記事の概要
本記事は、「参考記事を見ながらTitanicコンペに参加でき、内容もある程度理解できる」程度のKaggle初心者を対象とした、Kaggle脱初心者のための「Titanicコンペの先」講座となります。
(2020/1/14追記)なんと、本記事がQiitaアドベントカレンダー2019 プレゼント企画「日経 xTECH ビジネスAI賞」に選ばれました!
受賞を機に、より多くのデータサイエンティスト志望の方にステップアップのきっかけを与えられればと願うばかりです。
なお、露骨な宣伝になってしまいますが、私の現在の就職先である株式会社THIRDでは、経験有無に拘らずデータサイエンティスト職を随時募集しておりますので、もし本記事を読んでご興味いただけた方がいらっしゃったら是非ともお声掛けください。
筆者について
私は、SIerにて基幹システムに関する仕事をしていた一方で、AIについて2019年4月より独学での勉強を開始し、夏ごろAIベンチャー企業への転職を決定し、現在はデータサイエンティストとして日々を過ごしております。
転職を決めた時点では、Kaggleに本格的に取り組んでいたわけではなく、Titanicコンペをやってみただけの人でしたが、その後転職先の方から「一緒にKaggleをやってみないか」と声をかけていただき、
最終的には5人チームとして、メンバーからアドバイスを頂きつつ**「Predicting Molecular Properties」というコンペに約2ヶ月間参加し、銀メダル(上位1.1%)を獲得しました**。
Kaggle初参加で(すごいチームにいれてもらって)銀メダル(Top 1.1%)を手に入れた感想【Predicting Molecular Properties】
また、10~11月頃に行われた**「NFL Big Data Bowl」**コンペについては、終盤までほぼソロでの参加で銀メダル圏内(PublicLB30位前後)に到達しました1。
特に私は、今年の夏までAIとは全く無関係の仕事をしてきており、AIを独学で学んだ後即Kaggleに参加し始めたような人間であるため、今後のKaggle新規参加者の躓きやすいポイントを経験してきたと思っています。
この記事を書こうと思ったきっかけ
この記事を読んでいただいている皆様ならご存知の通り、Kaggleはデータ分析の能力を競うコンペティションサイトであり、
昨今市場価値が上昇し続けているデータサイエンティストという職を未経験・独学で目指すに当たり、データ分析のスキルを学習するための、非常に有効な手段の一つです。
近年、コンペティションサイトの戦績を生かしたポテンシャル採用は社会に徐々に浸透し始めており2、
Kaggleの戦績も、データサイエンティストとしての基礎能力を示す良い指標として各企業に認知されてきています。
特に未経験でデータサイエンティストへの転職を考える人にとって、Kaggleのコンペ参加経験あるいはメダルの獲得実績は、学習意欲やポテンシャルを示すための非常に重要なアピールポイントの一つとなりつつあります。
しかし、Kaggleにおいて**「Titanicコンペ参加」レベルから、「メダル対象コンペ参加」「メダルの獲得」レベルとの間には、非常に大きなハードルがあると思っています。**
特に、参加してみたはいいものの、何をすればいいかわからない、どんなスケジュール・工程を踏んでいけばいいのかわからない(データサイエンスにおける開発プロセスは独特であり、普通のソフトウェア開発のプロセスとははっきり異なります)、となり、結果として良くわからないままフェードアウトしてしまう人もいるのではないかと思います。
私はその理由を、Kaggle入門者向けの「Titanicコンペにとりあえず参加してみよう!」的な記事はたくさんあるのに、「Titanicコンペの先」のことを書いた脱初心者のための記事が少ないからではないか、と考えました。
これが、私がこの記事を書こうと思ったきっかけとなります。
したがって本記事には、私がKaggleに参加してから半年間の集大成として、参戦したコンペの経験談をベースに、銅メダル以上獲得3を目標としたできるだけ実践的な内容を網羅したつもりです。
また、コードの書き方やコード例については記事上には一切記載しませんので、必要であればググったり参考記事で確認していただければと思います。
本記事をきっかけに「AI未経験だけど、AIをやってみたい」と思っている方々がより積極的にKaggleに参加できるようになり、少しでもAI人材への転職の足掛かりになれば、幸いです。
Step 0 - 機械学習・ディープラーニングの勉強
少なくとも次のTitanicコンペの参考記事に書かれた内容がある程度理解できるレベルになる程度には、知識が求められます。参考までに、私は以下の方法を実践しました。
- CodecademyのMachine Learningコースで、Python/Numpy/Scipy/Pandas/Matplotlib/MLなどを習得
- DL4USの教材を読みながらGoogle Colab上で動かし、ディープラーニングのアルゴリズムを体験
- ディープラーニングG検定を受験し、AIに関する「一般常識」の学習
ただし、この手のいわゆる「ボトムアップ(積み上げ)的お勉強」ははっきりいってつまらないので、極力早い段階で区切りをつけて先へ進むのが吉です。
間違ってもライブラリの一通りの機能を網羅的に身に付けてから先に進めようとは思わない方が良いです。挫折しかねません。Kaggleを始めれば自然と身に付きます4。
Step 0.5 - Titanicコンペに参加
Kaggle参戦に向けての第一歩は、「Titanicコンペ」の参加です。
これについては、参考になる記事が多く存在するので、是非そちらを参考にしながらチャレンジしてみることをお勧めします。
- Kaggle事始め
- KaggleチュートリアルTitanicで上位3%以内に入るには。(0.82297)
- Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~
- [Kaggle]0から本当に機械学習を理解するために学ぶべきこと~一流のデータサイエンティストを例に~
また、以下の書籍はKaggleにおける技法が一通り紹介されている超が付くレベルの良書であり、はっきり言ってこの記事を読むよりこの本を読む方がメダル獲得に近づけると思うので、今後Kaggleを続けていく意志のある方は是非ご購入をお勧めします。
Step 1 - コンペの選択
Titanicコンペで一通りのことを学んだら、いよいよメダル対象コンペに参加していきます。
何はともあれ、まずは参加するコンペを決めましょう。
とりあえずコンペ一覧のページを見ながら、以下の条件を満たすコンペを選択することをお勧めします。
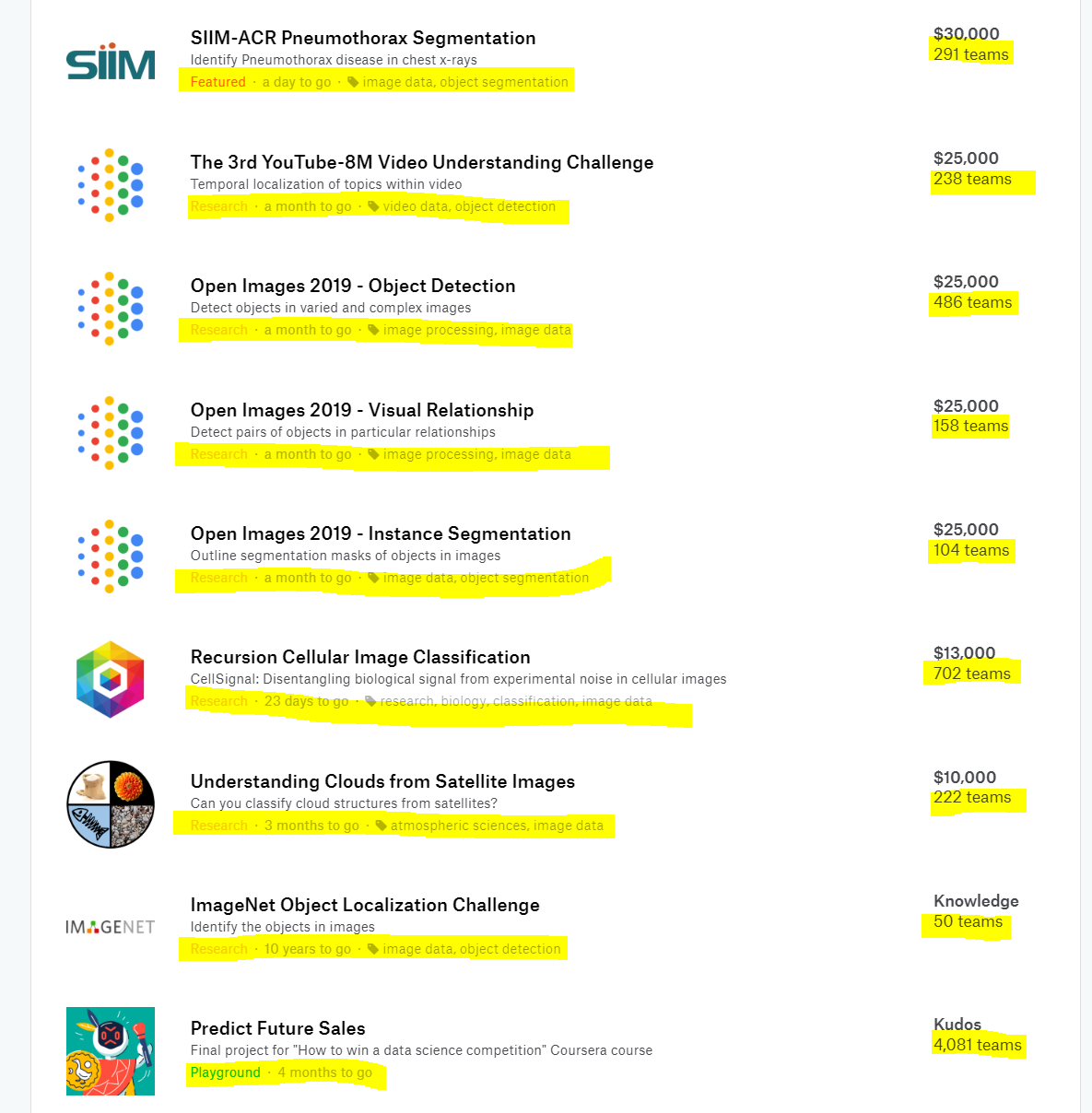
- コンペの種類を表す色付きの文字
⇒ メダル対象コンペである、「Featured」または「Research」 - コンペの残り日数
⇒ 始まったばかりのコンペが望ましいが、基本的に残り1か月もあれば十分 - コンペの属性を表すタグ情報
