対象読者
こんな人に向いてます
- Transformerを知らない人
- 私も全く知らずに調べました!なんにもわからない人の目線で書きます!
- 想定される疑問を載せてます!
- 多層パーセプトロンは知っているけど、それ以降出てきたいろんな用語についていけなくなった人
- いつも知らない言葉を含んだ図ばかりで結局詳細がよくわからないって思っている人
- 図に式も載せて式を見ればやっていることがわかるようにしました!
- 結局解説サイトを読んでもどう動くかわからない人
- 実際に軽いデータでTransformerを動かしてみたい人
- 軽く動かせるNotebookを用意してます!
ミスがあればご指摘くださると幸いです。
Transformer
自然言語処理で大活躍している手法。
- 機械翻訳
- テキスト要約
- 文章生成
- 文書カテゴリの分類
最近では、画像データやテーブルデータ(時系列データ)でも活躍しているようだ。
系列データに強そうなイメージ!
全体イメージ
モデルの動作イメージを機械翻訳を例に「学習」と「推論」の観点で見ていきます。
まずは、「Encoder」と「Decoder」という変換器があるんだなぁくらいにイメージを持ってもらい、動作のイメージをつかんでいきます。
後にその中身に入っていきます。
学習時
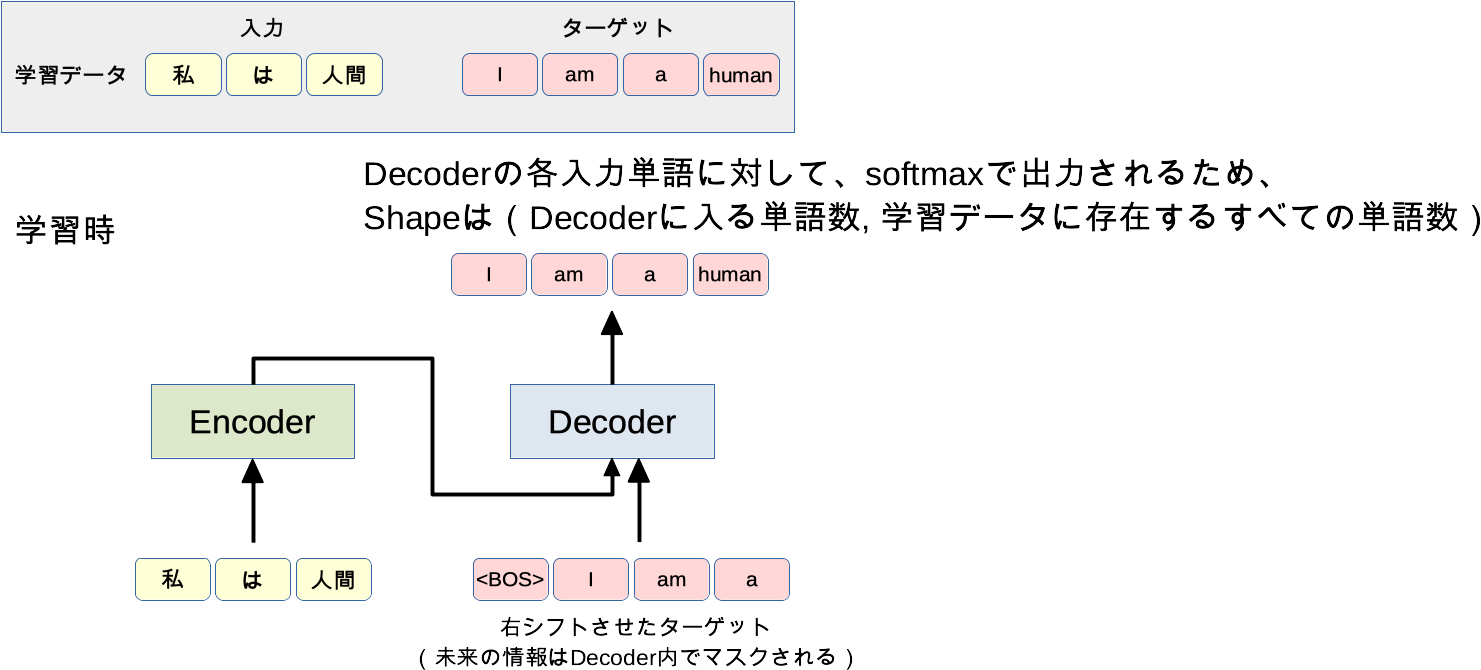
<BOS>: 開始を表す特殊文字。
Q&A
- 各単語はどうやって処理されるの?
