初めに
ここ最近ずっとディープラーニングでの画像認識の学習をしておりました。
その成果物/学習過程で作成したipynbファイルをシェア致します。
勿論忘備録/データ格納が主ですが、なかなかどうして初心者にも分かりやすい内容になっているのではないかと思います。
- 気軽にダウンロードして実行できる。
- 実装して確認できるのでイメージを掴みやすい。理論は他を当たって頂ければ...
- 至る所に私のメモがあります。是非ご参考に。(ダークソウル並みにあります)
結果的には実装メインになってしまったので理論は他で補っていだたければと思います。
前提知識
- pythonの基礎。
- ディープラーニングの大雑把な概要。
- 機械学習の簡単な経験やイメージ。
その他諸々前提知識は私の気まぐれで更新します。
畳み込みとDenceの簡単な違い。
共通部分:どちらも同じディープラーニングの手法。
多層パーセプトロン
model.add(Dense(units=num_middle_unit, activation='relu'))
入力層/中間層(隠れそう)/出力層で構成され、それぞれが全結合されている。隠れそうがあるから多層なんです。
基本で単純なディープラーニング。
畳み込み層Convolutional layer ⇒ CNN
model.add(Conv2D(64, (3, 3), activation='relu'))
ある程度の概要はこちらのcolabに記載されております。
他にもRNNやLSTN等様々なディープラーニング手法がある。
参照はこちら。
model.summary()は何を見ているの?
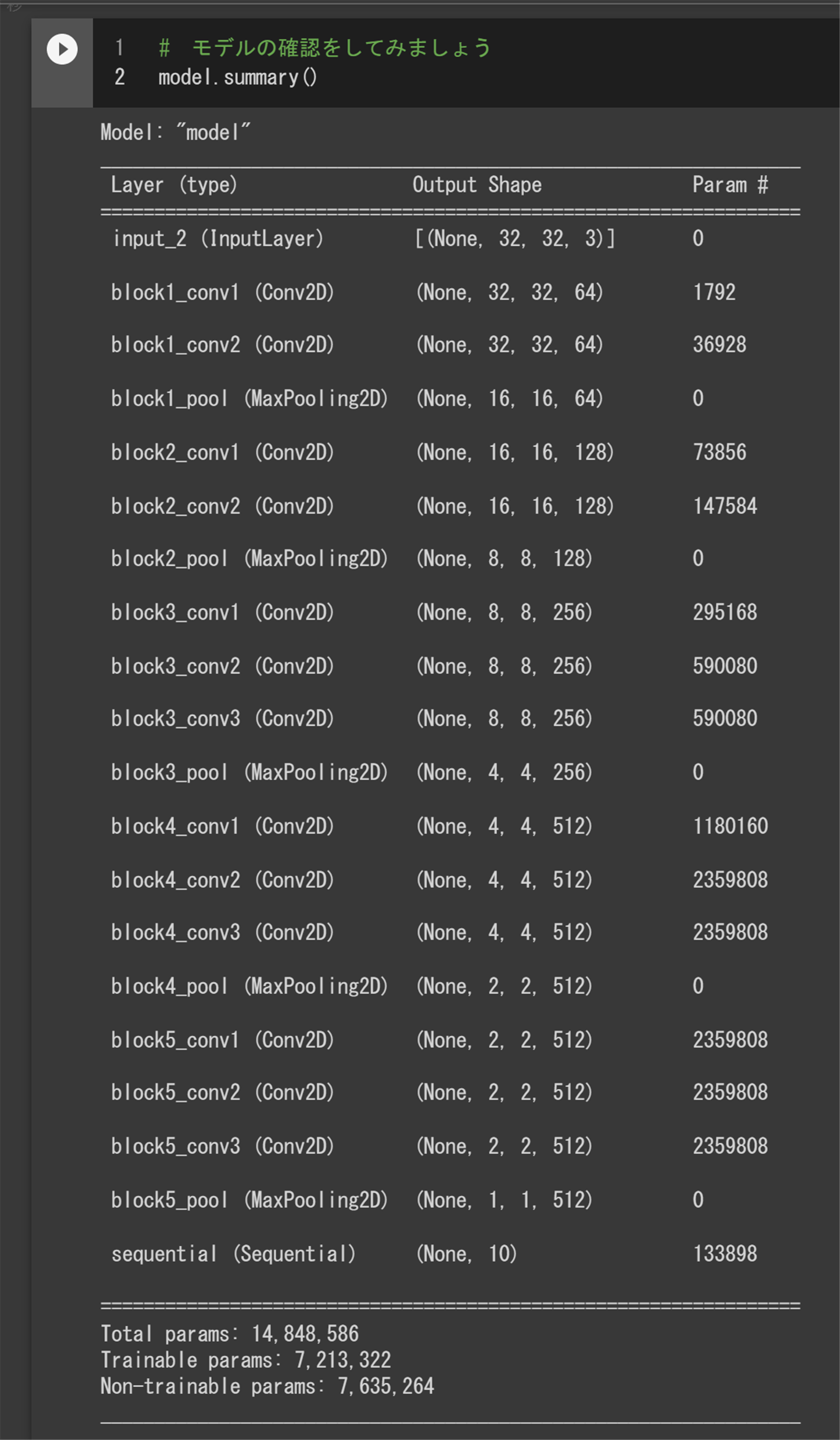

実装
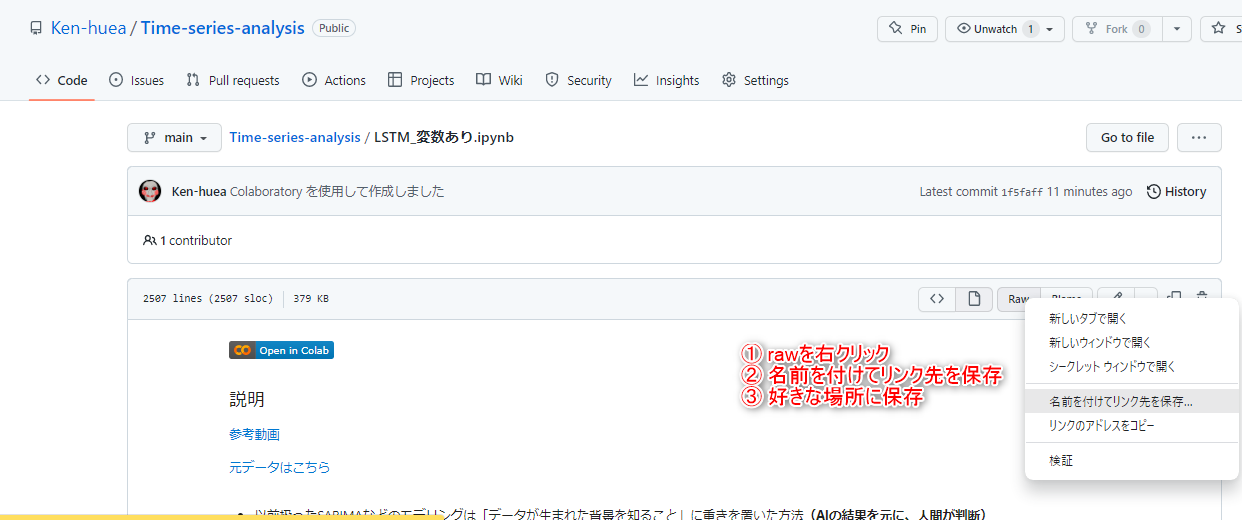
早速実装していきましょう。資料の保存方法はこちら
