はじめに
データ解析の情強な方なら、Kaggle はご存じだと思います。データ解析のSkillを競うCompetitionサイトで、与えられたテーマ(Dataset)に対して、世界中のデータ解析有識者が様々なデータ解析手法を駆使してより高い正答率(Score)を競い合う場所です。
が、Kaggleそのものは知っていても、どうやればKaggleに実際に参加できてランキングに加われるのかは知らない、と言う方は多いと思います。この記事では、とりあえずKaggleの何らかのCompetitionに参加して、解析結果をSubmitして、(その時点の)順位/Scoreを確認するまでの操作手順/流れをチラ裏したいと思います。
KaggleのWeb pageは色々な情報/Linkが詰まっているので、ぱっと見取っ付きにくいかもしれませんが、ポイントをつかめば参加してScoreを付けて貰う所まではとても簡単です。Scoreと順位が決まると俄然ヤル気が出てきますので、本記事がKaggleで色々挑戦するキッカケになれば幸いです。
大枠の流れ
本記事でチラ裏している手順は大きく以下の様になります。
- Kaggle Accountを作成しSign inする
- 参加したいCompetitionを決めDataset等をDownloadする
- Competitionで計算すべき内容を理解する
- Datasetを処理しSubmit用Dataを作成する
- Submitして順位とScoreを確定させる
Kaggle Accountを作成しSign inする
まず、Kaggle上のAccountを作成してSign inする必要が有ります。ここからKaggle Accountを作成します。GoogleやFacebookなどのAccountでSocial loginさせる事も可能です。
参加したいCompetitionを決めDataset等をDownloadする
Competitionを選ぶ
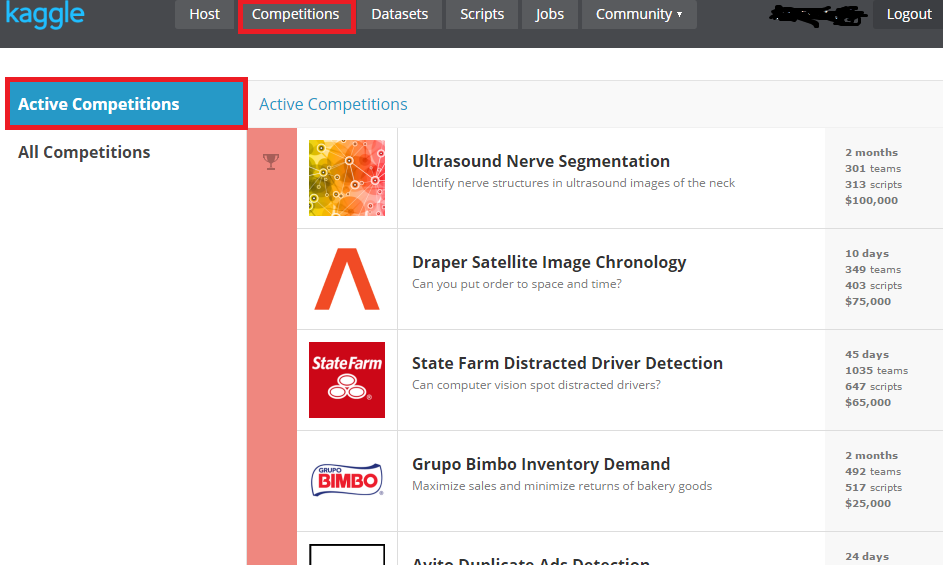
このページ、もしくは上のCompetitionsをクリックすると、Competitionの一覧が表示されます。開催されている(Activeな)Competitionは日々変わりますが、今回は下の方にあるTitanic: Machine Learning from Disasterに参加して見ましょう。
ご承知の様に、TitanicやIrisのDatasetは機械学習でとてもよく使われます。このCompetitionもKaggleの入門/Tutorialみたいな位置づけで、(たぶん)常にActiveなので、初めてTryしてみるには良いCompetitionだと思います。
Competitionの詳細を確認する
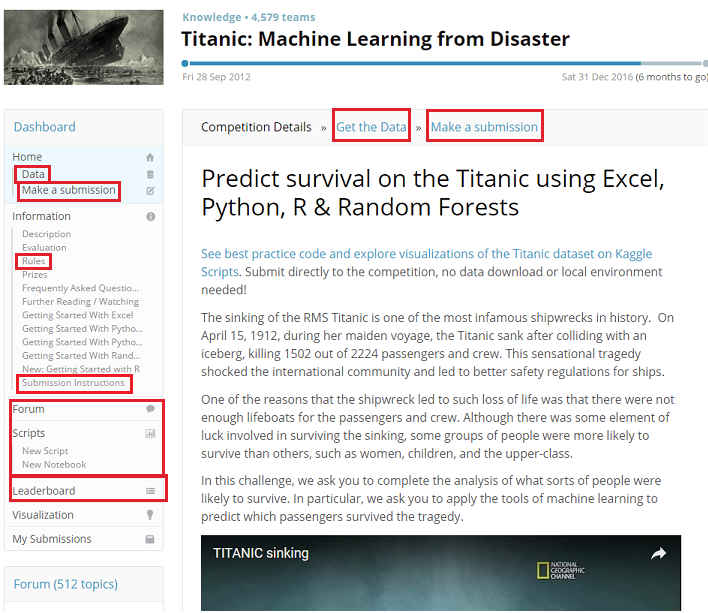
Titanic: Machine Learning from Disasterをクリックすると、Competitionの詳細ページに飛びます。Competition固有の情報/操作は各詳細ページからLinkで辿れる様になっています。簡単に詳細ページにある各Link先の解説をします。
Data (もしくはGet the Data) :訓練/テストデータ, Submission用データのひな形などのDownloadページ
Make a submission:解析結果をSubmitしてScoreを付けて貰うページ
Submission Instructions:Submit用fileのformatなどの説明ページ
