モチベーション
以下のことが気になった為
- CNNなしで画像分類でSOTAを達成したモデルとどのような構造か?
- CNNなしで画像分類でSOTAを達成したその理由
→CNNより局所的、大局的情報を取得できているためか - CNNよりいいのか?
→事前学習で画像枚数が9千万枚以上学習できるのであればVitのほうが良い - CNNは要らなくなるのか?→モデルが小さい場合は必要だろう
論文
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
何がすごいのか?
①SOTAのmodelより学習時間が減っている。精度向上。
パラメータ数が10億個あるBig Transfer(Bit)よりも学習時間が減っている
それでも、TPUv3で230daysとか。

②CNNいらず
CNN使っている気がするが...
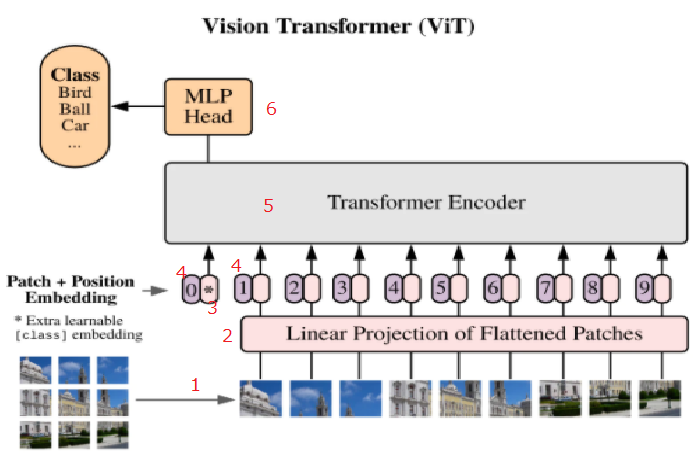
Vit Transformerの構造
Vitの全体ぞうは以下である
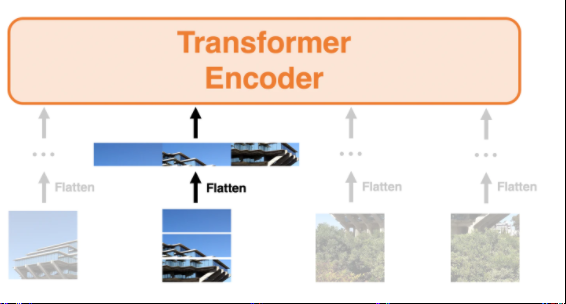
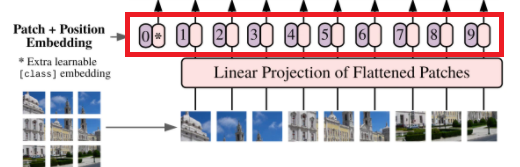
①パッチに分割
②ベクトル化
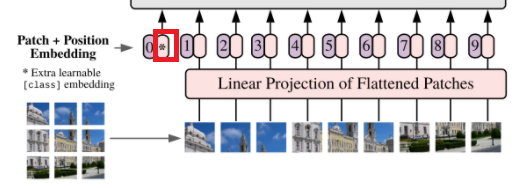
③CLSの追加
④位置情報の付加
⑤Attentionへ入力
⑥MLP
以下、文章の場合のTransformerと対比しながら見ていく
①パッチに分割する
- 文章の場合
【To be, or not to be, that is the question.】
