はじめに
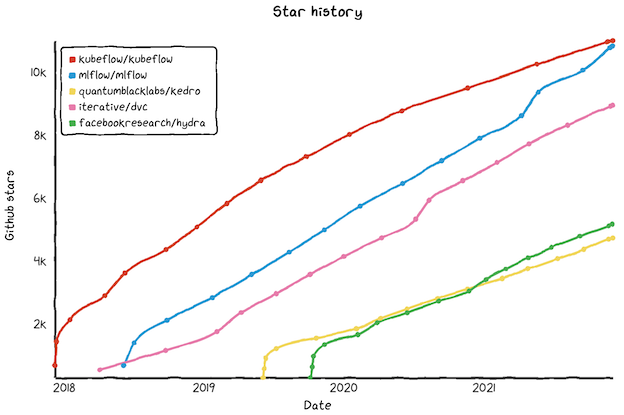
MLflowは機械学習のライフサイクル管理(MLOps)を目的としたライブラリで、主に実験管理用途で使用されることの多い注目度の高い(GitHubのStar1万超え)ツールです。
※水色がMLflowのStar数推移
一方で、MLflowの環境構築は機械学習エンジニアにとって門外漢のインフラの知識が求められるため、その活用において鬼門とも言える存在です。
本記事では、インフラの深い知識がなくともMLflowの環境構築ができるよう、公式ドキュメントのチュートリアル(4つのシナリオ)をベースに、分かりやすさ重視で解説していきたいと思います。
本記事の注意点
※本記事は環境構築に絞った内容となっております。まずはMLflow全般を解説した以下の記事をご参照ください
MLflow環境構築の概要
MLflowによる実験管理を実現するためには、以下の4種類の機構を整備する必要があります(実験管理用途ではレジストリサーバはあまり使わないので、残りの3種類が特に重要)
| 名称 | 機能 | 指定できるサービス |
|---|---|---|
| トラッキングサーバ | トラッキングの制御と結果のUI表示 | ホストPC, リモートサーバ, クラウド(EC2等) |
| バックエンド | ParametersやMetrics等の主要データを保存 | ファイルストレージ, DB(詳細はこちら参照) |
| Artifactストレージ | Artifact(テーブルデータや画像等の非構造化データ)を保存する | ファイルストレージ, FTPサーバ, クラウド(S3等), etc.(詳細はこちら参照) |
| レジストリサーバ | モデルとバージョン情報を保持する(MLflow Model Registryの設定が必要) | ホストPC, リモートサーバ, クラウド(EC2等) |
※バックエンドとArtifactストレージの指定可能サービスは上記リンクを参照ください。
公式ドキュメントでは、以下の4種類の方法(シナリオ)が紹介されています。
| シナリオ | 英名 | トラッキングサーバ | バックエンド | Artifactストレージ |
|---|---|---|---|---|
| 1 | MLflow on localhost | ローカルに自動生成 | ローカルストレージ | ローカルストレージ |
| 2 | MLFlow on localhost with SQLite | ローカルに自動生成 | ローカルDB | ローカルストレージ |
| 3 | MLflow on localhost with Tracking Server | ローカルに手動ホスティング | ローカルDB or ストレージ | ローカルストレージ |
| 4 | MLflow with remote Tracking Server, backend and artifact stores | リモートサーバ | リモートDB | リモートストレージ |
おすすめは個人開発ならシナリオ2、チーム開発ならシナリオ4です(理由は後述)
それぞれの概要と環境構築に関して解説します。
なお、参考としてサンプルコードを以下のGitHubにアップロードしております
有用だと思われた方は、Star頂けると励みになります!
シナリオ1: MLflow on localhost
全ての情報をローカルのストレージに保存します。
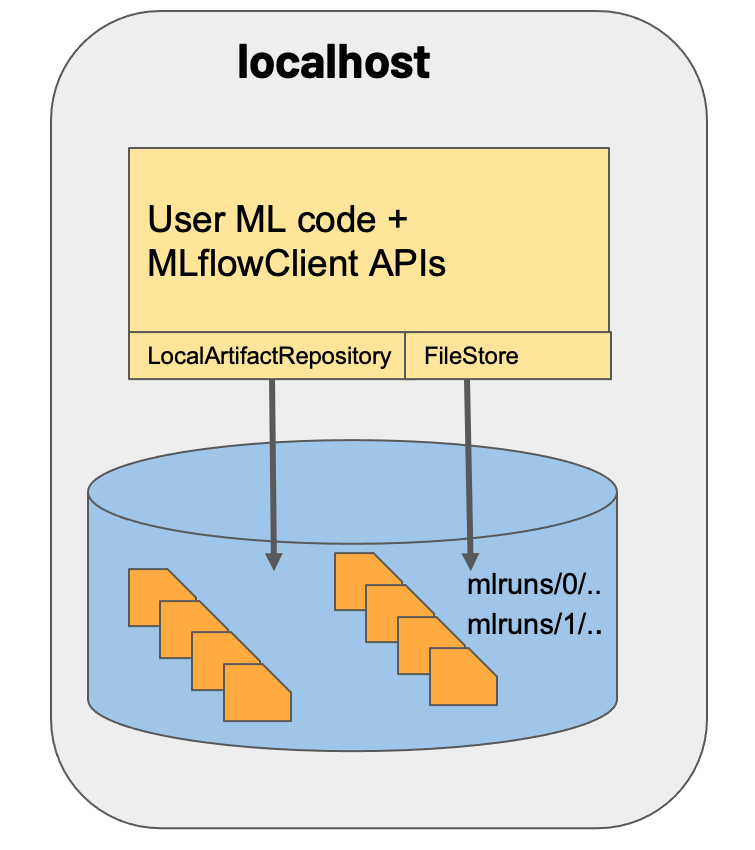
デフォルト設定(特別な設定をしない場合)ではこの方法が採用され、mlflowを実行したフォルダの直下に「mlruns」フォルダが作成され、その中に関連ファイルが一括保存されます。
保存先を取得したい場合
現在のデータ保存先はget_tracking_uri()(トラッキングサーバの場所)、get_registry_uri()(レジストリサーバの場所)、get_artifact_uri()(Artifactストレージの場所)の各種メソッドで取得できます
import mlflow
# トラッキングサーバの場所
tracking_uri = mlflow.get_tracking_uri()
print('Current tracking uri: {}'.format(tracking_uri))
# レジストリサーバの場所
mr_uri = mlflow.get_registry_uri()
print('Current model registry uri: {}'.format(mr_uri))
# Artifactストレージの場所
artifact_uri = mlflow.get_artifact_uri()
print('Current artifact uri: {}'.format(artifact_uri))
Current tracking uri: file:///[実行フォルダの場所]/mlruns
Current model registry uri: file:///[実行フォルダの場所]/mlruns
Current artifact uri: file:///[実行フォルダの場所]/mlruns/[エクスペリメント毎のフォルダ]/[Run ID毎のフォルダ]/artifacts
デフォルトでは実行フォルダ直下の「mlruns」フォルダ内にトラッキングサーバとレジストリサーバが生成され、Artifactストレージは「mlruns」内に生成されたエクスペリメントおよびRunごとのフォルダが使用されることが分かります
保存先を明示的に指定したい場合
特に保存先を指定しない場合、前述のように実行フォルダ直下の「mlruns」フォルダ内にデータが保存されますが、「トラッキングサーバ(バックエンド)の場所」「レジストリサーバの場所」「Artifactストレージの場所」を明示的に指定することもできます(Artifactストレージの場所はエクスペリメント作成時に指定するため、別記事で解説します)
import mlflow
# トラッキングサーバの場所を指定
TRACKING_URI= 'トラッキングサーバのパス/mlruns'
mlflow.set_tracking_uri(TRACKING_URI)
なお、パス指定時は以下に注意して下さい
・トラッキングサーバのパスの最後のフォルダ名は「mlruns」とする