Forum/Scripts:ある意味一番重要なページです!Competitionの参加者からの情報共有ページで、ScriptやJupyter notebookそのものを上げている人も多く、とても勉強になります。
Leaderboard:CompetitionのScore/順位のページ。解析結果をSubmitすると自分の名前もここに載ります。
DatasetをDownloadする
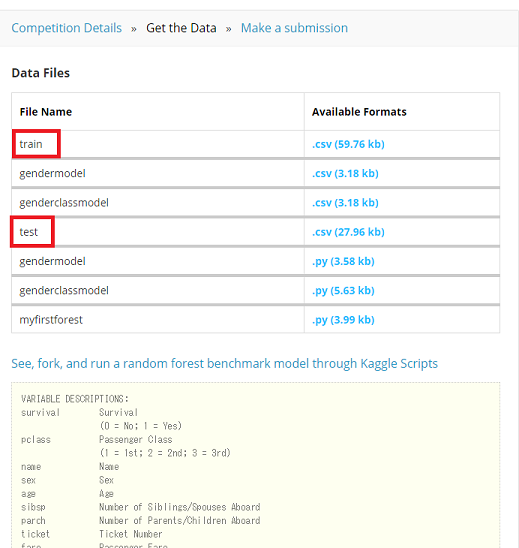
Get the Dataをクリックすると、DatasetのDownloadページに行きます。このページには、Dataset fileそのものと、fileの中の変数の説明やどんな解析をすれば良いかが書かれて居ます。
このCompetitionの場合、幾つかのcsvとpython scriptが置かれていますが、Submitにはtrain.csvとtest.csvの2つがあれば最低限OKですので、この2つのfileをDownLoadして下さい。
Competitionで計算すべき内容を理解する
Dataset fileをDownloadしたので、2つのfileの中身を簡単に解説しておきたいと思います。csvを開いてみてください。
train.csv
- 1行目はHeaderで、その後に891行 x 12列のデータのcsv
- 1列目が
PassangerId, 2列目がTitanicの事故で生存したかのFlag(Survived), 3列目以降が客の属性 - 客の属性には、
名前,年齢,性別,船室クラス,同乗した兄弟や子供などの人数など10個の属性データがある - 客の属性データの一部は欠損している (
PassangerIdとSurvivedは全て埋まっている) - いわゆる訓練用データ
test.csv
- 1行目はHeaderで、その後に418行 x 11列のcsv
- csvの構成は、
train.csvとほぼ同等だが、Survivedの列だけ無い - いわゆるテスト用データ
という事で、train.csvの891名のデータからTitanicの事故で生存したかの2クラス分類器を作り、test.csvの418名のデータに対して生存したかの予測をすれば良い、という事が解ります。
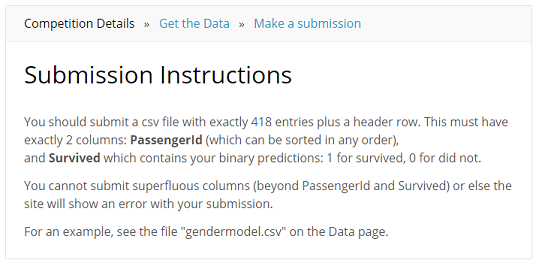
左ペインのSubmission Instructionsをクリックすると、Submit用のFileの詳細formatのページに行きます。以下を読むと、解析結果としてsubmitすべきcsv fileは、header+418行で、PassengerIdとSruvivedの2列を持つべしという事が解ります。
Datasetを処理しSubmit用Dataを作成する
DatasetをDownLoadして、計算すべき内容もわかったので、実際に分類器を作りSubmit用のFileを作ってみます。
以下、train.csvを使って予測器を作り、Submit用のcsv fileを作る超簡易Codeです。最低限の処理しかしていないので、予測の精度は高くないです。Codeの中身は、解説するまでも無いですが、Gender(SexをDummy変数化)/Age/Pclassの3つの変数からRandom Forestで予測器を作り、予測結果をtitanic_submit.csvに書きだしています。
pandas, scikit-learnが必要なので、未だの場合は事前にsudo pip install pandas scikit-learnを実行してlibraryをinstallして下さい。