という英文があったとき、以下のように分割する
【"To", "be", ",", "or", "not", "to", "be", ",", "that", "is", "the", "question", "."】
- Vitの場合
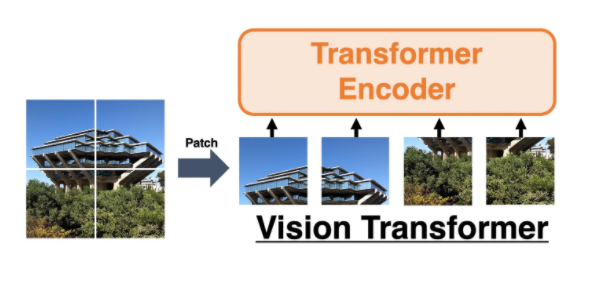
上記例でいえば、パッチN=4(4枚に分けている)
パッチNはパッチサイズP(128)画像サイズWH(今回は256256)より
N=HW/P^2=256256*/128*128=4で求まる
参考
②ベクトル化
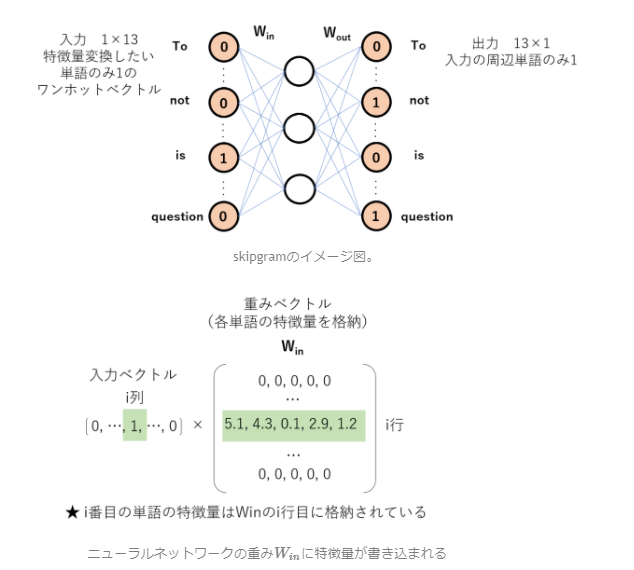
- 文章の場合
エンコーダ:問題を解けるような形式にエンコード(暗号化)する
デコーダ:暗号復元で英語→日本語に変換する
Transformerのエンコーダに入力するためにベクトル表現に変換する.
【"To", "be", ",", "or", "not", "to", "be", ",", "that", "is", "the", "question", "."】
それぞれの単語を特徴ベクトルで見分けれるようにする。
各単語の特徴量は任意に決めることができる。
例えば、300次元とすれば、この英文は13*300のベクトルで表現できる。
この特徴量を学習する。
参考
- Vitの場合
VItの場合も画像を特徴量に変換してTransFormerに入力できる形式にする。
P^2*C(P:パッチサイズ 128 C:3ch)のものを線形変換する。
どの実装が正しいのか分かっていません。
