やりたい事
サービスの統計情報を取得するために、データベースの登録状況をバッチ処理でCSVに落として保存している運用をされている方は結構いらっしゃるのではと思います。そのS3データを簡単に可視化する方法として、AWS AthenaとQuickSightを利用してみました。
AWS Athena
Amazon S3 内のデータを標準 SQL を使用して簡単に分析できるようになります。Athenaを利用の流れは以下のような形になります。
1.S3にバケットを作成して、分析したいCSVファイルを置く
2.AWS Athenaのコンソールでデータベースの作成
3.AWS Athenaのコンソールでテーブルを作成する
4.作成したデータベースに対して、SQLのクエリを発行して必要な情報のみ取得する。
SQLのクエリはPresto 0.172 に基づいていますので、通常のSQL文とは差分がありますので、注意が必要です。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/functions-operators-reference-section.html
S3データの準備
今回は、単純化するために、以下の2種類のCSVファイルを用意しました。
users_YYYYMMDD.csv
time,user_id,plan_id
2019-09-01,user_001,planA
2019-09-01,user_002,planA
2019-09-01,user_003,planB
2019-09-01,user_004,planB
2019-09-01,user_005,planC
devices_YYYYMMDD.csv
date,device_id,user_id,
2019-09-01,deviceA,user_001
2019-09-01,deviceB,user_001
