強化学習の基礎から最近の論文までの道のりを繫ぎたいというモチベーションで,最初は強化学習の基礎の基礎の解説から,Q学習についてR2D3, Agent57あたりまで読んだ論文についてまとめてみました.Actor-Criticについては,Q学習との比較用にA3Cあたりを少しだけ書いています.あと,最後に軽くマルチエージェント強化学習(MARL)とオフライン強化学習(Offline RL)にも触れて紹介しています.

基礎の基礎
強化学習とは?

- 教師あり学習,教師無し学習に並ぶ,機械学習の一分野.
- 端的に言うと,エージェントと呼ばれる行動主体が,ある環境のなかで得られる報酬を最大化する最適化問題.
- ただし,報酬を得るためにどうしたらよいかというのは非自明な場合が多く,また,報酬のみではスパースで扱いにくいので,途中の過程ででてくる状態や,エージェントの行動に価値を付与し,その価値を最大化する問題に置き換える.
- 状態や行動の価値に関しても一概に決まるものではないため,まずは価値を推測するところから始め,推測した価値の最大化までをひとまとめで行うことを目標とする.
- 応用されている分野としては,ゲームの攻略,ロボットの制御,自動運転,ロジスティックスの最適化など,様々ある.
- 近年ではマルチエージェント化も研究されている.
押さえておくべき用語

-
環境:
エージェントが行動する場所. -
エージェント:
環境内を行動する主体. -
状態 $s \in S$:
環境があるタイムステップにおいてどうなっているか. -
行動 $a \in A$:
エージェントがある状態に対して起こす行動. -
報酬 $r \in R$:
ある状態においてエージェントがある行動を行った結果得られる利益.強化学習はこの報酬を最大化することを目的とする. -
価値:
報酬に繋がる状態や行動のことで,以下の行動価値と状態価値がある.-
Q値(行動価値) $Q^{\pi}(s,a)$:
ある状態$s$においてある行動aをとった時の価値.(直接の報酬とは違うので注意.例えば,今回の行動で直接は報酬が得られなかったが,今回の行動の結果次のステップで報酬が得られる確率が高まったなら,今回の行動には価値がある.) -
状態価値 $V^{\pi}(s)$:
取った行動とは無関係に決まる,ある状態に達したときの価値.例えば,AlphaGoでの盤面評価など.
-
Q値(行動価値) $Q^{\pi}(s,a)$:
-
方策 $\pi$:
ある状態が $s$ になると確率的にある行動 $a$ をとる,と決めた関数.
価値ベースと方策ベース(とモデルベース)
-
価値ベース
エージェントの行動価値 $Q$ を推測し,以降の行動価値の現在割引和を最大化する行動 $a$ を決定する方法. -
方策ベース
状態価値 $V$ を推測し,以降の状態価値の現在割引和を最大化する方策 $\pi(s,a)$ を決定する方法. -
モデルベース
環境が完全に分かっているという仮定のもと,価値最大化をプランニングする方法.
方策オンと方策オフ
方策オンでは,状態と行動を現在の方策からサンプリングするのに対し,方策オフではこれまでの方策からサンプリングするという違いがある.これにより,経験再生(過去の経験をストックしておいて,そこからサンプリングしたバッチで学習する手法)の利用可否などのメリット・デメリットが生じる.
最適化問題の主な解き方
-
動的計画法
パラメータが既知の時.暫定解の利用で計算量をなるべく減らしつつも,全探索の完全な最適化を行う. -
モンテカルロ法
実際に試行を繰り返して得られた報酬から価値を推定する.例えばロールアウトと呼ばれる手法では,いくつかある次の方策の選択肢の中からひとつ選び,ランダムにエピソードが終わるまでモデルを回すシミュレーションをしてみて,そのサンプリングした結果を基に次の方策を選択する. -
TD(temporal difference)法
今期の推定価値と次期まで考慮した場合の推定価値との見込みの差分で,次状態まで考慮した推定現在割引価値 $r_t+\gamma \hat{V}\left(s_{t+1}\right)$ と,今期の行動により得られる価値関数 $\hat{V}\left(s_{t}\right)$ の差が十分に小さくなった場合に今期の価値関数の推定が収束したと判定する.
TD誤差: $\delta_{t} \triangleq r_{t}+\gamma \hat{V}\left(s_{t+1}\right)-\hat{V}\left(s_{t}\right)$
※ここで,$\gamma$は割引率.
全体の俯瞰
大きく分けて4つある
-
Q学習
行動価値関数を最大化する最適な行動を取ることで,報酬最大化を目指し,今期と次期の間でTD法を適用し,最適価値関数に対して誤差を収束させる方法.価値ベースで方策オフであり,$\epsilon$貪欲法により探索と活用のトレードオフがとりやすいことや,経験再生が利用できることがメリット. -
SARSA
Q学習の時に用いたTD法を,今期と次期の2期ではなく,何期分も先の行動まで考慮した場合.価値ベースであるが,今期の方策(最適行動)の決定に用いる次期以降の行動と,実際に用いる行動は異なる場合がある($\epsilon$貪欲に行動が決まることによる)ため,方策オンになる.Q学習と比べると,数期先の行動まで考慮に入れた最適化を行えることがメリットであり,その分Q学習よりもリスク回避的であると言われる. -
方策勾配法
文字通り,方策を最適化していく際に,誤差から勾配を求めて最適解に近づいていく方法.方策からサンプリングした標本が不偏推定量となってくれるので扱いやすいのがメリット.また,行動集合や状態集合の要素数が膨大である場合や,連続的である場合などにも用いることができる.方策ベースで方策オン. -
Actor-Critic法
基本的には方策勾配法と似たようなものであるが,異なるのは,価値推定において,方策を選択する際のモジュール(actor)と方策を評価する際のモジュール(critic)を別々にしたこと.これにより,推定価値を過大評価しないようになったことがメリット.方策ベースで方策オン.
今回はこの中でもQ学習を中心に,以下の論文を読み,体系的にまとめてみました.(再掲)
Q学習<基礎~DQN~R2D3, Agent57>
基礎
-
Q学習とは?(再掲)
行動価値関数を最大化する最適な行動を取ることで,報酬最大化を目指し,今期と次期の間でTD法を適用し,最適価値関数に対して誤差を収束させる方法.価値ベースで方策オフであり,$\epsilon$貪欲法により探索と活用のトレードオフがとりやすいことや,経験再生が利用できることがメリット. -
ε-greedy法
Q学習では行動選択の際に,Q値が大きくなる行動を選択したいが,ある時たまたま大きなQ値が得られた行動が,実はそんなに良くない行動なのに選ばれ続けてしまうことがある.この問題に対する対策として,最適と思われる行動をとり続けるだけでなく,適度にもっと良い値が得られないか探索することが必要.そこで,その探索と最適行動選択のバランスをとるために,確率εで探索を強制的に行わせるようにしている方法.

