はじめに
本記事は全4編によって構成されるうち、3つ目の記事となります。
前回ではCSVデータをDelta形式に変換したテーブルを可視化するために加工を行いました。
本記事のゴールとしては加工したテーブルを使用し、Databrick SQLで可視化に向けてSQLクエリを完成させます。
全4編の概要
全4編かけてBacklogで記録されたCSVデータ(検証用に一部編集済み)を元に、ノートブック上でテーブルの加工を行い、Databricks SQL(Redash)を用いて可視化まで行っていきます。
1. Delta形式のテーブル作成編
2. テーブルの加工編
3. SQLクエリ作成編
4. ビジュアル作成編
Databricksを利用してデータ加工をしていきたいという方向けに、加工の流れを一気通貫してざっくりと理解していただくことを想定しております。
*ただし一部複雑な加工や考え方が含まれていることご了承ください。
全4編のゴール
最終的なゴールはDatabricks SQLのダッシュボード上で以下のような要件を満たすグラフを作成します。
・日にちごとの残タスク数の推移を表示
・残タスクの数はプロジェクトごとに積み上げて表示
・グラフに表示する残タスク数を、タスクの保持者と難易度でパラメーター機能を用いて絞り込み可能
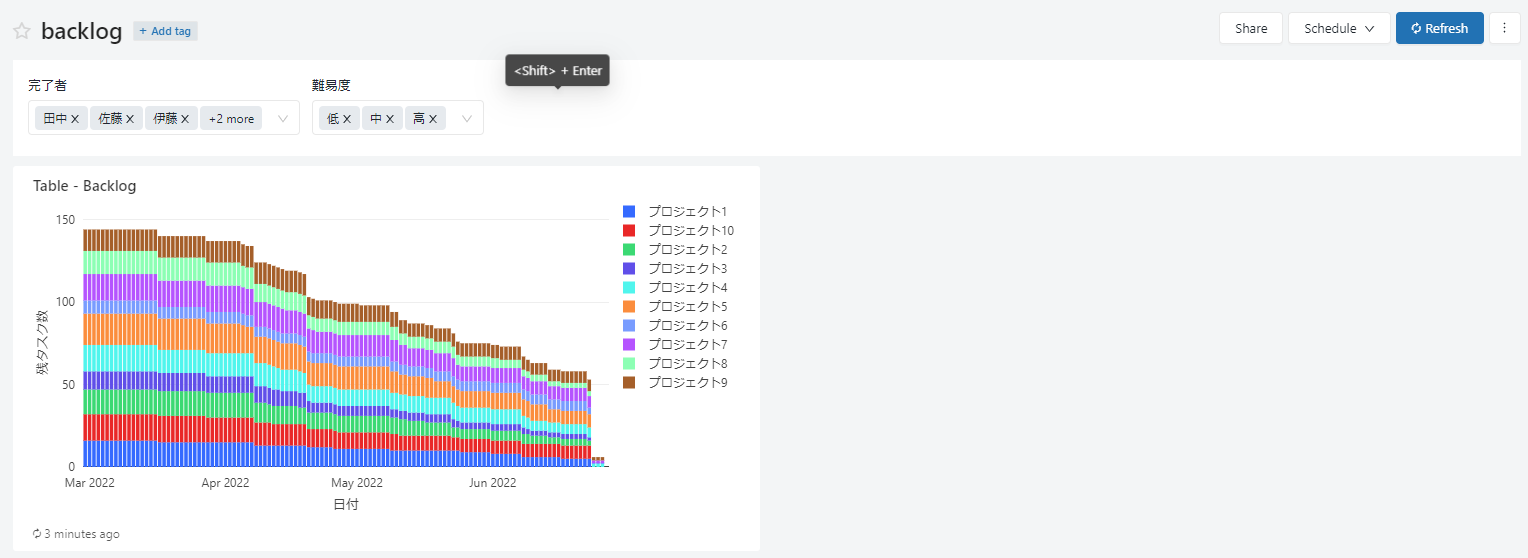
ビジュアル用クエリ作成