・絶対パス指定時は、file:///を先頭に付与してもしなくとも良い(例:「C:\Users\hoge」にトラッキングサーバを作成したい時は、TRACKING_URIに'file:///C:\Users\hoge\mlruns'または'C:\Users\hoge'と指定する)
・Artifactストレージのパスは絶対パスで指定(相対パスだとトラッキングサーバからの紐づけがうまくいかない)
・Artifactストレージのパスは、file:///を先頭に付与しない
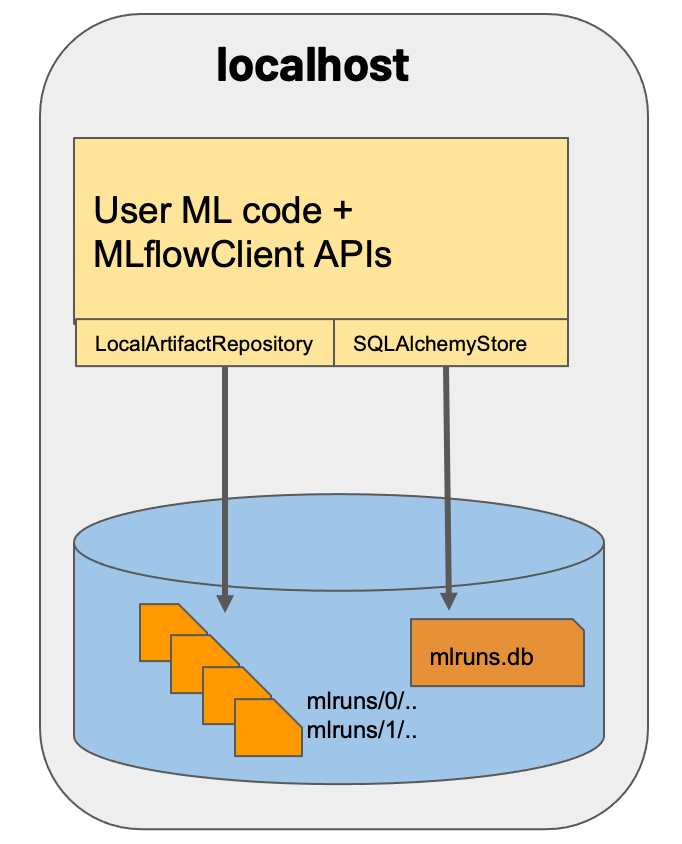
シナリオ2: MLFlow on localhost with SQLite
個人開発におすすめの構成です(理由は後述)
シナリオ1と近い構成ですが、バックエンドにDBを使用します。DBはSQLAlchemyに対応していれば何でもOK(Postgre、MySQL、SQLサーバー等メジャーどころのRDBであればOK)ですが、ここではインストール不要で使用が簡単なSQLiteを例に紹介します
SQLite可視化ツールのインストール
SQLite自体はPython標準で組み込まれていますが、DBの可視化が出来た方が作業が捗るので、可視化ツールをインストールします。選択肢はいくつかありますが、以下のDB Browser for SQLiteが便利です。
DBファイルの生成
SQLiteは一般的なRDBMSと異なり、DBをファイル形式で保持します。
Pythonの標準ライブラリsqlite3を使用してバックエンドとして使用するDBファイル「mlruns.db」を作成します
import mlflow
import sqlite3
import os
DB_PATH= 'トラッキングサーバのパス/mlruns.db'
os.makedirs(os.path.dirname(DB_PATH), exist_ok=True) # 親ディレクトリなければ作成
conn = sqlite3.connect(DB_PATH) # バックエンド用DBを作成
トラッキングサーバ(バックエンド)の場所を指定
トラッキング実行時には、上記で作成したDBファイルをtracking_uriに指定する必要があります。
import mlflow
# トラッキングサーバの(バックエンドの)場所を指定
tracking_uri = f'sqlite:///{DB_PATH}'
mlflow.set_tracking_uri(tracking_uri)
トラッキングサーバの場所は、作成したmlruns.dbファイルのパスに対してsqlite:///を先頭に付加して指定します(例:「C:\Users\hoge\mlruns.db」のとき、tracking_uriに'sqlite:///C:\Users\hoge\mlruns.db'と指定する)
(参考:SQLAlchemyにおけるSQLite .dbファイルへのパスの通し方)
シナリオ3: MLflow on localhost with Tracking Server
この方法ではトラッキングサーバとバックエンドを、ローカル内に別々に立ち上げます。
モジュールの独立性が向上するので、複数プロジェクトでのトラッキングサーバの共用、ひいては実験管理の一括化が進んで管理がはかどります。
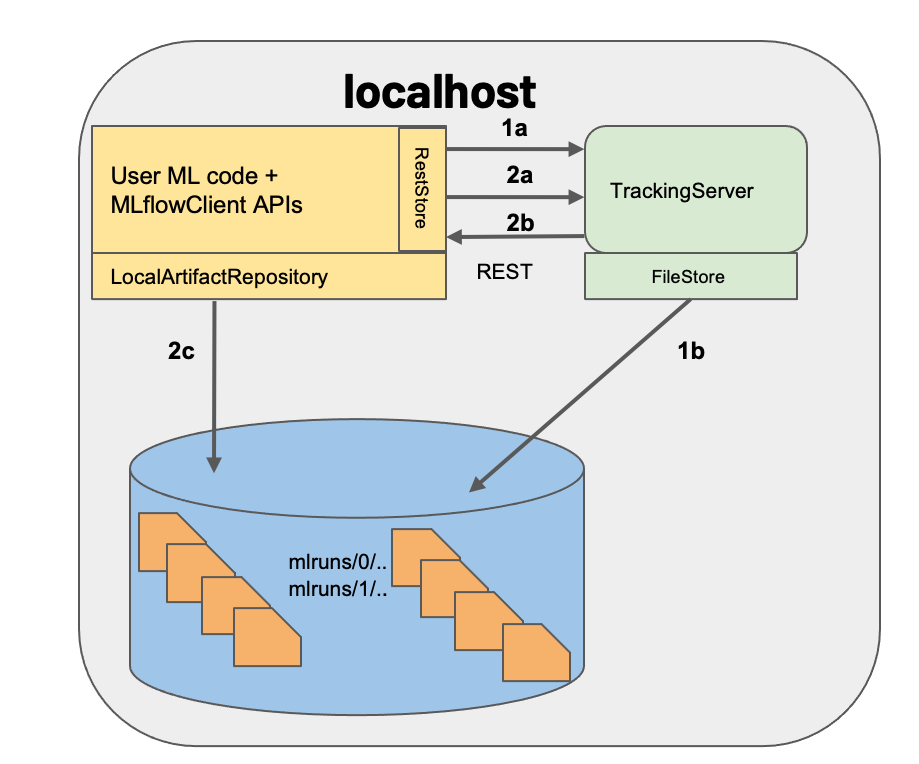
上図ではバックエンドにファイルストレージを使用していますが、本記事では環境のポータビリティ向上のためDockerとDBを使用する方法を紹介します
・本記事で紹介するDocker構成
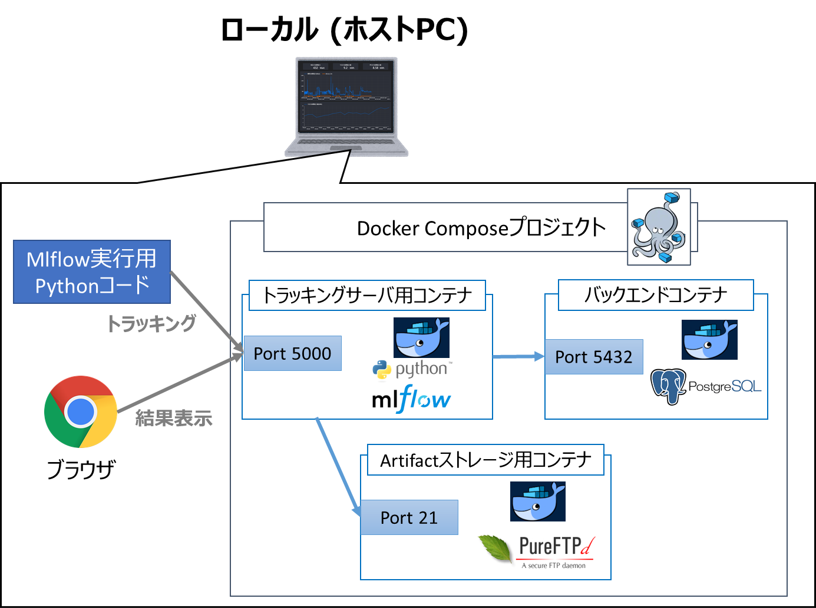
使用するコンテナの概要を下記します(一部のみ抜粋、詳細は後述)
| 名称 | コンテナの概要 |
|---|---|
| トラッキングサーバ | PythonイメージをベースにDockerfileでMLflow等必要パッケージをインストール |
| バックエンド | PostgreSQLイメージをそのまま使用(DBサーバ) |
| Artifactストレージ | pure-ftpdイメージをそのまま使用 (FTPサーバ) |
・フォルダ構成
コンテナの立ち上げは以下のようなフォルダ構成でDockerfile、docker-compose.yaml、.envを配置することで実現します。
├─tracking_server
│ └──Dockerfile
├─docker-compose.yaml
├─.env
│
├─db_server(DBコンテナとのファイル共有用空フォルダ)
└─ftp(Artifactストレージ用FTPコンテナとのファイル共有用空フォルダ)
以下で立ち上げの詳細方法を解説します。
・WSL2とDockerの導入
Windowsの場合はDockerを使用するために、WSL2 (Windows Subsystem for Linux 2)とDocker Dektopを導入します。
インストール法は以下を参照ください(「②Docker Desktopのインストール」まで完了させる)
※2022年2月よりDocker Desktopは従業員数250人以上または売上10億円以上の企業において有償化されます。有償化を回避したい方は以下の方法でインストールしてください
・トラッキングサーバ用のDockerイメージ作成
トラッキングサーバ用のDockerイメージは、Python公式のイメージを使用します。
こちらの記事で紹介したように、Pythonのイメージには主にbuster(パッケージは充実しているがサイズが大きい)とslim-buster(パッケージは最小限だがサイズが小さい)の2種類があり、mlflowやpsycopg2(Postogreの利用に必要)のインストールにはbusterのパッケージが必要となります。
Python Dockerイメージのタグの例(Docker Hubより)
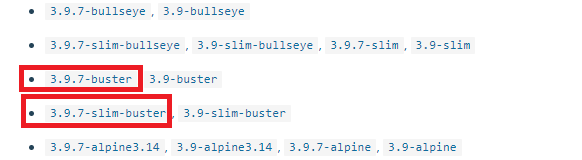
一方でbusterはイメージサイズが大きいため、生成されるコンテナの起動速度が遅くなります。今回の用途ではサクッと起動してトラッキングしたいので、イメージのサイズはなるべく小さくしたいです。
そこで今回、busterでインストールしたパッケージから必要部分だけをslim-busterにコピーする、マルチステージビルドという方法でイメージを作成します。
※マルチステージビルドとは?
