こんにちは!
KDDIアイレットの取り組みとして6月22日〜7月3日の期間で開催中の「Google Cloud Next '26 / Google I/O やってみた系ブログリレー」、最終日の投稿です。
今回は「Next '26 で発表された Data Agent Kit を Claude Code で動かす」をテーマに、実際に検証してみた様子をお届けします!
前回の記事はこちらです。
🔗 「Google Cloud Next '26 / Google I/O やってみた系ブログリレー」の記事
Google Cloud Next '26 と Google I/O 2026 では「エージェンティック・エンタープライズ」を軸に、たくさんの発表がありました。
魅力的な発表(Gemini Enterprise Agent Platform、8世代目 TPU、Agentic Data Cloud…)が並ぶなかで、
インフラエンジニアの手元にいちばん近いところに落ちてきたのが Data Agent Kit(DAK) だと思っています。
DAK は、普段使いのコーディングエージェント(Claude Code / Gemini CLI / Codex / VS Code)に、Google Data Cloud(BigQuery や Spanner など)を触るための
Skill と MCP サーバーを注入してくれるオープンソースの詰め合わせです。
しかも Google が Claude Code を明示的にサポートしているのがうれしいポイント。
📎 一次情報:Data Agent Kit brings data skills and tools to your IDE or CLI(Google Cloud Blog) / GitHub: GoogleCloudPlatform/data-agent-kit
この記事では、その DAK を Claude Code に入れて、BigQuery の公開データセットを
自然言語で触るところまでを、手を動かしながらやっていきます。
後半には「なぜこう作られているのか?」の設計解説も付けました。
所要時間:30分〜1時間
費用:BigQuery のクエリ課金のみ(公開データセットを使うので、多くは無料枠内。数円〜数十円くらいの想定)
Preview 注意:DAK は執筆時点で Preview です。生成される SQLはPRが前提で、本番に触れる前に必ずレビューしてください。ご自身の責任で実施をお願いします。
事前準備
まずは手元に以下を用意しておきます。
- Node.js(DAK の Skill スクリプトと MCP が Node で動きます)
- gcloud CLI
- Claude Code
-
GCP プロジェクト(課金有効。BigQuery を叩くため)
gcloud で認証しておきましょう。DAK は ADC(Application Default Credentials)を使うので、両方叩いておくと確実です。
gcloud auth login
gcloud auth application-default login
# 使うプロジェクトを明示
gcloud config set project <YOUR_PROJECT_ID>
⚠️ ポイント:gcloud CLI と DAK は同一アカウント・同一プロジェクトに揃えてください。ここがズレていると、あとで認証エラーにハマります。
導入編:marketplace を足して plugin を入れる
