概要
OpenAI Gymが新しい環境Roboticsを公開したので(公式ブログ)試してみました。 また、その中でHER(Hindsight Experience Replay)で、良いパフォーマンスが出たそうなので、アルゴリズムを理解し、動かしてみました。

環境作り
Python3.5.2の環境で、OpenAI GymのインストールとMuJoCoとmujoco-pyのインストールが必要です。
MoJoCoを使うのはライセンスが必要ですが、一旦、無償版(30日間)を使いました。
MuJoCoのライセンス取得
MuJoCoとMuJoCo-pyのインストール方法(公式GitHub)
OpenAI Gymのインストール方法(公式GitHub)
環境の種類
今回、8つのRobotics環境が公開されました。
Fecthと呼ばれる、物を摘めるようなロボットと、ShadowHandという手の動きを再現しているロボットがあります。
それぞれの環境の目的は以下の通りです。

HER(Hindsight Experience Replay)
考え方
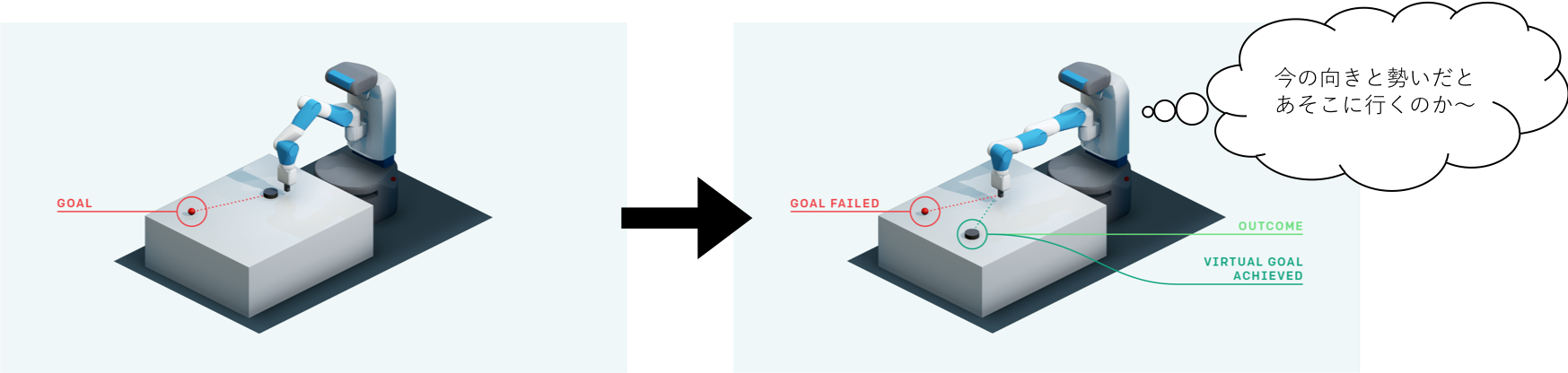
私たち人間はボールを転がした時、もしも目的の場所に辿り着かなくても、
「今の感じで転がすとあの辺に行くのか。ということは...」
と、失敗してもその体験を次のチャレンジに活かします。
強化学習でも同じように、試行結果が失敗で報酬が無くても、その試行データを利用して目的の達成に役立てよう、という考えです。
特徴
通常の価値関数は「ある状態$s$である行動$a$をとる価値」を表しますが、HERでは「ゴール:$g$」というインプットを増やし、「あるゴール$g$に対し、ある状態$s$である行動$a$をとる価値」を価値関数として定めます。
一度試行してみて、本来のゴールとは違う場所に辿り着いたとしても、後からそこを擬似ゴールとみなして報酬$+1$を設定し、今しがた試行した軌跡は擬似ゴールに辿りつくための成功の軌跡とみなし、その軌跡情報から、価値関数を更新します。
このような(Roboticsのような)問題・環境では、各ゴール間の空間的な距離(各位置)は意味を持っているため、ゴールの位置がインプットになっている価値関数において、失敗による擬似ゴールでの価値関数の更新が有効利用されます。
アルゴリズム全体
準備
- オフポリシーのアルゴリズム($Algorithm$)を選びます。(DQN等)
- 擬似ゴールを設定する戦略($Storategy$)を定めます。
- 報酬関数は $r:S \times A \times G \rightarrow R$ ($G$はゴール位置)
