注意事項
-
この記事では、公開されているCP4D無償トライアルの始め方を、順を追って解説します。
-
環境もデータも準備済みですので、お気軽にご自由にお使いください。進める上で、多少順番が前後しても特に問題ありません。
-
使用可能期間はデフォルトでは1週間ですが、最大2週間まで延長可能です。
-
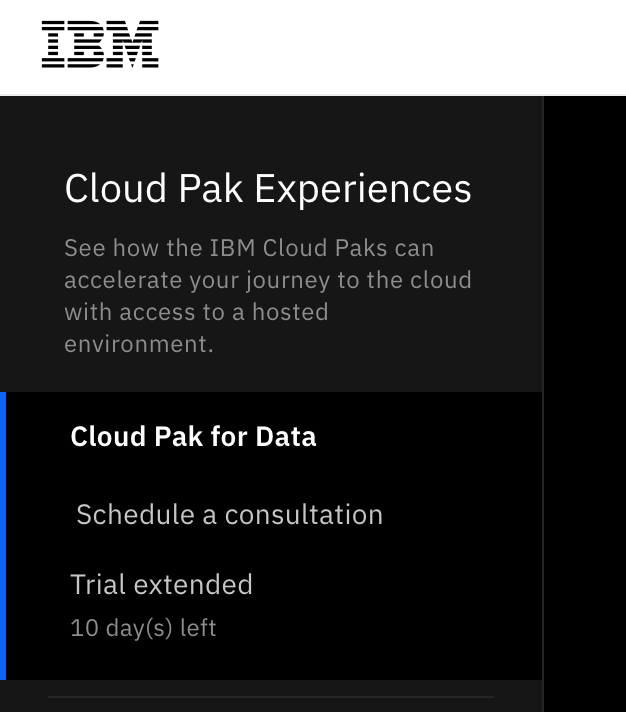
環境を起動する画面の左上に、期間を延長するリンクがあり、1週間使用期間を延長できるため、最大で14日間使用できます。(以下画像は、期間延長した後のもの。10 day(s) left の表記がありますね。)
-
IBMidというIBM CloudのIDが必要ですが、それは取得済み、と言う前提で解説します。
-
IBMidが未取得の方は、Qiitaでも取得の為の解説記事が多数(以下リンク等)ありますので、まずはそちらをご参照ください。
-
なおIBMid取得の前提条件として、有効なメールアドレスが必要です。
-