マルチステージビルドとは、複数のイメージを使って1つのイメージをビルドしてコンテナを軽量化する方法で、前述のように
「必要パッケージの揃った大きなイメージでライブラリをインストールし、必要なフォルダのみを小さなイメージにコピーし、小さなイメージの方を最終的に使用する」
という方法をとることが多いです(大きなイメージはコピーが終わったら捨てる)
Dockerfileの記述
このマルチステージビルドを実現するため、今回は以下のようなDockerfile(イメージのビルド時に実行する処理を一括記述したファイル)を作成します。
# builder for installing python packages
FROM python:3.9.7-buster as builder
# install mlflow and psycopg2
RUN pip install \
mlflow \
psycopg2
# main image
FROM python:3.9.7-slim-buster
# copy python packages
COPY --from=builder /usr/local/lib/python3.9/site-packages /usr/local/lib/python3.9/site-packages
# copy mlflow package
COPY --from=builder /usr/local/bin/mlflow /usr/local/bin/mlflow
# copy linux packages for Postgres
COPY --from=builder /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu
COPY --from=builder /lib/x86_64-linux-gnu /lib/x86_64-linux-gnu
# copy gunicorn package
COPY --from=builder /usr/local/bin/gunicorn /usr/local/bin/gunicorn
# open port 5000
EXPOSE 5000
# set environment variables
ARG POSTGRES_USER
ARG POSTGRES_PASSWORD
ARG DB_HOST
ARG DB_NAME
ARG DEFAULT_ARTIFACT_ROOT
ENV POSTGRES_USER=${POSTGRES_USER}
ENV POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
ENV DB_HOST=${DB_HOST}
ENV DB_NAME=${DB_NAME}
ENV DEFAULT_ARTIFACT_ROOT=${DEFAULT_ARTIFACT_ROOT}
# Start mlflow server
CMD mlflow server \
--host 0.0.0.0 \
--port 5000 \
--backend-store-uri postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${DB_HOST}:5432/${DB_NAME} \
--default-artifact-root ${DEFAULT_ARTIFACT_ROOT}
長いですが、重要(理解せずに使うとハマりやすい部分)なので細かく解説します
まず、本Dockerfileは#main imageのコメントを境に、上側がbuster(インストール用の大きなイメージ)を、下側がslim-buster(最終的に使用するベースとなる小さなイメージ)に対する処理となります。
FROM python:3.9.7-buster as builder
の部分でbusterのイメージを読み出し、
RUN pip install \
mlflow \
psycopg2
の部分でトラッキングに必要なMLflowとpsycopg2ライブラリをインストールします。
そして
FROM python:3.9.7-slim-buster
の部分で最終的に使用するベースとするslim-busterのイメージを読み出し、
# copy python packages
COPY --from=builder /usr/local/lib/python3.9/site-packages /usr/local/lib/python3.9/site-packages
# copy mlflow package
COPY --from=builder /usr/local/bin/mlflow /usr/local/bin/mlflow
# copy linux packages for postgres
COPY --from=builder /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu
COPY --from=builder /lib/x86_64-linux-gnu /lib/x86_64-linux-gnu
# copy gunicorn package
COPY --from=builder /usr/local/bin/gunicorn /usr/local/bin/gunicorn
でbusterからslim-busterへ必要なライブラリが含まれるフォルダをコピーします
上記でパッケージのインストールが完了するので、以降はトラッキングサーバの立ち上げに必要な処理となります。
EXPOSE 5000
で外部からサーバにアクセスするための5000番ポートを開放し、
ARG POSTGRES_USER
ARG POSTGRES_PASSWORD
ARG DB_HOST
ARG DB_NAME
ARG DEFAULT_ARTIFACT_ROOT
ENV POSTGRES_USER=${POSTGRES_USER}
ENV POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
ENV DB_HOST=${DB_HOST}
ENV DB_NAME=${DB_NAME}
ENV DEFAULT_ARTIFACT_ROOT=${DEFAULT_ARTIFACT_ROOT}
でdocker-compose.yamlから環境変数を受け取り(後述、主にPostgreDBのアカウント関係情報)、
CMD mlflow server \
--host 0.0.0.0 \
--port 5000 \
--backend-store-uri postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${DB_HOST}:5432/${DB_NAME} \
--default-artifact-root ${DEFAULT_ARTIFACT_ROOT}
でトラッキングサーバを立ち上げるコマンドを打っています
(--backend-store-uriはバックエンドDB=Postgreコンテナの場所を、--default-artifact-rootはArtifactストレージの場所を指定しています)
※マルチステージビルドの効果
参考までに、マルチステージビルドした場合と、しなかった場合(busterイメージをそのまま使用)のイメージサイズを比較してみました
| ビルド方法 | イメージサイズ |
|---|---|
| マルチステージビルドあり(前述の方法) | 663MB |
マルチステージビルドなし(busterをそのまま使用) |
1170MB |
| マルチステージビルドでイメージサイズを約半分に減らせていることが分かります。 |
ちなみに、さらに軽量化するのであれば
# copy linux packages for postgre
COPY --from=builder /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu
COPY --from=builder /lib/x86_64-linux-gnu /lib/x86_64-linux-gnu