Rainbowまでの流れ
-
DQN(deep Q-network)[1]
価値関数の推定を深層学習のネットワークを用いて行う.また,時系列相関の強いデータに対して学習をうまく行うために,経験再生(エージェントがデータサンプルをためておき,そこからサンプリングしてミニバッチ学習を行う)という工夫をしている.この結果,毎回の学習で全く違った結果が得られるという不安定性が解消され,より安定した学習を行えるようになった.
※画像はGorila[9]の論文より

-
優先度付き経験再生(Prioritized Experience Replay)[2]
DQNの経験再生で,サンプルを損失関数が大きくなるものから順に取り出すようにする.うまくいっていないところが優先的に学習できるようになり,学習効率が上がる. -
Double Q-learning[3], DDQN[4]
これまでは最適な行動を選択するQの価値関数と,その時のQ値を評価する関数が同じだったため,本当は価値が高くない行動なのに,誤って(誤差で)高い評価をし,モデルデータにしてしまうことがあった.そのため,最適行動を選択する関数とその時のQ値を評価する関数を別々に用意することで過大評価を抑制した.(雰囲気的にはActor-Criticに似ている.)
また,DDQNはDQNとDouble Q-learningを組み合わせたもの.
※ $q_{\bar{\theta}}$ と $q_{\theta}$ が区別されている.
$$\left(R_{t+1}+\gamma_{t+1} q_{\bar{\theta}}\left(S_{t+1}, \underset{a^{\prime}}{\operatorname{argmax}} q_{\theta}\left(S_{t+1}, a^{\prime}\right)\right)-q_{\theta}\left(S_{t}, A_{t}\right)\right)^{2}$$
-
Dueling Networks[5]
Q値のネットワークを途中からstate_value(状態価値)とadvantage(行動の価値のようなもの)に分けて,その和をQ値として学習するようにすると,要因分解してQ値を効率よく学習できる.(雰囲気的には,後述のAdvantage Actor-Criticと似ている.)
$$Q(s,a)=V(s)+A(s,a)$$

