MLflowとは?
MLflowは機械学習のライフサイクル管理(MLOps)を目的としたライブラリで、主に実験管理用途で使用されることの多いツールです。
実験管理とは、
・使用した学習器や学習データ、ハイパーパラメータ等のモデル作成条件
・そのモデルを評価して得られた評価指標
のセットを記録し、複数条件の比較を行うことで最適なモデル選定を行う工程です。
このような条件記録はExcel等での手入力が一般的かと思いますが、
「手入力は時間が掛かる!」
「手入力をミスして苦労して集めた結果が信頼できなくなった」
という経験をされた方も多いかと思います

上記のような経験から、MLflowにより実験管理を自動化すれば、多くのメリットが得られることはイメージが付くかと思います。
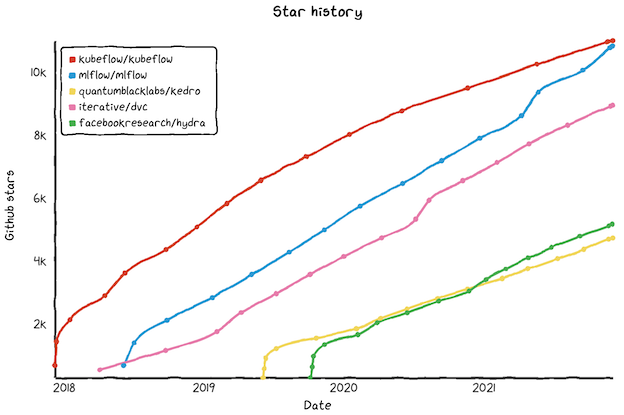
MLflowは2018年リリースの比較的新しいライブラリですが、GitHubのStarは既に1万を突破しており、下図のようにブームとなっているMLOps系ツールの中でも特に伸びが著しいことがわかります
※水色がMLflowのStar数推移
**「いつか使ってみたい!」**と思いつつも、日本語で体系的に書かれた記事が少ないため、どう勉強すべきか悩まれていた方も多いのではと思います。
そのような方の助けとなるよう、本記事では公式ドキュメントをベースに体系的に使用手順をまとめることを目指したいと思います。
インストール法
pipを使ってインストールできます
pip install mlflow
パッケージ管理にcondaを利用している人は、以下のコマンドでインストール可能です
conda install mlflow
機能
公式サイトによると、MLflowは以下の4つの機能から構成されます
| 機能名 | 用途 | 解説 |
|---|---|---|
| MLflow Tracking | 実験管理 | 機械学習モデルの条件やスコアを記録して一括管理 |
| MLflow Projects | コード管理 | 機械学習のコードを再利用可能な形で管理し、エンジニア間で簡単に使い回せるようにする |
| MLflow Models | デプロイ支援 | 機械学習モデルを各種プラットフォーム(例:AWS SageMaker)に簡単にデプロイできる形で管理する |
| MLflow Model Registry | ライフサイクル一元管理 | モデルのバージョン管理やアノテーション結果管理等の機械学習ライフサイクル管理を一元化する |
| 本記事では実験管理を目的としたMLflow Trackingについて主に取り上げます。 | ||
| (他の機能は他ライブラリとの競合性が強いため、普及が進んだ段階で別途記事化します) |
執筆には以下の公式ドキュメントを参考にしました
(トラッキングサーバの構築法等、公式ドキュメント未記載の内容も追記しています)
使用手順
公式ドキュメントに基づき、以下の手順で実験管理を実現します。
1. 管理したい情報の洗い出し
2. トラッキングサーバの構築
3. エクスペリメントの作成
4. 実験結果のロギング
5. 結果表示UIの立ち上げ
以下、詳細手順を解説します
手順1. 管理したい情報の洗い出し
実装を始める前に、何を記録したいのかを定義する必要があります。
公式ドキュメントでは、以下のように分類されています。
| 種類 | 英名 | 解説 | 実例 |
|---|---|---|---|
| コードのバージョン | Code Version | 記録時に使用したコードのGitリポジトリにおけるバージョン情報 | Gitコミットハッシュコード、コミットメッセージ |
| 時間情報 | Start & End Time | 記録を開始・終了した時刻 | 記録開始時刻、終了時刻 |
| MLflow Project 情報 | Source | MLflow Projectにおける各種情報 | プロジェクト名、エントリポイント |
| タグ情報 | Tags | キーと値からなる文字情報 | モデルの種類、バージョン情報等 |
| 実験条件 | Parameters | 性能に寄与するパラメータ等の実験条件 | ハイパーパラメータ、クロスバリデーション条件、乱数シード |
| 評価指標 | Metrics | 性能を測定するための指標 | 機械学習評価スコア、処理時間 |
| 関連ファイル | Artifact | 上記以外に保持したい任意のファイル情報 | CSV、画像、機械学習モデルのpickleファイル |
実験管理を目的とするのであれば、最重要は「Parameters (実験条件)」「Metrics (評価指標)」 ですが、他の情報も含めると後追いがしやすくなるので便利です。
厳密な洗い出しには時間が掛かるので、初期段階でどこまで細かく洗い出すかは、立場や目的に応じて以下のようにバランスを考えて判断するのが良いかと思います。
| 観点 | 判断 |
|---|---|
| データサイエンティストの観点 | アドホックな分析では「後から追加したい」という場面が多発するので、初期の洗い出しは最低限にとどめて手順2に移る |
