記念すべきQiita初投稿です![]()
リサーチインターンでPerson Re-Identificationというタスク(後述)についてサーベイをすることになりました。
さっと眺めてみたところ案の定ここ数年で深層学習モデルが火を吹き、Market-1501やDukeMTMC-reIDやMARSなどメジャーなデータセットにおいてSoTAをバチバチと競っていました。
研究はサーベイしないと何していいか全く分からないので、こと激流の真っ只中にある機械学習界隈においては最新の研究を大量にサーベイすればするほど幸せになれると思います。
そんな時にちょうどいい(?)のがCVPR2019ですね(?)
「person」で検索して出てきた掲載論文を上から順に、時間の許す限り1人粛々とまとめていきます。
(下書き開始から約1ヶ月後に追記)一応全て目を通し掲載できました。
なお目的としては現状把握が強めのため、さらっと把握するサーベイ色が濃いです。厳密な数式、具体的なネットワーク構造、実験結果など興味を持たれたものについては各リンクをご参照ください。
また本記事の中で用語の定義や説明がよく分からない部分については、私自身がまだ理解できていないところも多くあります。必要に応じて各論文を読み込み加筆修正を重ねていくつもりでいることをご了承ください。まだ書かれていない網羅性、議論、次に読むべき論文なども私自身の研究の必要性に応じて深掘りしていきます。
先に読むと後の理解が捗る話
Person Re-Identificationとは
Person re-identification (re-ID) aims to match a specific person across multiple camera views or in different occasions from the same camera view. It facilitates many important applications, such as cross-camera tracking.
This task is challenging due to large variations on person pose and viewpoint, imperfect person detection, cluttered background, occlusion, and lighting differences, etc..
(Densely semantically aligned person re-identification 1.Introductionより)
複数カメラによるビデオ映像群から人物検出とID保存を行なって同一人物を識別していくCV(Computer Vision)タスクです。ショッピングモールや学校の中などの特定エリア内における監視カメラネットワークを想像するとわかりやすいかと思います。
person re-IDとは
参考記事
-
Metric Learningについて
Papers
落合陽一さんの論文読みフォーマットを参考に読む際のポイントを設けています。
以下使用画像は各論文より引用
Perceive where to focus: Learning visibility-aware part-level features for partial person re-identification
-
どんなもの
- 自己教師あり学習(self-supervision)によって領域可視性(visibility of regions)を理解するVisibility-aware Part Model(VPM)
- Global featureに比べて領域(region)レベルの特徴量を学習するため、きめ細かい(fire-grained)情報を利用できる
- 共有領域の推定により、比較し合う画像の共有範囲外がノイズとなってしまうのを抑制
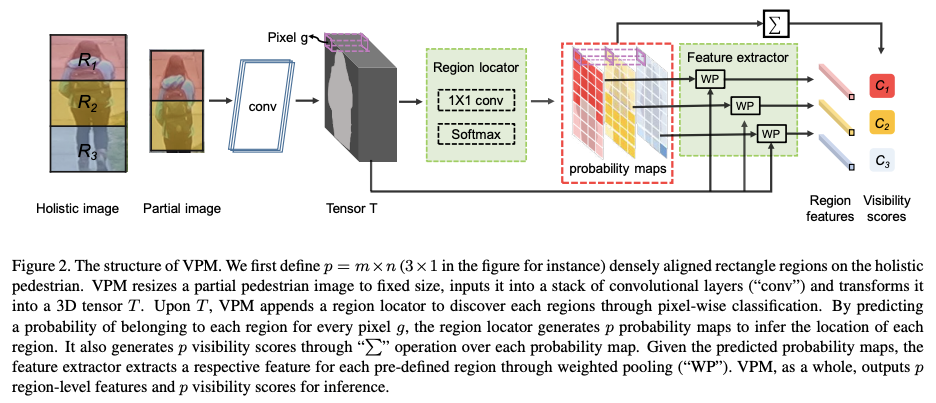
- 自己教師あり学習(self-supervision)によって領域可視性(visibility of regions)を理解するVisibility-aware Part Model(VPM)
-
批判されている理論は何?
- パーツごとに認識するperson re-IDの課題点はふたつ
- 全身画像によるre-IDは主に歩行者の関節運動とカメラ位置が原因で同一人物画像にばらつきが生じるが、partial re-IDでは同じ姿勢で同じカメラでも部分毎に写り方が異なってくる(画像a)
- 全身画像と直接見比べる際に、部分的な画像に写っていないところはむしろ識別の邪魔になってしまう(画像b)

- パーツごとに認識するperson re-IDの課題点はふたつ
-
どういう文脈・理路をたどっている?
- re-IDの研究界隈は過去数年で飛躍的に進化しているのに、そのシステムは今だに現実世界特有の困難に直面している
- 有効なアプローチのひとつとしてpartial re-ID(体のパーツレベルでの人物一致)がある
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Invariance matters: exemplar memory for domain adaptive person re-identification
-
どんなもの
- target domain内部のvariationを明示的に考慮し、3つのunderlying invariancesを調査
- exemplar-invariance
- まずラベル付きデータセットで訓練されたdeep re-IDモデルにクエリを投げた最上位の検索結果を見てみると、見た目的には相関する可能性が高いことがわかる
- 実際には同一人物の画像でもかなり異なったものがあるので、これはre-IDモデルが意味情報の代わりに視覚的情報を学習していることを示している
- camera-invariance
- カメラによって人物画像は全然違うものになるにも関わらず、camera-style transferによって生成された人物画像は元のidentityに従属している
- 人物画像と対応するcamera-style transferred画像は互いにcloseであるべきだ
- neighborhood-invariance
- sourceとtarget両domainで適切に学習したre-IDモデルにおいては、ターゲットセット内でtarget exemplarとそのnearest-neighborsはおそらく同じIDである
- この不変性はモデルの学習において、target domainにおける画像のvariation(姿勢や画角や背景の変化)を超えてよりロバストになるための助けとなる

- exemplar-invariance
- 上記の見方に基づき、システムにこれらの不変性を組み込むための新しい教師なしドメイン適応のperson re-ID手法としてメモリモジュールを提案
- 学習中はexemplar memoryがネットワークに導入され、ターゲットセットの各標本の最新の(up-to-date)表現を記憶
- メモリによってミニバッチではなく全体(global)なターゲット学習バッチに対して不変性の制約を適用できるので、ネットワーク最適化プロセスの最中にtarget domainの不変性を効果的に学習可能
- 少しの計算量とGPUメモリ増加でモデルの精度が劇的に向上
- target domain内部のvariationを明示的に考慮し、3つのunderlying invariancesを調査
-
批判されている理論は何?
- だいたいの教師なしドメイン適応(unsupervised domain adaptation)はクラスが共通だという閉じたシナリオを仮定していて、re-IDでは使えない
- sourceとtarget間のギャップを減らす最近の研究
- image-levelやattribute feature levelがある
- これらはsourceおよびtargetのdomain全体のvariationのみ考慮しており、target domain内部のvariationを無視している
-
どういう文脈・理路をたどっている?
- target domainから十分なラベルなしデータを得ることは比較的簡単だが、アノテーションなしでdeepなre-IDモデルを学習するのは難しい
- 既にラベル付きであるsource domainから、target setにも使える識別的な表現(discriminative representation)を学習したい = unsupervised domain adaptation(UDA)
- 学習データのクラス(今回なら人物IDデータベース)は実用時には全く異なるため、person re-IDにおいてUDAはopen set(unknownを含めて学習する)なdomain adaptationとなる
- つまりsourceとtargetで分布を直接alignするのは適切でない
- 最近のperson re-IDタスクにおけるUDA手法はいくつかあるが、target domain内部のvariationを無視している
- target variationはかなり大切だ
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Dissecting person re-identification from the viewpoint of viewpoint
-
どんなもの
- viewpointの違いによるperson re-IDへの影響を定量的に評価
- 学習セットのviewpointがシステムにどう影響するか
- クエリのviewpointが検索にどう影響するか
- 学習セットのviewpointを変えるとre-IDの精度はどうなるのか
- 0°から360°まで変化させて調査し、empiricallyな実験としてMarket-1203でも手作業でviewpointラベルを付与し実験している
- そのために人の3Dモデルを操作できるPersonXエンジンを開発(すごすぎる...)
