はじめに
__s_o__ です。
EC2 上のログをログエージェントを利用して CloudWatch Logs に転送することは、意外とやっている人が多いかもしれません。
今回はそこから少しだけ発展させて、CloudWatch Logs から S3 にログをエクスポートし、さらにそのログを Athena で取り込んで分析可能な状態にするまで掘り下げてみたいと思います。
各サービスの特徴と運用イメージ
| サービス名 | 説明 | 実際の運用イメージ |
|---|---|---|
| EC2 | AWS の IaaS 環境 | Web サーバ (nginx) を動かしている |
| CloudWatch Logs | AWS 環境のログを収集・整理する | nginx のログをリアルタイムで収集し、マネジメントコンソールから閲覧可能な状態にする |
| S3 | AWS のオブジェクトストレージ | 定期的に CloudWatch Logs のログをアーカイブする (gzip 保管) |
| Athena | S3 内のデータを、SQL などで分析可能な状態にする | アーカイブされたログを分析する (アクセス件数など) |
サービス間の連携を図示したものは下記となります。
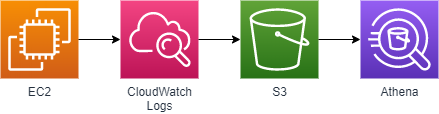
設定の流れ
EC2 (nginx ログ) → CloudWatch Logs の設定
EC2 上の nginx ログを CloudWatch Logs に出力します。下記記事を参考に、ひとまず access_log のみ転送するように設定します。
[/var/log/nginx/access.log]
datetime_format = %d/%b/%Y:%H:%M:%S %z
file = /var/log/nginx/access.log
buffer_duration = 5000
log_stream_name = {instance_id}
initial_position = start_of_file
log_group_name = /var/log/nginx/access.log
設定変更後、awslogs を再起動します。
$ sudo systemctl restart awslogsd
$ sudo systemctl status awslogsd
しばらく後、下記のように CloudWatchLogs にログが転送されます。
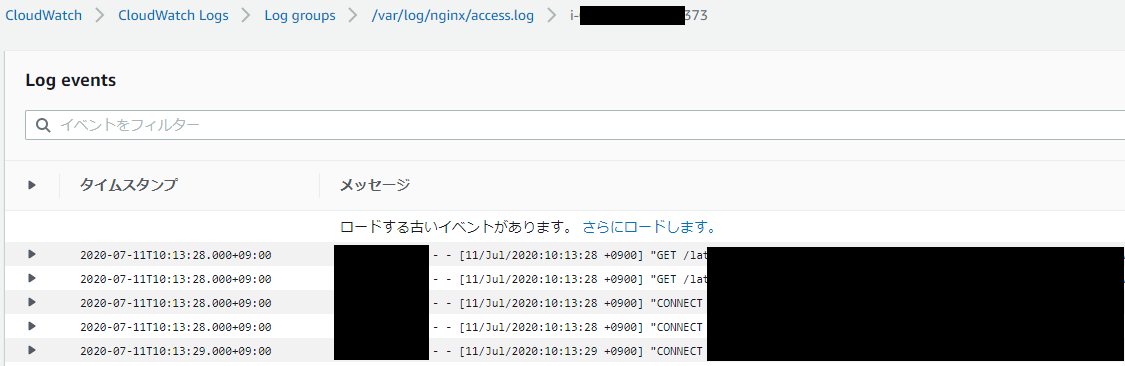
CloudWatch Logs → S3 の設定
CloudWatch Logs を S3 にエクスポートします。なお、あらかじめ「logs.xxx.yyy.zzz」というバケットを作成済みとします (「xxx.yyy.zzz」は任意のドメイン名を示しています。適時 読み替えてください)。