本手順は、2020年8月-10月時点で確認したものですが、サイトの構成等は予告なく変更される場合がありますので、ご注意下さい。なお途中の画面からガイドがポップアップで出てくるのですが、最後までガイドしてくれないようなので、途中から筆者の任意の ガイド項目を書いています。
-
本手順で使用されるCloud Pak for Data のバージョンは3.0.1です。(最新バージョンは、3.0.1です)
-
サポート対象のブラウザは、ChromeあるいはFireFoxです。それ以外のブラウザでは正しく動作しない可能性が有りますので、サポート対象のブラウザをお使いください。詳細は以下リンクをご参照ください。
-
また、画面のポップアップガイドとしては英語になりますが、解説は日本語で行います。なお、ブラウザの設定が日本語であれば、画面上の文言は(全てではないですが)日本語で表示されます。
-
また、所々ポップアップの短文が英語なのを機械翻訳で日本語にしたものを載せますが、DeepL(以下リンク)を使っています。
-
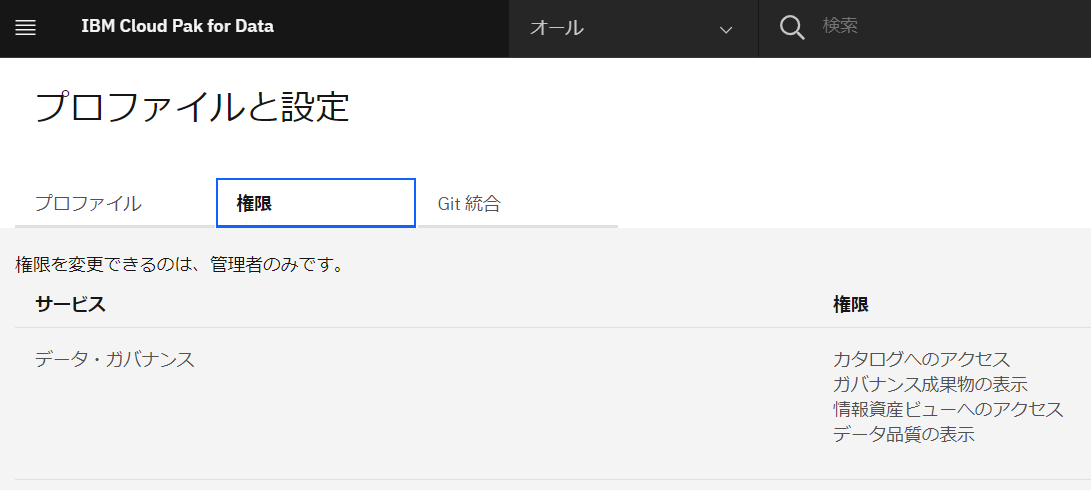
また、当該手順で使用されるユーザIDの権限は、以下の通りであり、各種資産やカタログの表示はできますが、カタログへの登録や承認はできません。