- 1266の個人(identity)
- 姿勢、viewpoint、照明、背景、行動(歩いたり走ったり)を変更できるしbounding boxもつけれる
- viewpointの違いによるperson re-IDへの影響を定量的に評価
-
批判されている理論は何?
- アルゴリズムデザインの最新研究によって定性的にperson re-ID認識システムへインパクトは与えているものの、パフォーマンスにどのように影響するのかは定量的には大部分が未知である
-
どういう文脈・理路をたどっている?
- viewpoint、姿勢、照明、背景、解像度はperson re-IDにおいて影響してくる問題
- viewpointに絞って歩行者の回転角度(rotation angle)による影響を定量評価する
- 学習に効果的な人物画像の向きがわかる(かも)
-
対象となるスコープにおいて網羅性と整合性はある?
- 5.Evaluation of Viewpointより
- viewpointが欠けると学習の質が落ちる
- ランダムよりも連続したviewpointsが欠ける方がdetrimentalである
- viewpointが学習時に限られているなら、前後だけよりも左右だけの方が良いモデル学習ができる
- クエリも同様に左右のviewpointの方が前後よりも一般的に高いre-ID精度が出る
- クエリと似たviewpointのfalse matchesよりクエリに似ていないviewpointのtrue matchesの方が検索が難しい
- 複雑な背景、強い照明、低い解像度など難しい環境になると上記の問題点はより過酷になる
- 5.Evaluation of Viewpointより
-
議論はある?
-
次に読むべき論文は?
Learning to reduce dual-level discrepancy for infrared-visible person re-identification
-
どんなもの
- mixed modality(可視光カメラ画像と赤外線カメラ画像間でのmodalityの混合)と見た目の不一致(appearance discrepancy)を分解し、別々に扱うことができるDual-level Discrepancy Reduction Learning(D^2RL)
- 画像レベルのdiscrepancy reductionサブネットワーク$T_I$を通じて緩和する
- modalityの不一致を分離し、与えられた可視または赤外線画像からマルチスペクトル画像を合成することにより画像表現を統一する
- 見た目の不一致は特徴レベルのdiscrepancy reductionサブネットワーク$T_F$によって扱うことができるようになる
- feature embeddingが統合した表現よりも効果的
- これら2つのネットワークをカスケード接続し、end-to-end mannerで最適化
- 最終的に$T_I$は$T_F$からより識別的にスペクトル画像を生成できるという恩恵を受け、$T_I$は$T_F$にもっと多くの変換済みサンプルを与える
- 画像レベルのdiscrepancy reductionサブネットワーク$T_I$を通じて緩和する
- mixed modality(可視光カメラ画像と赤外線カメラ画像間でのmodalityの混合)と見た目の不一致(appearance discrepancy)を分解し、別々に扱うことができるDual-level Discrepancy Reduction Learning(D^2RL)
-
批判されている理論は何?
- スペクトラムの異なるカメラでのperson re-IDを行っている先行研究では$\delta_m$(modalityの不一致)を$\delta_a$(appearanceの不一致)の一部と捉え、一般的なre-ID手法のように特徴レベルの制約を用いて$\delta_m+\delta_a$(mixed discrepancy)を減らそうと試みている
- 単一のmodality(Visible-VisibleやIR-IR)とcross-modalityのパフォーマンスギャップはかなり大きい
- これは、特徴レベルの制約のみではmodalityの不一致を効果的に取り除くことは出来ないことを示している
-
どういう文脈・理路をたどっている?
- 暗い場所でのperson re-ID手法として赤外カメラを使うものがある
- この際、人の画像を対応させるときに違うスペクトラムカメラで撮影された画像を見つけなければならないという問題が新たに発生する
- 従来のviewpointや姿勢の変化などの問題に加え、スペクトラムカメラによって画像処理が異なることに起因するmodalityの不一致が問題となり、これは見た目的な問題よりも影響が大きい
- 同じカメラで撮影した異なる人の画像同士よりも、可視光カメラと赤外線カメラで撮影した同じ人の画像同士の方が距離が大きい
- 暗い場所でのperson re-ID手法として赤外カメラを使うものがある
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Densely semantically aligned person re-identification
-
どんなもの
- 新しいdensely semantically aligned person re-IDフレームワーク
- Main Full image Stream(MF-Stream)とDensely Semantically Aligned Guiding Stream(DSAG-Stream)からなるネットワーク
- DSAG-StreamはMF-Streamがsemantically aligned featuresを学習するガイドとしてのレギュレータ的役割を果たす
- 正規空間(canonical space)で人の体にdense semantic alignmentを実行
- 限られた数の粗い関連付けしかできない姿勢情報と違って、dense semanticsは2D人物画像と3D表面ベースの人体正規表現との間に密な対応関係を確立
- 部分内もピクセル単位で24の領域にマッピングされる
- 推論時はDSAG-Streamを取り除き、計算効率よくロバストに
-
批判されている理論は何?
- partitionの仕方が良くない
- 水平分割など簡単なもの
- パーツ毎に分けようと試みているが満足できるalignmentとはいかない粗さ
- これではdensely semantically aligned featuresを効果的に学習できない
- partitionの仕方が良くない
-
どういう文脈・理路をたどっている?
- いくつかの研究でglobalな特徴表現をend-to-endで学習するためにCNNが使われているが、その能力には限界がある
- local differencesに重点が置かれていない
- misalignmentに効果がある明確なメカニズムが無い
- 最近は良くなってきた
- いくつかの研究でglobalな特徴表現をend-to-endで学習するためにCNNが使われているが、その能力には限界がある
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Generalizable person re-identification by domain-invariant mapping network
-
どんなもの
- モデル更新不要で初見のデータセットに適用できるdomain generalization手法であるDomain-Invariant Mapping Netwoek(DIMN)
- 人物画像とID分類器の重みベクトル間のマッピングを学習(つまり分類器はsingle shotを使用)
- 一度学習すれば、target domainにおいて各ギャラリーイメージはIDに対応する特定の線形分類器の重みベクトルを生成するネットワークに送り込まれる
- 重みベクトルとdeepな特徴量ベクトルとの単純なドット積を計算し、分類器でプローブ画像をマッチング
- ドメイン不変(domain-invariant)にするためメタ学習パイプラインに接続し、各学習episode中にsource domainタスク(ID)のサブセットをサンプリング
- 従来のmeta-learningと違う点がある
- target domainに対するモデルの更新は不要
- running average strategyに伴って更新されるメモリバンクモジュールを異なる学習タスクが共有する
- 一度学習すると、モデルはtarget domainで任意の数のIDに対応できる
- 5つの既存reIDデータセットを用いて、domain generalizationベンチマークを定義
- source domainと4つのtarget domain
- モデル更新不要で初見のデータセットに適用できるdomain generalization手法であるDomain-Invariant Mapping Netwoek(DIMN)
-
批判されている理論は何?
- 既存のUnsupervised Domain Adaptation(UDA)手法はラベルなしのtarget domainデータによる更新をしているので、データ収集とモデル更新が必要
- reIDに限らずDeep Learningにおけるdomain generalizationはfew-shot meta-learningアプローチが用いられている
- domain generalizationはsourceとtargetで同じラベル空間であることを仮定している
- meta-learningはクラス数が同じであることを仮定している
-
どういう文脈・理路をたどっている?