-
分布強化学習(Distributional Q-learning)[6]
報酬の期待値ではなく,報酬の分布関数を求めようとする手法.分布として報酬を求めることで,報酬に対するリスクまで考慮して強化学習を行うことができる.(例えば,期待報酬の最大化をしようとすると,最大報酬の確率が分からないので大きなリスクを取ってしまう場合があるが,分布が分かればリスク回避できるかもしれない,ということ.) -
Noisy Networks[7]
$\epsilon$貪欲法による探索では場合によっては効率が悪いことがあるので,行動価値関数を求めるDQNのネットワークの最終層にランダムなノイズを加え,より多様な状態を探索しやすくしている.
※$\epsilon^b$と$\epsilon^w$がノイズ.
$$\boldsymbol{y} = (\boldsymbol{b}+\mathbf{W} \boldsymbol{x})+\left(\boldsymbol{b}_{n o i s y} \odot \epsilon^{b}+\left(\mathbf{W}_{n o i s y} \odot \epsilon^{w}\right) \boldsymbol{x}\right)$$
-
Multi-step Learning(Boostrap)
DQNでは次状態におけるQ値の現在割引と今のQ値の合計で表されていたが,それをN期先までの考慮に拡張できるようになった.
※lossが,N期先の現在割引 $R_{t}^{(n)} + \gamma_{t}^{(n)} \max_{a^{\prime}} q_{\bar{\theta}}\left(S_{t+n}, a^{\prime}\right)$ と現在のQ値 $q_{\theta}\left(S_{t}, A_{t}\right)$ の差になっている.なお,$R_{t}^{(n)} \equiv \sum_{k=0}^{n-1} \gamma_{t}^{(k)} R_{t+k+1}$.
$$\left(R_{t}^{(n)} + \gamma_{t}^{(n)} \max_{a^{\prime}} q_{\bar{\theta}}\left(S_{t+n}, a^{\prime}\right)-q_{\theta}\left(S_{t}, A_{t}\right)\right)^{2}$$
-
Reward Clipping
報酬のスケールを [-1,1] に正規化し,一定にする方法.Q値の現在割引和が発散してしまうのを抑制し,Q値の急激な増加を防ぐことができるため勾配を安定化できる.一方で,報酬の大小はあまり区別されなくなる.
Rainbow[8]
今まで別々に研究されてきた上記のいろいろを全部のせて実装してみると,いい感じにSOTAになった.

Gorila[9]
分散学習をQ学習に導入した論文.仮想のエージェントを複数動かし,それらを同期してパラメータを更新したり,複数のエージェントの中から良さそうな行動を選んで実際にエージェントが行動する.経験再生に保存されるのは,実際に起こった経験で,仮想的なものは含まれない.

Ape-X[10]
特徴:優先度付き経験再生で分散処理したら速くなった&精度も大幅に向上した

-
分散処理
優先度付き経験再生を分散処理を用いて高速化に成功.(複数のアクターが同時に一つのreply memoryを共有して経験再生を行い,学習を進める.)Gorilaとの違いとしては,基本的にRainbowで利用された手法が使われており,特に優先度付き経験再生が行われている点がポイント.
R2D2[11]
特徴:時系列性をうまくQ値の算出に取り入れ,より自然な学習に