本手順の途中でカタログへの登録、と言う箇所もありますが、オペレーションとして実施は出来ても実際にはカタログへは登録されないようです。(下記画面は、右上のユーザアイコンをクリックし、「プロファイルと設定」をクリックすると表示されます。)
-
当該環境には既にテスト用のデータや、接続済みのデータベース(Db2とMongoDB)も準備されていますので、そちらを使っていただけます。
-
また、製品の公式ドキュメントは、こちらになります。 https://www.ibm.com/support/knowledgecenter/en/SSQNUZ_3.0.1/cpd/overview/welcome.html
-
この記事では「Collect」編と「Organize」編に焦点を絞って記載しますが、これはIBMが提唱する「AI-Ladder(AIのはしご)」という概念に含まれるものです。「AI-Ladder」については、こちらをご参考にしてみてください。
手順
1. Cloud Pak Experiences にアクセス
- 以下サイトにアクセス。
画面を下にスクロールすると、以下アクセスの為のボタンが見えてきます。
以下から、「Collect」「Organize」「Analyze」といったテーマごとに「Log in to explore」ボタンをクリックして各環境にアクセスします。
ログイン画面です。登録済みのメールアドレスを入力して、「次へ」をクリックしてください。(ブラウザや設定により若干画面出力に差異がある場合があります)
パスワードを入力します。
評価版へのアクセスに同意する画面です。営業からのご連絡を希望される方はチェックを入れてください。

画面を下にスクロールすると、以下アクセスの為のボタンが見えてきます。
以下から、「Collect」「Organize」「Analyze」といったテーマごとに「Explore」ボタンをクリックして各環境にアクセスします。
なお、3環境どれでも使用するID/権限は同一ですが、ポップアップしてくるガイドの種類が異なります。
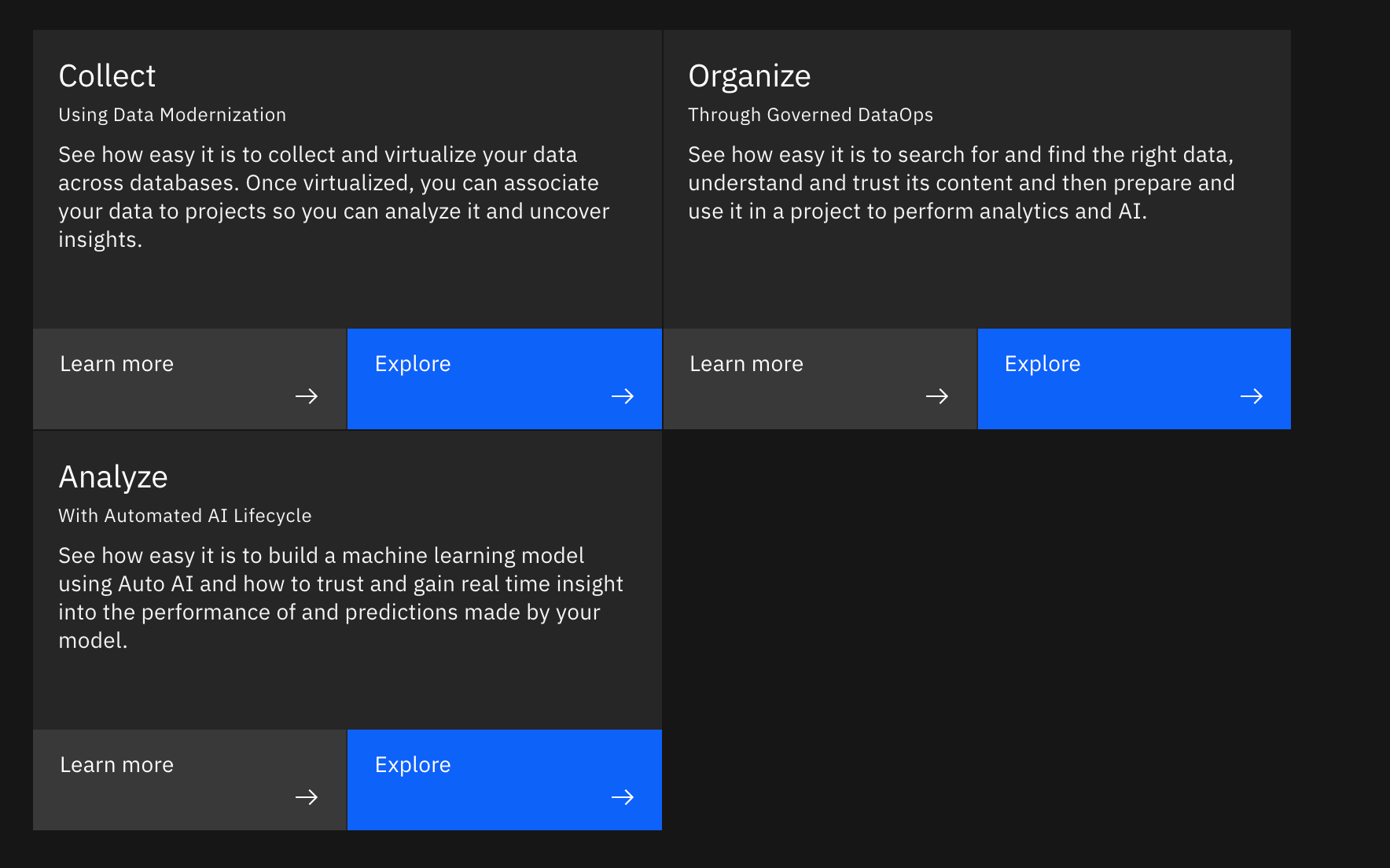
2. Collect
- 以下は、「Collect」のExploreボタンの箇所に記載されていた概説の文言の機械翻訳です。
「データの近代化を利用する
