はじめに
本記事は全4編によって構成されるうち、1つ目の記事となります。
この記事のゴールは使用するCSVデータをDelta形式へと変換したテーブルを作成することです。
全4編の概要
全4編かけてBacklogで記録されたCSVデータ(検証用に一部編集済み)を元に、ノートブック上でテーブルの加工を行い、Databricks SQL(Redash)を用いて可視化まで行っていきます。
1. Delta形式のテーブル作成編
2. テーブルの加工編
3. SQLクエリ作成編
4. ビジュアル作成編
Databricksを利用してデータ加工をしていきたいという方向けに、加工の流れを一気通貫してざっくりと理解していただくことを想定しております。
*ただし一部複雑な加工や考え方が含まれていることご了承ください。
全4編のゴール
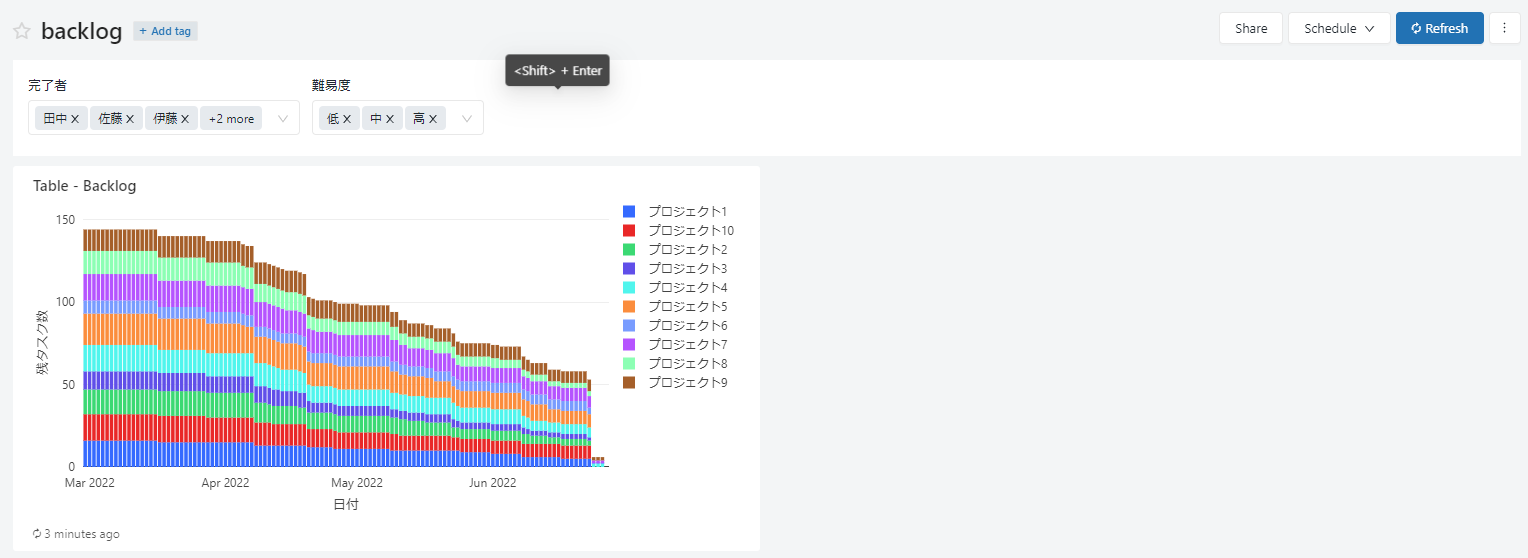
最終的なゴールはDatabricks SQLのダッシュボード上で以下のような要件を満たすグラフを作成します。
・日にちごとの残タスク数の推移を表示
・残タスクの数はプロジェクトごとに積み上げて表示
・グラフに表示する残タスク数を、タスクの保持者と難易度でパラメーター機能を用いて絞り込み可能
なぜDatabricksを使用するか
今回Databricksで作業する最大のメリットは生データの状態から加工、可視化までの作業を他サービスとの連携をすることなく一気通貫して作業を行える点です。
通常はデータを使用する際に以下のようなデータを扱う以前の問題を多々上げられることが多いです。
・データ基盤が複数あり使用すべきデータが不明
・処理に時間がかかる
・分析レポートが乱雑している
・分析用途に沿った他サービスとの連携にうまくいかない
Databricks社ではそういった問題を解消した便利なプラットフォームを提供しています。
さらに複数人との共同開発や、タイムトラベル機能によるノートブックのバージョン管理、ジョブ実行などの機能をうまく利用することによって使用者の用途に合った応用を効かせることができます。
今回は本記事で上記のメリットをすべてご紹介するまではいきませんが、PythonとSQLが書ければ簡単にDatabricksのみで生データの加工からデータの可視化までをすべて行えることをお見せできればと思います。
対象のデータ確認
以下のCSVデータを使用いたします。
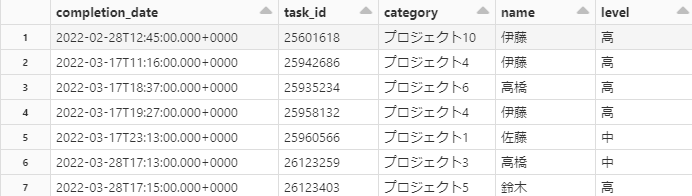
テーブルの各行にはそれぞれ完了したタスクについての情報を持っています。
・competetion_date
→タスクが完了した日時
・task_id
→タスクを識別するためのID
・category
→タスクはどのプロジェクトに属しているのか
・name
→誰によってタスクが完了されたか
・level
→タスクの難易度
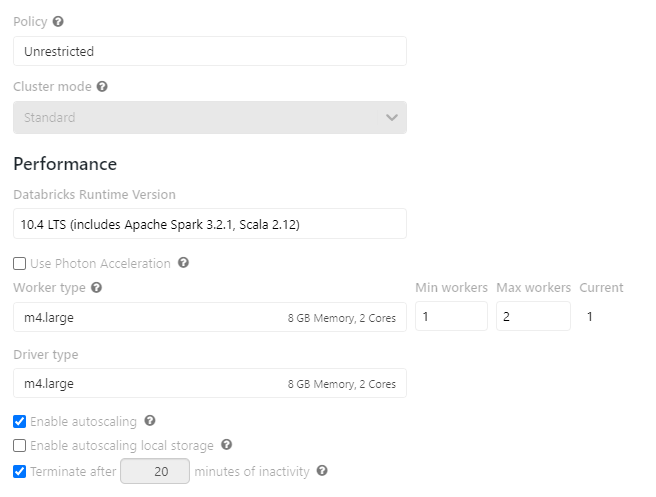
作業環境
以下のスペックのクラスターを使用いたします。
Delta形式化する理由について
データを加工や可視化していく前に生データであるCSVデータをDelta形式に変換したテーブルを作成します。