学習
1. バッファー$Re$を初期化
2. 以下を必要な回数分繰り返す
2-1. 本当のゴール$g$と初期状態$s_0$を定める
2-2. 以下を終末まで繰り返す
2-2-1. $Algorithm$のポリシーからゴール$g$に対する状態$s_t$の時の$a_t$を決めて行動する
2-3. 以下を2−2.の軌跡で繰り返す
2-3−1. ($s_t, s_{t+1}, r_t, a_t, g$)を全て観測して$Re$に記録しておく
2-3−2. 今回のエピソード2−2.の軌跡から$Storategy$に沿って、擬似ゴール$G$を決める
2-3−3. 全ての擬似ゴール$g' \in G$において以下を繰り返す
2-3−3−1. 擬似ゴールに対する報酬を$r'$として取得する
2-3−3−2. ($s_t, s_{t+1}, r'_t, a_t, g'$)を全て観測して$Re$に記録しておく
2-4. $Re$からミニバッチを取り出し、$Algorithm$のパラメータ更新を1エポック実施する。
$Storategy$の一番簡単なものは、エピソードの最後の位置を擬似ゴールにすることですが、エピソード内のその時点$t$より先の位置をランダムに複数選択すると、良い場合もあるようです。
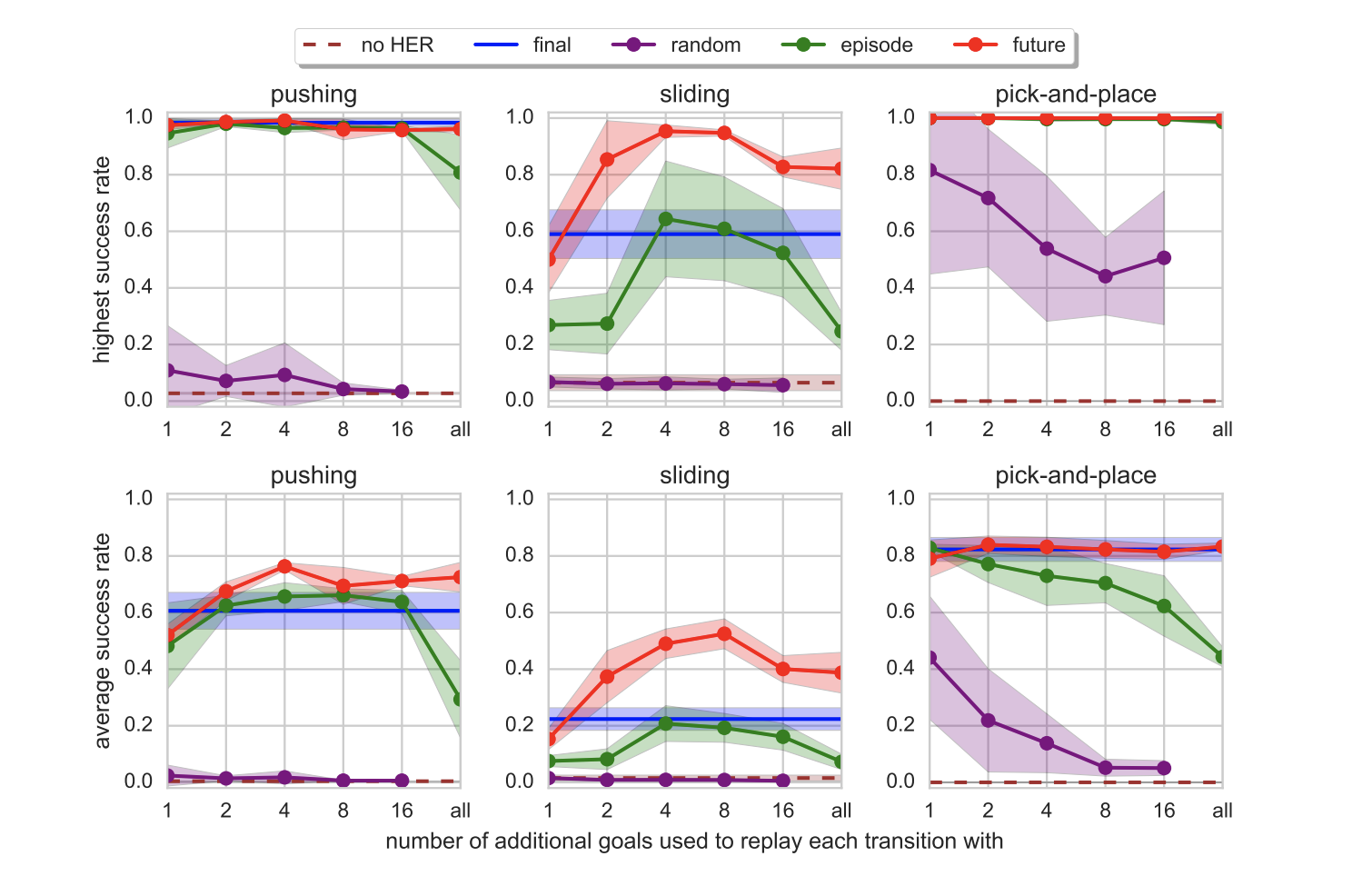
- future : エピソード内の、現時点より先の位置を擬似ゴールとする
- episode : エピソード内のランダム時点の位置を擬似ゴールとする
- random : 別エピソードも含めて過去のランダムな時点の位置を擬似ゴールとする
- final : エピソードの最後の時点の位置を擬似ゴールとする
Baselinesで試す
HERを試すため、OpenAIから出ているBaselinesを利用しました。(⬅︎ 手抜き)
Baselinesのインストール 公式
インストールでmpiのエラーが出たので、以下で対処。
brew install mpich
pip install mpi4py
学習
引数で環境の設定を好きなものに書き変えられます。
デフォルトはFetchReach-v0です。今回は変えませんでした。
python -m baselines.her.experiment.train
結果
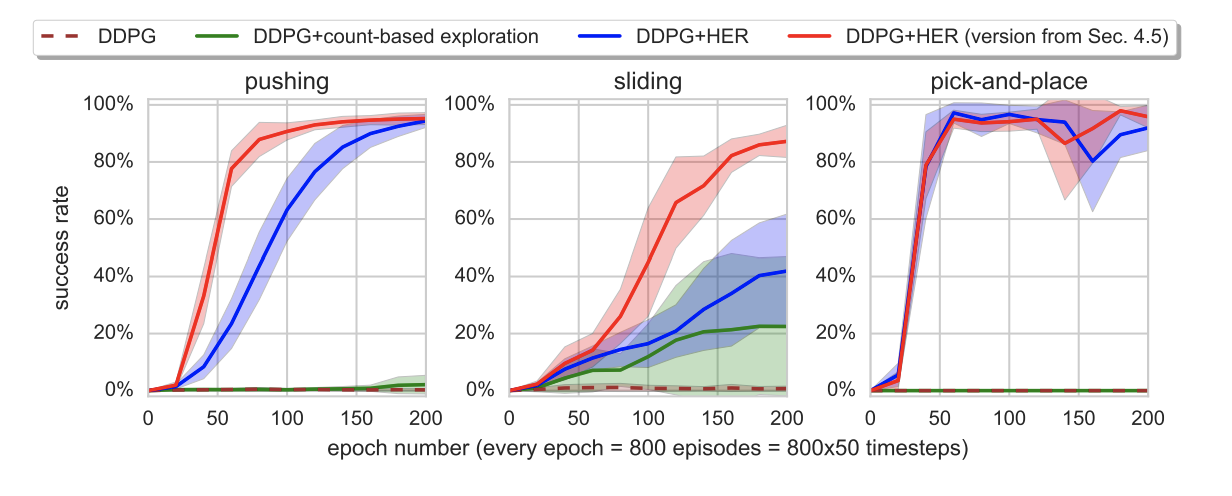
分かりにくいですが、全部成功してます。
python -m baselines.her.experiment.play {生成されたpklファイルパス}


論文ではDDPGだけのものと比較していますが、HERありの方がパフォーマンスが良いのが分かります。
