強化学習を一旦掘り下げられるよう整理したかったので,
- いつ
- だれが
- (どんな問題を解いたアルゴリズムで)
- 何の略称で
- 親は誰なのか
系図を作ってまとめてみました.(取り違えているかもしれません)
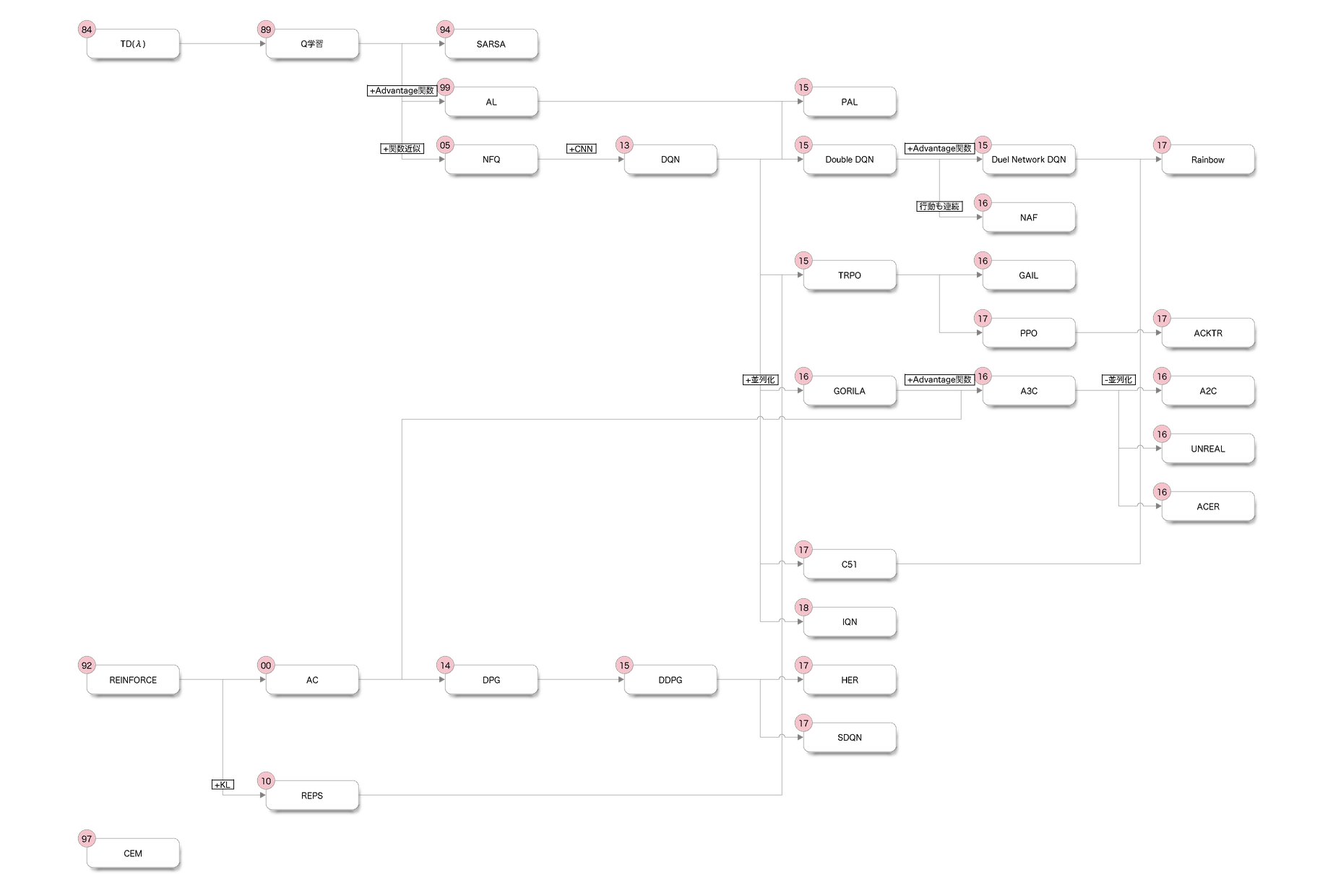
図: 主要な強化学習アルゴリズムの系図(左上の数字は誕生年)
TD(λ)(Sutton, 1984;1988)
- Temporal Differences
- Sutton, Richard S. "Learning to predict by the methods of temporal differences." Machine learning 3.1 (1988): 9-44.