| システム開発の観点 | 実システム開発においては後工程に行くほど変更の工数が増えるので、初期の洗い出しは関係者とコミュニケーションを取って丁寧に実施する |
手順2. トラッキングサーバの構築
MLflowによる実験管理を実現するためには、以下の4種類の機構を整備する必要があります(レジストリサーバはトラッキングサーバと同一とする事が多いので、残りの3種類が特に重要)
| 名称 | 機能 | 指定できるサービス |
|---|---|---|
| トラッキングサーバ | トラッキングの制御と結果のUI表示 | ホストPC, リモートサーバ, クラウド(EC2等) |
| バックエンド | ParametersやMetrics等の主要データを保存 | ファイルストレージ, DB(詳細はこちら参照) |
| Artifactストレージ | Artifact(テーブルデータや画像等の非構造化データ)を保存する | ファイルストレージ, FTPサーバ, クラウド(S3等), etc.(詳細はこちら参照) |
| レジストリサーバ | モデルとバージョン情報を保持する(MLflow Model Registryの設定が必要) | ファイルストレージ, DB等 |
| ※バックエンドとArtifactストレージの指定可能サービスは上記リンクを参照ください。 |
公式ドキュメントでは、以下の4種類の方法(シナリオ) が紹介されています。
| シナリオ | 英名 | トラッキングサーバ | バックエンド | アーティファクトストレージ |
|---|---|---|---|---|
| 1 | MLflow on localhost | ローカルに自動生成 | ローカルストレージ | ローカルストレージ |
| 2 | MLFlow on localhost with SQLite | ローカルに自動生成 | ローカルDB | ローカルストレージ |
| 3 | MLflow on localhost with Tracking Server | ローカルに手動ホスティング | ローカルDB or ストレージ | ローカルストレージ |
| 4 | MLflow with remote Tracking Server, backend and artifact stores | リモートサーバ | リモートDB | リモートストレージ |
| おすすめは |
・個人開発ならシナリオ2
・チーム開発ならシナリオ4
ですが、よう分からん!という方は、何もせずに手順3に進んでも問題ありません(デフォルトのシナリオ1が選択されます)
トラッキングサーバの構築は多くのインフラの知識が求められ、特にシナリオ3や4は複雑な手順を踏む必要があるため、構築方法は別記事にまとめました
上記記事を参考に環境構築を進めていただければと思います。
手順3. エクスペリメントの作成
MLflowでは実験をグルーピングして管理する事ができ、プロジェクト毎にグループを分ける等、実験管理の効率化に大きく寄与します。
この実験のグルーピング単位を、「エクスペリメント」と呼びます
また、トラッキングサーバを自前で立ち上げていない場合(手順2のシナリオ1およびシナリオ2が相当)、Artifactストレージの場所もエクスペリメント作成時に指定します。
手順2で選択したシナリオ毎に方法が異なるので、解説します
シナリオ1: デフォルト設定の場合
手順2で特にトラッキングサーバの作成を実施せず、デフォルト設定を使用した場合、エクスペリメントの生成を明示的に行う必要はありません
(エクスペリメントは自動生成されます)
シナリオ1: バックエンド、Artifactストレージを明示的に指定した場合
手順2で、ローカル内の任意のフォルダにバックエンド、Artifactストレージを指定する場合、以下のようにエクスペリメントを明示的に作成する必要があります。
import mlflow
# 各種パスを指定
TRACKING_URI = '[トラッキングサーバ(バックエンド)に指定したいパス]'
ARTIFACT_LOCATION = '[Artifactストレージに指定したいパス]'
EXPERIMENT_NAME = '[指定したいエクスペリメント名]'
# トラッキングサーバ(バックエンド)の場所を指定
mlflow.set_tracking_uri(TRACKING_URI)
# Experimentの生成
experiment = mlflow.get_experiment_by_name(EXPERIMENT_NAME)
if experiment is None: # 当該Experiment存在しないとき、新たに作成
experiment_id = mlflow.create_experiment(
name=EXPERIMENT_NAME,
artifact_location=ARTIFACT_LOCATION)
else: # 当該Experiment存在するとき、IDを取得
experiment_id = experiment.experiment_id