⇒ **「tabular data」**タグが付いたコンペが望ましい(GPU資源が豊富に使えるならば「image data」コンペの方が上位を狙いやすい) - コンペの参加チーム数
⇒ 参加チーム数が多いコンペの方が良い(好みの問題)
1.は言わずもがな、メダルが欲しければ「Featured」または「Research」コンペを選択しましょう。
この2つに難易度的な差はありませんが、「Featured」は商業寄り、「Research」は研究寄りという違いがあります。
2.については正直あまり重要視する必要はなく、残り期間が1か月程あれば十分だと思います。
後述するようにKaggleには「公開カーネル5」「ディスカッション」が存在し、
コンペが進むにつれてより高いスコア、より有用な情報を含むものが増えていくので、早くから取り組んでいたという時間的アドバンテージは思ったより大きくないです。
コンペ開始直後から取り組んでいた人を後から参加した人が抜かすということは往々にしてあり得ます。
3.については、通常「image data」コンペはGPU計算資源への依存度が高く、
GPUマシンが手元に無い、あるいはお金を使いたくないのであれば避けた方が無難です。
(逆に、GPUマシンをたくさん取り揃えられそうな場合は「image data」コンペの方がメダルが取りやすい)。
一応KaggleではGPUカーネルを借りることができますが、実行時間に週30時間という厳しい制約があり、これだけでモデルの学習や試行錯誤を行うことは困難です。
4.については、チーム数が多い方が公開カーネルやディスカッションでの情報交換が活発になり、情報収集が容易になります。
ただし、必ずしもチーム数が多い方がメダルが狙いやすいというわけではありません。
もちろん、自分の得意分野や学生時代の専攻と合致するようなコンペがあるならば、知識面でのアドバンテージが生かせるそちらを優先すべきでしょう。
逆に、全く分からなさそうな分野のコンペであっても、臆せずチャレンジしてみましょう。公開カーネルやディスカッションにて、ドメイン知識を持たない人に向けた解説はたくさん作られているので、必ずしも専門書や論文を熟読したりする必要はありません。
Step 2 - スケジュールの全体像の把握
私がKaggleの本格的なコンペに初めて参加して思ったことは、「スケジュールをどう組めばよいのかわからない」「どんな作業フェーズがあるのかわからない」でした。
ということで、私が考える「コンペのスケジュール全体像」を紹介いたします(これが正しいという保証はありませんし、データサイエンスにおける作業フェーズというのは本来境界があいまいなもので、現実的に画像のように明確に区切られることはまずありませんが、イメージとして知っているだけでも先を見据えた行動ができると思います)。
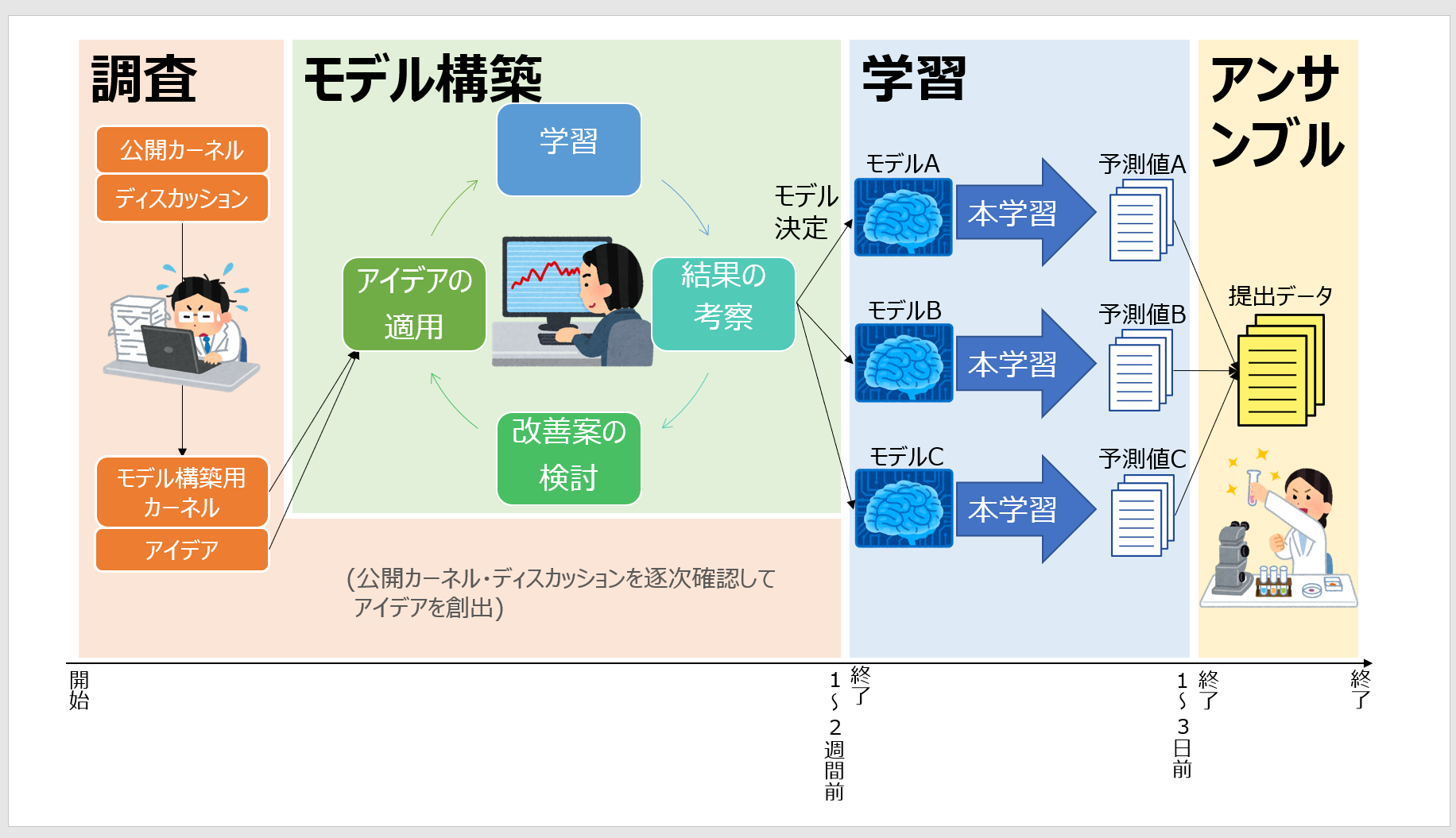
各フェーズの詳細については次Step以外で解説しますが、ここでも簡単に概要を説明をしておきます。
各フェーズの概要
調査フェーズ
調査フェーズでは、公開カーネルやディスカッション、必要なら関連する論文などから情報収集を行います。
公開カーネルのうち、シンプルで使えそうなモデルをピックアップし、次のモデル構築フェーズの元とします。
また、得られた情報をもとに、モデルの改善アイデアをアウトプットしていきます。
調査はコンペの最初だけやればいいというわけではなく、常に公開カーネルやディスカッションの状況をキャッチアップし、有用な情報があれば逐一自身のモデルに反映していくことが求められます。
モデル構築フェーズ
「モデル構築」と名付けていますが、特徴量作成やパラメータチューニング含め、スコア向上を目指して反復的に実験を行う作業を全て含めた総称としてこう呼んでいます。
調査をしていく中で「こういう特徴量を追加しよう」「モデルの複雑さ(パラメータ)を変えてみよう」「バリデーションの方法を変えてみよう」と思ったら、実際にやってみて学習を行い、結果を考察して次の実装につなげる…ということをひたすら繰り返します。
疎かにされがちですが、このフェーズにおいて最初にやるべきことは、バリデーション方法の確立です。
バリデーション方法の確立ができないと、実験によってスコアが上がったのか下がったのか、判断することが困難になり、実験自体まともにできなくなってしまうためです。
バリデーション手法が確立出来たら、特徴量作成・選択や、パラメータチューニングを行い、実験を行いながらスコアの上がる方向にモデルを改善していきます。
学習フェーズ
特徴量やモデルの方向性、ハイパーパラメータ等が固まったら、最終サブミットの為のアンサンブル用モデル作成に向けた本学習を行います。
特にGPUコンペの場合、学習量の差がスコアの優劣に直結する場合があるため、学習フェーズを長めにとる必要があります。
逆に、テーブルコンペで学習量をあまり必要としない場合は、学習フェーズ自体不要なことも多いです。
アンサンブルフェーズ
最後にアンサンブルフェーズでは、今までに作ったモデルの予測値を総合することで、最終サブミットの作成を行います。
アンサンブルという概念はデータサイエンスを一旦学べば当たり前の概念ですが、初学者からするとかなりとっつきづらい概念です。
スコアが100点の予測値と、50点の予測値を混ぜたら、普通はその間の75点くらいの予測値になりそう、と直感的に思いますが、実際には110点や120点の予測値ができる可能性がありうるのです(だから、個々のモデルのスコアはいまいちでも、いろんな種類のモデルが用意できた人は、最終サブミットのスコアを伸ばしやすいということになる)。
データのバイアスとバリアンスという概念を理解することが、アンサンブルを理解する鍵となります。
Step 3 - 調査フェーズ
上の画像では一括りになっていますが、調査フェーズは以下の2つのサブフェーズを持っています。
- コンペ参加直後に、コンペの概要を知り、ベースとなるモデルを選定するフェーズ(以後、**「コンペ参加直後調査」**と呼ぶ)
- コンペ参加中に、継続的に公開カーネル/ディスカッションの情報をキャッチアップし、有用な情報を取得するフェーズ(以後、**「コンペ参加中調査」**と呼ぶ)
なお、公開カーネルやディスカッションは全て英語で書かれているので、基本的には英語が読めることがアドバンテージになりますが、翻訳を使っても十分情報収集は可能だと思うので、英語が苦手であっても臆せず参加してほしいです。
コンペ参加直後調査
探索的データ解析(EDA)
まずは、コンペに参加することで、訓練データをダウンロードできるようになっているはずなので、とりあえずダウンロードしてみて、csvファイルならExcelでも使って眺めてみましょう。
コンペの「Data」ページには、大抵各カラムの概要が載っているので、それを見ながらデータの意味を理解していくとよいと思います。
このとき、目的変数(予測したい変数)が何なのかは必ず確認しておきましょう。
しかし、ただデータを眺めているだけでは何も始まりません。なぜなら、それだけでは各特徴量の分布や相関といった統計量が何も見えてこないからです(と言うものの、逆に統計量を見ているだけでは個々のデータの特徴が分からず、重要なヒントを見落とすこともあるので、データを眺めるという行為も重要だったりします)。
そこで、**探索的データ解析(EDA)**を行います。
