初めに
タイトルの通り、日大私文卒が時系列解析を学んでいきます。
今回は実際に実装していこうと思います。
ひとまず理論は理解していなくても確認だけして頂ければ結構です。沢山のデータに触れて実装と理論を双方バランスよく補強できればと思います。
環境
今回は簡単なデータを扱うのでgoogle colabで十分です。
扱うcsvデータはこちら。
前知識
バックナンバー記事の確認又はそれに付随する知識。
pythonやpandasの扱い。ごく簡単な機械学習(数値予測)の実装経験や知識。
RNNとLSTNを扱っているものもあります。
こちら解説が済んでいなかったので、現在作成しております。
バックナンバーはこちら。
更新情報
-
2022/08/28 callback関数を修正致します。
この修正により複数のepochs学習の中でのbest_modelを自動保存できるようになります。 -
2022/09/10 難易度★☆☆☆ の内容を全て修正致しました。
全体的なコードの統一化と分かりやすさ向上、バグ修正です。資料の添付。 -
2022/09/11 全てのcolabの調整を行いました。まだ、細かな微調整は残っておりますが...
-
2022/09/15 気になった部分を追記致しました。学習の助けになれば幸いです。
実装
早速実装していきましょう。保存方法はこちら
マージするのはやめてくださいね。
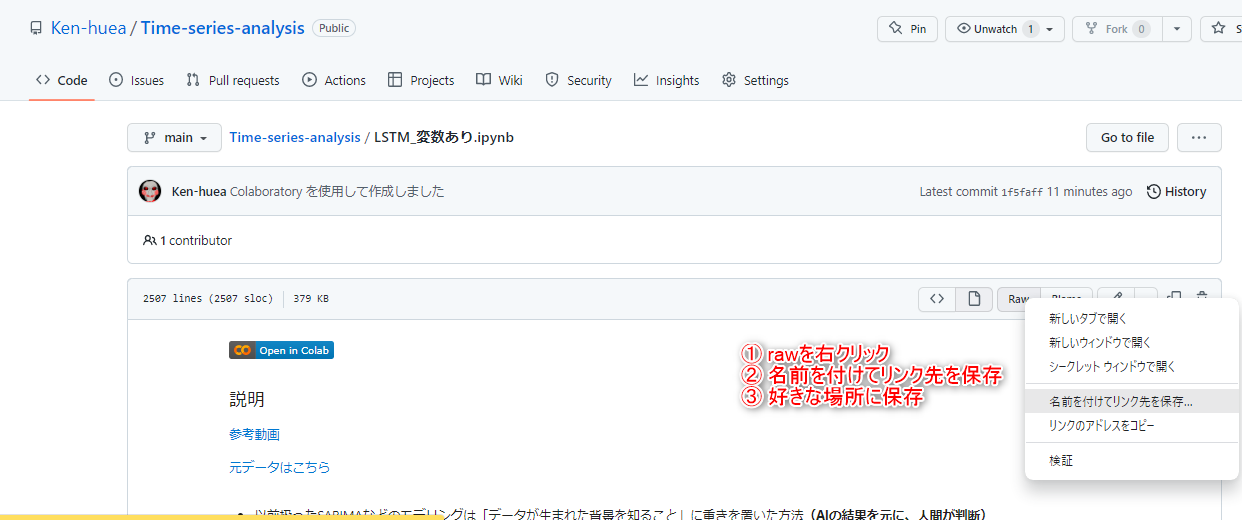
申し訳ございません、csvファイルがないものもありますよね。
まあでもソース元を逐一表示しているつもりなのでそこからgrtして頂ければ。
後、「同じような処理をしているけど、記法が統一されてないじゃないか。」と思いますよね。理由としては
① 記法統一が面倒くさい。
② 同じ処理でも人によってコードが異なるのを楽しんでもらいたい。 からです。
難易度★☆☆☆
- ARモデルの実装 csv資料はこちら
- ARMAモデルの実装 上記のARモデル実装と続けてどうぞ。 csv資料はこちら
- SARIMAモデルによる毎月の車の売上予測 csv資料はこちら
- SARIMAXでの時系列解析(毎月の平均気温予測) csv資料はこちら
難易度★★☆☆
- LSTNによる毎週の気温予測(変数の考慮無し) 資料はこちら
- LSTNによる毎週の気温予測(変数の考慮⇒確認) ⇒違いを確認。callbackを使用。
- LSTN(変数の考慮あり) 3年前の動画を実装してみたものです。確認はできました。シンプルに実装されております。資料csvはこちら
難易度★★★☆
下記二つはほとんど同じです。その2の方がより補足説明が洗練されておりますが、精度としてはその1の方が良いみたいです。
-
LSTNを用いた株価予測 これがLSTNで一番新しいです。個人的には比較的ましな解析だと思います。LSTNの実装のフィーリングを掴みたい方はこれが一番最初でもいいと思います。
新しい分、私の理解も多少なりとも進んでおりますので。 -
LSTNを用いた株価予測その2 こちら調整中です。
終わりに
これからもどんどん更新する予定です。とは言っても現在CNNの勉強中でして...