-
Sequentialデータを利用し,RNNを導入
今までは時系列相関により,あまり良くない今期にあまりよくない行動をとってしまっても,それまでの行動が良かった場合,今期の行動も良く評価されてしまうというジレンマがあり,経験再生からランダムに状態と行動の組をサンプリングしていた.一方,本来は時系列データは丸ごと学習させた方が良いはずで,R2D2ではそれを実現するために,1エピソード(ゲームの開始から終了まで)を丸ごとひとつの経験として経験再生にストックし,LSTMをQの推定に用いるようにしている.また,エピソードの長さによって経験の重みづけがされないよう,経験の大きさは正規化されている. -
Reward Clippingの廃止と価値の再スケール
今までは勾配消失や爆発を懸念して報酬は正規化されていたが,本来報酬は正規化されているわけではないので,より自然な環境での学習を行うためにクリッピングするのをやめた(エピソード内の報酬の振れ幅を学習に組み込むため).一方,引き続き安定した学習を行いたいという気持ちはあるので,報酬を正規化する代わりに,報酬って計算されたQ値の方を再スケールすることにした. -
Loss-of-Life-as-Episode-Endの取りやめ
これまではエージェントがゲームオーバーになったときに環境自体がが終わる設定になっていたが,実際にはエージェントがミスをしてゲームが終わっただけで,ゲーム自体の環境は続いていると考えられるので,ゲームオーバーになっても環境自体は修了しないという仮定を置いた.
R2D3[12]
特徴:Demonstrations(熟練の人間データ)を導入

背景:学習の困難性には,以下のような要因がある.
-
Sparse Rewards
報酬はエージェントが正しい行動をとり続けてようやく取得できるようになっている.ゲームが終わる最後の最後にしか報酬は手に入れられない. -
Partial Observability
エージェントは各timestepにおいて環境を部分的にしか観測できない. -
Highly Variable Initial Conditions
初期状態のバリエーションが多い(汎化性が持たせづらい).
Demonstraterはどうやって活用するのか?
- demo-ratioというハイパラによって,demonstrationsをミニバッチ内に混ぜ込む割合を決めている.この割合は,ごくごく小さい値にするのが良く,demo-ratioの調整が精度の鍵を握る.
- demonstratorがエージェントが学習する際のガイドになる.
- demonstrator(人間)が見つけられなかった(無意識に行っていた,または熟練者ですら行えていなかった)より適切な行動の特徴を発見できることもある.
Never Give Up (NGU) [13]
特徴:分散学習の強みを活かし,様々な方策の組み合わせを試して諦めずに探索

背景:人間データなしにスパースな報酬の探索問題を解くことは難しい
外部からの報酬がスパースならば,内的動機を報酬にしてしまうという方法が考えられるが,最初の方は積極的に探索していても,次第に内的動機が減衰してきてしまってだんだんと探索しなくなってしまう問題があった.(これは,最終的に最適行動をとりたいという探索と活用のトレードオフ問題と言える.)
工夫:諦めずに探索をずっと続けられるための内的動機による報酬設計と分散学習の設定を行った
- 内的動機の設計は,大きく以下の3つの工夫が行われている.
- 同じエピソード内で同じ状態を訪問することをなるべくなくし,新規性のある状態の訪問を推奨した.
- 異なるエピソード間にわたり,多く訪れた状態を訪問するのを緩やかにやめさせようとし,エピソード間にわたっても新規の状態への訪問を弱めに推奨した.
- 異なる状態の探索を推奨するため,状態はエージェントの環境に依存しないという仮定を置いた.
- また,分散学習は以下のような設定になっている.
- 重みづけされた複数のエージェントでネットワークと方策集合を共有し,各エピソードにおいてそれぞれのエージェントが各方策に沿って行動するようにした.
- これにより,ある程度良い行動を選んでいくような方策を行うエージェントを作りつつ,一方で諦めずにずっと探索を続けるエージェント,という役割分担を作り出すことができた。
- また,方策集合の更新は複数エージェントで同期して行うようになっている.
Agent57[14]
特徴:NGUに改良を加え,Atariゲーム全てで人間のレベルを超越

