はじめに
皆さんはじめまして@bantarouです。
Qiita初投稿なのでお手柔らかにお願いします。
最近ようやく念願のGPUを手に入れたのでpix2pixで遊んでいます。
なので、pix2pixに関する記事を読んでいるのですが線画を着色したり、線画からカラー画像を作成してみたり、といった線画を加工して何かを作成する話はよく聞くのですが、逆に線画自体を作成する話が殆どされていないのが気になりました。 (私が見逃している可能性も高いですが…)
そこで、今回はpix2pixを使ってカラー画像から線画を作成するモデルの作成と検証を行いたいと思います。
あっ、ここまで読んで頂いて、pix2pixって何?と思われた方はこの記事を読んでいただけると、一体どういうものか理解していただけると思います。 (要は解説丸投げ…)
実行環境
- OS: Ubuntu16.04 LTS
- GPU: GTX1060 3GB
- CUDA: 8.0
- cuDNN: 7.0.5
- Tensorflow-gpu: 1.4.1
- Python: 3.5.2
- OpenCV: 3.4.0
教師画像について
変換先として学習する線画ですが、この記事の膨張1回の欄を参考に、Python3でOpenCVライブラリを使って作成しました。
以下の画像のように、元々の画像と線画の画像を結合して、pix2pix用の教師画像を作成しました。
以下の教師画像の例ですが、画像の左側が元々の画像で右側が変換先となる線画となっています。

以下のコードは学習用の教師画像を作成するために書いたコードです。
./origin/以下の.jpgファイルを片っ端から線画変換して教師画像の作成し、./train/以下に保存します。
import os
import sys
import cv2
import numpy as np
from pathlib import Path
img_path_list = Path('./origin/').glob('*.jpg')
img_path_list = map(str, list(img_path_list))
time_cnt = 0
kernel = np.ones((5,5),np.uint8)
img_width = 400
img_height = 400
for img_path in img_path_list:
#Input Image
img = cv2.imread(img_path, 1)
#Cutting Image
if len(img[0]) < len(img):
h = int(img_height / len(img[0]) * len(img))
w = img_width
else:
h = img_height
w = int(img_width / len(img) * len(img[0]))
if len(img[0]) < img_width or len(img) < img_height:
continue
img = cv2.resize(img, (w, h))
cut_img = img[:img_height, :img_width]
mono_img = cv2.cvtColor(cut_img, cv2.COLOR_RGB2GRAY)
#Create Line Drawing
dilate_img = cv2.dilate(mono_img, kernel, iterations=1)
diff_img = cv2.absdiff(mono_img, dilate_img)