実装して試す
一旦、流れだけ書きました。
ちゃんと書いたら、記事を更新します。
import gym
env = gym.make('FetchSlide-v0')
obs = env.reset()
done = False
R =[]
action_list = []
substitute_goal = None
while not done:
# off-policyアルゴリズムの方策によって、Actionを決める
action = policy(obs['observation'], obs['desired_goal'])
next_obs, reward, done, info = env.step(action)
# バッファに記録
R.append((action, obs['observation'], next_obs['observation'],
reward, obs['desired_goal']))
# 擬似ゴール用の行動履歴
action_list.append(action)
if done:
# 今辿り着いたところを擬似ゴールと設定
substitute_goal = obs['achieved_goal']
obs = next_obs
for replay_action in action_list:
next_obs, reward, done, info = env.step(replay_action)
# 擬似ゴールに対する報酬の取得
substitute_reward = env.compute_reward(
obs['achieved_goal'], substitute_goal, info)
# バッファに記録
R.append((replay_action, obs['observation'], next_obs['observation'],
substitute_reward, substitute_goal))
obs = next_obs
上記のようにバッファRに記録をしたら、Rからミニバッチを取得してアルゴリズムのパラメータ更新を行う。
参考
Hindsight Experience Replay 論文
Medium : Learning from mistakes with Hindsight Experience Replay
Qiita : 物理エンジンmujoco登録の仕方
Open AI Gym & MuJoCo を使う
おわり
3Dロボットカッコいいので、MuJoCoのライセンスを買おうかな、と思いました![]()
記載に誤りがありましたら、ご指摘いただけたら嬉しいです。