はじめに
本記事は全4編によって構成されるうち、2つ目の記事となります。
前回ではCSVデータをDelta形式に変換したテーブルを作成を行いました。
本記事のゴールとしてDelta形式化したテーブルを用いて可視化に向けた加工を完了します。
全4編の概要
全4編かけてBacklogで記録されたCSVデータ(検証用に一部編集済み)を元に、ノートブック上でテーブルの加工を行い、Databricks SQL(Redash)を用いて可視化まで行っていきます。
1. Delta形式のテーブル作成編
2. テーブルの加工編
3. SQLクエリ作成編
4. ビジュアル作成編
Databricksを利用してデータ加工をしていきたいという方向けに、加工の流れを一気通貫してざっくりと理解していただくことを想定しております。
*ただし一部複雑な加工や考え方が含まれていることご了承ください。
全4編のゴール
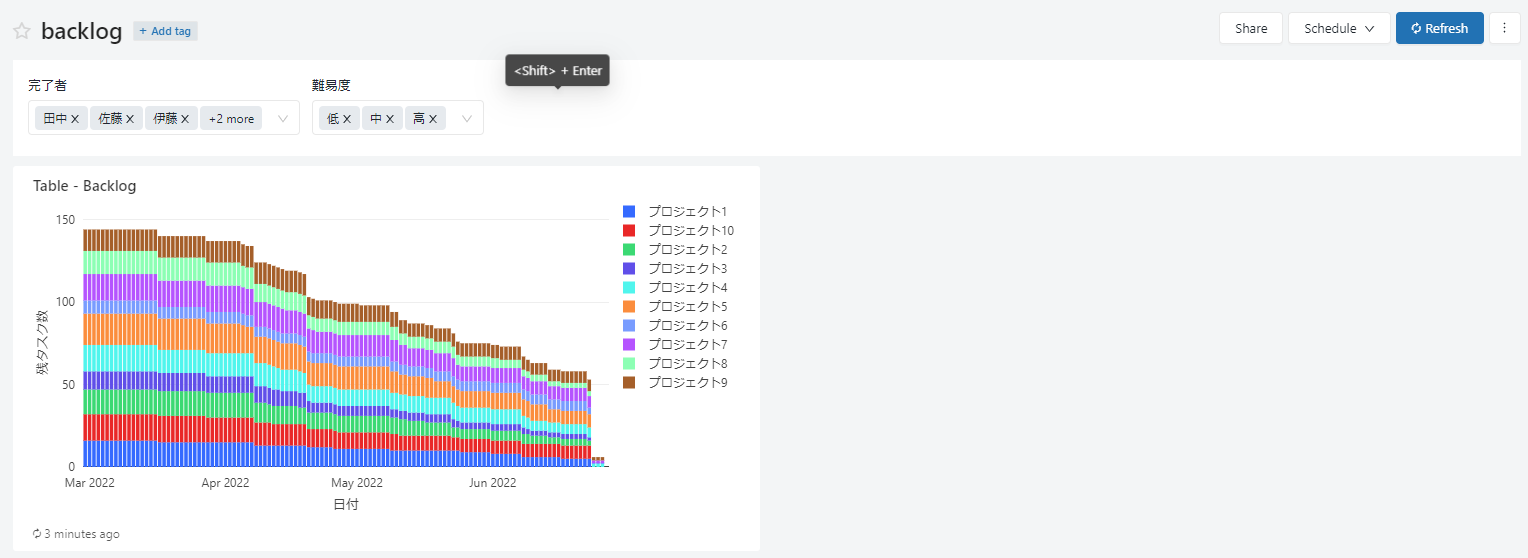
最終的なゴールはDatabricks SQLのダッシュボード上で以下のような要件を満たすグラフを作成します。
・日にちごとの残タスク数の推移を表示
・残タスクの数はプロジェクトごとに積み上げて表示
・グラフに表示する残タスク数を、タスクの保持者と難易度でパラメーター機能を用いて絞り込み可能
テーブルの加工
必要なモジュールをインポートします。
import pandas as pd
from pyspark.sql.functions import *
from pyspark.sql.window import Window
前回にDelta化したテーブルが保存されているデータベースへ移動します。
%sql
USE for_sample
テーブルを読み込みます。
df = spark.sql("select * from backlog_data")
display(df)
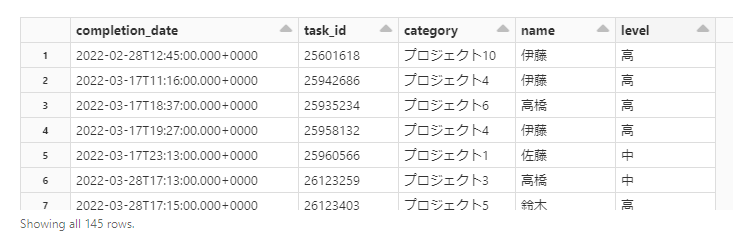
このテーブルではタスク保持者、難易度のパラーメーター機能を持ったプロジェクトごとに残タスク数が積み上がるようなビジュアルを表現できません。
なぜなら、以下のような問題から時系列に沿って残タスク数を導くことができないからです。
・タスク完了日以外は歯抜けになっている
・テーブルには完了したタスクの情報のみしかない
・残タスク数を導く情報が不足している
上記の問題を解消するために以下のようなテーブルの加工をおこなっていきます。
・歯抜けの日付を補完する
・各日付について完了したタスク以外の情報を持たせられる状態をつくる
・タスクが完了数を累積値で格納していく
・残タスク数を示すための総タスク数を格納する
まず、日付未満はこの先使わないので切り捨てます。
# 時刻の切り捨て
df = df.withColumn("completion_date",date_trunc("day", "completion_date"))
display(df)
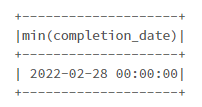
日付の最小を取ります。
# 日付の最小値
df.agg(min("completion_date")).show()
日付の最大も取ります。
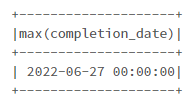
# 日付の最大値
df.agg(max("completion_date")).show()
一旦今までのテーブルは置いておき(後に利用)、先ほど取得した日付の最大値と最小値の範囲で、新しい一日ごとの日付のテーブルを作成します。
これで歯抜けの日付がなくなります。
# 日付データの作成
date = pd.date_range("2022-02-28","2022-06-27")
date_column = "date_range"
date = pd.DataFrame({date_column:date})