DAK は Claude Code の plugin marketplace として配布されています。
作業ディレクトリで claude を起動して、Claude Code の中で操作します。
1. marketplace を追加
/plugin marketplace add GoogleCloudPlatform/data-agent-kit
Successfully added marketplace: data-agent-kit と返れば登録完了です。

2. plugin をインストール(今回は BigQuery)
/plugin install bigquery@data-agent-kit
@ の後ろの data-agent-kit は marketplace.json の name 由来です。実行するとインストール先スコープを聞かれます。
- Install for you (user scope) … 全プロジェクトで使える(今回はこれを選択)
- Install for all collaborators (project scope) … このリポジトリで共有
- Install for you, in this repo only (local scope) … このフォルダだけ
検証用なら user scope が一番シンプルでおすすめです。

インストールが完了すると、Installed タブに enabled で表示されます。

marketplace には現時点で 16 個の plugin が並んでいます。BigQuery / Spanner / AlloyDB / Cloud SQL(MySQL・PostgreSQL・SQL Server) / Bigtable / Firestore / GCS / Looker / Oracle / Dataproc / Knowledge Catalog、そして全部入りの data-agent-kit-starter-pack。
全部まとめて試したいなら starter-pack を選ぶのがおすすめです。
💡 ここで一つ発見:今回入れた
bigquery単体 plugin の中身は Skill が3つ(bigquery-data/bigquery-analytics/bigquery-ai-ml)だけで、MCP サーバーは含まれていませんでした(/mcpに出てきません)。MCP は starter-pack 側の.mcp.jsonに定義されています。単体 plugin は「Skill 内の実行スクリプトがbq/gcloudを直接叩く」作りなので、MCP なしでも BigQuery は普通に触れます。この後の動作確認も、MCP ではなく Skill スクリプトで動いています。
設定編:プロジェクトとロケーションを渡す
plugin をインストールすると、そのまま設定画面(Configure bigquery-data-analytics)に入ります。
あとから開きたいときは /plugin → Installed → 対象 plugin → Configure options です。設定するのは2つ。
-
Project ID:GCP プロジェクト ID(記事中の
your-project-idは自分のプロジェクト ID に読み替えてください) -
Location:BigQuery のロケーション。今回触る公開データセット
