自前データでGoogle Colabでyolov5を訓練してローカルで実行する覚え書き(2022.8.3)
ブログはじめました medical なことをpythonで処理していきます
medical-python
こちらもチェックしてください
初めての記事投稿になります。
yolov5モデルを自前データでやりたいが、コードはできるだけ書きたくない方向けです。
マウス操作でできる事を重視してかきましたが、最後にモデルの選択で少しだけプログラムの書き換えが必要です。
1.自前データのラベリング(labelimg使用)
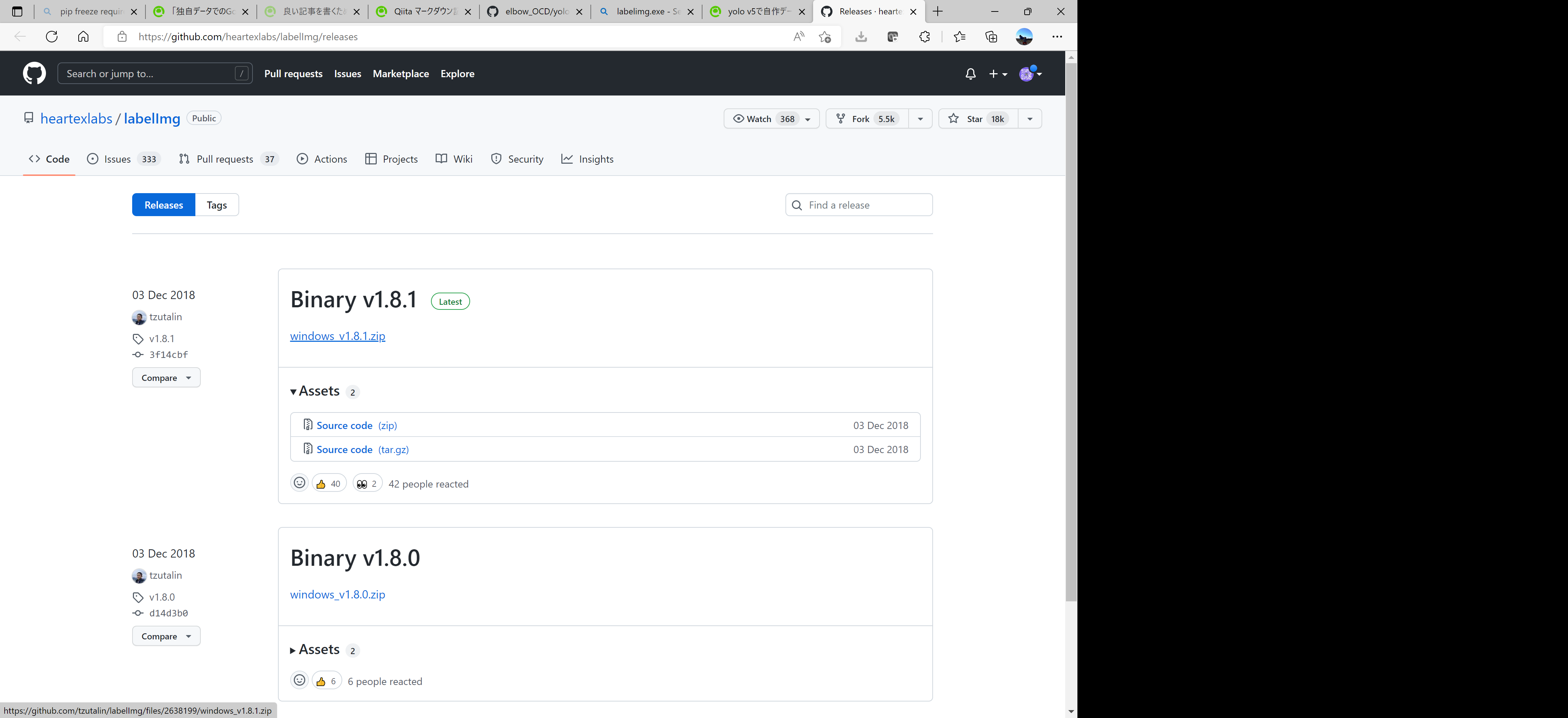
1-1:以下のサイトにアクセス
https://github.com/heartexlabs/labelImg/releases
windows_v1.8.1.zipをダウンロードして任意のフォルダで解凍する
1-2:predefined class.txtの書き換え
dataフォルダの中に、predefined classes.txtというファイルがある、これをメモ帳で開く
クラス名を以下のように書き換える
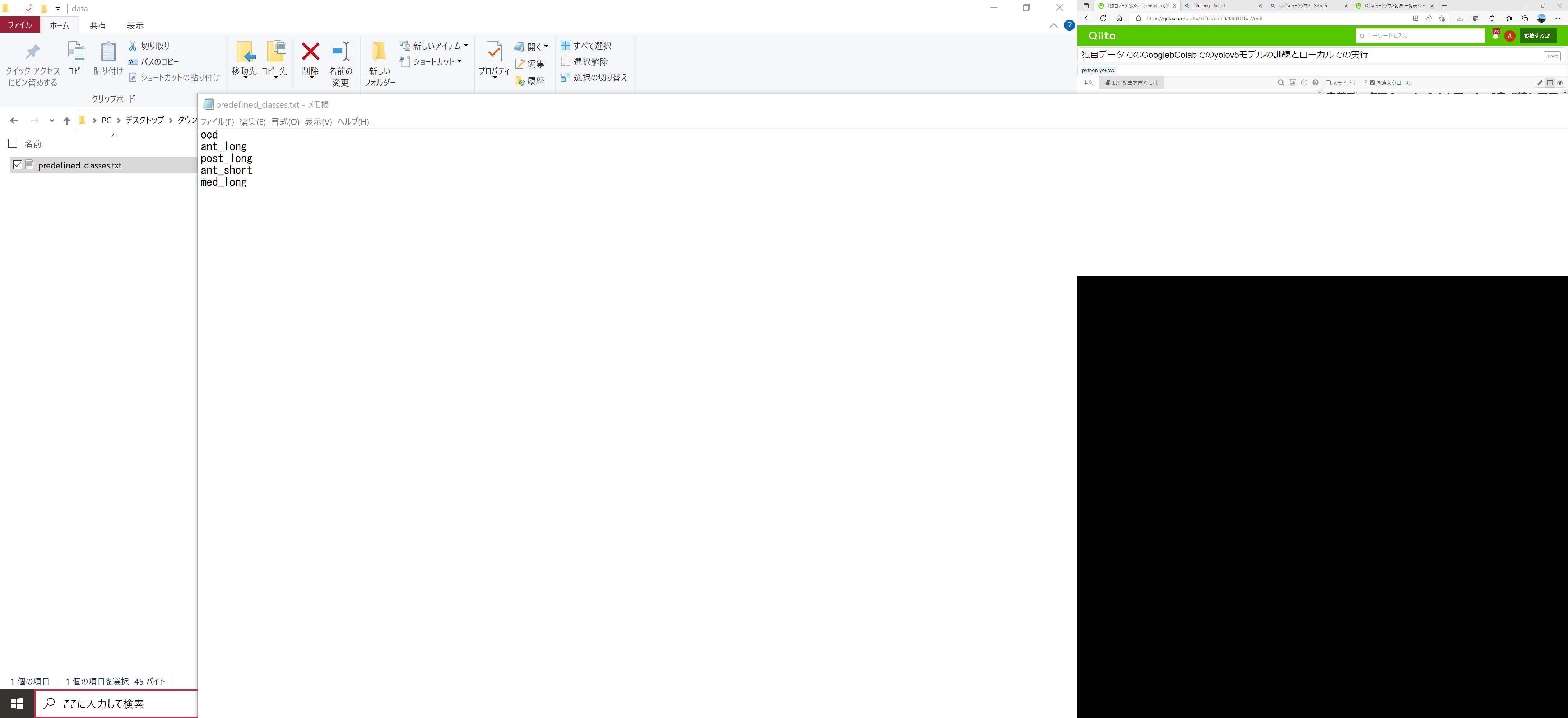
検出したいクラスを縦にかく、アノテーションの時はクラス名ではなくクラスのインデックス番号が記載されるので、この順番は大事。(あとで、訓練の際に似たようなファイルを作るが、順番は統一しておく)
(post_short, medial_normal, medial_injuryなど他の部位を検出させたいときはこの下に追記するとクラスのインデックス番号の整合性が合う)