の部分をフォルダ丸ごとでなく必要パッケージに絞ってコピーすれば、サイズが小さくなるかと思います。
(あまりにパッケージ数が多すぎて私は諦めました‥)
・docker-compose.yamlの作成
上記のDockerfileをそのままビルドしても良いですが、今回はDB(PostgreSQL)にもコンテナを使用するため、複数のコンテナを同一マシン上で動作・通信させる必要があります。この場合、
・通信のためにコンテナ同士を同ネットワークに所属させる必要がある
・依存関係に応じて適切な順番でコンテナを立ち上げる必要がある
・全コンテナを引数付きで起動(docker run)する手間が大きい`
等の問題が発生します。
これらの問題を一挙解決すべく、複数コンテナの起動を制御するためのツールがDocker Composeです。
Docker Composeは、docker-compose.yamlという設定ファイルで制御されます。
今回は、MLflowトラッキングサーバ+DBサーバ(バックエンド)を構成するために、以下のようなdocker-compose.yamlを作成します。
services:
waitfordb:
image: dadarek/wait-for-dependencies
depends_on:
- db-server
restart: always
command: db-server:5432
db-server:
image: postgres:13.3
container_name: ${DB_HOST}
restart: always
environment:
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_DB: ${DB_NAME}
TZ: "Asia/Tokyo"
ports:
- 5432:5432
volumes:
- $PWD/db_server:/var/lib/postgresql/data
pgadmin:
image: dpage/pgadmin4
restart: always
ports:
- 81:80
environment:
PGADMIN_DEFAULT_EMAIL: ${PGADMIN_EMAIL}
PGADMIN_DEFAULT_PASSWORD: ${PGADMIN_PASSWORD}
depends_on:
- db-server
tracking-server:
container_name: mlflow-tracking
build:
context: ./tracking_server
dockerfile: Dockerfile
args:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
- DB_HOST=${DB_HOST}
- DB_NAME=${DB_NAME}
- DEFAULT_ARTIFACT_ROOT=ftp://${FTP_USER_NAME}:${FTP_USER_PASS}@${HOST_IP}/artifact_location
image: mlflow-tracking:1.0
restart: always
ports:
- "5000:5000"
depends_on:
- db-server
- waitfordb
ftp-server:
image: stilliard/pure-ftpd:latest
container_name: ftp-server
ports:
- "21:21"
- "30000-30009:30000-30009"
volumes:
- $PWD/ftp/data:/home/ftpusers
environment:
- PUBLICHOST=localhost
- FTP_USER_NAME=${FTP_USER_NAME}
- FTP_USER_PASS=${FTP_USER_PASS}
- FTP_USER_HOME=/home/ftpusers
- ADDED_FLAGS="--tls=2"
restart: always
例のごとく長いですが、細かく解説します。
上記構成では、services:の直下に記載された以下の5つのコンテナが作成されます。
| コンテナ(サービス名) | 役割 | |
|---|---|---|
| 1 | waitfordb | DBサーバが起動するまでトラッキングサーバが起動しないよう制御 |
| 2 | db-server | バックエンドとして使用するDBサーバ(PostgreSQL) |
| 3 | pgadmin | PostgreSQLの管理ツール |
| 4 | tracking-server | MLflowのトラッキングサーバ(前述のDocerfileからビルド) |
| 5 | ftp-server | Artifactストレージとして使用するFTPサーバ |
コンテナごとにdocker-compose.yamlの記載内容を解説します
コンテナ1: waitfordb
こちらの記事で詳説されていますが、PostgreSQLの起動完了前にWebサーバ(今回の場合トラッキングサーバ)がDBにアクセスするとエラーが発生します。
これを防ぐために、wait-for-dependenciesイメージを使って、db-serverコンテナの起動が完了するまでtracking-serverコンテナの起動を待ちます。
image: dadarek/wait-for-dependencies
の部分で、wait-for-dependenciesイメージを読み込んでいます。
depends_on:
- db-server
の部分は、コンテナ間の依存関係を指定しており、db-serverコンテナが起動してからwaitfordbコンテナが起動するよう起動順を指定します。
restart: always
の部分は、こちらに記載されているようにDocker起動時に該当コンテナを自動起動させるための記述です。スタートアップさせたくない場合は指定を解除してください
コンテナ2: db-server
DBサーバとして使用するPostgreSQLのイメージです。
image: postgres:13.3
の部分で、PostgreSQL公式イメージを読み込んでいます。
container_name: ${DB_HOST}
の部分で、コンテナ名を指定しています。
先ほど少し触れましたが、Docker Composeで起動したコンテナ同士は同ネットワークに所属し、container_nameで指定したコンテナ名が、このネットワーク上でのホスト名となります。
ですので、後述のtracking-serverコンテナからDBコンテナへの通信にも同じホスト名を使用するため、ここには環境変数からDB_HOSTを渡します。
環境変数は、後述の.envから読み込んでいます。
environment:
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_DB: ${DB_NAME}
TZ: "Asia/Tokyo"
の部分は、PostgreSQLのユーザ名、パスワード、DB名、タイムゾーンを環境変数から受け取って指定しています。
ports:
- 5432:5432
の部分で、ホスト側(外部からアクセスするとき)、コンテナ側(Docker Compose内コンテナからアクセスするとき)のポートに5432番を渡しています。
(今回はtracking-serverからのアクセス=後者のコンテナ側ポートしか使用していません)
volumes:
- $PWD/db_server:/var/lib/postgresql/data
の部分は、コンテナ外部と内部に共有フォルダを設定しています(詳しくはこちらの記事を参照ください)
このフォルダにはDBの情報が保存されているため、共有フォルダに指定することで、DBコンテナを削除してもエクスペリメント等のデータを残すことができます。
コンテナ3: pgadmin
pgAdminはPostgreSQLをGUIで管理するためのツールで、DBの様子を見たい時に便利です。
普段は使用しないため、負荷を下げたい方は削除しても良いかもしれません。