下記記事を参考にしながら、設定を進めていきます。
まずはバケット「logs.xxx.yyy.zzz」に、下記バケットポリシーを設定し、CloudWatch Logs からアクセス可能な状態にします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logs.ap-northeast-1.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::logs.xxx.yyy.zzz"
},
{
"Effect": "Allow",
"Principal": {
"Service": "logs.ap-northeast-1.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::logs.xxx.yyy.zzz/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}
上記設定後、CloudWatch Logs に移動し、先ほど設定したロググループ (今回の場合は「/var/log/nginx/access.log」) を指定します。右上のメニューより「アクション」 > 「データを Amazon S3 にエクスポート」を選択します。

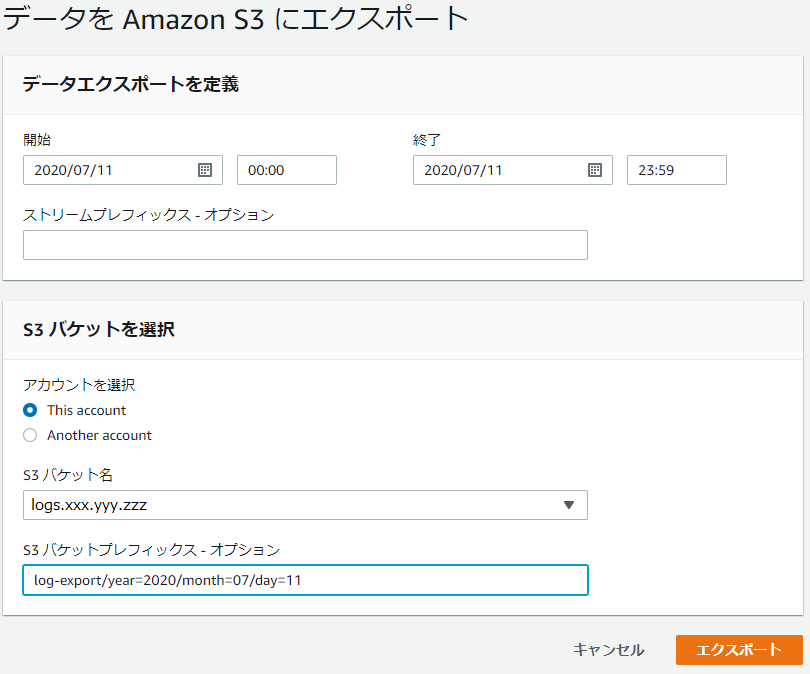
下記のように入力し、ロググループを S3 にエクスポートします。エクスポート単位 (=S3 上のオブジェクト単位) は 1 日単位としています。
| 項目 | 説明 |
|---|---|
| 開始 | 特定日付の最初の時間 (00:00) を指定します |
| 終了 | 特定日付の最後の時間 (23:59) を指定します |
| S3 バケット名 | あらかじめ準備したバケット名 (今回の場合は「logs.xxx.yyy.zzz」) を指定します |
| S3 バケットプレフィックス | バケット配下に「log-export」というフォルダを作成し、その下にエクスポートします。「year=」や「month=」などは Athena のパーティションを意識したフォルダ構造です。Athena のパーティションについては後述します |
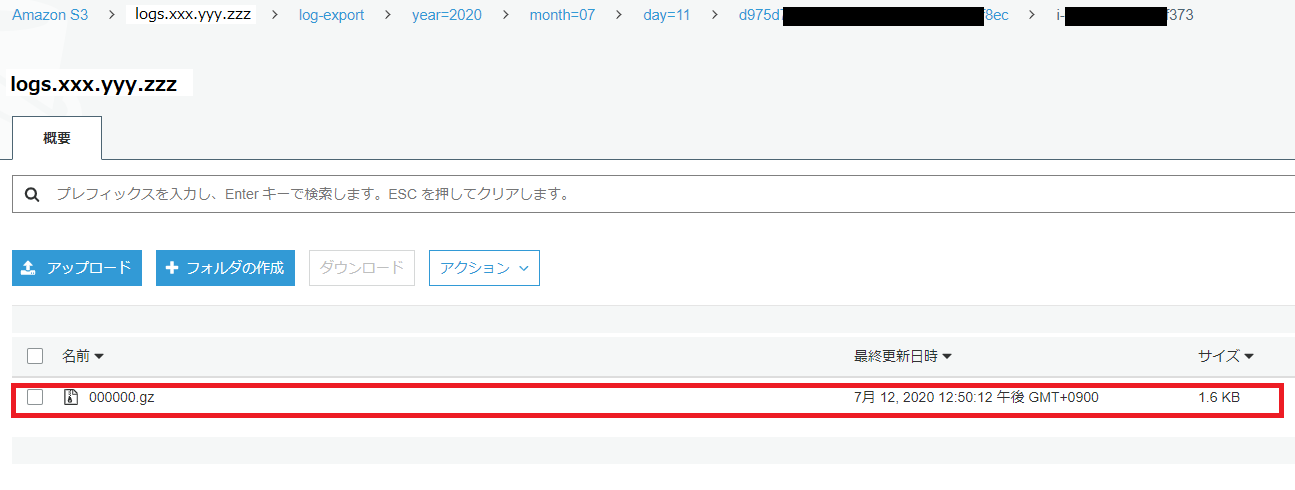
上記でエクスポート後、S3 に下記のとおりエクスポートされます。なお、ログは gzip で圧縮された形で出力されます。Athena は gzip 圧縮済みのファイルも読み込めるため、特に後続の作業に問題ありません。逆に、読み込みサイズが小さいほど Athena の料金が低くなるため、コスト管理の面ではありがたいです。
S3 → Athena の設定