date = spark.createDataFrame(date)
display(date)
次に、日付ごとに各プロジェクト、名前、難易度のすべての組み合わせでタスクが完了した、していないにかかわらず情報を持たせられるような加工を行います。
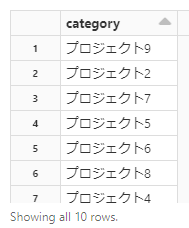
カテゴリーのみの入ったデータを作成します。
以下、実行するとdistinct()で重複を除き、10種類のプロジェクトが存在することがわかります。
# カテゴリーデータ
category = df.select("category").distinct()
display(category)
名前のみ、難易度のみの入ったデータも同様に作成します。
同じく重複を除き、名前は5人、難易度は3種類あります。
# 名前テーブル
name = df.select("name").distinct()
display(name)

# 難易度を示すテーブル
level = df.select("level").distinct()
display(level)
作成した日付、カテゴリー、名前、難易度のみのテーブルで交差結合を行います。
これにより、どの日付であっても各プロジェクト、名前、難易度のすべての組み合わせでタスク状況について情報を追加できるようになります。
# 交差結合
tbl = date.crossJoin(category)
tbl = tbl.crossJoin(name)
tbl = tbl.crossJoin(level)
display(tbl)
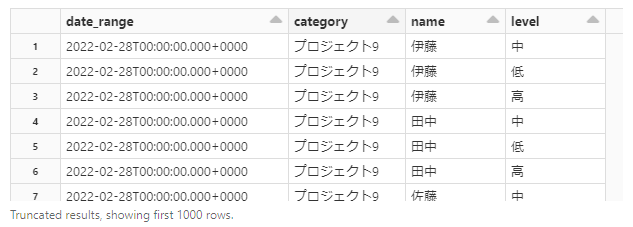
各組み合わせで交差結合を行ったので、テーブルは120日(4か月)×10プロジェクト×5人×3難易度=18000行になりました。
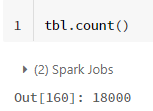
次のステップとして、新しく作ったテーブルに元のテーブルを結合させ、タスクの完了した情報を持たせます。
元テーブルのカラムの名前を新しく作成したテーブルと重複しないように変更を行います。
# カラム名を重複しないよう変更
df = df.withColumnRenamed("category","category_o")\
.withColumnRenamed("name","name_o")\
.withColumnRenamed("level","level_o")
display(df)
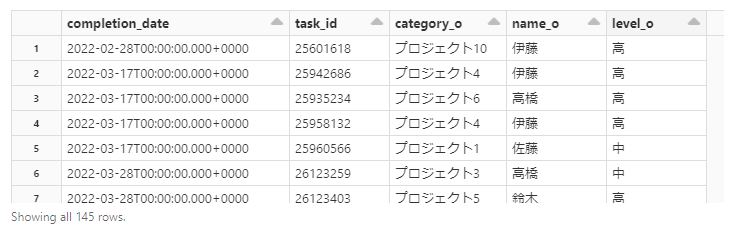
新しいテーブルを基準に元テーブルを左外側結合します。
実行すると以下の画像にあるテーブルの116行目のように、タスクが完了した行には欠損がないようなテーブルが出来上がります。
欠損がある行に関しては特にその日においてタスクが完了されていないという意味になります。
# 元テーブルと結合
df = tbl.join(df,(tbl.date_range == df.completion_date)\
& (tbl.category == df.category_o)\
& (tbl.name == df.name_o)\
& (tbl.level == df.level_o),"left_outer")
display(df.orderBy(col('date_range').asc()))

データの数をもう一度確認すると以下の画像から結合前の18000より若干増えていることがわかります。
これはある日付でプロジェクト、名前、難易度の組み合わせが同じタスクが複数完了されることによって外部結合した時に重複した行がでてきたと考えられます。
一旦、次の作業に進み、最後に重複した行について処理します。
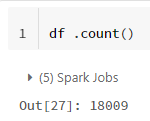
タスクが完了した行に1というラベルを付けます。