- reIDに使われている各データはdomainと見ると、全く違った状況(屋内外、ショッピングモール、交差点、空港など)から集められたデータであるのでdomain gapがあると考えられる
- モデルを更新せずに新しいデータセット(domain)に適用するとかなりのパフォーマンス低下が見られ、モデルの過学習や不十分なdomain generalizationであることを示している
- domain generalizationには異なるラベル空間(person ID)という問題を解決する必要がある
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Re-ranking via metric fusion for object retrieval and person re-identification
-
どんなもの
- 新しいfusion with diffusionアルゴリズムであるUnified Ensemble Diffusion(UED)
- diffusionステップがNFぐらい速い
- REDよりノイズに対してロバスト
- TPFのように相互作用を考慮しながら2つ以上のsimilaritiesに対応できる
- UEDと既存手法を分析、継承されたプロパティは確かに統合フレームワークに由来する
- UEDの特殊なケースが既存の3手法、ということになる
- 固有の相違点は目的関数に対する追加制約と類似性伝播の変動(variation)にある
- 副産物として、知り得る限りでは初めてre-rankingにおけるmetric weightを学習する強力なoptimizerとしてreplicator equationを紹介
- UEDはformulationとderivationにおいて注意深く設計された
- 不運にもUEDは解くのが困難な非凸最適化(non-convex optimization)となってしまったことに起因
- 新しいfusion with diffusionアルゴリズムであるUnified Ensemble Diffusion(UED)
-
批判されている理論は何?
- NFは最も速いがノイズのある類似度(noisy similarity)に影響されやすい
- 対照的にTPFは2つのsimilarityの相互作用を考慮しある程度ノイズにロバストだが、毎回2つのsimilarityのみ融合可能
- REDは動的に重みを学習しノイズの影響を消せるが、入力ごとにdiffusionステップを行う必要があるため比較的計算コストが高い
-
どういう文脈・理路をたどっている?
- 既存のfusion with diffusion methods
- Naive Fusion(NF)
- シンプルに複数のaffinity graphのedge weightsを平均
- Tensor Product Fusion(TPF)
- 2つの全く異なる相補的なmetricを結合する
- Regularized Ensemble Diffusion(RED)
- ノイズのあるmetricを入力とする
- 複数のグラフベースなmanifoldのsmoothnessを最大化するために類似度と重みを同時に学習
- Naive Fusion(NF)
- 既存のfusion with diffusion methods
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Weakly supervised person re-identification
-
どんなもの
- 全体として弱教師ありのperson re-IDをMulti-Instance Multi-Label(MIML)learningという問題と捉え、Cross-View(CV) MIML手法を開発
- bag内の類似instanceを利用してbag内位置合わせ(intra-bag alignment)を行う
- distribution prototypeをMIMLに埋め込むことで、カメラビューでキャプチャされたbag間でのpotential matched instanceをマイニングできる(cross-view bag alignmentと呼ぶことにする)
- 最終的にCV-MIMLをDeep Neural Networkに埋め込むことでend-to-endなDeep CV-MIMLモデルを作り上げる
- 全体として弱教師ありのperson re-IDをMulti-Instance Multi-Label(MIML)learningという問題と捉え、Cross-View(CV) MIML手法を開発
-
批判されている理論は何?
- 教師ありのre-IDは学習時にいくつか仮定がある
- probeセットやギャラリーセットの画像は、(たいていは検出器の助けを借りながら)未加工のビデオからフレーム毎に手でトリミングされラベル付けされる
- 全学習サンプルがマッチングするターゲットであり、外れ値は存在しない
- このような規則通りのアノテーションでは精緻な教師データを必要としてしまい、person re-IDモデルのロバストに学習する困難さを排してしまう
- 教師ありのre-IDは学習時にいくつか仮定がある
-
どういう文脈・理路をたどっている?
- 弱教師ありでperson re-IDをモデリングしたい
- (この論文のみの定義?)弱教師とは映像に対してどのIDが現れるかのみをアノテーションすればよく、フレーム毎には何もしなくてもよいこととする
- アノテータが見逃していてアノテーションの中には入っていないIDの人が映っている可能性(unknown扱い)にも対応したい
- このために、ギャラリーセット内の各ビデオクリップをbagと考える
- 各bagは未加工の各ビデオクリップから検出した人物画像のinstanceが複数入っており、bagレベルでのラベルと交わっている
- probeセットについては、ギャラリーで探すtargetとなる個人が含まれる
- 各入力は手でトリミングしたターゲットとなる人物画像のセット
- 便宜上、probe入力もbagとする
- 弱教師ありでperson re-IDをモデリングしたい
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Query-guided end-to-end person search
-
どんなもの
- person detectionとre-identificationを同時最適化(joint optimization)するQuery-guided End-to-End Person Search(QEEPS)
- end-to-endでquery-guidedな唯一の方法
-
OIM(Online Instance Matching)を改良
- Query-guided Siamese Squeeze-and-Excitation Network(QSSE-Net)
- 最近のSqueeze-and-Excitation(SE)を拡張
- (globalな画像レベルの)クエリやギャラリー間依存性によってチャネル毎にSiamese feature responseをre-calibrate
- Query-guided Region Proposal Network(QRPN)
- クエリ固有の提案(proposal)によりパラレルRPNを補完
- 空間的特徴を強調、特にクエリ固有のdiscriminantなものを持ってくるSEブロック拡張
- Query-Similarity Network(QSimNet)
- クエリとギャラリー画像のproposal re-id特徴を取得し、query-guided reidスコアを提供
- Query-guided Siamese Squeeze-and-Excitation Network(QSSE-Net)
- person detectionとre-identificationを同時最適化(joint optimization)するQuery-guided End-to-End Person Search(QEEPS)
-
批判されている理論は何?
- person detectionとre-IDそれぞれで完結してしまうともう片方に有用なcontextualな情報が失われてしまう
-
どういう文脈・理路をたどっている?
- person searchはperson localization(detection)とre-identificationに分けられ、それぞれが教師ありネットワークである
- 人間が画像から人物検索を行うとき、各個人だけを見ずにTシャツの色など追加のヒントも参考にしている
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Distilled person re-identification: towards a more scalable system
-
どんなもの
- 知識の再利用(knowledge reuse)に基づくスケーラブル適合システムであるMulti-teacher Adaptive Similarity Distillationフレームワーク
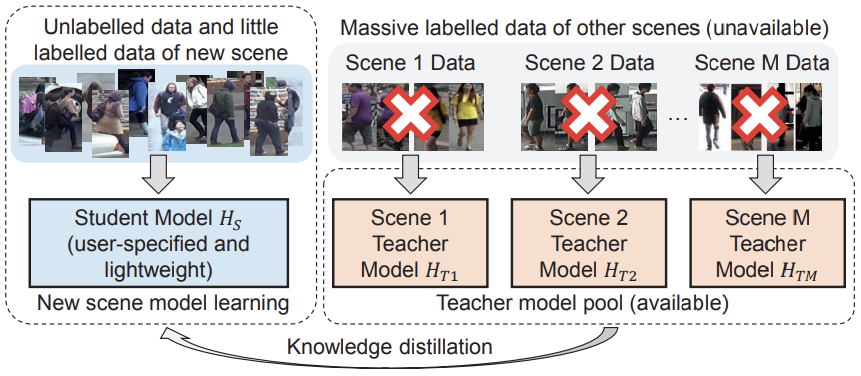
- target domainにおけるラベルなしデータと少量のラベル付きIDから、source domainデータなしで拡張可能
- rawデータの代わりに、教師モデル$H_{T_i}$における既存のシーン$i$の知識(knowledge)を溜める
- 新しいシーンに拡張する時は、教師モデルプール${H_{T_i}}^M_{i=1}$の知識を集め、target domain用の新しいユーザ固有の軽量な生徒モデル$H_S$へ転移させる
- 類似度における知識埋め込み(knowledge embedding)を行い、教師モデルのsample pairwise類似度行列を模倣するためのLog-Euclidean Similarity Distillation Loss
- distillation lossにおける複数の教師モデルのcontributionを動的に調整し、target domainのための効果的に知識を集めるAdaptive Knowledge Aggregator
- computing empirical riskのためにvalidationデータとして10前後のラベル付きデータのみ必要
- 知識の再利用(knowledge reuse)に基づくスケーラブル適合システムであるMulti-teacher Adaptive Similarity Distillationフレームワーク
-
批判されている理論は何?