データベースにまたがるデータの収集と仮想化がいかに簡単にできるかをご覧ください。仮想化したら、データをプロジェクトに関連付けることができるので、データを分析して洞察を得ることができます。」
- 以下、Exploreボタンをクリックすると環境が構築されますので、少し待ちます。
- 環境ができると、ウインドウの色が緑に変わります。ポップアップブロッカーが有効な場合は自動的に管理画面が出ませんので、ご注意ください。と書かれています。
- 新しいタブが開いて管理画面が現れます。ガイドによるツアーが始まります。
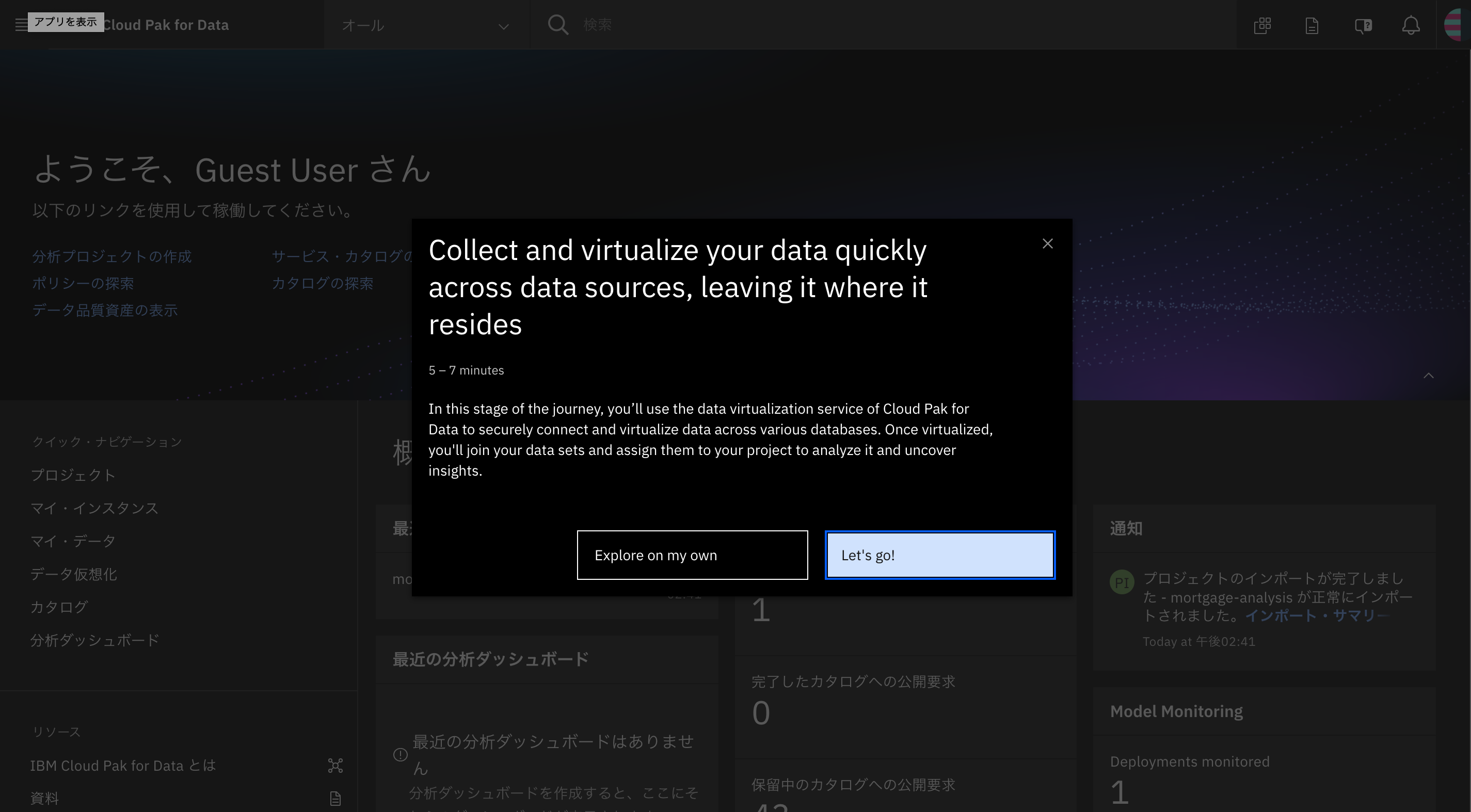 - なお、以下は「Let's go!」の上部に記載のあった短文の機械翻訳です。
- 「データソース間でデータを迅速に収集し、仮想化することで、データが存在する場所にデータを残すことができます。この段階では、Cloud Pak for Dataのデータ仮想化サービスを使用して、さまざまなデータベースにまたがるデータを安全に接続し、仮想化します。仮想化が完了したら、データセットを結合し、プロジェクトに割り当てて分析し、インサイトを明らかにします。」
- ここでは、ガイドによるツアーにしたがって見ていきます。「Let's go!」をクリックします。
