はじめに
- 新規データを受領した際に、統計モデリングや機械学習の前に実施すべき10ステップをまとめてみました
- すぐにモデリングや機械学習による予測・分類をしたくなりますが、間違えた分析結果や作業の手戻りを避ける為に基本的な下記ステップをまず実施することが重要と思います
10ステップ
- データ型の確認
- データ形の変換(日付型)
- データ形の変換(カテゴリ型の作成)
- 基本統計量の算出
- 単変量データの可視化
- 異常値の置換・除去
- 欠損値の補完・除去
- 相関(数値×数値)の可視化:ペアプロット&相関行列
- 相関(数値×カテゴリ)の可視化:ボックスプロット
- 相関(カテゴリ×カテゴリ)の可視化:ヒートマップ
対象データ概要
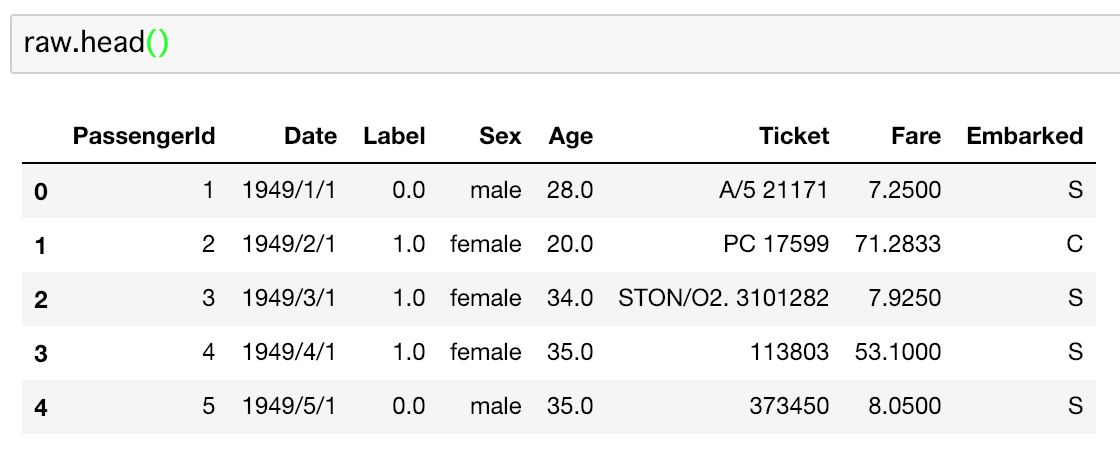
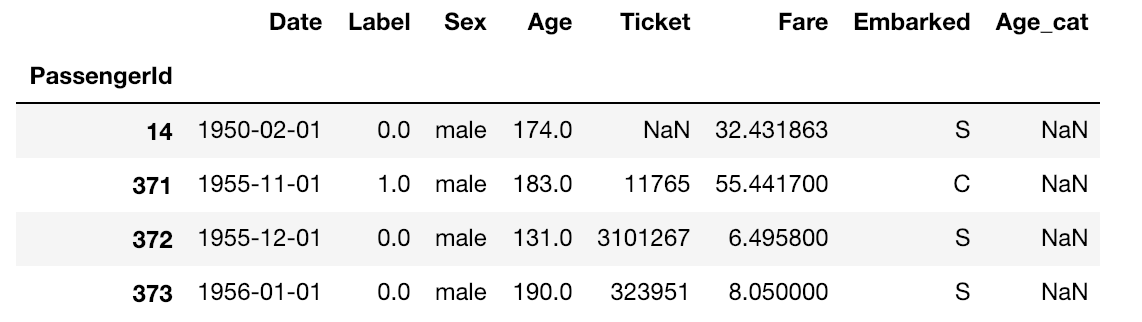
- 今回はサンプルとして下記のようなデータを対象にします
- 有名なTitanicのデータを加工しました(オリジナルデータは現実には存在しないくらい綺麗だったので)
- こちらのデータを参考に10ステップを紹介していこうと思います
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
raw = pd.read_csv('sample.csv', encoding='shift_jis')
raw.head()
1. データ型の確認
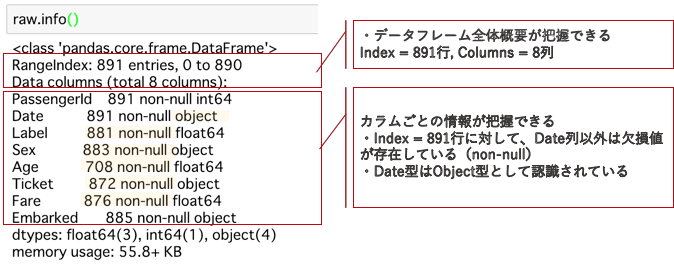
- まずは読み込んだデータ型を確認します
- pd.Dataframe.info()で簡単に確認できます
- ここで欠損値がどの程度存在しているか、データ型が予期した通りに取り込まれている確認します
raw.info()
2. データ形の変換(日付型)
- DateがObject型として取り込まれているので、datetime型に変換します
- (今回はやりませんが)時系列データとして処理をする際は、datetime型に変換して、resampleやtimedeltaとして処理すると簡単です
- datetime型はデータ読取時にフォーマット指定をしない限りはObject型で認識されるので、本処理が必要になります
- pd.to_datetimeはテキストのフォーマットをから自動的にdatetime型へ変換してくれます(おかしなフォーマットでない限りは結構読み取ってくれます)