- 既存の教師ありre-ID手法は豊富なラベル付きIDを必要とする
- 大規模システムには現実的でなく、ラベルなしデータや限定的にラベルを付けたデータから学習できるシステムがスケーラブル
- 新しいシーンへと拡張するとき、大半の既存re-ID手法は転移学習を行う
- 事前学習やjoint trainingのために補助的なsource domainデータが必要だが、プライバシーやtransfer(転移or譲渡?)の問題によりアクセスできない場合がある
- 使用可能でも、joint trainingは計算コストが増加する上、事前学習モデルは異なるユーザ固有の要求があり適用が困難かもしれない
- 近年re-IDの元となっているResNet50のような巨大なNNモデルはチップのフロントエンド処理におけるカメラハードウェア開発トレンドには適合できないため、軽量なモデルであるべき
- 既存の教師ありre-ID手法は豊富なラベル付きIDを必要とする
-
どういう文脈・理路をたどっている?
- re-IDシステムの拡張性は大規模監視システムに導入する障壁となっており、まだ研究段階である
- 教師なしや転移学習によってラベル量を減らし高速な検索をしようというアプローチが提案されている
- 拡張性の高いシステムを作り上げるためには、これら先行研究の異なるアプローチを統合することが望まれる
- ラベリングコストを下げる
- (source domainデータなしに)拡張コストを下げる
- テスト計算コストを下げる
- 提案するシステムにおける知識転移はムズい
- 限られたラベルのみ付いたtargetデータとsourceデータの欠により、軽量モデルにおいて学習のための情報がほとんど得られず、知識を圧縮する必要がある
- 教師モデルにおいて知識蒸留っぽいことをする必要がある
- 既存の知識蒸留はclosed-set分類でsoft labelによって知識を伝えるため、open setでのidentification問題であり学習時とテスト時でIDが異なるre-IDには向いていない
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Towards rich feature discovery with class activation maps augmentation for person re-identification
-
どんなもの
- ベースラインモデルのactivation scopeを拡張し体全体にわたって十分な視覚的特徴を学習可能なClass Activation Maps Augmentation(CAMA)
- 視覚的かつ識別的な領域(visual discriminative regions)はClass Activation Mapsによってlocateされる
- Overlapped Activation Penalty(OAP)と名付けた新しい損失関数を導入し、ordered branchesによってバックボーンモデルを拡張
- 現在のbranchは多様な視覚的手がかりを得るように、前段のbranchesがあまりactivateしなかった領域から強制的にきめ細かい特徴を発見する
- ランキング結果をより解釈しやすくするため、Ranking Activation Mapsのような視覚化手法を提案
- クエリとランキングリスト内のギャラリー両画像において、視覚的特徴を明示的にビジュアライズ
- person re-IDにおいてランキング結果を解釈するのは知り得る限り初の試み
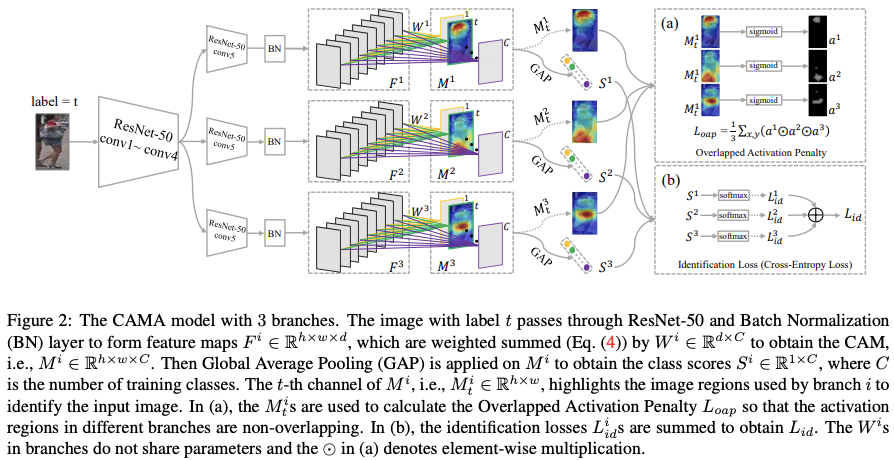
- ベースラインモデルのactivation scopeを拡張し体全体にわたって十分な視覚的特徴を学習可能なClass Activation Maps Augmentation(CAMA)
-
批判されている理論は何?
- 体全体から視覚的特徴を得るには、体のparts localizationのためにrigidな空間的分割や姿勢推定や見えない部分の学習など追加のステップが必要
- アルゴリズムの複雑性と不確定性を増長させてしまう
-
どういう文脈・理路をたどっている?
-
person re-IDにおける課題のひとつとして、人物間の細かな差異(small inter-person variation)が判別を困難にしている
- 例)服装が上下とも全く同じ色合いである別人に対して、服装に注意が向いているせいで(靴の色やカバンのストラップは違うのに)同一人物であると誤認識してしまう
-
少数の視覚的手がかりのみに注目してしまう傾向がある
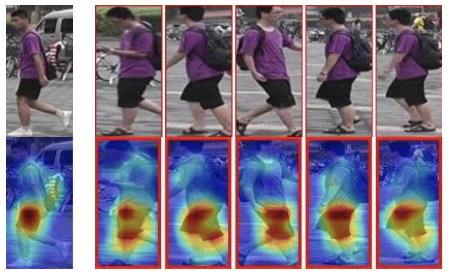
-
限られた学習データから豊富な識別的特徴を発見する手法はいくつかある
- 特別に設計された正則化(regularization)や制約で、classification lossを超える様々なmetric learning loss
- triplet loss
- quadruplet loss
- group similarities learning
- 複数のパーツから人の体全体にわたって、よりきめ細かい視覚的手がかりを発見し学習することに専念するmulti-branch network(本論文はこれ)
- rigid spatial divisions
- latent parts localization
- pose estimation
- human parsing
- attention map
- data augmentationにより学習データのvariationを増やす
- random cropping(mirroring)
- synthesized samples
- GAN
- adversarial occluded samples
- 特別に設計された正則化(regularization)や制約で、classification lossを超える様々なmetric learning loss
-
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Joint discriminative and generative learning for person re-identification
-
どんなもの
- 識別器と生成器をjoint learningする統合ネットワークDG-Net
- 歩行者画像を2つの潜在空間に分解する各エンコーダにおいて、コード(code)としてエンコード済み特徴量空間にアクセス
- appearance空間では見た目とIDに関連したsemanticをエンコード
- structure空間ではgeometryとposition関連の構造情報、その他追加のvariationを囲む(enclose)

- appearance空間エンコーダは識別モジュールと共有でre-ID学習バックボーンとして提供される
- 手順
- 生成モジュールはオンラインでappearanceエンコーダを改良するために合成画像を出力する
- エンコーダは改善したappearanceエンコーディングで生成モジュールに影響を与える
- 両モジュールは共有appearanceエンコーダでjointly optimized

- 歩行者画像を2つの潜在空間に分解する各エンコーダにおいて、コード(code)としてエンコード済み特徴量空間にアクセス
- 識別器と生成器をjoint learningする統合ネットワークDG-Net
-
批判されている理論は何?
- person re-IDにおけるGANはその生成パイプラインが独立しているモデルが一般的
- 生成(generative)モジュールの最適化ターゲットがre-IDタスクとうまく整合せず、生成データからのgainが制限されてしまう場合がある
- person re-IDにおけるGANはその生成パイプラインが独立しているモデルが一般的
-
どういう文脈・理路をたどっている?