- なお、以下は「Let's go!」の上部に記載のあった短文の機械翻訳です。
- 「データソース間でデータを迅速に収集し、仮想化することで、データが存在する場所にデータを残すことができます。この段階では、Cloud Pak for Dataのデータ仮想化サービスを使用して、さまざまなデータベースにまたがるデータを安全に接続し、仮想化します。仮想化が完了したら、データセットを結合し、プロジェクトに割り当てて分析し、インサイトを明らかにします。」
- ここでは、ガイドによるツアーにしたがって見ていきます。「Let's go!」をクリックします。
- 画面左上に現れる「Open the Navigation Menu」の近くの「横線が4本並んでいるアイコン(ハンバーガーメニューと言うらしいです)」をクリックします。
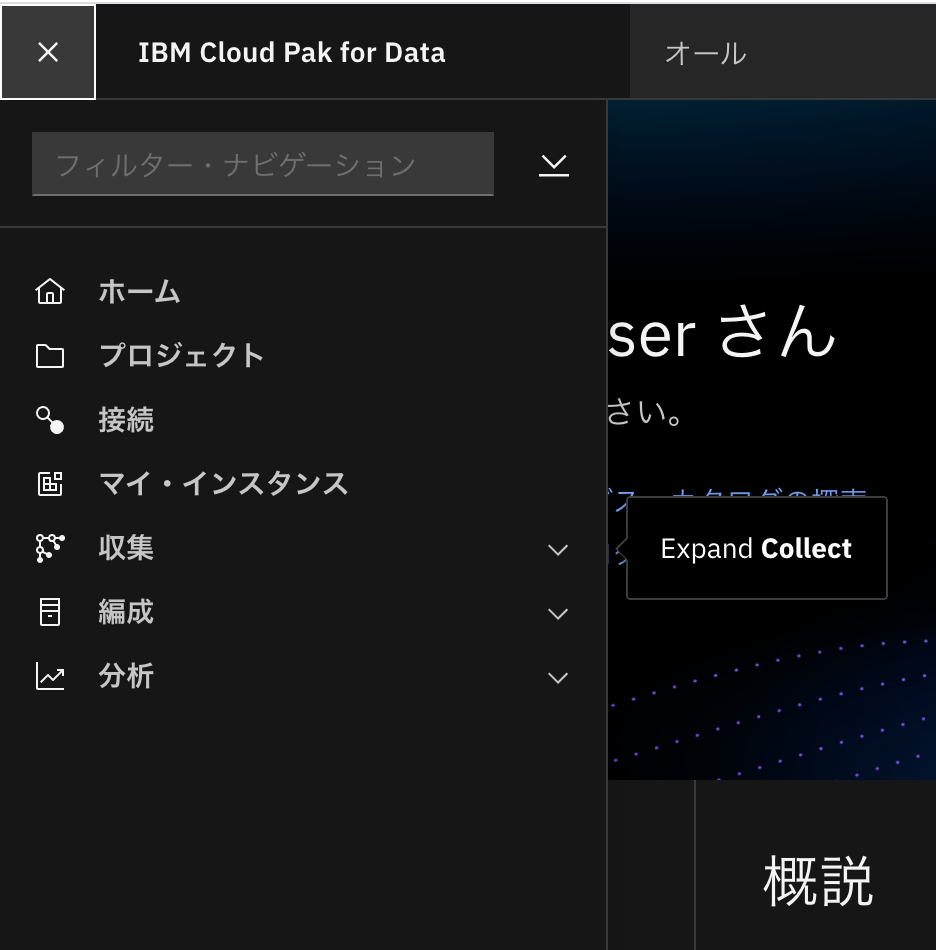
- ガイドに「Expand Collect」と記載がありますので、ここでは「収集」の箇所をクリックします。
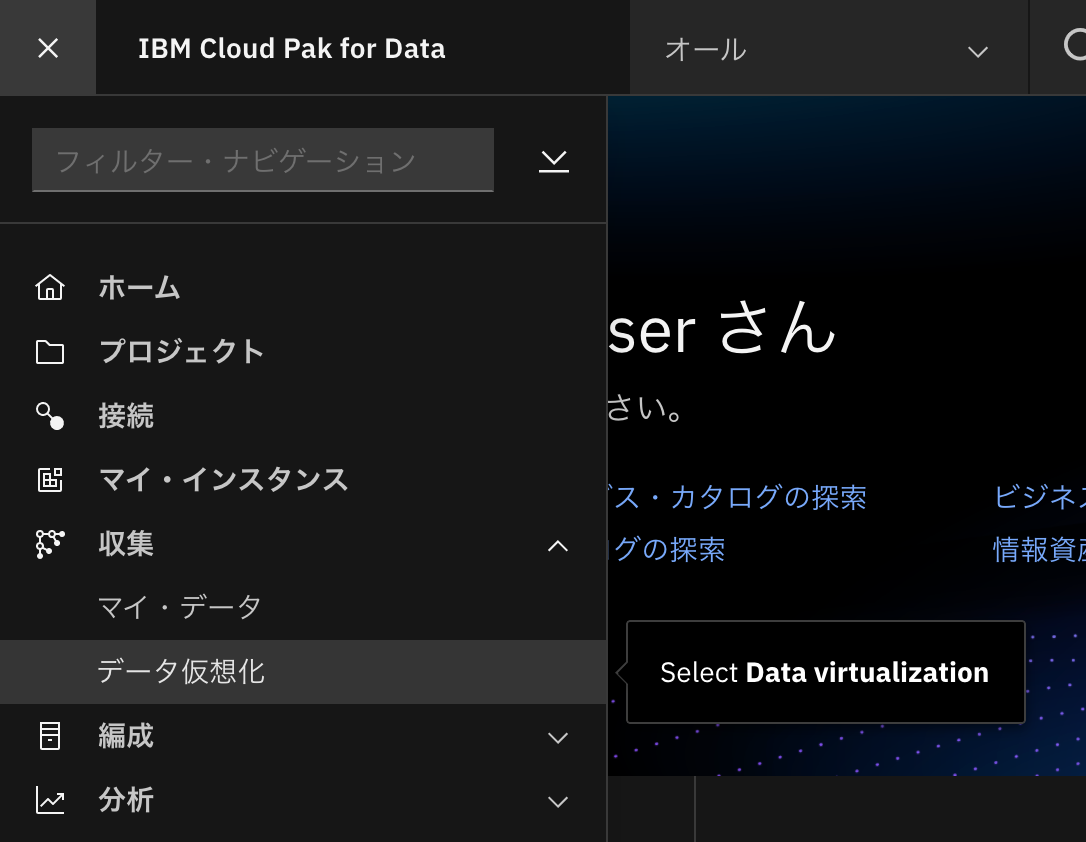
