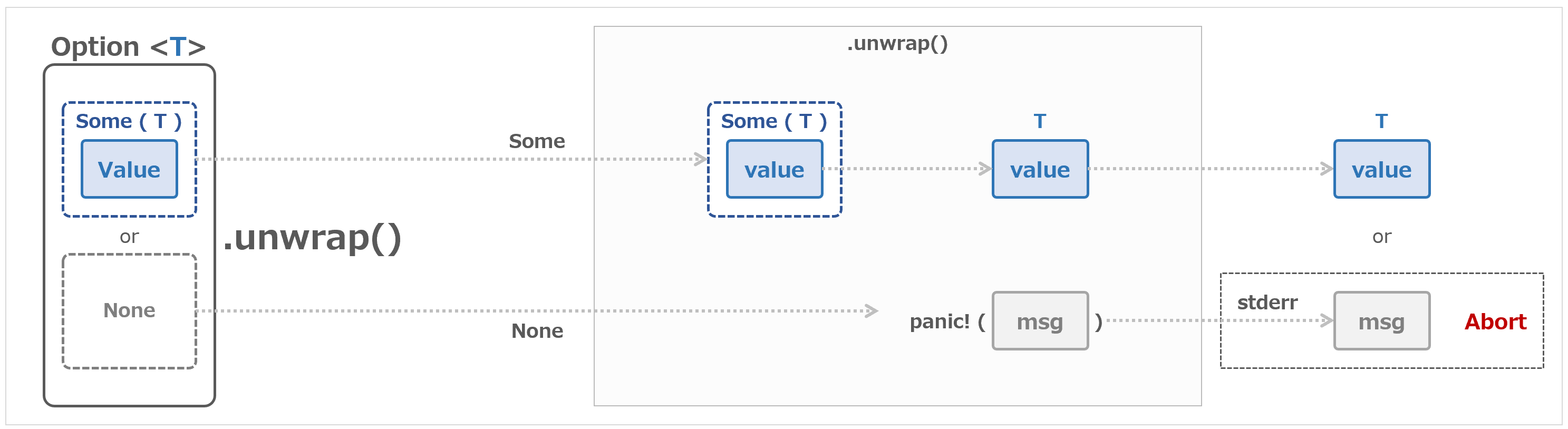
- Some(T) の場合
Some(T) の皮を剥いて T を取り出し返す。 - None の場合
Panic! を起こしてプログラムを強制終了させる。
3.4.25. ユーティリティモジュール (src/util/mod.rs)
ユーティリティモジュールのコードは以下のとおりだ。
use std::fmt::Display;
use std::convert::TryFrom;
use regex::Regex;
# [cfg(test)]
mod tests;
// 2つの Display トレイトを結合して文字列にして返す
pub fn join<T1, T2>(disp1: T1, disp2: T2) -> String
where
T1: Display,
T2: Display,
{
format!("{}: {}", disp1, disp2)
}
// Display トレイトを文字列にして返す
pub fn msg<T>(disp: T) -> String
where
T: Display,
{
format!("{}", disp)
}
// HTMLエンコード関数
pub fn enc_html(c: char) -> String {
match c {
'<' => "<" .to_string(),
'>' => ">" .to_string(),
'&' => "&" .to_string(),
'"' => """.to_string(),
'\''=> "'" .to_string(),
' ' => " ".to_string(),
_ => c .to_string(),
}
}
// 文字を全角文字へ変換する
pub fn char_to_wide(c: char) -> char {
const NARR_MIN : u32 = 0x20u32;
const NARR_MAX : u32 = 0x7eu32;
const NARR_SP : u32 = 0x20u32;
const WIDE_SP : u32 = 0x3000u32;
const WIDE_MIN : u32 = 0xFF00u32;
let c = c as u32;
let c =
if c == NARR_SP { WIDE_SP }
else if c < NARR_MIN { c }
else if c > NARR_MAX { c }
else { c - NARR_MIN + WIDE_MIN };
char::try_from(c).unwrap()
}
// 文字列を全角文字へ変換する
pub fn str_to_wide(s: &str) -> String {
s.chars().map(|c| char_to_wide(c)).collect()
}
// 文字を半角文字へ変換する
pub fn char_to_narrow(c: char) -> char {
const WIDE_MIN : u32 = 0xFF01u32;
const WIDE_MAX : u32 = 0xFF5eu32;
const WIDE_SP : u32 = 0x3000u32;
const NARR_SP : u32 = 0x20u32;
const NARR_MIN : u32 = 0x21u32;
let c = c as u32;
let c =
if c == WIDE_SP { NARR_SP }
else if c < WIDE_MIN { c }
else if c > WIDE_MAX { c }
else { c - WIDE_MIN + NARR_MIN };
char::try_from(c).unwrap()
}
// 文字列を半角文字へ変換する
pub fn str_to_narrow(s: &str) -> String {
s.chars().map(|c| char_to_narrow(c)).collect()
}
// 空白類を詰める
pub fn shrink_space(s: &str) -> String {
const RE: &str = r"(?s)([[:cntrl:]\s]+)(?-s)";
let regex = Regex::new(RE).unwrap();
regex.replace_all(s, "\x20").into_owned()
}
// ASCII 文字集合の文字のみ抽出
// (JIS X 0208 文字のうち、対応するASCII 文字があれば変換)
pub fn extract_ascii(s: &str) -> String {
let s = str_to_narrow(s);
const RE: &str = r"(?s)([^[:ascii:]]+)(?-s)";
let regex = Regex::new(RE).unwrap();
regex.replace_all(&s, "").into_owned()
}
// JIS X 0208 文字集合の文字のみ抽出
// (ASCII 文字のうち、対応するJIS 文字があれば変換)
pub fn extract_jis208(s: &str) -> String {
let s = str_to_wide(s);
const RE: &str =
"(?s)([^\
\u{00A2}-\u{00F7}\u{0391}-\u{03C9}\
\u{0401}-\u{0451}\u{2010}-\u{2312}\
\u{2500}-\u{254B}\u{25A0}-\u{266F}\
\u{3000}-\u{301C}\u{3041}-\u{3093}\
\u{309B}\u{309C}\u{309D}\u{309E}\
\u{30A1}-\u{30F6}\u{30FB}\u{30FC}\
\u{30FD}\u{30FE}\u{4E00}-\u{9FA0}\
\u{FF01}-\u{FF5D}\u{FFE3}\u{818F}\
]+)(?-s)";
let regex = Regex::new(RE).unwrap();
regex.replace_all(&s, "").into_owned()
}
このモジュールは、文字列処理などある程度汎用的な関数を集めている。
3.4.26. Result<T, E> 再び
3.4.26.1. unwrap() を使う
glyph.rs では Option<T> 型の unwrap() を使ったが、Result<T, E> 型にも unwrap() メソッドがあり、上記コード内で使っている。
let regex = Regex::new(RE).unwrap();
正規表現オブジェクトを生成する Regex::new() は Result<Regex, Error> を返すので、正常な場合は皮を剥いて Regex を取り出せるように unwrap() している。そして、この関連関数はパラメータに渡した正規表現文字列(上記では RE) に誤りがあった場合は Error を返すのだが、ここでエラーが発生するということは、つまりプログラムの内部エラーであるので、panic! を起こしてプログラムを強制終了させている。
Result<T, E> の unwrap() の挙動は以下のとおりだ。
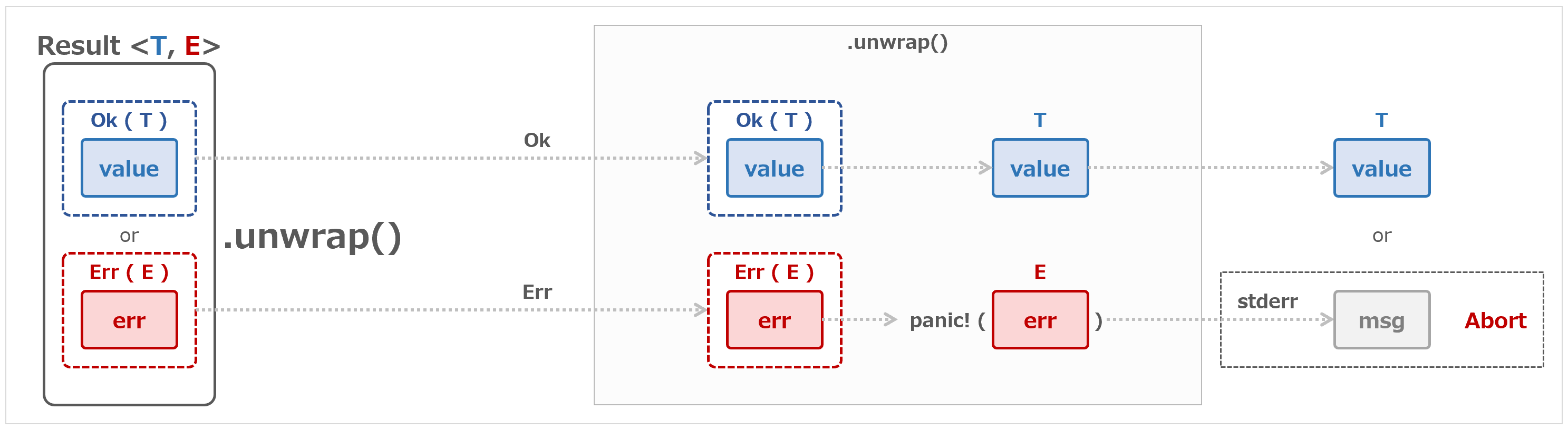
3.4.27. トレイト境界
先ほど、トレイトはインターフェースのようなものだと書いたが、これをジェネリックな型引数に適用することでジェネリックの範囲を制限することができる。Rust ではこれをトレイト境界と呼び、このモジュール内でも使っている。
pub fn join<T1, T2>(disp1: T1, disp2: T2) -> String
where
T1: Display,
T2: Display,
{
format!("{}: {}", disp1, disp2)
}
上記 where の下の 2 行がトレイト境界の記述箇所で、ここでジェネリックな型引数 T1 と T2 を Display トレイトを実装する型のみに制限している。なお、T1 と T2 がどちらも Display トレイトであるにも関わらず別々の型引数にしているのは、T1 と T2 の型が異なる可能性があるからだ。これをひとつにしてしまうと、例えば最初の引数に String (Display トレイトを実装) を渡し、2 番目の引数に Error (Display トレイトを実装)を渡すことができなくなってしまう。
3.4.28. テストを書く (src/util/test.rs)
ユーティリティモジュールはある程度汎用的な関数の集まりであるため今回単体テストを書いたのだが、このモジュール内で、そのことを以下のようにしてコンパイラに伝えている。
# [cfg(test)]
mod tests;
このように書いておくと cargo test とすればテスト用コードをビルド、実行してくれる。
そしてテストコードの内容は以下のとおりだ。
use std::convert::TryFrom;
use super::*;
# [test]
fn enc_html_test() {
let data_list = [
('<' , "<" ), ('>' , ">" ),
('&' , "&" ), ('"' , """),
('\'', "'" ), (' ' , " "),
('A' , "A" ), ('z' , "z" ),
('あ', "あ" ), ('ん', "ん" ),
('ア', "ア" ), ('ン', "ン" ),
('漢', "漢" ), ('字', "字" ),
];
for d in data_list.iter() {
assert_eq!(enc_html(d.0), d.1);
}
}
src/util/tests.rs(続き)
