Denseをはじめ,これらshapeにBatchサイズの階は不要です.
したがって,input_shape = (24, 24)としてください.
エラー文でもNoneの箇所がありますが,ここには任意のバッチサイズを受け入れるためNoneと記載されているという認識が良いかと思います.
また,入力の形状が不一致な他に,出力の形状も不一致でエラーになります.
ので,これを回避すべく出力側のユニット数を2で定義します.
さらに,全結合で実行しているので,結合しない方向の個数が縦幅24,結合する方向の個数が横幅24として実行されるため,縦幅24に等しい出力の次元数になり出力の形状と一致しません.
import numpy as np
from keras.layers import Dense
from keras.models import Sequential
# 疑似データを用意する
N, H, W = 120, 24, 24
# 入力値はmin-max正規化されていることを想定してrandom.uniform(0, 1)で用意する
my_train_images = np.random.uniform(0, 1, N * H * W).reshape(N, H, W)
my_train_labels = np.random.uniform(0, 1, N * 2).reshape(N, 2)
model = Sequential()
model.add(Dense(units=32, input_shape=(24,24)))
model.add(Dense(units=16))
model.add(Dense(units=2))
model.compile(
optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy']
)
from keras.utils.vis_utils import plot_model
plot_model(
model,
to_file="a.png",
show_shapes = True,
show_layer_activations = True
)

この状態でデータを与えると,先述の結合しない方向がある理由から出力の形状が(None, 24, 2)となり,与えたデータ(None, 2)との不一致で
ValueError: Shapes (30, 2) and (30, 24, 2) are incompatible
が生じるため,二次元配列(24, 24)の入力を一次元配列(576,)に次元を平滑化Flattenして全結合を行う必要があります.
from keras.layers import Dense, Input, Flatten
model = Sequential()
model.add(Input(shape = (H, W)))
model.add(Flatten())
model.add(Dense(units = 32))
model.add(Dense(units = 16))
model.add(Dense(units = 2))

これでエラーは消えて実行可能な状態になります.
Denseのunitの値の決め方のすゝめ
一般的に,分類問題を解かせる場合は,「入力側が大きく,出力側に行くにつれて小さくなる」のがセオリーです.上記のモデルはこれを遵守しており,問題ないと感じます.
注意してほしいのは「一般的な『値』は決まっていない」ということです.これらハイパーパラメータの最適値は入力の特性次第で変化します.そのためにハイパーパラメータチューニングを行うライブラリが存在しますし,その中で取り組まれる試行錯誤の上で決定するものです.
詳しくは次の記事を参考にしてください.
上のコードでのハイパーパラメータは
- 全結合層の数
- 全結合層
Denseの内容:
- unit数
- 活性化関数:
activation
- カーネル初期値:
kernel_initializer
- カーネル正則化:
kernel_regularizer
- etc..
- optimizer:
- Adam
- Adadelta
- Adamax
- SGD
- RMSprop
- etc...
などです.対して記事ではSVMのハイパーパラメータ2つだけを最適化しています.
余談
他人のモデルに口出しするのはあまり気が進みませんが,損失関数は2値出力用のbinary_crossentropyが適用されており,正しくないと考えます.普通,One-Hot Encodingされた2ラベルの分類ではcategorical_crossentropyを利用すべきで,かつ出力の活性化関数はSoftmaxを利用する必要があります.
また,いずれのモデルも活性化関数が線形関数linearであることに注意してください.これが原因で入力値の和と差のみで出力値を得る線形モデルになっています.通常は双曲線正接関数やSigmoid関数,ReLU関数などの非線形関数を使うのが一般的です.
したがって,私なら次のように書きます1.
model = Sequential()
model.add(Input(shape = (H, W)))
model.add(Flatten())
# 576に対して32は小さすぎかもなので追加する
# レイヤを増やしすぎたので勾配消失問題に対応すべくReLUを利用する
# ReLU用の重み初期値であるHeの初期値[^1]を利用する(デフォルトはtanh用)
model.add(Dense(units = 128, activation = "relu", kernel_initializer = "he_uniform"))
model.add(Dense(units = 64, activation = "relu", kernel_initializer = "he_uniform"))
model.add(Dense(units = 32, activation = "relu", kernel_initializer = "he_uniform"))
model.add(Dense(units = 16, activation = "relu", kernel_initializer = "he_uniform"))
model.add(Dense(units = 2, activation = "softmax"))
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
また,画像なら画像として扱うべく,一般的に使われる畳み込みConv2Dの利用を推奨します.