ここからの作業はDatabricks SQLで行います。まずSQL Warehouseの作成から行います。
今回は画像にあるスペックで作業いたします。
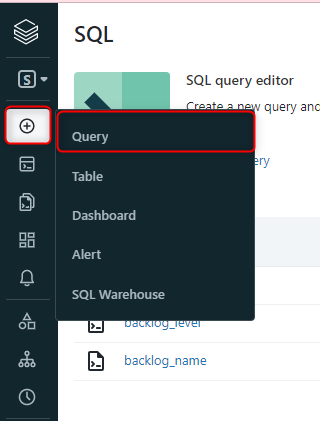
クエリを作成します。
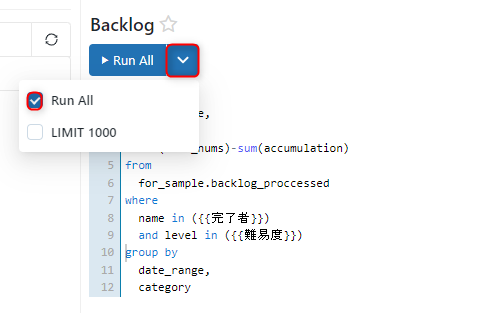
今回はパラメーター機能を付けるためのクエリ2つと本クエリ1つで合計3つのクエリを作成します。
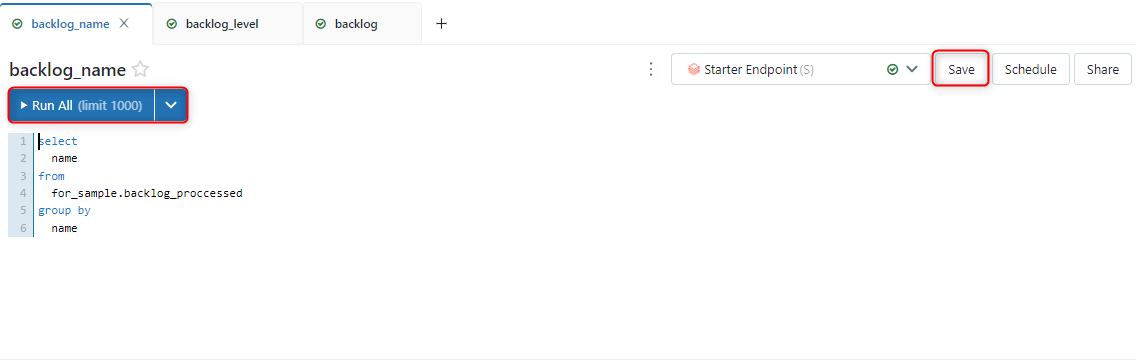
まず、パラメーター用のクエリを作成ます。
name、levelでパラメーターをかけられるようにします。
「Run All」をクリックして実行を行い、成功すれば「save」をクリックして保存します。
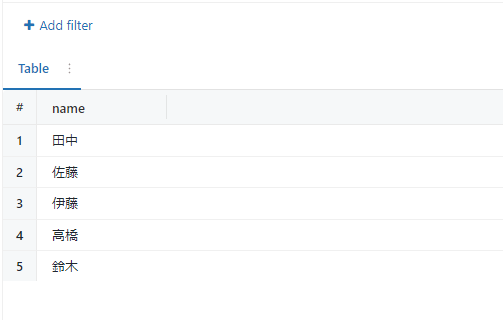
<タスク完了者のパラメーター用クエリ>
前回の記事で加工したテーブルから完了者を示すカラムをselectします。
重複しないように完了者でgroup byを行っています。
select
name
from
for_sample.backlog_proccessed
group by
name
実行結果になります。
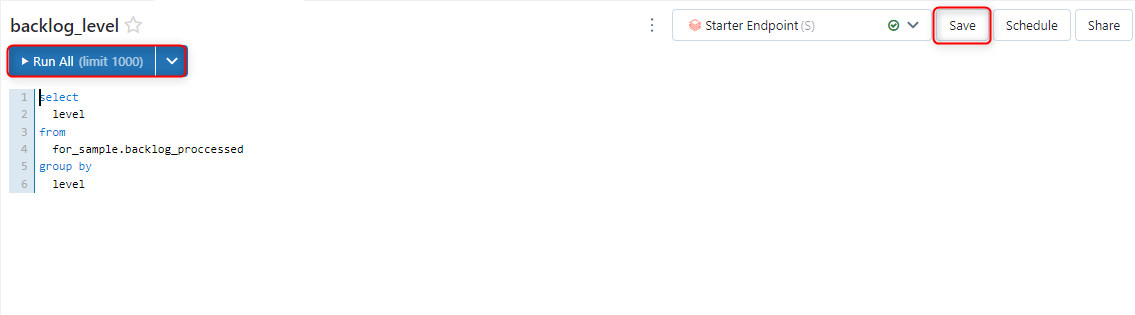
<タスク難易度のパラメーター用クエリ>