EDAというのは、データに対して様々な統計量の抽出・視覚化を行って、データ内容を理解していく行為です。
本来(ビジネス等においては)、EDAは自分の手で行うものですが、Kaggleにおいては、コンペ開始直後から多くの有志の方によりEDAを行ったカーネルが公開されていくので、
それを一つずつ読んでいくだけでもデータに関してかなりの理解が得られます。
下の画像は、EDAを行っている公開カーネルのグラフの例となります。
EDAを行っている公開カーネルにはこのようなグラフがたくさんあり、整然と並んだグラフをただ眺めていくだけでも、コンペに関する知見をどんどん増やすことができます。
ですが当然他人の手によるEDAには誤りがあったり、重要なヒントを見落としていたりということはあり得る話ですので、常に批判的な目で見ることが求められ、必要であれば自分でEDAを行うことになります。
**自分でEDAをする際は、是非他人のEDAを参考してみてください。**Pandasの扱い方からデータの抽出方法や種々のグラフの描画方法など、見ているだけで勉強になります。
評価指標の理解
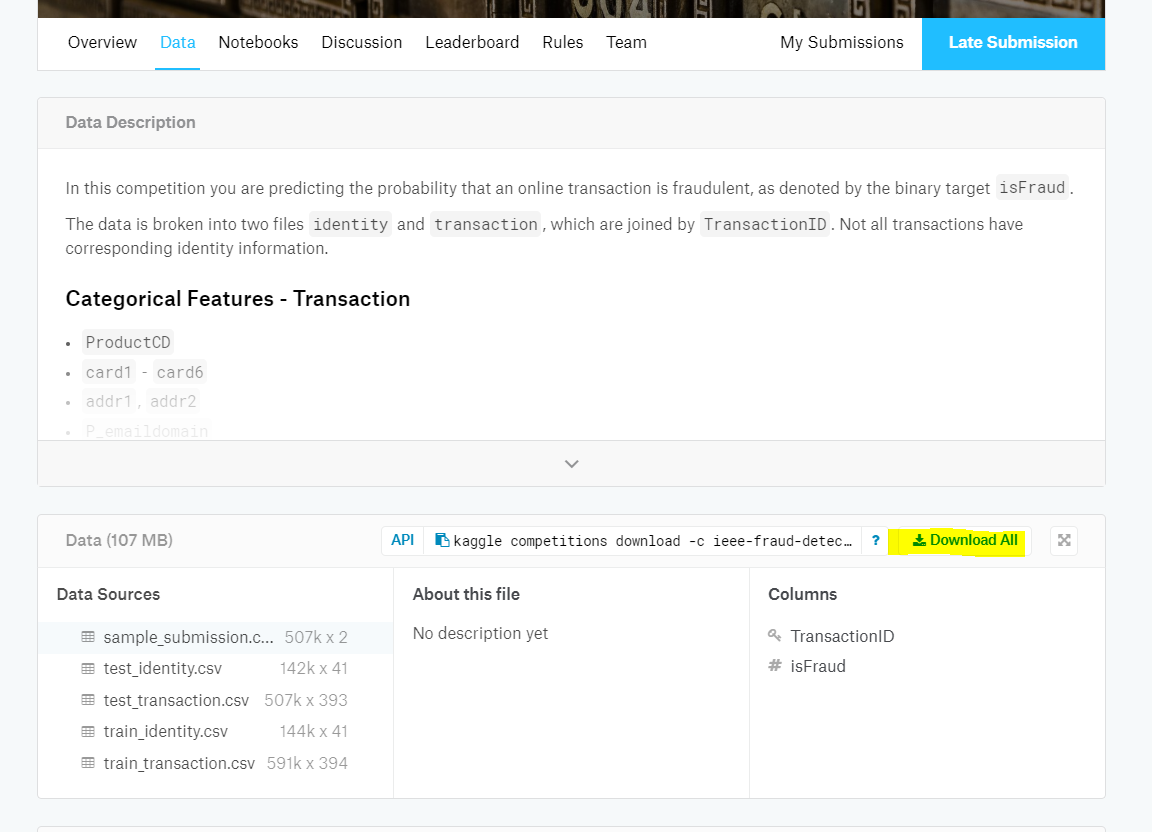
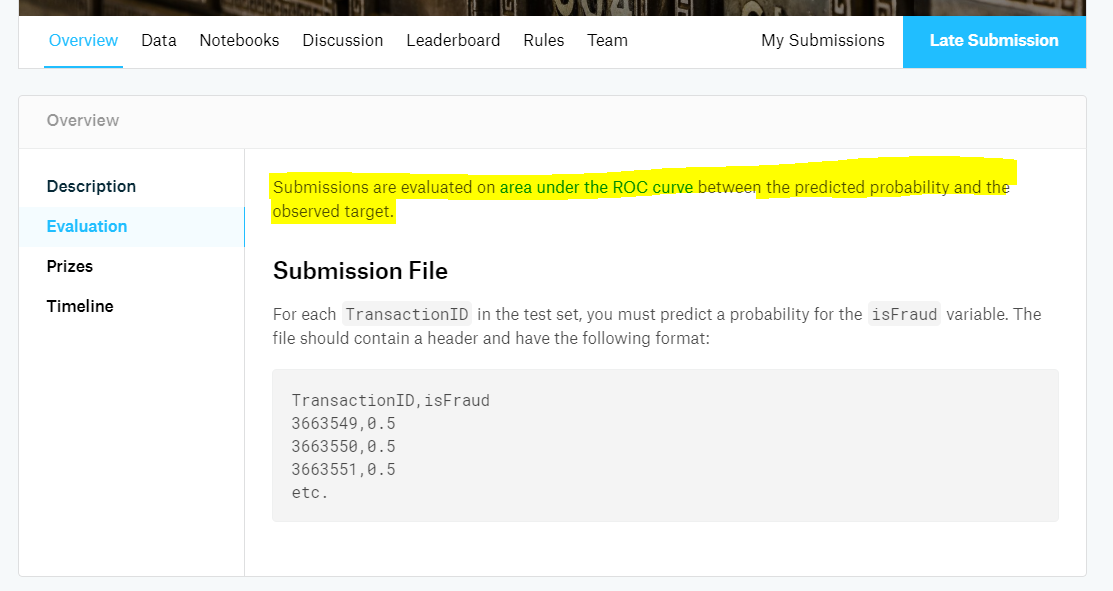
次に理解しておく必要があるのは、**評価指標6**が何であるかということです。
評価指標に関する説明は、コンペの「OverView」→「Evaluation」ページに記載されています。
例えば「IEEE-CIS Fraud Detection」の場合は以下の通り、「AUC(Area under an ROC curve)」7が評価指標です。
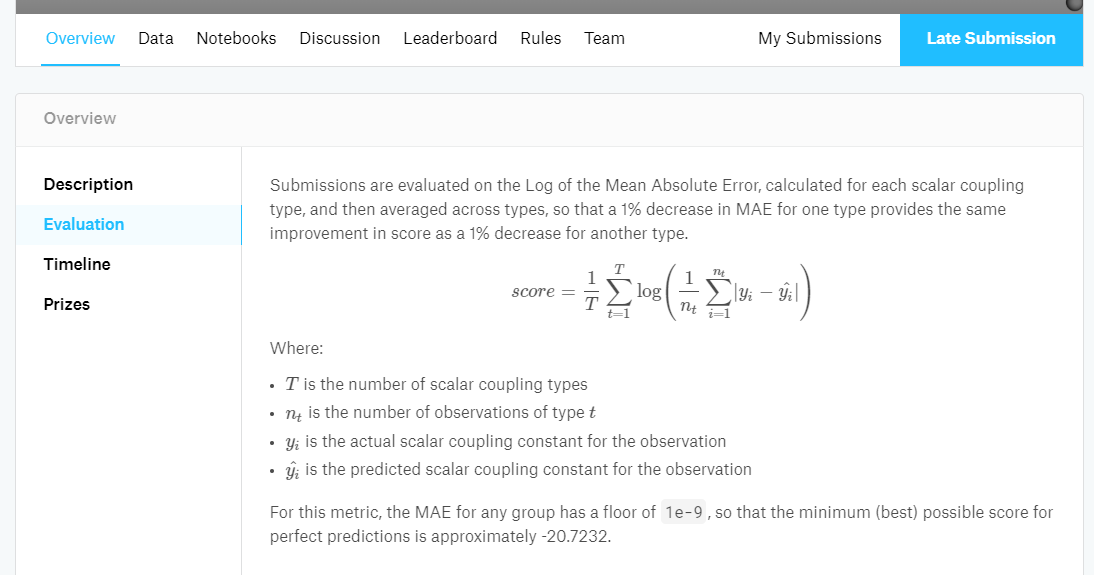
一方で、例えば「Predicting Molecular Properties」の場合は以下のような数式で書かれており、一目で理解するのは少々難しくなっています。一言で表すなら、「Log MAEのクラス平均」でしょうか。
実際は、公開カーネルから拾ってくるモデルの中に評価指標が既に目的関数として搭載されているので、あまり意識しなくてもコンペへの参加はできると思います。
ですが、評価関数そのものに重要なヒントが隠されている場合もあり8、知っておくことは重要です。
コンペの目的の理解
おそらく、ここまで読み込んでようやく、そのコンペの目的・趣旨が理解できるようになり、ドメイン知識も含めて足りない情報が何なのか分かってくるようになります。
例えば「NFL Big Data Bowl」のコンペの趣旨を要約すると、以下のようになります。
NFLの試合における、『ランプレー』における『ハンドオフ』時点での選手の位置・速度等の情報から、『ゲイン(ヤード数)』を予測せよ。
括弧でくくったキーワードは、アメフトを知らなければ分からないものなので、当然アメフトのルールを理解することから始まります。私はNFLの試合の解説動画を視聴することから始めました。もちろん、公開カーネルやディスカッションで解説してくれていることもあります。
一方、「Predicting Molecular Properties」のコンペの趣旨を要約すると、以下のようになります。
分子の構造を表す座標データから、特定の二原子間における『スカラーカップリング定数』を予測せよ。
このような完全な専門用語の場合、キーワードをググってもあまり情報が得られないこともあります。公開カーネルやディスカッションでドメイン知識を解説してくれている人がいるはずなので、探してみるとよいでしょう。
なお、「Discussion」ページ(下画像)の中で一番上の方にある色付きのスレッドは、コンペ開催者が作成したものであり、そのコンペにおける重要な補足情報や注意書きが含まれている可能性があるため、このタイミングで一読しておくことをお勧めします。
ベースモデルの種類の決定
ある程度コンペの内容が把握できた段階で、いよいよこれからモデル構築を行うベースとなるカーネル(ベースモデル)を決めます。
…その前に、Kaggleにおいて現在主流である、LightGBMとニューラルネットワーク、どちらを選択するかを決めることになります。
基本的には、最初に扱うモデルとしてはLightGBMをお勧めします。
LightGBM
勾配ブースティング決定木と呼ばれる種類のモデルであり、「tabular data」コンペでは最もよく使われてるモデルです。
学習速度・精度ともに安定感があり、特別な理由がない限りこれを選ぶのが無難です。
類似モデルでよく使われるものにXGBoostやCatBoostがありますが、少なくとも初めのうちは使う必要はありません。
LightGBMの概要については、例えば以下の記事が詳しいです。
LightGBM ハンズオン - もう一つのGradient Boostingライブラリ
ニューラルネットワーク
ニューラルネットワークは、LightGBMと比べてモデルの自由度が高いことが最大の強みです。
層の深さや隠れ層の次元を自由に変えることができ、時系列データや自然言語、グラフ構造など、LightGBMでは単純に処理できないデータを扱える様々なモデルが存在します。
とはいえ、それらを適切に選択・チューニングすることは難しく、LightGBMと比較して上級者向けであるため、公開カーネルを一瞥してLightGBMが主流のようであれば、触る必要はないと思います9。
ベースモデルの選定
さて、モデルの種類が決まったら、実際にベースモデルを公開カーネルの中から探しましょう。
モデルの選択基準は、主に以下の4つが考えられます。
- モデルのシンプルさ
- モデルのPublicLBスコア
- モデルの可読性
- (ニューラルネットワークの場合のみ)モデルが使用しているディープラーニングのフレームワーク
このうち、1.と2.は相反します。なぜなら、スコアが高いカーネルほど、人の手で特徴量作成などの試行錯誤が行われており、シンプルでなくなるからです。
できるだけスコアの高い公開カーネルに手を出したくなるのは山々ですが、私としてはできるだけシンプルなカーネルから始めるのが正しい在り方だと思っています。
シンプルなカーネルというのは要するに、必要最低限のデータクレンジングのみが行われており、余計な特徴量の追加等の試行錯誤が行われていないということです。
他人の手によって行われた試行錯誤は、すべて正しいやり方で行われているとは限りません。スコア向上に寄与しなかったり、逆効果になっているものもあり得ます。
そのような試行錯誤は、まずシンプルなカーネルでちゃんとバリデーション手法を確立した上で、一つずつ自分の手で試してみるべきです10。
なお、3.と4.については好みの問題なので割愛します。ニューラルネットワークに初めて触るのであれば、Kerasが最も分かりやすいと思います。
コンペ参加中調査
コンペ参加中の情報収集に関して、公開カーネル/ディスカッションでvoteが集まっているものは、当然常にチェックすべきなのですが、
それ以外にも、以下のようなところから情報が得られる可能性があります。
Public LeaderBoardの順位とその変化
Public LeaderBoardの順位やその変化には、今のコンペの状況を間接的に表れていると思っています。