Q学習(Watkins, 1989)
- Watkins, Christopher JCH, and Peter Dayan. "Q-learning." Machine learning 8.3-4 (1992): 279-292.
REINFORCE(Williams, 1992)
- REward Increment = Nonnegative Factor Offset Reinforcement
- Williams, Ronald J. "Simple statistical gradient-following algorithms for connectionist reinforcement learning." Machine learning 8.3-4 (1992): 229-256.
SARSA(Rummery, 1994)
- State-Action-Reward-State-Actionの略称(論文の注釈で登場)
- Rummery, Gavin A., and Mahesan Niranjan. On-line Q-learning using connectionist systems. Vol. 37. Cambridge, England: University of Cambridge, Department of Engineering, 1994.
- cf. sugulu, Qiita -【強化学習初心者向け】シンプルな実装例で学ぶSARSA法およびモンテカルロ法【CartPoleで棒立て:1ファイルで完結】
CEM(Rubenstein, 1997)
- Cross Entropy Method
- 進化的アルゴリズム
- 参考1: http://web.mit.edu/6.454/www/www_fall_2003/gew/CEtutorial.pdf
- 参考2: https://esc.fnwi.uva.nl/thesis/centraal/files/f2110275396.pdf
- 参考3: http://learning.mpi-sws.org/mlss2016/slides/2016-MLSS-RL.pdf
AL(Baird Ⅲ, 1999)
- Advantage Learning
- Baird III, Leemon C. Reinforcement learning through gradient descent. No. CMU-CS-99-132. CARNEGIE-MELLON UNIV PITTSBURGH PA DEPT OF COMPUTER SCIENCE, 1999.
AC(Sutton et al., 2000)
- Actor-Critic
- Sutton, Richard S., et al. "Policy gradient methods for reinforcement learning with function approximation." Advances in neural information processing systems. 2000.
NFQ(Riedmiller, 2005)
- Neural Fitted Q Iteration
- Riedmiller, Martin. "Neural fitted Q iteration–first experiences with a data efficient neural reinforcement learning method." European Conference on Machine Learning. Springer, Berlin, Heidelberg, 2005.
REPS(Peters et al., 2010)
- Relative Entropy Policy Search
- Peters, Jan, Katharina Mülling, and Yasemin Altun. "Relative Entropy Policy Search." AAAI. 2010.
DQN(Mnih et al., 2013)
- Deep Q-Networks
- Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013).
- cf. sugulu, Qiita -【強化学習初心者向け】シンプルな実装例で学ぶQ学習、DQN、DDQN【CartPoleで棒立て:1ファイルで完結、Kearas使用】
DPG(Silver et al., 2014)
- Deterministic Policy Gradient
- Silver, David, et al. "Deterministic policy gradient algorithms." ICML. 2014.
DDQN(Hasselt et al., 2015)
- Double DQN
- Van Hasselt, Hado, Arthur Guez, and David Silver. "Deep Reinforcement Learning with Double Q-Learning." AAAI. Vol. 2. 2016.
- cf. sugulu, Qiita -【強化学習中級者向け】実装例から学ぶDueling Network DQN 【CartPoleで棒立て:1ファイルで完結】
Dueling DQN(Wang et al., 2015)
- Double DQNの進化版
- Wang, Ziyu, et al. "Dueling network architectures for deep reinforcement learning." arXiv preprint arXiv:1511.06581 (2015).
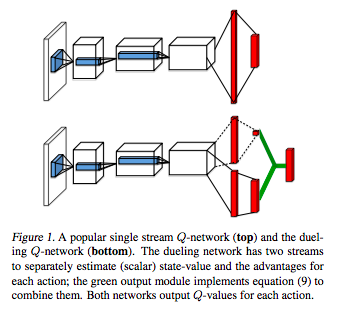
PAL(Bellemare et al., 2015)
- Persistent Average Learning
- Wang, Ziyu, et al. "Dueling network architectures for deep reinforcement learning." arXiv preprint arXiv:1511.06581 (2015).