バックエンドおよびArtifactストレージの**パス指定方法に関しては、こちらを参照**ください。
特に、Artifactストレージのパス先頭にfile:///を付加しないように注意してください。
シナリオ2: バックエンドにSQLiteを指定した場合
手順2で、ローカル内のSQLiteにバックエンドを作成した場合、以下のようにエクスペリメントを作成します。
import mlflow
# 各種パスを指定
DB_PATH = '[バックエンドとして作成したDBファイルのパス]'
ARTIFACT_LOCATION = '[Artifactストレージに指定したいパス]'
EXPERIMENT_NAME = '[指定したいエクスペリメント名]'
# トラッキングサーバ(バックエンド)の場所を指定
tracking_uri = f'sqlite:///{DB_PATH}'
mlflow.set_tracking_uri(tracking_uri)
# Experimentの生成
experiment = mlflow.get_experiment_by_name(EXPERIMENT_NAME)
if experiment is None: # 当該Experiment存在しないとき、新たに作成
experiment_id = mlflow.create_experiment(
name=EXPERIMENT_NAME,
artifact_location=ARTIFACT_LOCATION)
else: # 当該Experiment存在するとき、IDを取得
experiment_id = experiment.experiment_id
DBファイルの**パス指定方法に関しては、こちらを参照**ください
(Artifactストレージのパス指定方法はシナリオ1と同様です)
シナリオ3, 4: トラッキングサーバを手動ホスティングした場合
手順2で、ローカル内にトラッキングサーバを立ち上げ(シナリオ3)、あるいはリモートに立ち上げ(シナリオ4)た場合、トラッキングサーバ作成時のmlflow server --default-artifact-root引数でArtifactストレージの場所を指定済なので、エクスペリメント生成時にArtirfactストレージを指定する必要はありません
import mlflow
# 各種パスを指定
TRACKING_URI = '[トラッキングサーバのアドレス]'
# トラッキングサーバの場所を指定
mlflow.set_tracking_uri(TRACKING_URI)
# Experimentの生成 (artifact_locationは指定済なので不要)
experiment = mlflow.get_experiment_by_name(EXPERIMENT_NAME)
if experiment is None: # 当該Experiment存在しないとき、新たに作成
experiment_id = mlflow.create_experiment(
name=EXPERIMENT_NAME)
else: # 当該Experiment存在するとき、IDを取得
experiment_id = experiment.experiment_id
トラッキングサーバのアドレスは、
シナリオ3の場合: http://127.0.0.1:[ポート番号](ローカルホスト)
シナリオ4の場合: http://[リモートサーバのIP]:[ポート番号](リモートサーバ)
のように指定します
ポート番号は指定方法によりますが、基本的には5000となっているはずです(最新版Macでは5001とすることもある)
手順4. 実験結果のロギング
手順1で決めた情報を実際に記録します。
この操作がいわゆる「トラッキング」を実行する部分となります。
・記録手順
MLflowにおいて、記録したい1回の実験のことをRunと呼びます。
この1度のRunの間に、手順1で定めたParameters, Metrics, Artifact等の情報を記録していきます。
Runでロギングを実行するためには、以下の手順となるようコードを実装する必要があります。
- Runの開始
- ロギングの実施
- Runの終了
1. Runの開始
Runを開始するには、mlflow.start_run()メソッドを使用します。
mlflow.start_run(experiment_id=experiment_id)
その際、以下のようにwith構文を使用すれば、インデントで区切った範囲内のみでRunが実行されて可読性が上がり、エラーが起こった際もRunが自動で終了するので、実用上便利です。
with mlflow.start_run(experiment_id=experiment_id) as run:
...
以下、ロギング処理を記述
2. ロギングの実施
ロギングには、記録したい情報の種類ごとにメソッドが用意されています
ロギング用メソッドの一覧
| メソッド名 | ロギング対象 | 解説 |
|---|---|---|
| mlflow.log_param() | Parameters | パラメータを記録 |