- 単語はそれぞれベクトル表現に変換されます(word2vecなど)。
- ベクトル表現に埋め込まれるのでEmbeddingと呼ばれます。
- 学習時に時系列のためのループが必要?
- 不要です。
- これまでの時系列予測モデル(LSTM、RNN)と異なり、同時に次時点の予測を学習します。
- たとえば
Iにとってamとaは未来の情報なので、Decoder内で見えないように隠しながら学習します。
- バッチで学習するときに単語の長さは揃えないといけない?
- テンソルを作るために、バッチ内の単語数は揃えないといけません。
- 足りない単語数分は特殊文字で埋めて対応します。
- Decoderの出力はどうやって単語になるの?
- Decoderの直接の出力は
Decoderへの入力単語数xすべての単語数の行列です。 - 候補となる単語の確率が入っているので、最も高い確率の単語を取ってこれば単語に変換できます。
- クラス分類のときのSoftmaxと同じだと思うとイメージしやすいです。
- Decoderの直接の出力は
| a | am | ... | human | ... | I | ... | |
|---|---|---|---|---|---|---|---|
| 1単語目 | 0.01 | 0.01 | ... | 0.02 | ... | 0.7 | ... |
| 2単語目 | 0.02 | 0.8 | ... | 0.01 | ... | 0 | ... |
| 3単語目 | 0.75 | 0 | ... | 0.01 | ... | 0.01 | ... |
| 4単語目 | 0 | 0.02 | ... | 0.9 | ... | 0.01 | ... |
推論時
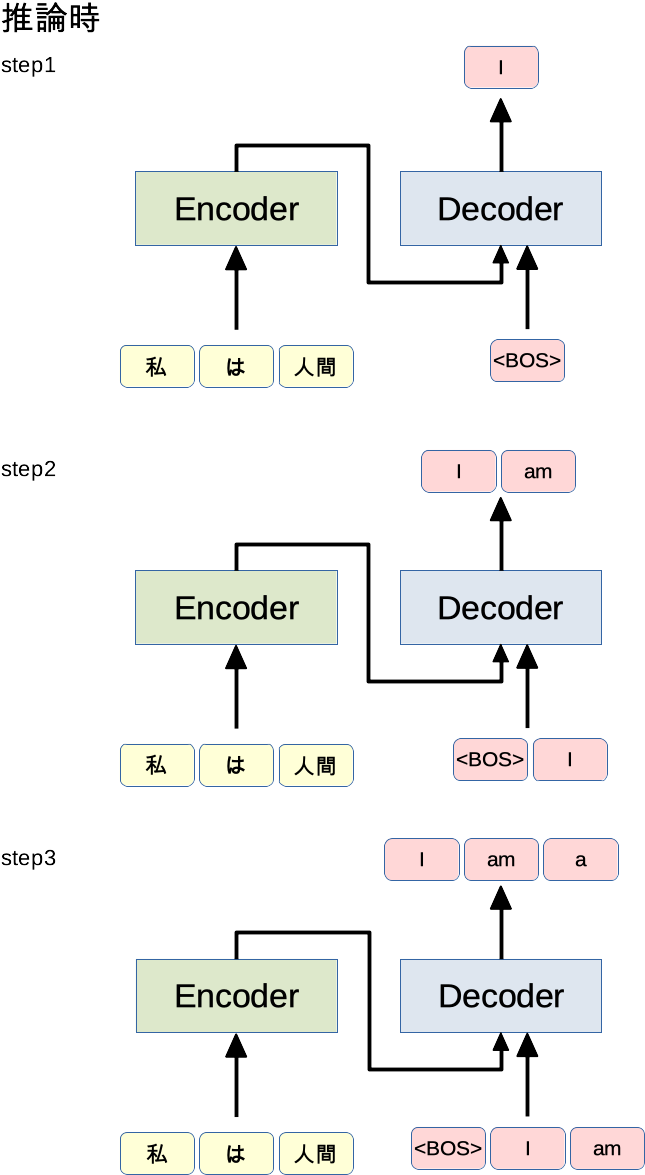
学習時と異なり順次予測していきます。
Q&A
- どこまでstepをやるの?
-
<EOS>(終了文字)が出るまで。-
<EOS>を含めて学習していれば出力されるはず! - 文の場合
.ピリオドとかでもいいかも。
-
-
- Decoderに入れる単語数と出力の単語数(図の赤の部分)は等しい?