全結合で特徴量に変換しているが、論文中にはFilterで変換との記載がある。また、Filterを可視化するとConvolution層の序盤のような可視化画像があることから、下記実装①があっているか不明。実装②はConv2Dを使用して変換しているが、こればCNNは使用していないと言えるのか?

実装①
全結合で3072->128次元の出力に変換している。
# 入力サイズは1バッチ分のデータ64、3チャネル、224*224
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = p, p2 = p)
# により、1バッチの64データ分、パッチの49個の画像に1画像を分割(224*224/32/32=49)、1画像分の32*32*3chを1次元の配列に直すと3072の配列となる
x = self.patch_to_embedding(x)
print(f"after patch_to_embedding:{x.shape}")
self.patch_to_embedding = nn.Linear(patch_dim, dim)#patch_dim:3072 dim:128(出力)
実装② にあるEmbeddingの実装ではConv2dが使われている。

③CLSの追加
- 文章の場合
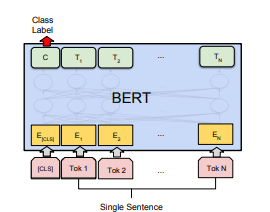
BERT
記事を入力して、9つのニュース記事のグループのうち、どのグループに属する記事かを推論する場合。
BERTにはCLS(クラス)とSEP(文章の終わり)が存在する。