2019-09-01,deviceA,user_003
2019-09-01,deviceB,user_004
2019-09-01,deviceA,user_005
2019-09-01,deviceB,user_005
S3に以下のように配置します。
データベースの作成
AWS Athenaの利用は最初はデータベースを作成する事から始めます。ただし、この時点ではS3との関係などは意識する必要はなく、これからS3のデータと関連づけるためのデータベースを作成します。データベースの作成も通常通り、SQL文で実施します。
CREATE DATABASE sandboxusers;
テーブルの作成
データベースの作成は、S3のバケット毎に行います。時系列のCSVファイルなど、複数のCSVファイルを1つのバケットに置く場合、同一形式のCSVファイルである必要があります。
CREATE EXTERNAL TABLE IF NOT EXISTS users_table (
`date` date,
user_id string,
plan_id string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ( 'escapeChar'='\\', 'quoteChar'='\"', 'integerization.format' = ',', 'field.delim' = ',' )
LOCATION 's3://sandbox-1234/athena/users'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1')
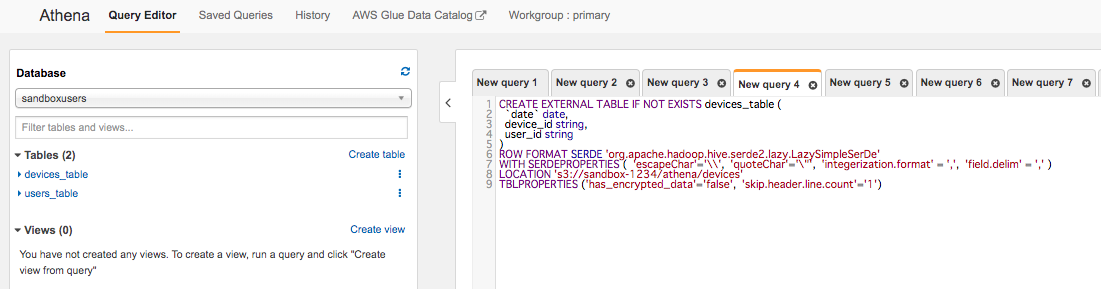
CREATE EXTERNAL TABLE IF NOT EXISTS devices_table (
`date` date,