# [test]
fn char_to_wide_test() {
let data_list = [
// ASCII 範囲内
(' ' , ' '), ('~' , '~'),
('\x20', ' '), ('\x7e', '~'),
('\t' , '\t'), ('\n' , '\n'),
('!' , '!'), ('/' , '/'),
('0' , '0'), ('9' , '9'),
(':' , ':'), ('@' , '@'),
('A' , 'A'), ('Z' , 'Z'),
('[' , '['), ('`' , '`'),
('\\' , '\'),
('a' , 'a'), ('z' , 'z'),
// ASCII 範囲外
('\x1f', '\x1f'), ('\x7f', '\x7f'),
('ぁ' , 'ぁ' ), ('ゞ' , 'ゞ' ), // \u3041 - \u309e
('ァ' , 'ァ' ), ('ヿ' , 'ヿ' ), // \u30a1 - \u30ff
('一' , '一' ), ('龠' , '龠' ), // \u4e00 - \u9fa0
];
for d in data_list.iter() {
assert_eq!(char_to_wide(d.0), d.1);
}
}
# [test]
fn str_to_wide_test() {
assert_eq!( str_to_wide(
"012789\nABCXYZ\tabcxyz @" ),
"012789\nABCXYZ\tabcxyz @" );
assert_eq!( str_to_wide(
"漢字あいうわをん\nアイウワオン\tABCXYZabcxyz @" ),
"漢字あいうわをん\nアイウワオン\tABCXYZabcxyz @" );
}
# [test]
fn str_to_narrow_test() {
assert_eq!( str_to_narrow(
"012789\nABCXYZ\tabcxyz @" ),
"012789\nABCXYZ\tabcxyz @" );
assert_eq!( str_to_narrow(
"漢字あいうわをん\nアイウワオン\tABCXYZabcxyz @" ),
"漢字あいうわをん\nアイウワオン\tABCXYZabcxyz @" );
}
# [test]
fn char_to_wide_narrow_test() {
// ascii -> jis -> ascii
for c in (0x20u32..0x7eu32).rev() {
let c = char::try_from(c).unwrap();
assert_eq!(c, char_to_narrow(char_to_wide(c)));
}
// jis -> ascii -> jis
for c in (0xff01u32..0xff5eu32).rev() {
let c = char::try_from(c).unwrap();
assert_eq!(c, char_to_wide(char_to_narrow(c)));
}
}
# [test]
fn str_to_wide_narrow_test() {
// ascii -> jis -> ascii
const NARR1: &str = "012789\nABCXYZ\tabcxyz @";
assert_eq!(NARR1, str_to_narrow(&str_to_wide(NARR1)));
// jis -> ascii -> jis
const WIDE1: &str = "012789\nABCXYZ\tabcxyz @";
assert_eq!(WIDE1, str_to_wide(&str_to_narrow(WIDE1)));
}
# [test]
fn shrink_space_test() {
// narrow space
assert_eq!( shrink_space(
" a\tb\rc\nd e f\t\r\n g " ),
" a b c d e f g " );
// wide space
assert_eq!( shrink_space(
" あい うえお " ),
" あい うえお " );
}
# [test]
fn extract_ascii_test() {
assert_eq!( extract_ascii(
"abcアイウxyzワヲンABCあいうXYZえおか"),
"abcxyzABCXYZ");
}
# [test]
fn extract_jis208_test() {
assert_eq!( extract_jis208(
"abcアイウxyzワヲンABCあいうXYZえおか"),
"abcアイウxyzワヲンABCあいうXYZえおか");
}
3.4.29. この後に学ぶこと
Rust を本格的に使いこなすには、ある程度の量のコードを書きながら、所有権の移動、参照と借用、ジェネリックなライフタイムパラメータなどにもっと慣れる必要があるし、&str と String の使い分けや、効率的なメモリの使い方などについてもまだまだ学ぶ必要があるだろう。
また、型推論という機能は、自分でコードを書く上ではタイプ量を減らせてとても便利に感じる一方、もっと標準ライブラリに慣れないと、人が書いたコードの変数型がよくわからず分析に苦労しそうだ。
この言語に関するお前の次のステップは、以下のような基本を改めて学びながら、実践的なコードをどんどん書き連ねていくことに他ならない。
プログラミング言語 Rust, 2nd Edition (Rust 2018 Edition 非対応)
4. 作業を助けてくれる道具
ここではプログラミングをサーポートしてくれるツールを導入する。
4.1. Git
Git は、現在バージョン管理システムのデファクト・スタンダードとなっている。
その特徴だが、お前の知っている CVS との大きな違いは、リポジトリが分散管理されることだろう(下図)。
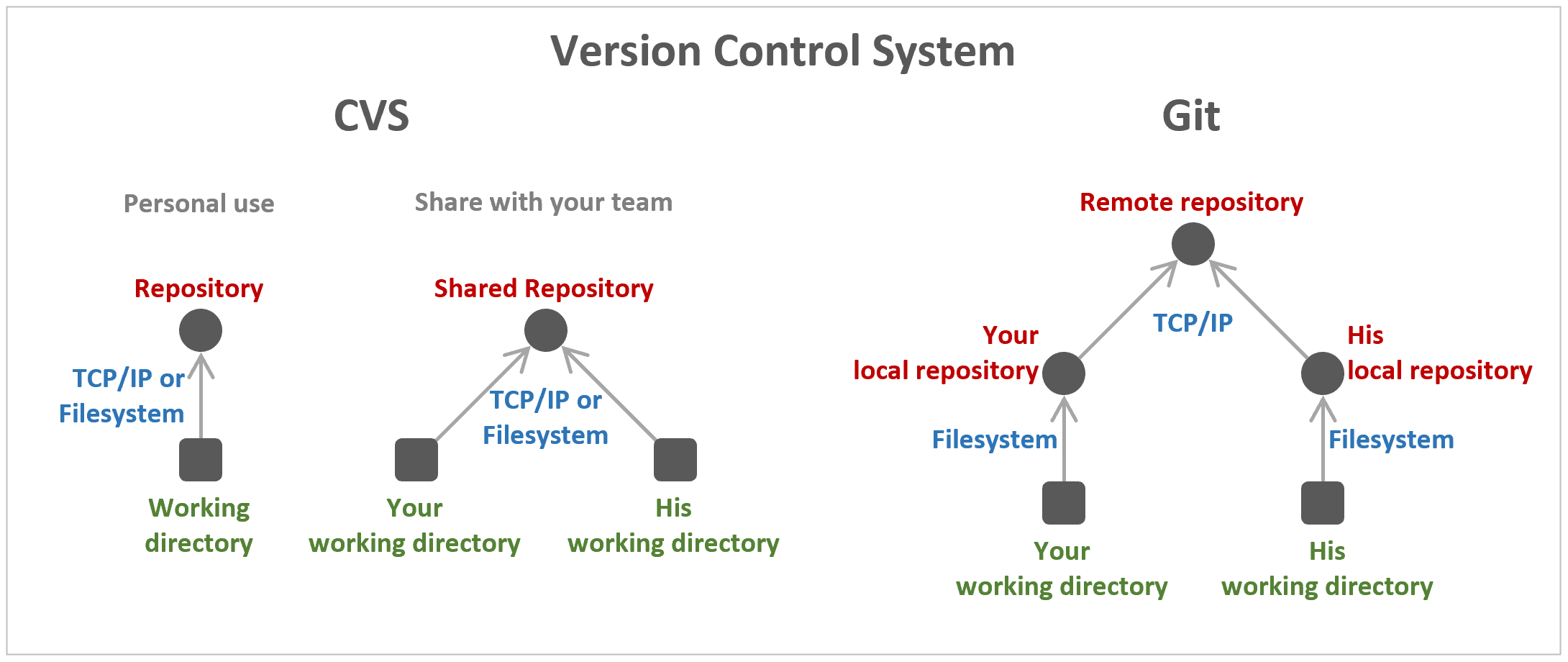
CVS でリモートから chekout した場合、ローカルにダウンロードされるのはあくまで「作業コピー」だったが、Git の場合はローカルへ「リポジトリ」がまるごとコピーされるということだ。
これによりローカル上のコミットがチームへ影響を与えることがない、分散リポジトリにより障害にきわめて強いなどのメリットが得られるようだ。
また、コマンドは以下のような感じだが、それほど違和感なく使えそうだ。
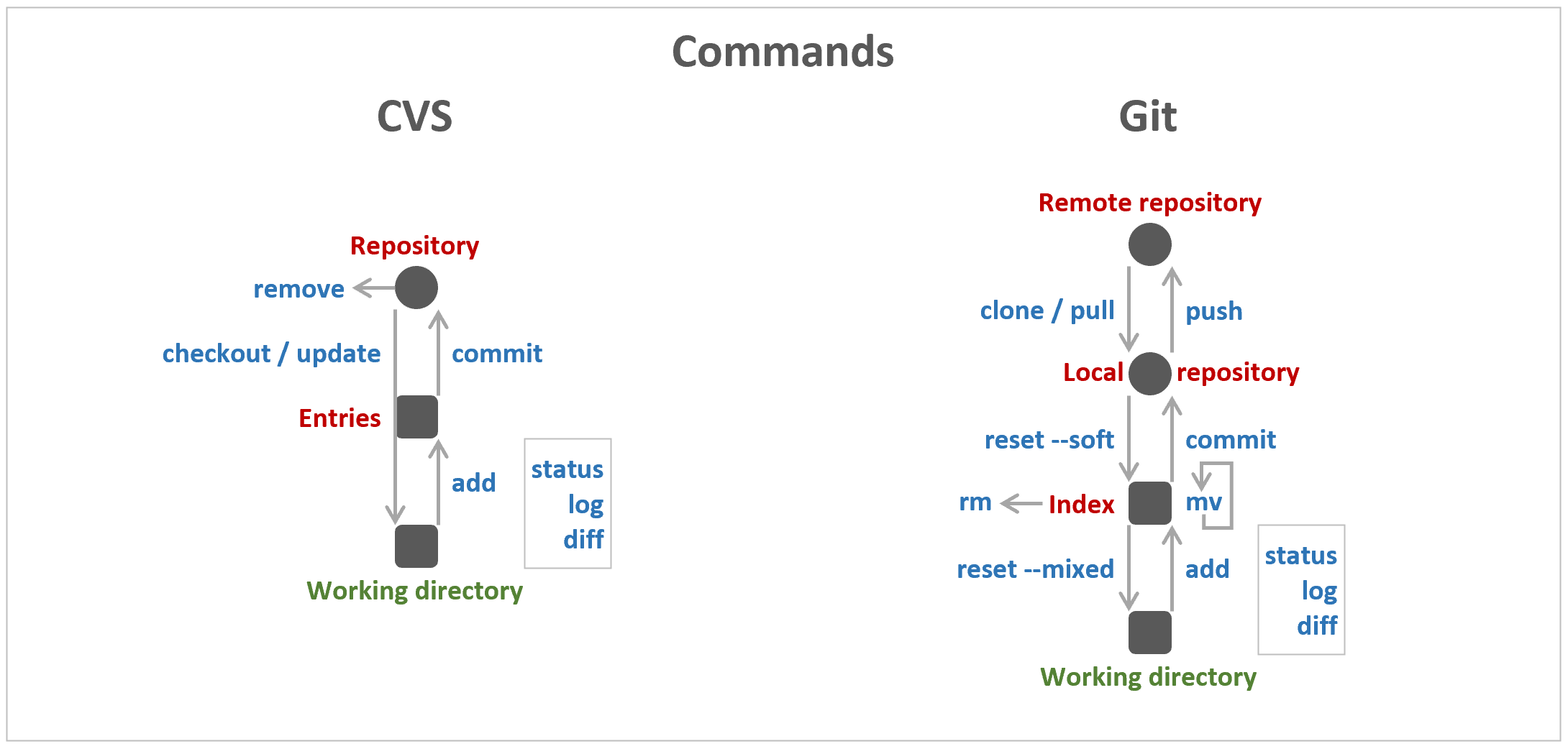
特に嬉しいのが git mv コマンドだろう。これがあるおかげで、CVS ではカオスになってしまうようなファイル名変更やディレクトリ構成変更にもうまく対応できそうだ。
4.1.1. インストール
Ruby の準備で rbenv を導入する際にインストールしているのでそっちを見てくれ。
4.1.2. GitHub を試す
Ruby の rvenv の項でも書いたが、世界中の多くのプロジェクトがこの GitHub という Web サービス上に Git のリポジトリを作って、そこでソースコードを公開するのが一般的になっている。
また、GitHub には無償で利用できるプランがあり、非公開のプライベート・リポジトリを作ることもできるから、個人的なソースコードやドキュメントなどをバックアップするためにも活用できそうだ。
以下のサイトでユーザ登録すれば簡単にリポジトリを作ることができる。
GitHub で作成したリポジトリにファイルを登録する。
$ mkdir your-repos-path
$ cd your-repos-path
$ vi your-file
$ git init
$ git add your-file
$ git commit -m "first commit"
$ git remote add origin https://github.com/user-name/your-repos-name.git
$ git push -u origin master
それにしても恵まれた時代だ。つくづくそう思う。
4.2. Vim
主にシンタックスハイライト機能を使うために、Vim を導入する。
4.2.1. インストール
vim は vi から派生した高機能エディタだ。そして、CentOS 等のデフォルトの vi も vim であるらしい。
現在インストールされている vi にシンタックス・ハイライト機能がサポートされているか確認する。
$ vi --version | grep syntax
-eval -mouse_gpm -syntax -xterm_save
サポートされていないので、vim のインストール済みパッケージを確認する。
$ dnf list installed | grep vim
vim-minimal.x86_64 2:8.0.1763-13.el8 @anaconda
デフォルトでインストールされているのが minimal 版であることが分かったので、高機能版を導入するためにインストール可能なパッケージを確認する。
$ dnf list | grep vim
vim-minimal.x86_64 2:8.0.1763-13.el8 @anaconda
vim-X11.x86_64 2:8.0.1763-13.el8 AppStream
vim-common.x86_64 2:8.0.1763-13.el8 AppStream
vim-enhanced.x86_64 2:8.0.1763-13.el8 AppStream
vim-filesystem.noarch 2:8.0.1763-13.el8 AppStream
vim-enhanced.x86_64 をインストールする。
$ sudo dnf install vim-enhanced
...
Complete!