S3 に保管したログデータを Athena に読み込ませます。まずは S3 のログデータから DB & テーブル を作成します。
下記記事を参考にしながら設定を進めていきます。
参考 : nginxのアクセスログからAmazon Athenaを利用してリファラー別にリクエスト数を集計する
なお、以後の設定に関しては、上記記事と下記点が異なるのでご留意ください。
- 上記記事では nginx のログを直接 S3 に保管しているが、今回は CloudWatch Logs を介している
→ CloudWatch Logs 経由の場合、各ログエントリの先頭にタイムスタンプが付く。Data Format 指定時に左記を考慮する必要がある - 上記記事では Athena のパーティションを設定していないが、今回は パーティションを設定している
→ S3 のフォルダ構造や Athena の設定でパーティションを考慮する必要がある (S3 のフォルダ構造については、前述で考慮済み)
それでは、実際の設定を進めていきます。まずは Athena の左メニューより「Table」 > 「Create Table」 > 「from s3 bucket data」を選択します。
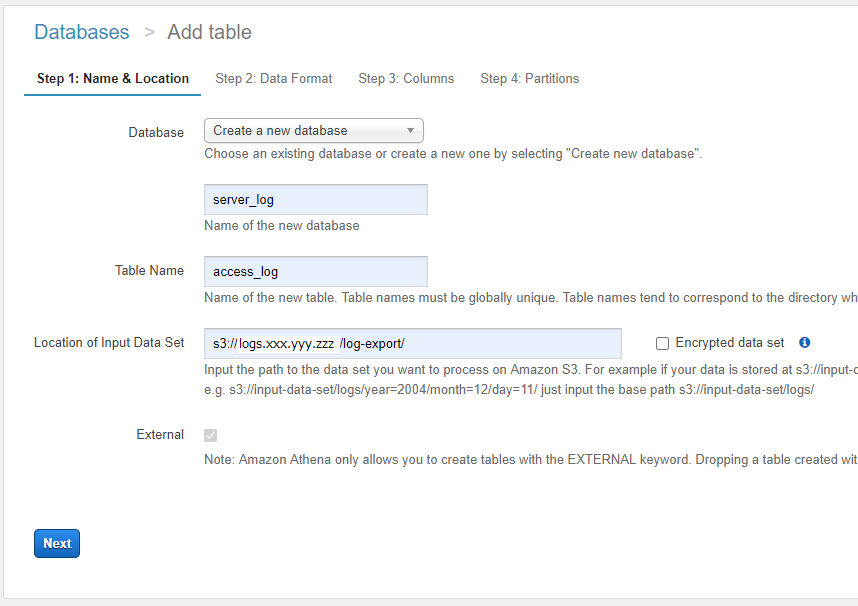
Step1 は下記のとおり設定します。
| 項目 | 説明 |
|---|---|
| Database | 任意のデータベース名を指定します。今回は「server_log」としています |
| Table Name | 任意のアクセス名を指定します。今回は「access_log」としています |
| Location of Input Data Set | S3 バケットの URL を指定します。今回は「s3://logs.xxx.yyy.zzz/log-export/」です。URL の最後は必ずスラッシュを含めるようにしてください |
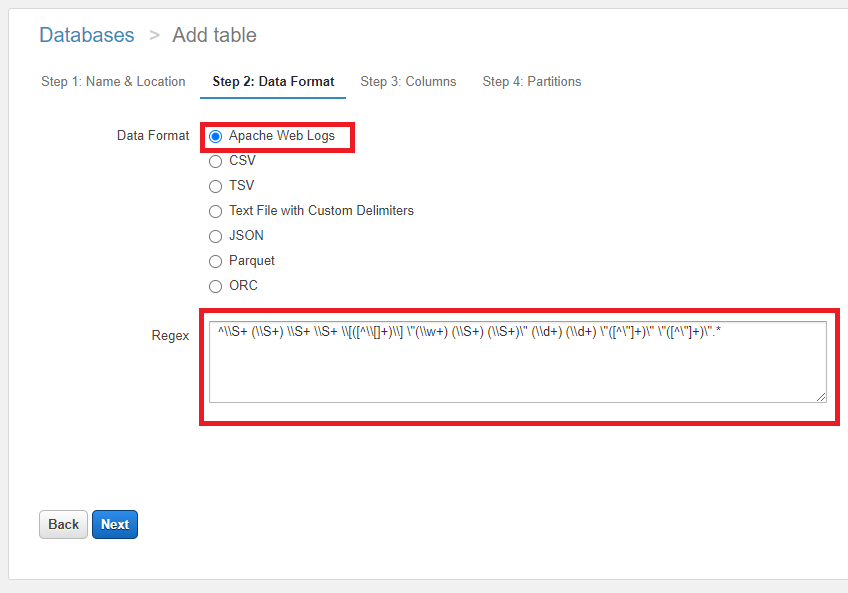
Step2 は下記のとおり設定します。
| 項目 | 説明 |
|---|---|
| Data Format | 「Apache Web Logs」を指定します |
| Regex | 「^\S+ (\S+) \S+ \S+ \[([^\[]+)\] "(\w+) (\S+) (\S+)" (\d+) (\d+) "([^"]+)" "([^"]+)".*$」を設定します。CloudWatch Logs 経由で出力しているログのため、参考記事に比べて先頭に「\S+ 」が増えています |
なお、正規表現 (Regex) の検証に関しては下記サイトが役立ちます。
参考 : Regular Expression Test Drive
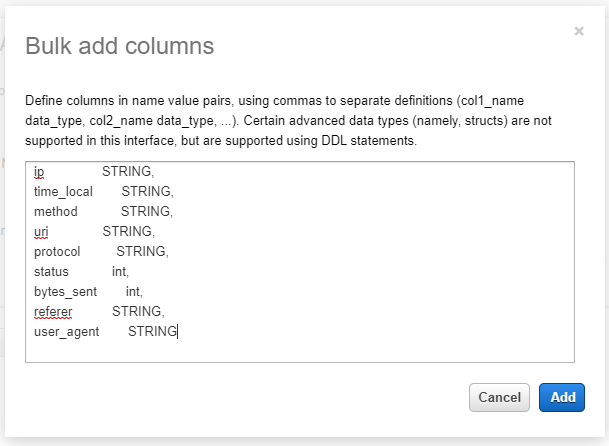