import pandas as pd
import csv as csv
from sklearn.ensemble import RandomForestClassifier
# Load training data
train_df = pd.read_csv("train.csv", header=0)
# Convert "Sex" to be a dummy variable (female = 0, Male = 1)
train_df["Gender"] = train_df["Sex"].map({"female": 0, "male": 1}).astype(int)
train_df.head(3)
# Complement the missing values of "Age" column with average of "Age"
median_age = train_df["Age"].dropna().median()
if len(train_df.Age[train_df.Age.isnull()]) > 0:
train_df.loc[(train_df.Age.isnull()), "Age"] = median_age
# remove un-used columns
train_df = train_df.drop(["Name", "Ticket", "Sex", "SibSp", "Parch", "Fare", "Cabin", "Embarked", "PassengerId"], axis=1)
train_df.head(3)
# Load test data, Convert "Sex" to be a dummy variable
test_df = pd.read_csv("test.csv", header=0)
test_df["Gender"] = test_df["Sex"].map({"female": 0, "male": 1}).astype(int)
# Complement the missing values of "Age" column with average of "Age"
median_age = test_df["Age"].dropna().median()
if len(test_df.Age[test_df.Age.isnull()]) > 0:
test_df.loc[(test_df.Age.isnull()), "Age"] = median_age
# Copy test data's "PassengerId" column, and remove un-used columns
ids = test_df["PassengerId"].values
test_df = test_df.drop(["Name", "Ticket", "Sex", "SibSp", "Parch", "Fare", "Cabin", "Embarked", "PassengerId"], axis=1)
test_df.head(3)
# Predict with "Random Forest"
train_data = train_df.values
test_data = test_df.values
model = RandomForestClassifier(n_estimators=100)
output = model.fit(train_data[0::, 1::], train_data[0::, 0]).predict(test_data).astype(int)