image: dpage/pgadmin4
の部分で、pgadminイメージを読み込んでいます。
ports:
- 81:80
の部分は、ホスト側(外部からアクセスするとき)のポートに81番を、コンテナ側(Docker Compose内コンテナからアクセスするとき)のポートに80番を指定しています。
今回は前者をPCブラウザ(コンテナ外)からpgAdminへのアクセスに使用するので、http://127.0.0.1:81(localhostの81番ポート)と打てばログイン画面にアクセスすることができます(pgAdminでDBを操作する方法はこちらやこちらを参照ください)
environment:
PGADMIN_DEFAULT_EMAIL: ${PGADMIN_EMAIL}
PGADMIN_DEFAULT_PASSWORD: ${PGADMIN_PASSWORD}
の部分は、pgAdminにログインするためのメールアドレス(ユーザ名)とパスワードを表す環境変数を指定しています。
コンテナ4: tracking-server
MLflowで立ち上げるトラッキングサーバ本体が動作するコンテナです。
先ほど作成したDockerfileをビルドして使用します。
build:
context: ./tracking_server
dockerfile: Dockerfile
args:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
- DB_HOST=${DB_HOST}
- DB_NAME=${DB_NAME}
- DEFAULT_ARTIFACT_ROOT=ftp://${FTP_USER_NAME}:${FTP_USER_PASS}@${HOST_IP}/artifact_location
の部分は、Dockerfileをビルドする際の条件を指定します。
context:の部分はDockerfileの存在するフォルダ、dockerfile:はDockerfileのファイル名を指定しています。
args:の部分は、Dockerfileに環境変数を渡しています。詳しくはこちらの記事を参照ください。
特に
DEFAULT_ARTIFACT_ROOT=ftp://${FTP_USER_NAME}:${FTP_USER_PASS}@${HOST_IP}/artifact_location
の部分は、Artifactストレージ(FTPサーバのコンテナ)にアクセスするパスを指定していますが、注意すべきはサーバ側(tracking-serverコンテナ)とクライアント側(ホストPC)両方からアクセス可能なアドレスを指定する必要があることです。
以下のように両者は所属するネットワークが異なるため、FTPコンテナにアクセスできるアドレスも異なります。
| アクセス元 | FTPコンテナにアクセス可能なアドレス |
|---|---|
| クライアント側(ホストPC) | ・localhost ・127.0.0.1 ・ホストPCのプライベートIP(例:192.168..) |
サーバ側(tracking-serverコンテナ) |
・FTPサーバのコンテナ名 ・ホストPCのプライベートIP |
両者から共通してアクセス可能な「ホストPCのプライベートIP」を環境変数HOST_IPに記載しておき、使用します(ホストPCのIPを固定する必要があることにご注意ください)
image: mlflow-tracking:1.0
の部分は、ビルドで作成されるイメージ名(mlflow-trackingの部分)とタグ(1.0の部分)を指定しています。任意のわかりやすい名前を指定してください。
ports:
- "5000:5000"
の部分は、ホスト側とコンテナ側両方のポートに5000番を指定しています。
これによりブラウザからhttp://127.0.0.1:5000(localhostの5000番ポート)と打てばMLflowのUI(別記事で解説)にアクセスすることができます。
コンテナ5: ftp-server
Artifactストレージとして使用するFTPサーバのコンテナです。
image: stilliard/pure-ftpd:latest
の部分で、FTPサーバとして使用するpure-ftpdイメージを読み込んでいます。
ports:
- "21:21"
- "30000-30009:30000-30009"
の部分は、FTPサーバにアクセスするためのポート(通常21番)を指定しており、
volumes:
- $PWD/ftp/data:/home/ftpusers
の部分で、Artifactの保存場所を共有フォルダに指定しており、これによってコンテナの外からもArtifactファイルにアクセスできます。
environment:
- PUBLICHOST=localhost
- FTP_USER_NAME=${FTP_USER_NAME}
- FTP_USER_PASS=${FTP_USER_PASS}
- FTP_USER_HOME=/home/ftpusers
の部分は、FTPサーバのユーザ名やパスワード等を環境変数から読み込んで指定しています
- ADDED_FLAGS="--tls=2"
はTLS通信を指定しています(参考)
.envの作成
何度か登場している環境変数ですが、docker-composeにおいて環境変数を一括指定するために使用する設定ファイルが、.envです。
docker-compose runの実行時に、同じフォルダに.envがあれば、ここに記載された内容が環境変数に反映されます。
POSTGRES_USER=mlflow_backend
POSTGRES_PASSWORD=mlflow
PGADMIN_EMAIL=mlflow@test.info
PGADMIN_PASSWORD=mlflow
DB_HOST=postgres-db
DB_NAME=mlflow-db
HOST_IP=[ホストPCのプライベートIPアドレス]
FTP_USER_NAME=mlflow_ftp
FTP_USER_PASS=mlflow
それぞれの変数は以下の用途に使用されます(ユーザ名やパスワードは任意で決めて構いません)
| 環境変数名 | 内容 |
|---|---|
| POSTGRES_USER | バックエンドとして使用するPostgresSQL DBのユーザ名 |
| POSTGRES_PASSWORD | バックエンドとして使用するPostgresSQL DBのパスワード |
| PGADMIN_EMAIL | pgAdminに使用するメールアドレス |
| PGADMIN_PASSWORD | pgAdminに使用するパスワード |
| DB_HOST | バックエンドのホスト名(Docker上でアクセスしやすいようdb-serverコンテナのcontainer_nameと一致させる) |
| DB_NAME | バックエンドとして使用するPostgresSQLのDB名 |
| HOST_IP | ホストPCのプライベートIPアドレス(固定IPが望ましい) |
| FTP_USER_NAME | FTPサーバのユーザ名 |
| FTP_USER_PASS | FTPサーバのパスワード |
・Dockerコンテナの立ち上げ
docker-compose.yamlと同じフォルダで以下のコマンドを実行し、必要なDockerコンテナを一括で立ち上げます
docker-compose up
※M1 MacにおけるDocker Composeエラー対策
上記の方法はWindows+WSL2での方法ですが(恐らくUbuntu等のネイティブなLinux distributionでも同様の方法で実現可能です)、M1 Macの場合は少し方法を変える必要があります。
まず、Dockerfileでコピーするフォルダ名の「x86_64-linux-gnu」を「aarch64-linux-gnu」に変える必要があります。
またMac OS Montereyではポート番号5000がAirPlay Receiverにデフォルトで使用されており、以下のどちらかの対策を実施する必要があります。
・mlflow-trackingコンテナのポート番号を5000以外とする