- 同じ人物画像でも背景、viewpoint、姿勢などでかなり変わる
- 最新手法のアプローチ
- deep metric learning問題として
- deep embedding学習のプロキシとしてのclassification loss
- 同一人物画像の差異による影響をより減らそうというパーツベースのマッチングや、variationを明示的に調整し補正するアンサンブル
- data augmentationのためにGANを用いているものもある
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Unsupervised person re-identification by soft multilabel learning
-
どんなもの
- 潜在的識別情報をマイニングするsoft multilabel-guided hard negative mining、つまり見た目は似ているが異なるラベルなし人物を見分けるsoft multilabelを扱う
- soft multilabelはラベルなしのターゲットとなる
- 対のラベル誘導(pairwise label guidance)がなくてもいいように、ラベルなしデータ内の潜在的ラベル情報をマイニングするsoft mutltilabel learning
- 全てのラベルなしデータセット内人物画像に対して、既存のラベル付き補助sourceデータセットから参照人物(reference person)のセットと共にこのラベルなしの人物を比較することでsoft multilabel(single pseudo labelの代わりに実数値ラベル尤度ベクトル)を学習する
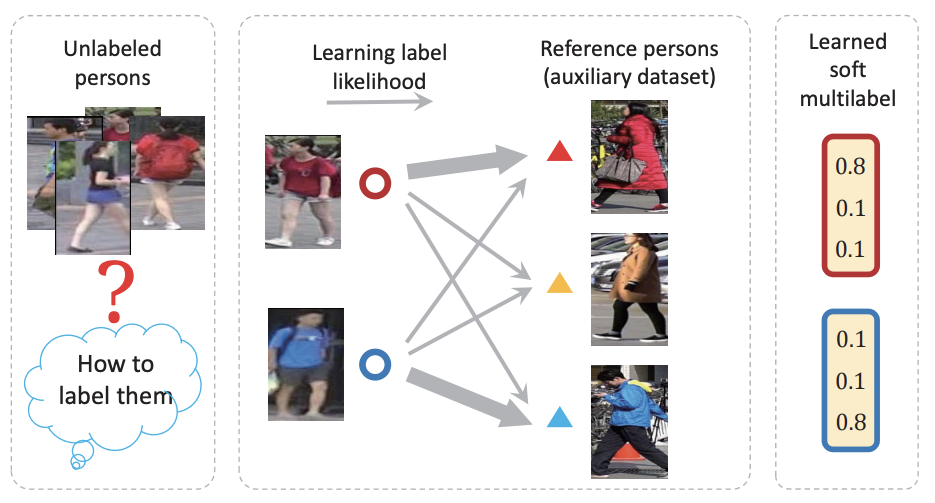
- 全てのラベルなしデータセット内人物画像に対して、既存のラベル付き補助sourceデータセットから参照人物(reference person)のセットと共にこのラベルなしの人物を比較することでsoft multilabel(single pseudo labelの代わりに実数値ラベル尤度ベクトル)を学習する
- 潜在的識別情報をマイニングするsoft multilabel-guided hard negative mining、つまり見た目は似ているが異なるラベルなし人物を見分けるsoft multilabelを扱う
-
批判されている理論は何?
- 既存の教師なしre-IDではまだ精度が満足に出ない
- 学習の指針としての対となるラベルが無いと、人物IDを識別する情報を発見するのはかなり困難
- 同一人物でも画像の見た目がかなり異なる
- 見た目が似ている人物がいることがある
- 学習の指針としての対となるラベルが無いと、人物IDを識別する情報を発見するのはかなり困難
- 既存の教師なしre-IDではまだ精度が満足に出ない
-
どういう文脈・理路をたどっている?
- 教師ありre-IDはペアごとにラベル付けされたかなりのデータが必要であり、ラベルなしデータのみ利用可能な大規模アプリケーションにおいてスケーラビリティを制限する
- そこで教師なし学習
- targetのラベルなしデータをクラスタリング
- ラベル付きのsourceデータセットから知識転移
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Learning context graph for person search
-
どんなもの
- コンテキストの手がかりを探索する新しいフレームワーク
- instance-level features
- targetとなる人物が入力されると、context candidatesとして同じシーンに映る全ての歩行者を集める
- relative attentionモジュール
- 有用なコンテキストのみ選り好みする
- context graphを構築
- probe-gallery pairsについてglobal similarityをモデリング
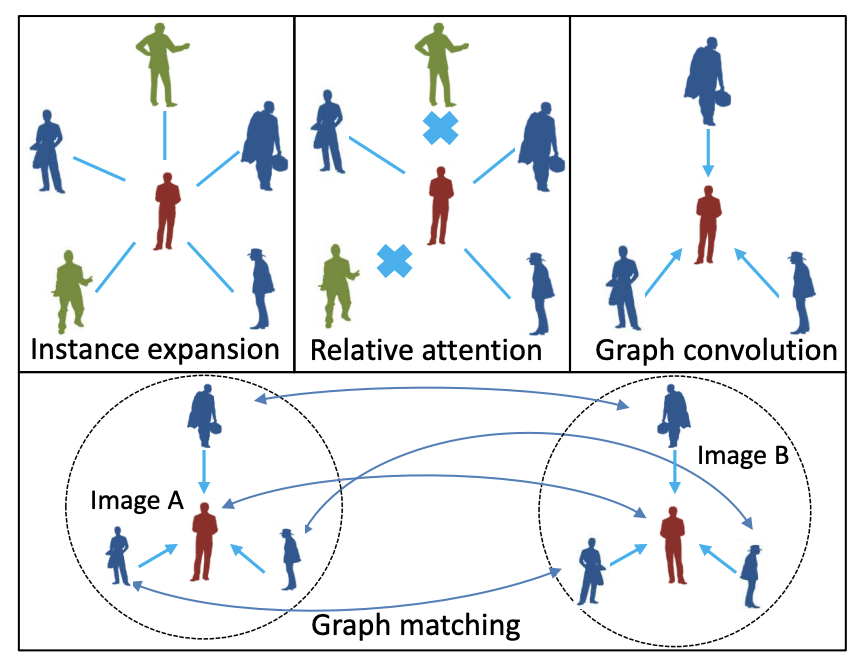
- probe-gallery pairsについてglobal similarityをモデリング
- instance-level features
- コンテキストの手がかりを探索する新しいフレームワーク
-
批判されている理論は何?
- ある人物と一緒に写っている人が同じかどうかという情報をperson re-IDに用いる
- グループごと識別するのは容易ではない(手でアノテーション)
- 歩行速度や相対位置
- モデリングも最適化も困難
- ある人物と一緒に写っている人が同じかどうかという情報をperson re-IDに用いる
-
どういう文脈・理路をたどっている?
- 既存のperson re-ID手法とは、異なるカメラ間で手作業で切り取った画像やビデオクリップをマッチングするタスク
- 個人の特徴量に基づいたdistance metricsを学習
- 事前に正確に切り取られたりアノテーションされている必要がある
- 誤った検出やアノテーションは大きなノイズ
- 歩行者検出とperson re-IDを一つのタスクとしたperson searchというタスク設定
- 現実のアプリケーションに近い設定
- システムがオフラインの歩行者検知器なしで機能する
- 個人の特徴量に視覚的な手がかりを用いている
- 特に大規模なギャラリーセットで似た服装が多く困難
- 最近の研究ではシーンのコンテキストを用いているものがある
- 既存のperson re-ID手法とは、異なるカメラ間で手作業で切り取った画像やビデオクリップをマッチングするタスク
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Progressive pose attention transfer for person image generation
-
どんなもの
- 姿勢を転移(transfer)させるPose-Attentional Transfer Blocks(PATBs)
- ターゲットに到達する前に姿勢に関する中間表現をprogressiveに転移させる
- 各transferブロックが多様体へとlocal transfer
- global manifoldの複雑な構造を捉えないようにしている
- 姿勢に基づいて関心領域(regions of interest)を推定するattentionメカニズム
- 姿勢表現を更新した画像を出力
- 姿勢を転移(transfer)させるPose-Attentional Transfer Blocks(PATBs)
-
批判されている理論は何?
- 最近の研究でもロバストな結果は出ていない
-
どういう文脈・理路をたどっている?