raw['Date'] = pd.to_datetime(raw['Date'])
3. データ形の変換(カテゴリ型の作成)
- 年齢を数値でなく、年代(カテゴリ)で処理したかったケースを想定します
- pd.cutで数値データを簡単にカテゴリデータに変換できます(binsにカテゴリの単位を入力)
- 結果の、(a, b]はa < x <=bを表します
- デフォルトはright=Trueですが、年齢は通常右側(大きい方)は含まないので、right=Falseとする必要があります
raw['Age_cat'] = pd.cut(raw['Age'], bins=np.arange(0, 100, 10), right=False)
3. データ形の変換(ID列をpd.DataframeのIndexへ変更)
- 厳密にいうとデータ型の変換ではないのですが、単純なIndex紐付けなのでここに記載してしまいます
- pd.Dataframe.set_index('列名')で対象をデータフレームのインデックスに指定できます
- 小ネタとして、set_index('列名')で処理すると、元の列は削除されますが、set_index(Dataframe['列名']]とすると元の列が残ります
raw = raw.set_index('PassengerId')
# raw = raw.set_index(raw['PassengerId'])#元の列名が残る方法
4. 基本統計量の算出
- pd.Dataframe.describe()で基本統計量をまとめて算出してくれます
- デフォルトだとinclude=Noneで数値データの基本統計量のみ算出されます
- include='all'とすると、Object型、Categry型のデータの統計量も算出します
raw.describe(include='all')
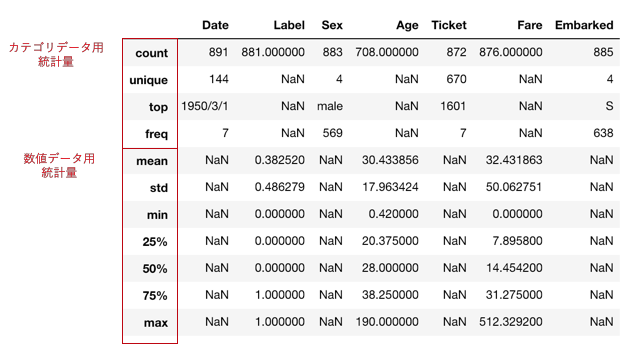
基本統計量の指標一覧
| 指標 | 意味 |
|---|---|
| count | データの個数 |
| unique | ユニークな値の個数 |
| top | 最頻値(最も多く出現したカテゴリ) |
| freq | topで返されたカテゴリの出現回数 |
| mean | 平均 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | 第一四分位数 |