- 等しいです。
- step1の出力とstep2の出力が違うこともある?(この例だと「I」について)
- あるけど、最終的な予測としては最終stepの結果しか使わないため問題にならない
詳細イメージ
学習と推論のイメージができたところで、EncoderとDecoderの中身を見ていきます。
論文にはこのような図が載っていますが、ニューラルネットに慣れていない人からすると何やっているかわからないんですよね。
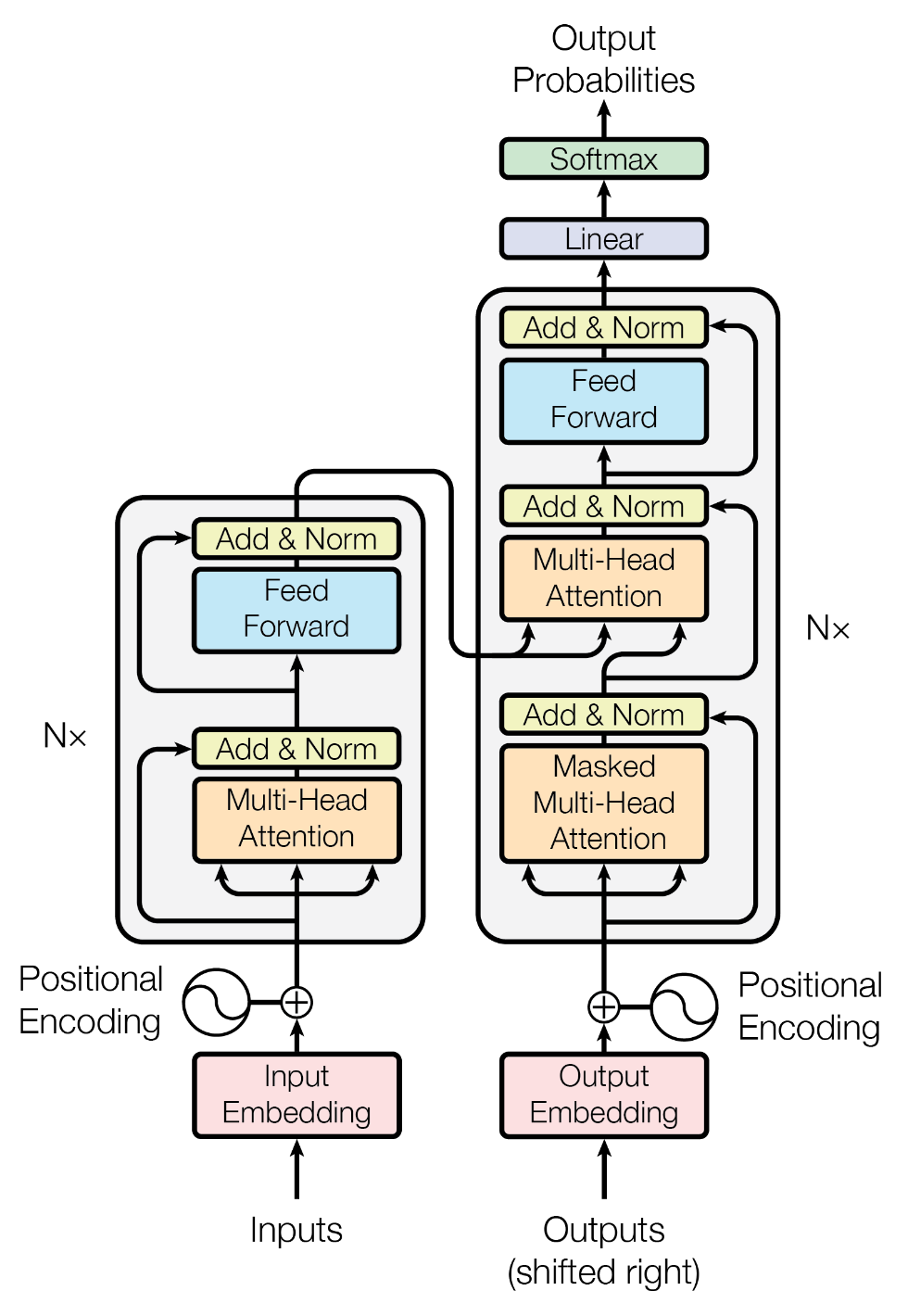
ということで図に式を載せながら何をやっているか確認していきます。
※コメントでいただいたご指摘を修正(2021/04/13)
Encoder
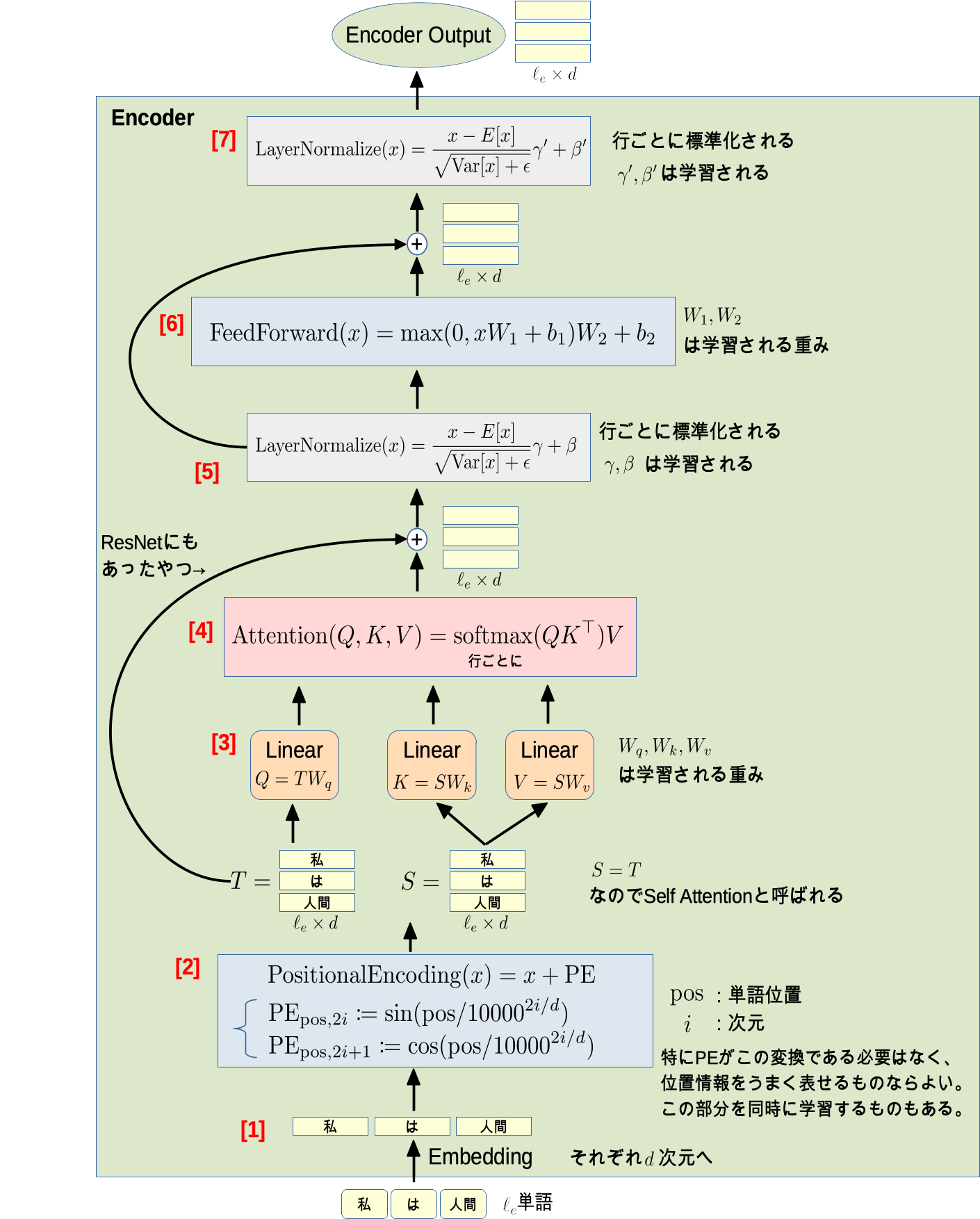
図を見れば何をやっているかわかると思いますが、一応説明します。
- [1] $\ell_e$個の単語それぞれが$d$次元ベクトルに変換されます
-
[2] 単語の位置情報(各単語が何番目に現れたか)が埋め込まれます
- 位置情報が表現できればどんな変換でもOK
- この部分を学習するものもある
- [3] $\ell_e \times d$の行列を重み$W_q,W_k,W_v$で線形変換します
-
[4] $QK^\top$の各行をsoftmax取った行列に$V$を掛けます
- ここは単純化しているので後述します
- [5] 各行ごとに標準化(平均引いて標準偏差で割る)したものを$\gamma$倍して$\beta$を足す
-
[6] 行列を線形変換後、0とのmaxを取って、再び線形変換
- 0とのmaxをとる活性化関数をReLUといいます
- [7] [5]と同様。
やっていることを式で追うと非常に単純ですよね。
ちょいちょい関数挟まるけど、基本的に行列の積を計算しているだけ!