- 姿勢転移(pose transfer)は人物画像において特定の側面しか見えていないと困難である
- 特定の人物が取り得る姿勢は多様体を構成する
- 姿勢を制限すればlocal lebelでは異なる多様体間の移動(transition)はシンプルになる
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Patch-based discriminative feature learning for unsupervised person re-identification
-
どんなもの
- ラベルなしデータから識別的なpatch特徴量を学習するPatch-bAsed Unsupervised Learning(PAUL)フレームワーク
- 特徴マップからpatchを選び各patchから識別的特徴量を学習するPatchNet
- 似たpatchから特徴を引っぱり出し、似ていないpatchは遠ざけるPatch-basEd Discriminative feAture learning Loss(PEDAL)
- 同時に各画像のランダム変換によってsurrogate positive sampleを生成し、cyclic rankingでtripletを構成するミニバッチ内のhard negative sampleをマイニング
- 同一画像の全patch特徴量を活用して画像レベルのguidanceを提供するImage-level Patch Feature learning Loss(IPFL)
- ラベルなしデータから識別的なpatch特徴量を学習するPatch-bAsed Unsupervised Learning(PAUL)フレームワーク
-
批判されている理論は何?
- 最新の教師なしre-IDはラベル付きのsourceデータセットから知識転移
- 異なるデータセット間のギャップは大きい
- 最新の教師なしre-IDはラベル付きのsourceデータセットから知識転移
-
どういう文脈・理路をたどっている?
- ラベル付きの膨大なデータセットがないとperson re-IDモデルを学習できないのは実世界において課題
- 異なるデータセット間でも特定の2画像の見た目が似ていれば、そのpatchも似ていることを発見
- patchベースなら識別的特徴量学習モデルがより一般化可能で、異なるデータセット間で識別的なpatch特徴量を学習できるのでは

-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Attribute-driven feature disentangling and temporal aggregation for video person re-identification
-
どんなもの
- 特徴のもつれを解き(feature disentangling)フレームの再重み付け(frame re-weighting)を行うための属性駆動(attribute-driven)手法
- ひとフレームの特徴量はsub-featuresグループへと分解
- それぞれが特定のsemantic属性に対応
- sub-featuresは属性認識の信頼度(confidence of attribute recognition)により再重み付けされ、最終的な表現として時間次元(temporal dimension)へと集約
- 各フレームの最もinformativeな領域が強化される
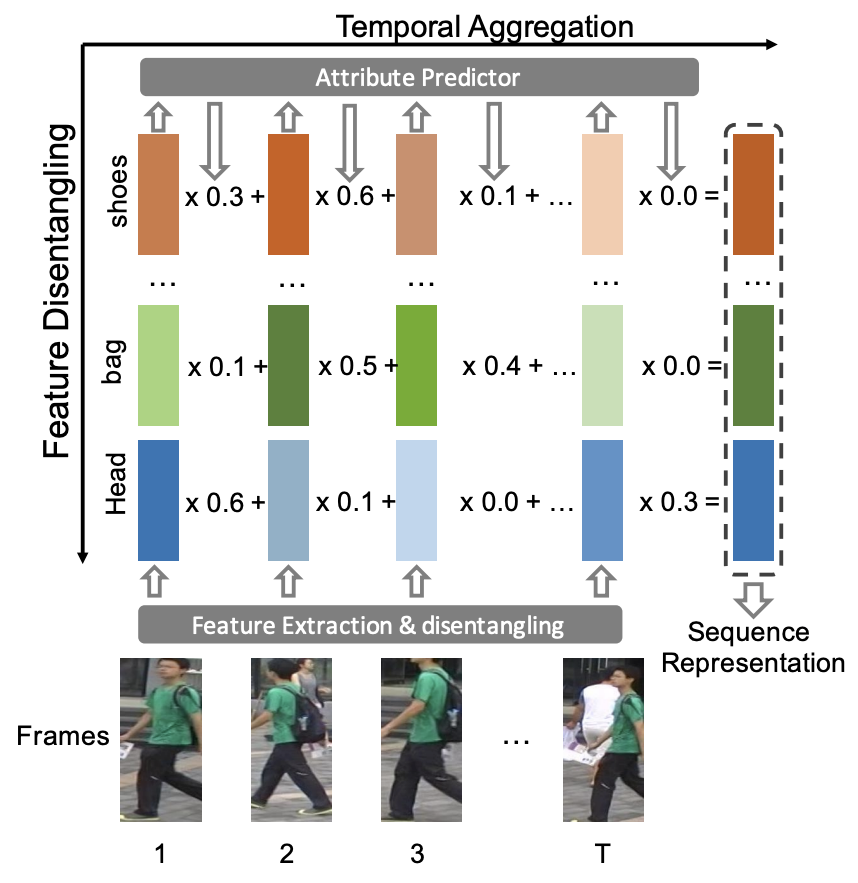
- 特徴のもつれを解き(feature disentangling)フレームの再重み付け(frame re-weighting)を行うための属性駆動(attribute-driven)手法
-
批判されている理論は何?
- 同じ体の領域の局所特徴量を同じtemporal weightのまま異なるフレームで共有するのはsuboptimal
- シーケンス間には姿勢変化やocclusionがある
- 同じ体の領域の局所特徴量を同じtemporal weightのまま異なるフレームで共有するのはsuboptimal
-
どういう文脈・理路をたどっている?
- ビデオでのreID
- RNN構造を取り入れたもの
- temporal average poolingに取って代わるTemporal Attention
- 質が高くocclusionの少ないフレームはaggregationにおいて大きな重みを持つだろうという仮定
- 体の領域ごとの局所特徴量
- ビデオでのreID
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
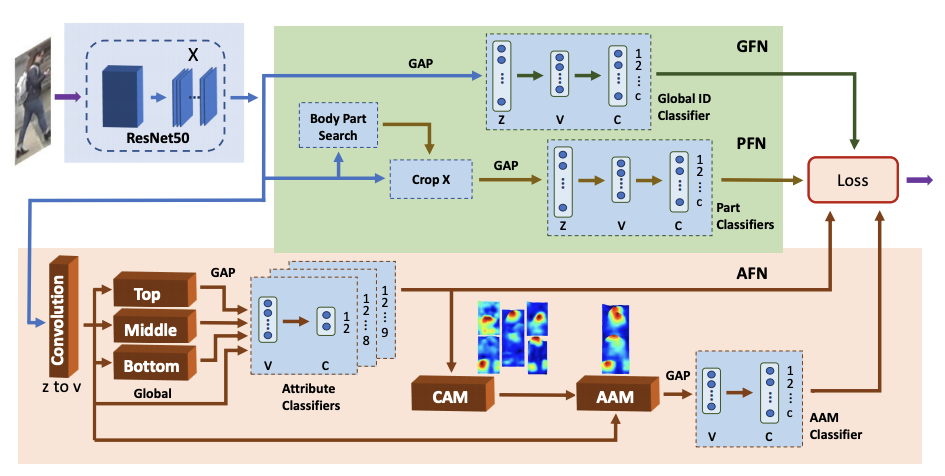
AANet: Attribute Attention Network for person re-identifications
-
どんなもの
- 人物の属性情報をclassificationフレームワークで使用できるAttribute Attention Network(AANet)
-
Global Feature Network
- 入力されたクエリ画像に基づいてglobal ID classificationを行う
-
Part Feature Network
- 体のパーツ検出
-
Attribute Feature Network
- 人物属性からclass-aware regionsを抽出し、Attribute Attention Map(AAM)を作成
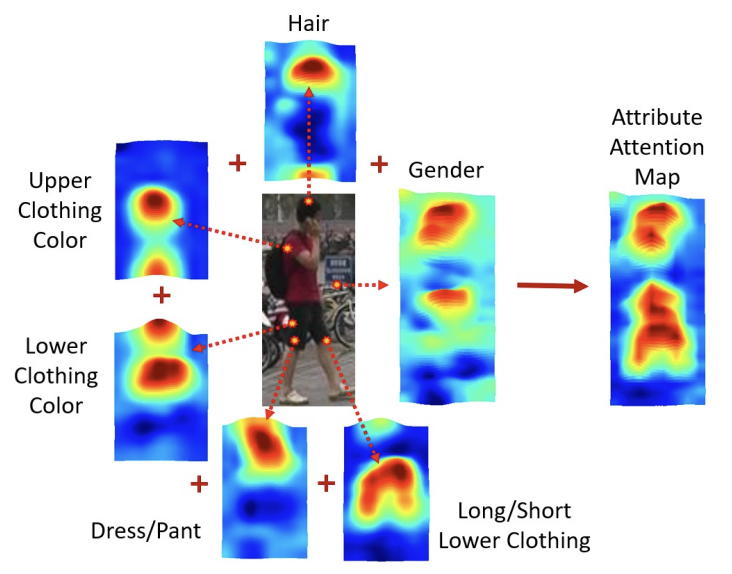
- 人物属性からclass-aware regionsを抽出し、Attribute Attention Map(AAM)を作成
-
homoscedastic uncertainty learningで3つのサブタスクを最適化し最終的なlossを計算
-
- 人物の属性情報をclassificationフレームワークで使用できるAttribute Attention Network(AANet)
-
批判されている理論は何?