例えば、以下のような場合が考えられます。
- 上位者のスコアが抜きんでて高く、スコアの崖がある。あるいは、スコアが低めだったユーザーが突然上位に跳ね上がってくることがある。
- 何らかの「気付き」、あるいは「魔法の特徴量」が存在し、それが上位と下位を分けている可能性がある11。
- 突然、ユーザーのスコアが軒並み上がり始めた。
- 公開カーネルやディスカッションにて新たな情報が出回った可能性がある。不運な場合はリーク(外部の情報によってテストデータの正解が分かってしまうこと)が発生していることも12。
過去のコンペの上位者の手法
似たような性質のコンペが過去に開催されている場合、その上位者が採っていた手法がうまくはまる可能性があります。
これはどちらかと言えばKaggle歴の長い人ほどアドバンテージになるため、初参加で考慮するのは難しいですが、ディスカッションで過去の類似のコンペを教えてくれている人がいる場合もあるので、その場合はチェックしておくとよいでしょう。
Step 4 - モデル構築フェーズ
Kaggleにおけるメインとなるフェーズであり、上位を目指す上で最も重要なフェーズです。
多くのアイデアを考え、試行錯誤し、スコアを向上させることが、メダル獲得のために求められます。
基本的にはPDCAサイクルのように実験を反復試行しながら、その結果のスコア上がり下がりを見て、よりスコアが高くなる方向に特徴量を追加したり、パラメータを変えたりしていくことになります。
バリデーション方法の確立
実験を始める前に最初にやらなければならないことがあります。それがバリデーションの方法、すなわち実験結果(スコア)を正しく考察できるようにする基盤を確立することです。
Kaggleにおける「スコア」
ここで、Kaggleにおいて頻繁に使われる「CVスコア」「LBスコア」の意味についておさらいしておきます。
- CVスコア
- Cross Validation(交差検証)スコアの略で、LeaderBoardへ提出することなく、訓練データのバリデーションによって計算されたスコアのこと。
- LBスコア
- LeaderBoardスコアの略で、すなわちLeaderBoardへのサブミットの値を元に計算されたスコアのこと。LBスコアはさらにPublic/Privateの2種類に分かれる。
- PublicLBとは、コンペ中に閲覧できるPublic LeaderBoardのスコアのこと。
- PrivateLBとは、コンペ終了後に閲覧でき、最終順位の決定に用いられるPrivate LeaderBoardのスコアのこと。
- LeaderBoardスコアの略で、すなわちLeaderBoardへのサブミットの値を元に計算されたスコアのこと。LBスコアはさらにPublic/Privateの2種類に分かれる。
ここで、一つ当たり前の事実を確認しておきます。我々が最適化しなければならないスコアは、PrivateLBです。すなわち、CVスコアやPublicLBスコアが上がっても、それ自体何の意味もありません。
CVスコアやPublicLBスコアの上昇が意味を持つためには、それらがPrivateLBと相関していることがはっきりしなければなりません。
ですが、PrivateLBの値はコンペ終了後まで全く公開されないため、相関度を確認することができません。
そのため通常、PublicLBとPrivateLBの間に相関が存在するという仮定13を設けることになります。
バリデーションの目的
さて、上記の仮定を設けたことにより、PublicLBスコアが実験結果の考察に使えそうな気がしてきますが、PublicLBを実験結果の考察に使うのはあまり良くありません14。その理由は主に以下の2点です。
- Public LeaderBoardへのサブミットには、1日5回までという制約があるため
- PublicLBスコア計算用のテストデータでは、母数が少なくスコアのブレが大きいことがあるため
特に1.の理由が重要です。例えば、あるパラメータを色々変えてみてスコアを比較する…なんてやろうと思った場合、5回しかスコアが確認できないというのはあまりに少なすぎることがすぐに分かるでしょう。
2.はコンペにも拠りますが、基本的にPublicLB用テストデータの母数は訓練データの母数より少ないことが多いです。交差検証であればすべての訓練データをテストに使えるので、その分スコアのバリアンス(分散・ブレ)を抑えることができます。
スコアのブレをできるだけ抑えることはとても重要です。スコアのブレが大きいと、仮にスコアが上がったように見えても、本当にスコアが上がったのか、たまたま上振れで上がったのか判断できないからです。これでは、暗闇の中を手探りで進むような状況になってしまいます。PublicLBよりも高い精度でスコアを見積もれるCVは、まさに暗闇を照らす光であり、道しるべとなるはずです15。
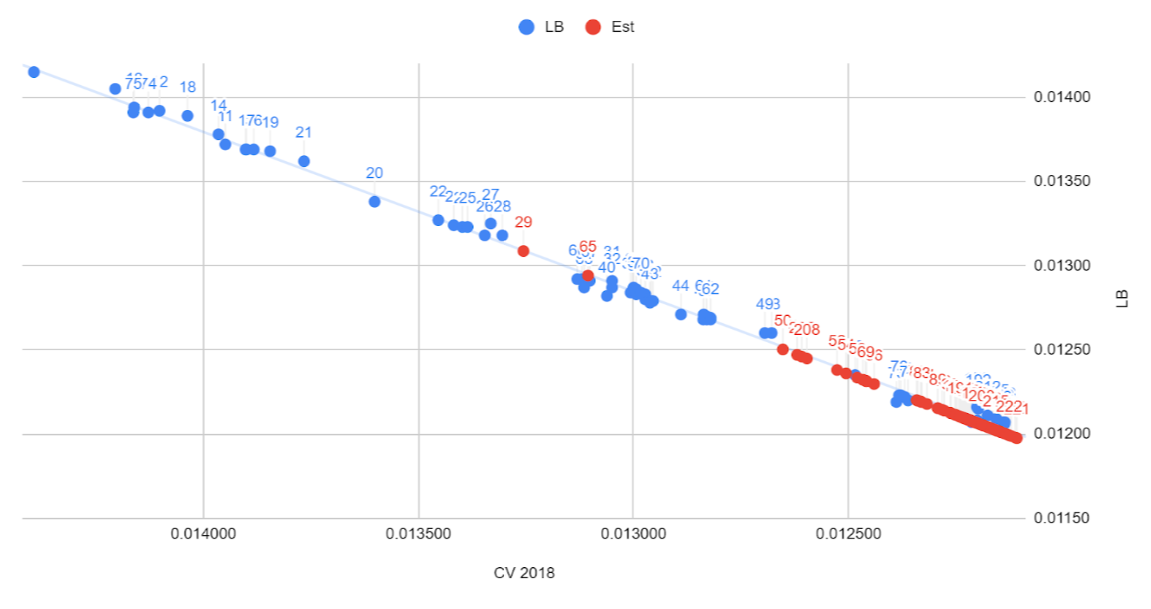
下の画像は、「NFL Big Data Bowl」のPublicLB1位のチームにより公開された、CVスコアとLBスコアの相関図です。
このチームはきわめて精度の高いバリデーション手法を確立できており、CVスコアとLBスコアに高い相関ができていたおかげで、試行錯誤を正確かつ高速に行うことができていた様子が伺えます。
バリデーション手法の一例
Kaggleのコンペでは、何も考えずに単純な交差検証(KFold)を行うだけでは、不十分であることが多いです(少なくとも私が参加したコンペについては)。
この段階でデータに対してどれだけ考察し、適切なバリデーションを構築できるかが後の順位にかかわってきます。
実際どんなバリデーションが良いのかはコンペによって全く違ってくるので、一概には言えないのですが、以下では参考として今まで使ってきたバリデーション手法の一例を挙げたいと思います。
もっとバリデーション手法を詳しく知りたい方は、以下の記事が参考になります。
- Visualizing cross-validation behavior in scikit-learn
- validationの切り方いろいろ(sklearnの関数まとめ)【kaggle Advent Calendar 4日目】
- 【翻訳】scikit-learn 0.18 User Guide 3.1. クロスバリデーション:推定器の成果を評価する
GroupKFold
GroupKFoldは、汎用性が高くよく使われるバリデーション手法の一つです。
簡単に言うと、同じグループに属するデータが、学習データまたはバリデーションデータの双方に含まれないように、バリデーションを行うというものです。
使用する理由は様々ですが、ここでは**「他の(同じグループに属するような)学習データからのリークの防止」**のためのGroupKFoldの使い方を紹介します16。
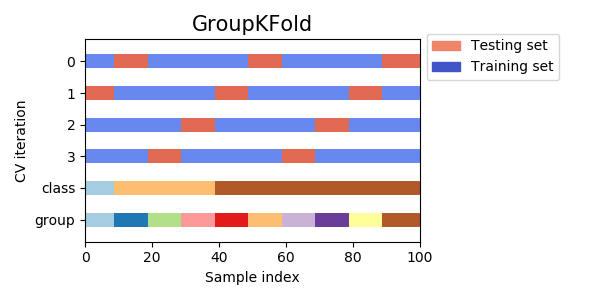
例えば以下のようなデータに対してバリデーションセットを分割することを考えてみます(クレジットカードのトランザクションデータのようなものを想定)。
| ID | ユーザーID | 利用日 | 利用金額 |
|---|---|---|---|