分類タスクの場合はCLSが使用される。
CLSの出力にMLPなどを接続して分類する。
- Vitの場合
BERT同様にCLSを付加する。
④位置情報の付加
- 文章の場合
語順情報の付加
単語の重要度を評価できるが、語順情報を考慮できない為、語順情報をベクトルに付加する。
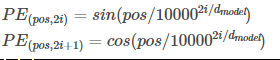
posは文章の中で何番目の単語かを表し、iはその単語の特徴量ベクトルのうち何次元目の数値かを表す。
つまりPEは(単語数×埋め込み次元)の形状の配列であり、文章を表す特徴量のテンソルと同じ形状をしてる。
この2つのテンソルを要素ごとに加算することで、Positional Encodingの処理が完了する。
特徴量を300次元とした場合、300次元それぞれに位置の情報を加算する
- Vitの場合
各パッチの特徴量とCLSに位置情報を付加する。
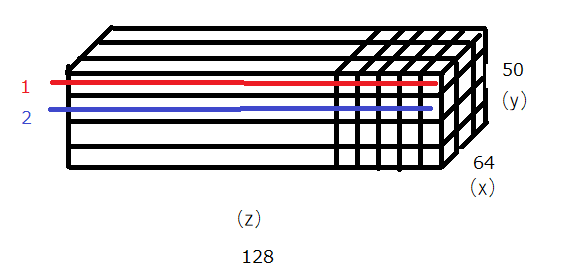
バッチ数が64 パッチ数が49 128次元とした場合(64,49,128),CLSを足して(64,50,128)のテンソルに対して(64,50,128)の形状をしたPEで位置情報を付加する。
1番目のパッチには1を2番目のパッチには2を・・・。加える数は学習する。
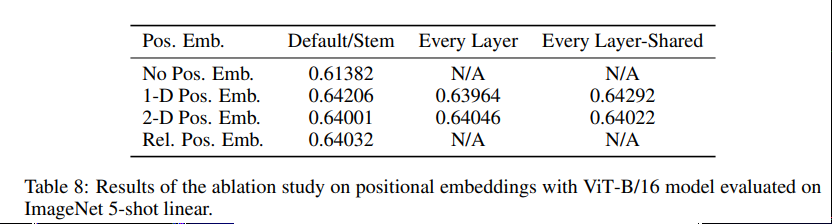
筆者は2Dの位置情報を付加することや、相対距離を付加することも試しているが、顕著な精度の向上は見られていない。元の画像が224224でもパッチレベルでは1414などで、学習が簡単で差が出なかったのではと考察している。