- 服の色、髪、カバンの有無などの人物属性情報は使用されていない
-
どういう文脈・理路をたどっている?
- 既存のperson re-ID手法は大きく二つに分けられる
- metric learning
- classificationにする
- Softmax正規化とcross-entropy lossを計算することで学習
- 体のパーツや姿勢などsemantic情報を統合している
- 典型的なre-IDモデルは人物の外観がクエリとギャラリー間で大きく変化しないことを前提としている
- 既存のperson re-ID手法は大きく二つに分けられる
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
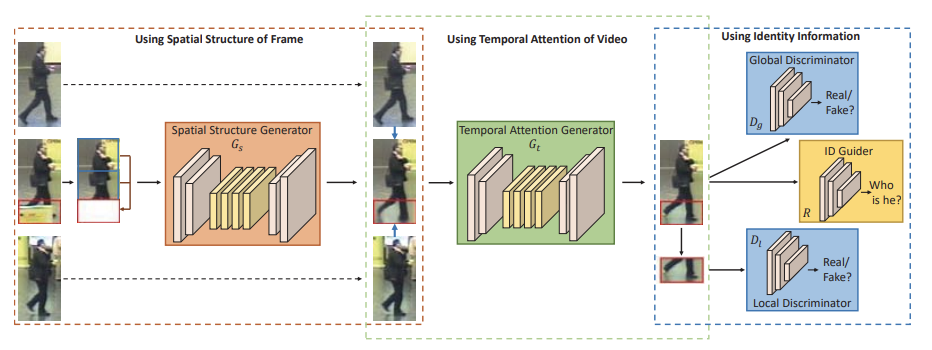
VRSTC: occlusion-free video person re-identification
-
どんなもの
-
隠れた体のパーツを視覚的に復元するSpatial-Temporal Completion network(STCnet)
- 見えている部分の空間的構造を使用するspatial structure generator
- 時間的に歩行者シーケンスの前後フレームを使用するtemporal attention generator
-
re-IDネットワークとSTCnetを結合することでocclusion-freeを実現するVRSTCフレームワーク
-
-
批判されている理論は何?
- partial occlusionに対してAttention機構を用いる既存手法はある程度toleranceはある
- しかし遮蔽されているフレームを破棄しているので理想ではない
- 隠れていない部分はre-IDに有用
- 部分的に破棄すると有用な時間的情報が遮られる
-
どういう文脈・理路をたどっている?
- 以前はocclusionのあるフレームも全て同等に扱っていた
- 最近はpartial occlusionに対してAttentionメカニズムを用いるものが増えてきた
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
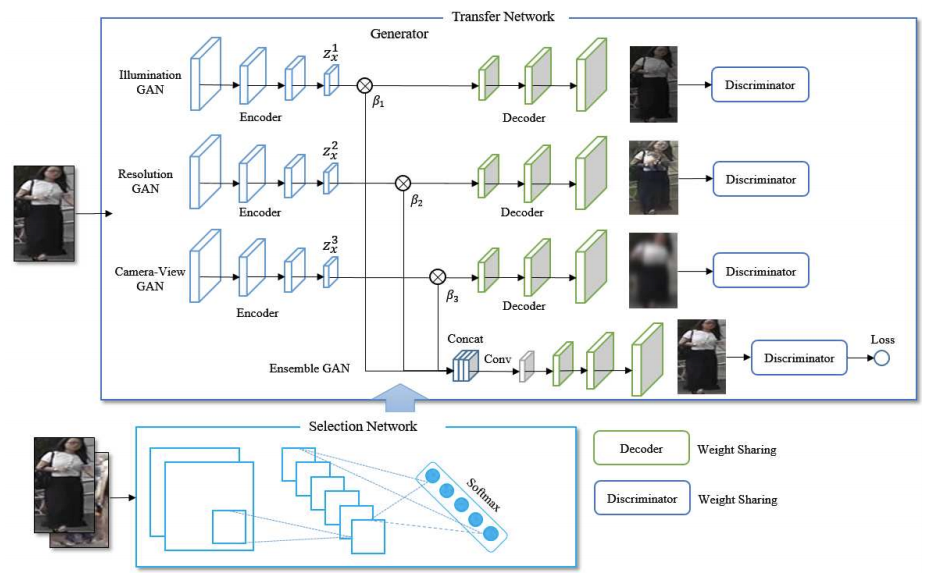
Adaptive transfer network for cross-domain person re-identification
-
どんなもの
- 効果的なcross-domain person re-IDのためのAdaptive Transfer Network(ATNet)
- domain gapというブラックボックスを調査し、"divide-and-conquer"の原理に基づいて処理を行う
- 複雑なcross-domain transferを中間サブタスクのまとまりへと分解
- 各サブタスクは特定のfactorを注視しきめ細かいレベルでstyle transferを行うことに集中する
- sub-transformersは同時に最適化、このアンサンブルはさまざまなfactorの影響に基づき各画像に対してself-adaptive
- factorごとの影響に対する理解力を伴ったstyle tranferを可能にする
- CycleGANを元にして照明、解像度、カメラビューの各factorとそのselection networkで構成される
- 効果的なcross-domain person re-IDのためのAdaptive Transfer Network(ATNet)
-
批判されている理論は何?
- データセットdomain間の不均衡は、画像処理中に複数の問題(照明、解像度、カメラのviewpointなど)によって引き起こされている
- 画像間でさえ異なる要因が発生しているので、既存のunsupervised domain adaptation手法ではsuboptimal
-
どういう文脈・理路をたどっている?
- 様々な場所と時間で複数のカメラが撮るため、データセット間で歩行者の見た目がかなり異なってしまう(domain gap)
- 例えばMarket-1501データセットを学習したGoogleNetはPRID2011データセットではわずか5.0%のrank-1精度
- domain gapの解決策としてunsupervised domain adaptation(UDA)
- 一般的なUDAはsourceとtarget両domainでクラスが同じことを仮定
- domain転移手法としてCycleGANをもとにしている(?)