| 50% | 第二四分位数(中央値) |
| 75% | 第三四分位数 |
| max | 最大値 |
5. 単変量データの可視化
- クロス集計をして各変数間の関係性をみるまえに、まずは各変数ごとに可視化をしてデータを理解します
- 数値データはヒストグラム、カテゴリデータはカウントプロットで可視化すると分かりやすいです
- pandasのデフォルトのグラフでも可視化はできるますが、ヒストグラムは平均・中央値と比較してみたい、カウントプロットは実数も重ねてみたい、、ので関数を定義します
# 数値データ用ヒストグラム
def num_vis(data):
data.hist(figsize=(5, 4), color='darkblue', alpha=.7)
mean = data.mean()
median = data.median()
ymax = pd.cut(data, 10).value_counts().max()
plt.vlines(x=mean, ymin=0, ymax=ymax, colors='red', linestyles='--', lw=.7)# 平均値の直線追加
plt.annotate('Mean: {}'.format(round(mean, 2)),xy=(mean, ymax), color='red')
plt.vlines(x=median, ymin=0, ymax=ymax, colors='orange', linestyles='--', lw=.7)# 中央値の直線追加
plt.annotate('Median: {}'.format(round(median, 2)),xy=(mean, ymax*0.8), color='orange')
plt.title(data.name)
plt.show()
# カテゴリデータ用カウントプロット
def cut_vis(data):
t = data.value_counts()
t.plot.bar(figsize=(5, 4), color='indianred', alpha=.7)
for i in range(len(t)):
plt.annotate(t[i], xy=(i, t[i]/2), ha='center')#haでannotatioinのテキストを中央寄せ
plt.title(data.name)
plt.show()