背景:NGUは探索を諦めない一方で,課題もあった
- Agent57はNGUと同じ著者によるもので,NGUの改良版になっている.
- 著者は,NGUは内的動機により探索し続ける点はスパースな外的報酬に対応できるものの,学習過程への貢献度によらずすべての方策を同じように学習していたことがボトルネックになっていたと述べている.(学習の場面に応じて,どの方策を優先すべきかをコントロールできていなかった.)
工夫:学習の過程に応じて方策の優先順位を動的に決定
- 行動価値Qを,外的報酬によるものと内的動機付けによるものに因数分解してパラメタ付けをすることで,それぞれを別のネットワークで最適化しつつ,学習過程に応じて外的報酬と内的動機の重みづけを変えていくことができるようになった.
- 方策集合のなかのどの方策を優先させるか,学習過程に応じて動的に決定していくmeta-controllerを導入した.
- 以上により,全体的に学習の安定性が向上し,Atariの全ゲームで人間レベルを超越できた.
Actor-Critic<基礎~A3C>
基礎
-
Actor-Criticとは?(再掲)
価値推定において,方策を選択する際のモジュール(actor)と方策を評価する際のモジュール(critic)を別々になっている.これにより,推定価値を過大評価しないようになったことがメリット.方策ベースで方策オン.

A3CとA2C[15]
-
Advantageの導入
Actor-Criticに,ある状態における行動の相対的な良さを示すアドバンテージ関数を導入し,方策を改善.これにより,状態の良さに学習が左右されにくくなる.
$$A^{\pi}(s, a) \triangleq Q^{\pi}(s, a) - V^{\pi}(s), \quad \forall(s, a) \in \mathcal{S} \times \mathcal{A} \
\mathbb{E}_{\pi} \left[A^{\pi}(S, A) | S=s \right]=0, \quad \forall s \in \mathcal{S}$$ -
A3C/A2Cの違い(同期・非同期)
A3CはQ学習のGorilaの流れを汲んで,分散学習を行う.方策ベースであるので,経験再生は利用せず,各エージェントネットワークがグローバル・パラメータを勾配により直接改善していくが,その際にエージェント間で同期を行わないのがA3C,同期をおこなうのがA2C.
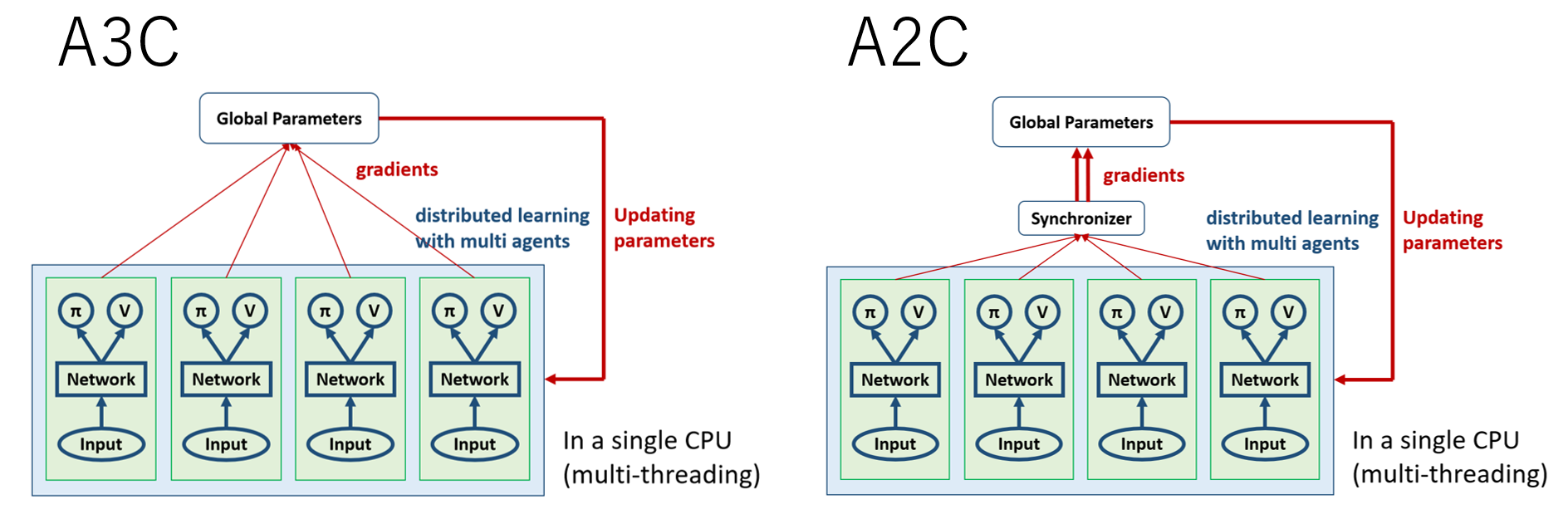
追記と修正
A2Cで"Advantage"と呼ばれているのは,上記の相対的な良さを表すAdvantageではなく,行動価値関数Qの推定に1期まで考えるだけでなく,n期先まで考えて行うことを指していたようです.なお,上記の相対的な良さを表す方のAdvantageもA2Cには実装されているので,2つの異なるAdvantageがA2Cには導入されており,論文で提案されているAdvantageはnステップ先まで考える方を指している,ということに注意が必要となります.(2020.08)
Q学習とActor-Criticとの関係
Q学習とActor-Criticとの使い分けは難しいが,Q学習とActor-Criticにはそれぞれ以下のようなpros&consがある.