インストールした vim の機能を確認する。
$ vim --version | grep syntax
+eval +mouse_gpm +syntax
シンタックス・ハイライト機能がサポートされていることが確認できた。
そこで、元々の vi (vim-minimal) と新しい vim (vim-enhanced) を改めて確認する。
$ ls -l /usr/bin/vi*
-rwxr-xr-x. 1 root root 1413696 Nov 11 19:08 /usr/bin/vi
lrwxrwxrwx. 1 root root 2 Nov 11 19:08 /usr/bin/view -> vi
-rwxr-xr-x. 1 root root 3522560 Nov 11 19:08 /usr/bin/vim
lrwxrwxrwx. 1 root root 3 Nov 11 19:08 /usr/bin/vimdiff -> vim
-rwxr-xr-x. 1 root root 2121 Nov 11 19:08 /usr/bin/vimtutor
導入した vim を vi という名前で呼び出せるようにするために、元々の vi を vim-min に変更する。
$ sudo mv /usr/bin/vi /usr/bin/vim-min
$ ls -l /usr/bin/vi*
lrwxrwxrwx. 1 root root 2 Nov 11 19:08 /usr/bin/view -> vi
-rwxr-xr-x. 1 root root 3522560 Nov 11 19:08 /usr/bin/vim
lrwxrwxrwx. 1 root root 3 Nov 11 19:08 /usr/bin/vimdiff -> vim
-rwxr-xr-x. 1 root root 1413696 Nov 11 19:08 /usr/bin/vim-min
-rwxr-xr-x. 1 root root 2121 Nov 11 19:08 /usr/bin/vimtutor
新しい vim (vim-enhanced) へのシンボリックリンク vi を作成する。
$ sudo ln -s /usr/bin/vim /usr/bin/vi
$ ls -l /usr/bin/vi*
lrwxrwxrwx. 1 root root 12 Apr 26 09:04 /usr/bin/vi -> /usr/bin/vim
lrwxrwxrwx. 1 root root 2 Nov 11 19:08 /usr/bin/view -> vi
-rwxr-xr-x. 1 root root 3522560 Nov 11 19:08 /usr/bin/vim
lrwxrwxrwx. 1 root root 3 Nov 11 19:08 /usr/bin/vimdiff -> vim
-rwxr-xr-x. 1 root root 1413696 Nov 11 19:08 /usr/bin/vim-min
-rwxr-xr-x. 1 root root 2121 Nov 11 19:08 /usr/bin/vimtutor
シンタックスハイライト以外の機能をデフォルトで利用するために ~/.vimrc に以下の設定を追記する。
| set option | 説明 |
|---|---|
| set showcmd | 入力中のコマンドをステータス行に表示 |
| set cursorline | 現在行を強調表示 |
| set cursorcolumn | 現在列を強調表示 |
| set smartindent | スマートインデントを利用 |
| set showmatch | 対応する括弧を表示 |
| syntax enable | シンタックスハイライトの有効化 |
| set incsearch | 検索文字列入力時にマッチする文字列をインクリメンタル検索 |
| set wrapscan | 最後まで検索したら最初に戻る |
| set hlsearch | 検索キーワードをハイライト表示 |
4.2.2. Vundle の導入
TypeScript や後述の TSX のシンタックスがデフォルトでハイライトされないため、Vundle というプラグイン・マネージャを導入する。
Vundle は GitHub で公開されているため、以下のように git コマンドでインストールする。
$ git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
.vimrc の先頭に以下を追記する。
set nocompatible
filetype off
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
Plugin 'VundleVim/Vundle.vim'
"ここにプラグインを追記
call vundle#end()
filetype plugin indent on
TypeScript のシンタックスがハイライトされるよう、 .vimrc に以下を追記する。
Plugin 'VundleVim/Vundle.vim'
Plugin 'leafgarland/typescript-vim' "<- 追記
ターミナルで以下を実行。
$ vim +PluginInstall +qall
- 身だしなみを整えるための道具
身だしなみは大事だ。どんなナイスガイだって、その素晴らしいキャラクターは外見を通じてしか人には伝わらない。そして、それはプログラマが作り上げるプロダクトについても同じだ。
ということで、ここでは身だしなみを整えるための現代的なツールを導入することにする。
5.1. React (Hooks with TypeScript)
お前の時代には、例えば Java で Web をやるのであれば、アプリケーションの身だしなみにあたるプレゼンテーション・ロジックは、主にサーバサイドのモジュールである JSP で書いていた。
だが、現代では少し状況が変わってきていて、クライアント側の JavaScript などで直接 DOM ツリーの一部を更新するようなアプリケーションが一般的になってきているんだ。そういった現代的なアプリケーションは、操作の度にブラウザがリロードされていた時代のものと比べて、ユーザからの見た目は非常にスマートでエレガントだ。
そんなフロントエンド・モジュールのための有名なフレームワークには、Angular、React、Vue などがあり、まあどれを使っても良いと思うが、今回は React を導入して検証することにする。
5.1.1. インストール
インストールといっても、JavaScript のライブラリだから、開発プロジェクトごとに npm を使って導入するだけだ。
また、React は TypeScript をサポートしており、せっかくだから今回は TypeScript のプロジェクトを作ることにしよう。
そして使い心地を確かめるための適当な題材としては、 React 公式のすばらしいチュートリアルがあったのでこれをやってみようと思うが、このチュートリアルで説明されている書き方は古いらしく、現在は推奨されていないようなので、Hooks という機能を使った今どきの書き方でやってみることにする。
React 公式の環境構築ツール Create React App を使って TypeScript の環境を作る。
$ mkdir ~/learn_react
$ cd ~/learn_react/
$ npx create-react-app tutorial-ts --typescript
構築が終わるとサンプルプロジェクトが出来上がっているのでこれを動かしてみる。
$ cd tutorial-ts/
$ npm start
この状態で、ホストOS (Windows 10) の Web ブラウザで http://192.168.33.10:3000/ にアクセスすればこのプログラムのレスポンスを確認できる。
5.1.2. 検証
サンプルプロジェクトを消し、HelloWorld を書いて動かす。
$ cd ~/learn_react/tutorial-ts/src
$ rm *
$ $ echo '
> import React from "react"
> import ReactDOM from "react-dom"
> ReactDOM.render(
> <div>hello, world</div>,
> document.getElementById("root")
> )
> ' > index.tsx
$ cd ..
$ npm start
ブラウザで確認すると、"hello, world" と表示されることが確認できた。
ちなみに、 npm start で動かすサーバプログラムを別ターミナルで起動した状態にしておくと、ソースコードを修正する度に自動的に再構築され、ブラウザ側で勝手にリロードしてくれるため非常に便利だ。
5.1.3. チュートリアルの「三目並べ」を試す
React 公式のチュートリアルはすばらしい。
このチュートリアルで、ひととおりの JavaScript による (Hooks を使わない) React を学び、最後の6つの課題である、
- 履歴の(col, row)表記
- 選択中の履歴を bold 体にする
- マス目を2重ループで実現
- 履歴を昇降トグルできるようにする
- 勝利につながった 3 つのマス目をハイライト
- 引き分けメッセージ
を実装した(下図)。

だが、俺にはこのプログラムの変数や関数の名前の付け方がしっくりこなかったため、Hooks + TypeScript で実装するにあたり、オブジェクト指向で設計し直すと共に、コンポーネントの切り出し方も含めて全体構成を以下のように整理し直してみた。
5.1.4. プログラムの構成
上図やプログラム内で使われる用語の定義は以下のとおりだ。
| 用語 | 別名 | 意味 |
|---|---|---|
| ReactCompo | React Component | React のコンポーネント。TSX では HTML 要素のように <> で表記され、TypeScript プログラムでは ReactElement 型のオブジェクトとして表現されるもの。 本プログラムは、GameCompo, BoardCompo, RowCompo, SquareCompo, HistoryCompo, StatusCompo の 6 つの React Component で構成される。 |
| <button> | ボタン | 上図でこのように表記されているコンポーネントは、ユーザ入力(具体的にはクリック操作)を受け付ける。 |
| Game | ゲーム | アプリケーション全体。DOM ツリーの最も上位のノード。 |
| Board | ボード 盤面 |
三目並べのゲーム版のこと。 DOM ツリー上では 3 つの「行」で構成される。 またプログラム内部で盤面上の駒の配置状態を表す場合は、9 つのマス目の配列で構成される。 |
| Row | Row 行 |
表示上、および DOM ツリー上で、盤面のヨコ1列を表す「行」のこと。3 つのマス目で個性される。 |
| Rows | 行見出し | 表示上の各行左端の見出しのこと。 "1" or "2" or "3"。 |
| RowIndex | 行インデックス | 各行のインデックス番号。 0 or 1 or 2。 |
| Col | Column 列 |
表示上の盤面のタテ1列の「列(カラム)」のこと。3 つのマス目で構成される。 |
| Cols | 列見出し | 表示上の各列上端の見出しのこと。 "a" or "b" or "c"。 |
| ColIndex | 列インデックス カラムインデックス |
各列(カラム)のインデックス番号。 0 or 1 or 2。 |
| Square | スクエア マス目 |
盤面を構成するマス目のこと。 クリック操作で駒を配置することができる。 |
| SquareIndex | スクエアインデックス マス目インデックス |
9つのマス目を一意に定めるインデックス番号。 盤面の左から右、上から下へ 0 ~ 8 が付番される。 |
| Piece | 駒 ピース |
マス目に配置する駒のこと。またはマス目に記録する印のこと。 "O" or "X"。 なお、マス目上の駒の配置状態を表す言葉としても使われ、 その場合は "O" or "X" or null。 |
| History | 履歴 Hs |
着手履歴、およびその表示領域のこと。最大 9 つの「ステップ」で構成される。 |
| HistoryHeader | 履歴ヘッダ HsHead |
DOM ツリー上の「履歴の見出し」のこと。 |
| HistoryOrder | 並び順ボタン 昇降トグル HsOrder |
履歴の並び順を切り替える「▼」「▲」のトグルボタン。クリック操作で切り替えることができる。 |
| HistoryBody | 履歴ボディ HsBody |
DOM ツリー上の「履歴の本体」のこと。各ステップを含む。 |
| Step | HistoryStep ステップ 履歴ステップ 番手 |
履歴を構成する各要素のこと。 インデックス、盤面の状態、説明で構成される。また、この表示領域はボタンでもあり、クリック操作で他のステップへジャンプすることができる。 |
| StepIndex | ステップインデックス | 各ステップのインデックス番号。 0 ~ 8。 |
| Desc | 説明 | 各ステップの説明。インデックス番号、配置した駒やその位置などの情報を含む。 |
| Status | ステータス | 次のプレーヤや勝敗状況などのユーザ向けメッセージ。およびその表示領域。React では State というこれと似た用語があるが、本プログラムでは status はここで定義するメッセージのこと、State は React 用語の State のこととして区別する。 |
| Player | プレーヤ | ゲームのプレーヤのこと。 プレーヤの名称は、各プレーヤの持ち駒である 'O' または 'X' で示される。 |
| Bingo | BingoLine ビンゴ 勝ちライン ビンゴ駒 |
盤面上の駒がゲームの勝利につながる縦、横、斜めに揃っている状態。またはそのライン。またはそのライン上にある駒やマス目のこと。 |
なお上表でパスカルケースとなっているものは、プログラム内でキャメルケースやスネークケースで表記されることがあるので、その例を以下に示す。
| 記法 | 例 |
|---|---|
| パスカルケース | HsOrder |
| キャメルケース | hsOrder |
| スネークケース | hs_order hs-order |
5.1.5. コンポーネント間通信
プログラム内で動的に変化する情報をコンポーネントが取り扱うために、React では State と Props という概念を導入している。また、ボタンクリックなどのイベントを検出したコンポーネントが、他のコンポーネントにそれを通知する際にはコールバックが使われる。
| 方法 | 説明 |
|---|---|
| State | React Component が自身で責任を持って更新すべき情報。 State を利用するコンポーネントは、保持しておきたい情報を React に渡しておき、次回の描画の際にそれを取り出して利用する。 |
| Props | 自身が更新の責任を持たないが、表示や計算のために必要とする情報。 Props は React Component が親コンポーネントからもらって利用する。 |
| Callback | イベントを検知した React Component が親コンポーネントなどにそれを伝えるためのハンドラ |
今回のプログラムでのコンポーネント間通信の概要は以下のとおりだ。
上図をみると以下のことがわかる。
- Props
コンポーネントが描画などのために必要とする情報のほとんどは、 GameCompo を頂点にして、親コンポーネントから子コンポーネントへ伝搬している。 - State
主に GameCompo が利用し、それ以外では HistoryCompo がトグルボタンの状態を保持するためだけに利用される。 - Callback
SquareCompo のクリックイベント(マス目に駒が置かれる)、 HistoryCompo のクリックイベント(他のステップが選択される)が発生すると、コールバックを介して GameCompo へ伝達される。
5.1.6. TSX形式の記述スタイル (index.tsx)
React Component は、一般的に拡張子 .tsx (JavaScript の場合は .jsx) で記載されたコードの中で利用され、これを HTML 要素のように、例えば Game コンポーネントであれば <GameCompo /> などの形で呼び出すことができる。 TSX は JSP に似ているかもしれない。 JSP は HTML の中に Java のコードを埋め込む形だが、TSX は TypeScript コード内に HTML を埋め込むようなスタイルになる。
それでは実際に今回のプログラムを示そう。
本プログラムの最上位にあたる index.tsx は以下のとおりだ。
import './index.css'
import React from 'react'
import ReactDOM from 'react-dom'
import GameCompo from './components/GameCompo'
ReactDOM.render(
<GameCompo />,
document.getElementById('root')
)
このプログラムを見ると、実際に TypeScript のコード内で GameCompo を <GameCompo /> の形で呼び出していることがわかる。 TSX にこう書くことで、TypeScript に変換される際に、これが ReactElement というオブジェクトに書き換えられるようだ。
5.1.7. Hooks の useState を使う (GameCompo.tsx)
次に GameCompo の中身を示す。
import React, {useState} from "react"
import Game from "../rules/Game"
import BoardCompo from "./BoardCompo"
import StatusCompo from "./StatusCompo"
import HistoryCompo from "./HistoryCompo"
// ゲームコンポーネント
const GameCompo: React.FC = () => {
// state of react hooks ----------------------------
const [game, setGame] = useState( () => new Game() )
// callback handler --------------------------------
const putPiece =(square: number): void => // マス目に駒が置かれた
setGame( game.putPiece(square) )