# 関数を各変数へ適用
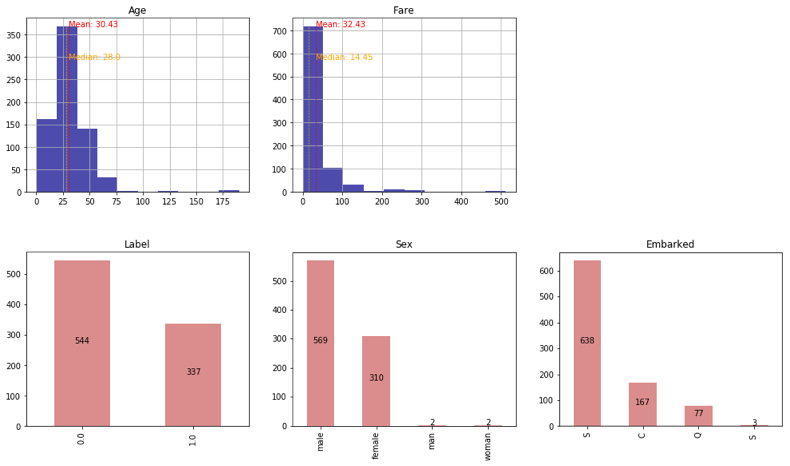
num_vis(raw['Age'])
num_vis(raw['Fare'])
cut_vis(raw['Label'])
cut_vis(raw['Sex'])
cut_vis(raw['Embarked'])
- Ageに異常値がありそうで、Sexに表記揺れが存在していることが確認できます
6. 異常値の置換・除去
-
基本統計量の確認や単変量データの可視化からみえた異常値を処理していきます
-
何を持ってい"異常"とするかはデータの発生原因を詳しく考察する必要があります
- [補足]マーケティング領域には、N1マーケティングやエクストリームユーザー観察といった方法論では、あえて、"異常値"を探しに行き、サービスの新たな使い方のヒントを探る領域もあります
- その為、安易に"異常値"を置換・除去すべきではないといえます
-
ここでは、以下の2点を修正するとします
- Ageに125歳や175歳が存在 => 異常値として除去
- Sexに表記揺れ(大文字) => 小文字に統一
# 異常値として除去する対象を表示(確認)
raw[raw['Age'] > 100]
# 対象のIndexを取得して、pd.Dataframe.dropで除去
raw = raw.drop(raw[raw['Age'] > 100].index, axis=0)
- 文字列置換をする関数を定義して、Dataframeの行方向にapplyするだけなのですが、今回はDataframeにNaNがあるので、pd.isnaで回避するようにしています
- 補足:NaNの扱いについて
- NaNの取り扱いですが、数値でも文字列もないため、少々特殊です
- x == np.nanのように記載するとエラーします
- np.isnan(x)でTrue/False判定をしようとすると、numpyのisnanは数値しか扱えないので、エラーを返します
- そこで、文字列も数値も扱えるpd.isna(x)で判定します
- numpyはis.nanでpandasはpd.isnaで若干違うのが分かりづらい
def replace_male(x):
if pd.isna(x):
pass
else:
return x.replace('man', 'male')
def replace_female(x):
if pd.isna(x):
pass
else:
return x.replace('woman', 'female')
raw['Sex'] = raw['Sex'].apply(replace_female)
raw['Sex'] = raw['Sex'].apply(replace_male)
7. 欠損値の補完・除去
- 最も簡単な(雑な)欠損値の除去方法は欠損を含むデータは全て除去する方法です(今回は採用しません)
- pd.Dataframe.dropna()で一括処理できます
- pd.Dataframe.dropna(inplace=True)で欠損除去して、データフレームごと入れ替える機能もありますが、欠損値の補完・除去の作業は、rawデータを行ったり来たりするので、元データは保管しておくと便利です
# data = raw.dropna()
# 欠損値除去後のデータは別名にして、元データは残しておくと後々便利
- 今回は欠損値を平均値で補完する方法を採用します
- 欠損値の保管方法は他にも色々とあります(回帰モデルによる推定値や、カーネル密度推定による推定値)
- 平均値で補完することの妥当性はデータの分布や欠損値の発生原因から別途考察する必要があります
- pd.DataFrame['Col_name'].fillna()の引数に入れたデータで欠損値を一括入力してくれます
raw['Age'] = raw['Age'].fillna(raw['Age'].mean())
raw['Fare'] = raw['Fare'].fillna(raw['Fare'].mean())
8. 相関(数値×数値)の可視化:ペアプロット&相関行列のヒートマップ
- 数値×数値データの関係性を可視化するにはペアプロットが便利です
- また各変数の相関関係を把握する為に合わせてで相関行列をヒートマップで表現しておくと便利です
8-1. ペアプロット
sns.pairplot(data=raw, vars=['Age', 'Fare'], size=3)
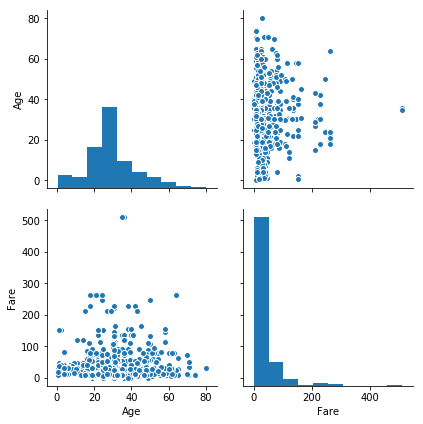
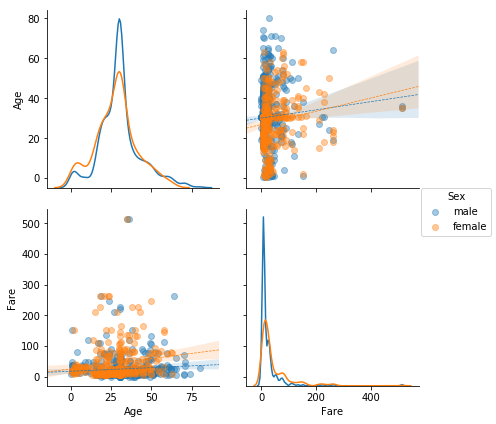
- ペアプロットは引数が色々あり、層別傾向や回帰直線も表現することができます
- kind='reg'で回帰直線を追加、diag_kind='kde'でヒストグラムをカーネル密度推定で表現、hueで層別塗り分けをします