コメント頂ければ相談や修正したり対処致します。
叩けば叩くほど改善点が見つかります。近いうちにtrainとtestのみでなく、validationデータを用いた分析にも手を出していこうかと。一歩づつ階段を上っていきましょう。
気になった部分。
SARIMAX について。(2022/09/15)
SARIMAXでの平均気温の予測はこのように算出しております。
bestPred = result.predict('2018-12', '2019-12',exog=df_test[["降水量の合計(mm)","日照時間(時間)"]])
予測したい期間:'2018-12', '2019-12'
予測する変数(材料):df_test[["降水量の合計(mm)","日照時間(時間)"]]
df_testの時系列は"2018-12:2019-12"なので、未来の平均気温予測に未来の降水量の合計と日照時間のデータが必要という事です。
違和感を感じますでしょうか?今現在9月として、10月の平均気温の予測をする為に10月の降水量と日照時間のデータを準備せよ。という事です。
未来のデータを準備するなんてできるわけないでしょう?なので実生活にどれほどSARIMAXが使用できるか?というのは頭の片隅に入れておいてください。
(変数の予測データを用いるという方法もありますが、このように工夫が必要です。)
LSTN モデル構築 について。(2022/09/15)
モデル構築は感覚的な要素も多く感じる。
例えば、パラメータを増やしても、必要のない情報まで学習しており、思うように学習が進んでいない。そのような結果も往々としてある。
中間層をただ単純に増やせば良いというものではないという結果に。⇒工夫が返って悪くなる場合も。
学習の補足。callback関数など(2022/09/15)
現在の私はこの学習を良く用います。結構使いがってが良いので意味を説明致します。
from keras import callbacks # コールバック(1epoch終了毎に呼び出される)おなじみのimport
history = model.fit(train_X,
train_Y,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=val_split,
callbacks=[
callbacks.EarlyStopping(monitor='val_loss',patience = pati_time),
callbacks.ModelCheckpoint(filepath = './model/best_model.h5',monitor='val_loss', save_best_only=True)
]
)
validation_split=val_split:学習データのtrainのうち、X%を検証データvalidationとして使用するという事です。これでval_lossを参照して精度を確認頂ければと思います。
EarlyStopping:これ以上精度が上がらない場合に学習を打ち切る事が出来ます。これにより過学習と無駄な時間の経過を防ぐことが来ます。
また最後に学習した結果が一番良い、とは限りませんよね。
monitor='val_loss', save_best_only=Trueによりval_lossがベストなモデルのみが保存されます。 この保存したモデルでfitを行うとベストモデルでpredictする事が出来ます。
ディープラーニングの際にepoc数によるlossやaccuancyの可視化
#acc, val_accのプロット
plt.plot(history.history["loss"], label="loss", ls="-")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
のplt.plot(history.history["loss"], label="loss", ls="-")
history.history について。
historryという変数とhistoryという変数があります。
history属性には、学習過程の損失やメトリクスの値が入っています。
ですので、学習過程を可視化したい場合は、変数名.history["取得したいメトリクス"] で値の取得を行います。
詳細はこちら
modelとhistoryの違いについて。
学習時にはこちらを使用する。
# 基本モデル生成
from keras.models import Sequential # 基本モデルのクラス
model = Sequential()
ここの部分なのだけれど、history には学習した情報が格納されているだけで、
学習したモデルそのものは格納されていない。
Historyオブジェクトではなく、学習したモデルを利用して予測を行う。
# モデルの学習
history = model.fit(
X_train_n,
X_test,
epochs=100 # 学習回数
)
y_predict = np.argmax(model.predict(y_train_n),axis=1)