TRPO(Schulman et al., 2015)
- Trust Region Policy Optimization
- Schulman, John, et al. "Trust region policy optimization." International Conference on Machine Learning. 2015.
DDPG(Lillicrap et al., 2015)
- Deep DPG
- Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015).
PER(Schual et al., 2015)
- Prioritized Experience Replay
- Schaul, Tom, et al. "Prioritized experience replay." arXiv preprint arXiv:1511.05952 (2015).
- sugulu, 【強化学習中級者向け】実装例から学ぶ優先順位付き経験再生 prioritized experience replay DQN 【CartPoleで棒立て:1ファイルで完結】
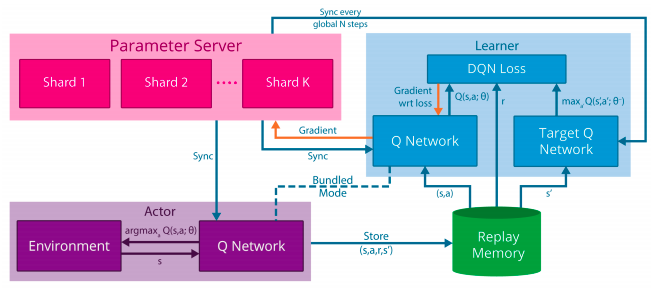
Gorila(Nair et al., 2016)
- General Reinforcement Learning Architecture
- Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International conference on machine learning. 2016.
NAF(Gu et al., 2016)
- Normalized Advantage Function
- 行動空間が連続な問題でも解けるようDouble DQNを拡張
- Gu, Shixiang, et al. "Continuous deep q-learning with model-based acceleration." International Conference on Machine Learning. 2016.
A3C(Mnih et al., 2016)
- Asynchronous Advantage Actor-Critic
- Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International conference on machine learning. 2016.
- cf. sugulu, Qiita -【強化学習】実装しながら学ぶA3C【CartPoleで棒立て:1ファイルで完結】
A2C(Mnih et al., 2016)
- Advantage Actor-Critic
- アイデア: https://blog.openai.com/baselines-acktr-a2c/
- Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International conference on machine learning. 2016.
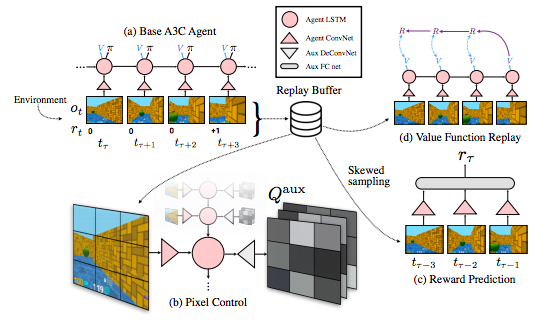
UNREAL(Jarderberg et al., 2016)
- UNsupervised REinforcement and Auxiliary Learning
- Jaderberg, Max, et al. "Reinforcement learning with unsupervised auxiliary tasks." arXiv preprint arXiv:1611.05397 (2016).
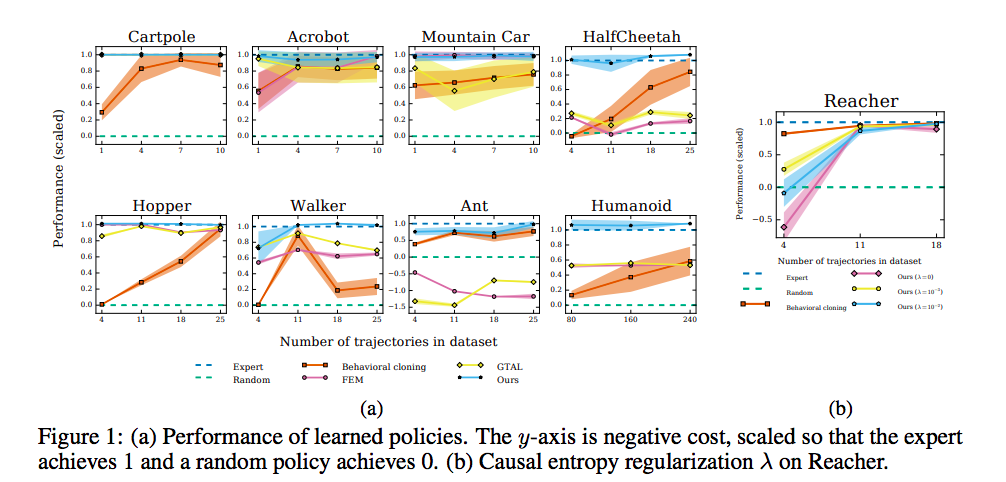
GAIL(Ho et al., 2016)
- Generative Adversarial Imitation Learning
- Ho, Jonathan, and Stefano Ermon. "Generative adversarial imitation learning." Advances in Neural Information Processing Systems. 2016.