| mlflow.log_params() | Parameters | 複数のパラメータを一括記録 |
| mlflow.log_metric() | Metrics | 評価指標を記録 |
| mlflow.log_metrics() | Metrics | 複数の評価指標を一括記録 |
| mlflow.set_tag() | Tags | タグ情報を記録 |
| mlflow.set_tags() | Tags | 複数のタグ情報を一括記録 |
| mlflow.log_artifact() | Artifact | Artifactを保存 |
| mlflow.log_artifacts() | Artifact | 複数のArtifactを保存 |
| mlflow.log_text() | Artifact | テキストファイルをArtifactとして保存 |
| mlflow.log_image() | Artifact | numpy.ndarray等を画像化してArtifactとして保存 |
| mlflow.log_figure() | Artifact | matplotlibやplotlyのFigureを画像化してArtifactとして保存 |
| mlflow.log_dict() | Artifact | jsonやyamlをArtifactとして保存 |
| mlflow.sklearn.log_model() | Artifact | Scikit-Learnの学習済モデルをMLflow Modelsの形式でArtifactとして保存 |
| mlflow.pytorch.log_model() | Artifact | PyTorchの学習済モデル(.pth)をArtifactとして保存 |
| mlflow.tensorflow.log_model() | Artifact | TensorFlowの学習済モデル(SavedModel形式)をArtifactとして保存 |
| 例えば、パラメータx_1に1を、パラメータx_2に2を、評価指標yに3を記録したい場合、以下のように実装します。 |
with mlflow.start_run() as run:
mlflow.log_param('x_1', 1)
mlflow.log_param('x_2', 2)
mlflow.log_metric('y', 3)
上記処理は、以下のように記述することもできます
with mlflow.start_run() as run:
mlflow.log_params({'x_1': 1, 'x_2': 2})
mlflow.log_metric('y', 3)
また、同じ評価指標(Metrics)を複数連続記録することもできます。
この機能は学習のEpochなど、同じ処理を複数回繰り返してスコアの推移を見たい場合を想定しているようです。
with mlflow.start_run() as run:
for epoch in range(0, 3):
mlflow.log_metric(key="quality", value=2*epoch, step=epoch)
後述のUIでグラフ表示することも可能です
3. Runの終了
Runを終了するには、mlflow.end_run()メソッドを使用します。
mlflow.end_run()
なお、with構文使用時はend_run()は不要であることにご注意ください(インデントを抜ければ自動でRunが終了する)
【手順4:参考】 実験管理のユースケース
上記手順でロギングを実施できますが、これだけではイメージがつき辛いかと思います。
実運用をイメージしやすいよう、いくつかユースケースを紹介します。
ユースケースA: シンプルなロギング
まずは動作のイメージを掴めるよう、重要情報であるParameters, Metrics, Artifactを1個ずつ記録する、シンプルな例を解説します。
with mlflow.start_run(experiment_id=experiment_id) as run:
# 実験条件(Parameters)
mlflow.log_param('x', 1)
# 評価指標(Metrics)
mlflow.log_metric('y', 2)
# その他のデータ(Artifacts)
features = 'rooms, zipcode, median_price, school_rating, transport'
mlflow.log_text(features, 'features.txt')
mlflow.log_param()メソッドで実験条件(Parameters)を
mlflow.log_metric()メソッドで評価指標(Metrics)を
mlflow.log_text()メソッドでテキストファイルをArtifactsとして
保存しています。
詳細は後述しますが、上記コードでRun実行後にUIを起動すると、以下のようにParameters、Metrics、Artifactsが記録されていることが分かります。