diff_not_img = cv2.bitwise_not(diff_img)
diff_not_img = cv2.cvtColor(diff_not_img, cv2.COLOR_GRAY2RGB)
#Output Image
if not os.path.exists("./train"):
os.mkdir("./train")
time_cnt += 1
marge_img = cv2.hconcat([cut_img, diff_not_img])
cv2.imwrite("./train/fix_" + str(time_cnt) + ".jpg", marge_img)
教師画像の学習
今回は、手元にあった100枚の猫の画像を元に教師情報を作成してpix2pixで学習を行いました。
pix2pixのソースコードですが公式のコード(https://github.com/phillipi/pix2pix) をそのまま利用しました。
そして、以下のように公式の説明どおりに指定して学習させました。
python3 pix2pix.py --mode train --output_dir <学習モデルの出力先> --max_epochs 100 --input_dir <教師画像の保存先> --which_direction AtoB
学習したモデルでのテスト
以下のように公式その説明どおりの使い方で、学習したモデルから線画の作成を行いました。
python3 pix2pix.py --mode test --output_dir <生成画像の出力先> --input_dir <入力する画像の保存先> --checkpoint <学習モデルの出力先>
作成した画像ですが百聞は一見に如かずだと思うので、まずは以下の画像をご覧ください。
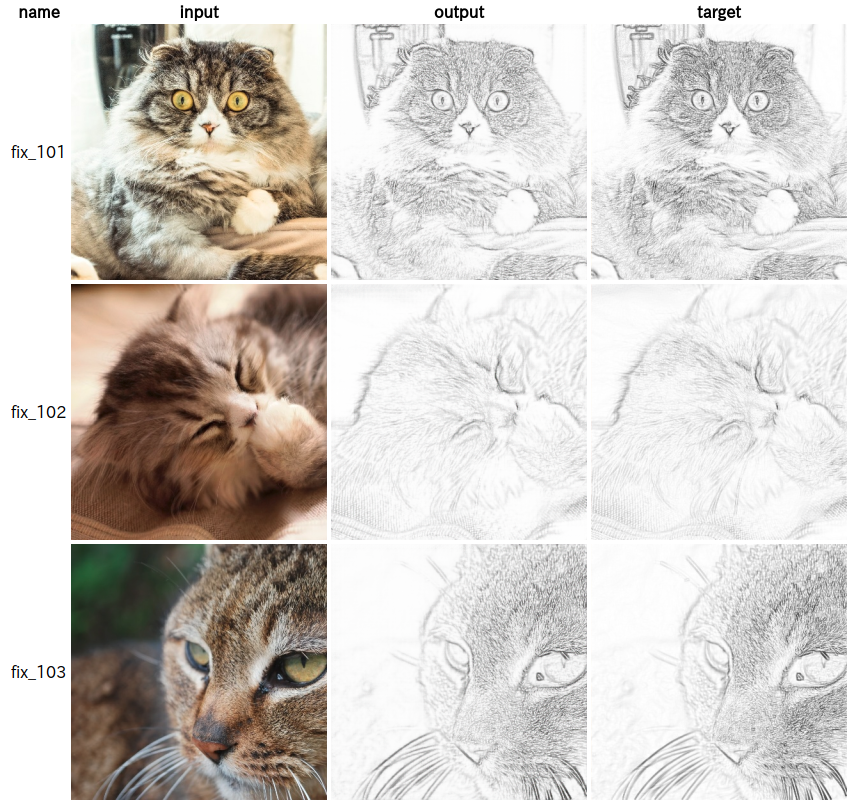
左の画像から順に、入力画像、出力画像、OpenCVで線画変換を行った画像となっています。
こうして見ると改めてpix2pixの凄さが分かりますね。
てっきり出力画像が滲んだりするかと思いましたがそんな事もなく、outputの画像がtargetの画像とほぼ一致しています。
また、今回は猫の画像だけを学習に使ったので、猫以外の画像を入力して線画の作成を行った際どのようになるか検証してみました。
検証の結果は以下の画像の通りです。

とりあえず、レナさんの画像とゴーファーくんの画像を食べさせてみたのですが、これもうまい事線画に変換できていることが分かると思います。 (レナさんの顔面から毛が生えてるみたいな面白い結果にならなかったのでちょっと残念)
結果から、pix2pixによって、猫の画像だけという偏ったデータからでも画像から線画に変換するモデルを形成できている事が確認できました。
恐らく、猫の画像から線画へのモデルを構築したというよりも、画像の局所部分を線に変換するモデルを構築したため、このような結果になったのだと考えております。
おわりに
今回のpix2pixを使ってカラー画像から線画を作成するお話ですが、普通に綺麗な線画が出力されるという意外性のない結果に落ち着きました。
最初に、pix2pixを使って線画を作成する話をあまり見かけなかったみたいな話をしたと思いますが、意外性が皆無な結果なため、誰も手をつけないor発表して来なかったのでは?と邪推してます。 (後はわざわざpix2pixを使って線画を作る必要が無いとかも理由かも)
とりあえず疑問に思っていた事を検証できたので、個人的に今回の結果は満足でした。
間違い等がございましたらご指摘よろしくお願いします。