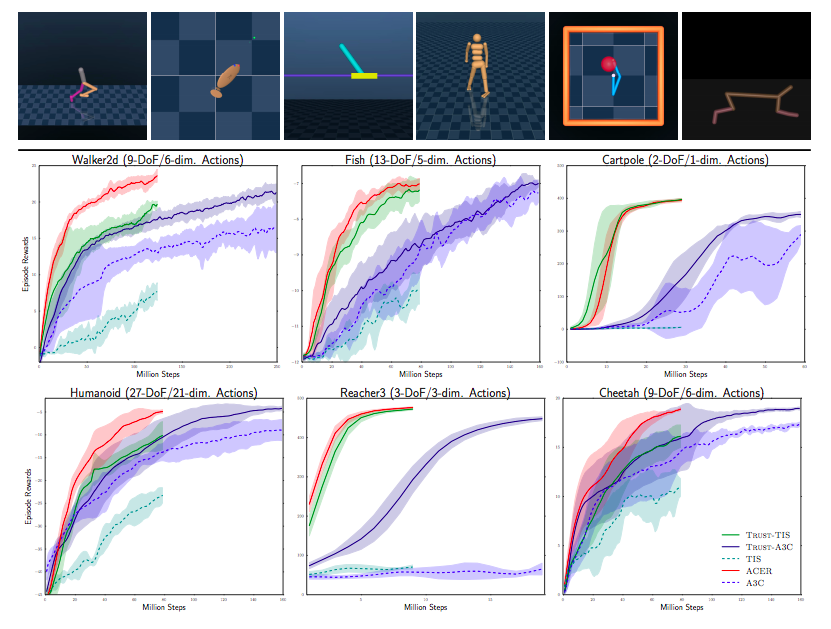
ACER(Wang et al., 2016)
- Actor-Critic with Experience Replay
- Wang, Ziyu, et al. "Sample efficient actor-critic with experience replay." arXiv preprint arXiv:1611.01224 (2016).
HER(Andrychowicz et al., 2017)
- Hindsight Experience Replay
- Andrychowicz, Marcin, et al. "Hindsight experience replay." Advances in Neural Information Processing Systems. 2017.
- cf. ishizakiiii, Qiita - 失敗からも学ぶ 強化学習 HERのアルゴリズムを理解して、OpenAI Gymの新しいロボットで試してみた
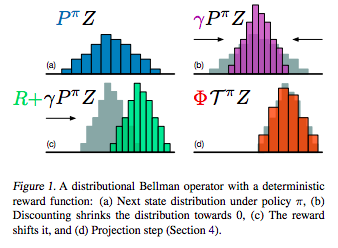
C51(Bellemare et al., 2017)
- Rainbowの特殊系
- A Distributional Perspective on Reinforcement Learning
- Bellemare, Marc G., Will Dabney, and Rémi Munos. "A distributional perspective on reinforcement learning." arXiv preprint arXiv:1707.06887 (2017).