上例ではmlflow.log_text()メソッドを使用していますが、下例のようにテキストファイル出力後にmlflow.log_artifact()メソッドを実行しても同じ処理が実現できます。
# その他のデータ(Artifacts)
features = 'rooms, zipcode, median_price, school_rating, transport'
with open('features.txt', 'w') as f:
f.write(features)
mlflow.log_artifact('features.txt')
処理としては同じですが、mlflow.log_text()メソッドの方が短いコードで同様の機能(テキストファイル限定ですが)を実現できていることがわかります。
mlflow.log_text()メソッド以外にも、mlflow.log_image()(画像)やmlflow.sklearn.log_model()(Scikit-Learnの学習済モデル)等のArtifact保存を簡略化するメソッドが多数用意されています(前述)
ユースケースB: アンスコムの例における多項式回帰の次数評価
より実用的なケースとして、アンスコムの例において多項式回帰を行い、何次式で回帰すれば最もフィッティング性能が高くなるかを評価します。
アンスコムの例には、以下のように1〜4の4つのデータセットが含まれているので、評価指標をR2-Scoreとし、1次〜4次式で多項式回帰した際の指標をMLflowで記録します

from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 次数を指定して多項式回帰を実行するメソッド
def poly_regression(n, X, y, ax):
# テストデータ分割
X_train, X_test, y_train, y_test = train_test_split(X, y,
shuffle=True, random_state=42,
test_size=0.5)
# 多項式変換
pf = PolynomialFeatures(degree=n)
pf.fit(X_train)
X_train_poly = pf.transform(X_train)
X_test_poly = pf.transform(X_test)
# 回帰
lr = LinearRegression()
lr.fit(X_train_poly, y_train)
y_pred = lr.predict(X_test_poly)
# R2スコアで性能評価
r2 = r2_score(y_test, y_pred)
mlflow.log_metric(f'r2_degree{n}', r2) # スコアをMetricsとして記録
# グラフ作成
X_view = np.linspace(np.amin(X), np.amax(X), 200).reshape(200, 1)
X_view_poly = pf.transform(X_view)
y_pred_view = lr.predict(X_view_poly) # 回帰線を作成
ax.scatter(X_test.ravel(), y_test) # テストデータを散布図プロット
ax.plot(X_view.ravel(), y_pred_view, c='red') # 回帰線をプロット
ax.set_title(f'Degree={n}')
# 次数を変えてスコアを評価するメソッド
def validate_degrees(data, dataset_name):
# Runを開始
with mlflow.start_run(experiment_id=experiment_id) as run:
# データセットを選択
data_selected = data[data['dataset'] == dataset_name]
X = data_selected['x'].to_numpy().reshape(len(data_selected), 1)
y = data_selected['y'].to_numpy()
mlflow.log_param('dataset', dataset_name) # データセット名をParametersとして記録
# グラフ用のfig, axesを作成
fig, axes = plt.subplots(1, 4, figsize=(18, 4))
# 次数を変えてスコアを評価
for n in range(1, 5):
poly_regression(n, X, y, axes[n - 1])
# グラフをArtifactとして保存
fig.suptitle(f'Dataset={dataset_name}', size=16)
mlflow.log_figure(fig, f'figure_{dataset_name}.png')
plt.show()
# 全てのデータセットでスコアの評価を実行
data = sns.load_dataset('anscombe')
# データセット1の評価
validate_degrees(data, 'I')
# データセット2の評価
validate_degrees(data, 'II')
# データセット3の評価
validate_degrees(data, 'III')
# データセット4の評価
validate_degrees(data, 'IV')
上記コードでは、Runが4回実行(データセットごとに実行)され、それぞれのRun内で1次〜4次の多項式回帰を実施・スコアを記録しています。
コードを実行してUIを立ち上げると、以下のような画面が表示されます。
(下記の画面構成にするために操作が必要ですが、UIの解説時に詳説します)