| 1 | Aさん | 1/1 | 60000円 |
| 2 | Aさん | 1/2 | 85000円 |
| 3 | Aさん | 1/3 | 92000円 |
| 4 | Bさん | 1/1 | 980円 |
| 5 | Bさん | 1/2 | 850円 |
| 6 | Bさん | 1/3 | 1000円 |
| 7 | Cさん | 1/1 | ?円 |
| 8 | Cさん | 1/2 | ?円 |
| 9 | Cさん | 1/3 | ?円 |
ID1~6が訓練データ、ID7~9がテストデータであり、訓練データとテストデータがユーザーIDによってはっきり分かれていることとします。
このデータを見ると、Aさんは毎日の利用金額が多く、Bさんは少ないことが見て取れます。
したがって、仮に通常のKFoldを使用し、Aさんのデータが学習データ・バリデーションデータの双方に含まれてしまうと、モデルは「Aさんは1/1,1/2で利用金額が高めだから、1/3も高めだろう」のような予測をしてしまいます。
ですが、テストデータであるCさんのデータについては、すべての日の金額がマスキングされているため、Cさんがお金をたくさん使う人なのか、そうでないのかは、データから読み取ることはできません。
バリデーション時に余計な情報(LBスコア計算時には参照することのできない情報)をモデルに与えていることになり、バリデーションスコアが不当に高くなってしまうことになります。
なので、ユーザーIDでGroupKFoldをすることにより、「そのユーザーがお金をたくさん使う人なのか」という余計な情報をモデルに与える(リークする)ことなく、LBスコア計算時と同じ条件でバリデーションスコアが計算できる、ということです。
時系列データを扱うコンペにおけるバリデーション手法
時系列データを扱う場合、特に過去のデータから未来のデータを予測するコンペの場合、バリデーションが特に難しくなります。
上記で使用したGroupKFoldを使うことでうまくいく場合や、「過去から未来を予測する」という条件を保ちながらバリデーションできるTimeSeriesSplitという手法がよく用いられますが、単純にこれらを使ってもうまくいかないことも多いです。
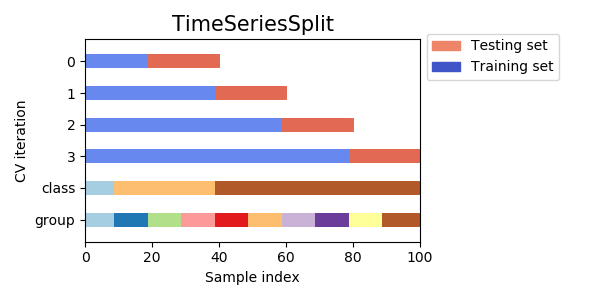
時系列データ(未来予測)でのバリデーションが特に難しい理由は、**「直近の未来の予測と、遠い未来の予測では、スコアも異なるし、有効な特徴量も違うから」**です。
1か月後の未来を予測したいのであれば、下画像のようにして、訓練データとバリデーションデータを1ヶ月離してTimeSeriesSplitする、という方法が考えられます。
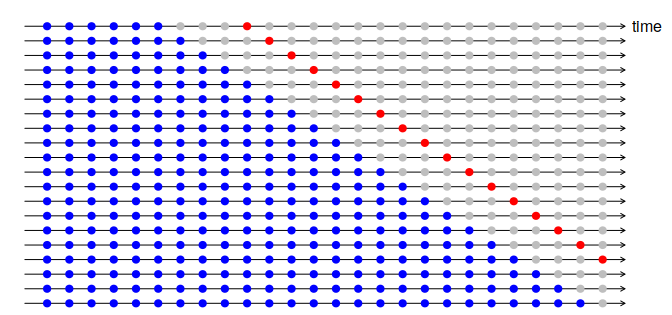
また、極端な話、1年後の未来を予測しなければならないのに、訓練データが1ヶ月分しかない、といった場合、そもそもLBスコア計算時と同じ条件でのバリデーションは不可能になります。
他にもTime Series Nested Cross-Validationなるものも存在するようです。
いずれにしろ、時系列データでは問題に応じて独自のバリデーションを確立することが必須であり、腕の見せ所でもあります。
特徴量の作成
特徴量の作成(Feature Engineering, FE)に関する技術は膨大であり、また、LightGBMとニューラルネットワークでは特徴量の作成方針が異なります。
以下ではLightGBMを使用する場合の特徴量作成方針として、重要と思うものを簡単に説明します。
特徴量同士の四則演算
LightGBMでは、「ある特徴量について、特定の値より大きいか小さいか」によるデータの分割をひたすら繰り返します17。
逆に、「複数の特徴量を参照するような条件」での分割は不可能です。
例えば、「ある特徴量Xの値が別の特徴量Yより大きいかどうか」で分割することはできません。
ですが、新たに「X-Y」という特徴量を用意すれば、「特徴量X-Yが0より大きいかどうか」で分割することができるので、上記の条件で分割できるようになります。
このように、2特徴量を組み合わせた新たな特徴量を用意することで、LightGBMに新たな分割の指標を与えることができ、スコアが上がる可能性があります。
なお、組み合わせ方は単純な四則演算に限らず、例えば「X^3 * log(Y)」のように、XやYに対してn乗したり指数・対数を取ることでさらに異なる特徴量を作ることもできます。
どの特徴量をどのように組み合わせるかは、EDAを行ったり、問題に対するドメイン知識などから考えることになり、如何に有効な特徴量を作れるかどうかは最終順位に大きく影響してきます。
また、総当たり特徴量作成(brute force feature engineering)なる手法も存在します。これは、手あたり次第に特徴量を作って全部モデルに突っ込み、のちに説明するPermutation Importanceのような方法で有効な特徴量を見つけ出していく方法です。
集約(Aggregation)特徴量
データが何らかのグループに分けられる場合に、「目的変数以外18のある特徴量Xの、グループ毎の集約関数(mean/median/std/max/min)の値」を集約特徴量といい、こちらも特徴量作成において重要かつ基本となる考え方の一つです。
例えば、以下のようなクレジットカードの使用履歴データが与えられたときに、そのトランザクションにおいてカードが不正利用されたかどうかを判定したいと考えます(「IEEE-CIS Fraud Detection」の問題設定に近い)。
| ID | ユーザーID | 利用日 | 利用金額 | 不正利用かどうか |
|---|---|---|---|---|
| 1 | Aさん | 1/1 | 60000円 | False |
| 2 | Aさん | 1/2 | 85000円 | False |
| 3 | Aさん | 1/3 | 90000円 | False |
| 4 | Bさん | 1/1 | 980円 | False |
| 5 | Bさん | 1/2 | 850円 | False |
| 6 | Bさん | 1/3 | 200000円 | True |
| 7 | Cさん | 1/1 | 120円 | ? |
| 8 | Cさん | 1/2 | 50000円 | ? |
| 9 | Cさん | 1/3 | 400円 | ? |
このデータから、「普段あまり高額な買い物をしないような人が、突然高額な買い物をした場合、不正である可能性が高い」という仮説が浮かび上がります。
この仮説に基づいて、例えば「ユーザー毎の利用金額の中央値」と、「利用金額と左記中央値の比率(割り算)19」という新たな集約特徴量を作ってみたのが、以下の表になります。
| ID | ユーザーID | 利用日 | 利用金額 | ユーザー毎の利用金額の中央値 | 中央値と利用金額の比率 | 不正利用かどうか |
|---|---|---|---|---|---|---|
| 1 | Aさん | 1/1 | 60000円 | 85000円 | 0.71 | False |
| 2 | Aさん | 1/2 | 85000円 | 85000円 | 1.00 | False |