・こちらの方法でAirPlay Receiverのチェックを外してOFFにする
私のM1 Macで動作するDockerfileおよびdocker-compose.yamlをGitHubにアップロードしているので、ご参照いただければと思います。
シナリオ4: MLflow with remote Tracking Server, backend and artifact stores
トラッキングサーバ、バックエンド、Artifactストレージをそれぞれリモートに作成します。
複数のクライアントからトラッキングサーバやストレージを共有できるため、チーム開発向きの構成かと思います。
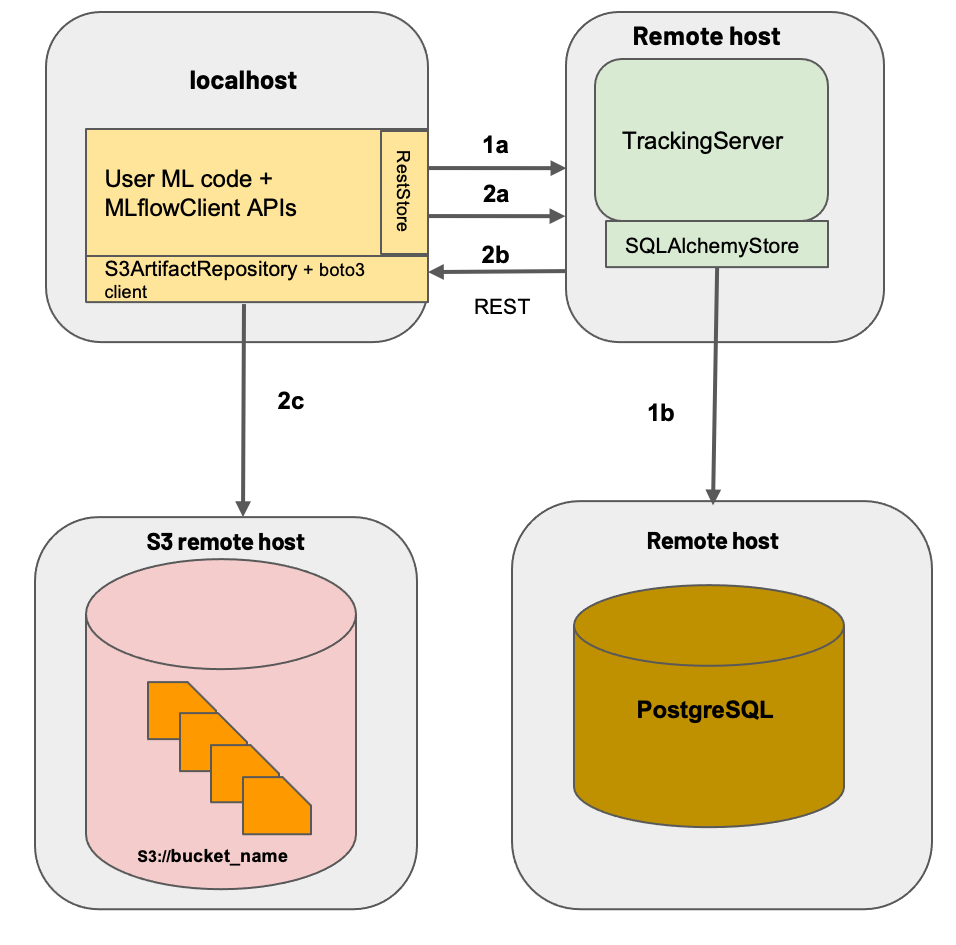
構築方法はシナリオ3と類似(DockerコンテナやArtifactストレージの場所がリモートサーバやクラウドに変わるだけ)していますが、複数マシン間での通信が必要となるため、ネットワークやクラウド周りで設定すべき項目が増えます。
複雑な構成のため、慣れない状態だとネットワーク周りとMLflow自体のどちらに問題があるのか特定に手間が掛かるので、まずはシナリオ3で練習すると良いかと思います。
本記事では、下図のようにトラッキングサーバとバックエンドをリモートサーバ上にDockerで、ArtifactストレージをAmazon S3に構成する例を紹介します。
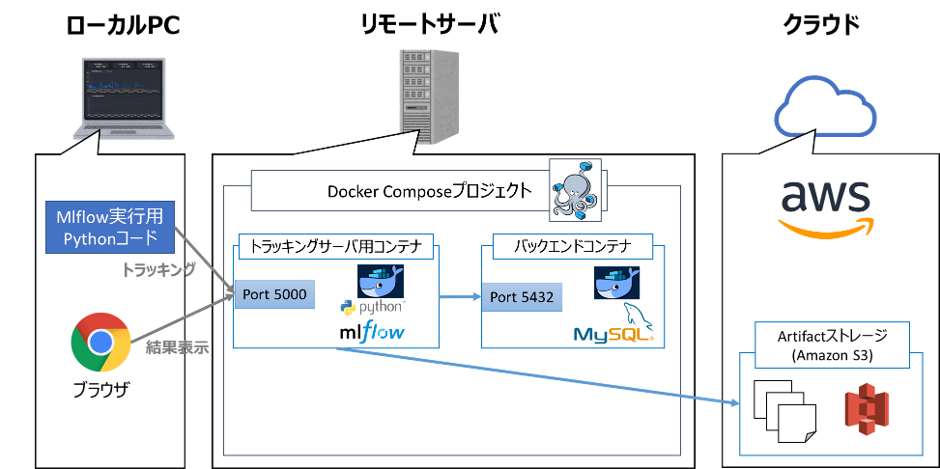
| 名称 | 概要 |
|---|---|
| トラッキングサーバ | PythonイメージをベースにDockerfileでMLflow等必要パッケージをインストール (シナリオ3とほぼ同様) |
| バックエンド | MySQLイメージをそのまま使用 (シナリオ3のPostgreSQLから変更※) |
| Artifactストレージ | Amazon S3を使用 |
※バックエンドをシナリオ3のPostgreSQLからMySQLに変えていますが、筆者が使ってみたかっただけで特に意図はありません。PostgreSQLでもOKです(MySQLでMLflowを使用する方法はこちらを参考にさせて頂きました)
・フォルダ構成
リモートサーバ上に以下のフォルダ構成でDockerfile、docker-compose.yaml、.envを配置します
├─tracking_server
│ └──Dockerfile
├─docker-compose.yaml
├─.env
│
└─db_server(DBコンテナとのファイル共有用空フォルダ)
・WSL2とDockerの導入
リモートサーバがWindowsの場合、WSL2 (Windows Subsystem for Linux 2)とDocker Dektopを導入します。
シナリオ3のときと方法は同じなので、こちらを参照ください
・トラッキングサーバ用のDockerイメージ作成
以下のDockerfileを作成して前述のフォルダ構成で配置します
# builder for installing python packages
FROM python:3.9.7-buster as builder
# install mlflow and mysqlclient
RUN pip install \
mlflow \
mysqlclient \
boto3
# main image
FROM python:3.9.7-slim-buster
# copy python packages
COPY --from=builder /usr/local/lib/python3.9/site-packages /usr/local/lib/python3.9/site-packages
# copy mlflow package
COPY --from=builder /usr/local/bin/mlflow /usr/local/bin/mlflow
# copy linux packages for mysql
COPY --from=builder /usr/lib/aarch64-linux-gnu /usr/lib/aarch64-linux-gnu
# copy gunicorn package
COPY --from=builder /usr/local/bin/gunicorn /usr/local/bin/gunicorn
# open port 5000
EXPOSE 5000
# set environment variables
ARG MYSQL_USER
ARG MYSQL_PASSWORD
ARG DB_HOST
ARG DB_NAME
ARG DEFAULT_ARTIFACT_ROOT
ENV MYSQL_USER=${MYSQL_USER}
ENV MYSQL_PASSWORD=${MYSQL_PASSWORD}
ENV DB_HOST=${DB_HOST}
ENV DB_NAME=${DB_NAME}
ENV DEFAULT_ARTIFACT_ROOT=${DEFAULT_ARTIFACT_ROOT}
# Start mlflow server
CMD mlflow server \
--host 0.0.0.0 \
--port 5000 \
--backend-store-uri mysql://${MYSQL_USER}:${MYSQL_PASSWORD}@${DB_HOST}:3306/${DB_NAME} \
--default-artifact-root ${DEFAULT_ARTIFACT_ROOT}
以下の2点以外はシナリオ3とほぼ同内容なので、Dockerfileの解説はシナリオ3を参照ください。
| 変化点 | docker-compose.yamlにおける変化点 | |
|---|---|---|
| 1 | DBがPosgreSQL → MySQLに変わった | 7行目のpip install mysqlclient(mysqlclent参考)および最後から2行目の--backend-store-uri mysql://...の部分が相当 |
| 2 | ArtifactストレージがFTPサーバ → Amazon S3に変わった | 8行目のpip install boto3および最後の行の--default-artifact-rootの部分が相当 |
・docker-compose.yamlの作成
シナリオ3のときと同様、MLflowトラッキングサーバ+バックエンドを構成するために、以下のようなdocker-compose.yamlを前述のフォルダ構成通り作成します。
services:
db-server:
image: mysql:5.7
container_name: ${DB_HOST}
platform: 'linux/amd64'
restart: always
environment:
MYSQL_USER: ${MYSQL_USER}
MYSQL_PASSWORD: ${MYSQL_PASSWORD}
MYSQL_DATABASE: ${DB_NAME}
MYSQL_ROOT_PASSWORD: ${MYSQL_ROOT_PASSWORD}
TZ: "Asia/Tokyo"
ports:
- 3306:3306
volumes:
- $PWD/db_server:/var/lib/mysql
adminer:
image: adminer
container_name: adminer
restart: always
depends_on:
- db-server
ports:
- "8080:8080"
tracking-server:
container_name: mlflow-tracking
build:
context: ./tracking_server
dockerfile: Dockerfile
args:
- MYSQL_USER=${MYSQL_USER}
- MYSQL_PASSWORD=${MYSQL_PASSWORD}
- DB_HOST=${DB_HOST}
- DB_NAME=${DB_NAME}
- DEFAULT_ARTIFACT_ROOT=${DEFAULT_ARTIFACT_ROOT}