上図のように、データセットやパラメータ(次数=degree)を変えた際のスコアの変化を一括で可視化することができるので、データセットやパラメータを変えた際の結果を比較したい時に、MLflowは有効なツールとなることが、わかるかと思います。
行ごとのStart Timeをクリックすると、Runごとの詳細画面が表示されます。
コードで記録したParameters、Metrics、Artifactsが表示されることが分かります。

最低限の記録内容としてParametersとMetricsがあれば十分ですが、上例のようにグラフをArtifactとして保存すると、結果を分かりやすく可視化できて便利です。
Metricsをクリックするとグラフ表示画面に遷移します。

グラフの種類は、mlflow.log_metric()でロギングした際に、単一の値を指定していたら棒グラフ📊が、step引数を指定して複数の値を指定していたら折れ線グラフ📉が表示されます
上記のデータセット2(データセットII)の場合では、1次式と比べて2次式のスコアが高くなり、3次式以上でも同様のスコアが維持される(性能に寄与しているのは2次の項ですが、3次式以上の式にも2次の項が含まれるため)事が分かります。
ユースケースC: パラメータチューニング
MLflowには、後述するようにメジャーな機械学習ライブラリに関して自動ロギングを実現できるメソッドが用意されています。
その中でも使用頻度が高いと思われる、パラメータチューニングの経過と結果をmlflow.sklearn.autolog()メソッドで記録する方法を紹介します。
パラメータチューニングの方法はいくつかありますが、今回は最もシンプルなグリッドサーチでの例を紹介します
チューニングの処理内容および使用したデータセットは**こちらの記事**を踏襲します。
・コード
以下のようなコードで、パラメータチューニングの結果を記録できます。
mport seaborn as sns
from sklearn.model_selection import GridSearchCV, KFold
from sklearn.svm import SVC
# データの読込とチューニング条件の指定
iris = sns.load_dataset("iris") # irisデータセット取得
OBJECTIVE_VARIALBLE = 'species' # 目的変数の指定
USE_EXPLANATORY = ['petal_width', 'petal_length', 'sepal_width', 'sepal_length'] # 説明変数の指定
y = iris[OBJECTIVE_VARIALBLE].values # 目的変数
X = iris[USE_EXPLANATORY].values # 説明変数
estimator = SVC() # 学習器(サポートベクターマシン)
cv = KFold(n_splits=3, shuffle=True, random_state=42) # クロスバリデーション(KFold)
scoring = 'f1_micro' # チューニングに使用するスコア(F1 Micro)
cv_params = {'gamma': [0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100],
'C': [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]} # チューニング用のパラメータ
# MLflowによるロギング開始
mlflow.sklearn.autolog()
with mlflow.start_run(experiment_id=experiment_id) as run:
# グリッドサーチのインスタンス作成
gridcv = GridSearchCV(estimator, cv_params, cv=cv,
scoring=scoring, n_jobs=-1)
# グリッドサーチ実行
gridcv.fit(X, y)
# 最適パラメータの表示
best_params = gridcv.best_params_
best_score = gridcv.best_score_
print(f'最適パラメータ {best_params}\nスコア {best_score}')
・実行結果のUI表示
上記コード実行後にUIを起動すると、以下のようにチューニング結果が表示されます

詳細は後述しますが、以下のようにチューニング結果に関するParameters, Metrics, Tas, Artifactsが記録されていることが分かります。

・mlflow.sklearn.autolog()の概要
mlflow.sklearn.autolog()でどのような情報が記録されるかを、公式ドキュメントをベースに解説します。
ロギングが実行されるタイミング
基本的には、学習器(SVCやRandomForestClassfier等のインスタンス)に対して、下記の学習用メソッドが実行されたタイミングでロギングが実行されます。
estimator.fit()
estimator.fit_predict()
estimator.fit_transform()
ロギングされるParameters
一般的に「ハイパーパラメータ」と認識されている変数(SVMにおけるCやgamma)以外にも、学習器クラスのプロパティとして指定可能な変数が全て記録されます
下図のように、APIリファレンスのParameters記載されている変数が記録されるとみなして良いかと思います。
(以下はSVRの例、赤枠のParametersが記録されます)

ロギングされるMetrics
学習データに対する各種評価スコアが記録されます。
以下のように、分類モデルと回帰モデルの場合でスコアが異なります
-
分類モデルの場合
Accuracy, Precision, Recall, F1
(Probability=Trueの場合log loss, roc_auc_scoreも追加記録) -
回帰モデルの場合
MSE, RMSE, MAE, R2-Score
ロギングされるTags
以下のように学習器のクラス名が記録されます

・チューニング用クラスにおけるロギング
チューニング用クラス(sklearn.model_selection.GridSearchCVおよびsklearn.model_selection.RandomizedSearchCV)においても、fit()メソッド実行時にロギングが実行されますが、
通常の学習器と挙動が異なるので、解説します。
チューニング用クラスにおいて実行されるRun
最終的なチューニング結果を記録したRunを親として、評価スコアが上位となったパラメータ(デフォルトでは上位5パラメータが記録されるようです)が子のRunとして記録されます。
詳細は前述のUIでの表示例が分かりやすいかと思います
チューニング用クラスにおいて記録されるParameters
以下の情報が記録されます
- 最適パラメータ(下図のbest_Cおよびbest_gamma)
-
GridSearchCVクラスのプロパティ(下図のcv, error_score, estimator...など、チューニング条件に関する情報)