なんでこんな事やるんだろうというところはAttentionの部分かと思いますが、これは後に図で説明します。
(他はニューラルネットでよくある線形変換+活性化関数や標準化ですね。)
Decoder
図の大きさに圧倒される必要はありません。Encoderと同じような流れがあります。
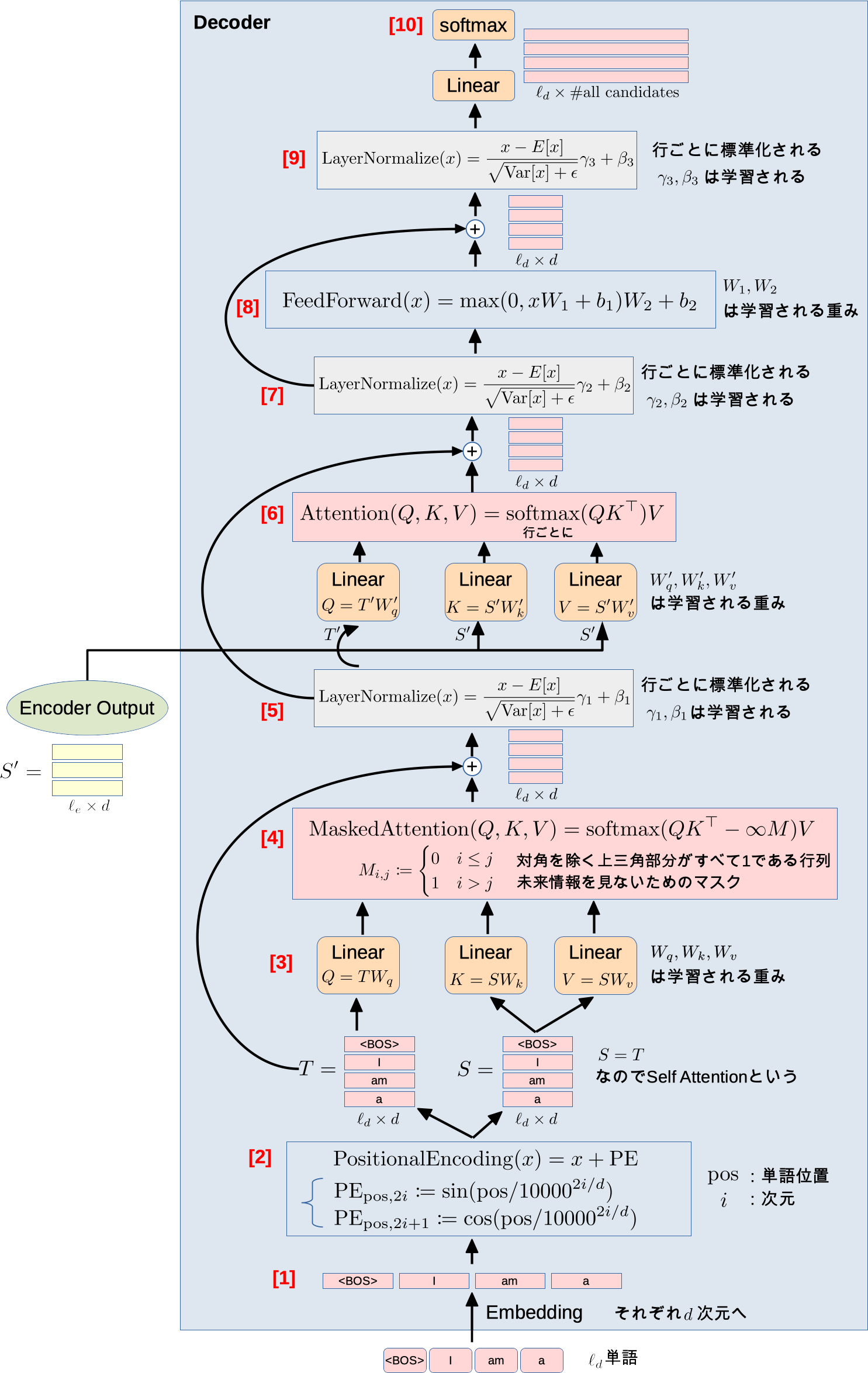
- [1],[2],[3] Encoderの最初の流れと同じです
-
[4] Encoderのときと違うのは$-\infty M$があることです
- これで未来の情報を見えなくしてます
- softmaxにある指数部分が$-\infty$になることで情報を消してます($e^{-\infty}=0$)
- $M$のイメージ:
<BOS> |
I |
am |
a |
|
|---|---|---|---|---|
<BOS> |
0 | 1 | 1 | 1 |
I |
0 | 0 | 1 | 1 |
am |
0 | 0 | 0 | 1 |
a |
0 | 0 | 0 | 0 |
- [5] 各行ごとに標準化です
- [6] Decoder内で計算した行列を$Q$、Encoderの出力を$K,V$にして、この計算を行います
- [7],[8],[9] Encoderの最後の流れと同じです
- [10] 直前の線形変換で次元数をすべての候補単語数にしたあとに、softmaxをとって確率にします
Decoderでも特に数学的に難しいところはありませんでした。
すべて式で書くとやっていることがクリアになってスッキリしますね。