const jumpTo = (step : number): void => // ステップが選択された
setGame( game.jumpTo(step) )
// render ------------------------------------------
return (
<>
<div className="title">
Tick-tac-toe
</div>
<div className="game">
<div>
{/* 盤面 */}
<BoardCompo
board = {game.board }
onSelect = {putPiece } />
{/* ステータス */}
<StatusCompo
status = {game.status } />
</div>
{/* 履歴 */}
<HistoryCompo
history = {game.history}
onSelect = {jumpTo } />
</div>
</>
)
}
export default GameCompo
上記では以下のようなことをしている。
-
import ~
プログラム内で利用する外部機能のインポート。- React 関連ライブラリ
React,useState - GameCompo の状態を格納するエンティティ
Game - 子コンポーネント
BoardCompo,StatusCompo,HistoryCompo
- React 関連ライブラリ
-
const GameCompo: React.FC = () => {
関数定義。この関数 GameCompo は React.FC という型のインターフェースであり、これが index.tsx 内で呼び出そうとしている<GameCompo />の正体だ。React ではコンポーネントをクラスで実装することもできるが、現在はこのように関数で表現することが推奨されており、Hooks は React Component を関数で実装するためのサポート機能が強化されている。 -
const [game, setGame] = useState( () => new Game() )
ここで Hooks の機能 useState を使って State の出し入れができるようにしている。関数コンポーネントはその名の通り「関数」なので、コンポーネント内で宣言した変数は関数の終了と共にその命が終わってしまうが、 State にデータを設定しておくことで、次回関数がコールされた際にもそのデータを利用することができる。- まず useState() の引数に State の初期値(GameCompo の状態を保持するエンティティ Game オブジェクト)を渡している。ここで渡した初期値
()=> new Game()は最初に 1 度だけ State として設定され、2回目以降は無視されるので毎回上書きされることはない。 - そして今回ここで引数として
() => new Game()の形で Game オブジェクトを生成する関数を渡しているが、ここは単にnew Game()とし、既に評価された Game オブジェクトを渡す形にしてもアプリケーションの見た目には違いはない。
それではなぜこのような形にしているかというと、描画される度に(この関数コンポーネントが呼び出される度に) new Game() が実行されてしまうのを防ぐためだ。単にリテラルを渡す場合などであれば useState(0) などとすれば良い。その場合、useState() に毎回 0 が渡されるが、その 0 は useState() 内部で最初のコールの時にだけ使われ2回目以降は無視されるからだ。無駄な処理は行われるが、整数リテラルを代入する程度のコストであれば問題はないであろう。だが、new Game() のようにコストのかかる初期化の場合はどうだろうか? useState ではこのような問題に対処するために「初期値を返す関数」を渡すことで毎回評価されないような工夫がされている。だから useState(0) の代わりに useState( ()=>0 ) の形で「 0 を返す関数」を渡しても動作に違いは出ない。 - 次に useState の戻り値だが、これはお前には見慣れない書き方だろう。 JavaScript や TypeScript では、
let array=[100,200]; let x, y; x=array[0]; y=array[1]とするところを、let [x, y] = [100, 200]のように短く書くことができる。これは便利だ。 - つまりここでは
const [game, setGame] = ~とすることで、game という変数に Game オブジェクトが代入され、 setGame という変数に「Game オブジェクトを State として保存するための関数」が代入され、これを使って State の出し入れができるようになるというわけだ。
- まず useState() の引数に State の初期値(GameCompo の状態を保持するエンティティ Game オブジェクト)を渡している。ここで渡した初期値
-
const putPiece = (square: number): void =>setGame( game.putPiece(square) )
マス目がクリックされた際のコールバック。
ここにクリックされたマス目のインデックスが通知されてくるので、アプリケーション全体の状態を管理する Game オブジェクトに対して putPiece() というメソッドを通じてマス目に駒が置かれたことを伝えている。- ここでのポイントは Game オブジェクトを参照する変数 game は Hooks の useState で取得したものだということだ。
- 同様に Hooks の useState で取得した setGame という関数を使い、これに状態変更後の Game オブジェクトを渡すことでアプリケーションの再描画を促している。
- また、次の行の
const jumpTo = ~は、履歴のステップがクリックされた際のコールバックであるが、やっていることは putPiece とほぼ同じだ。
-
return ( ~
この中で TSX 特有の(HTML 要素のような)書き方をしている。-
<></>
TSX で記載した箇所を ReactElement 型のオブジェクトとして評価させるためには、複数の子要素をひとつの要素(例えば <div> など)で括る必要がある。だが<div></div>と書くと DOM に余分なノードが追加されてしまうので、それを避けるためにここでは<>という書き方をしている( <> は <React.Fragment> という特殊な書き方の省略系)。 -
<BoardCompo board={game.board} onSelect={putPiece} />
ここで子コンポーネント BoardCompo を呼び出している。BoardCompo の最初の引数として、(useState で取得した)game 変数から取り出した board オブジェクトを渡し、2番目の引数として、コールバック関数の putPiece を渡している。この引数として渡すものが「React の Props」の正体である。 - 同様に StatusCompo と HistoryCompo を呼び出している。
-
次に GameCompo のエンティティである Game のコードを示す。
import History from "./History"
// ゲームクラス
export default class Game {
// private properties ----------------------------------- // ゲームは
private _history: History // 単なる履歴のラッパー
// constructor ------------------------------------------
constructor(history?: History) {
if (history === undefined) this._history = new History()
else this._history = history
}
// accessors --------------------------------------------
get board () { return this._history.currentStep.board } // 現在の盤面
get status () { return this._history.currentStep.status } // 現在のステータス
get history() { return this._history } // 履歴
// public methods ---------------------------------------
// 以下はいずれも Game オブジェクトを再生成している。
// React の useState を使って値を更新した後、 React に
// (更新が認識され)再レンダリングされるようにするため
putPiece(squareIndex: number): Game { // 現在の盤面に駒を配置
this._history.update(squareIndex)
return new Game(this._history)
}
jumpTo(stepIndex: number):Game { // 他のステップへジャンプ
this._history.current = stepIndex
return new Game(this._history)
}
}
Game クラスは、GameCompo が必要とする board, status, history などのエンティティを保持しており、クリックイベントなどの通知を受け入れる putPiece() や jumpTo() といったメソッドを用意している。
5.1.8. ソースコードの分割
本家のチュートリアルではプログラムを index.js と index.css という 2 つのファイルに書いていたが、今回書き直すにあたって、この GameCompo と Game のように、React Component を View としての役割に集中させるために、各コンポーネントが描画のために必要とするプログラムの状態を、それぞれのコンポーネントに対応するエンティティクラスを用意して管理させている。
そのため今回、ソースコードを以下のように分割している。
src ........................ [ ソースコードルート ]
├── index.tsx .............. ルートノード
├── index.css .............. スタイルシート
├── components ............. [ コンポーネント ]
│ ├── GameCompo.tsx ...... ゲーム全体
│ ├── BoardCompo.tsx ..... 盤面(行 x 3)
│ ├── RowCompo.tsx ....... 行(マス目 x 3)
│ ├── SquareCompo.tsx .... マス目
│ ├── StatusCompo.tsx .... ステータス
│ └── HistoryCompo.tsx ... 履歴
└── rules .................. [ ルール ]
├── Game.ts ........... ゲームのエンティティ
├── Board.ts .......... 盤面のエンティティ
├── Row.ts ............ 行のエンティティ
├── Square.ts ......... マス目のエンティティ
├── History.ts ........ 履歴のエンティティ
├── Step.ts ........... 履歴のステップのエンティティ
└── Rules.ts .......... 勝敗判定など
BoardCompo に対応する Board などのように、原則として、 React Component の名称から "Compo" を外したものをエンティティのクラス名としているが、以下の 2 点はその例外である。
- StatusCompo のエンティティ
StatusCompo が必要とするのは、string 型の単純なステータスメッセージなので、今回はわざわざエンティティ・クラスを用意していない。 - HistoryCompo のエンティティ
履歴クラスのオブジェクトはステップ・オブジェクトのリストを管理しているため、今回は History と Step という 2 つのクラスのリレーションでそれを表現することとした。
また、アプリケーションのロジックをエンティティから切り離すために、勝敗判定などのルールを Rules.ts に切り出した。
5.1.9. Props を使う (BoardCompo.tsx)
BoardCompo のコードは以下のとおりだ。
import React from "react"
import {Cols} from "../rules/Rules"
import Board from "../rules/Board"
import RowCompo from "./RowCompo"
interface BoardProps { // コンポーネント・プロパティ
board : Board // ・盤面オブジェクト
onSelect: (index: number) => void // ・マス目が選択された際のハンドラ
}
// 盤面コンポーネント (行の縦並び)
const BoardCompo: React.FC<BoardProps> = ({ board, onSelect }) =>
// render -----------------------------------------------------
<>
{/* ヘッダ(上端) */}
<div key ="bd-row-0">
<button className = "bd-head-org" />
{/* 列ヘッダの横並び(列数分のループ) */}
{Cols.names.map( (columnName, i) => (
<button
className = "bd-head-top"
key ={"bd-col-" + i} >
{columnName}
</button>
))}
</div>
{/* ボディ。行の縦並び(行の数だけループ) */}
{board.rows.map( (row, i) => (
<RowCompo
key = {"bd-row-" + i + 1}
row = {row }
onSelect = {onSelect } />
))}
</>
export default BoardCompo
このコードのポイントは以下のとおりだ。
-
interface BoardProps { ~
ここで、 BoardCompo が Props として親コンポーネントから受領する情報を TypeScript のインターフェース BoardProps として定義している。そしてこのインターフェースには、エンティティの Board オブジェクトとコールバックの onSelect をメンバとして持たせている。 -
const BoardCompo: React.FC<BoardProps> = ({ board, onSelect }) => ~
ここで React.FC というジェネリック型の型引数に React.FC<BoardProps> の形で上記インターフェースを渡している。その上で仮引数を ({ board, onSelect }) とすることで、BoardProps で定義した情報を取り込んでいる。ちなみに、この書き方はさっきの配列と同じようにconst {foo, bar} = {foo:"FOO", bar:0}のような便利な書き方で受け取っており、このように BoardProps のメンバー board と onSelect を直接取り込むことで、(props) として受け取った時に props.board などと書かなければならないような煩わしさから解放されるというわけだ。 -
{Cols.names.map( (columnName, i) => ( ~
TSX 内で TypeScript のコードを書くにはこのように {} で括る必要がある。ここでは Cols.names という列名の配列を元にして map 関数で列ヘッダを書いている。 -
{board.rows.map( (row, i) => ( ~
同様に、board.rows という Row オブジェクトの配列を元にして map 関数ですべての行を書いている。その中で子コンポーネントである RowCompo を呼び出しているが、ここで Props として、board.rows(配列)の要素である row オブジェクトと、 onSelect コールバックを渡している。
React では Props をこのように使う事で、親コンポーネントから子コンポーネントへ情報が伝達されていく。
次に BoardCompo のエンティティクラスである Board のコードを示す。
import Row from "./Row"
import Square from "./Square"
import {Cols, Rows, Squs, Piece,
Bingo, inflateAndMap} from "./Rules"
// 盤面クラス
export default class Board {
// private properties -------------------------------------- // 盤面は以下で構成
private _winner : Piece | null // ・この盤面の勝者
private _squares: Square[] // ・マス目配列
// constructors --------------------------------------------
constructor(board?: Board) { // コンストラクタ
if (board === undefined) { // 空の盤面を生成
this._winner = null
this._squares = inflateAndMap(Squs.len, i => new Square(i) )
} else { // クローンを生成
this._winner = board._winner
this._squares = board._squares.map( s => s.clone() )
}
}
// accessors -----------------------------------------------
get bingo (): boolean { return this._winner !== null } // ビンゴ状態か?
get winner(): Piece | null { return this._winner } // 勝者を返す
get filled(): boolean { // 既に盤面が
return this._squares.find(s => s.empty) === undefined // 埋まっているか?