- source domainの画像をID付きのままtarget domainに転移
- ラベル付きstyle-transferred画像をtarget domainで学習させる
- domain gapをブラックボックスとして扱っており、単一のstyle transformerに頼って解決しようとしている
- 様々な場所と時間で複数のカメラが撮るため、データセット間で歩行者の見た目がかなり異なってしまう(domain gap)
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
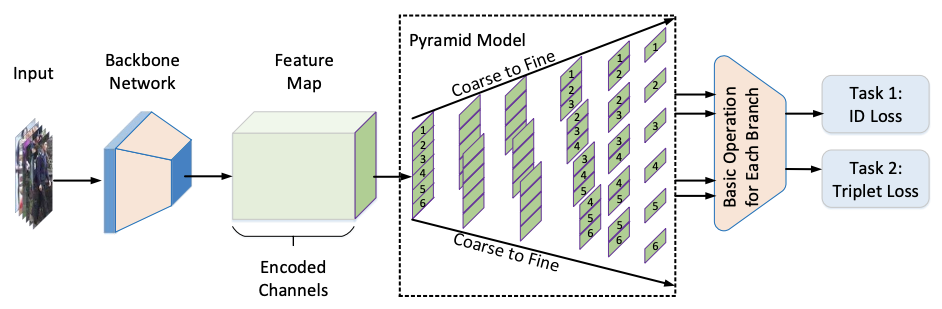
Pyramidal person re-identification via multi-loss dynamic training
-
どんなもの
- person re-IDのためのbackbone networkが抽出した特徴量マップに基づく新しいcoarse-to-fine pyramidal model
- 特定のcoarse-to-fineなアーキテクチャを伴う3次元のsub-mapsのセット
- 各memberは異なる空間スケールにおける識別的情報を捉える
- 畳み込み層がピラミッド内の枝分かれ(separated branch)のため特徴量の次元削減を行う
- 各ブランチにおいてsoftmax関数のidentification lossが、特徴量を入力とする全結合層に独立に適用される
- 全ブランチの特徴量が、より識別的な特徴量を学習するtriplet lossを定義するidentity表現を形作るべく集約される
- 特定のcoarse-to-fineなアーキテクチャを伴う3次元のsub-mapsのセット
- 2つのlossを円滑に統合するため、2つのsampling strategiesを伴ってdeep neural networksのパラメータを最適化する動的学習スキーム(dynamic learning scheme)を調査
- person re-IDのためのbackbone networkが抽出した特徴量マップに基づく新しいcoarse-to-fine pyramidal model
-
批判されている理論は何?
- 正確なbounding boxの検出が前提であるため、person re-IDのパーツベースのモデルや学習の困難性が問題となり既存手法を改善する余地は限られている
- 大半のマルチタスク手法は、学習プロセス中固定のbalancing parametersを用いたlossを重み付けするアプローチを採択している
- パフォーマンスが適切なパラメータに大きく依存するが、これは間違いなく大きな労力を要するうえに扱いにくい作業となる
- 異なるタスク間における困難さは段階的にモデルがアップデートされることで変化し、結果として各イテレーションで適切なパラメータが全く異なる
- さらに重要なのは、異なるlossのためのsampling strategiesは一般的に考慮すべき事項が多岐にわたる
- triplet lossのためのhard sample samplingがidentification lossの他のタスクを抑圧するなど
-
どういう文脈・理路をたどっている?
- person re-IDは歩行者検出システムの次なる高度なタスクと考えられ、基本的に検出モデルが正確でhighly-alignedなbounding boxを提供する前提
- occlusionやpartial variationのような避けられない課題に対してある程度ロバストではある
- SoTAはPCB(Part-based Convolutional Baseline)
- backbone networksの特徴量マップを固定数パーツに直接分割する構造が、パフォーマンス向上を制限している
- 全体のパフォーマンスが、パワフルでロバストな人物検出モデルが正確なbounding boxを出力するかどうかにかなり依存している
- 小さなviewの変化やinternal variationに対してロバストなglobal informationは、認識と識別の重要な手がかりでもあるのに完全に無視されている
- backbone networksの特徴量マップを固定数パーツに直接分割する構造が、パフォーマンス向上を制限している
- タスク間の適切な共有情報を抽出するマルチタスク学習が良い結果を出している
- 一般性を失うことなく、"loss"と"task"という言葉が使われており、既存のre-ID手法も多くはmulti-loss schemeの恩恵を受けてパフォーマンスを向上させている
- person re-IDは歩行者検出システムの次なる高度なタスクと考えられ、基本的に検出モデルが正確でhighly-alignedなbounding boxを提供する前提
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
Interaction-and-aggregation network for person re-identification
-
どんなもの
- 特に体の姿勢やスケール変動があるCNNについて、特徴表現性能を強化する新しいネットワーク構造であるInteraction-and-Aggregation(IA)
- Spatial Interaction-and-Aggregation(SIA)
- 入力された人物画像の姿勢やスケールに沿って適応的に受容野を決定
- CNNの中間特徴マップから、異なるimage position間の相互依存を2タイプ発見するspatial semantic relation mapを生成
- 似ている特徴表現のpositionは高い相関性を持つappearance relation
- それぞれが近いpositionは高い相関性を持つlocation relation
- 様々な姿勢やスケールでも体のパーツを適用的にローカライズできる
- spatial relationマップに基づき、異なるposition間で意味的に対応する特徴を統合することで特徴マップを更新する"aggregation"操作を導入
- CNNの中間特徴マップから、異なるimage position間の相互依存を2タイプ発見するspatial semantic relation mapを生成
- 入力された人物画像の姿勢やスケールに沿って適応的に受容野を決定
- Channel Interaction-and-Aggregation(CIA)
- 異なるチャネルからの特徴量は独立だと仮定するCNNとは違い、チャネル間のsemanticな相互依存を明示的にモデリング
- 全チャネルにわたって視覚的な手がかりから意味的に似た特徴を選択的に統合し、特徴表現を明示
- 両モジュールは計算コストが軽く、モデルの複雑さをわずかに増加させるだけでdeep CNN内の任意の深さに挿入できる
- Spatial Interaction-and-Aggregation(SIA)
- 特に体の姿勢やスケール変動があるCNNについて、特徴表現性能を強化する新しいネットワーク構造であるInteraction-and-Aggregation(IA)
-
批判されている理論は何?
- 体のパーツ検出やmulti-scale featuresを用いる既存手法は、体の姿勢やスケールにおける大きな変動をモデリングするのに限界がある
- 特徴量抽出に用いられているCNNは幾何学的構造が固定であり、幾何学的な変動をモデリングするには限界がある
- 畳み込み層は入力特徴マップを固定の場所にサンプリングし、プーリング層は固定比率で空間解像度を減らす
- 特徴マップの受容野(receptive fields)は矩形と決まっており、non-rigidな体のパーツを異なる姿勢で適応的にはローカライズできない
- 同じCNNの活性化層は同じサイズで、異なるスケールの体のパーツが持つsemanticsをエンコードするのに望ましくない
- 特にかばんのような小さい視覚的手がかりがCNNにおいては高次特徴量で容易に消えてしまう
- 特徴量抽出に用いられているCNNは幾何学的構造が固定であり、幾何学的な変動をモデリングするには限界がある
- 体のパーツ検出やmulti-scale featuresを用いる既存手法は、体の姿勢やスケールにおける大きな変動をモデリングするのに限界がある
-
どういう文脈・理路をたどっている?
- body part misalignmentはre-IDに大きく影響してしまう
- 歩行者は多様な姿勢をとる
- 同じ人物でも不完全な検出により画像間でスケールが異なる
- パーツの検知を活用するには高い精度が必要
- 複数レイヤーで計算される特徴量マップをmulti-scaleで融合
- これら既存手法は手作業でスケールを決めているが、巨大なスケールのvariationには効果的でない
- body part misalignmentはre-IDに大きく影響してしまう
-
対象となるスコープにおいて網羅性と整合性はある?
-
議論はある?
-
次に読むべき論文は?
所感
論文があげる課題として
- 環境
- 背景の乱雑さ
- 明るさ(暗すぎ、逆光などで識別能力が落ちる)
- occlusion(物陰や人同士の重なりにより全身が映らない)
- データ
- sourceとtargetでclassが違う
- 一人当たりのデータ量が少ない
- アノテーション大変
があげられていることが多いです。
これらに対する論文のキーワードとして
- part-level(体のパーツレベルに分割して特徴量をつかむ)
- Attention機構
- disentanglement
- 学習法
- 転移学習
- {自己・弱・半}教師あり学習
- 教師なし学習
- Metric Learning
などが流行ってるように感じました。
直感的には時空間情報を使えれば精度上がりそうだなぁという気持ちになっています。人間が同じタスクをやるなら時空間的な情報(この人はこのくらいの時間によく現れる、視野が重なってないこのカメラ間をこんなに速く移動できるはずはないからこの人はさっきの人とは別人だ、など)を使うと思います。lossに組み込むのが難しそうだったりアノテーション量が増えるなどの問題が大きそうですが...。
時間を見つけることができればICCV2019でも同じことしようかなと企んでいますがやるかは未定です。