完了者のパラメーターと同様にクエリを記述します。
select
level
from
for_sample.backlog_proccessed
group by
level
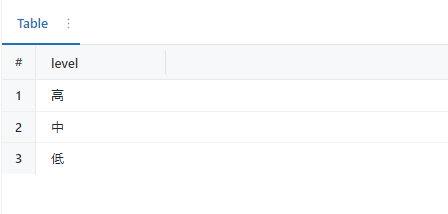
実行結果になります。
次に、本クエリの作成を行います。
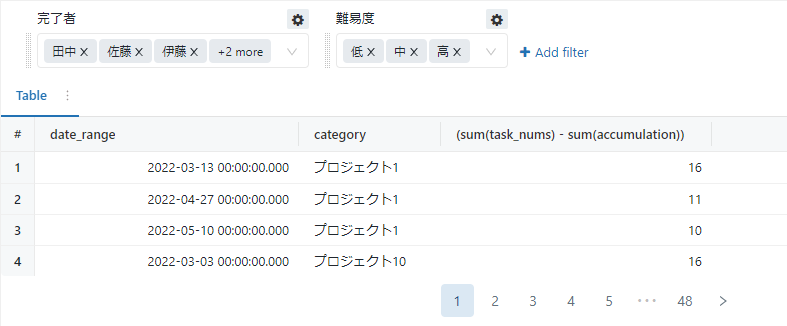
まず時系列カラム、どのカテゴリーに属しているかを示すカラム、そして総タスク数とタスク完了数の累積の差である残タスク数を作成したテーブルからselectします。
select
date_range,
category,
sum(task_nums)-sum(accumulation)
from
for_sample.backlog_proccessed
次にwhere文の中で以下のように記述することによりパラメーターを作成できます。
where
name in ({{完了者}})
and level in ({{難易度}})
作成したパラメーターに先ほど作成したパラメーター用クエリを呼び出します。
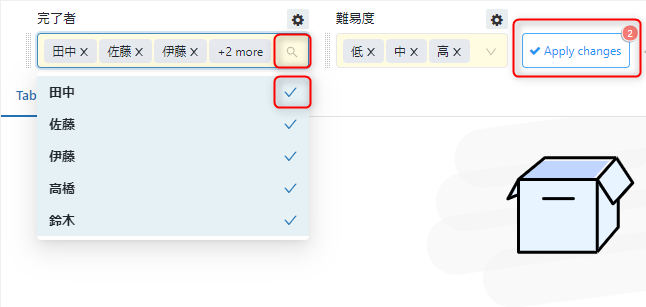
まず以下の画像の赤枠の歯車マークをクリックします。
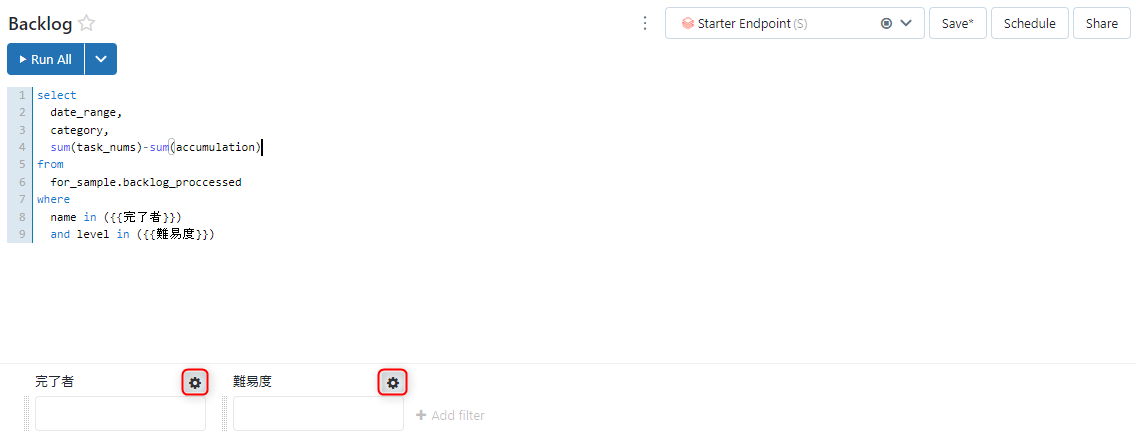