- 「データ仮想化」をクリックします。
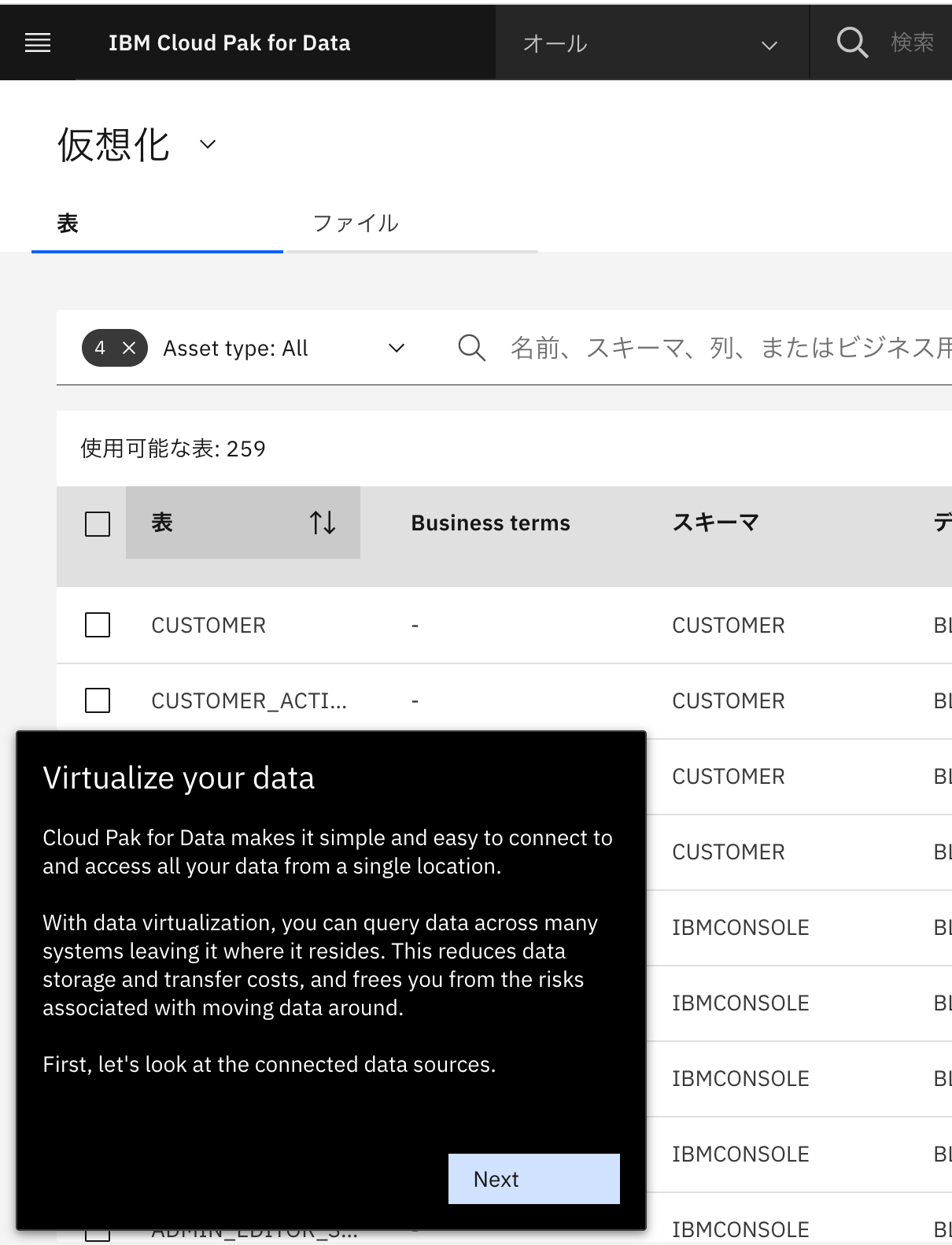
-
以下、ガイドの英語の翻訳文です。
-
「データの仮想化
Cloud Pak for Data を使用すると、1 つの場所からすべてのデータに簡単に接続してアクセスすることができます。データの仮想化により、データが存在する場所を残したまま、多くのシステムにまたがってデータを照会することができます。これにより、データの保管と転送のコストが削減され、データの移動に伴うリスクから解放されます。まず、接続されたデータソースを見てみましょう。」 -
「Next」をクリックします。
-
左上の「仮想化」の箇所がドロップダウンメニューになっていますので、そこをクリックします。
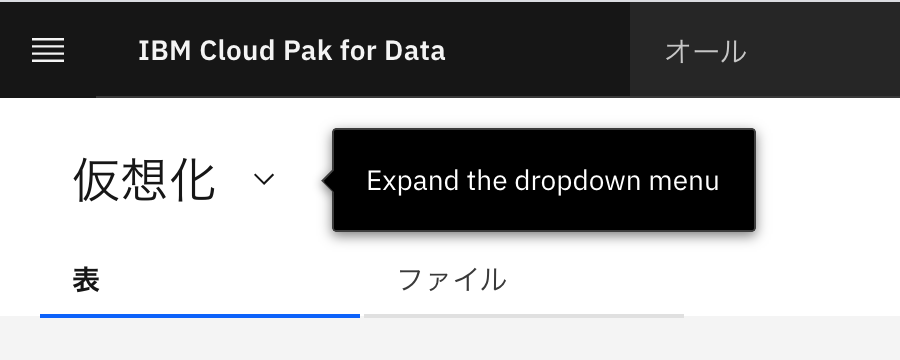
なお、以降は画面のガイドがでなくなりますので、筆者の勝手により進行します。(V2.5のExperience(以下リンク参照)に準じる進行をします。)
次に、このデータ仮想化のプルダウンメニューにどういうものがあるのかを一通り見ていきます。