image: mlflow-tracking:1.0
restart: always
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION}
ports:
- "5000:5000"
depends_on:
- db-server
上記docker-compose.yamlにより、以下の3つのコンテナが生成します。
| コンテナ(サービス名) | 役割 | |
|---|---|---|
| 1 | db-server | バックエンドとして使用するDBサーバ(MySQL) |
| 2 | adminer | MySQLの管理ツール |
| 3 | tracking-server | MLflowのトラッキングサーバ(前述のDocerfileからビルド) |
以下の3点以外はシナリオ3とほぼ同内容なので、docker-compose.yamlの解説はシナリオ3を参照ください。
| 変化点 | docker-compose.yamlにおける変化点 | |
|---|---|---|
| 1 | DBがPosgreSQL → MySQLに変わった | db-serverコンテナのimageがpostgres→mysqlに変わり、ポート番号が5432→3306に変わった |
| 2 | DB管理ツールがpgAdmin → Adminerに変わった | adminerコンテナが相当 |
| 3 | ArtifactストレージがFTPサーバ → Amazon S3に変わった | FTPサーバ用のコンテナがなくなり、tracking-serverコンテナのDEFAULT_ARTIFACT_ROOTに環境変数からS3のアドレスを入力するよう変更 |
なお、後述のS3アクセスキー情報のコンテナへの登録は、以下の部分で実施しています(参考)
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION}
同じネットワーク内のPCからであれば、ブラウザから
http://[リモートサーバのIP]:5000(トラッキングサーバのポートが5000番以外なら適宜変更)と打てばMLflowのUIに
http://[リモートサーバのIP]:8080(Adminerのポートが8080番以外なら適宜変更)と打てばAdminerのUIに
アクセスできます
(ファイアウォールでポートが遮断されていることが多いので、必要に応じてTCP5000番や8080番のポートを解放してください)
・AWSのアクセス権限設定
ここからクラウド(AWS)上での操作に移ります。
Amazon S3にPython(boto3ライブラリ)からアクセスできるよう、設定します。
AWSの登録とIAMユーザ作成
AWSへの登録自体はこちらを参照ください。
次にAWSへの認証情報を持ったIdentity and Access Management (IAM)ユーザを作成します。
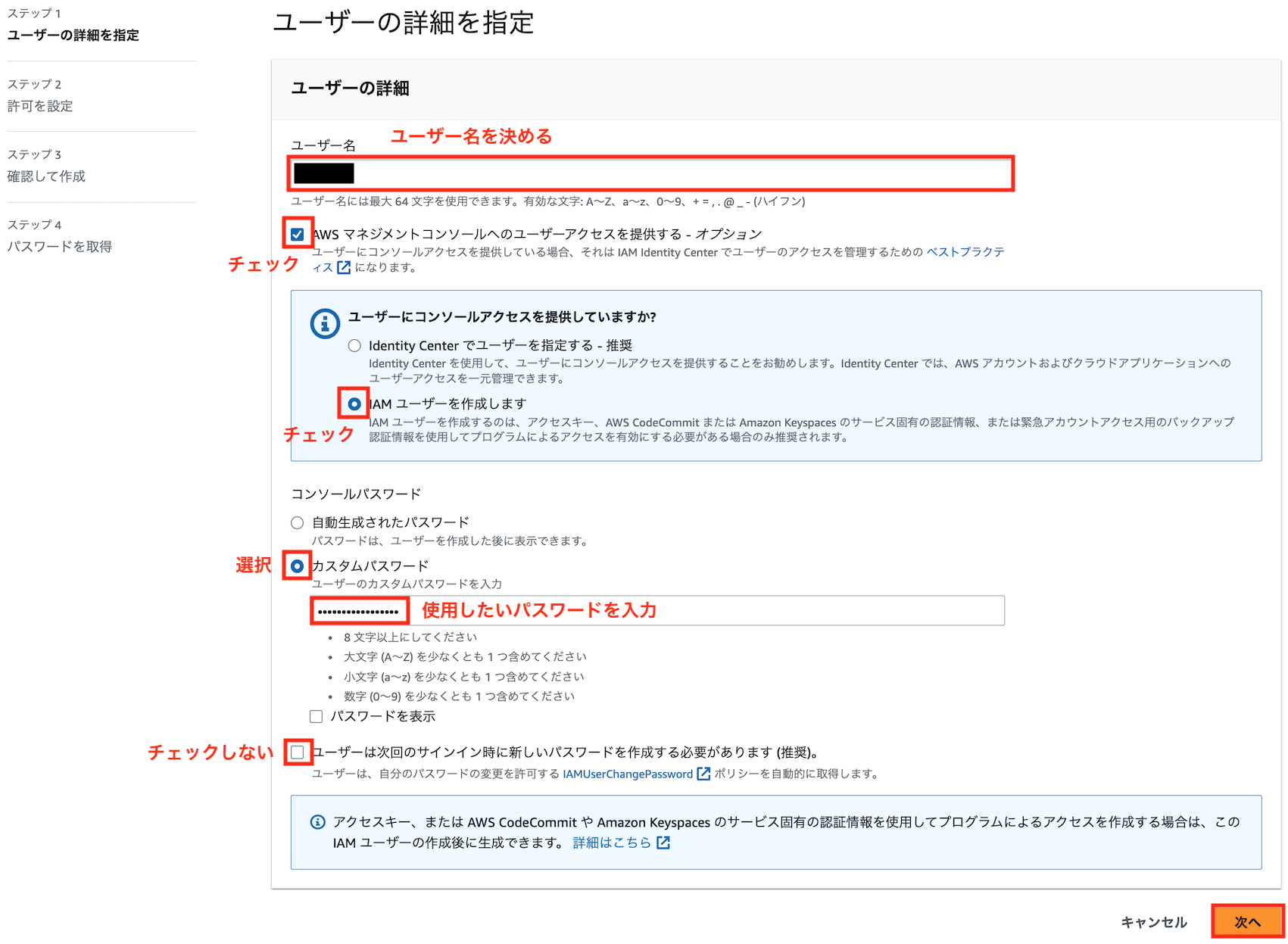
ルートユーザでログインして、コンソールからIAM → ユーザーと進み、「ユーザを追加」をクリックします

好きなユーザ名とパスワードを入力し、以下のようにユーザーを作成します
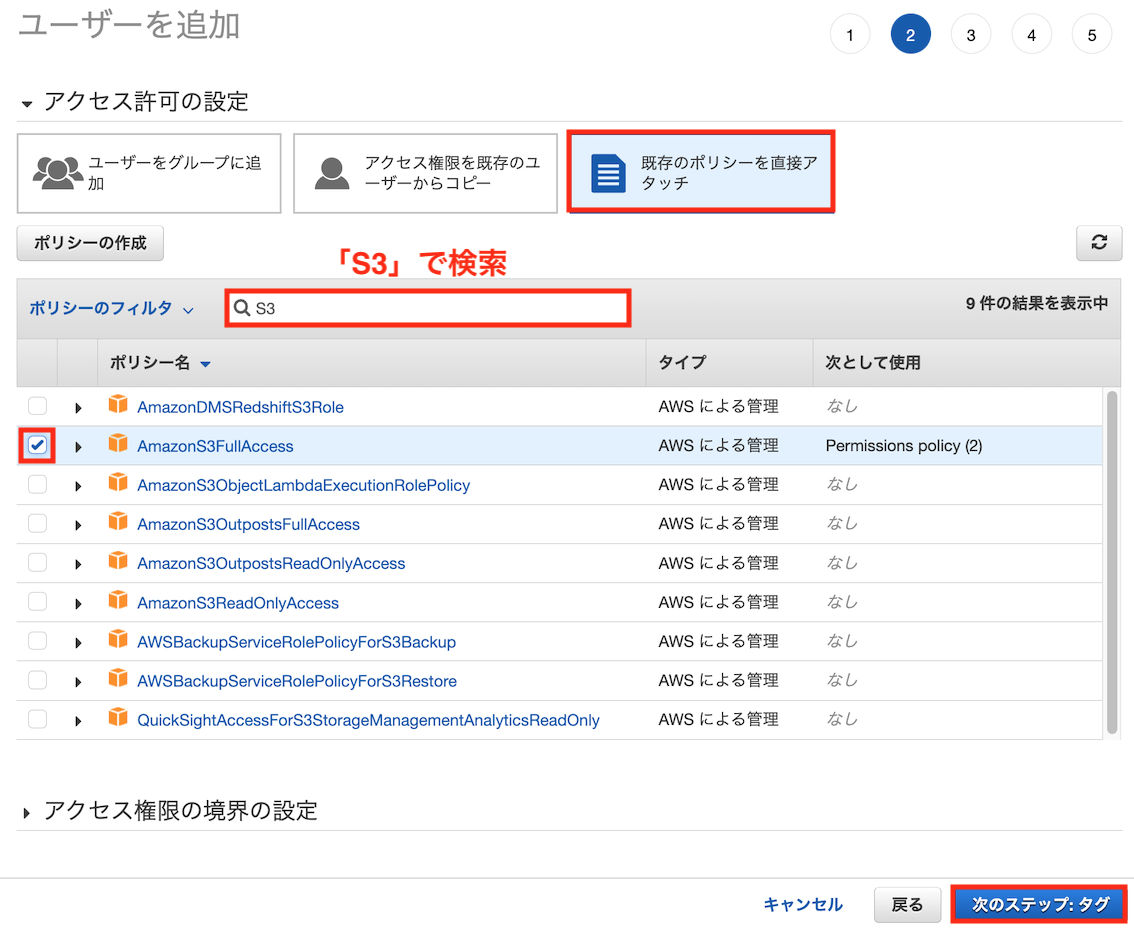
S3にアクセスするためのポリシーを設定します(下の例ではS3のフルアクセス権限であるAmazonS3FullAccessを設定しています。運用方法に合わせ適宜変更してください)
タグを設定し(未記入でもOK)、「ユーザの作成」をクリックします。
アクセスキーの入手
先ほど作成したIAMユーザでコンソールにログインし、IAM → ユーザ → 先ほど作成したユーザ → 「セキュリティ認証情報」タブに移動し、「アクセスキーの作成」をクリックします。

アクセスキーを作成して出てきたアクセスキーIDとシークレットアクセスキーをメモします
AWS CLIのインストールとアクセスキーの登録
AWSをコマンドラインから操作するためのAWS CLIを、クライアントPCに以下を参考にインストールしてください
インストールが完了したら、ターミナル(Windowsの場合Powershell)から以下のコマンドを打ち
aws configure
以下のように入力します
AWS Access Key ID [None]: [アクセスキーID]
AWS Secret Access Key [None]: [先ほどメモしたシークレットアクセスキー]
Default region name [None]: ap-northeast-1
Default output format [None]: [空欄でOK]
「~/.aws/credentials」と「~/.aws/config」に入力したクレデンシャル情報(アクセスキーやリージョン)が生成していれば成功です。
Amazon S3のバケット作成
Artifactストレージとして使用するAmazon S3のバケットを作成します。
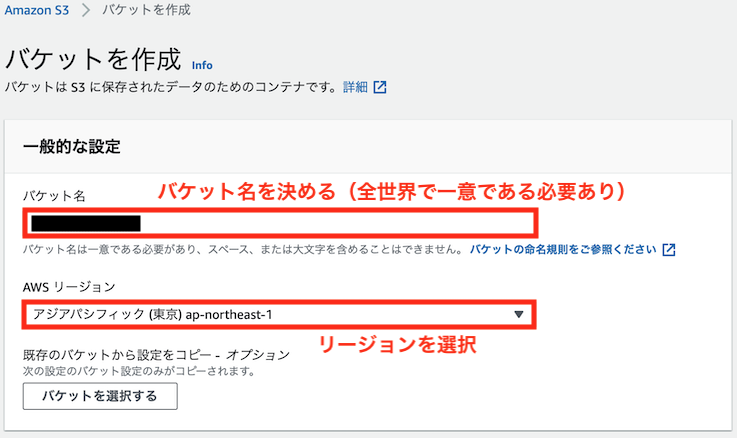
先ほど作成したIAMユーザでコンソールにログインし、S3 → 「バケットを作成」をクリックします

バケット名とリージョンを決め、「バケットの作成」をクリックしてください
(パブリックアクセス、バージョニング、暗号化を設定する場合は、これらの設定も変更してください)
Boto3のインストール
PythonからS3へのデータアップロードには、boto3というライブラリを使用します。
(MLflowも内部ではboto3を使用しています)
クライアントPC上で以下コマンドでboto3をインストールします
・pipの場合
pip install boto3
・condaの場合
conda install boto3
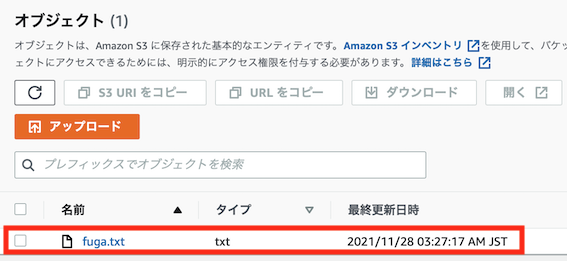
boto3によるPythonからS3へのアップロード動作確認
クライアントPC上で以下のようなコードを動作させ、S3へデータがアップロードできるか確認します(できればリモートサーバでもdocker-compose upでコンテナ立ち上げ後、コンテナ内に入ってコードを実行し、動作確認できればベストです)
import boto3
import os
# アップロード用のテキストファイル作成
text = "rooms, zipcode, median_price, school_rating, transport"
text_path = 'fuga.txt'
with open(text_path, "w") as f:
f.write(text)
# S3にアップロード
s3 = boto3.resource('s3')
bucket = s3.Bucket('[S3のバケット名]')
bucket.upload_file(text_path, text_path)
os.remove(text_path)
該当S3バケットにファイルがアップロードされていれば成功です
.envの作成
ここからリモートサーバの作業用フォルダ(前述)での操作に戻ります
docker-composeにおいて環境変数を一括指定するため、以下の.envを作成します。
MYSQL_USER=mlflow_backend
MYSQL_PASSWORD=mlflow
MYSQL_ROOT_PASSWORD=mlflow_root
DB_HOST=mysql-db
DB_NAME=mlflow-db
DEFAULT_ARTIFACT_ROOT=s3://[S3のバケット名]/artifact_location
AWS_ACCESS_KEY_ID=[IAMユーザのアクセスキーID]
AWS_SECRET_ACCESS_KEY=[IAMユーザのシークレットアクセスキー]
AWS_DEFAULT_REGION=[S3のリージョン(通常はap-northeast-1)]
それぞれの変数は以下の用途に使用されます(ユーザ名やパスワードは任意で決めて構いません)
| 環境変数名 | 内容 |
|---|---|
| MYSQL_USER | バックエンドとして使用するMySQL DBのユーザ名 |