Attention
最後にこのモデルの気持ちを理解するためにAttentionを説明します。
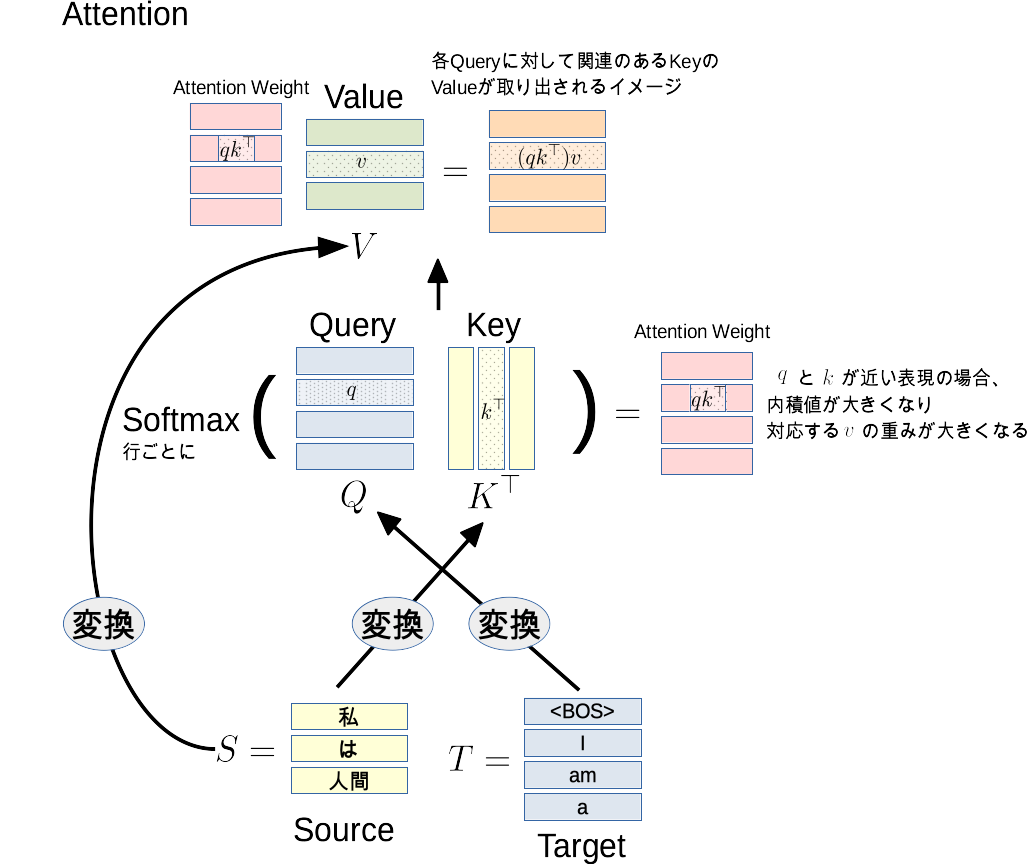
Attentionでは、Query $Q$、Key $K$、Value $V$という概念があります。
これは連想配列(Pythonのdict、C++のmapなど)を連続化したものと認識すればよいです。
連想配列は、あるキー$k$に対して、対応する値$v$を返しますが、Attentionでは$q$と$k$の内積$q k^\top$でキーとの関連度を計算して、これを重みとした加重平均で値が引き出されます。
内積の値が大きい(関連度が高い)ものが優先的に重視されて引き出されるイメージです。
Attentionの気持ちは、「あの単語が来たらこの単語の値を使えばいい!」っていうのを学習しているイメージです。
これまでの説明の図では場所を取るため省いていましたが、次のような工夫があります。
Scaled Dot-Product Attention
$$
\mathrm{ScaledAttention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V
$$
内積値は次元が大きいほど値が大きくなりがちです。
そうなると逆伝播するときに勾配がサチってしまいます。
そこで次元数$d$の平方根で割るということをしています。
Multi-Head Attention