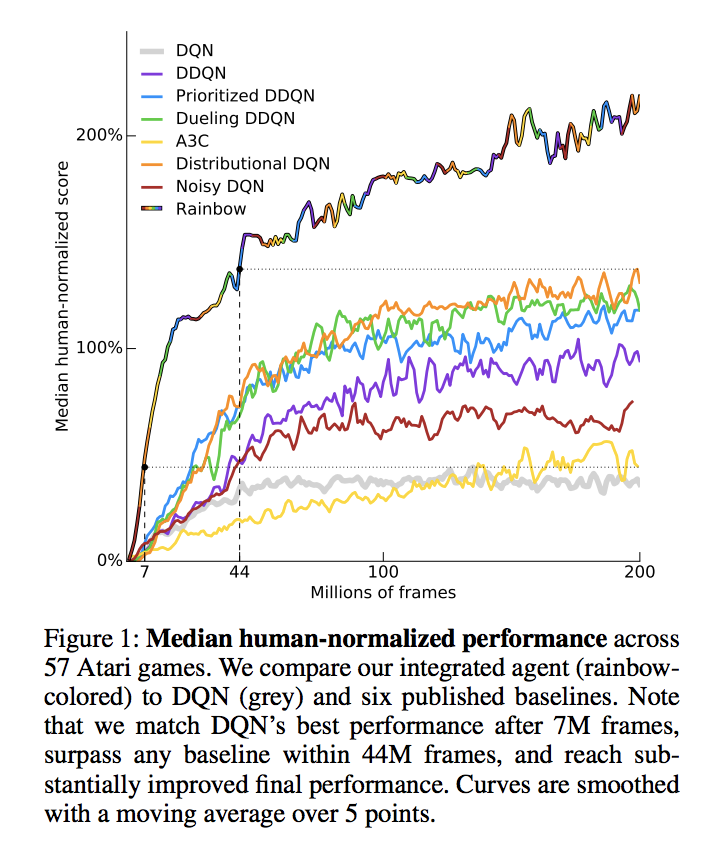
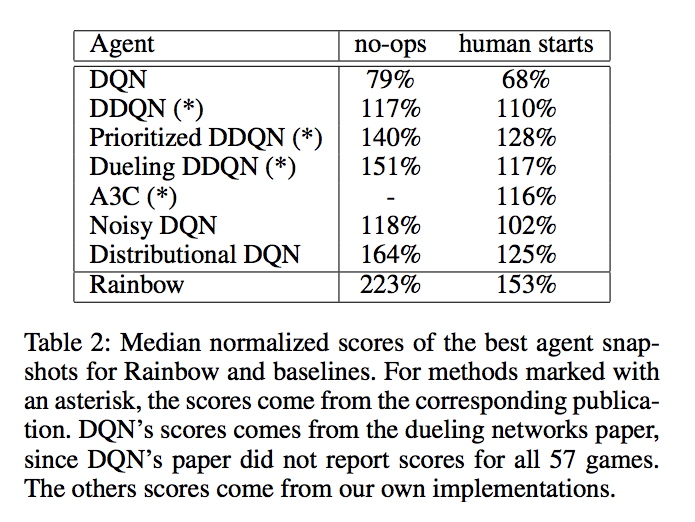
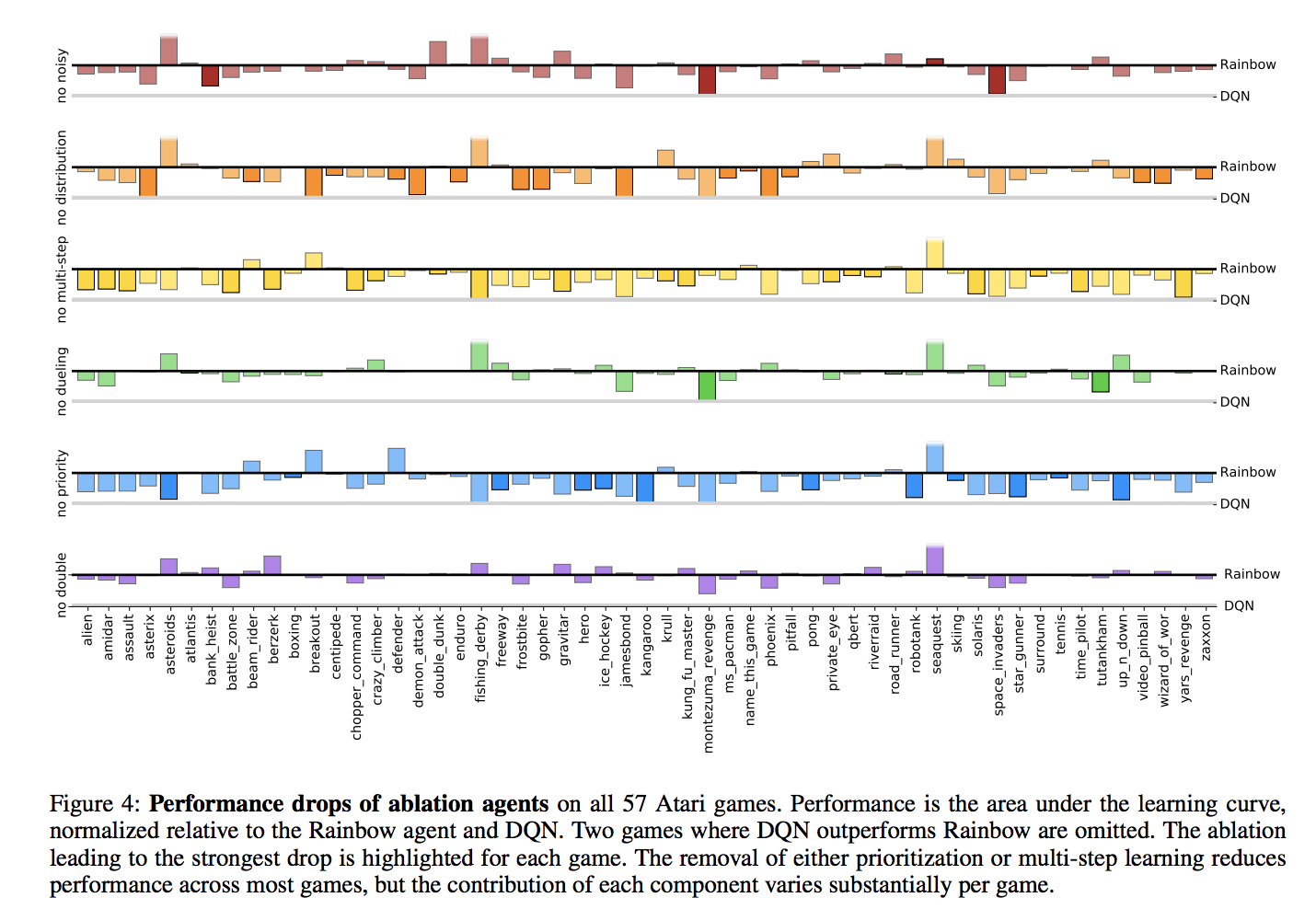
Rainbow (Hessel et al., 2017)
- Hessel, Matteo, et al. "Rainbow: Combining improvements in deep reinforcement learning." arXiv preprint arXiv:1710.02298 (2017).