マージするのはやめてくださいね。
難易度★☆☆☆
ディープラーニング によるmnist分類。⇒ 結構分かりやすくできたと自負しております。最初にイメージを掴んで頂ければ。
例:手書き数字の画像(8)をAIが判断して予測を返す("これは8です")。
CNNにおける分類(mnist) ほぼほぼ上と同じですが、理論の補足や学習モデルが異なっております。2つセットでどうぞ。
CNNにおける分類(cifer10) もう少し精度の向上が必要。
難易度★★☆☆
CNNと転移学習(cifer10)
VGG16というモデルをダウンロードして分類に用います。それとモデルの保存と読込。
自前のモデル読込 自分で保存した学習図済みモデルをcolabにアップロードし予測を行っております。使用教材はmnistの数値予測です。 こうする事により学習の手間やモデル構築の手間が軽減されることが期待できます。 モデルはこちら
難易度★★★☆
CNN(cifer10)の画像増殖⇒データが沢山ある場合は問題ないのですが、少ない場合はどうしましょう?限られた資源の中で最大限の効用を発揮するにはあらゆる工夫をしなければなりません。例えば「画像データが100枚しかないならばその100枚を水増しして1000枚に」。
男女識別 ⇒ 同じ分類ですが、よりイメージが湧きやすいかと。今までの資料を参照すれば決してできないものではないので是非力試しに。 Qiita
男女識別の画像増殖⇒試してみたけど、思ってた以上に成果は伸びず…
batch size 128だとtestデータでのloss: 0.776 testデータでのaccuracy: 0.8015 SGD
手書き分類 こちらもmnistとは基本的な思考は同じですが、より複雑にデータを扱っております。興味があればどうぞ。資料はこちら
こちらは調整中。
画像増殖② 手書き分類kaggleのCNNのみ
その他メモ