チューニング用クラスにおいて記録されるMetrics
最適パラメータを渡した学習器best_estimatorに対して、分類モデルと回帰モデルの場合で異なるスコア(通常の学習器のときと同様)が記録されます
-
分類モデルの場合
Accuracy, Precision, Recall, F1
(Probability=Trueの場合log loss, roc_auc_scoreも追加記録) -
回帰モデルの場合
MSE, RMSE, MAE, R2-Score

チューニング用クラスにおいて記録されるTags
チューニングに使用したクラス名が記録されます

チューニング用クラスにおいて記録されるArtifacts
以下の情報がArtifacts記録されます
- 最適パラメータを渡した学習器
best_estimatorのMLflow Modelsフォーマットでの保存データ - チューニングに使用した
GridSearchCVインスタンスのMLflow Modelsフォーマットでの保存データ - チューニング履歴のCSVファイル※1
- 混同行列(分類タスクのみ)※2

※1: チューニング履歴のCSVファイル

※2: 混同行列

※mlflow.sklearn.autolog()使用時の注意点
-
Scikit-Learn公式のチューニング用クラス以外には非対応のため、Optuna等で使用したければ自分でロギング用のコードを作成する必要があります。
-
mlflow.sklearn.autolog()は、パラメータチューニングのような重い処理と同時実行すると所要時間が増加(私の環境では2〜3倍程度まで増加)してしまうので、速度を重視するのであればmlflow.sklearn.autolog()は使用せず、チューニング実行後に必要情報のみロギングした方が良いかと思います。
上記問題に対処する(速度低下防止&Optuna対応)パラメータチューニング用のライブラリを個人的に開発中なので、公開まで暫しお待ちいただければと思います。
その他の自動ロギングメソッド
上記のmlflow.sklearn.autolog()以外にも、メジャーな機械学習ライブラリ(TensorFlow、Pytorch等)に関して自動ロギングを実現できるメソッドが用意されています。
詳細は以下を参照ください
特殊なRunの実行方法
複数のRunを同時実行したり、Runをネストさせる構成も実現できるようです。
公式ドキュメントでは、以下のようにあるRunの下位で別のRunを実行するネスト構成の例が示されています
with mlflow.start_run(run_name='PARENT_RUN') as parent_run:
mlflow.log_param("parent", "yes")
with mlflow.start_run(run_name='CHILD_RUN', nested=True) as child_run:
mlflow.log_param("child", "yes")
前述のパラメータチューニングでの親子Runもネスト構成の一例です
手順5. 結果表示UIの立ち上げ
MLflowには、記録した結果をブラウザ上で表示する機能があります。
内部的にはWebサーバを立ち上げることとなるのですが、MLflowではこの立ち上げを簡単なコマンドで実現することができます。
手順2で選択したシナリオにより、方法が異なるため、それぞれ解説します。
シナリオ1: デフォルト設定の場合
トラッキングを実行したフォルダ(=mlrunsフォルダの上位フォルダ)にコンソール(PowerShellやターミナル)で移動し、以下のコマンドを打ちます
mlflow ui
これでトラッキングサーバのUIが起動するので、
Chrome等のブラウザのアドレスにhttp://127.0.0.1:5000と打てば結果表示UIが表示されます
シナリオ1: バックエンド、Artifactストレージを明示的に指定した場合
トラッキングサーバに指定したフォルダ(=mlrunsフォルダの上位フォルダ)にコンソールで移動し、以下のコマンドを打ちます
mlflow ui
これでトラッキングサーバのUIが起動するので、
Chrome等のブラウザのアドレスにhttp://127.0.0.1:5000と打てば結果表示UIが表示されます
シナリオ2: MLFlow on localhost with SQLiteの場合
トラッキングサーバに指定したフォルダ(=mlruns.dbがあるフォルダ)にコンソールで移動し、以下のコマンドを打ちます
mlflow ui --backend-store-uri sqlite:///mlruns.db
これでトラッキングサーバのUIが起動するので、
Chrome等のブラウザのアドレスにhttp://127.0.0.1:5000と打てば結果表示UIが表示されます
シナリオ3: MLflow on localhost with Tracking Serverの場合
Dockerfileにmlflow uiコマンドが記載されているので、コンソール側からの起動は不要です。
Chrome等のブラウザのアドレスにhttp://127.0.0.1:5000と打てば結果表示UIが表示されます(ポート番号を5000以外に設定した場合はそのポート番号を代わりに入力してください)
シナリオ4: MLflow with remote Tracking Server, backend and artifact stores
Dockerfileにmlflow serverコマンドが記載されているので、コンソール側からの起動は不要です。
Chrome等のブラウザのアドレスにhttp://[リモートサーバのIP]:5000と打てば結果表示UIが表示されます(ポート番号を5000以外に設定した場合はそのポート番号を代わりに入力してください)
なお、リモートサーバのファイアウォールで5000番ポートを開けておくよう注意してください
UIの操作法
前述のユースケースBの例をベースに、UIの操作法について解説します。
(ユースケースCの例もご参照頂くと、理解が進むかと思います)
エクスペリメント一覧画面
まず、ブラウザでMLflow UI画面を開くと、以下のようなエクスペリメント一覧画面
画面左側から閲覧したいエクスペリメントを選択します