| 3 | Aさん | 1/3 | 90000円 | 85000円 | 1.06 | False |
| 4 | Bさん | 1/1 | 980円 | 980円 | 1.00 | False |
| 5 | Bさん | 1/2 | 850円 | 980円 | 0.87 | False |
| 6 | Bさん | 1/3 | 200000円 | 980円 | 204 | True |
| 7 | Cさん | 1/1 | 120円 | 400円 | 0.3 | (False) |
| 8 | Cさん | 1/2 | 50000円 | 400円 | 125 | (True) |
| 9 | Cさん | 1/3 | 400円 | 400円 | 1.00 | (False) |
こうすると、例えば「中央値と利用金額の比率が10以上」とかで分割することで、不正利用かどうかを判定できることがわかります。
上記は極端な例でしたが、このように**「あるグループにおける特徴量の傾向」**を特徴量として与えたい場合に、集約特徴量が役に立つ可能性があります。
特徴量の削減(選択)
「学習に役立たない余計な特徴量」の存在は、学習時間やメモリ使用量を悪化させます。場合によっては、スコアを悪化させる可能性があります20。したがって、そういった特徴量は削減すべきです。
どの特徴量が余計かを判定するための手法として現在主流のものに、「Permutation Importance」という手法が存在します。
簡単に言うと、「ある特徴量をバリデーションデータ全体でシャッフルした場合に、どれだけCVスコアが悪くなるか(場合によっては良くなることも)」を見ることで、その特徴量の重要度を判定するという方法です。
Permutation Importanceの詳しいやり方は本記事では割愛しますが、以下の記事が参考になります。
Data Augmentation
Data Augmentationは、訓練データに対して変換をかけたものを新たな訓練データとすることで、訓練データを水増しして精度を向上させようという手法です。
主に画像認識タスクでよく使われる手法ですが、テーブルコンペでも有効な可能性があります。
例えば、「NFL Big Data Bowl」では、アメフトのフィールド全体を上下・左右反転するように選手の座標を変換したものを新たな訓練データとして追加することで、精度が向上したという報告が出ています。
なお、訓練データではなく**テストデータに対するAugmentationをTTA(Test Time Augmentation)**と呼びます。
テストデータに対して変換を施し、それらに対する平均値を最終的な予測値とすることで、精度が向上する場合があるようです。
パラメータチューニング
モデルのパラメータチューニングにおいて、最も重要なのは**モデルの「複雑さ」**です。
例えばLightGBMでの「木の深さ」、ニューラルネットワークでの「層の数」は複雑さの主要なパラメータの一つとなります。
モデルの複雑さは、単純すぎると特徴量の複雑な相関を見つけられず、逆に複雑すぎると細かすぎる相関にオーバーフィッティングしてしまうので、程よい複雑さとなるように設定する必要があります。
手動で試行錯誤しながら調整してもいいですが、より高速に最適なパラメータを得たい場合は、**Optuna**という自動パラメータチューニングツールを使うのが良いと思います。
Step 5 - 学習フェーズ
学習フェーズは、最終サブミットに向けて本格的にモデルを学習させるフェーズ…なのですが、これが必要になるのは大抵GPUコンペのみです。
なぜならテーブルコンペの場合は、そもそも学習時間が短いので、モデル構築フェーズの実験結果をそのままアンサンブルの材料にしてしまうことが多いためです。
GPUコンペの場合は、学習量が多ければ多いほどスコアが伸びるようなものが存在し(例えば「Predicting Molecular Properties」はモデルや特徴量の工夫以上に学習量が重要だった)、その場合はGPU計算資源と学習時間を十分確保しておく必要があります。
GPUマシンが手元に無い場合は、AWSやGCPからGPUインスタンスを借りることになります。GPUインスタンスは非常に高く、最低でも数万単位の出費を覚悟することになります…
学習フェーズの説明はこれだけで終わりでもよいのですが、さすがにこれだけでは味気ない…ということで、この段階でよく用いられることの多い、疑似ラベルという手法を紹介しておきます。
Pseudo Labeling
Pseudo Labelingは半教師あり学習と呼ばれる手法の1つで、簡単に言うと「モデル学習後に、予測済みテストデータの一部(特に予測が確実と思われるもの)を訓練データに追加して、再びモデルを学習する」という作業を1回~複数回行うことで精度を高める手法であり、最近のコンペでの上位入賞者が良く使っている手法です。
Pseudo Labelingが使用できる条件は、
- 分類問題である
- LBスコア計算用のテストデータが公開されている21
であり、主に以下のような場合に有効です。
- 訓練データが不足している場合
- テストデータと訓練データの分布が違う場合(訓練データに無いような傾向のデータがテストデータにのみ存在する場合)
特にKaggleにおいては後者に対する目的でPseudo Labelingが使われることが多いようです。
Pseudo Labelingは比較的最近になって使われ始めた技術ということもあり、どれくらいの割合を訓練データに追加するのがよいのかなど、まだまだベストプラクティスが確立されておらず発展途上の技術だと個人的には思っています22。
Step 6 - アンサンブルフェーズ
通常、Kaggleにおいては単一モデルの予測値を最終サブミットとすることはまれで、数個~数十個のモデルの予測値からアンサンブルという手法で最終サブミットを作成します。
「Step 2」の繰り返しになりますが、スコアが100点の予測値と、50点の予測値を混ぜたら、110点や120点の予測値ができる可能性があります。
なぜなら、アンサンブルによって、予測スコアの「バイアス」や「バリアンス」を減らすことができるからです。
Kaggleにおけるアンサンブル手法に関して詳しく知りたい方は、以下を読むとよいと思います。アンサンブル手法が網羅的に説明されている「バイブル」です。
その他、分かりやすいアンサンブルの記事を以下に紹介します。
データのバイアスとバリアンス
ある目的変数に対する予測値と正解値の間の誤差と呼んでいるものは、厳密にはバイアスとバリアンスの2種類に分かれます。
モデルのバイアスとは、**「真の正解に対する『そのモデルでseed(乱数)を変えて何度も何度も学習させて平均を取ったときに収束する予測値』の差」23のことで、バリアンスとは、「バイアスに対する『1回学習させたときの予測値』の差」**のことです。
以上の説明をがんばって図にしてみたものが以下になります(分かりにくくてすみません)。
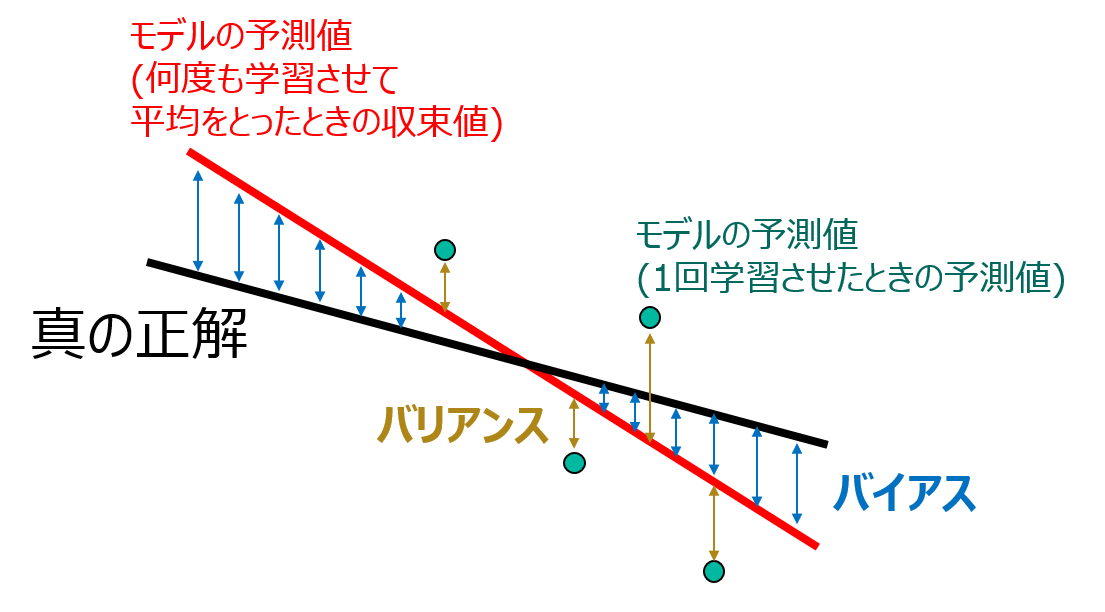
アンサンブルの手法
単純なk-fold平均