1-3:labelimg.exeの起動とアノテーション
labelimgを起動 データ形式でyoloを選択(左列) use default labeにチェックを入れる
openDirで画像が保存されているフォルダを指定
change Save Dirでアノテーションしたファイルの保存先を指定
Create RectBoxから画像のアノテーションを行う
SaveしてNext Imageへ進む
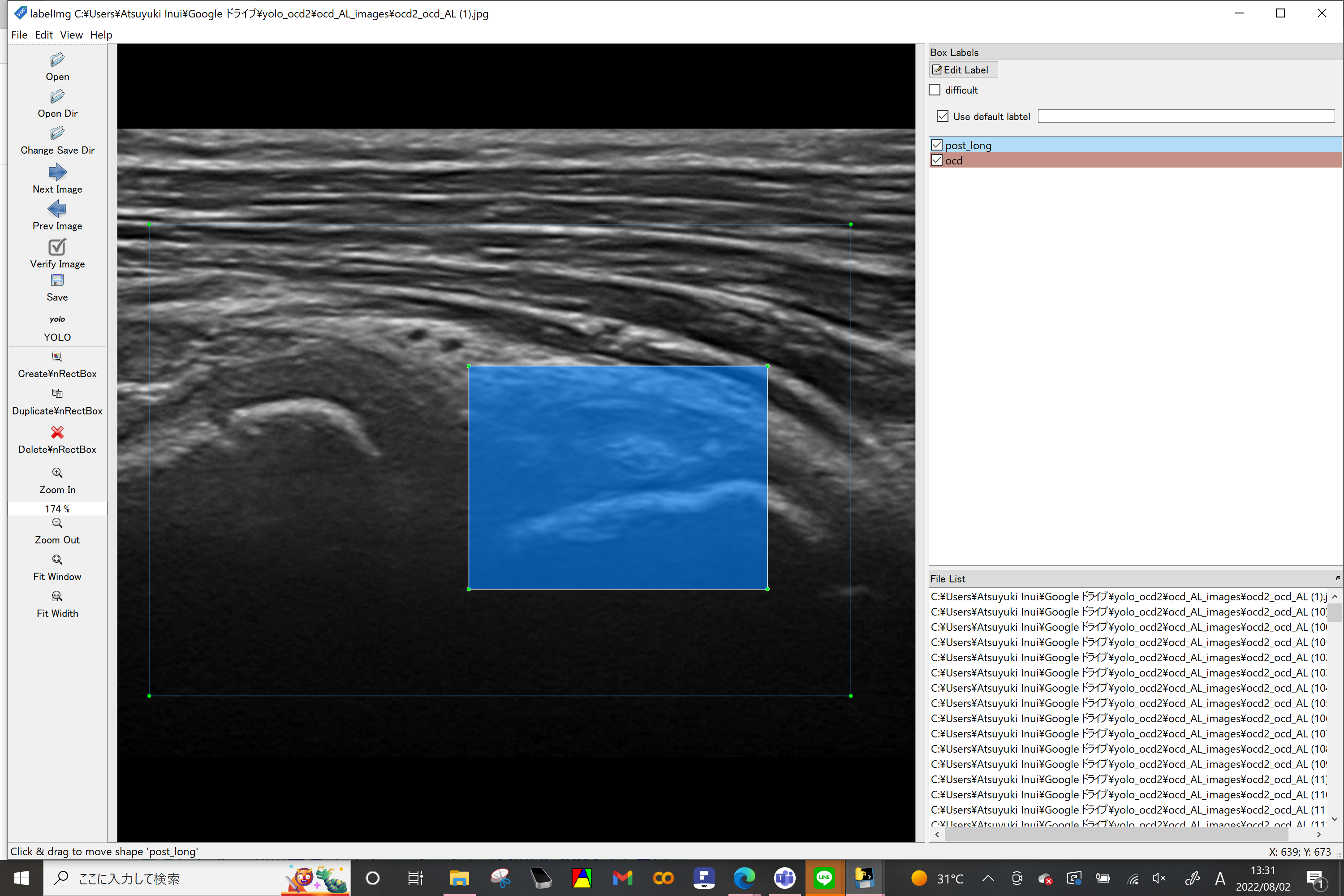
すべてのデータにラベル付けが終われば、google driveの直下に作るのフォルダに画像(jpeg :pngでうまくいかなかったことあり)とtextファイルを移す
2.GoogleDriveにフォルダを作成してフォルダを配置する
https://github.com/atstuyuki/elbow_OCD/blob/main/yolo_ocd3%20.zip
上記からyolov3の空のZipフォルダをダウンロードして展開し
google driveにyolov3というフォルダを作ってデータを以下のように配置する
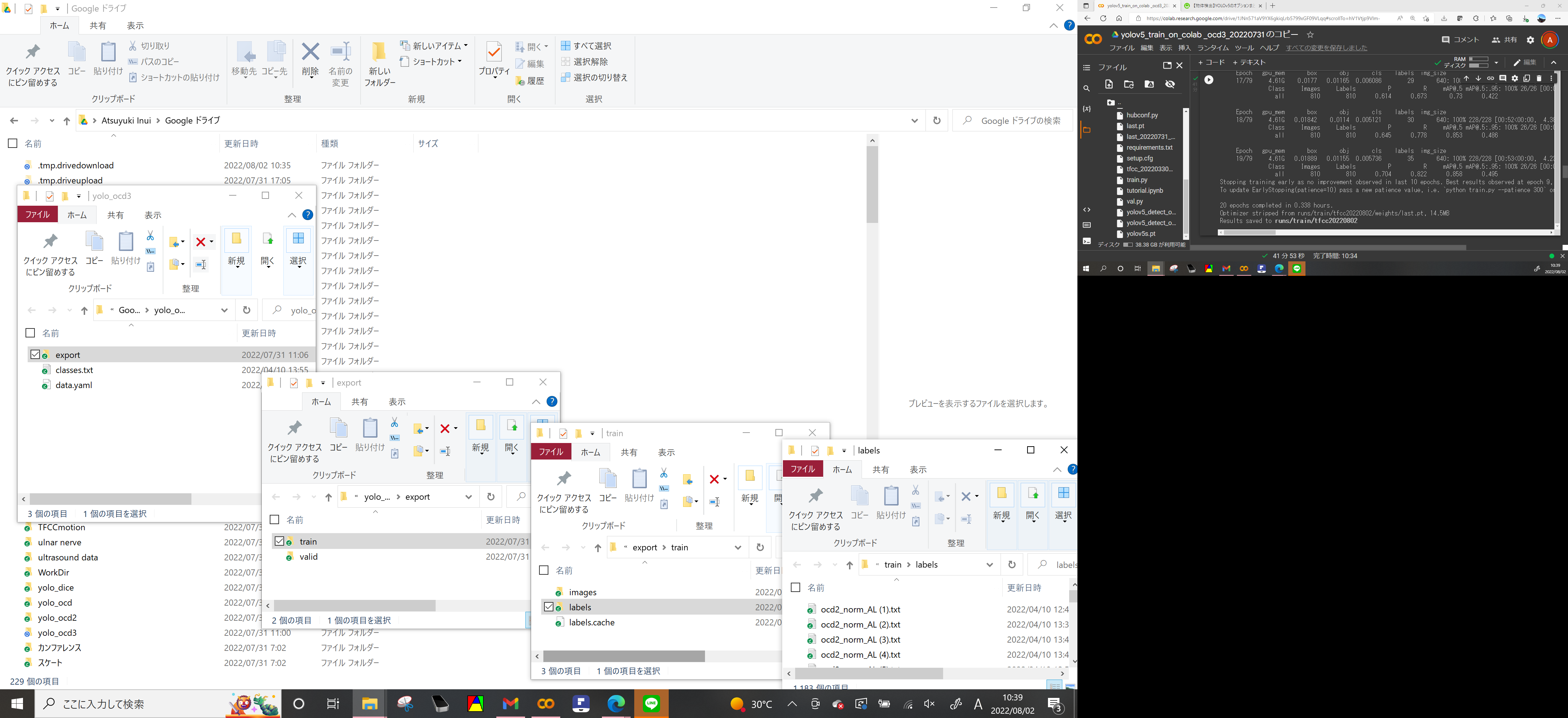
google drive直下にyolo_ocd3というフォルダを作成した場合(本当はvalidフォルダのimage labeフォルダにもデータが入っている
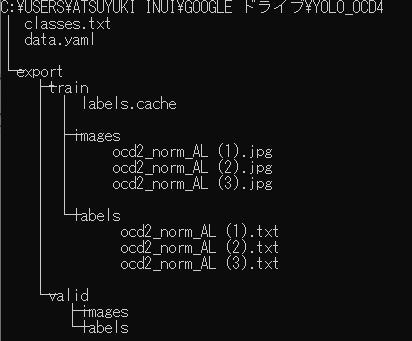
エクスプローラーでフォルダを順番に開いたらこんな感じ
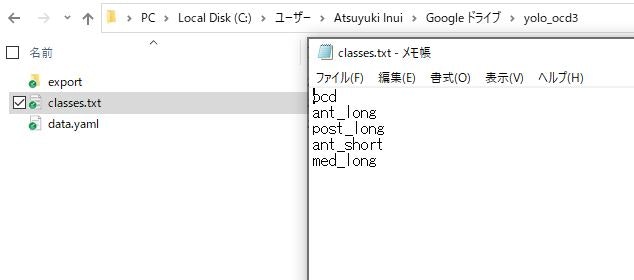
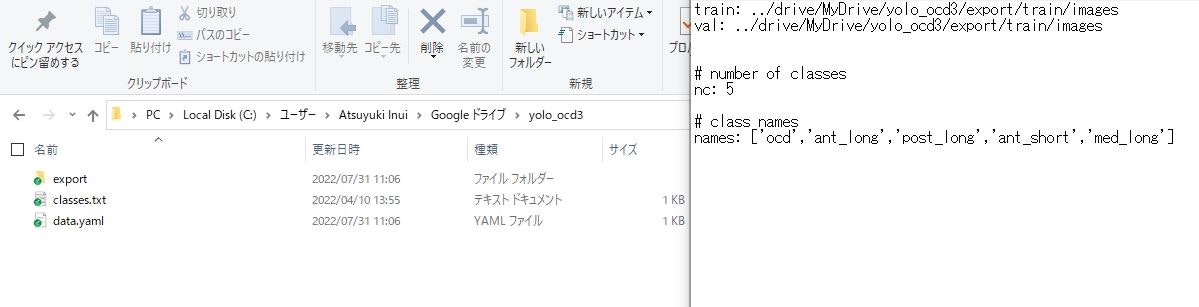