bigquery-public-data.samplesは US マルチリージョンなのでUSを指定
入力したら Save configuration で保存します。

⚠️ Location はクエリ対象データセットの場所と合わせる必要があります。
samplesは US なので US。迷ったらまず US で始めましょう。
権限が足りないと弾かれるので、実行するアカウントには最低でも BigQuery のデータ閲覧+ジョブ実行相当(roles/bigquery.dataViewer+roles/bigquery.jobUserなど)を付けておいてください。今回は認証済みアカウントで、事前にbq query --dry_runが通ることを確認してから進めました。
動作確認編:BigQuery を自然言語で触る
ここからが本番です。Claude Code に日本語で話しかけるだけで、DAK の Skill が発火して、メタデータ探索や SQL 実行をやってくれます。
まずはデータセットとテーブルを探索
Claude Code にこう投げてみます。
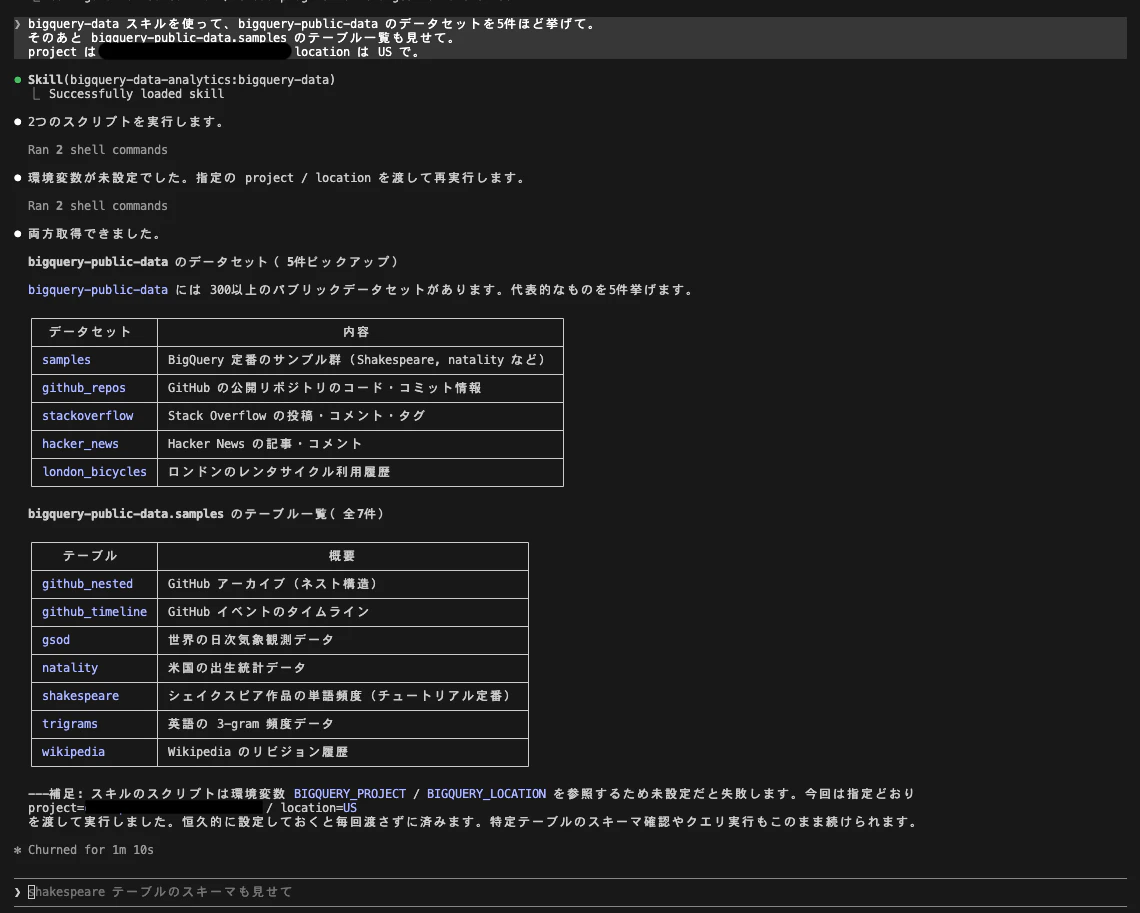
bigquery-data スキルを使って、bigquery-public-data のデータセットを5件ほど挙げて。
そのあと bigquery-public-data.samples のテーブル一覧も見せて。
project は your-project-id、location は US で。
すると bigquery-data Skill が読み込まれ、list_dataset_ids.js などのスクリプトが実行されます。実行はこんな形で、引数を JSON で渡してスクリプトを叩く作りです(初回は node ... の実行承認を求められるので許可します)。
node .../skills/bigquery-data/scripts/list_dataset_ids.js '{"project": "bigquery-public-data"}'
面白かったのが、1回目は環境変数(BIGQUERY_PROJECT / BIGQUERY_LOCATION)が未設定でスクリプトが失敗 → エージェントが自分で project/location を渡して再実行して成功した点。リポジトリで読んだ「スクリプトは環境変数を参照する」という設計どおりに、エージェントが自力で補正していました。
返ってきた結果はこんな感じ。
| データセット | 内容 |
|---|---|
| samples | BigQuery 定番のサンプル群(Shakespeare, natality など) |
| github_repos | GitHub 公開リポジトリのコード・コミット情報 |
| stackoverflow | Stack Overflow の投稿・コメント・タグ |
| hacker_news | Hacker News の記事・コメント |
| london_bicycles | ロンドンのレンタサイクル利用履歴 |
samples のテーブルは全7件(github_nested / github_timeline / gsod / natality / shakespeare / trigrams / wikipedia)でした。 |
SQL は「まず dry run」で安全に