Delta形式とはDelta lakeというDWHとData lakeの両方の特徴を機能として併せ持つオープンソースのストレージサービスを利用するためのデータ形式になります。
Delta形式に変換することによって、以下のような代表的なメリットがあります。
・大規模データの高速処理が可能
・データの信頼性(例えばデータの破損や複数人による同時操作による影響を防ぐなど)を保つ
・タイムトラベル機能により加工前のテーブルに戻ることができる
・ストリーミングやバッチ処理に応用できる
今回使用する生データでは小規模のデータであり、Delta形式に変換する恩恵は受けにくいですが大規模データを扱うことも想定してDelta形式のテーブルを作成していきます。
こちらの公式サイトではDelta lakeについて詳しく記載されております。
CSVデータのDelta形式化
必要なモジュールをインポートします。
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
スキーマを指定してCSVデータを読み込みます。
from pyspark.sql.types import *
dataset = "dbfs:/FileStore/tables/samples/back_log.csv"
# スキーマ指定
schema = StructType([
StructField("completion_date",TimestampType(), False),
StructField("task_id",IntegerType(), False),
StructField("category",StringType(), False),
StructField("name",StringType(), False),
StructField("level",StringType(), False)
])
#データの読み込み
df = spark.read\
.format("csv")\
.options(header="true")\
.load(dataset, schema=schema)
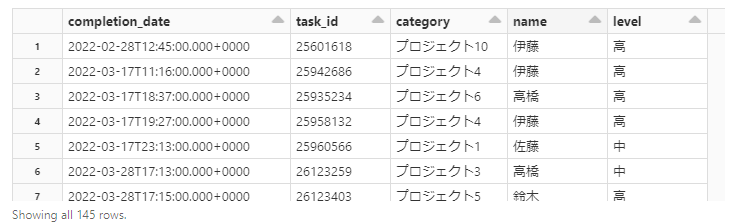
display(df)
先ほど確認したCSVデータが以下のように出力されます。
Delta形式化するテーブルを保存したい任意のデータベースに移動します。
%sql
USE for_sample
Delta形式化するテーブルに対して任意の保存先のパスを指定して、移動したデータベースにテーブルを保存します。
path = "dbfs:/FileStore/tables/backlog_data"
tbl_name = "backlog_data"
# Delta形式化
df.write.format("delta").option("path",path).saveAsTable(tbl_name)
まとめ
これでテーブルのDelta形式化が完了しました。
次回はDelta形式化したテーブルを可視化に向けて加工していきます。