3.classes.txt, data.yamlファイルの中身をメモ帳で開いて確認
違う名前で訓練していたり、ディレクトリのパスが違えば適宜 classes.txt data.yamlファイルの書き換えと上書き保存する
各クラスの並び順が大事(ocd=0番、ant_long=1番)になる、名前ではなく番号を学習するので、LabelIMGでアノテーションしたときと、クラスの並び順が異なれば学習ができない
4.GooglebColabに接続して訓練の実行
Githubのこのページにアクセス https://github.com/atstuyuki/elbow_OCD/blob/main/yolov5_train_on_colab__ocd3_20220731.ipynb
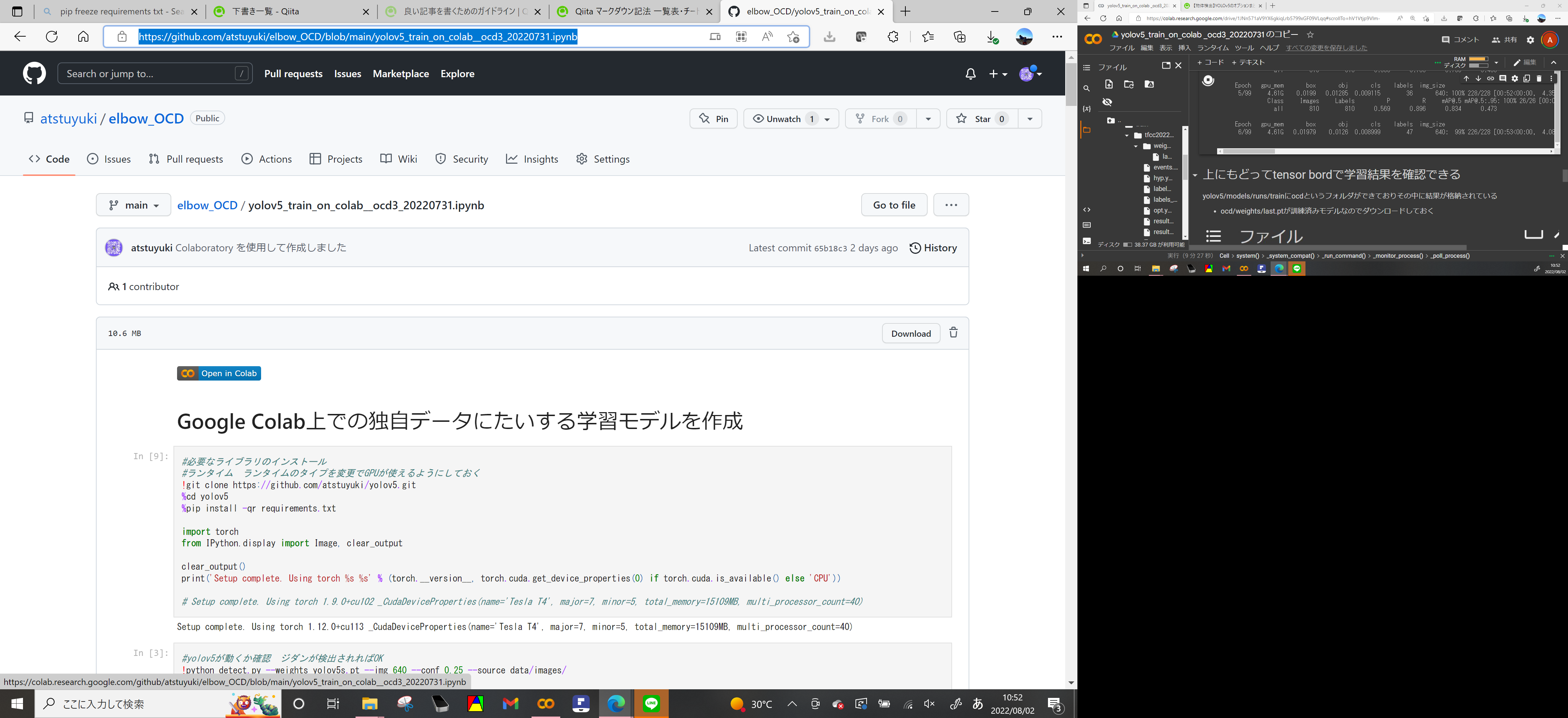
左上のopen in colabから自分のgoogle アカウントでログインしてcolabノートブックを実行
#ランタイムの選択でGPUを選択しておくこと
#しばらく画面を操作しないと自動的に接続が切れる事がある
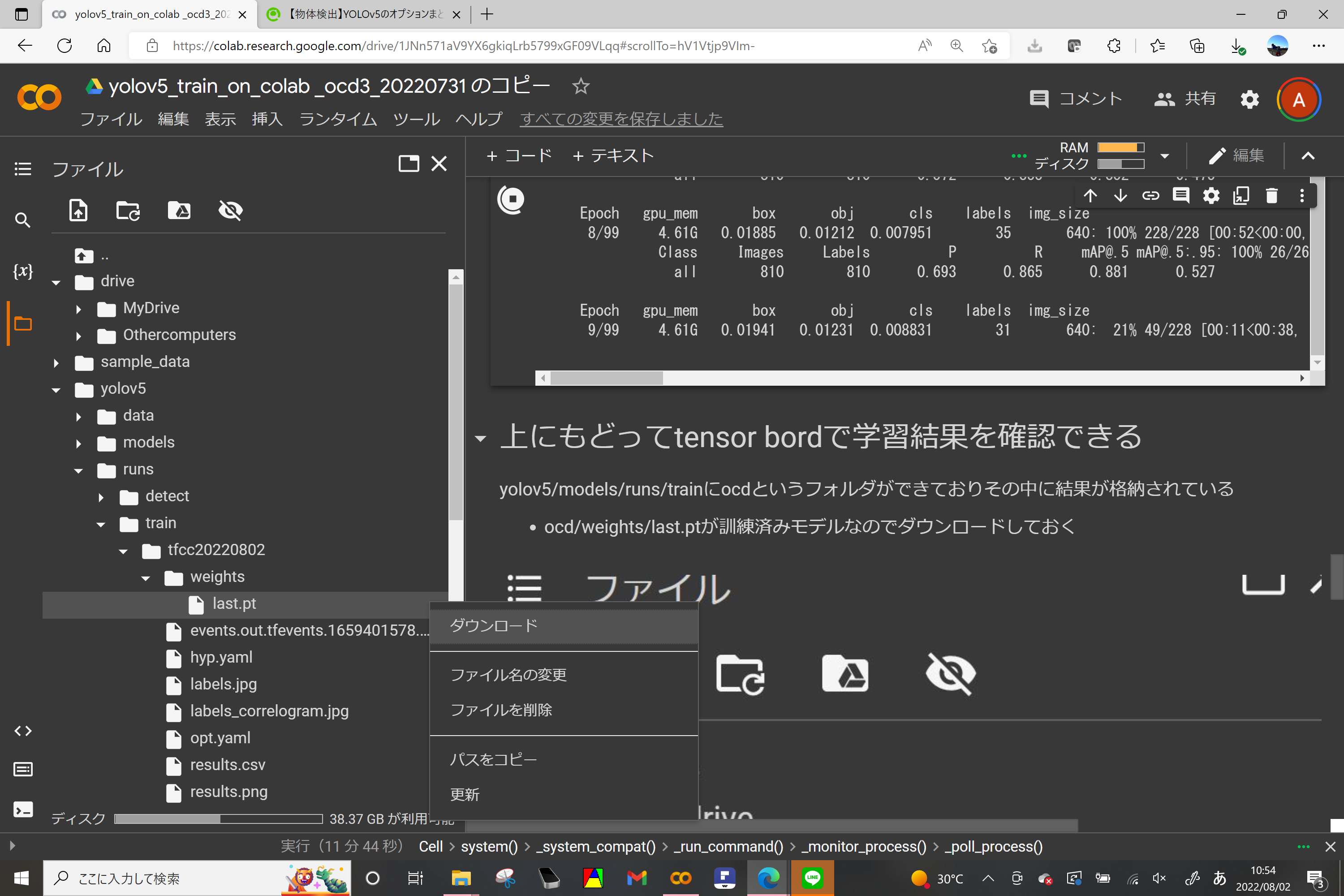
5.学習済みモデルのダウンロード
学習が終わればyolov5/runs/train/ocd/weights のフォルダにlast.ptという訓練済みモデルができるのでこれを右クリックでダウンロード
google colab上でモデルの動作確認をしたい場合は以下の記事を参考ください
自前データで学習したyolov5モデルを使ってgoogle colab上で物体検出