2D
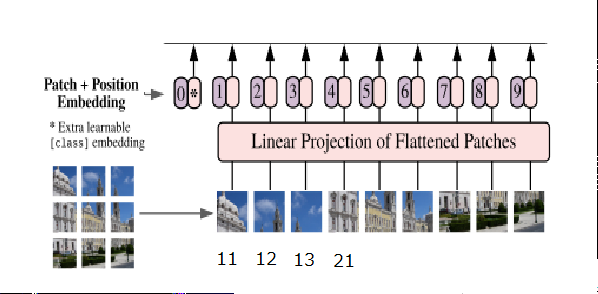
付加する値はパッチの行列が同じだと類似度が高くなる傾向になっている。
パッチ1とパッチ1は同じなので黄色。
同じ行の1-2,3,4,5,6,7とは似た値が付加される為類似度が高くなっている。列方向も同じ。
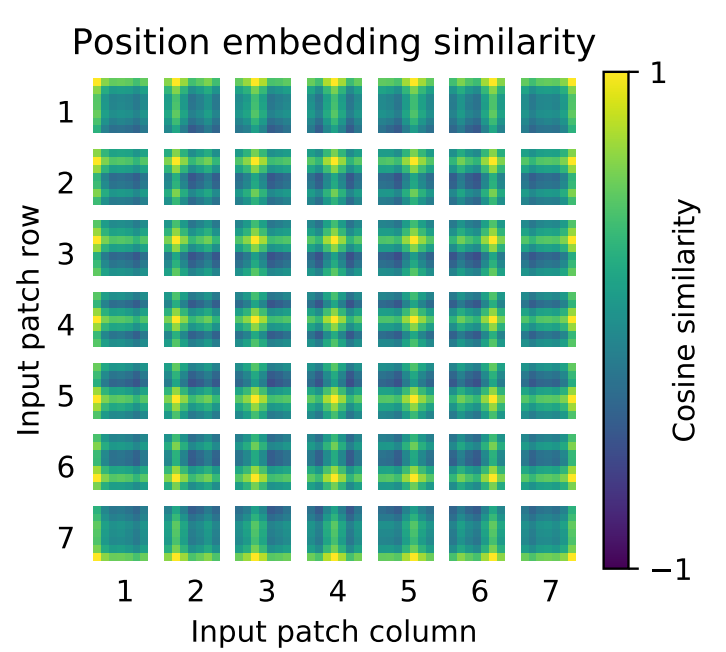
ハイパーパラメータによってこの類似度は変わる(加算する値の傾向が変わってくる)。
位置情報の追加の方法より、ハイパーパラメータのほうが重要。
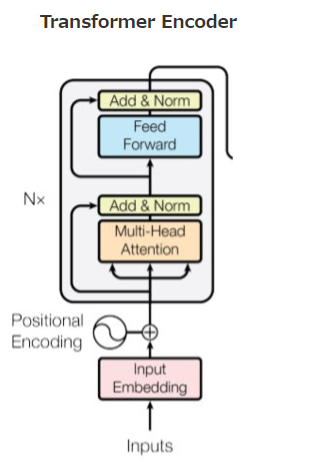
⑤Attentionへ入力
- 文章の場合
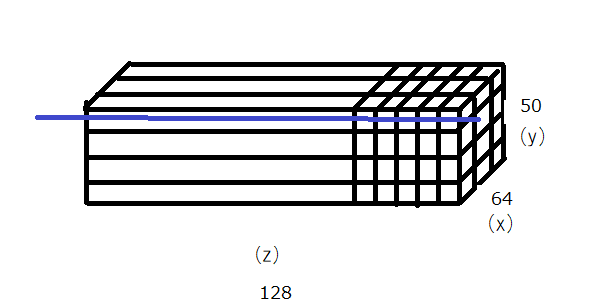
Layer Normalization
50個の分、1つの文が128単語とした時に128単語にまたがって正規化を行う
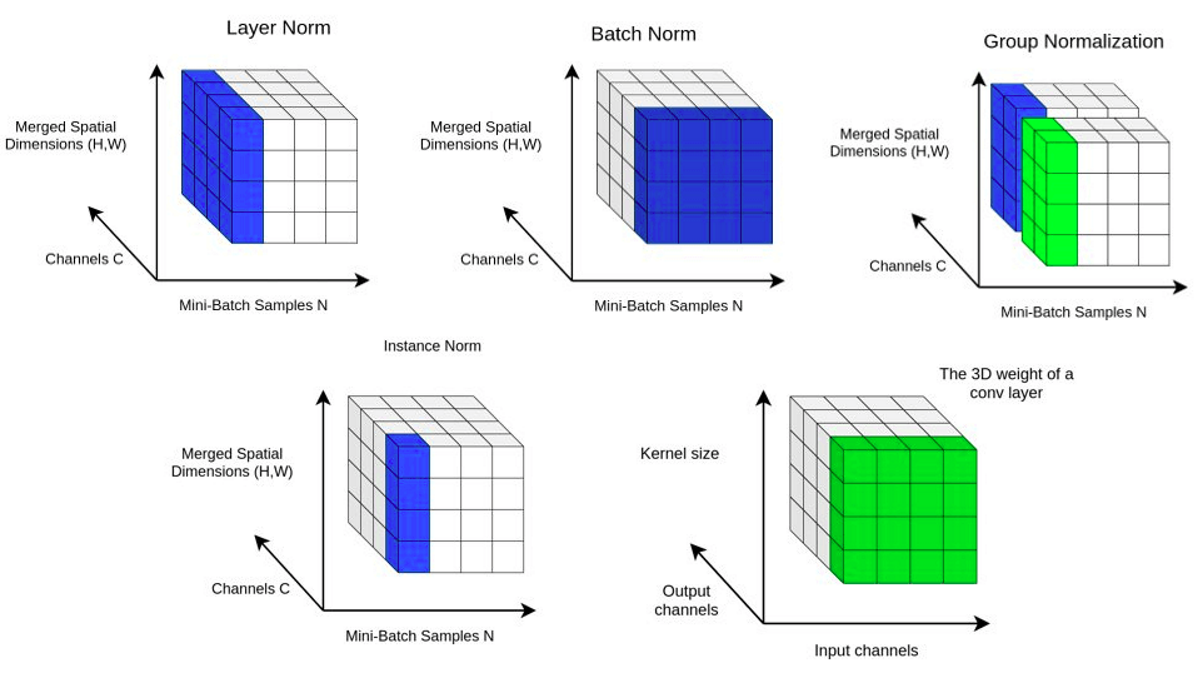
- Vitの場合
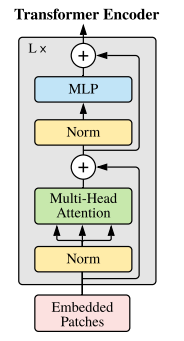
Layer Normの箇所が異なるのと、層を深くするために残渣結合がある。
SOTAとの比較
SOTA modelをVITが上回っている
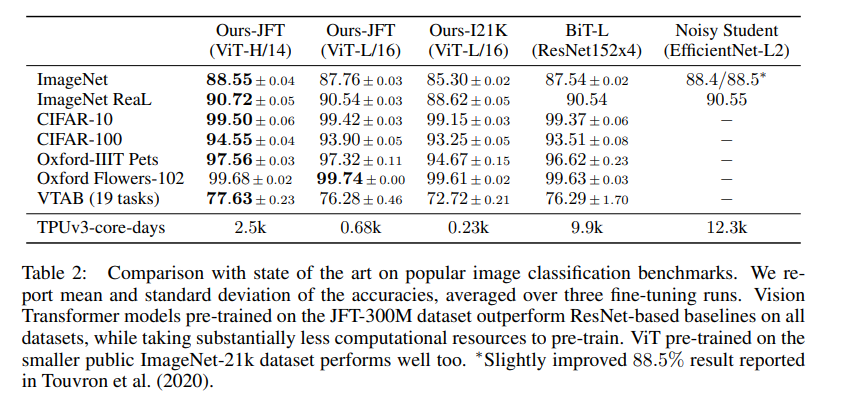
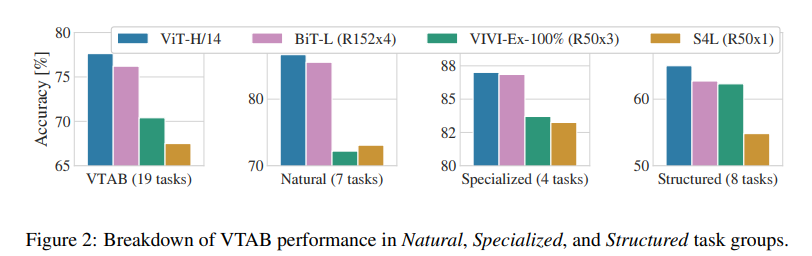
各ベンチマークでVitのほうが性能が良い。