# export result to be "titanic_submit.csv"
submit_file = open("titanic_submit.csv", "w")
file_object = csv.writer(submit_file)
file_object.writerow(["PassengerId", "Survived"])
file_object.writerows(zip(ids, output))
submit_file.close()
作成されたtitanic_submit.csvを開き、Submission Instructionsの内容に沿って居るか確認して下さい。
Submitして順位とScoreを確定させる
最後に、Submit用のFileをuploadして、Scoreと順位を確認します。
Make a submissionをクリックすると、そのCompetitioに初めてSubmitする場合 は、Competition Rulesのページがまず表示されます。このページの一番下にあるI understand and acceptをクリックするとSubmitが出来る様になり、Make a submissionのページに移動します。
Click or drop your submission hereをクリックして先ほど作成したtitanic_submit.csvを選択し、Submitをクリックすると、fileのuploadとScoreの計算が行われ、結果がLeader board上で表示されます。
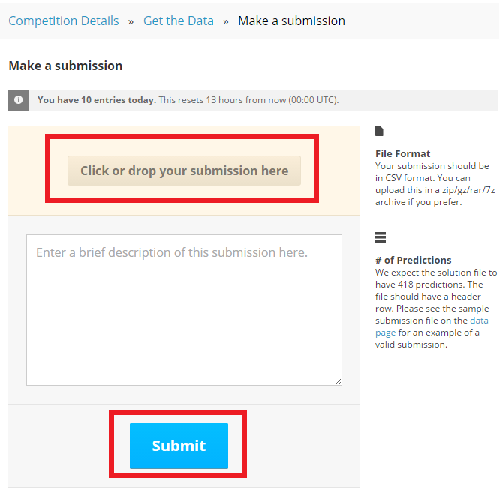
これにて、無事Submitが行われScoreが確定しました。最後にLeaderboardに行き、自分の名前が載っているか確認してみてください。
その他
Scoreの計算方法
Scoreの計算方法は、Evaluationに詳細が載っています。今回の事例の場合2クラス分類なので、Scoreは正しく予測ができた割合になり、数字が大きく1に近いほど良いScoreとなります (Your score is the percentage of passengers you correctly predict.)。
多クラス分類の場合は、multi-class logarithmic lossという評価手法が使われ、数字が小さく1に近いほど良いScoreになります。
Forum/Scriptsのページ
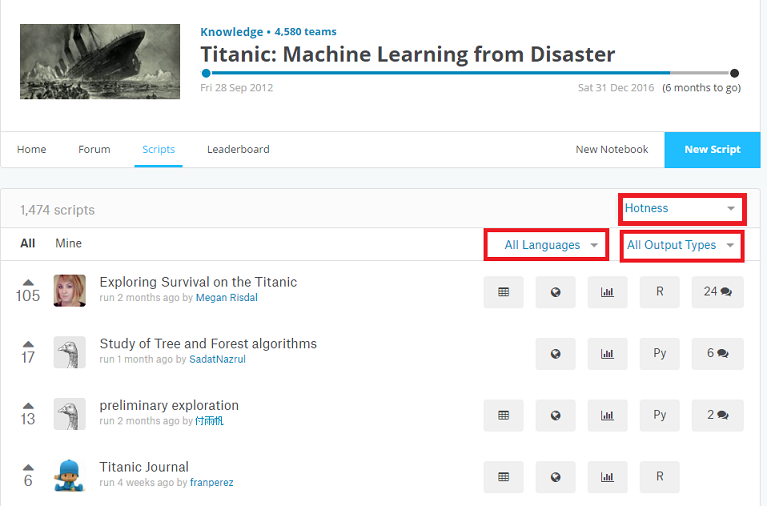
Forum, Scriptsのページには、世界中のデータ解析の有識者から様々なScriptなどが活発に共有され、とても勉強になります。個人的にはCompetitionそのものよりも重要だと思っていますし、Codingの参考にもなります。All Language、All Output Types、HotnessなどのPull downを変更して、参考になるScriptを探してみて下さい。
上位入賞者のテクニック
Kaggleでは、自分が使った手法やCodeそのものを開示する事は必須ではありませんが、大きなCompetitionの上位入賞者はKaggleの公式Blogにおいて、自己紹介と使った手法の概要紹介をするケースが良くあります。公式BlogのWINNERS' INTERVIEWSを見てみると、上位入賞者がどんなアルゴリズム/手法を使っているのかとても参考になります。
最後に
良いKaggle生活を!