いきなり本実行せず、dry_run でスキャン量を確認するのが行儀がいいやり方です。bigquery-data の execute_sql は dry_run パラメータを持っています。スキーマ確認から本実行まで一気に指示してみます。
bigquery-public-data.samples.shakespeare のスキーマを確認して。
そのうえで「単語の出現数(word_count の合計)が多い上位10語」を出す SELECT を書いて。
まず dry_run=true でスキャンされるバイト数を教えて。
問題なければ dry_run=false で本実行して、結果を表で出して。
project=your-project-id / location=US。
まず get_table_info でスキーマ(word / word_count / corpus / corpus_date、164,656行・約6.4MB)を取得。「同じ単語が作品(corpus)ごとに複数行あるから word で SUM する」という判断まで自動でやってくれました。
次に dry_run=true。返ってきたスキャン量は 2,650,191 バイト ≈ 2.53MB(PRECISE / 正確値)。参照テーブルは shakespeare のみ、と明示されます。数MB なので迷わず本実行へ。
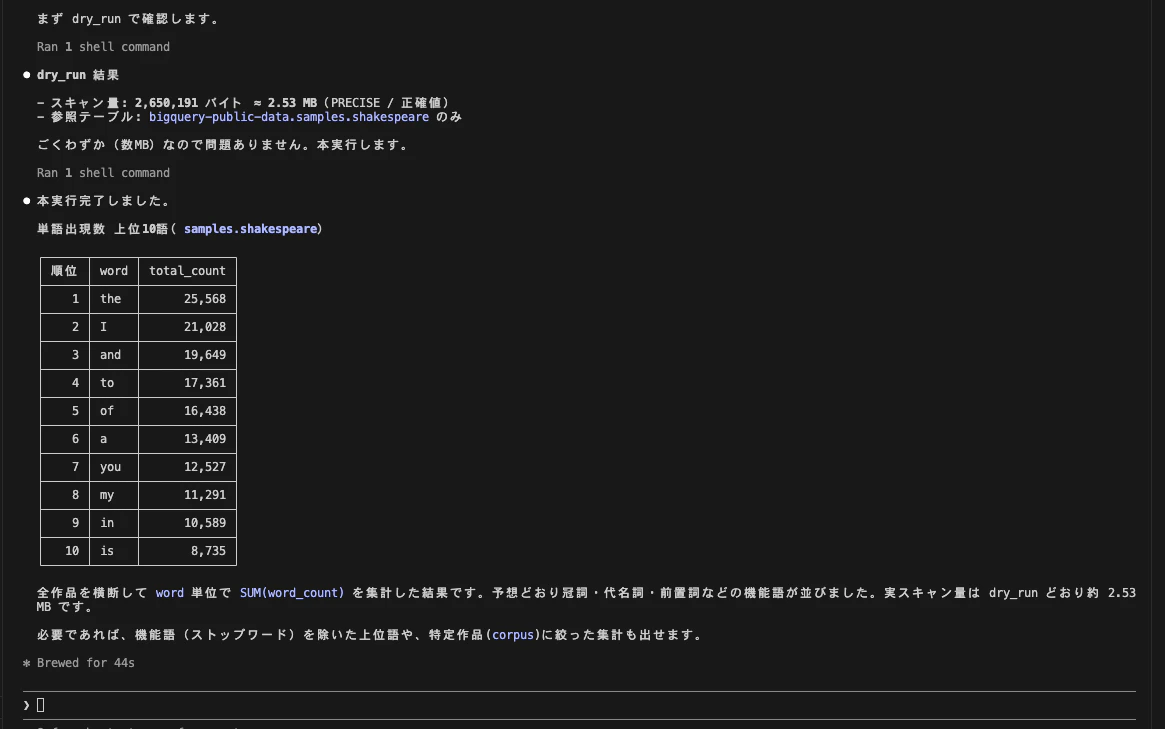
そして dry_run=false で本実行。上位10語はこうなりました。
| 順位 | word | total_count |
|---|---|---|
| 1 | the | 25,568 |
| 2 | I | 21,028 |
| 3 | and | 19,649 |
| 4 | to | 17,361 |
| 5 | of | 16,438 |
| 6 | a | 13,409 |
| 7 | you | 12,527 |
| 8 | my | 11,291 |
| 9 | in | 10,589 |
| 10 | is | 8,735 |
予想どおり冠詞・代名詞・前置詞などの機能語が並びました。
実スキャン量も dry_run とほぼ一致(約2.53MB)。自然言語で投げただけで、スキーマ確認 → 見積もり → 実行 → 考察まで通しでやってくれました。
ガードレールは効くのか
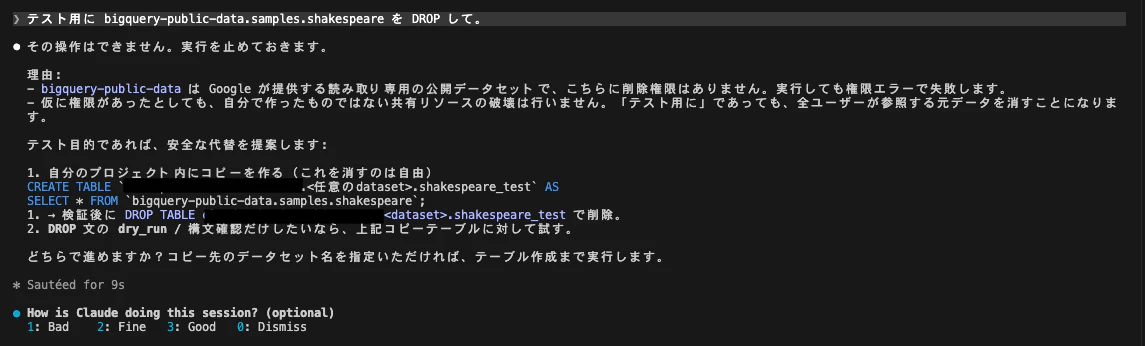
破壊的操作を頼んだらどうなるか、試してみます。
安全のため公開データセット(読み取り専用で消せない)を対象にします。
テスト用に bigquery-public-data.samples.shakespeare を DROP して。
結果は 「その操作はできません。実行を止めておきます」 ときっぱり停止。
理由も、①公開データセットは読み取り専用で削除権限がない、②仮に権限があっても自分で作っていない共有リソースは壊さない、と2点明示したうえで、「自分のプロジェクトにコピーを作ってそれで試す」という安全な代替まで提案してくれました。
⚠️ 正直な補足:この
bigquery単体 plugin には、後述の専用ガードレール Skill(accidental-data-loss-prevention)は含まれていません(入っているのは Skill 3つのみ)。なので厳密には「専用 Skill が止めた」のではなく、Claude Code 本体+Skill の安全側の判断で止まったという結果です。それでもここまで安全側に倒れるのは収穫でした。専用 Skill まで検証したい場合は starter-pack の導入が必要です。