但し書き
とはいえ,近年ではQ学習での重点サンプリングによりデータの不偏性を疑似的に獲得したり,Actor-Criticでもマルチエージェント化によってエージェント単位での$\epsilon$による探索と活用のトレードオフが図られたりと,どちらも弱点を克服するような提案がなされているそう.さらに,方策ベースとQ学習を組み合わせるようなモデル(PGQ[16])や,Q学習での工夫をActor-Criticに応用するということもある(分散学習など)ようで,やはり使い分けはよく分からなかった.また今度Actor-Critic系統についても勉強してみたい.
Appendix
マルチエージェント強化学習(MARL)への導入
強化学習における興味深い議論のひとつに,マルチエージェント化があります.これは,ひとつの環境に複数の行動主体を存在させ,目的に応じた最適化を行う分野のことです.今までは,単体のエージェントを考えてきたので各エージェントに自身の利得(報酬)を最大化させるだけで十分でしたが,複数のエージェントにした場合,実は話はそんなに単純ではありません.なぜなら,各エージェントが自分の利得を最大化しようとした結果,時として社会的ジレンマが発生するようなゲーム理論的な課題が起こってしまったり,他のエージェントの存在によって各エージェントが環境をコントロールできなくなってしまうからです.その中で,どのようにエージェント集団を協調させたり,逆に敵対的に学習させたり,自律分散システムを導入したりしていくのか.それらは,とても興味深い議論であると言えます.
MARLはそれ自体非常に広い分野であるためここでは詳しくは述べませんが,スライドにまとめてみたので興味ある方は見てみてください.
強化学習とゲーム理論(MARL)
オフライン強化学習(OfflineRL)への導入
【追記(2021.04)】
近年強化学習界隈で話題を集めているもう一つのテーマに,強化学習をオフラインで,過去に蓄積されたデータのみを使って学習しよう,というものがあります.これまでゲームAIを中心とした強化学習の発展の発展にはシミュレーション環境の実装が大きく貢献してきて,エージェントに実環境と相互作用して十分に探索させることにより,囲碁などで人間のパフォーマンスを上回ることができました.一方,これから強化学習を導入していきたい実応用の場面では,このようにオンラインで環境に作用しながら探索を行うことは時にはリスクがあります.例えば,医療の意思決定や自動運転,ロボット制御に強化学習を応用する場合には,エージェントがうまく学習できていない場合や探索的な行動は重大な事故に繋がる恐れがあります.そこで,これらの意思決定最適化のための強化学習を,オフラインで,実環境と作用することなく学習し,過去に集めたデータのみを使って学習し,さらにある程度の性能保証まで与えた上で実応用に利用したいというモチベーションがあります.この,オフラインでの意思決定のエージェントの学習の実現のために研究が盛り上がっているオフライン強化学習とオフ方策評価についてまとめたgithubレポジトリとスライドを公開したので,興味ある方はぜひ見てみてください.
awesome-offline-rl
Offline Reinforcement Learning
【追記(2021.05)】
Qiita記事も公開しました.
ゼロから始めてオフライン強化学習とConservative Q-Learningを理解する
参考文献
全体を通して
- MLP機械学習プロフェッショナルシリーズ強化学習,森村哲郎,講談社
- 速習強化学習-基礎理論とアルゴリズム-,Csaba Szepesvari,小山田創哲訳,共立出版
- A (Long) Peek into Reinforcement Learning
- 深層強化学習アルゴリズムまとめ
全体の俯瞰
Q学習<基礎~DQN~R2D3, Agent57>
原論文
- [1] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. "Playing Atari with Deep Reinforcement Learning". NeurIPS, 2013. [link]
- [2] Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. "Prioritized Experience Replay". ICLR, 2016. [link]
- [3] Hado Hasselt. "Double Q-learning". NeurIPS, 2010. [link]
- [4] Hado van Hasselt, Arthur Guez, and David Silver. "Deep Reinforcement Learning with Double Q-Learning". AAAI, 2016. [link]
- [5] Ziyu Wang, Tom Schaul, Matteo Hessel, Hado van Hasselt, Marc Lanctot, and Nando de Freitas. "Dueling Network Architectures for Deep Reinforcement Learning". ICML, 2016. [link]
- [6] Marc G. Bellemare, Will Dabney, and Rémi Munos. "A Distributional Perspective on Reinforcement Learning". ICML, 2017. [link]
