はじめに
pandasデータフレームをRのdplyr同様に操作可能にするdfplyライブラリについてまとめるシリーズです。
dfplyについてはこちらをご参照ください。
dplyr使いのためのpandas dfplyすごい編
Window関数?
SQLではおなじみですが、主に集計や分析に使われる関数ですね。
実行結果がgroup_byしたときのように集約されるわけではなく、入力データに対しての実行結果が戻されます。そのためmutateと一緒に使うことが多いと思います。
dplyrでのwindow関数は、matsuou1氏がまとめているこちらも参考にして頂けるとわかりやすいです。
事前準備、例データ
今回も、みんな大好きtitanicを使用します。
import pandas as pd
import numpy as np
from dfply import * #dfply読み込み
import seaborn as sns
titanic = sns.load_dataset('titanic') #titanic読み込み
ランキング
選択列の値に対して順位番号をつけていく関数です。
dfplyでは、以下の関数が実装されているようです。
| 関数 | 説明 |
|---|---|
| row_number | 選択列の値に対して順番付け(デフォルトは昇順) |
| min_rank | 選択列の値に対して順番付け(同値は同番号、その場合次番号は飛ぶ) |
| dense_rank | 選択列の値に対して順番つけ(同値は同番号、その場合次番号は飛ばない) |
| percent_rank | min_rankのスケールを0~1に変換したもの |
titanic >> arrange(X.age) >> select(X.age) >> mutate(
row_number=row_number(X.age, ascending=True),
min_rank=min_rank(X.age, ascending=True),
dense_rank=dense_rank(X.age, ascending=True),
percent_rank=percent_rank(X.age, ascending=True)) >> head(6)
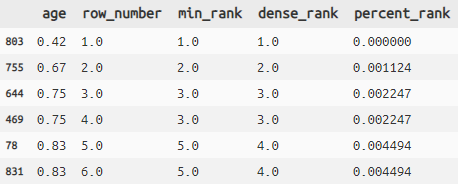
- 各順位番号はnull(None, NaN)を対象には含みません。
- ascending = Trueは省略可
オフセット
選択列の前後のレコードの値を取得できます。
| 関数 | 説明 |
|---|---|
| lead | 選択列の値に対して前レコードの値をとる |
| lag | 選択列の値に対して後レコードの値をとる |
# lag lead
titanic >> group_by(X.sex) >> mutate(
lead1=lead(X.age, i=1),
lead2=lead(X.age, i=2),
lag1=lag(X.age, i=1),
lag2=lag(X.age, i=2)) >> \
head(3) >> select(X.sex, X.age, X.lead1, X.lead2, X.lag1, X.lag2)
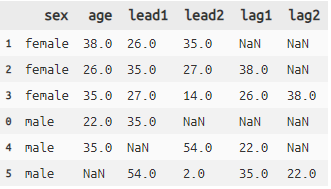
- group_byを使うとそのグループ内でのオフセットも可能です(dplyrと一緒です)
- i = は何レコード分ずらすかの指定です(省略可)
- dplyrではnull値を埋める数値も指定できましたが、dfplyではできないようです
累積
選択した列に対して1レコードずつ累積で関数を処理していきます。例で見た方が理解が早いですね。
累積1:cumsum, cummin, cummax, cummean, cumprod
| 関数 | 説明 |
|---|---|
| cumsum | 対象レコードまでの累積和(足し算) |
| cummin | 対象レコードまでの最小値 |
| cummax | 対象レコードまでの最大値 |
| cummean | 対象レコードまでの平均値 |
| cumprod | 対象レコードまでの積 |
titanic >> select(X.age) >> mutate(
cumsum=cumsum(X.age),
cummin=cummin(X.age),
cummax=cummax(X.age),
cummean=cummean(X.age),
cumprod=cumprod(X.age)) >> head(7)
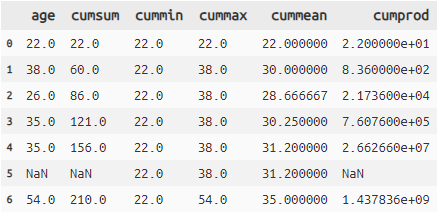
- 例えばcummaxはageの6レコード目に54がでてきて累積値で一番高い数値になったため、54が返されています
累積2:cumany, cumall
cumany,cumallは少々ややこしいです(使用機会も少ないと思いますが)。
選択列がTrue or Falseのbool型のときに判定を行う関数です。これも例を見た方が理解が早いですね。
# bool型のデータを作成
test = pd.DataFrame({'bools':[True,False,False,True,False]})
# cumany, cumall
test >> mutate(cumany=cumany(X.bools), cumall=cumall(X.bools))
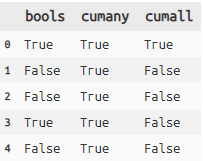
- cumanyは選択列にTrueが表れた時点で以降すべてTrueと判定します
- cumallは選択列にFalseが表れた時点で以降すべてをFalseと判定します
その他
between
選択した列の値が、指定した値の範囲内にあるかないかを判定しbool型を返します。
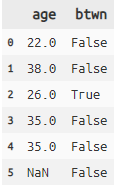
# ageが25~30の範囲内にあるかどうか判定
titanic >> mutate(age_btwn=between(X.age, 25, 30, inclusive=True)) >> \
select(X.age, X.age_btwn) >> head(6)
まとめ
window関数もdplyr同様しっかり再現されてますね。
dfplyやっぱりすごいです。