はじめに
dfplyすごい
以前からR, とりわけdplyrユーザーのpandas操作のために記事をまとめてきましたが、dplyr同様の操作は実現できていませんでした。**が、**ついにdfplyという素晴らしいライブラリを見つけましたので記事にまとめます。
関連シリーズ
dplyr使いのためのpandas dfply データ加工編(tidyr)
[dplyr使いのためのpandas dfplyでもJOIN編]
(https://qiita.com/T_Shinomiya/items/cca75a0bd1b0b1663dbf)
[dplyr使いのためのpandas dfply window関数編]
(https://qiita.com/T_Shinomiya/items/327cc073e8079eabe242)
以前の記事はコチラ
dplyr使いのためのpandas 基礎編
dplyr使いのためのpandas スライスsliceとインデックスindex編
dplyr使いのためのpandas マルチカラム操作編
dplyr? ってかたはコチラ(敬愛するmatsuou1氏の記事)
[dplyrを使いこなす!基礎編]
(https://qiita.com/matsuou1/items/e995da273e3108e2338e)
dfplyのなにがすごい?
dplyrの機能がほぼそのまま実装されているところです。
では、例を見ていきましょう。
事前準備、例データ
例データはseabornライブラリに付属しているみんな大好きtitanicを使います。
import pandas as pd
import numpy as np
from dfply import * #dfply読み込み
import seaborn as sns
titanic = sns.load_dataset('titanic') #titanic読み込み
# titanic.head(10)
select 列選択
titanic >> select(X.survived, X.pclass, X.sex, 3, ['fare']) >> head(5)
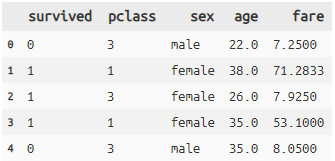
- 変数の指定形式は「X.」を付ける、「列番号」「リスト表記[]」のどれかです。X.形式が一番使いやすいかと。
- magritterは、「%>%」ではなく「>>」です。
drop
列を除くdropもあります。
titanic >> select(~X.survived, ~X.pclass, ~X.sex) >> head(5)
or
titanic >> drop(X.survived, X.pclass, X.sex) >> head(5)

列選択関数
他にも列を選択する関数が用意されています。
| 関数 | 構文 | 説明 |
|---|---|---|
| starts_with | select(starts_with('p')) | 列名がpではじまる列を取得 |
| end_with | select(ends_with('s')) | 列名がsでおわる列を取得 |
| contains | select(contains('e')) | 列名にeを含む列を取得 |
| ~ | select(~contains('e')) | 列名にeを含まない列を取得 |
| columns_between | select(columns_between(X.sex, X.fare)) | sex~fareの間の列を取得 |
| columns_to | select(columns_to(X.age, inclusive=True)) | ageより前の列を取得 |
| columns_from | select(columns_from(X.age)) | age以降の列を取得 |
filter_by 行選択
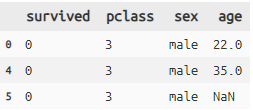
titanic >> filter_by(X.sex == 'male') >> #sexがmaleのレコードを抽出
select(X.survived, X.pclass, X.sex, X.age) >> head(3)
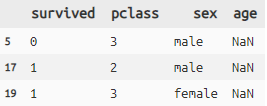
null値(NoneやNan)の行選択
titanic >> filter_by(X.age.isnull()) >> #.isnull()で
select(X.survived, X.pclass, X.sex, X.age) >> head(3)
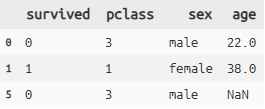
index_slice指定でも可(row_slice)
titanic >> row_slice([0,1,5]) >> select(X.survived, X.pclass, X.sex, X.age)
mutate 列追加
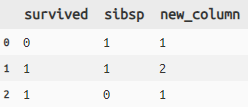
# mutate
titanic >> mutate(new_column = X.survived + X. sibsp) >> #new_columnを作成
select(X.survived, X.sibsp, X.new_column) >> head(3)
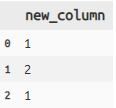
transmute 作成した列のみにselect
titanic >> transmute(new_column = X.survived + X. sibsp) >> head(5)
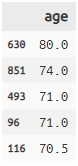
arrange 並び替え
titanic >> arrange(X.age, ascending = False) >> select(X.age) >> head(3)
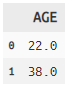
rename 列名変更
titanic >> rename(AGE = X.age) >> select(X.AGE) >>head(2)
distinct 重複レコード除去
titanic >> distinct(X.sex) >> select(X.survived, X.pclass, X.sex)
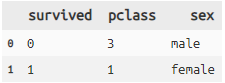
group_by 集約
titanic >> group_by(X.sex) >>
mutate(age_lead = lead(X.age), age_lag = lag(X.age)) >>
head(3) >> select(X.sex, X.age, X.age_lead, X.age_lag)
# lead()とlag()は一つずらした値をとるwindow関数です。
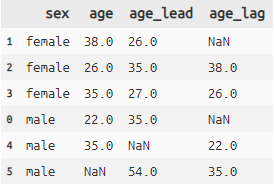
summarise 要約
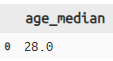
titanic >> summarise(age_median = X.age.median())
summarise_each 指定した列に複数の関数を適用して要約
titanic >> group_by(X.sex) >> summarise_each([np.mean, np.var], X.age, 4, 'pclass')

データ加工
case_when, if_else
dplyrのベクトル変換関数も使えます。
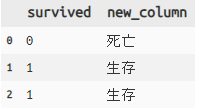
# case_when
titanic >> mutate(new_column = case_when([X.survived ==0, '死亡'],[X.survived==1, '生存'])) >>
select(X.survived, X.new_column) >> head(3)
# if_else
titanic >> mutate(new_column = if_else(X.survived ==0, '死亡', '生存')) >>
select(X.survived, X.new_column) >> head(3)
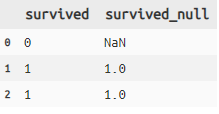
na_if
条件に合致した要素をNaNに変換します
# na_if
titanic >> mutate(survived_null = na_if(X.survived,0)) >>
select(X.survived, X.survived_null) >> head(3)
補足:日付型 ⇄ 文字型の変換
こちらにまとめました
pandasデータフレームの日付型⇄文字型変換とdfply使用時のメモ
まとめ
R,dplyrユーザーがPython,pandasに移行する際の強力なライブラリになりそうです。
まだまだdplyr同様の機能があり、紹介できておりませんので、またの機会に。
これからはdfplyでデータ操作にラクラク励めそうです。