テーブルの108行目の「is_done」という名前のカラムに1とついているのが確認できます。
# タスクが完了した日付を含む行にラベル付け
df = df.withColumn("is_done",when(df.completion_date.isNotNull(),1).otherwise(0))
display(df)

ここで、この先必要のないカラムを削除します。
# 不要なカラムの削除
df = df.drop("completion_date","task_id","category_o","name_o","level_o")
display(df)
ここからタスク完了数の累積値と総タスク数を求めるステップに入ります。
まず、準備としてウィンドウを定義します。
時系列で並び変えてから、カテゴリー、名前、難易度で「partition」を行い、計算する範囲を「rangeBetween」で指定します。
「w1」は累積値に、「w2」は総タスク数を求める際に使用します。
# 日付ごとに業者名、指摘者、ファイル名でpartitionを行う
w1 = Window.partitionBy(df.category,df.name,df.level).orderBy(df.date_range).rangeBetween(-sys.maxsize,0)
w2 = Window.partitionBy(df.category,df.name,df.level).orderBy(df.date_range).rangeBetween(0,sys.maxsize)
まず累積値を計算します。
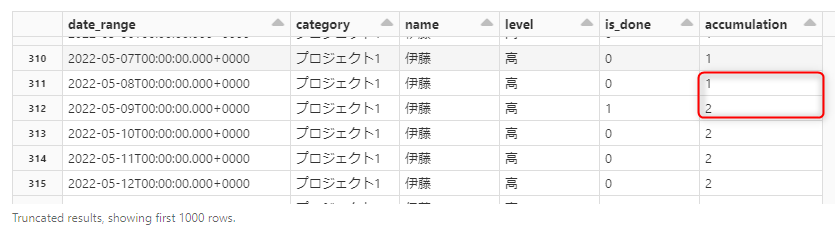
定義したウィンドウごとにタスク完了ラベルの付いたカラムの合計値をとることで、累積値を計算することができます。
実行できると各組み合わせでの累積値の格納が完了しました。
# 累積カラムを追加し、ウィンドウごとに累積値を格納する
df_total = sum(df.is_done).over(w1)
df = df.withColumn("accumulation",df_total)
display(df)
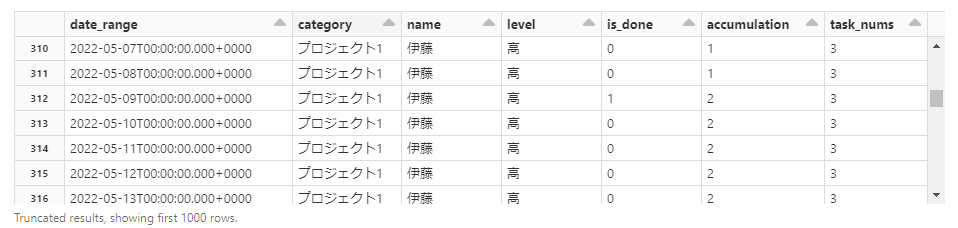
次に総タスク数も計算します。
2つ目に定義したウィンドウでつい先ほど作成した累積カラムの最後の行をとることによって、タスクの総数を導くことができます。
# 総タスク数を示すカラムを追加し、ウィンドウごとに総タスク数を格納する
all_task_nums = last(df.accumulation).over(w2)
df = df.withColumn("task_nums",all_task_nums)
display(df)
重複した行を削除し、データの数を確認すると元の18000行に戻っていることが確認できます。
# 重複行の削除
df = df.distinct()
df.count()

必要な加工をすべて終えたので、加工済みテーブルをデータベース保存します。
path = "dbfs:/FileStore/tables/backlog_processed"
table_name = "backlog_proccessed"
# 加工済みテーブルの保存
df.write.format("delta").option("path",path).saveAsTable(table_name)
まとめ
これで加工済みテーブルが完成しました。
次回はDatabricks SQLを利用し、加工済みのテーブルを使用してクエリを作成していきます。
技術面の参考資料
結合処理
今回交差結合と左外結合を使用しました。
他にもテーブルの結合の種類はたくさん存在し、こちらの記事が参考になります。
window関数を使用した累積値の計算
累積値を計算する範囲としてwindowを作成しましたが、こちらの記事を参考にしております。