import numpy as np
from keras.layers import Dense, Input, Flatten, Conv2D, AveragePooling2D
from keras.models import Sequential
N, H, W, C = 120, 24, 24, 1
my_train_images = np.random.uniform(0, 1, N * H * W * C).reshape(N, H, W, C)
my_train_labels = np.random.uniform(0, 1, N * 2).reshape(N, 2)
# my_train_images[:, :, :, np.newaxis] # my_train_images.shape = (120, 24, 24)のときはこの行が必要
model = Sequential()
model.add(Input(shape = (H, W, C)))
model.add(Conv2D(16, (5, 5), activation = "relu", kernel_initializer = "he_uniform"))
model.add(AveragePooling2D(2))
model.add(Conv2D(32, (3, 3), activation = "relu", kernel_initializer = "he_uniform"))
model.add(AveragePooling2D(2))
model.add(Conv2D(64, (3, 3), activation = "relu", kernel_initializer = "he_uniform"))
model.add(AveragePooling2D(2))
model.add(Flatten())
model.add(Dense(32, activation = "relu", kernel_initializer = "he_uniform"))
model.add(Dense(16, activation = "relu", kernel_initializer = "he_uniform"))
model.add(Dense(2, activation = "softmax"))
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
model.fit(
my_train_images,
my_train_labels,
epochs = 15,
batch_size = 30
)
model.png
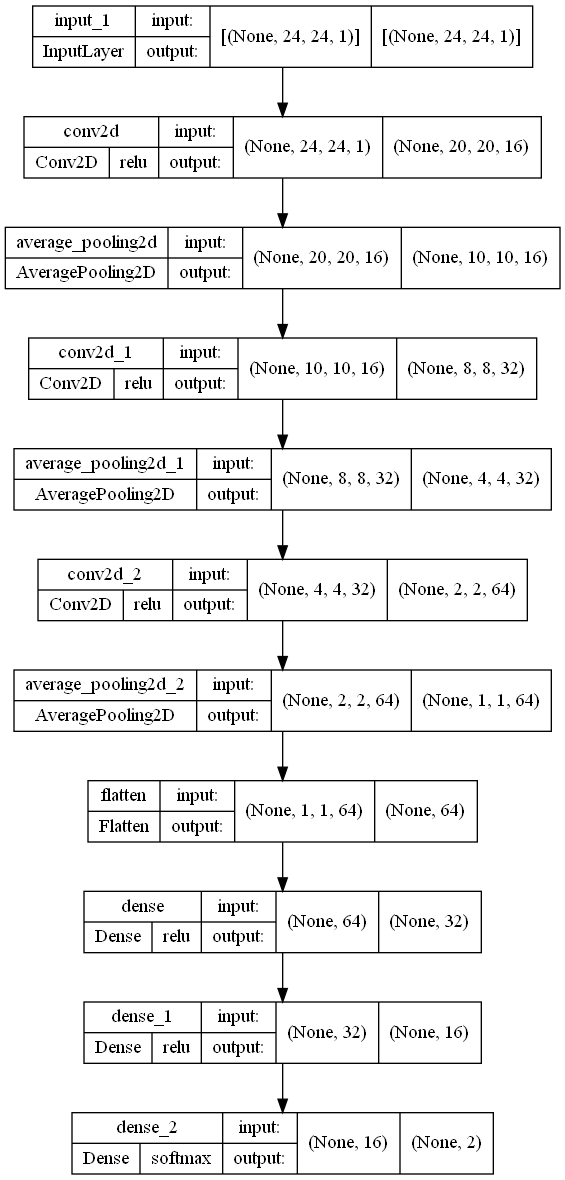
input_shape = (○, △,・・・) の〇△の設定する場所の意味
これが〇△の値の意味という話であれば,データの種類によって次のように意味が変化します.
- 構造化データ
input_shape = (F,): 特徴量の個数F
- 波形データ
input_shape = (L, C): 波の長さLとチャンネル数C(モノラルなら1, ステレオなら2)
- 画像データ
input_shape = (H, W, C): 畳み込みを使ったコードからわかる通り,画像の縦幅H,横幅W,チャンネル数C(モノクロなら1, RGBなら3, 透過もあるなら4)
- バッチの次元と合わせてNHWC形式と呼ばれる
- Chainer,PyTorchはNCHW形式であることに注意.
- 3Dデータ
input_shape = (H, W, D, C): 縦幅H,横幅W,深さD, チャンネル数C
plot_modelによって出力されたモデルの状態を示す画像ではこれらより前にNoneが入っており,データ数(実際に入るのはバッチ数)を意味します.
これらを踏まえて逆に言えば,カラー画像1枚を入力したいと思っても,input_shapeに設定するような(24, 24, 3)の形状のものを渡すとエラーになります.かならず(1, 24, 24, 3)のように,バッチの次元があるデータをモデルに渡す必要があります.
今回は元データが(120, 24, 24)で,batch_size = 30にしたのでmodelが受け取ったものは(30, 24, 24),input_shape = (24, 24)であるからバッチサイズの次元が追加されて(None, 24, 24)となり,入力で与えた1バッチ分のデータ(30, 24, 24)にフィットします.