6.ローカルでの環境構築(winpython編がメイン)
1.anacondaを使うひとはanacomda prompt からyolov5という名前で仮想環境を構築して起動する
conda create -n yolov5
conda activate yolov5
2. python使わないがyoloだけやってみたい人はWinpython環境を勧める。(Windowsのみ)
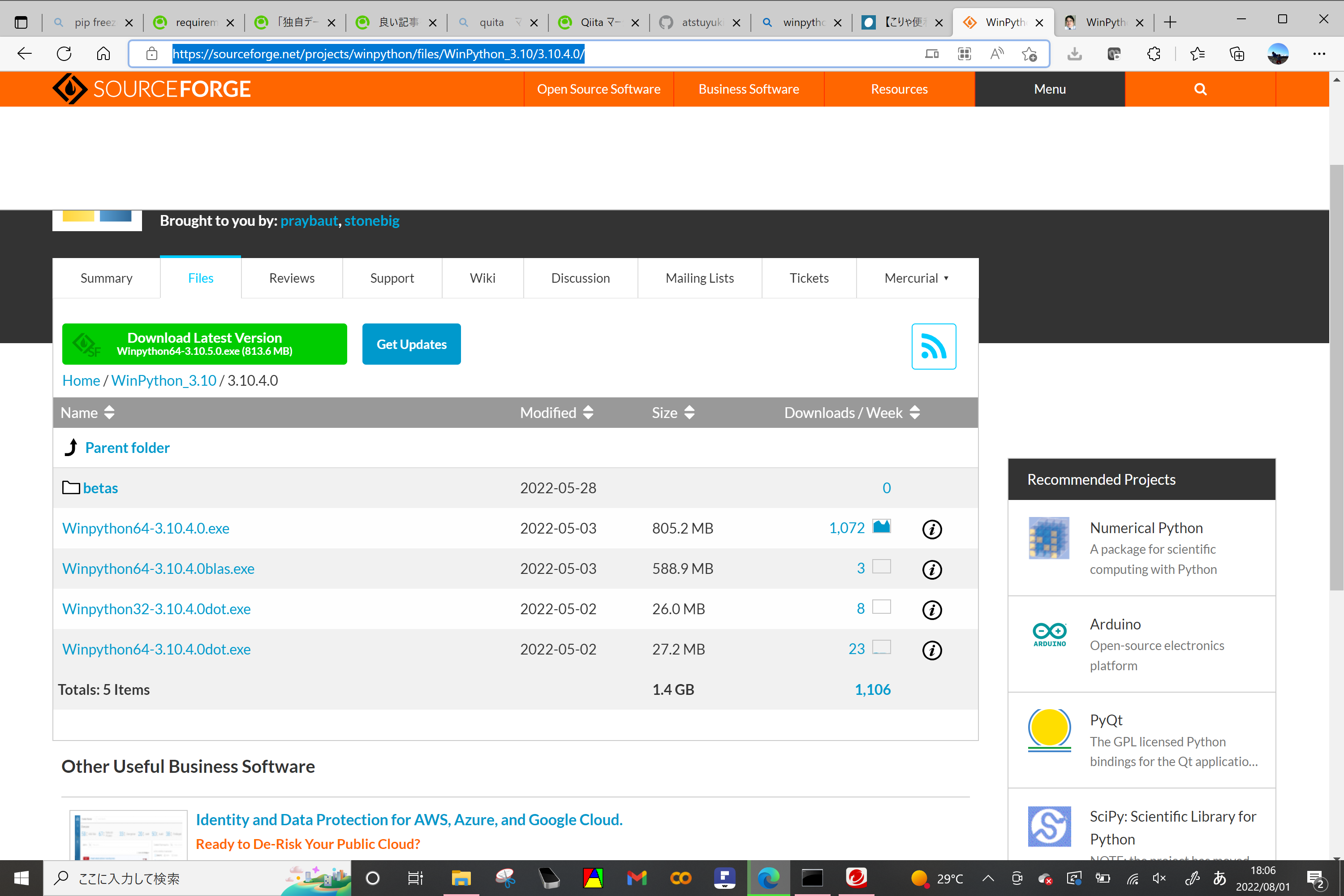
https://sourceforge.net/projects/winpython/files/
↑から好きなpythonを選んでダウンロードする。ダウンロード数の多いものを選んでおけばだいたい大丈夫
例えば
https://sourceforge.net/projects/winpython/files/WinPython_3.10/3.10.4.0/
から、Winoython64-3.10.3.0.exeをクリックしてダウンロード
pythorchが入っている必要があるので、重たいファイルをダウンロートしておく。
任意の場所で解凍(extraxt)する(Cドライブ直下とか、外付けUSBとか)
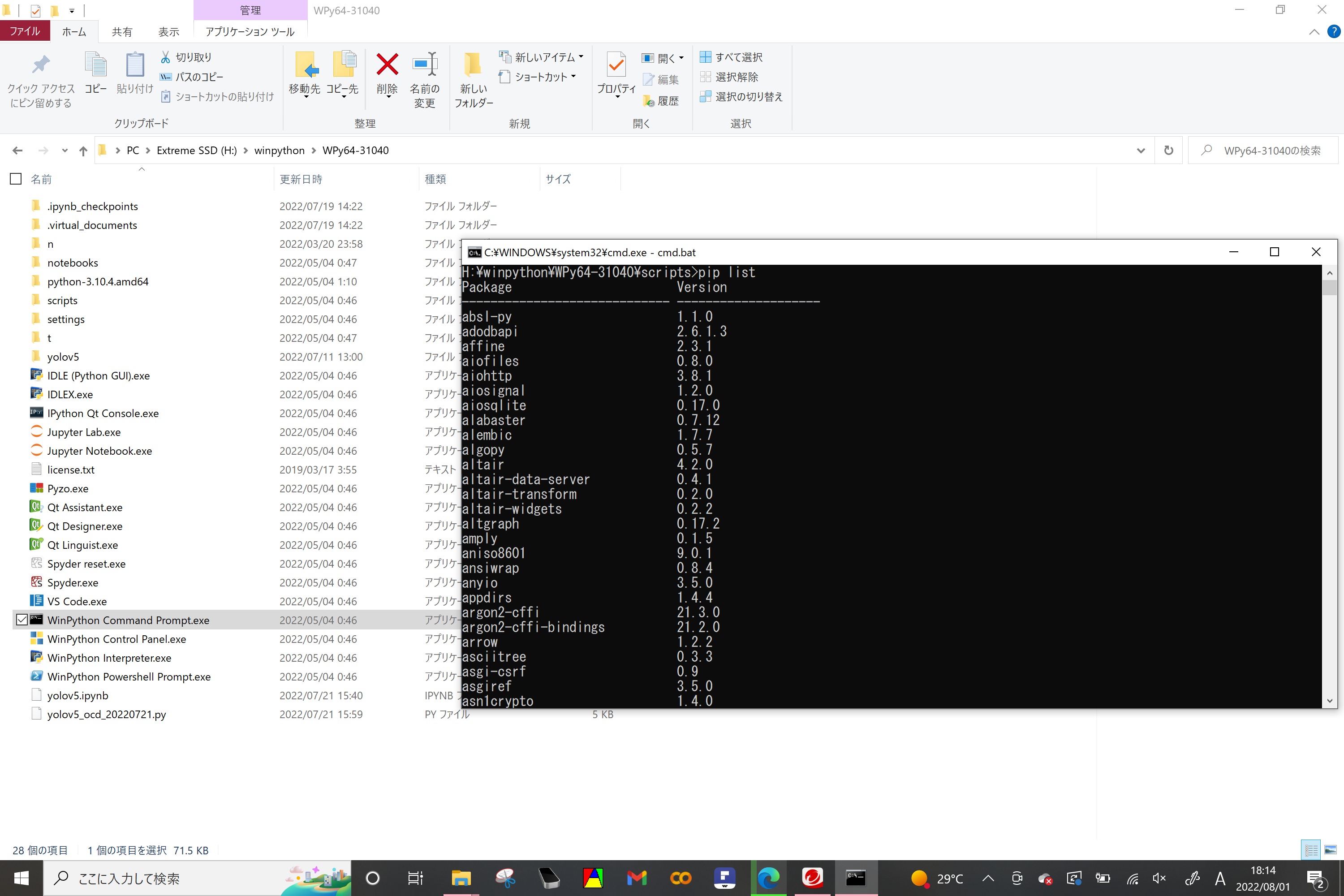
3.解凍したwinpythonフォルダでWinpython Command Prompt.exeをクリックして
pip list
を実行するとダウンロードしたWinpythonにインストール済みのパッケージが確認できる。torch(Deep Learning用のライブラリ)が入っている事を確認する。
