はじめに
dplyr同様の操作を可能にするdfplyライブラリのまとめ、今回はデータの加工編です。
なんと、tidyrの関数も使えます!
基本操作は下記記事をご参照ください。
dplyr使いのためのpandas dfplyすごい編
事前準備、例データ
例データはseabornライブラリに付属しているみんな大好きtitanicと簡単に作成したデータを使います。
Python:事前準備
import pandas as pd
import numpy as np
from dfply import * #dfply読み込み
import seaborn as sns
titanic = sns.load_dataset('titanic') #titanic読み込み
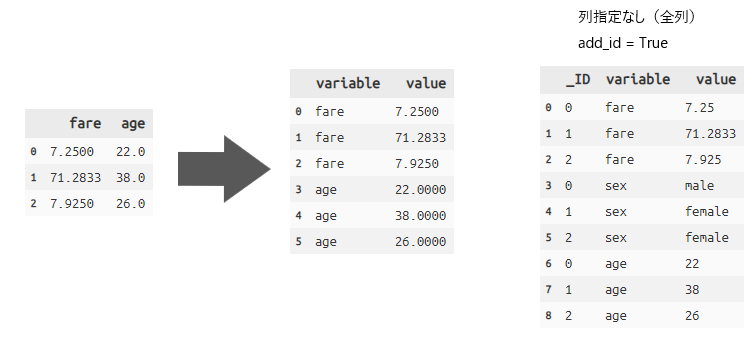
gather long形式データへ変換
long形式のデータへ変換する関数です。
Python:dfply-gather
# gather(variable=新しいKey列名, 新しいデータ列名, 列指定)
titanic_long = titanic >> head(3) >> select(X.fare, X.age) >>
gather('variable', 'value', [X.fare, X.age])
# 列指定をしないと全列で変換が行われる
titanic_long = titanic >> head(3) >> select(X.fare, X.sex, X.age) >>
gather('variable', 'value', add_id=True) # _ID列を付与
spread wide形式データへ変換する
Python:dfply-spread
# _ID列をユニークKey, variableとvalueをwide形式データに変換
titanic_wide = titanic_long >> spread(X.variable, X.value, convert=True) #convertで型を自動変換
# 型タイプを見る
print(titanic_wide.dtypes)
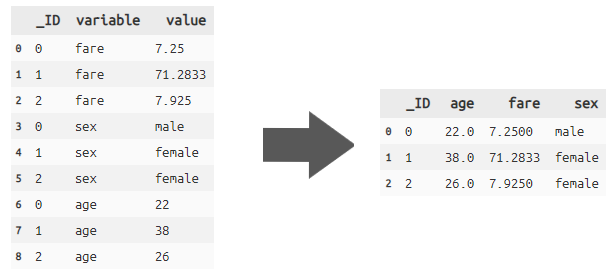
↓ データの型(convert=Falseやデフォルトだとすべてobject型になる)
_ID int32
age float64
fare float64
sex object
dtype: object
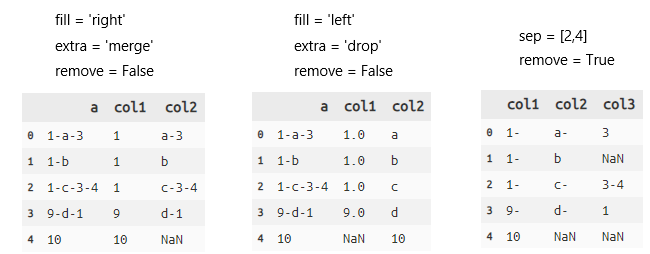
separate 列分割
Python:dfply-separate
# 検証用データ
d = pd.DataFrame(["1-a-3" ,"1-b", "1-c-3-4", "9-d-1","10"], columns=["a"])
# separate
d >> separate(X.a, ['col1', 'col2'], sep="-", fill='right', extra='merge', remove=False, convert=True)
# sep:区切り記号、何文字目かで区切るかも指定できる(図参照)
# fill:left or right 分けれなかったときの左右詰設定
# extra:drop or merge 分けきれなかったデータを落とすか、くっつけておくか
# remove:分割前列を除く
unite 列結合
Python:dfply-unite
# 検証用データ
d = pd.DataFrame({"a": ["1", "2", "3"], "b": ["a", "b", "c"], "c": [True, False, np.nan]})
# unite
d >> unite('united', X.a, 'b', 2, sep='*', remove=True, na_action='maintain')
#X.a, 'b', 2はいずれも列を指定するもの
#sep:結合時に挟む文字
#remove:結合材料列を除く
#na_action:maintainはNaNを無視しない、ignoreは無視、as_stringで文字と認識して結合

まとめ
上記の機能(tidyr)もRデータフレーム加工ではよく使用される関数で、それも実装されているのは非常に助かりますね。dplyr使いにとってなんとありがたいライブラリなのでしょうか。