Step3 では「Bulk add columns」ボタンを押下し、下記項目を入力して一括で列を設定します。
ip STRING,
time_local STRING,
method STRING,
uri STRING,
protocol STRING,
status int,
bytes_sent int,
referer STRING,
user_agent STRING
最後の Step 4 では下記のとおりパーティションを設定します。パーティションは、S3 バケットのフォルダ構成に合わせて設定します。
| Column Name | Column type |
|---|---|
| year | int |
| month | int |
| day | int |
設定完了後、「Create table」ボタンを押下してテーブルを作成します。
なお、Step 1 ~ Step 4 をクエリで設定する場合は下記構文となります。
CREATE EXTERNAL TABLE IF NOT EXISTS server_log.access_log (
`ip` string,
`time_local` string,
`method` string,
`uri` string,
`protocol` string,
`status` int,
`bytes_sent` int,
`referer` string,
`user_agent` string
) PARTITIONED BY (
year int,
month int,
day int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' = '^\\S+ (\\S+) \\S+ \\S+ \\[([^\\[]+)\\] \"(\\w+) (\\S+) (\\S+)\" (\\d+) (\\d+) \"([^\"]+)\" \"([^\"]+)\".*'
) LOCATION 's3://logs.xxx.yyy.zzz/log-export/'
TBLPROPERTIES ('has_encrypted_data'='false');
さて、今回はパーティションを使用しているため、最後に下記クエリを実行してパーティションを有効にします。
MSCK REPAIR TABLE access_log
以上で Athena 分析を行う準備がすべて整いました。
Athena のパーティションについて
このタイミングになってしまいましたが、Athena のパーティションについて説明します。
Athena では読み込んだファイルサイズによって課金されます。そのため、全データを一つのファイルで S3 に保管して、それを Athena で読み込ませたりすると、毎回それなりのコストが発生します。