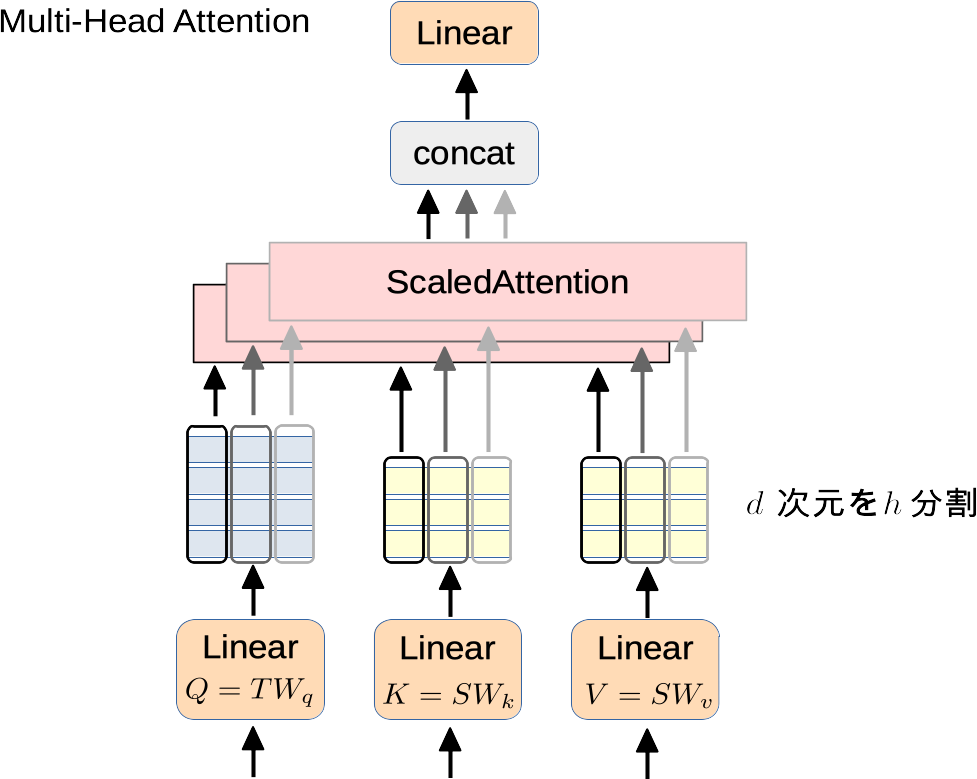
$Q,K,V$それぞれを図のように$h$分割して、それぞれにAttentionをした結果をつなげて使うというものです。
実験的に精度が上がることが示されました。
また、論文では適当な箇所にDropoutを挟んで汎化性能を上げていました。
内容を理解した今、この図を見ると抵抗ないかと思います。
論文ではNxと書かれているように、このグレーの箇所を任意回繰り返すのが良いことも書かれています。
実際に動かしてみる
ここまででTransfomerを理解できたと思います。
では実際に動かしてみよう。
今回は自然言語ではなく、Kaggleで行われたRiiidコンペを例にNotebookを用意しました。
Notebookはこちら (Kaggleアカウントを作ればその場で動かせます)
ソースコードの解説はNotebookの方のコメントでやってます。
PyTorchがわからない方はクイックPyTorch入門をどうぞ。
Qiitaではイメージをつかむための画像だけ載せておきます。
Riiidコンペとは
TOEICの問題を受けた学生がその問題を正解できるか予測するコンペです。
このコンペの上位解法にはTransfomerベースの手法が多くありました。(これを機に勉強しようと思いました。)
| timestamp | user_id | content_id (問題ID) |
answered_correctly (正解:1, 不正解:0) |
|---|---|---|---|
| 0 | 115 | 5692 | 1 |