| MYSQL_PASSWORD | バックエンドとして使用するMySQL DBのパスワード |
| MYSQL_ROOT_PASSWORD | バックエンドとして使用するMySQL DBのルートパスワード |
| DB_HOST | バックエンドのホスト名(Docker上でアクセスしやすいようdb-serverコンテナのcontainer_nameと一致させる) |
| DB_NAME | バックエンドとして使用するMySQLのDB名 |
| DEFAULT_ARTIFACT_ROOT | Artifactストレージとして使用するS3のURI |
| AWS_ACCESS_KEY_ID | IAMユーザのアクセスキーID |
| AWS_SECRET_ACCESS_KEY | IAMユーザのシークレットアクセスキー |
| AWS_DEFAULT_REGION | S3のリージョン(通常は東京リージョン=ap-northeast-1) |
・Dockerコンテナの立ち上げ
リモートサーバ上のdocker-compose.yamlと同じフォルダで以下のコマンドを実行し、必要なDockerコンテナを一括で立ち上げます
docker-compose up
参考: トラッキングサーバへの認証機能の付加
共有サーバとして使用するという特性上、認証機能があることがセキュリティ的に望ましいですが、MLflowには認証機能がありません。以下の記事でnginxをリバースプロキシとして使用して認証機能を付加する例を紹介されていますので、参考頂ければと思います。
また、上例ではmlflow server --host引数に0.0.0.0を指定して全てのIPアドレスからトラッキングサーバへの接続を許可していますが、接続を制限したい場合は、--host引数を指定してください。
参考:バックエンドおよびArtifactストレージの種類
トラッキングサーバ立ち上げ(mlflow serverコマンド実行)時に、
--backend-store-uri引数でバックエンドを
--default-artifact-root引数でArtifactストレージを
指定できます。
公式ドキュメントに列記されている、指定できるストレージの種類と指定法を解説します
バックエンド
--backend-store-uri引数で指定できるバックエンドには以下の種類があります
| 名称 | 種類 | Python側ライブラリ | 引数指定時のフォーマット | 参考リンク |
|---|---|---|---|---|
| ディレクトリ | ファイル | - | file:///[使用するディレクトリのパス] | |
| SQLite | DB | - | sqlite:///[DBファイルのあるパス] | 参考 |
| PostgreSQL | DB | psycopg2 | postgresql+psycopg2://[ユーザ名]:[パスワード]@[ホストのアドレス]:[DBのポート番号]/[DB名] | 参考 |
| MySQL | DB | mysqlclient | mysql://[ユーザ名]:[パスワード]@[ホストのアドレス]:[DBのポート番号]/[DB名] | 参考 |
| Oracle | DB | cx_oracle | oracle://[ユーザ名]:[パスワード]@[ホストのアドレス]:[DBのポート番号]/[DB名] | 参考 |
| SQL Server | DB | pyodbc | mssql+pyodbc://[ユーザ名]:[パスワード]@[ホストのアドレス]:[DBのポート番号]/[DB名] | 参考 |
※MLflowからDBへのアクセスにはSQLAlchemyを使用しているので、SQLAlchemyのリンクを参考に貼っております。
※「Python側ライブラリ」と書いてあるライブラリをサーバ側にインストールする必要があります。
Artifactストレージ
--default-artifact-root引数で指定できるArtifactストレージには以下の種類があります。
| 名称 | Python側ライブラリ | 引数指定時のフォーマット | 備考 |
|---|---|---|---|
| ディレクトリ | - | [使用するディレクトリのパス] | |
| FTPサーバ | - | ftp://[ユーザ名]:[パスワード]@[ホストのアドレス]/[FTPサーバ内のディレクトリ] | |
| SFTPサーバ | pysftp | sftp://[ユーザ名]@[ホストのアドレス]/[SFTPサーバ内のディレクトリ] | パスワード認証は非推奨、公開鍵認証を推奨 |
| HDFS | - | hdfs://[ホストのアドレス]:[ポート番号]/[ディレクトリ] | Kerberos認証用の環境変数指定が必要 |
| Amazon S3 | boto3 | s3://[バケット名]/[バケット内のディレクトリ] | 前述のアクセス設定が必要 |
| Azure Blob Storage | azure-storage-blob | wasbs://[コンテナ]@[ストレージアカウント].blob.core.windows.net/[ディレクトリ] | 参考 |
| Google Cloud Storage | google-cloud-storage | gs://[バケット名]/[バケット内のディレクトリ] | 参考 |
※「Python側ライブラリ」と書いてあるライブラリをサーバ側、クライアント側両方にインストールする必要があります。
なお、--default-artifact-root引数や、create_experiment()メソッドのartifact_location引数など、Artifactを指定するパスはサーバ側とクライアント側で同一にする必要があります
シナリオ3のように同一マシン内のコンテナ(ホスト側)とホスト(クライアント側)から同一のパスでアクセスするのは骨が折れますが(通常コンテナからはコンテナ名で、ホストからはlocalhostでアクセスするため、名称を統一することが困難)、前述のようにホストPCのプライベートIPを指定するか、extra_hostsオプションでlocalhostにホストPCのプライベートIPを割り当てることが有効な解決策となります。
参考:個人開発でシナリオ2をおすすめする理由
端的に言うと、環境構築の手間と管理の手間のバランスが良いことが挙げられます
以下、シナリオ1~4のメリットとデメリットを解説します。
シナリオ1のメリットとデメリット
シナリオ1は環境構築不要で簡単に使用できることが利点ですが、実行フォルダの直下に、バックエンドやアーティファクト用の大量のファイルが生成されます。
Gitで管理しているプロジェクトの下に大量のファイルができると管理の煩わしさが増大する事は、想像に難くないかと思います。
シナリオ3・4のメリットとデメリット
シナリオ3はモデルの作成と実験管理用のトラッキングサーバをコンテナで分けており、シナリオ4は物理的に分けているため、障害対策やサーバの独立性向上の観点では好ましい構成となっており、特にシナリオ4はチーム開発において複数のクライアントでの実験管理を1つのトラッキングサーバーに集中させられるため、管理が一元化できることがメリットと言えます。
前述のトラッキングサーバ構築手順を読まれた方は分かるかと思いますが、デメリットは環境構築の手間が掛かることです。
インフラまわりの知識が必要となるため、分析・機械学習をメインとして取り組まれている方には馴染みのない内容が多いと思います。
これに加えて、
| シナリオ3 | ただでさえ重い機械学習と同じPCでWebサーバとDBのコンテナを動かすため、PCにかなりのスペックが求められること |
| シナリオ4 | サーバの数が増えるために環境構築の手間がさらに増大すること |
が加わります
シナリオ2のメリット
シナリオ1と比べたメリット:バックエンドにDBを使用しているためにファイルの数が減り、管理が楽になる
シナリオ3・4と比べたメリット:環境構築が楽
上記の理由で、個人開発目的では管理と環境構築のバランスが取れたシナリオ2が、おすすめとなります