GUI用のライブラリPySimpleGUIも使うので、引き続きcommand promptに以下を入力してインストールする
pip install pysimplegui
conda 環境の人はconda installで入れてください(https://anaconda.org/conda-forge/pysimplegui)
再び、pip listでPySimpleGUIが入っている事が確認できる。
(2022.8.30追記)
Winpythonのバージョンによってはpytorch実行時にnumpyのバージョンが合わずにエラーが出る様です。その修正方法について記事を書きました
pytorchのnumpyバージョンエラーの修正
4.yolov5環境の構築
GitHubのこのページに移動(本家のページでも良いですが、このページでは病変の物体検出用のモデルを格納済みです) https://github.com/atstuyuki/yolov5
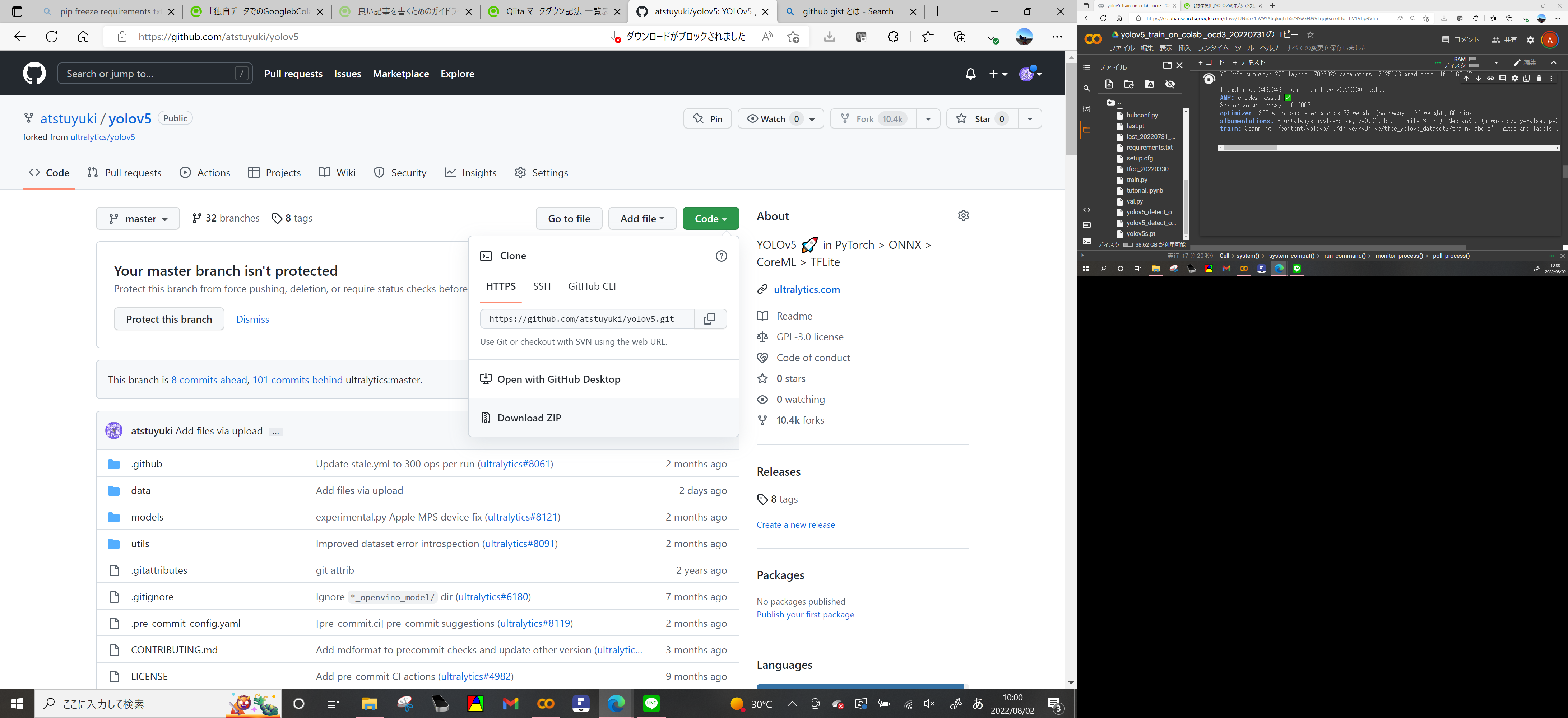
codeからDownloadZipを選択してフォルダ(yolov5-master)をダウンロード・解凍する
winpythonフォルダを開けて、その中に'yolov5'というフォルダを新規作成
yolov5フォルダ内部に先ほど解凍したyolov5-master内部のフォルダをすべてコピーして貼り付ける
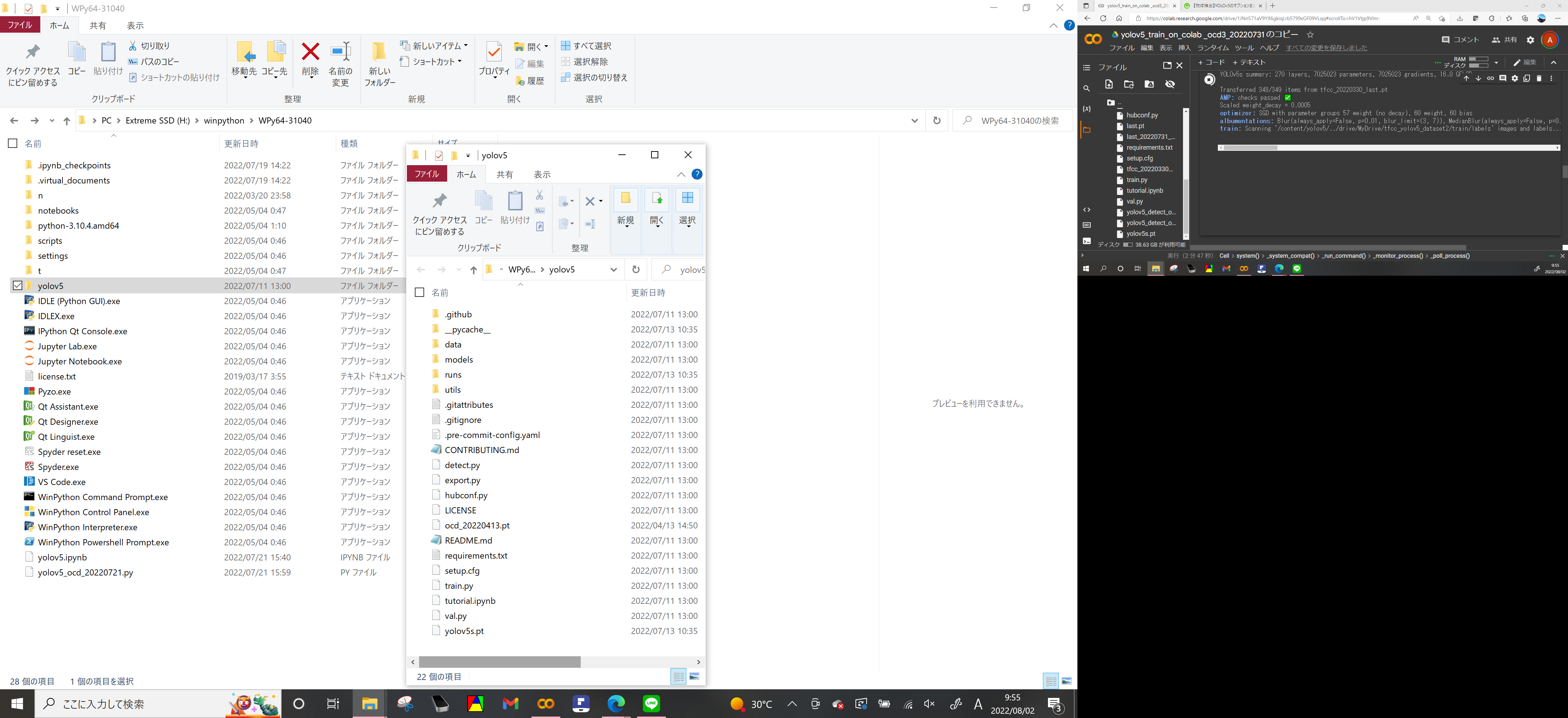
自前の学習済みモデル(先ほどgoogle_colabで学習させてダウンロートしたlast.ptファイル)がある場合はそのファイルをこのフォルダ内にコピーして貼り付ける
7.ローカルでの実行