そのため、通常は期間などでファイル (フォルダ) を分割し、必要な範囲だけを Athena で読み取れるようにします。パーティションを設定することによって、Athena の SQL 文の Where 句でパーティション項目を指定できるようになります。イメージは下記のとおりです。
select * from access_log where year=2020
上記の「year」は実際のデータに含まれるカラムではなく、パーティションで指定したカラムになります。実際のデータに含まれるカラムでは無いですが、Where 句の検索対象として指定することができます。
なお、Athena でパーティションを有効にするには下記が必要になります (すべて今までの手順で記載済みです)。
- パーティションの設定にあわせて、S3 のフォルダ構造を定義する必要がある
- Athena でテーブルを作成する際、パーティションを定義する必要がある
- Athena でテーブルを作成後、
MSCK REPAIR TABLE access_logでパーティションを有効にする必要がある
パーティションに関するさらに詳しい情報は下記をご参照ください。
参考 : データのパーティション分割
Athena で検索
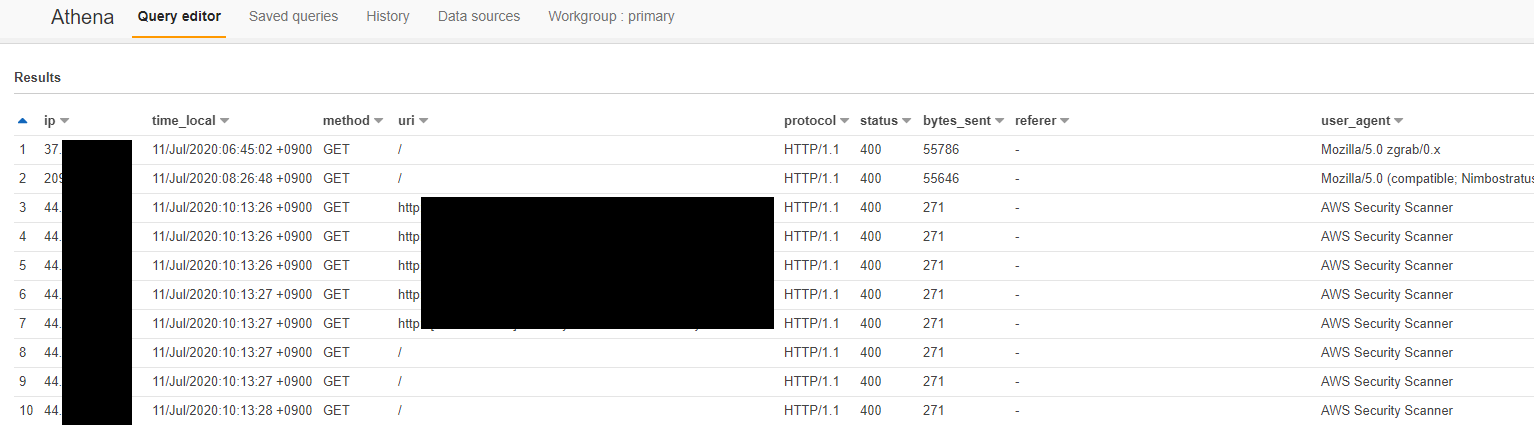
Athena へのデータ設定が完了したので、最後に SQL を使ってデータを検索してみます。
select * from access_log where year=2020 and month =07 and ip <> ''
※2020 年 7 月のデータを検索しています。ip <> '' で空白行を排除しています
検索結果は下記となります。
まとめ
以上、EC2 の nginx ログを CloudWatch Logs → S3 → Athena を介して分析する、でした。
今回の構成は、たとえば下記のようなカスタマイズができます。
- Zabbix などのログ監視機構を使っているので CloudWatch Logs は不要……ということであれば、EC2 から直接 S3 にログをエクスポートし、それを Athena で分析することが可能
- 今回、CloudWatch Logs から S3 へのエクスポートは手動で行っているが、Lambda や Kinesis Firehose を使うことでエクスポートを自動化することが可能
- Athena に設定したデータ (データセット) を QuickSight から参照し、データを可視化することが可能
……等々、いろいろと発展性の高い構成なので、この構成をベースに、今後もいろいろ試していきたいと思います。
参考 : Kinesis Firehoseを使ってCloudWatch Logをs3へ出力してみた
参考 : AWS Athena + QuickSightでS3に蓄積されたCSVデータを可視化