VATBは統一されたベンチマークのこと
事前学習
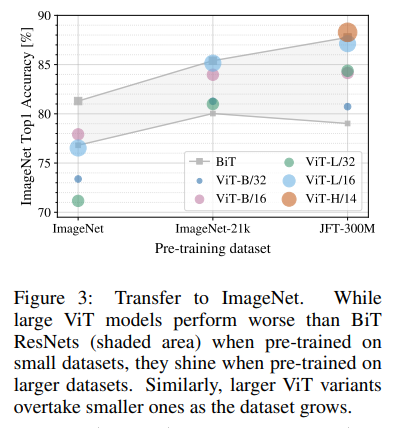
小規模データセットであるImageNet(クラス1,000個の計130万枚)
中規模ImageNet-21k(クラス21,000個の計1,400万枚)
大規模JFT-300M(クラス18,000個の計3億枚)
で事前学習してImageNetへ転移学習した時の性能。
データセットが少ないときはVitの性能は低い。
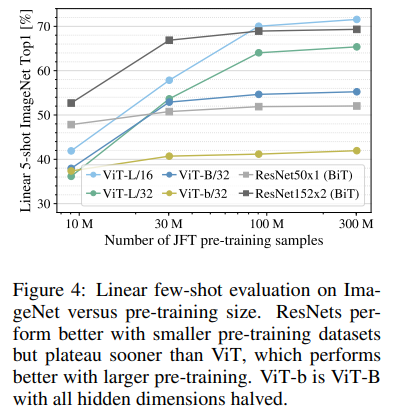
30M(3千万枚)以下は性能が低い
Attention Distance
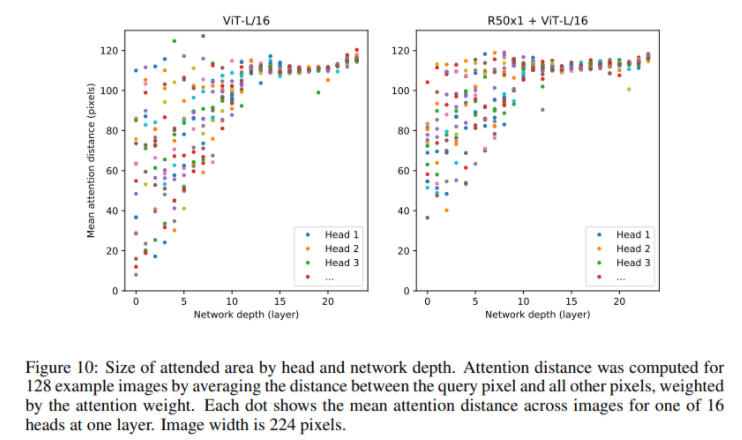
画像サイズ:224
ヘッド数:16
試行画像数:128
Attention DistanceはCNNにおける受容野の大きさと同じ
ネットワークが浅いほど参照している画素距離が近く
ネットワークが深くなるほど、広い範囲を参照している
HybridModel(Attentionへの入力がResNetで抽出した特徴量)だと層が浅いときから比較的大きな領域を見ている。
Attentionの可視化

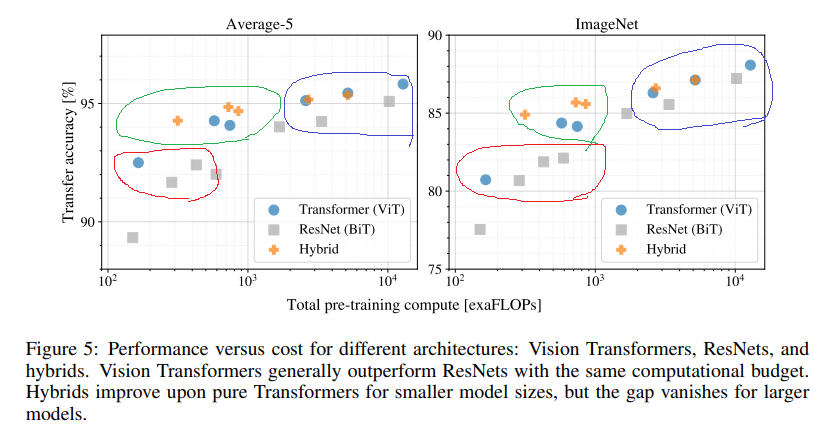
Hybrid Architecture
入力を画像のパッチではなく、Resnetで得た特徴量を入力する
赤:モデルが小さいときにはVitの精度をわずかに上回る
緑:Hybridがコスパがよい
青:モデルが大きくなるとVitのほうが良くなる。さらに向上できるようにも思える。