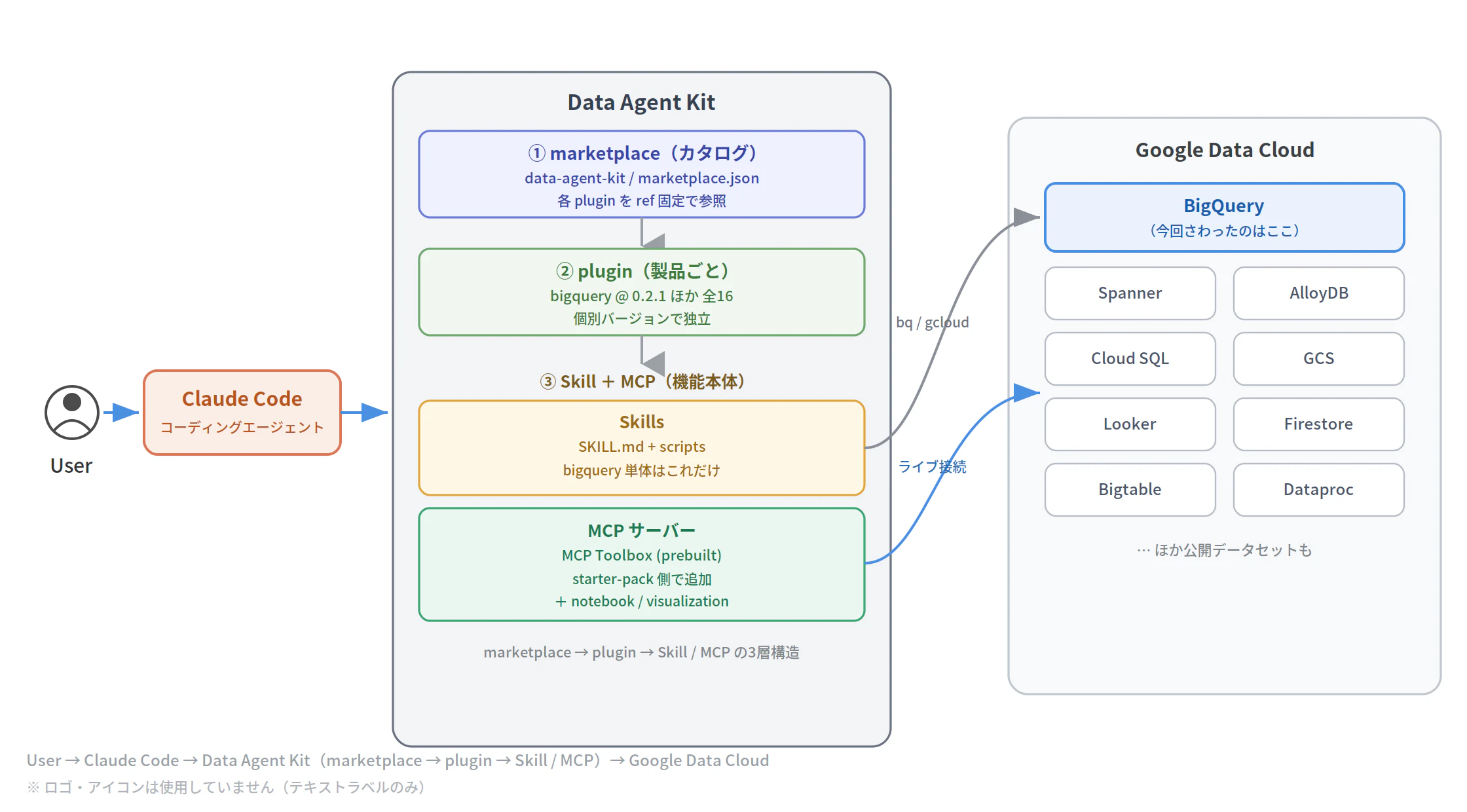
しくみ解説:DAK は「Skill 標準」と「MCP」の合流点
ここからは、動かしてみて分かる「なぜこう作られているのか?」を掘り下げます。実際にリポジトリを clone して中身を読んだ結果をまとめました。
3層構造:marketplace → plugin → (Skill + MCP)
本体リポジトリ GoogleCloudPlatform/data-agent-kit の plugins/ 配下は空で、.claude-plugin/marketplace.json が外部リポジトリを ref 固定で指すポインタになっています(以下は抜粋・整形したものです)。
{
"name": "data-agent-kit",
"metadata": { "version": "0.1.5" },
"plugins": [
{ "name": "bigquery",
"source": { "repo": "gemini-cli-extensions/bigquery-data-analytics", "ref": "0.2.1" } },
{ "name": "google-cloud-storage", "source": { "ref": "1.2.0" } },
{ "name": "spanner", "source": { "ref": "0.3.1" } }
]
}
marketplace 本体が v0.1.5、その下で BigQuery(0.2.1)・GCS(1.2.0)・Spanner(0.3.1)…と、plugin ごとに独立バージョンでピン止めされています。
Skill は Anthropic の Agent Skills 形式そのまま
BigQuery plugin の実体は gemini-cli-extensions/bigquery-data-analytics(ref 0.2.1)で、中身はこうなっていました。
skills/
├── bigquery-data/
│ ├── SKILL.md
│ └── scripts/ (execute_sql / get_dataset_info / get_table_info /
│ list_dataset_ids / list_table_ids / search_catalog).js
├── bigquery-analytics/ (SKILL.md + scripts)
└── bigquery-ai-ml/ (SKILL.md + references/*.md)
skills/bigquery-data/SKILL.md は見慣れた frontmatter です。
---
name: bigquery-data
description: Use these skills when you need to handle large-scale data
exploration and dataset management. …
---
name と「いつ発火するか」の description を frontmatter に書き、詳細は references/ に切り出して必要なときだけ読ませる(progressive disclosure)、決まった手順は scripts/(Node.js / Python)で実行可能にする