- [7] Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, and Shane Legg. "Noisy Networks For Exploration". ICLR, 2018. [link]
- [8] Matteo Hessel, Joseph Modayil, Hado van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. "Rainbow: Combining Improvements in Deep Reinforcement Learning". AAAI, 2018. [link]
- [9] Arun Nair, Praveen Srinivasan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Vedavyas Panneershelvam, Mustafa Suleyman, Charles Beattie, Stig Petersen, Shane Legg, Volodymyr Mnih, Koray Kavukcuoglu, and David Silver. "Massively Parallel Methods for Deep Reinforcement Learning". ICML, 2015. [link]
- [10] Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado van Hasselt, and David Silver. "Distributed Prioritized Experience Replay". ICLR, 2018. [link]
- [11] Steven Kapturowski, Georg Ostrovski, John Quan, Remi Munos, and Will Dabney. "Recurrent Experience Replay in Distributed Reinforcement Learning". ICLR, 2019. [link]
- [12] Tom Le Paine, Caglar Gulcehre, Bobak Shahriari, Misha Denil, Matt Hoffman, Hubert Soyer, Richard Tanburn, Steven Kapturowski, Neil Rabinowitz, Duncan Williams, Gabriel Barth-Maron, Ziyu Wang, Nando de Freitas, and Worlds Team. "Making Efficient Use of Demonstrations to Solve Hard Exploration Problems". ICLR, 2020. [link]
- [13] Adrià Puigdomènech Badia, Pablo Sprechmann, Alex Vitvitskyi, Daniel Guo, Bilal Piot, Steven Kapturowski, Olivier Tieleman, Martín Arjovsky, Alexander Pritzel, Andew Bolt, and Charles Blundell. "Never Give Up: Learning Directed Exploration Strategies". ICLR, 2020. [link]
- [14] Adrià Puigdomènech Badia, Bilal Piot, Steven Kapturowski, Pablo Sprechmann, Alex Vitvitskyi, Daniel Guo, and Charles Blundell. "Agent57: Outperforming the Atari Human Benchmark". ICML, 2020. [link]
解説記事
- 【深層強化学習】Ape-X 実装・解説, 論文で理解するApe-Xの概要|論文で理解する深層強化学習の研究トレンド#1
- 深層強化学習手法R2D2を理解する
- 論文で理解するR2D2の概要|論文で理解する深層強化学習の研究トレンド#2
- 論文で理解するR2D3の概要|論文で理解する深層強化学習の研究トレンド#3
Actor-Critic<基礎~A3C>
原論文
- [15] Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, Koray Kavukcuoglu. "Asynchrous Methods for Deep Reinforcement Learning". ICML, 2016. [link]
解説記事
追記(と修正)
- つくりながら学ぶ!深層強化学習 PyTorchによる実践プログラミング,小川雄太郎,マイナビ出版
Q学習とActor-Criticとの関係
- [16] Brendan O'Donoghue, Remi Munos, Koray Kavukcuoglu, and Volodymyr Mnih. "Combining Policy Gradient and Q-Learning". ICLR, 2017. [link]
- 【論文紹介】PGQ: Combining Policy Gradient And Q-learning