アンサンブルとはちょっと違いますが、k-foldによってバリデーションを行った場合に、各foldごとにモデルが1つできるので、それらの予測値を平均することでサブミットを作ることができます。
ただ、これだけの場合はあくまで「単一モデル」の予測値として扱われることが多い気がしてます。
Seed Averaging
Seed Averagingとは、Seed(乱数)を変えながら同じモデルを何度も学習させ、その平均値をサブミットとする手法で、上図におけるバリアンスを減らすことができます。
統計学の定理より、n回のSeed Averagingを行うと、バリアンスの標準偏差は1/√n倍に小さくなります。
実装も単純ながら確実に効果があり、下記のブレンディングやスタッキングと併用されることも多いです。
ブレンディング(重み付き平均)24
ブレンディングとは、複数種類のモデルの予測値を、適当な重みで平均した値をサブミットとする手法で、上図におけるバリアンスだけでなく、バイアスを減らせる可能性がある(必ず減らせるわけではない)手法です。
ブレンディングでは、Seed Averagingと異なり、異なる種類のモデル(例えばLightGBMとニューラルネットワーク)や、あるいは同種であっても異なるパラメータのモデル(例えば木の深さが5のLightGBMと10のLightGBM)に対して平均を取る必要があります。
ブレンディングを行う際に非常に重要な一つの原則があります。それは、予測値同士の相関が弱いものをブレンディングするということです。その方が、バイアスを減らせる可能性が高いためです。
逆に、相関が強いもの同士を平均化しても、バイアスは減らずにバリアンスのみが減ることになり、得られる恩恵はSeed Averagingとほぼ変わらないことになります。
下の画像では、モデルAとモデルBの予測値(バイアス)が相補的になっているため、平均値と取ると大幅に真の正解に近づいていることがわかります(実際はここまで綺麗に予測値が相補的であることはまずなく、特徴量空間はもっと次元が大きいので、こんなに単純ではない)。
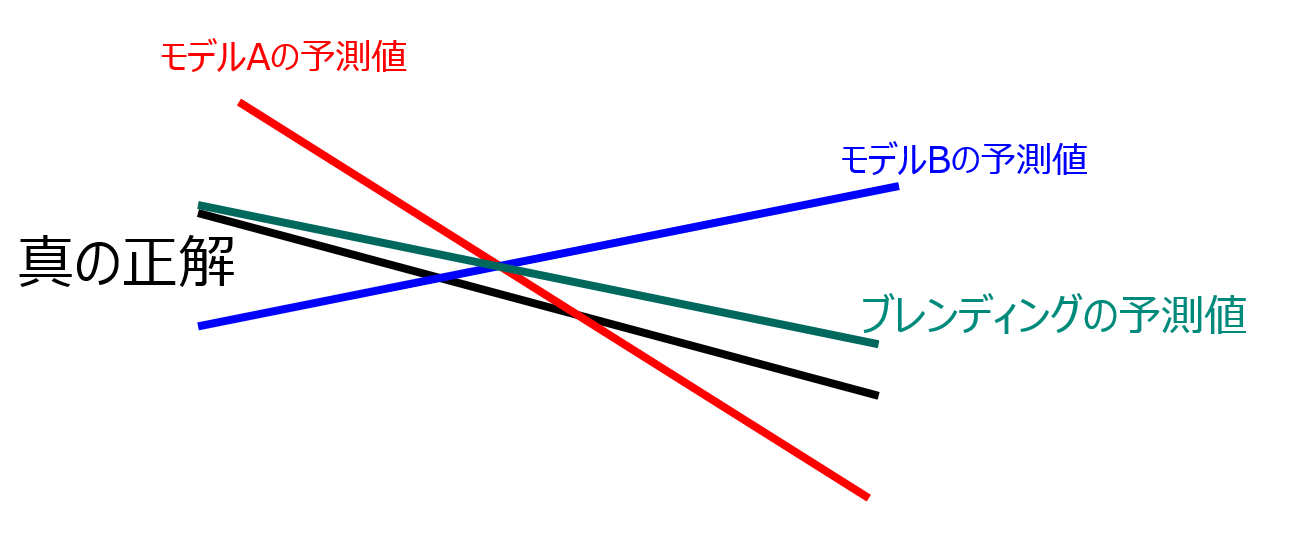
ブレンディングの実装例として、「IEEE-CIS Fraud Detection」における以下の公開カーネルはスコアの高さだけでなく相関の弱い予測値を優先してブレンディング候補に採用するよう工夫されており、使い勝手が良いと思います。
スタッキング
スタッキングは、根本的にはブレンディングと同じく重み付き平均を行うのですが、その時の「重み」を手動で決めるのではなく、何らかの回帰モデル(例えば線形回帰)を使って学習する手法です。
具体的には、k-foldでの各モデルのバリデーションデータに対する予測値を用意し、元々の特徴量と一緒に回帰モデルに突っ込み学習させます。
これにより、例えば**「モデルAがある種類のデータの予測が得意で、モデルBが別の種類のデータの予測が得意」のような時に、モデルAとモデルBの良いとこ取りができる**ようになります。
よって、単純なブレンディングよりもさらにバイアスを減らすことができます。
スタッキングのイメージは下の画像のような感じです。ブレンディングが2つのモデルの中間線であるのに対し、スタッキングは2つのモデルのうち真の正解に近い方を選び取るようなイメージです。
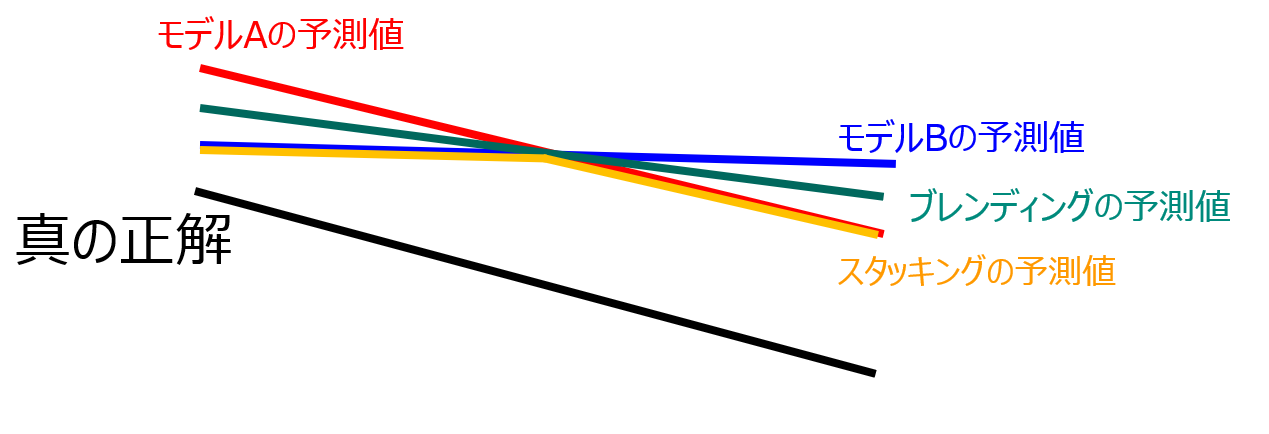
スタッキングのやり方は結構複雑なので、本記事では詳細は割愛します。詳細については以下の記事が参考になります。
なお、スタッキングをする際の注意点として、学習フェーズにおいてすべてのモデルが「全く同じバリデーションによるk-fold」で学習されており、かつ「テストデータの予測値だけでなく、バリデーションデータの予測値が必要」である必要があります。
最後にスタッキングを試す場合は、上記を踏まえて各モデルの学習を回す必要があります。
上記条件を満たさないモデルについてはスタッキングが使えないので、スタッキング後にブレンディングでアンサンブルする等行うことになります。
Step 7 - 次のコンペに向けて
コンペが終了したら、振り返ることなく次に進むのではなく、以下を確認しておくとよいでしょう。
コンペ上位(金メダル獲得)者の手法を見ておく
コンペ終了後、ディスカッションにて**「○○th Place Solution」のようなスレッドが立つと思います。ここでは金メダル獲得者がどのような手法を使っていたか説明してくれているので、必ずチェックしましょう**。
上位者がどんなモデルを使っていたか、どんな工夫をしていたか確認することは、自分の技術や知見を大きく広げるチャンスです。
Shakeの原因を把握する
大抵のコンペでは、PublicLBとPrivateLBでの順位が変化するShakeUp/ShakeDownが発生します。
これは、PublicLBとPrivateLBのデータの分布が異なる場合に発生します。
特に大きなShakeがあった場合はコンペ終了後にディスカッションで議論されることもあるので、確認しておくと良いと思います。
最後に
私は、Kaggleでのメダル獲得は、決して簡単ではなく、常日頃から情報収集や「実験」をし続ける習慣が無ければ、達成できない領域であると思っています。
ですので、これからメダル獲得を目指す方は、まずKaggleを「趣味」として自らの時間を投資するという覚悟を持つ必要があると思います。
とはいえ、ちゃんと問題に対して熟考し、適切なアプローチを取ることができれば、銀メダルまでであれば初心者がソロで十分到達できる領域であると確信しています(ちなみに金メダルは銀とは天と地ほどの差があります…)。
Kaggleでのメダル獲得実績を得ることができれば、データサイエンティストとして仕事に就くには、十二分の能力があると言っていいと思います25。
なお、今回の記事では「転職活動のためにKaggleでメダルを獲得する」のようなニュアンスが強かったのですが、当然データサイエンティストとして就職した後も、Kaggleを続けることには大きな意義があることをここに付記しておきます。
詳細は割愛いたしますが、私が現在業務で扱っているニューラルネットワークモデルについて、Kaggle上位者が使用していた手法を応用することで大きな精度向上に成功したこともあります。
確かに、Kaggleは通常のデータ分析業務と異なり、「データ収集が不要」「プロジェクトの目的(または目的関数)が明確」など、多くの違いがあり、Kaggleから始めてデータサイエンスに携わる方はそのギャップに留意する必要があります。
ですが、Kaggleで培った精度向上の技術は、非常に役に立つはずです。なぜなら、どんなAIプロダクトであっても、精度26が1%向上することは、それだけでプロダクトの価値を何万円、あるいは何億円と高めることが往々にして有り得るからです。
そして、何といっても、データサイエンティストの業務やKaggleへの参加は、とても楽しいです。
数年前まではAIの勉強というは非常にハードルが高く、生半可な気持ちでは手も出せない領域でしたが、そのハードルはどんどん下がってきており、私のようにSIerから転職する方々、未経験からチャレンジする方々は、年々増えてきているはずです。
本記事によってKaggle参加のハードルを少しでも下げることができ、Kaggleの楽しさをより多くの方に知ってもらえることを祈っています。