sns.pairplot(data=raw, vars=['Age', 'Fare'], hue='Sex', kind='reg', diag_kind='kde', size=3,
plot_kws={'scatter_kws': {'alpha': 0.4},'line_kws': {'linestyle': '--', 'linewidth': .7}})
8-2. ヒートマップ
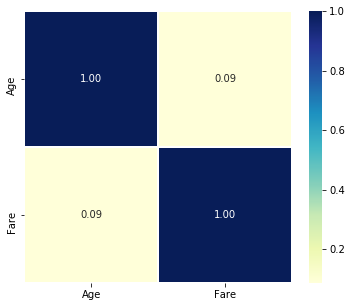
- pd.Dataframe.corr()で相関行列が算出できるので、それをSeabornのヒートマップで可視化します
- ヒートマップは色だけでなく、数値もセット見た方が正確に理解できるので、annot=Trueで数値を表示し、表示する桁数をfmt="1.2f"で指定しておくと見やすいです
plt.figure(figsize=(6, 5))
sns.heatmap(raw[['Age', 'Fare']].corr(), fmt="1.2f", annot=True, lw=0.7, cmap='YlGnBu')
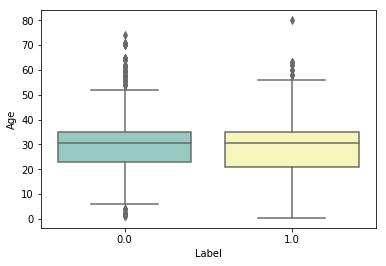
9. 相関(数値×カテゴリ)の可視化:ボックスプロット
- 数値×カテゴリデータはボックスプロットでカテゴリごとの数値傾向を見るとデータの関係性が理解できます
- SeabornのBoxplotで簡単に可視化できます
sns.boxplot(data=raw, x='Label', y='Age', palette="Set3")
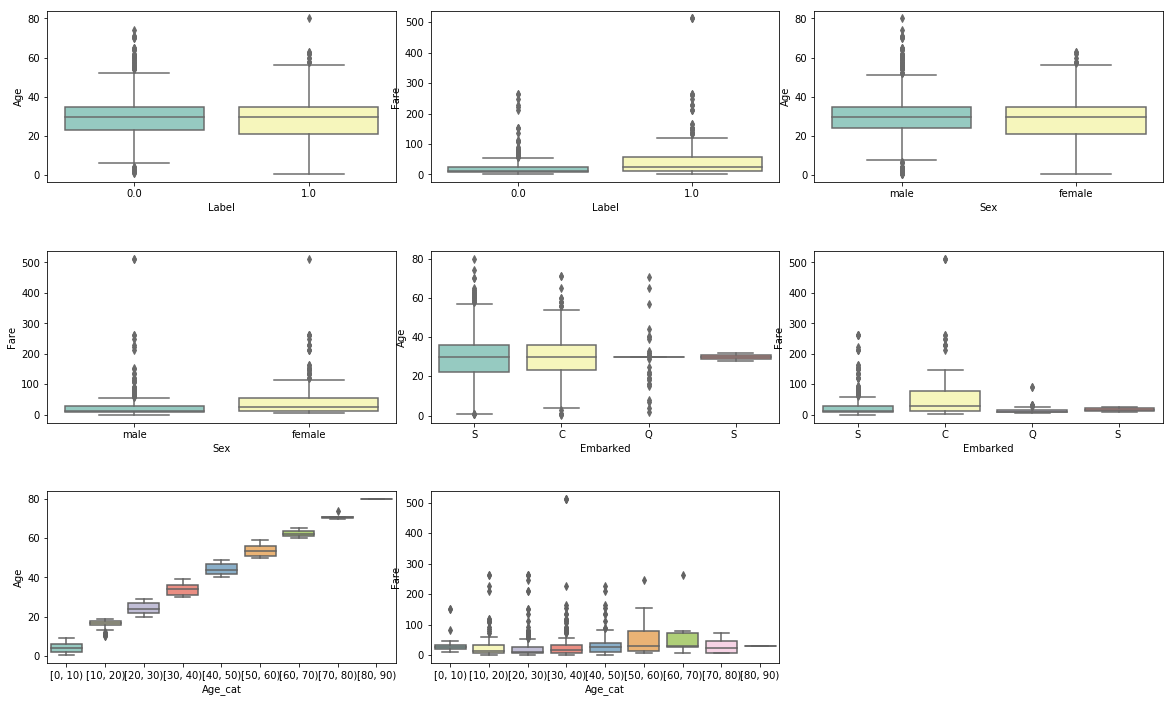
- 上記手続きを全ての数値×カテゴリの組み合わせに適用します
plt.figure(figsize=(20, 7))
plt.subplots_adjust(wspace=0.1, hspace=0.4)
i = 1
for x in ['Label', 'Sex', 'Embarked', 'Age_cat']:
for y in ['Age', 'Fare']:
plt.subplot(3, 3,i)
sns.boxplot(data=raw, x=x, y=y, palette="Set3")
i += 1
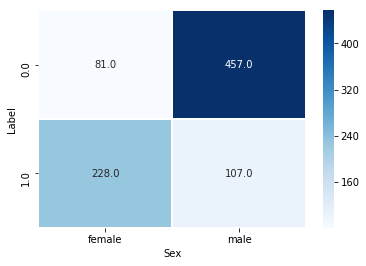
10. 相関(カテゴリ×カテゴリ)の可視化:ヒートマップ