}
get rows(): Row[] { // マス目の1次元配列を
return Rows.names.map( (name, i) => // 行 x 列の構造に
new Row( name, Cols.names.map( (_, j) => // 組み替えて返す
this._squares[i * Cols.len + j] )
)
)
}
// public methods ------------------------------------------
clone = ( ): Board => new Board(this) // クローン生成
squares = (i: number): Square => this._squares[i] // i番目のマス目を返す
putPiece = (i: number, piece: Piece): Board => { // i番目のマス目に駒配置
const nb = this.clone() // イミュータブルに...
nb._squares[i] = new Square(i, piece) // ピースを置いて
const result = Bingo.maybe(i => nb._squares[i].piece) // ビンゴチェックをして
if (result.bingo) { // ビンゴなら
nb._squares = nb._squares.map( s => s.cloneClear() ) // 1度ビンゴ印を消して
nb._winner = result.winner // 勝者を書き留めて
result.bingoLine?.forEach(i => // ビンゴ印を付け直す
nb._squares[i] = nb._squares[i].cloneBingo() )
}
return nb
}
}
この Board クラスの概要は以下のとおりだ。
- Board クラスは盤面全体の状態を管理しており、内部にマス目を管理する Square オブジェクトの1次元配列を保持している。
- 盤面がビンゴ状態であるか?(bingo)、勝者がいるのであればそれが誰であるか?(winner)、盤面のすべてのマス目が駒で満たされている(つまりゲームが終了している)か?(filled)、といったアクセサを持っている。
- BoardCompo が BoardRow に引き渡す Props Row の配列を返すアクセサ(rows)を持っている。このアクセサは、このオブジェクトが内部で保持している1次元のマス目配列を、BoardCompo と RowCompo が必要とする Row x Col の 2 次元の構造に組み替えて返すものである。
- 新しいステップに移行する際に必要とされる、盤面の複製を返すメソッド(clone)、特定のマス目オブジェクトを返すメソッド(squares)を持っている。
- この盤面のマス目に駒を配置した際に盤面がどういう状況になるのか、その結果の盤面を返すメソッド (putPiece) を持っている。
続いて、行を表現する RowCompo および そのエンティティである Row のコードを示す。
import React from "react"
import Row from "../rules/Row"
import SquareCompo from "./SquareCompo"
interface RowProps { // コンポーネント・プロパティ
row : Row // ・(盤面の)行オブジェクト
onSelect: (index: number) => void // ・マス目が選択された際のハンドラ
}
// (盤面の)行コンポーネント (マス目の横並び)
const RowCompo: React.FC<RowProps> = ({ row, onSelect }) =>
// render -----------------------------------------------
<div>
{/* 行ヘッダ(左端) */}
<button
className = "bd-head-left"
key ={"bd-head-left-" + row.name} >
{row.name}
</button>
{/* 行ボディ(横一列のマス目の数だけループ) */}
{row.squares.map( (square, i) =>
<SquareCompo
key = {"square" + i}
square = {square }
onSelect = {onSelect } />
)}
</div>
export default RowCompo
import Square from "./Square"
// (盤面の)行クラス
export default class Row {
// constructor & private properties --------------------
constructor( // 行は
private _name : string , // ・名前(行見出し)
private _squares: Square[] // ・マス目配列(列数分)
) {} // で構成される
// accessors -------------------------------------------
get name (): string { return this._name }
get squares(): Square[] { return this._squares.slice() } // イミュータブルに...
}
Row クラスは内部では Square の配列を保持していて、RowCompo はその内容を表示するために SquareCompo を呼び出しているが、これらのコードではこれまでに説明したこと以外に特に新しいことはしていない。
5.1.10. コールバックによる通知を行う (SquareCompo.tsx)
マス目を管理する SquareCompo のコードを示す。
import React from "react"
import Square from "../rules/Square"
interface SquareProps { // コンポーネント・プロパティ
square : Square // マス目オブジェクト
onSelect: (index: number) => void // マス目が選択された際のハンドラ
}
// マス目コンポーネント (マス目 1 個)
const SquareCompo: React.FC<SquareProps> = ({ square, onSelect }) =>
// render ------------------------------------------------
<button
className = {square.bingo ? "square-bingo" : "square"}
onClick = {() => onSelect(square.index) } >
{square.piece}
</button>
export default SquareCompo
SquareCompo は末端のコンポーネントであるため、React Component の呼び出しは行っておらず、代わりに HTML の <button> 要素を書いている。
また、ボタン(マス目)がクリックされた際のハンドラとして、親コンポーネントからもらったコールバック関数(を呼び出す関数)を渡している。
続いて SquareCompo の Entity クラスである Square のコードを示す。
import {Piece} from "./Rules"
// マス目クラス
export default class Square {
// constructor & private properties ---------------------
constructor( // マス目は
private _index: number , // ・盤面上のインデックス
private _piece: Piece | null = null , // ・置かれた駒
private _bingo: boolean = false // ・ビンゴ駒かどうか
) {} // で構成される
// accessors --------------------------------------------
get index(): number { return this._index }
get piece(): Piece | null { return this._piece }
get bingo(): boolean { return this._bingo }
get empty(): boolean { return this._piece === null } // マス目が空か?
get used (): boolean { return this._piece !== null } // マス目が使われているか?
// public methods ---------------------------------------
clone = (): Square => // 複製
new Square(this._index, this._piece, this._bingo)
cloneClear = (): Square => // ビンゴ印を消して複製
new Square(this._index, this._piece)
cloneBingo = (): Square => // ビンゴ印を付けて複製
new Square(this._index, this._piece, true)
}
Square クラスは盤面を構成するマス目を管理しており、マス目のインデックス(index)、マス目に置かれた駒(piece)、マス目がビンゴライン上にあるかどうか(bingo)、マス目が空いているかどうか(empty)、逆にマス目に駒が置かれているか(used)などのアクセサを持っている。
5.1.11. 下位コンポーネントで useState を使う (HistoryCompo.tsx)
続いて、ゲームの履歴を管理する HistoryCompo のコードを示す。
import React,{useState} from "react"
import History from "../rules/History"
interface HistoryProps { // コンポーネント・プロパティ
history : History // ・履歴オブジェクト
onSelect: (index: number) => void // ・(履歴の)ステップが選択された際のハンドラ
}
// 履歴コンポーネント
const HistoryCompo: React.FC<HistoryProps> = ({ history, onSelect }) => {
// state of react hooks ------------------------------
const [isAscending, setIsAscending] = useState(true)
// callback handler ----------------------------------
const toggleClick = () => setIsAscending(!isAscending) // 昇降トグルのハンドラ
// pretreatment
let steps = history.steps
if (!isAscending) steps = steps.slice().reverse() // 降順ならリストを逆転
// render ------------------------------------------
return (
<div className="history">
{/* 履歴ヘッダ */}
<div className="hs-header">
<span>History</span>
{/* 昇降トグルボタン */}
<button
className = "hs-order"
onClick = {toggleClick} >
{isAscending ? "▼" : "▲"}
</button>
</div>
{/* 履歴ボディ */}
<div className="hs-body">
{/* ステップの縦並び(ステップの数だけループ) */}
{steps.map( step => (
<button
className = {(step.index === history.current) ?
"step-curr" : "step" }
key = {"hs-" + step.index }
onClick = {() => onSelect(step.index)} >
{step.desc}
</button>
))}
</div>
</div>
)
}
GameCompo 内で使った Hooks の useState をこの HistoryCompo の中でも使っている。このコンポーネント内にある昇降トグルボタンがクリックされると履歴表示の昇順・降順が切り替えられるが、トグルが現在どちらの状態にあるのかを、ここで React の State として保存している。このトグルの切り替え状態は、このコンポーネントだけが必要とする情報であり、それ以外にアプリケーションの挙動に影響を与えない。
このため、このコンポーネントは昇降トグルボタンがクリックされると、それを他のコンポーネントに伝えることはせずに、自身のハンドラ内で const toggleClick = () => setIsAscending(!isAscending) を実行している。
また、これと異なり、ステップがクリックされた際はアプリケーションが盤面をそのステップの内容に描き換える必要があるため、こちらがクリックされた際の挙動は親コンポーネントから渡されたハンドラに処理を任せている。
HistoryCompo が画面表示の際に利用する History と Step というエンティティクラスのコードを以下に示す。
import Step from "./Step"
// 履歴クラス
export default class History {
// private properties -------------------------------------- // 例歴は以下で構成
private _steps : Step[] // ・ステップの配列
private _current: number // ・現在のステップ
// constructors --------------------------------------------
constructor() {
this._current = 0
this._steps = [Step.makeFirst()]
}
// accessors -----------------------------------------------
get steps () { return this._steps } // ステップ配列
get current () { return this._current } // ステップインデックス
get currentStep() { return this._steps[this._current] } // ステップそのもの
set current(stepIndex: number) { this._current = stepIndex } // ステップを移動する
// public methods -----------------------------------------
update(squareIndex: number): void { // 現在ステップに駒配置
const step =
this._steps[this._current].makeNext(squareIndex) // 新しいステップを作り
if (step !== undefined) { // 上手く作れたら
this._current = step.index
this._steps // 現在以降を切り捨てて
= this._steps.slice(0, this._current).concat(step) // 新たな未来を作る
}
}
}
History クラスは、ステップの配列を管理しており、過去のステップの盤面に駒が置かれた場合は、それ以降の未来を切り捨てて新たな履歴を作り直すような挙動を管理している。
import Board from "./Board"
import {Players, Cols, Rows} from "./Rules"
// (履歴の)ステップクラス
export default class Step {
// static methods -------------------------------------
static makeFirst(): Step { // 最初のステップを作る
return new Step( 0, "#0 Start", new Board() )
}
// constructor & private properties -------------------
constructor( // ステップは
private _index: number, // ・インデックス
private _desc : string, // ・説明文
private _board: Board // ・盤面
) {} // で構成される
// accessors ------------------------------------------
get board () { return this._board }
get index () { return this._index }
get desc () { return this._desc }
get status(): string { // このステップの
if (this._board.bingo) // ステータスメッセージを返す
return "Winner: " + this._board.winner
else if (this._board.filled)
return "Draw!"
else
return "Next player: " + Players.byStep(this._index + 1)
}
// public methods -------------------------------------
// このステップの盤面に次の駒を置いて新たなステップを作る
makeNext(squareIndex: number): Step | undefined {