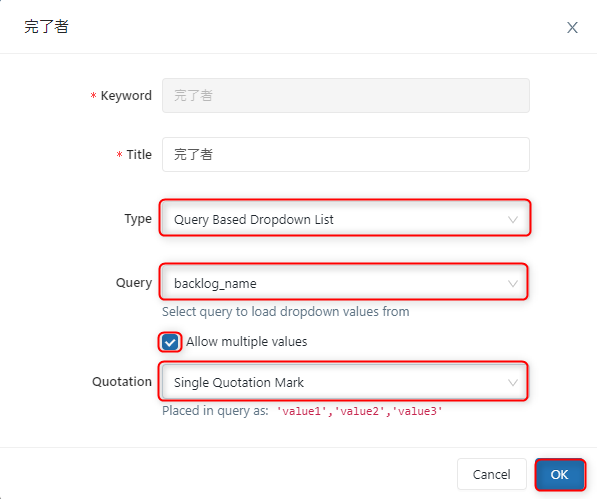
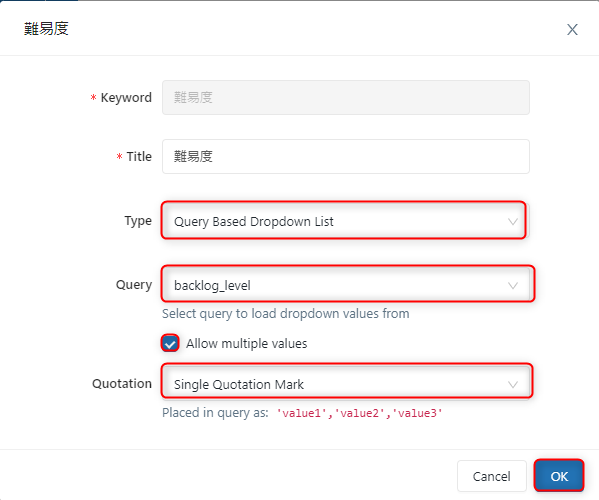
完了者と難易度でそれぞれ以下の作業を行う
・「Type」に「Query Based Dropdown List」を選択
・「Query」に「パラメーター用クエリの名前」を選択
・「Allow multiple values」にチェックを入れる
・「Quotation」に「Single Quotation Mark」選択
虫眼鏡マークからパラメーターをかけたい値だけチェックを付け、「Apply changes」をクリックすることにより、表示させたい値を絞ることができます。
最後に日付とカテゴリーでgroup byを行うとクエリの完成です。
group by
date_range,
category
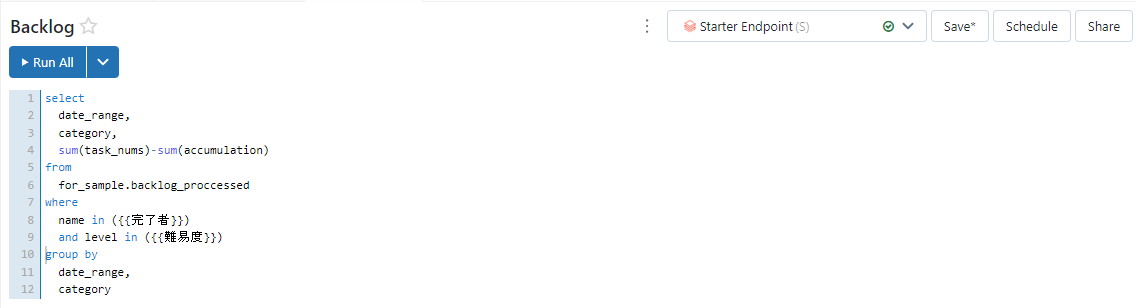
上の画像にあるクエリを実行します。
実行は赤枠にある「Run all」のみチェックがついている状態で行ってください。
以下の画像のようなテーブルが出力されました。
成功すれば「save」をクリックすることを忘れないでください。
まとめ
これで可視化用のクエリが完成しました。
次回は出力されたテーブルを可視化していきます。
技術的な参考資料
パラメーター機能
こちらの公式ドキュメントにパラメータ機能が解説されております。