https://github.com/atstuyuki/elbow_OCD/blob/main/yolov5_ocd_detect.zip
上記から圧縮フォルダをダウンロードして解凍
実行ファイル yolov5_ocd_20220721.py と
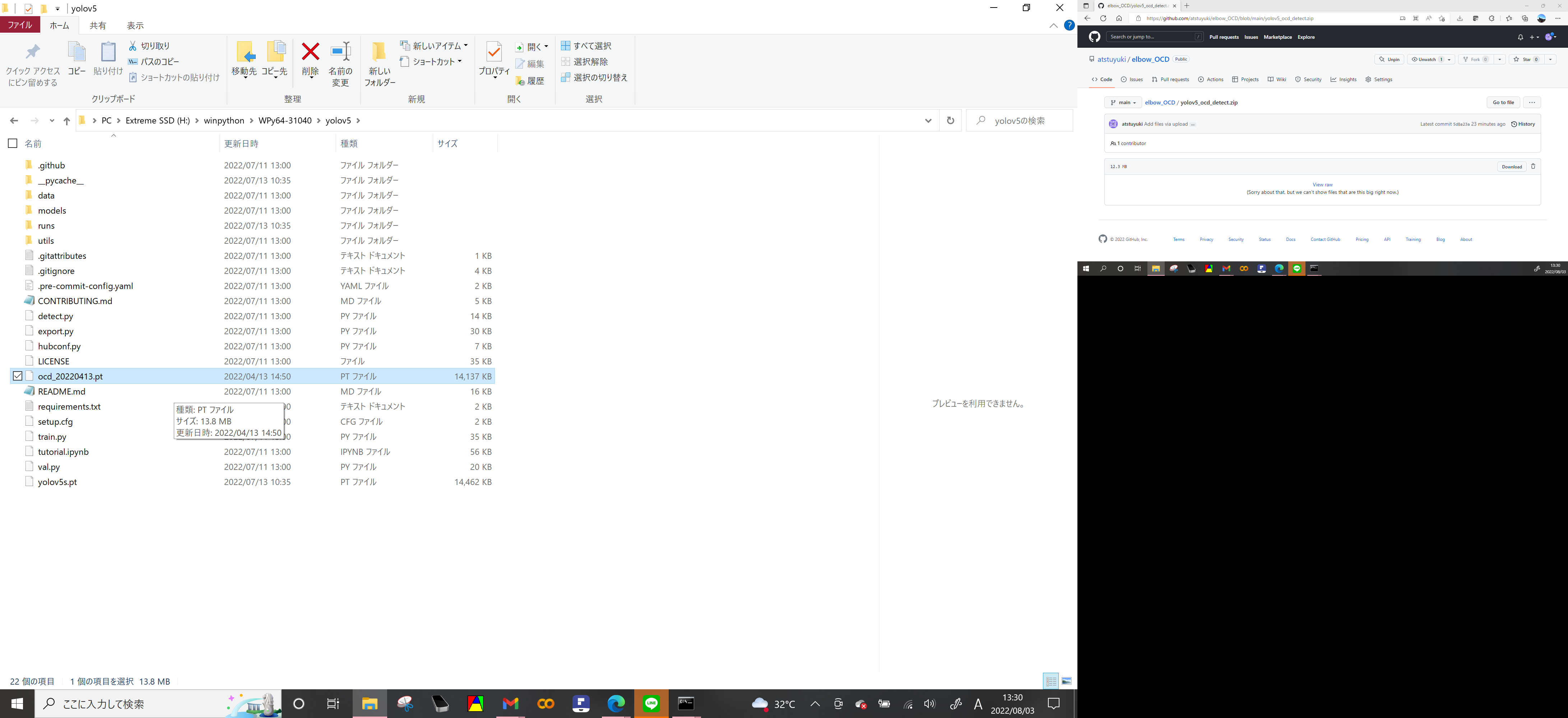
当方の学習済み重みファイル ocd_20220413.pt がある
実行ファイル(.py)をwinpython直下のディレクトリに置く
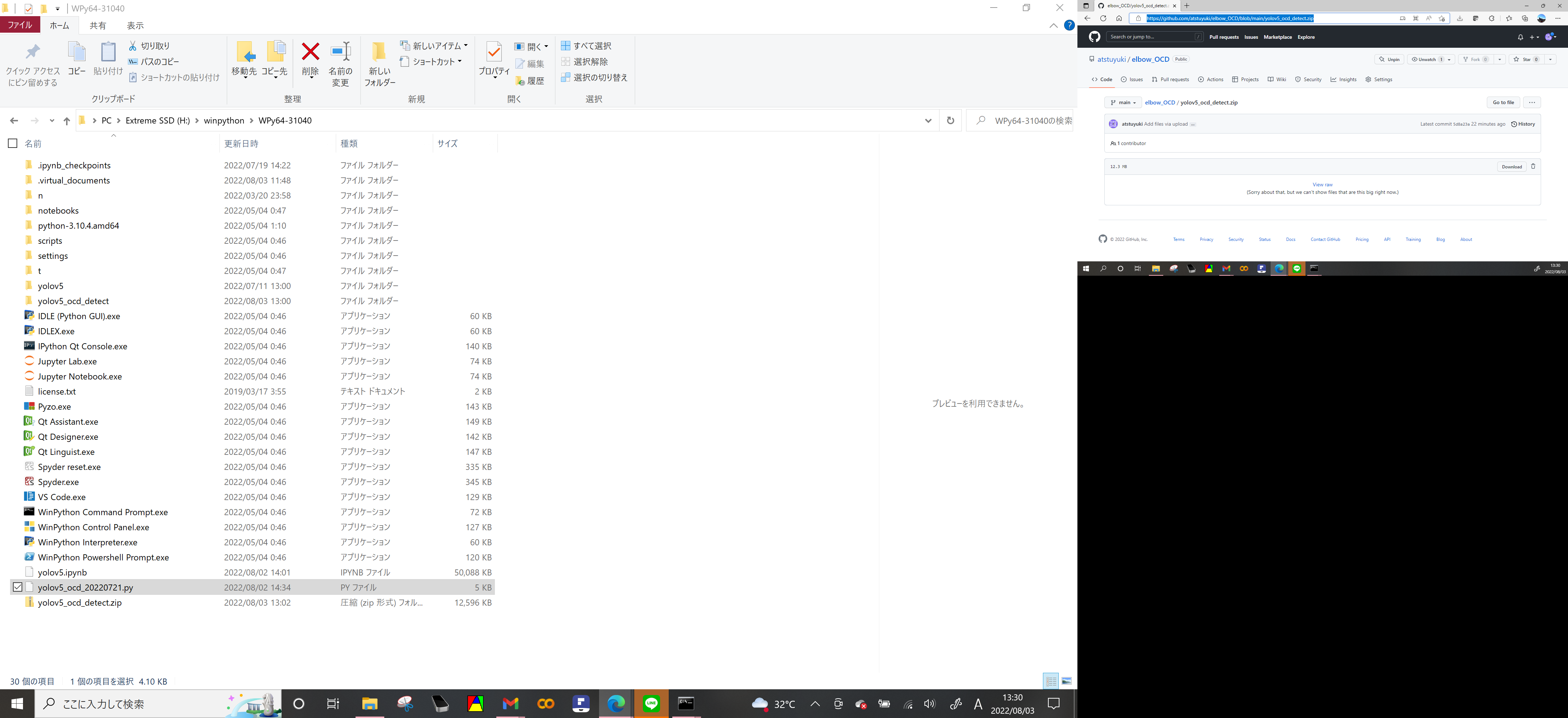
学習済み重みファイル(.pt)はサブフォルダのyolov5フォルダに置く
自分で学習させた重みファイルを使用する場合(先ほど訓練させた last.pt)もこのフォルダに置く
どのモデルを使って検出させるかでpyファイルの書き換えが必要です
yolov5_ocd_20220721.pyファイルをvscode.exeにドラッグアンドドロップして開く(もしくはメモ帳や自分の好きなeditorで開く)

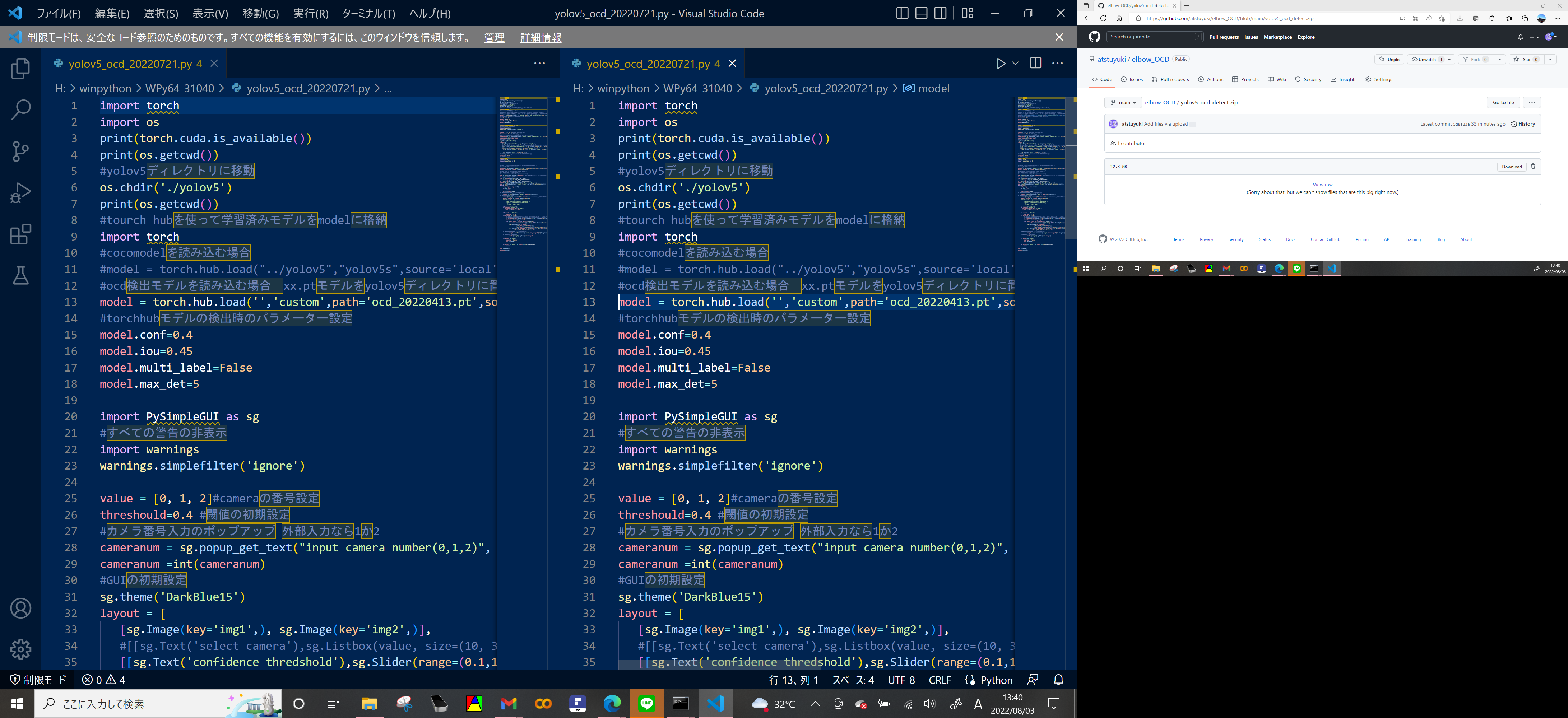
10~13行目が物体検出モデルの指定 デフォルトは80種類の物体を検出するCOCOモデル
自分の指定するモデルを使用するときは11行目に#をつけてコメントアウト
13行目の#を消去してプログラムを有効化
#ocd検出モデルを読み込む場合 xx.ptモデルをyolov5ディレクトリに置いておく
model = torch.hub.load('','custom',path='ocd_20220413.pt',source='local',force_reload=True)