- cf. Jun Okumura, SlideShare - DQNからRainbowまで 〜深層強化学習の最新動向〜



PPO(Schulman et al., 2017)
- Proximal Policy Optimization
- Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
- cf. sugulu, Qiita -【強化学習】実装しながら学ぶPPO【CartPoleで棒立て:1ファイルで完結】
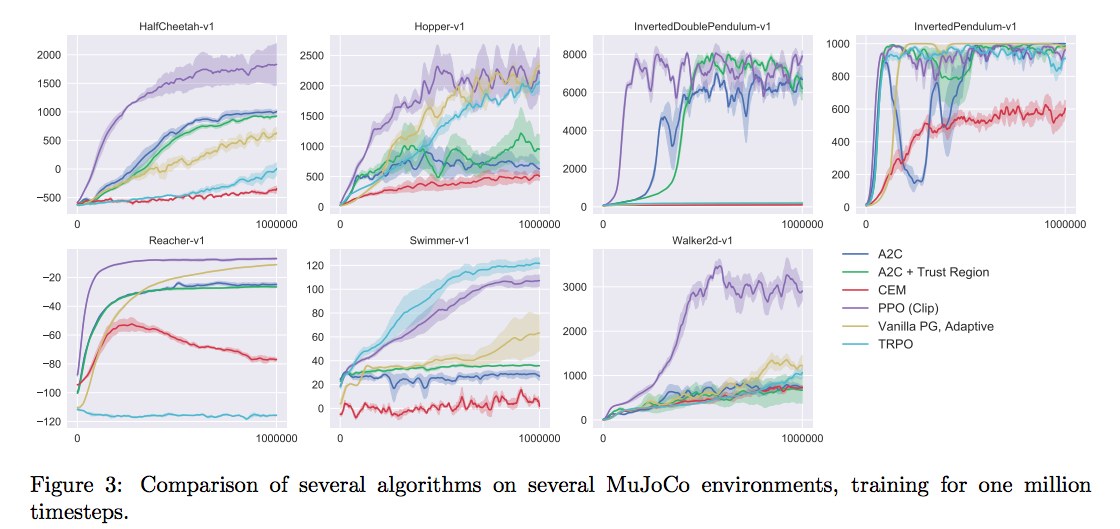
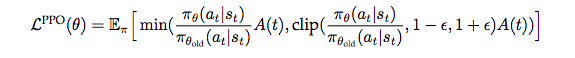
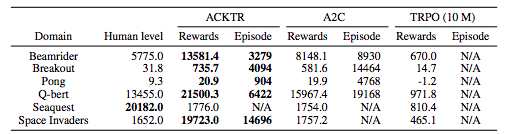
ACKTR(Wu et al., 2017)
- Actor Critic using Kronecker-Factored Trust Region
- Wu, Yuhuai, et al. "Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation." Advances in neural information processing systems. 2017.
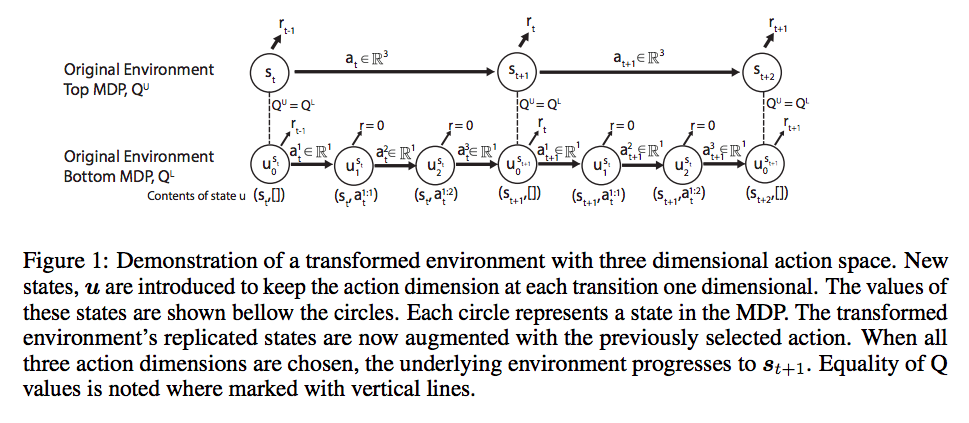
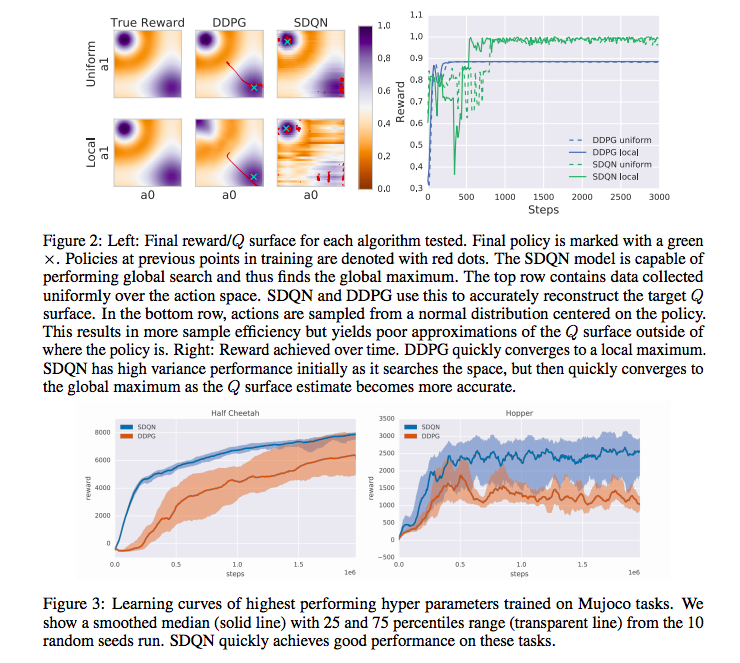
SDQN(Metz et al., 2017)
- Sequential DQN
- Metz, Luke, et al. "Discrete sequential prediction of continuous actions for deep RL." arXiv preprint arXiv:1705.05035 (2017).