device_id string,
user_id string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ( 'escapeChar'='\\', 'quoteChar'='\"', 'integerization.format' = ',', 'field.delim' = ',' )
LOCATION 's3://sandbox-1234/athena/devices'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1')
WITH SERDEPROPERTIESで区分する文字を指定します。またLOCATIONでs3のバケットの場所を指定します。最後の'skip.header.line.count'='1'はCSVの1行目を飛ばす設定となっています。上記のクエリを実施することで、AWS Athenaにテーブルが作成されます。
クエリを行う
テーブルを作成した後は、SQLを用いてクエリする事ができます。特に時刻の扱いは通常のSQLと差分がある場合があり、注意が必要です。
SELECT * from users_table where (date between date '2019-09-01' and date '2019-09-02') and plan_id = 'planA';

JOINも動作します。
SELECT *
from users_table
inner join devices_table
on users_table.user_id = devices_table.user_id
where (users_table.date = CAST('2019-09-01' as date)) and (devices_table.date = CAST('2019-09-01' as date))

QuickSightの設定
ここではスタンダードプラン、Tokyoリージョンを設定してQuickSightのアカウントを設定します。
データセットでAWS Athenaを選択します。
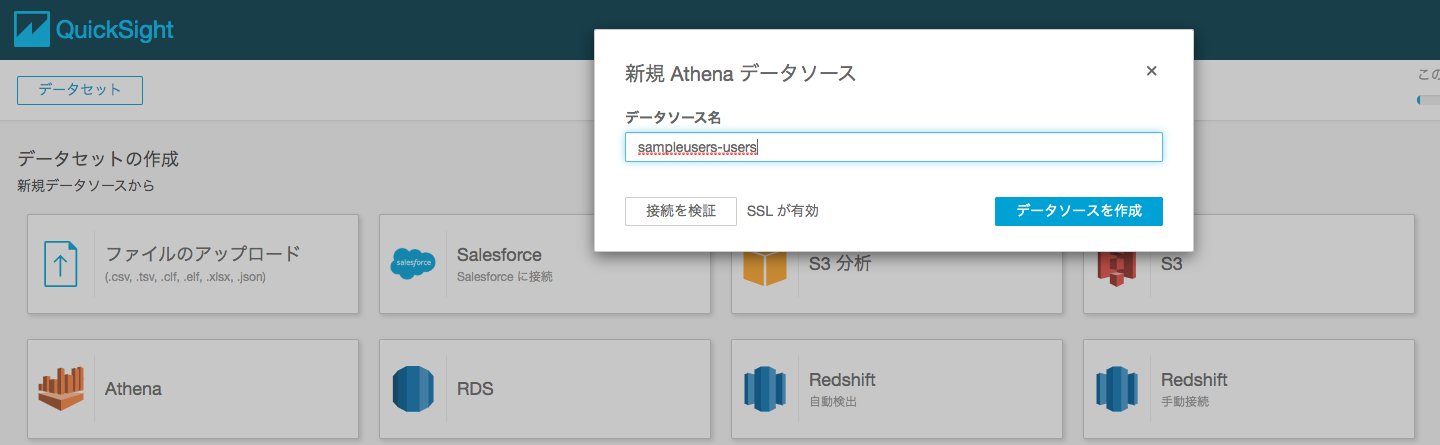
先程作成したテーブルと、QuickSightにデータを取り込むのではなく、都度クエリーする形を選択します。
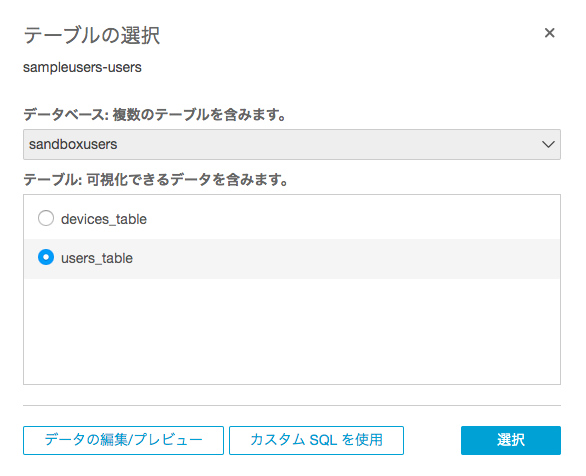
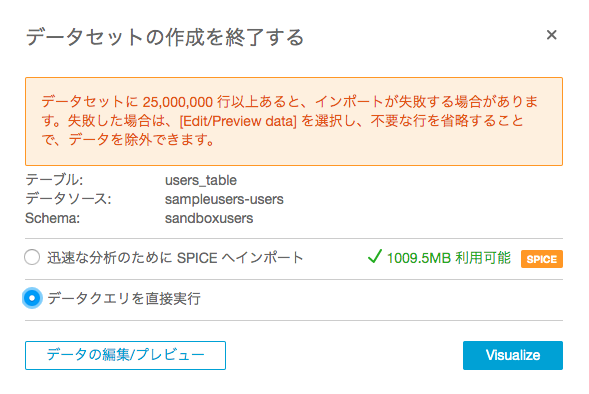
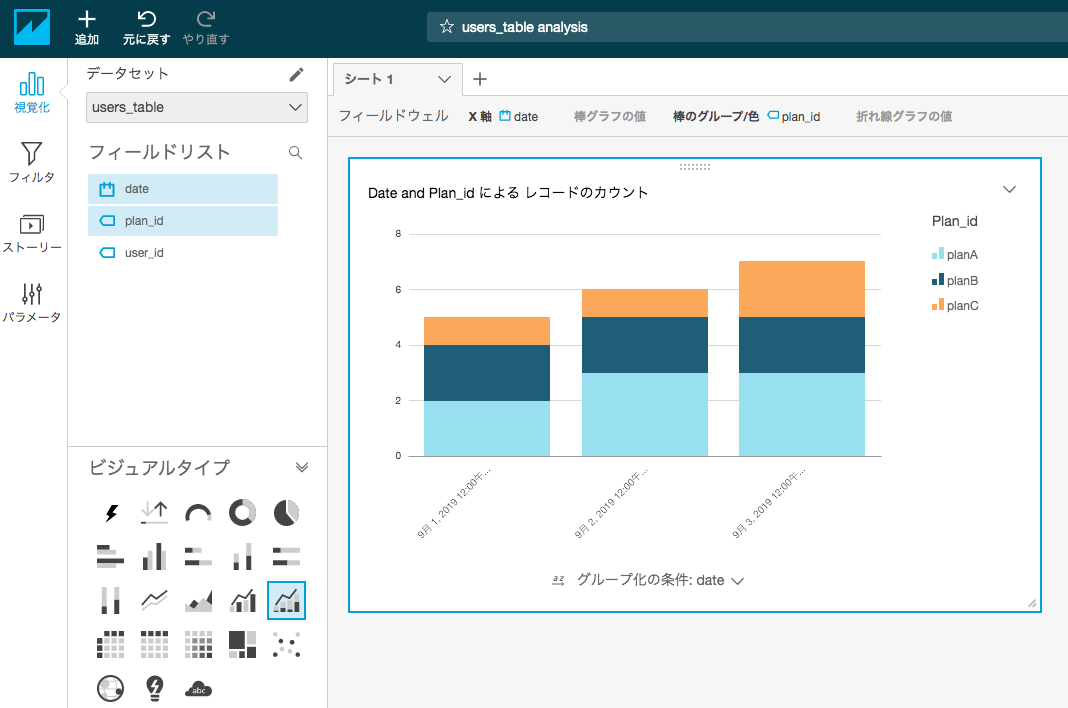
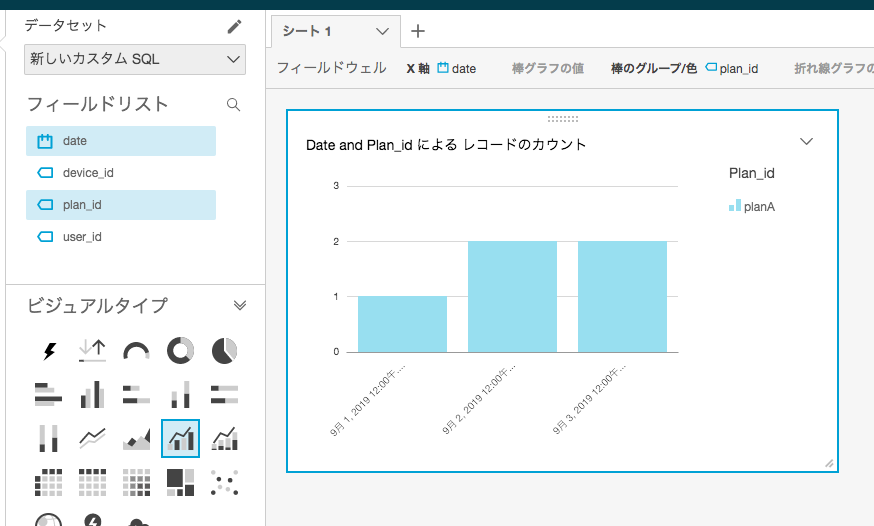
カラムとグラフの種類を選択すると、簡単にグラフ化する事ができます。
QuickSightのカスタムSQLの利用
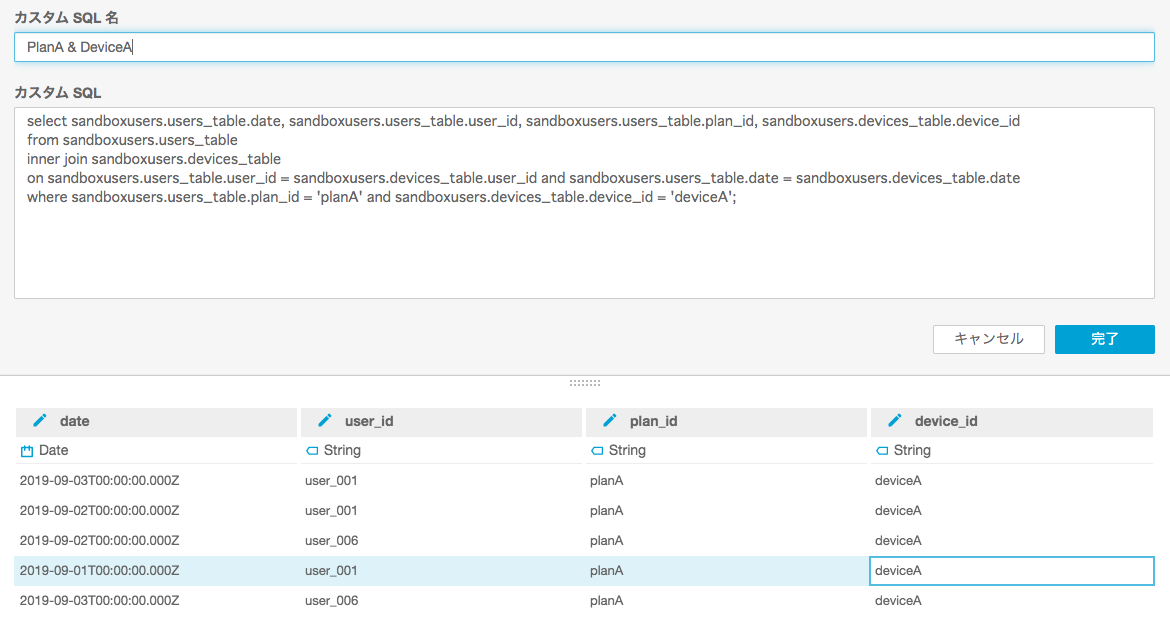
AWS Athenaのテーブルをそのまま表示するだけではなく、複数のテーブルをジョインした結果を用いる事もできます。方法は、先程と同様にデータセットでAWS Athenaを選択して、カスタムSQLを選択します。
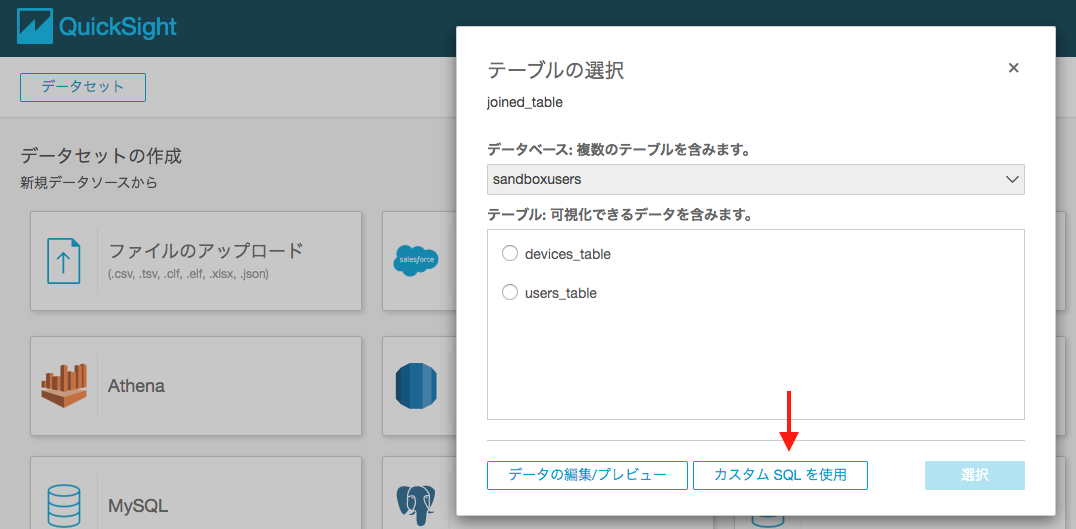
この例では、users_tableのplanAのユーザーでかつ、devices_tableでdeviceAを持つユーザーのみの抽出を行っています。
追記 タイムスタンプの扱いについて
ISO 8601方式のタイムスタンプはAthenaではTIMESTAMP型としてデータベースに登録できません。それが不便だなと悩んでいたのですが、以下の良記事で対応できました。ここで記述されているQuickSightでの計算フィールドを用いた方法で対応しました。