| 56943 | 115 | 5716 | 1 |
| 118363 | 115 | 128 | 1 |
| 131167 | 115 | 7860 | 1 |
このような形式のデータで、ユーザーごとの時系列データとみなすことができます。
単純なモデル
普通に思いつきそうなTransformerを作ってみる。
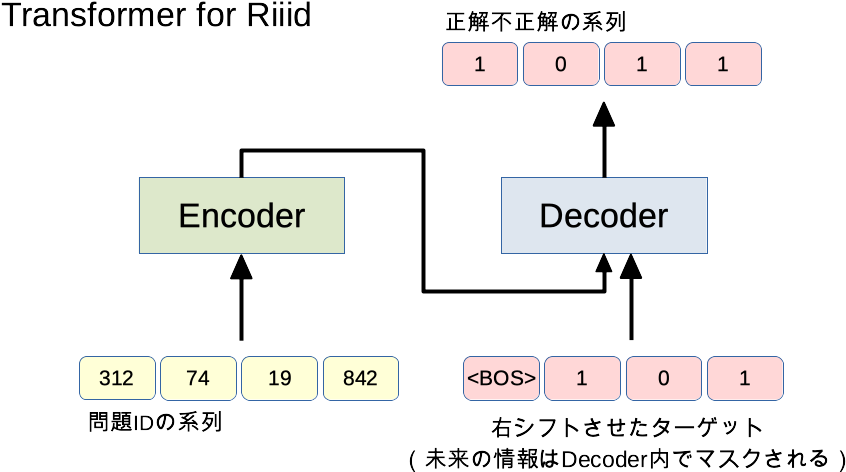
機械翻訳の例に当てはめて考えてみると、こんな感じですかね。
SAKT model
※コメントでいただいたご指摘を修正(2021/04/11)
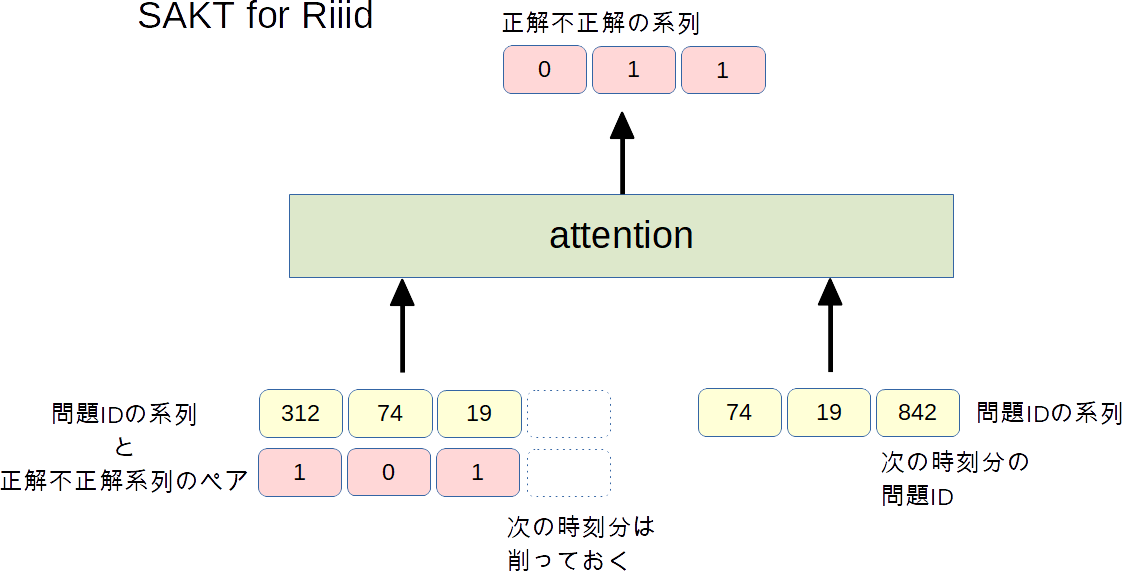
- A Self-Attentive model for Knowledge Tracingというものがあるらしい
- Encoder/Decoderモデルではなく, 「問題IDと正解不正解の系列をペア」と「問題ID」をAttentionするモデル
Kaggleに参加する人たちはよく論文を探してくるなぁと関心します。
参考資料
-
作って理解する Transformer / Attention
- とてもわかりやすい解説でした
論文解説 Attention Is All You Need (Transformer)-
attention-is-all-you-need-pytorch
- 見やすかったpytorchの実装
- 論文
-
Transformerのデータの流れを追ってみる
- 記事を書いた後に見つけましたが理解が深まります