QR-DQN(Dabney et al., 2017)
- Quantile Regression DQN
- Dabney, Will, et al. "Distributional reinforcement learning with quantile regression." arXiv preprint arXiv:1710.10044 (2017).
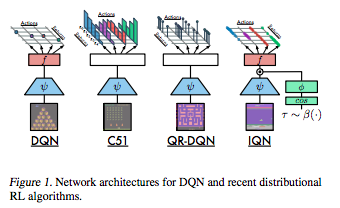
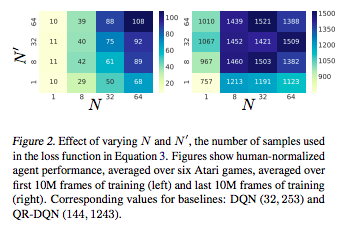
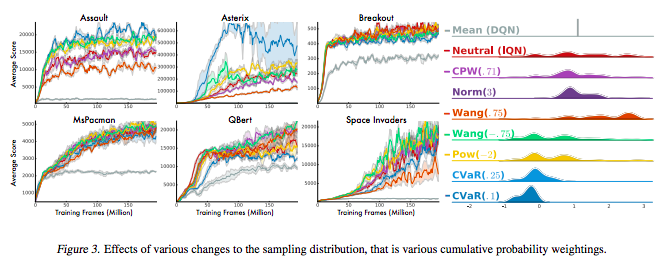
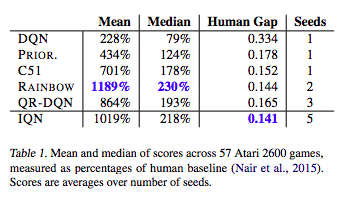
IQN(Dabney et al., 2018)
- Implicit Quantile Network
- Dabney, Will, et al. "Implicit Quantile Networks for Distributional Reinforcement Learning." arXiv preprint arXiv:1806.06923 (2018).
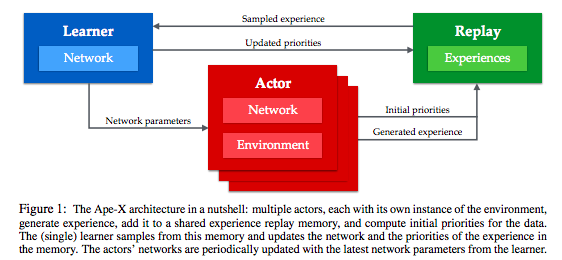
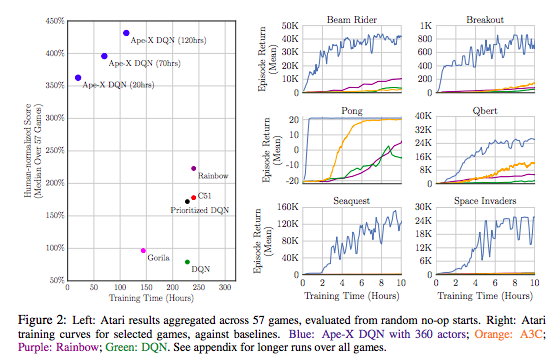
Ape-X(Horgan et al. 2018)
- DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY
- 参考: 【深層強化学習】『2018年最強手法(?)』Ape-X 実装・解説, Qiita.