if (this._board.filled || // 既に盤面が埋まっていたり
this._board.bingo || // 勝敗が付いていたり
this._board.squares(squareIndex).used) // マス目が使用済みなら
return undefined // 新しいステップは作らない
const index = this._index + 1 // 新しいステップインデックス
const col = Cols.namesBySquare(squareIndex)
const row = Rows.namesBySquare(squareIndex)
const player = Players.byStep(index)
const desc = `#${index} (${col}, ${row}) ${player}` // 新しい説明
const board =
this._board.putPiece(squareIndex, player) // 新しい盤面
return new Step(index, desc, board)
}
}
この Step クラスは、自身の盤面の状態と画面表示用の説明文を管理し、そこに新たに駒が置かれた場合に新しいステップを生成する機能を有している。
5.1.12. エンティティクラスを持たないコンポーネント (StatusCompo.tsx)
続いて StatusCompo であるが、このコンポーネントはユーザ向けのステータスメッセージの文字列を表示するだけのシンプルなコンポーネントであるため、これに対応するエンティティクラスは存在しない。
import React from "react"
interface StatusProps { // コンポーネント・プロパティ
status : string // 次の番手、勝者、引き分けなどの情報
}
// ステータスコンポーネント
const StatusCompo: React.FC<StatusProps> = ({ status }) =>
// render ------------------------------
<div className="status">
{status}
</div>
export default StatusCompo
5.1.13. ロジックを司るクラス (Rules.ts)
続いて、ゲームのルールを定めている Rules.ts のコードを示す。これは React とは直接関係がない話だが、アプリケーションのロジックを司るクラス(このプログラムではゲームのルールを定めるクラス)として、View としてのコンポーネントや、状態を管理するエンティティクラスとは切り離すことにした。
// types & constants --------------------------------
export type Piece = "O" | "X" // マス目に置く駒
const PLAYERS: Piece[] = ["O", "X"] // プレーヤ
const COLS : string[] = ["a", "b", "c"] // 盤面の列見出し
const ROWS : string[] = ["1", "2", "3"] // 盤面の行見出し
const BINGO_LINES: number[][] = [ // ビンゴパターン8種
[0, 1, 2], [3, 4, 5], [6, 7, 8], [0, 3, 6],
[1, 4, 7], [2, 5, 8], [0, 4, 8], [2, 4, 6],
]
/* 3人対戦の4目並べ
export type Piece = "O" | "X" | "H" // マス目に置く駒
const PLAYERS: Piece[] = ["O", "X", "H"] // プレーヤ
const COLS : string[] = ["a", "b", "c", "d"] // 盤面の列見出し
const ROWS : string[] = ["1", "2", "3", "4"] // 盤面の行見出し
const BINGO_LINES: number[][] = [ // ビンゴパターン10種
[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9,10,11],
[12,13,14,15], [ 0, 4, 8,12], [ 1, 5, 9,13],
[ 2, 6,10,14], [ 3, 7,11,15], [ 0, 5,10,15],
[ 3, 6, 9,12]
]
*/
const SQUARES_LEN = COLS.length * ROWS.length
// public functions ---------------------------------
// 元になる配列が無い状態で要素数nのマップを行う
type IAM_Func = (i: number) => any
export const inflateAndMap = (n: number, fn: IAM_Func) : any[] =>
Array<null>(n).fill(null).map( (_, i) => fn(i) )
// static classes------------------------------------
// プレーヤクラス
export class Players { // ステップ誰の番かを管理
static byStep = (stepIndex: number): Piece => // プレーヤ名は駒名と同じ
PLAYERS[ stepIndex % PLAYERS.length ]
}
// 盤面の列情報を管理するクラス
export class Cols {
static get len() { return COLS.length } // 列数を得る
static get names(): string[] { // 列名の配列を得る
return COLS.slice()
}
static namesBySquare = (index: number): string => // マス目のインデックスから
COLS[index % COLS.length] // 列名を得る
}
// 盤面の行情報を管理するクラス
export class Rows {
static get len() { return COLS.length } // 行数を得る
static get names(): string[] { // 行名の配列を得る
return ROWS.slice()
}
static namesBySquare = (index: number): string => { // マス目のインデックスから
const rowIndex = Math.floor(index / Cols.len) // 行名を得る
return ROWS[rowIndex]
}
}
// マス目数の情報を管理するクラス
export class Squs {
static get len() { return Cols.len * Rows.len } // マス目数を得る
}
// ビンゴ検査結果クラス
class BingoResult {
constructor(
public winner : Piece | null,
public bingoLine: number[] | null
) {}
get bingo() { return this.winner !== null }
}
// ビンゴ検査のコールバックの型
type MBB_Func = (squareIndex: number) => Piece | null // マス目の駒を返す
// ビンゴ検査クラス
export class Bingo {
private static isAllSame = // bingoLine 配列が示す
(squares : (Piece | null)[] , // すべてのマス目に、皆同じ
bingoLine: (number )[] ): boolean => { // 種類の駒が置かれているか
const b0 = bingoLine[0] // 1つでも空のマス目があれば
if (squares[b0] === null) return false // ビンゴではない
const found = bingoLine.slice(1).find( // 2個目以降もすべて同じなら
bn => squares[b0] !== squares[bn] // ビンゴ
)
return found === undefined
}
static maybe = (fn: MBB_Func) : BingoResult => { // ビンゴ検査
const squares = // 呼び出し元の盤面を
inflateAndMap(SQUARES_LEN, i => fn(i) ) // 1度駒の配列にする
const bingoLine = // ビンゴラインが形成されて
BINGO_LINES.find( // いるか確認
bl=>Bingo.isAllSame(squares, bl)
)
if (bingoLine === undefined) { // ビンゴではない
return new BingoResult(null, null)
} else { // ビンゴである
const b0 = bingoLine[0]
const winner = squares[b0]
return new BingoResult(winner, bingoLine)
}
}
}
このようにゲームのルール(ロジック)をここに集中させることにより、例えば、上記の 2 ~ 9 行目を、その下のコメントアウト部分 (11 ~ 20 行目)に置き換える程度の修正で、「2人対戦の三目並べ」を「3人対戦の4目並べ」などに変更できるようにしている(下図)。

5.1.14. React と map 関数の相性
また、このコード内の inflateAndMap という関数は、もしかしたら React の他のアプリケーションでも再利用できるかもしれない。
// 元になる配列が無い状態で要素数nのマップを行う
type IAM_Func = (i: number) => any
export const inflateAndMap = (n: number, fn: IAM_Func) : any[] =>
Array<null>(n).fill(null).map( (_, i) => fn(i) )
どの程度需要があるかわからないが、これを用意しておくと、TSX の中で元になる配列がない状態でループしたい場合に、以下のように書かなければならないコードを、
<ul>
{Array<null>(10).fill(null).map( (_, i) =>
<li>レコードが {i + 1} 枚</li>
)}
</ul>
以下のようにすっきり書くことができる。
<ul>
{inflateAndMap(10, i =>
<li>レコードが {i + 1} 枚</li>
)}
</ul>
TSX は map 関数と相性が良い。React の公式では、return 前の JavaScript のコード内で、配列に <>形式 で書いた React 要素を push していく方法が紹介されているが、これだと DOM ツリー全体の見通しが悪くなるように思う。
だが TSX 内にループを書こうとしても、ReactElement 値の返却が要求される TSX の中では文である for(値として評価されない)や undefined を戻す forEach のような関数を書くことはできない。
そこで map の登場になるわけだが、map 関数であれば、コールバックが返す <>形式 の React 要素を配列に格納して戻してくれるのでそのまま TSX 内に書くことができて便利だし、その方が見通しの良いコードが書けるのではないだろうか。
5.1.15. React.FC について
TypeScript で React を利用するにあたり、コンポーネントをどのように実装すれば良いかをネットで調べていて React.FC というインターフェースを実装すれば良さそうな事はわかったのだが、このインターフェースがいったい何なのかがわからなかったので、以下の方法で調べてみた。
$ cd ~/learn_react/tutorial-ts/
$ find node_modules/ -type f -name '*.ts' | xargs grep 'type *FC'
node_modules/@types/react/index.d.ts: type FC<P = {}> = FunctionComponent<P>;
FC という型が node_modules/@types/react/index.d.ts に記載されていることがわかったので、更にこのファイルを調べてみると以下のような定義が見つかった。
...
type FC<P = {}> = FunctionComponent<P>;
interface FunctionComponent<P = {}> {
(props: PropsWithChildren<P>, context?: any): ReactElement<any, any> | null;
propTypes?: WeakValidationMap<P>;
contextTypes?: ValidationMap<any>;
defaultProps?: Partial<P>;
displayName?: string;
}
...
データ型 FC は FC<P = {}> となっており、これは 型引数 P を省略することができるジェネリック(総称型)で、 FunctionComponent<P> の別名であることがわかる。
そして、 FunctionComponent<P> を見てみると、これがインターフェース(これも型引数 P を省略可能なジェネリック)で、1 つのメソッドと、省略可能な 4 つのプロパティを持つことがわかる。
そして、このメソッドは以下のような構造を持っている。
(props: PropsWithChildren<P>, context?: any): ReactElement<any, any> | null
| 項目 | 型 | 説明 |
|---|---|---|
| 引数 props | PropsWithChildren<P> | |
| 引数 context | any | 省略可能 |
| 戻り値 | ReactElement<any, any> または null |
ここに出てくる PropsWithChildren という型を調べてみると以下のようになっている。
...
type PropsWithChildren<P> = P & { children?: ReactNode };
...
この & については後述するが、要はこの PropsWithChildren<P> という型は、ユーザがコンポーネントに渡した引数の型 P のプロパティと、children という名前の ReactNode 型のオブジェクトを収めたオブジェクトのプロパティ(つまり children そのもの)の両方を持つ型、ということになる。
例えば TSX で以下のような記述をすると、親コンポーネントである ParentCompo の Props として、ChildCompo が渡されるのだが、 children というのはこれのことである。
<ParentCompo foo="bar">
<ChildCompo />
</ParentCompo>
このコードの foo は型引数 P で {foo} の形で渡されるので、つまり PropsWithChildren はこの {foo} と {children} をマージした型 {foo, children} という意味になり、ParentCompo のアトリビュートとして渡した foo と、子要素として渡した ChildCompo を上手くマージしてくれるという意味だ。
5.1.16. TypeScript の共用型と交差型
上記 PropsWithChildren の定義で使われていた、ビット演算子でお馴染みの & は、TypeScript の 交差型 を定義するために利用されるものだ。 交差型は A & B で表され「オブジェクト A, B 双方のプロパティを持つオブジェクト」という意味になるが、TypeScript にはこれと対の | で表される 共用型 もある。共用型は A | B で定義され、「A または B のいずれかの型」であることを示すものだ。この共用型の方が用途が多く、今回のプログラムの中でもいろいろな箇所で使っている。
例えば、 Rules.ts 内では駒を表現する型を type Piece = "O" | "X" と定義しており、これは "O" か "X" のいずれかしか許容しない型という意味になり、 Square.ts 内に書かれたアクセサ get piece(): Piece | null {...} は、このアクセサが Piece 型のオブジェクトか null のいずれかを返すということを示している。
TypeScript のこの型チェックは厳格で、コーディングの際に非常に重宝した。
例えば戻り値が string 型の関数を書いていて、もしそのコードが undefined を返す可能性を持っていれば、TypeScript のトランスパイラはきちんとそのことを示唆してくれる。これにより、undefined を返さないコードを書くか、戻り値を string | undefined とするかのどちらかに書き直すことができる。また、null を返す可能性がある関数を呼び出した場合などに、チェックを怠ったままその戻り値を使おうとすると、そのことを示唆してくれるんだ。TypeScript のこの機能はコードの品質を上げるのにとても役立ってくれそうだ。
一方で、TypeScript のコードを書いていてうんざりしたのが、メソッド内でプロパティにアクセスする際に必ず this を書かなければならないことだ。これはもう最悪で、タイプ量は増えるわコードは横に長くなるわで、まるで this を書くために生まれてきたのではないかという気にさせられる。
5.1.17. スタイルシート (index.css)
最後にこの三目並べのスタイルシートのコードを以下に示す。
body {
font : 14px "Century Gothic", Futura, sans-serif;
margin: 20px;
}
.title { /* アプリ全体のヘッダ */
color : steelblue;
font-size : 20px;
font-weight: bold;
text-align : center;