私もまだまだ未熟なため、内容について間違い・不十分・不適切な個所、あるいは「こんな情報が足りない」といったご意見などあると思います。Kaggle熟練者からのご指摘をお待ちしております。
以上となります。最後まで本記事を読んでいただき、誠にありがとうございました。
-
PrivateLBの結果はまだ出ていません
が、PublicLBより順位は下がりそう。 ↩ -
昨年になって、競技プログラミングの国内最大手であるAtCoderについて、レーティング(=実力指標)を元に就職活動ができるAtCoderJobsのサービスが開始されるなど、コンペティションサイトの戦績という指標の認知度は高まっています。 ↩
-
各メダルの割合は、大雑把に以下の通りです(正確な数値はコンペの参加人数に依存)。金メダル:上位0.5~1%、銀メダル:上位5%、銅メダル:上位10% ↩
-
完全に偏見ですが、世の中の「AI・機械学習入門」的な題名の本は、単にPythonやそのライブラリの使い方が書いてあるだけで、データサイエンスのエッセンスが何も書かれていないものが多いと思っています。 ↩
-
カーネル(Kernel)は、Kaggleが提供する計算資源上で動くコードのこととして本記事では呼称していますが、Kaggleでの正式名称は最近になって「Notebook」に変わったようです。 ↩
-
あるいは、スコアなどとも呼びます。なお、「目的関数」はモデルが最大化(最小化)しようとしている関数のことを指し、評価指標とは意味が異なります。 ↩
-
AUCは、Kaggleの分類系コンペにおいて頻出の評価指標です。次の記事の説明が詳しいです。ROC 曲線とAUC を用いて2値分類機械学習モデルの性能を計測・チューニングする ↩
-
例えば、MAEとRMSEでは、RMSEの方が外れ値の影響が受けやすいというのは常識です。また、本記事の「Predicting Molecular Properties」の例では、実は各クラスのデータ数に最大で数十倍の差があるため、クラスごとにデータの重みづけが必要である(あるいは各クラス別々に学習してもよい)という隠されたヒントが存在します。 ↩
-
特に自然言語処理はディープラーニングで現在最も勢いのある分野であり、Transformerをベースにした新たなモデルが次々と開発されていますが、モデルの理解難度は非常に高いので(私もあまりよくわかってません)、初心者は避けるべきです。 ↩
-
実際、私も高いスコアの公開カーネルに手を出したり、バリデーション手法を疎かにしてきた苦い経験があるので、特に強調して書いているつもりです。 ↩
-
「IEEE-CIS Fraud Detection」はまさにこの「魔法の特徴量」の意味に気付けるか否かが明確に順位を分けたコンペでした。何百とあるマスキングされた特徴量のうち、ある一つが「ユーザーが過去に支払った累積金額」を表しており、これと「そのトランザクションで支払われた金額」からユーザーとトランザクションを完全に紐づけることができた、というものです。 ↩
-
「ASHRAE - Great Energy Predictor III」は、リークによりPublicLBの大幅変動が発生したコンペの一つです。 ↩
-
この仮定が成り立たないことは普通にあり得ます(特に時系列データを扱うコンペの場合)。その場合は、PublicLBとPrivateLBで順位の大幅変動(ShakeUp/ShakeDownと呼ばれる)が発生することがあります。ShakeDownに巻き込まれないためには、PublicLB用のテストデータとPrivateLB用のテストデータについて、条件や分布の違いが無いか確認し、違いがある場合はPrivateLBにより近そうなバリデーションを考える必要があります(当然PublicLBは信用してはいけない)。ただ、これは完全にコンペ個別の問題依存の話のため、本記事では割愛します。 ↩
-
どうしてもバリデーションがうまくいかない場合は、泣く泣くPublicLBを見ながら実験を頑張ることもできなくはありませんが、その状態でコンペで上を目指すのは困難です(経験談)。 ↩
-
Kaggleには「Trust your CV」という格言(?)があります。PublicLBのスコアより、自らのバリデーションスコアを信じろ、ということです。 ↩
-
これ、Kaggleの初級レベルの技術としてすごく重要だと思っているのですが、ちゃんと説明されている記事は少ないです。 ↩
-
なので、ある特徴量xに対し、x^nやa^x、log(x)のような、単調性をもつ変換をかけただけの特徴量を追加してもLightGBMにおいては無意味です。逆にニューラルネットワークでは重要になります。 ↩
-
「目的変数に対する集約特徴量」は特に**Target Encoding**と呼ばれる別の手法になり、リーク防止のために複雑な処理が必要になる(大きなグループに対して適用するのであればリーク防止処理は不要となり、本記事と同じように扱えることも)。 ↩
-
「四則演算特徴量」の活用例にもなっています。 ↩
-
その特徴量と目的変数が「たまたま」相関しており、その相関に対してオーバーフィッティングしてしまっている場合。 ↩
-
Pseudo Labelingのような特殊な技術が流行ることを嫌ってか、最近では「NFL Big Data Bowl」のようにテストデータがコンペ終了後まで公開されないタイプのコンペも増えてきています。 ↩
-
Kaggleの文脈におけるPseudo Labelingは、Kaggle特有の技術である故に、Kaggle内のコミュニティでのみしか発展しないという問題があります。一方、本来の半教師あり学習としてのPseudo Labelingはセマンティックセグメンテーション等における自動ラベリング技術として有用であり、研究も盛んに行われこなわれています。 ↩
-
言い換えると、そのモデルが持つ本質的な誤差、またはそのモデルが目指せる限界。 ↩
-
実はKAGGLE ENSEMBLING GUIDEにおける「Blending」と定義が異なるのですが、Kaggleでは専ら本記事の通り、単純な重み付き平均のことを指します。 ↩
-
そして、企業側にも一言申し上げたいのですが、Kaggleでメダル獲得実績がある(できればソロ)というのは、データサイエンティスト未経験であったとしても、相当な基礎知識と熱意があることの証明であるので、業務経験者や機械学習系専攻出身者ばかりを求めようとせず、積極的に採用していただきたいなあと思っております。 ↩
-
Kaggleと違ってビジネスにおいては評価指標がはっきり決まっているわけではないので、精度(正答率)という言葉を使うときには特に気を付ける必要があります。単に『精度XX%!』のように謳っているAIプロダクトがあったとしたら、裏にトリックがあると疑うべきです。データサイエンティストは、精度の数値を発表する際に、精度としてどんな評価指標を使っているか、なぜその評価指標を使ったか、学習データとテストデータは何を使ったか、その値はどの程度信頼できるのか、その精度の高さによって生み出せる利益の期待値はどの程度かなどなど、ある程度説明できるようにする必要があると思っています。 ↩