エクスペリメント内のRun一覧が表示されますが、このままだと列が多すぎて肝心のParametersやMetricsが見えないので、「Columns」ボタンで列を絞ります。

不要な列のチェックを外します(基本的にはStart Time、Parameters、Metricsを残せば十分だと思います)

だいぶ表示がスッキリしました。MetricsやParametersはデフォルトでは最大3列しか表示されませんが、折り畳みボタンを押すと全て表示されることが可能です。
また、Start Timeの列をクリックするRunごと詳細画面に入れます。

Runごと詳細画面
Runごとの詳細画面を開くと、最初は以下のように表示されます。

Artifacts内のファイルをクリックすると、プレビューが表示されます(画像、CSV、テキスト等が表示可能)

Parameters, Metrics, Tagsはデフォルトでは折り畳まれていますが、クリックで表示させることができます

Metricsの「Name」をクリックするとグラフ表示画面に入ります。
グラフ表示画面
以下のようなグラフが表示されます。
mlflow.log_metric()でロギングした際に、単一の値を指定していたら棒グラフ📊が、step引数を指定して複数の値を指定していたら折れ線グラフ📉が表示されます。

まとめ
・MLflowは機械学習のライフサイクル管理(MLOps)向けライブラリの代表格
・4種類の機能(Tracking, Projects, Models, Model Registry)を備えるが、実験管理用途のMLflow Trackingが特によく使用される
・MLflow Trackingは、パラメータやデータを変更した場合の性能変化を記録したい場合に便利
・多様なサーバ構成を選択可(本記事ではシナリオ1〜4として解説)
・Scikit-LearnやPytorch等の有名ライブラリには自動ロギング機能が準備されている
サンプルコード
以下のGitHubにサンプルコードをアップロードしているので、ご参照ください
(有用だと思われた方は、Star頂けると励みになります!)
サンプルコードは以下のような構成になっています。
| シナリオ1 (デフォルト設定) |
シナリオ1 (別フォルダ指定) |
シナリオ2 | シナリオ3 | シナリオ4 | |
|---|---|---|---|---|---|
| サーバ側のフォルダ | /scenario1_default | /scenario1_local | /scenario2_sqlite | /scenario3_trackingserver /server | /scenario4_remote /server |
| クライアント側のフォルダ | サーバ側と同じ | サーバ側と同じ | サーバ側と同じ | /scenario3_trackingserver /client | /scenario4_remote /client |
| コード実行例 (ロギングのみ) |
a_log_simple_default.py | a_log_simple_local.py | a_log_simple_sqlite.py | a_log_simple_trackingserver.py | a_log_simple_remote.py |
| コード実行例 (多項式回帰の次数) |
b_log_anscombe_default.py | b_log_anscombe_local.py | b_log_anscombe_sqlite.py | b_log_anscombe_trackingserver.py | b_log_anscombe_remote.py |
| コード実行例 (パラメータチューニング) |
c_log_tuning_default.py | c_log_tuning_local.py | c_log_tuning_sqlite.py | c_log_tuning_trackingserver.py | c_log_tuning_remote.py |
シナリオ3、シナリオ4では、サーバ側のDocker Composeをdocker-compose runで立ち上げた状態で、クライアント側で「コード実行例」のコードを実行してください