width : 216px;
}
src/index.css(続き)
/* --------------------------- <GameCompo> ゲーム・コンポ --------- */
.game {
display : flex;
flex-direction: row;
}
/* --------------------------- <BoardCompo> 盤面コンポ ------------ */
[class^="bd-head"] { /* ヘッダ 共通項 */
background : #fff;
border : 1px solid #fff;
color : #777;
float : left;
font-size : 12px;
font-weight : bold;
list-style : none;
margin-right: -1px;
margin-top : -1px;
padding : 0px;
text-align : center;
}
.bd-head-org { /* ヘッダ 左上隅 */
height : 18px;
line-height: 18px;
width : 12px;
}
.bd-head-top { /* ヘッダ a/b/c */
height : 18px;
line-height: 18px;
width : 34px;
}
.bd-head-left { /* ヘッダ 1/2/3 */
height : 34px;
line-height: 34px;
width : 12px;
}
/* --------------------------- <SquareCompo> マス目コンポ --------- */
[class^="square"] { /* 共通項 */
background : #fff;
border : 1px solid #999;
float : left;
font-size : 24px;
font-weight : bold;
height : 34px;
line-height : 34px;
margin-right: -1px;
margin-top : -1px;
padding : 0px;
text-align : center;
width : 34px;
}
[class^="square"]:focus { /* 共通項 フォーカス時 */
background: #ddd;
outline : 0px;
}
.square { /* ビンゴライン上ではない */
color: black;
}
.square-bingo { /* ビンゴライン上 */
color: darkred;
}
/* --------------------------- <StatusCompo> ステータス・コンポ --- */
.status {
color : #555;
margin-left: 10px;
text-align : center;
}
/* --------------------------- <HistoryCompo> 履歴コンポ ---------- */
.history {
margin-left: 20px;
}
.hs-header { /* ヘッダ */
background : white;
border : 0px;
color : #555;
height : 18px;
line-height: 16px;
text-align : center;
}
.hs-order { /* 並び順ボタン(▼▲昇降トグル) */
font-size : 9px;
height : 14px;
margin-left: 10px;
padding : 0px;
width : 14px;
}
.hs-body { /* ボディ */
border : 1px solid #999;
display : flex;
flex-direction: column;
/*height :172px;*/
padding : 0px;
width : 90px;
}
[class^="step"] { /* 履歴ステップ(履歴行) 共通項 */
border : 0px;
color : #555;
outline : 0px;
width : 100%;
text-align: left;
}
.step { /* 履歴ステップ 選択中でない */
background: white;
}
.step-curr { /* 履歴ステップ 選択中 */
background : lightblue;
font-weight: bold;
}
5.1.18. この後に学ぶこと
React に関してこの後に学ぶとしたら以下のようなものだろうか。
- React Router
現在の Web アプリケーションは SPA が主流になってきているようなので、クライアントモジュール側でブラウザのアドレスバーを触りあたかもページ遷移しているように見せたい、というような要求もそれなりに出てくるだろうと思われる。 - Redux による状態の管理
複雑な状態管理をチームで開発するようなケースでは縦割りができる Redux などの利用は重宝するであろう。
5.2. Bootstrap
お前ももうすぐ知ることになるだろうが、アップルに返り咲いたジョブズが iMac 成功後の 2001 年に iPod という製品を市場に投入したんだ。
これは 1000 曲分の音楽を持ち歩ける、言ってみればハードディスク付きのウォークマンだ。ジョブズがプレゼンで Sarah McLachlan の Building A Mystery を流した時こそ、発表会場に集まった報道陣はさほど興味を示さなかったようだが、この製品と iTunes という音楽配信サービスが、その後、音楽産業の構造を一変させることになるんだ。
そして 2007 年に iPod Touch という、多点検出のタッチスクリーンとフラッシュメモリによる 2 次記憶装置を搭載したデバイスが登場、更に翌年、これに通信機能を搭載した iPhone 3G が発売され、その後、日本の通信業界も様変わりすることになったんだ。
現代は、この i-mode 端末の進化版とも呼ぶべきガジェットを誰もが持ち歩く時代だ。そしてデバイスの進化と並行して、黎明期は散々だった HTML も標準化が進み、今じゃ 1 本のソースコードで PC にもモバイルにも対応する「レスポンシブ Web デザイン」という手法での開発が一般的になった。
そして、そのレスポンシブに対応した CSS フレームワークというものが登場し、その中ではおそらくこの Bootstrap がデファクトスタンダードと言える存在だろう。
5.2.1. Bootstrap の導入
Bootstrap の実体は CSS と JavaScript のファイルだから、配布元からダウンロードして、それを利用するコンテンツと一緒にサーバに放り込んでおけばいいんだが、CDN (Content Delivery Network) からも配信されているから、今回は主体となるコンテンツにそこへのリンクを貼る手軽な方法で導入することとする。
Bootstrap のテンプレートは以下のとおりで、必要とするスタイルとスクリプトへのリンクだけが書かれた非常にシンプルなものだ。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset ="utf-8">
<meta name ="viewport"
content ="width=device-width, initial-scale=1 shrink-to-fit=no">
<title>[Title]</title>
<!-- Bootstrap Core CSS -->
<link rel ="stylesheet"
href ="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css"
integrity ="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk"
crossorigin="anonymous">
</head>
<body>
<!--============================-->
<div>Template for Bootstrap 4</div>
<!--============================-->
<script src ="https://code.jquery.com/jquery-3.5.1.slim.min.js"
integrity ="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj"
crossorigin="anonymous"></script>
<script src ="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js"
integrity ="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo"
crossorigin="anonymous"></script>
<script src ="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/js/bootstrap.min.js"
integrity ="sha384-OgVRvuATP1z7JjHLkuOU7Xw704+h835Lr+6QL9UvYjZE3Ipu6Tp75j7Bh/kR0JKI"
crossorigin="anonymous"></script>
</body>
</html>
5.2.2. Grid system を試す
Bootstrap の大きな特徴は、ディスプレイ幅を 12 分割したグリッドで管理するレイアウトシステムだろう。 この Grid System はディスプレイサイズに応じた 5 段階の端末カテゴリに対応している。
簡単なサンプルを以下に示す。
(上記テンプレートに書いたヘッダとフッタは省略している)
<!--=================================-->
<div>Grid template for Bootstrap 4</div>
<!--=================================-->
<style type="text/css">
body {padding:20px; font: bold 14px sans-serif;}
.box1 {padding:10px; background :#213a49; color:#eceedc; border:0.5px solid #fff; text-align:center;}
.box2 {padding:10px; background :#a43e39; color:#eceedc; border:0.5px solid #fff; text-align:center;}
.tsp {padding:10px; background :#fff ; color:#fff;}
</style>
<div class="container-fluid">
<div class="row">
<div class="box1 col-md-12">.col-md-12</div>
</div>
<div class="row">
<div class="box2 col-md-1">.col-md-1</div>
<div class="box2 col-md-1">.col-md-1</div>
<div class="box2 col-md-2">.col-md-2</div>
<div class="box2 col-md-3">.col-md-3</div>
<div class="box2 col-md-5">.col-md-5</div>
</div>
<div class="row">
<div class="box1 col-md-2">.col-md-2</div>
</div>
<div class="row">
<div class="box2 col-md-4">.col-md-4</div>
</div>
<div class="row">
<div class="box1 col-md-7">.col-md-7</div>
</div>
<div class="row">
<div class="tsp col-md-7">.col-md-7</div>
<div class="box2 col-md-3">.col-md-3</div>
<div class="box2 col-md-2">.col-md-2</div>
</div>
<div class="row">
<div class="box1 col-md-1">1</div>
<div class="box1 col-md-1">2</div>
<div class="box1 col-md-1">3</div>
<div class="box1 col-md-1">4</div>
<div class="box1 col-md-1">5</div>
<div class="box1 col-md-1">6</div>
<div class="box1 col-md-1">7</div>
<div class="box1 col-md-1">8</div>
<div class="box1 col-md-1">9</div>
<div class="box1 col-md-1">10</div>
<div class="box1 col-md-1">11</div>
<div class="box1 col-md-1">12</div>
</div>
</div>
上記コードの PC での表示結果は以下のとおりだ。

そしてモバイル端末での表示結果は以下のとおりだ。

このように Grid system を使えば、端末サイズに応じたレイアウト切り替えを 1 つのソースコードで簡単に実現できるようになる。
そして、上記コードで利用している Bootstrap の機能(HTML 要素の class 属性で指定)は以下のとおりだ。
| 対象となる要素 | class | 補足 |
|---|---|---|
| グリッドのコンテナ | .container-fluid | ウィンドウの横幅に応じて流動的にレイアウトを変動させる。 |
| 行 | .row | 列となる子要素のコンテナ。 |
| 列 | .col-md- | 左記の md は、ウィンドウ幅が Medium (720px) 以上の場合にこの要素を「行」の中の「列」として表示するという意味(Medium 未満の場合は行の横幅一杯までこの列の幅を広げる)。 そしてこのプレフィクスの後に 1 ~ 12 の数値を付けて利用する。1 は列の横幅を 12 分の 1、2は 12 分の 2 にするという意味になる。 |
また、上記コードでは、列要素を「列」として表示するか横幅一杯まで広げるかの起点を Medium サイズとしたが、これ以外のサイズを起点とする場合は以下のプレフィクスを使う。
| class プレフィクス | カテゴリ | 横幅 |
|---|---|---|
| .col- | Extra small | 576px 未満(つまりすべて) |
| .col-sm- | Small | 576px 以上 |
| .col-md- | Medium | 768px 以上 |
| .col-lg- | Large | 992px 以上 |
| .col-xl- | Extra large | 1200px 以上 |
5.2.3. Navbar を試す
Bootstrap の機能でもう 1 つ重宝しそうなのがナビゲーションバーだ。
これを使うと、横幅の広いデスクトップ端末ではメニューアイテムを横に並べ、モバイル端末では縦に並べることができる。
ソースコードを以下に示す。
(テンプレートのヘッダおよびフッタは省略)
<!--===================================-->
<div>Navbar template for Bootstrap 4</div>
<!--===================================-->
<style type="text/css">
body {padding:20px;}
</style>
<nav class="navbar navbar-expand-lg navbar-light bg-light">
<a class="navbar-brand">
[Brand]
</a>
<button class ="navbar-toggler"
type ="button"
data-toggle ="collapse"
data-target ="#navbarSupportedContent"
aria-controls="navbarSupportedContent"
aria-expanded="false"
aria-label ="Toggle navigation">
<span class="navbar-toggler-icon">
</span>
</button>
<div class="collapse navbar-collapse"
id ="navbarSupportedContent">
<ul class="navbar-nav mr-auto">
<li class ="nav-item active">
<a class="nav-link" href ="#">
Home
<span class="sr-only">
(current)
</span>
</a>
</li>
<li class ="nav-item">
<a class="nav-link" href ="#">
Link
</a>
</li>
<li class="nav-item dropdown">
<a class ="nav-link dropdown-toggle"
href ="#"
id ="navbarDropdown"
role ="button"
data-toggle ="dropdown"
aria-haspopup="true"
aria-expanded="false">
Dropdown
</a>
<div class ="dropdown-menu"
aria-labelledby="navbarDropdown">
<a class="dropdown-item" href="#">Action</a>
<a class="dropdown-item" href="#">Another action</a>
<div class="dropdown-divider"></div>