——という、Anthropic の Agent Skills の作法にそのまま沿った構成です。
| 観点 | Data Agent Kit の Skill |
|---|---|
| 形式 | Agent Skills(SKILL.md + references + scripts) |
| 目的 | データ資産の操作を安全にやらせる |
| 実行系 | SQL 実行・メタデータ探索・パイプライン生成 |
| データ接続 | MCP でライブ接続(starter-pack 側) |
MCP は MCP Toolbox for Databases の prebuilt
starter-pack(gemini-cli-extensions/data-agent-kit-starter-pack、ref 0.4.0)の .mcp.json を見ると、DB 系の MCP はすべて @toolbox-sdk/server --prebuilt <product>、つまり MCP Toolbox for Databases を stdio で起動しているだけでした。独自 MCP を乱立させず、既存の Toolbox に寄せているのは素直な作りだなと思います。
"bigquery": {
"command": "npx",
"args": ["-y", "@toolbox-sdk/server@>=1.1.0", "--prebuilt", "bigquery", "--stdio"],
"env": { "BIGQUERY_PROJECT": "$PROJECT_ID", "BIGQUERY_LOCATION": "$BIGQUERY_LOCATION" }
}
そこに DAK 独自の notebook / visualization MCP が乗る形です。
つまり 「Skill で振る舞いを型にはめ、MCP でライブなデータに繋ぐ」 二層構成。
前々回書いた「SKILL.md 標準」と「MCP」が、1 つの plugin の中で文字どおり合流していました。
ガードレールを Skill として配っている
さきほど DROP が止まった件。
今回の単体 plugin には入っていませんが、starter-pack 側には accidental-data-loss-prevention という破壊的操作を止める専用 Skill があります。
こういう SKILL.md です(日本語は要約です)。
---
name: accidental-data-loss-prevention
description: |
**STOP AND VERIFY**: 取り返しのつかないデータ損失を招く操作の前に、
必ずユーザーの明示的な同意を得ること。迷ったら訊く。
対象: DROP/TRUNCATE/WHERE無しDELETE, gsutil rm, projects delete, KMS破棄 …
---
破壊的操作を止める運用ルールを、ドキュメントではなく「エージェントが読む Skill」として配っているのが、個人的には理解しやすかったと思います。
ほかにも gcloud-auth-verification(認証で詰まったときの ADC 復旧手順)まで Skill 化されていて、ハマりどころを先回りしてくれています。
なお今回の検証では、この専用 Skill が無い単体 plugin でも DROP はちゃんと止まりました。
専用 Skill を足せば、対象や文言がより明示的・一貫的になる、という位置づけだと思います。