前処理について
様々な精度向上テクニック
ディープラーニングのモデル構築の際に使用する精度向上が期待できるハイパーパラメータ。詳しくはこちらの動画の後半
-
ミニバッチ学習
ニューラルネットは、データが増えれば増えるほど、1epoch毎の計算時間が多くなるため、全てのデータを使って、勾配(重み)を更新していては、非効率的である。そのため、全データから、ランダムに任意の個数のデータを抽出し、学習させると、扱うデータ量が減り、計算速度が向上し、限られたリソースで、多くの勾配(重み)を更新できる。 -
重み更新法の変更
今まで使用してきたSGDは確率的勾配降下法と呼ばれるもので、その他にも、「Adam」「RMSprop」「Adagrad」「Adamax」「Nadam」などがある。
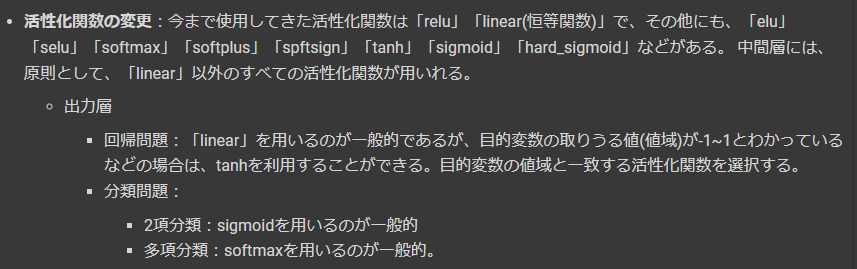
-
ドロップアウト
一定の確率でランダムにニューロンを無視して学習を進めることで、過学習を押さえ、汎化性能の高いモデルを作ることができます。 -
Batch Normalization:バッチ正規化
基本的には、勾配消失・勾配爆発を防ぐための手法であり、これまでは、活性化関数の変更・学習係数を下げる・DropOut層の追加などで対応してきたが、Batch Normalizationは、ミニバッチの各出力を正規化させ、学習過程の安定と学習速度の向上を実現した。

学習(callback関数)についてはこちらを参照
終わりに
正直数学的な前知識も必須だろし気が乗らないなーとは思っていたのですが、
やってみると案外楽しく実装できました。大変だったのはshapeをちゃんとそろえる事。
沢山のエラーを解決しここまでこぎつけましたが、結局いt版多いのはshpaeの問題でしたので。少しでも学習のお役に立てば幸いです。
宜しければ時系列versionもありますのでいかがでしょうか。