<a class="dropdown-item" href="#">Something else here</a>
</div>
</li>
<li class="nav-item">
<a class="nav-link disabled" href="#">Disabled</a>
</li>
</ul>
<form class="form-inline my-2 my-lg-0">
<input class ="form-control mr-sm-2"
type ="search"
placeholder="Search"
aria-label ="Search">
<button class="btn btn-outline-success my-2 my-sm-0"
type ="submit">
Search
</button>
</form>
</div>
</nav>
そして、PC とモバイルデバイスでの表示結果は以下のとおりだ。
このようにシンプルなコードでレスポンシブに対応することができるのだが、Navibar については、HTML 要素のクラス属性を他の属性と関連付ける必要があったり、複数のクラスを同時に指定する必要があったり、要素の親子同士でも関連づけが必要だったりと少々ややこしいので、表示イメージにコードを重ねて整理してみた。
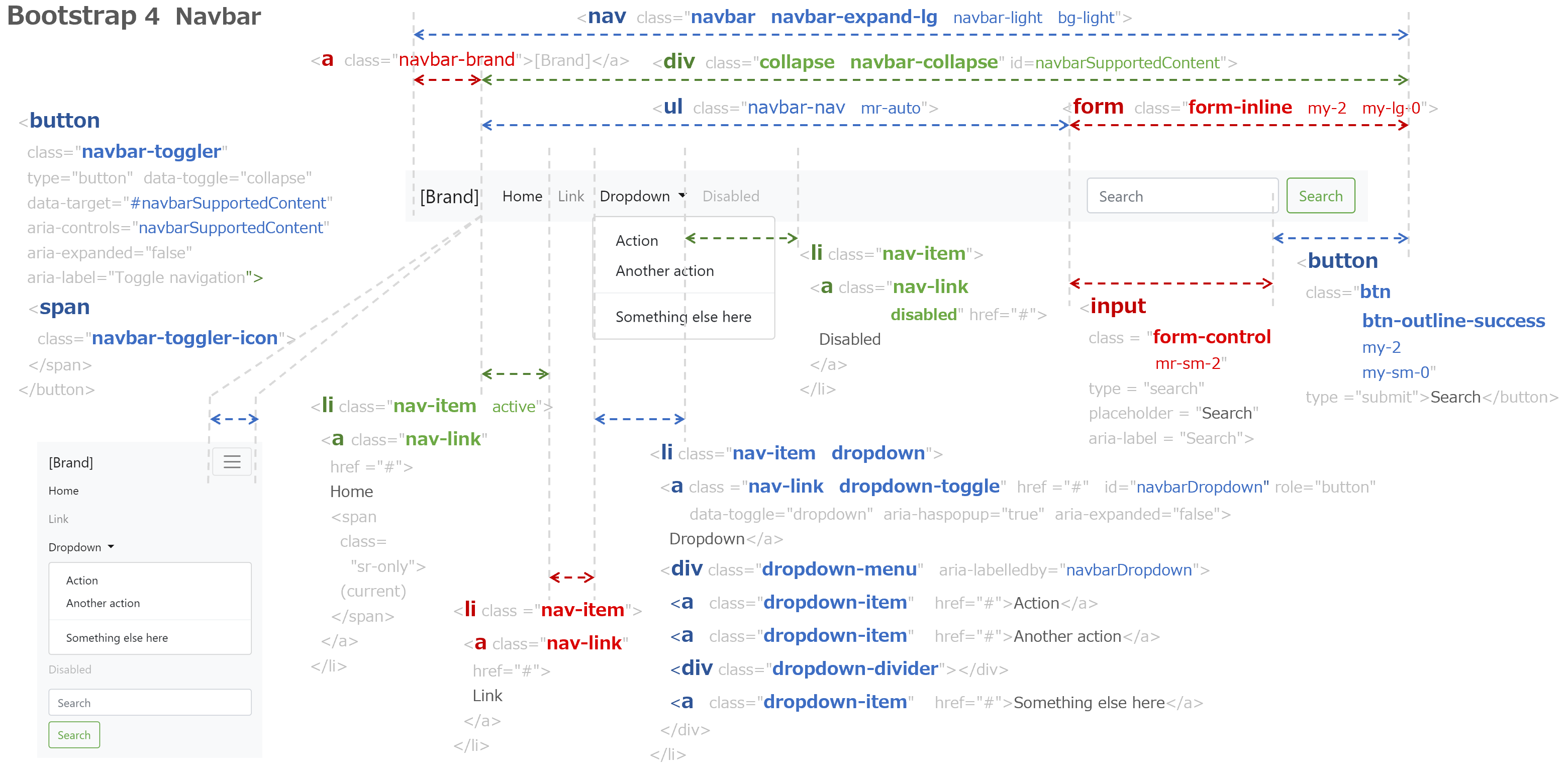
こうすれば詳細を掴みやすくはなるのだが、今度は逆に全体構成が分かりづらくなるため、別の角度からも整理してみる。
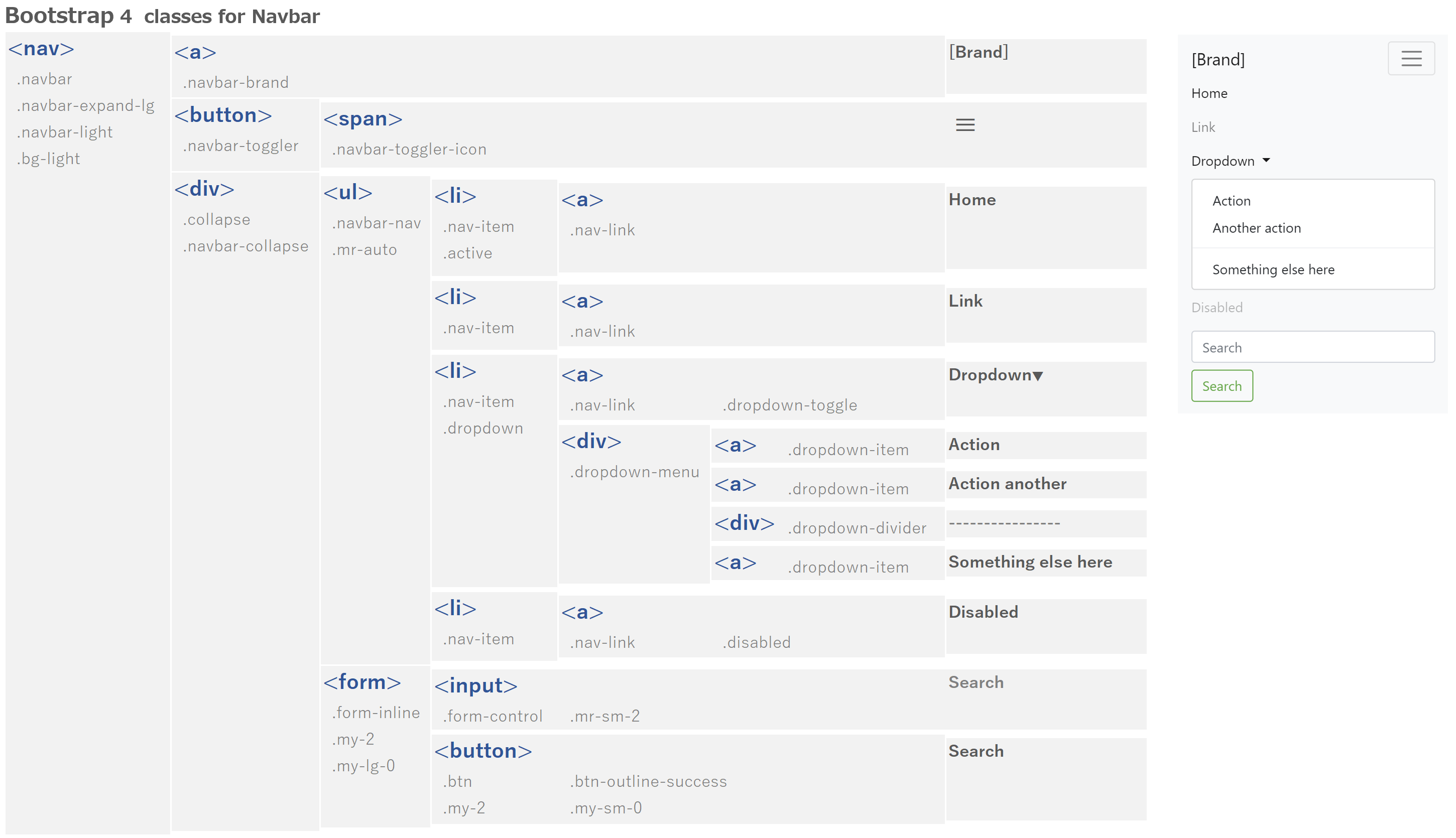
なるほど、木構造が見えてきた。
-
<nav> .navbar ナビゲーションバー全体
- <a> .navbrand ブランドロゴ
- <button> .navbar-toggler ハンバーガーメニューボタン
-
<div> .navbar-collapse 折り畳みメニュー全体
-
<ul> .navba-nav メニュー
-
<li> .nav-item メニューアイテム
- <a> .nav-link アンカーリンク
-
<li> .nav-item .dropdown ドロップダウンメニュー
- <a> .nav-link .dropdown-toggle ドロップダウンの見出し
-
<div> .dropdown-menu ドロップダウン本体
- <a> .dropdown-item ドロップダウンのアイテム
- <div> .dropdown-divider 仕切り線
-
<li> .nav-item メニューアイテム
-
<form> .form-inline 検索フォーム
- <input> .form-control 入力フィールド
- <button> .btn 検索ボタン
-
<ul> .navba-nav メニュー
これらのテンプレートはきっと色々な場面で使いまわせるだろう。
5.3. Font Awesome
Font Awesome はピクトグラムやアイコンなどのシンプルな絵文字をフォントとして提供するサービスだ。
フォントの本来の利用目的からはズレているかもしれないが、アウトラインフォントは技術的にはベクター画像の一種だし、特にビューアなどを用意しなくとも既知の技術をそのまま利用できるということもあり、Font Awesome は文字コードが振られた統一感のある洒落た画像として便利に使うことができる。
5.3.1. 導入
Font Awesome 公式 でユーザ登録すれば、フリープランでも 1,500 以上のアイコンを利用することができる。
5.3.2. Font Awesome を試す
ユーザ登録をするとキットが作成されるので、例えば Web での利用であれば html ファイルの head 要素内に、この Kit ID を含めた script 要素を書くことでアイコンが利用できるようになる。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset ="utf-8">
<title>[Title]</title>
<!-- Font Awesome Script -->
<script src ="https://kit.fontawesome.com/YourKitName.js"
crossorigin="anonymous"></script>
<body>
<h1>Font Awesome 6</h1>
<!-- The i Elements -->
<div style="font-size:2em">
<i class="fab fa-font-awesome" style="color:royalblue"></i>
<span style="color:#555"> The <i> Element</span>
<i class="fas fa-arrow-left" style="color:seagreen" ></i>
</div>
<!-- CSS Pseudo-Elements -->
<style>
.icon::before { content:"\f2b4"; font-family:"Font Awesome 5 Brands"; font-weight:400; color:royalblue; }
.arrow::after { content:"\f060"; font-family:"Font Awesome 5 Free" ; font-weight:900; color:seagreen ; }
</style>
<div style="font-size:2em">
<span class="icon arrow" style="color:#555"> Pseudo-Element </span>
</div>
</body>
</html>
上記コードの YourKitName.js は Font Awesome で発行されたものを張り付ける。
また、表示方法は、疑似要素を使う方法と i 要素などを使う方法の 2 種類あるが、上記コードでは両方とも使っている。
この html をブラウザで表示すると以下のようになる。

5.3.3. Font Awesome Animation を試す
Font Awesome 公式はシンプルなアニメーションを提供しているが、font-awesome-animation というサードパーティからもっと凝ったアニメーションが提供されているので、これを使ってみる。
template_fontawesome6_animation.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset ="utf-8">
<meta name ="viewport"
content ="width=device-width, initial-scale=1 shrink-to-fit=no">
<title>[Title]</title>
<!-- Font Awesome Script -->
<script src ="https://kit.fontawesome.com/YourKitName.js"
crossorigin="anonymous"></script>
<!-- Font Awesome Animation CSS -->
<link rel ="stylesheet"
href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome-animation/0.3.0/font-awesome-animation.min.css">
<body>
<!--=============================-->
<h1>Template for Font Awesome 6</h1>
<!--=============================-->
<span class="fa-3x">
<i class="fas fa-fan faa-spin animated"></i>Animation
</span>
</body>
</html>
ブラウザでの表示結果は以下のとおりだ。

5.3.4. いろいろなスタイリングを試す
Font Awesome が提供する機能は宣言的に利用することができるので、使う上で難しいことは特にない。

上記 Sizing icons のコードは以下のとおりである。
<i class="fas fa-football-ball fa-xs" ></i>
<i class="fas fa-football-ball fa-sm" ></i>
<i class="fas fa-football-ball fa-lg" ></i>
<i class="fas fa-football-ball fa-2x" ></i>
<i class="fas fa-football-ball fa-3x" ></i>
<i class="fas fa-football-ball fa-5x" ></i>
<i class="fas fa-football-ball fa-7x" ></i>
<i class="fas fa-football-ball fa-10x"></i>
上記 Icons in a List のコードは以下のとおりである。
<ul class="fa-ul">
<li><span class="fa-li"><i class="fas fa-check-square" ></i></span>List icons can </li>
<li><span class="fa-li"><i class="fas fa-check-square" ></i></span>be used to </li>
<li><span class="fa-li"><i class="fas fa-spinner fa-pulse"></i></span>replace bullets</li>
<li><span class="fa-li"><i class="far fa-square" ></i></span>in lists </li>
</ul>
上記 Rotating icons のコードは以下のとおりである。
<i class="far fa-fw fa-paper-plane"></i> normal<br>
<i class="far fa-fw fa-paper-plane fa-rotate-90" ></i> rotate 90° <br>
<i class="far fa-fw fa-paper-plane fa-rotate-180" ></i> rotate 180° <br>
<i class="far fa-fw fa-paper-plane fa-rotate-270" ></i> rotate 270° <br>
<i class="far fa-fw fa-paper-plane fa-flip-horizontal"></i> frip horizontal<br>
<i class="far fa-fw fa-paper-plane fa-flip-vertical" ></i> frip vertical <br>
<i class="far fa-fw fa-paper-plane fa-flip-both" ></i> frip both <br>
上記 Animating icons のコードは以下のとおりである。
<div class="fa-2x">
<i class="fas fa-spinner fa-spin" ></i>
<i class="fas fa-circle-notch fa-spin" ></i>
<i class="fas fa-sync fa-spin" ></i>
<i class="fas fa-cog fa-spin" ></i>
<i class="fas fa-spinner fa-pulse"></i>
</div>
上記 Stacked icons のコードは以下のとおりである。
<span class="fa-stack">
<i class="far fa-circle fa-stack-2x"></i>
</span>
<span class="fa-stack">
<i class="far fa-circle fa-stack-2x"></i>
<i class="fas fa-flag fa-stack-1x"></i>
</span>
<span class="fa-stack">
<i class="fas fa-circle fa-stack-2x"></i>
<i class="fas fa-flag fa-stack-1x fa-inverse" ></i>
</span>
<span class="fa-stack">
<i class="fas fa-square fa-stack-2x"></i>
<i class="fas fa-spinner fa-stack-1x fa-inverse fa-spin" ></i>
</span>
<span class="fa-stack">
<i class="fas fa-car fa-stack-1x"></i>
<i class="fas fa-ban fa-stack-2x" style="color:tomato"></i>
</span>
<span class="fa-stack">
<i class="fas fa-mobile-alt fa-stack-1x"></i>
<i class="fas fa-ban fa-stack-2x" style="color:tomato"></i>
</span>
上記 Font Awesome Animation の使用例は以下のとおりである。
<table>
<tr>
<td>
<i class="fas fa-compact-disc faa-spin animated"></i> spin <br>
</td>
<td>
<i class="fas fa-wrench faa-wrench animated"></i> wrench <br>
<i class="fas fa-wine-glass-alt faa-shake animated"></i> shake <br>
<i class="fas fa-laugh faa-tada animated"></i> tada <br>
<i class="fas fa-bell faa-ring animated"></i> ring <br>
</td>
<td>
<i class="fas fa-futbol faa-bounce animated"></i> bounce <br>
<i class="fas fa-cloud faa-float animated"></i> float <br>
<i class="fas fa-dog faa-vertical animated"></i> vertical <br>
</td>
<td>
<i class="fas fa-exclamation faa-flash animated"></i> flash <br>
<i class="fas fa-heartbeat faa-pulse animated"></i> pulse <br>
<i class="fas fa-car faa-burst animated"></i> burst <br>
</td>
<td>
<i class="fas fa-arrow-right faa-horizontal animated"></i> horizontal <br>
<i class="fas fa-biking faa-passing animated"></i> passing <br>
<i class="fas fa-swimmer faa-passing-reverse animated"></i> passing-reverse<br>
</td>
</tr>
</table>
Font Awesome は、今後、いろいろな場面で使っていくことになるだろう。
おわりに
ある事情により人生の転換点を迎え、エンジニアに返り咲こうと思い立ったこの俺が、この 20 年間の空白を埋めるべくまず最初にやったことが Google を使った情報収集だった。
だがネットは便利だが情報が溢れすぎている。そこはマーケティングのためのバズワードや、特定の立ち位置における個人や組織人の主張で溢れかえっており、俺はその洪水に溺れそうになるという、まあ考えてみればごく当たり前の状況に陥った。
ネットという広大な海で、
素敵な肩書きを持つ 1000 人の著者が 1000 種類の主張をし、
言葉巧みな 1000 個の記事が 1000 種類のお薦めを並べていた。
胡散臭いバッタもんと最高の掘り出し物が濫立するその光景は、まるでドキュメンタリー番組で見る中東諸国のバザールのようだった。
そしているうちに、ふと気づいたことは、どんなに評判の良い情報あっても、自分で噛みしめみてそれを味わうことができなければ、それは単なる情報のかたまりにすぎず、それは決して自分の血や肉にはならないということだ。
そこで俺はかつての 20 年前と同じように自分の直観を信じてみることにした。
自分に一番関心があるのは自分自身なわけだし、その情報をインプットするために割いた時間に対して責任を取ってくれるのも、結局のところ自分しかいないのだ。
そう思ってからは早かった。直観を頼りに気の向くままに自分好みの情報を集めていった。
俺は20年分の遅れを取り戻すべく、そうやって気になった分野について、その表面を手あたり次第すくい取ってみた。
この記事はそうやってたどり着いた最初の着地点だ。
そして、ここまでいろいろ書いてきたが、この 20 年間に起こったことのうち、俺やお前にとって重要な出来事でまだ伝えていなかったことが 2 つある。
- 一つは 2011 年に R.E.M. が解散したことで、
- もう一つが 2018 年に Jerry こと Gerald M Weinberg 氏が亡くなったことだ。
R.E.M. については新しい楽曲が聴けなくなったことは残念だが、最近になって Peter Buck と Mike Mills がなんとあの Bill Berry とライブで共演したり、Michael Stipe がソロ活動を始めたというニュースが飛び込んできたりしている。だからまあ寂しさはない。
Weinberg 氏については、おそらく彼の影響を最も受けているであろう我々の世代こそが、彼の残した言葉をもっともっと後世に伝えていかなければならないと感じているところだ。
よし。これで言いたいことはすべて言った。
さあ俺はこれを足掛かりにしてこれからの人生を築いていくことになるだろう。
俺が果たして蛙のように華麗に跳躍できるかどうか
どうかそこから暖かく見守っていてほしい。
じゃあな。
またどこかで会おう。