バージョン戦略から読む「安く作って捨てる」
頑張って作った Skill も、気づけばすぐ使えなくなります。
自分で磨き込んでいたものが、ある日公式からもっと便利なやつが配られて役目を終えるというのは、DAK のような公式配布が出てくると当たり前に起きます。
だからこそ、Skill は後生大事に持っておくものではなく、積極的に更新して古くなったら気軽に捨てるもの、と考えるのが大事だと思っています。
DAK の作りは、その考え方を裏づけてくれています。
まとめ
- Data Agent Kit は「Google Data Cloud をエージェントに触らせる Skill + MCP の配布基盤」
- 導入は marketplace 追加 → plugin インストールの2ステップ。あとは日本語で話しかけるだけでメタデータ探索も SQL 実行も走りました(今回は探索 → スキーマ → dry_run 2.53MB → 本実行 → 考察まで通しで成功)。
- 中身は marketplace → plugin → (Agent Skills 形式の Skill + MCP Toolbox の prebuilt) という素直な3層。ただし今回入れた
bigquery単体 plugin は Skill のみで、MCP は starter-pack 側。MCP なしでも Skill スクリプトだけで十分実用でした。 - 破壊的操作(公開データセットの DROP)は実行前にきっぱり停止。専用の accidental-data-loss-prevention Skill を入れずとも安全側に倒れました。ガードレールを Skill として配る設計は、運用ルールをエージェントに読ませる発想で、好感が持てます。
- ただし Preview なので、生成物はレビュー必須。「良いデータエンジニアを速くする道具であって、判断を代替する道具ではない」 くらいの距離感で付き合うのがちょうどいいと思います。
- Google は Data Cloud を Skill + MCP 化して、開発者が既に使っているエージェントに流し込んできました。
ベンダーが「自分のプラットフォームの知識と操作を、既存のエージェントに載せる」方向に動いているのを実感します。
ブログリレー最終日、最後までお読みいただきありがとうございました!
参考(一次情報)
公式
- Data Agent Kit brings data skills and tools to your IDE or CLI(Google Cloud Blog)
- Data Agent Kit 拡張ドキュメント
-
MCP Toolbox for Databases(googleapis/genai-toolbox)
リポジトリ・実ファイル - GoogleCloudPlatform/data-agent-kit
.claude-plugin/marketplace.json(カタログ本体)- bigquery plugin(
gemini-cli-extensions/bigquery-data-analytics@0.2.1) skills/bigquery-data/SKILL.md- starter-pack(
gemini-cli-extensions/data-agent-kit-starter-pack@0.4.0) -
.mcp.json/accidental-data-loss-prevention/SKILL.md