概要
- 先日発表されたpix2pixが楽しそうだったので実際に動かしてみた。
- 対象を絞れば学習画像が500枚程度でもそれなりに動く。
- 結論:GANすごい。
はじめに
pix2pixとは、ざっくりと言えば、2画像間に潜む画像変換をDNNで表現してしまおう!というものです。変換前後の画像さえ用意できれば大体どんな変換でも対応可能らしく、例えば以下のようなことが可能らしいです。
- 航空写真 → 地図画像
- モノクロ画像 → カラー画像
- 線画 → カラー画像
- (上記すべて逆も可能)
何やら万能っぽい雰囲気!素晴らしいことにコードが公開されている(torchだけど)!しかも自前画像でも簡単に試せそう!
ということで試してみました。
データ
flickrから収集したラーメン画像(1,000枚)を使用。多少のゴミは無視で。公式のソースコードに合わせて、各画像を中心でクロップ&リサイズしておき、学習画像と評価画像は各500枚としました。
試した画像変換は「モノクロ画像 → カラー画像」です。
追記:「線画 → カラー画像」も試しました。線画は元画像にblurやらcannyやらをかけて適当に作りました。
実験条件
公式のソースコードそのままで変えていません。
結果
実行環境はUbuntu16.04+GTX1060。買ってて良かったGPU。
評価結果の一部を以下に載せましたが、学習画像が500枚しかないことを考えると驚くべき結果が出ているように思います。
モノクロ画像 → カラー画像
| 入力 | 出力 | 正解 | 感想 |
|---|---|---|---|
 |
 |
 |
あまり違和感ない |
 |
 |
 |
あまり違和感ない |
 |
 |
 |
肉味噌がネギ化している・・・ |
 |
 |
 |
つけ麺もOK |
 |
 |
 |
テーブルの木目調も頑張ってる |
追記 : 線画 → カラー画像
明らかに無茶な問題設定ですね。やっぱりモノクロ画像のカラー化に比べると出来があまり良くないです。・・・でも、この入力画像からこの出力が出せているのは凄くないですか?(親心)
学習の経過を見ているとまだまだ学習できそうな印象です(DCGANの途中結果っぽい)。デフォルトだと200epoch回す設定なんですが、もう少し増やしてみても良かったかもしれません。
| 入力 | 出力 | 正解 | 感想 |
|---|---|---|---|
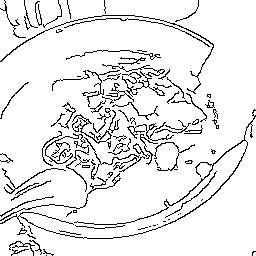 |
 |
 |
海苔どこいった? |
 |
 |
 |
正解画像とは違うけど結構自然っぽい? |
 |
 |
 |
幽体離脱・・・ |
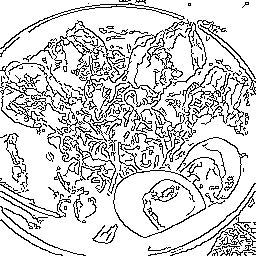
 |
 |
 |
こっちは麺がネギ化してる。ネギ麺。 |
 |
 |
 |
テーブルの情景を頑張って描こうとしているっぽい。けなげ。(親心) |
さらに追記
「結果が出来すぎてる。学習データ入れたんじゃね?」「500枚少なすぎじゃね?」というもっともな声を随所で見かけたので、コメント。
- TrainとTestはいちおう分けています。分けていますが、ラーメン画像にそもそもバリエーションが少ないので、よく似た画像は含まれていると思います。
- 他の料理とか動物とかを混ぜると、この枚数では上手くいかないと思います。冒頭に「対象を絞れば」と書いたのは、そのためです。
- 被写体の位置が変わるタイプの変換は苦手だと思います。単純に上下flipでも壊滅しそう。
- ちなみに、公式サンプル(ラベル画像→建物)では、Trainはたった400枚です。
- 学習データ数が少なくてもそれなりに上手くいく理由は、ラーメン画像の多様性が少ないから、被写体の位置が変わらない変換をやっているから、入力が乱数ではなく画像だから、等々雑に考察しております。詳しい方がいらっしゃいましたらコメント頂きたいです。
- 参考までに、学習データの結果は↓です。「線画→カラー画像」は学習データの割にそんなに上手くいってないです(謎)。。
学習データの結果
| 入力 | 出力 | 正解 | 感想 |
|---|---|---|---|
 |
 |
 |
やや赤みがかっているが、丸暗記の勢い。 |
 |
 |
 |
丼の色を間違えているが、丸暗記の勢い。 |
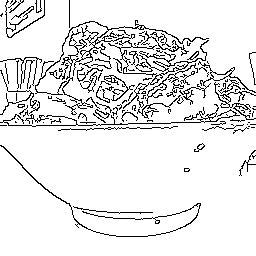
 |
 |
 |
色味は丸暗記してそう。でも学習データの割にショボい。 |
 |
 |
 |
色味は丸暗記してそう。でも学習デー(ry |
おわりに
- 簡単・便利・楽しい。万能感ありますね。
- OpenImagesの画像をぶち込んでみたい。
-
論文をざっと見た感じあまり特別なことはしていないようなのでchainerとかで書いてみようかなぁ。でも誰かがやってそうだなぁ。
→chainer実装が公開されてました!感謝!これでもっと自由に遊べますね。 - 変換の種類を潜在変数的なアレで何やかんやすれば、複数の画像変換を同時に行うモデルも作れそう?
- MSCOCOのマスク画像を使って実験中です。面白い結果が出たら新たに投稿します。
結論:GANすごい。