- カテゴリデータの関係性を把握するには、クロス集計表を出力して、ヒートマップで視覚的に把握するのが分かりやすいです
- pd.crosstabでカテゴリデータのクロス集計表を作成して、それをSeabornのヒートマップで可視化します
sns.heatmap(pd.crosstab(raw['Label'], raw['Sex']), fmt="1.1f", annot=True, lw=0.7, cmap='Blues')
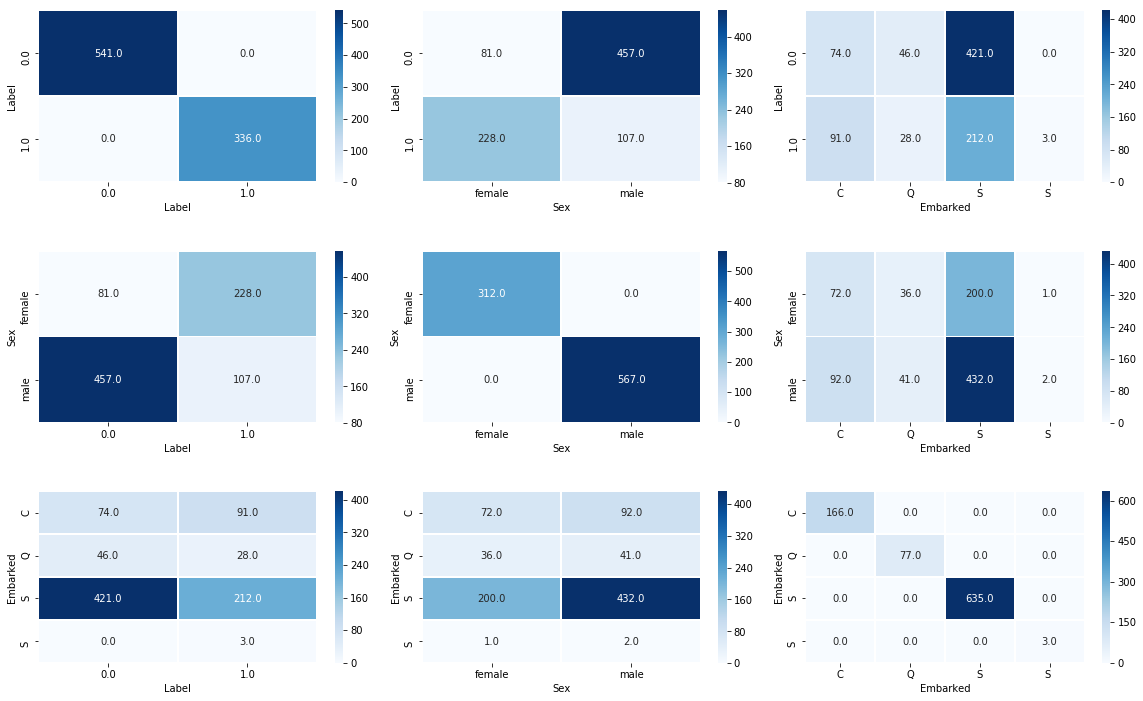
- 同様に全てのカテゴリ×カテゴリの組み合わせに適用します
plt.figure(figsize=(20, 7))
plt.subplots_adjust(wspace=0.1, hspace=0.4)
i = 1
for label_1 in ['Label', 'Sex', 'Embarked']:
for label_2 in ['Label', 'Sex', 'Embarked']:
plt.subplot(3, 3,i)
sns.heatmap(pd.crosstab(raw[label_1], raw[label_2]), fmt="1.1f", annot=True, lw=0.7, cmap='Blues')
i += 1
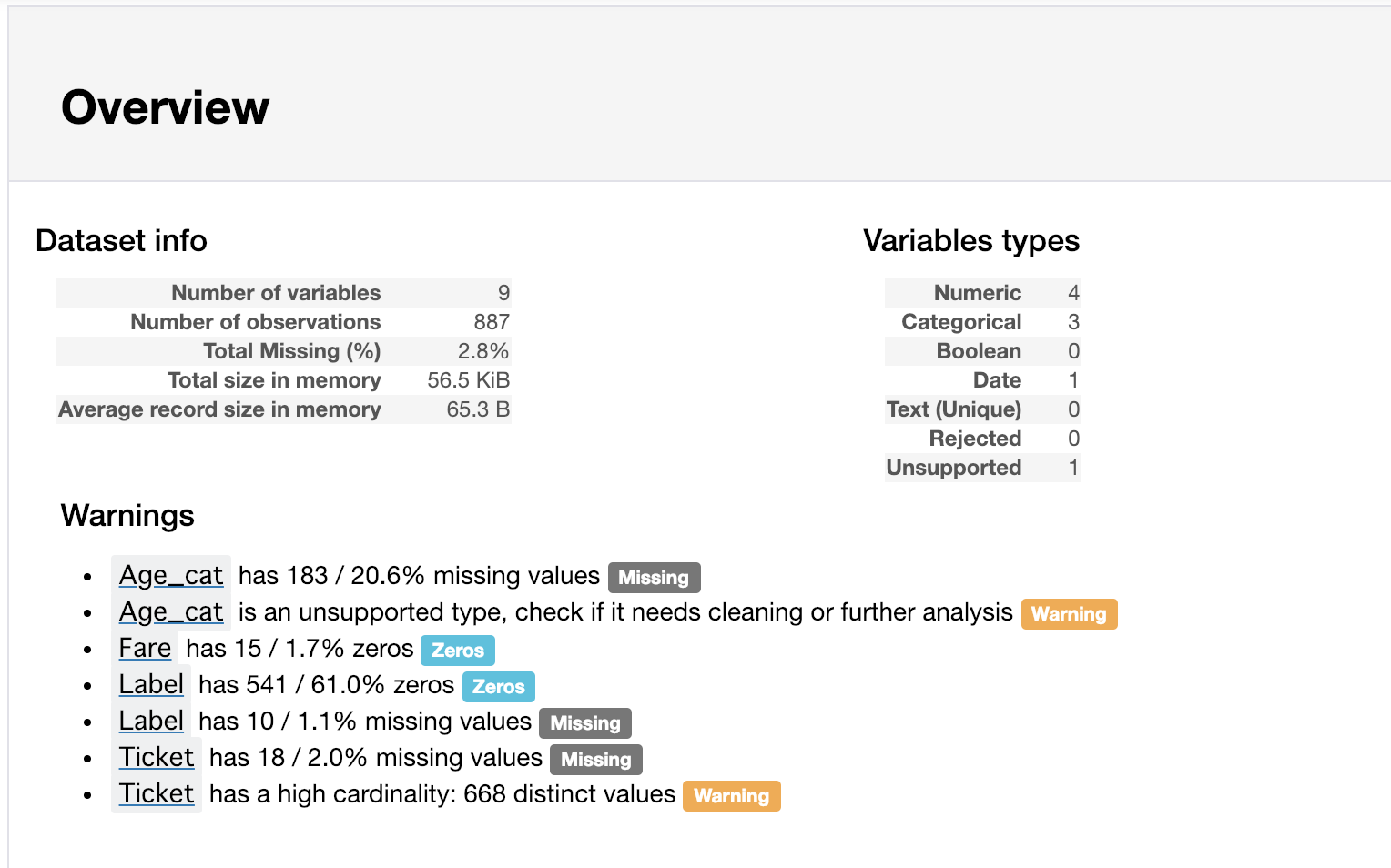
おまけ:pandas_profilingによるデータプロファイルレポートの自動作成
- pandas_profilingのProfileReportを使うとレポートを一括して作成できます
- 非常に便利な機能です
- ただし、個人的には便利すぎて、細かくデータ理解をせずに分かった気になってしまうので、あまり使ってないです
import pandas_profiling as pdp
report = pdp.ProfileReport(raw)
report# notebook上にレポートを表示
# report.to_html# html形式でレポートを出力
さいごに
- これまで何となくやってきた前処理・データ理解部分を改めて手順として整理してみました
- 分析のドメインによって他にも追加の前処理等々はあるかと思いますが、上述は非常に基本的で、どの分析プロセスにも共通する処理なのではないかと思います
- 他にも必要な処理や便利な方法があればフィードバックいただけますと幸いです