たとえばlast.ptを使うなら
#ocd検出モデルを読み込む場合 xx.ptモデルをyolov5ディレクトリに置いておく
model = torch.hub.load('','custom',path='last.pt',source='local',force_reload=True)
と書き換える。
下図の左が書き換え前 右が書き換え後
yolov5_ocd_20220721.pyファイルをWinPython Interpreter.exeにドラッグアンドドロップするとpyファイルが実行されるの(パラメーター設定したいときは上述のpyファイルを書き換えてください)
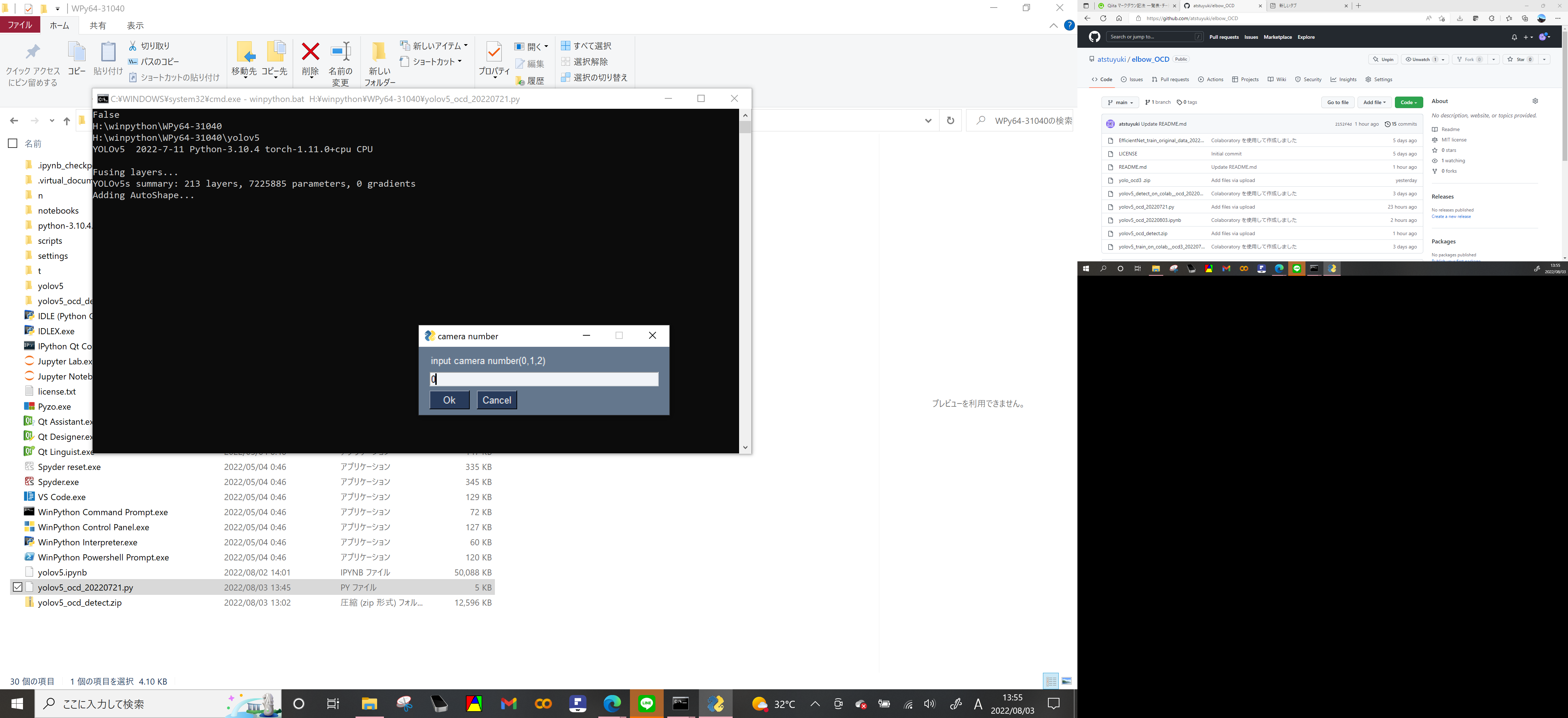
しばらくすると起動してinput camera numberと出るので半角整数を入力(PCによってカメラ番号は異なるが、通常フロントカメラが0 エコーからの外部入力は1(PCに2つカメラがあれば外部入力は2)
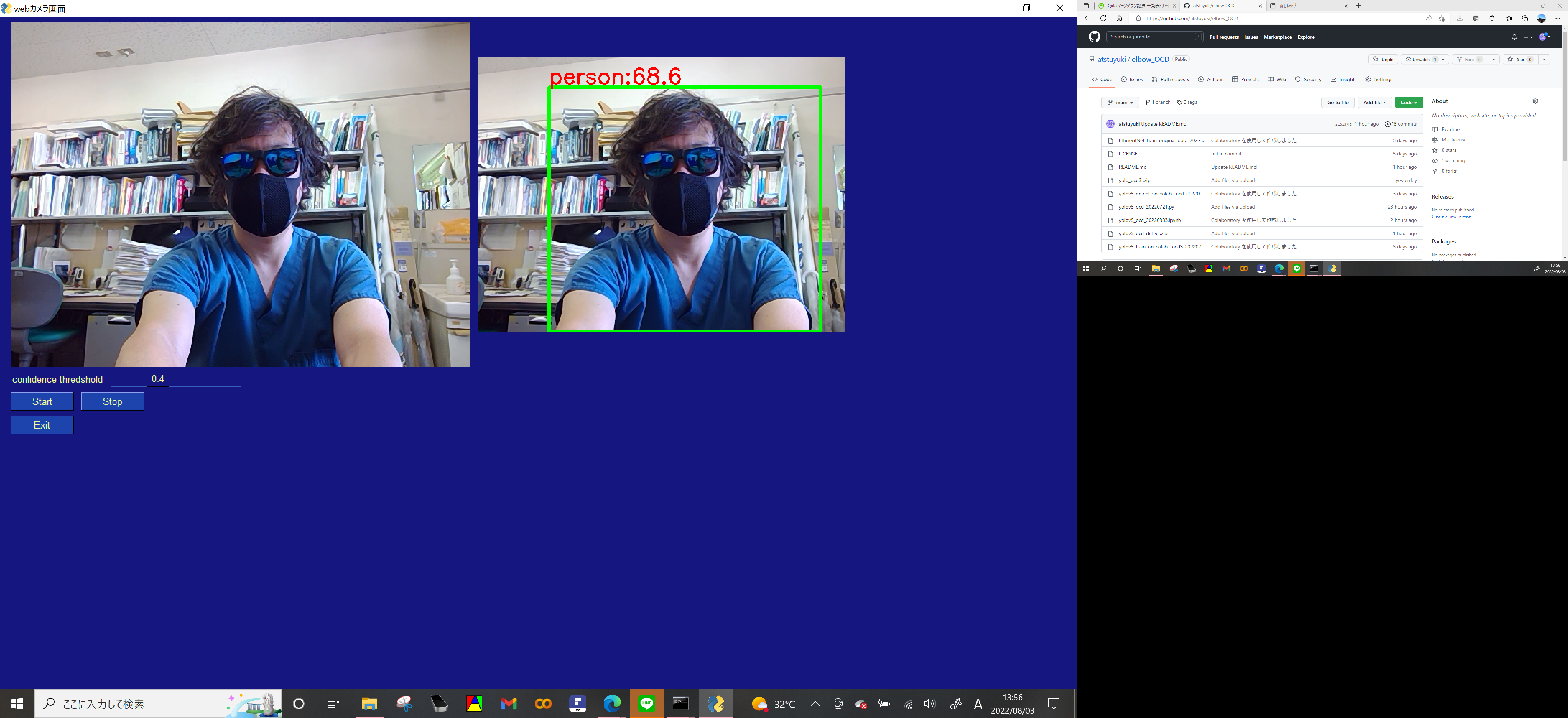
少し待つと左にカメラからの入力画像開始、startで検出開始 stopで検出終了 exitでプログラム終了
今回はcocoモデルを使っているので人物が検出されています
どうしてもjupyter notebook形式でinteractiveに操作したい人は
winpythonのJupyterLab.exeをクリックして起動後に新しいpythonファイルを作成し
こちらのコードを参考に
https://github.com/atstuyuki/elbow_OCD/blob/main/yolov5_ocd_20220803.ipynb
同じ内容をipynb形式で作ったのでこれをコピーしてください
注)PysimpleGUIを使っている関係でgoogle colabでは動きません
(言語設定でエラーが出る事があり、コントロールパネル>時計と地域>地域>管理>システムロケールの変更で対応すると動く事あり)
8. 参考サイト
全体的
https://qiita.com/PoodleMaster/items/5f2cc3248c03b03821b8
https://farml1.com/tomato_yolov5/
labelimg
https://doc.gravio.com/manuals/gravio4/1/ja/topic/labelimg
https://laid-back-scientist.com/labelimg
google colab1でyolov5
https://qiita.com/DiNOV-Tokyo/items/1333ff4a6d9b4b5b79c0
https://laid-back-scientist.com/yolo-v5
Winpythonについて
https://www.kkaneko.jp/tools/win/winpython.html
https://resanaplaza.com/2022/01/24/%e3%80%90%e3%81%93%e3%82%8a%e3%82%83%e4%be%bf%e5%88%a9%e3%80%91winpython%e3%81%a7python%e7%92%b0%e5%a2%83%e3%82%92usb%e5%8c%96%e3%81%97%e3%82%88%e3%81%86%ef%bc%81/