其のあと、実際のデータ仮想化を実行します。
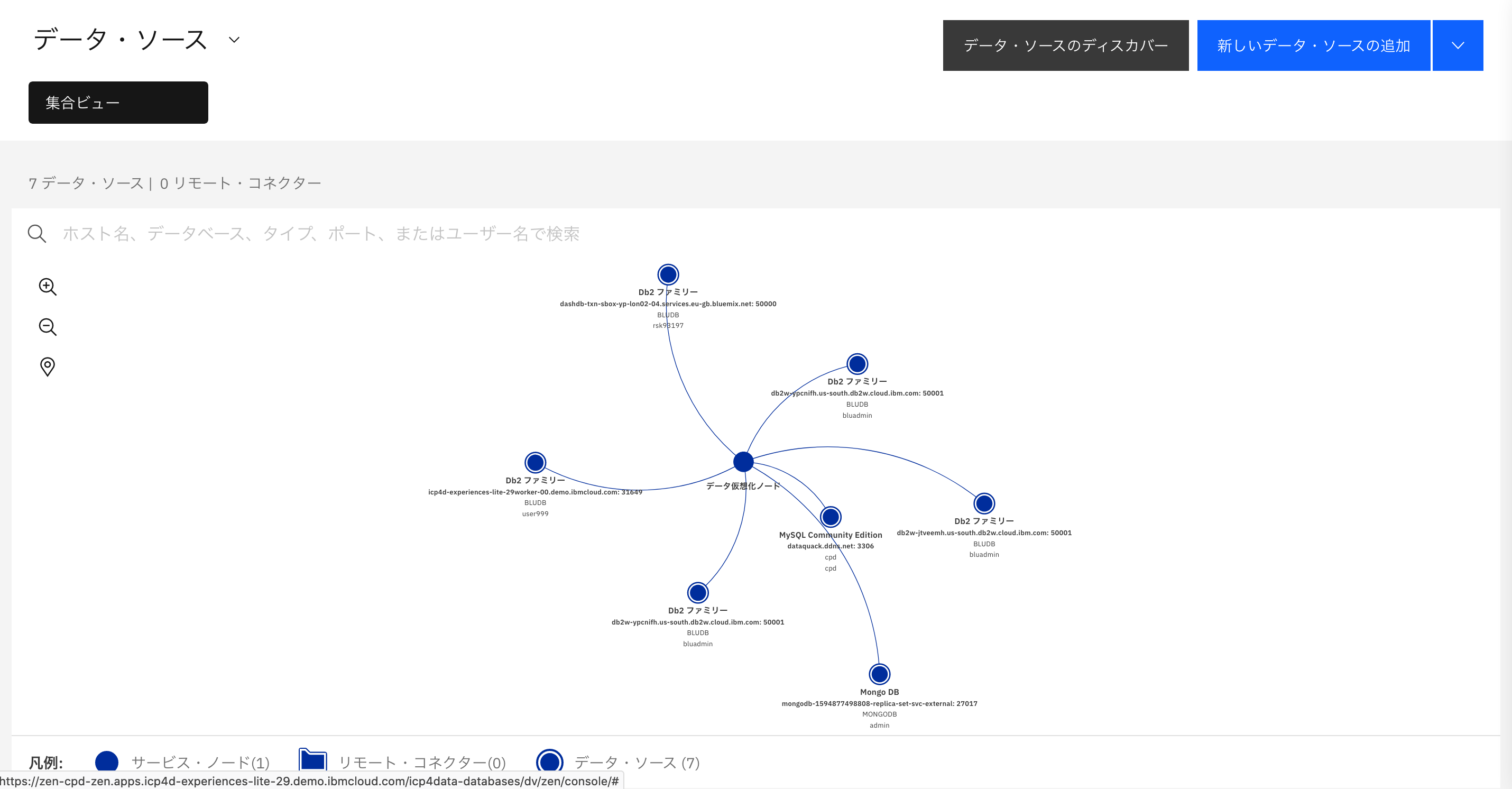
「データ・ソース」
左上のクリックダウンメニューからクリックすると、このようにCP4Dに接続されたデータソースが確認できます。この環境では既に、Db2やMongoDBが接続済みであることが分かります。
「仮想化」
左上のクリックダウンメニューからクリックすると、このように仮想化の対象となるデータベースが一覧できます。

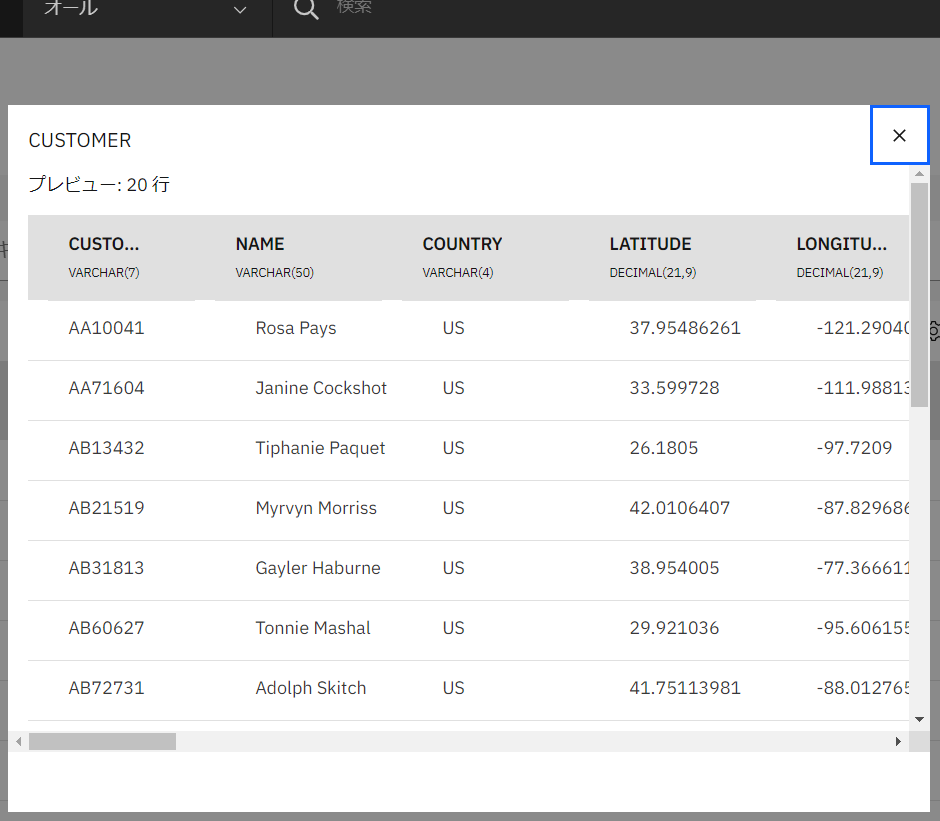
データのプレビュー
- 各列の右端にカーソルを合わせると目玉(プレビュー)のマークが現れます。クリックすると、その表のプレビューが見られます。

「自分の仮想化データ」
左上のクリックダウンメニューからクリックすると、当該ユーザが仮想化したデータベースが一覧できます。(この場合はまだ仮想化していないので、対象はありませんが)
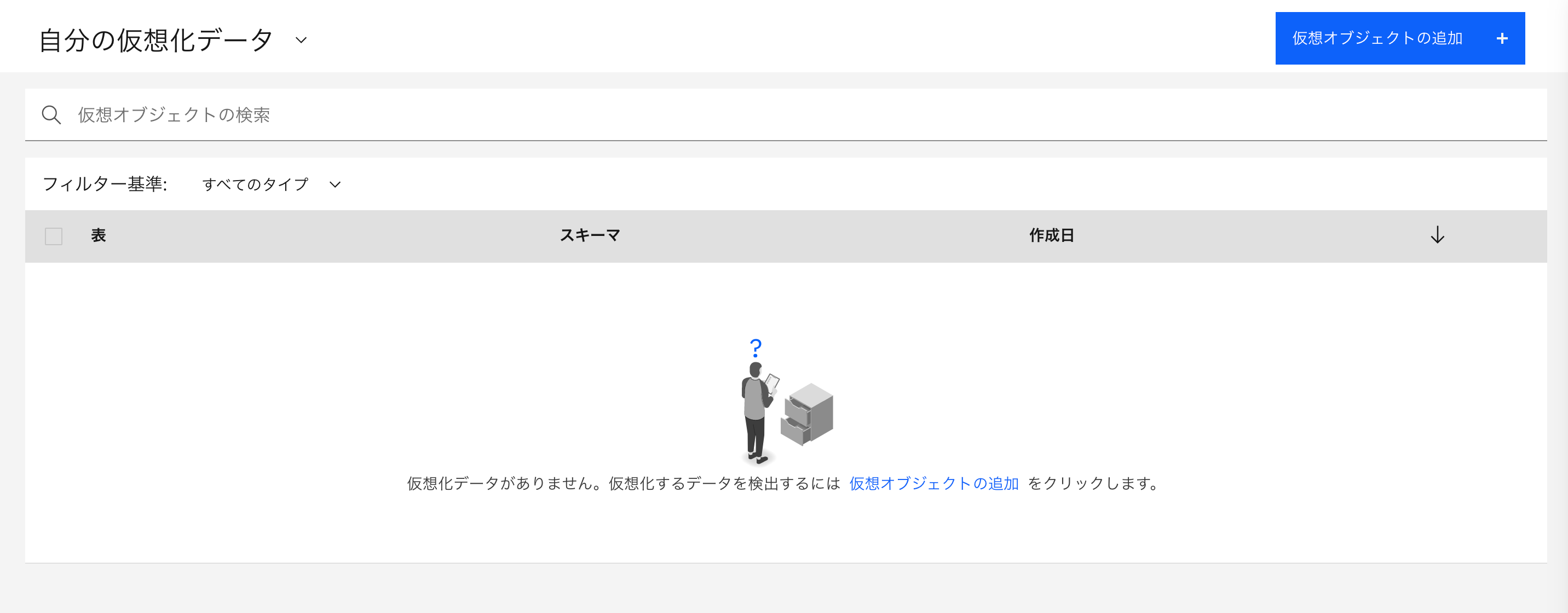
「SQLエディター」
左上のクリックダウンメニューからクリックすると、各種SQLを発行できる画面になります。
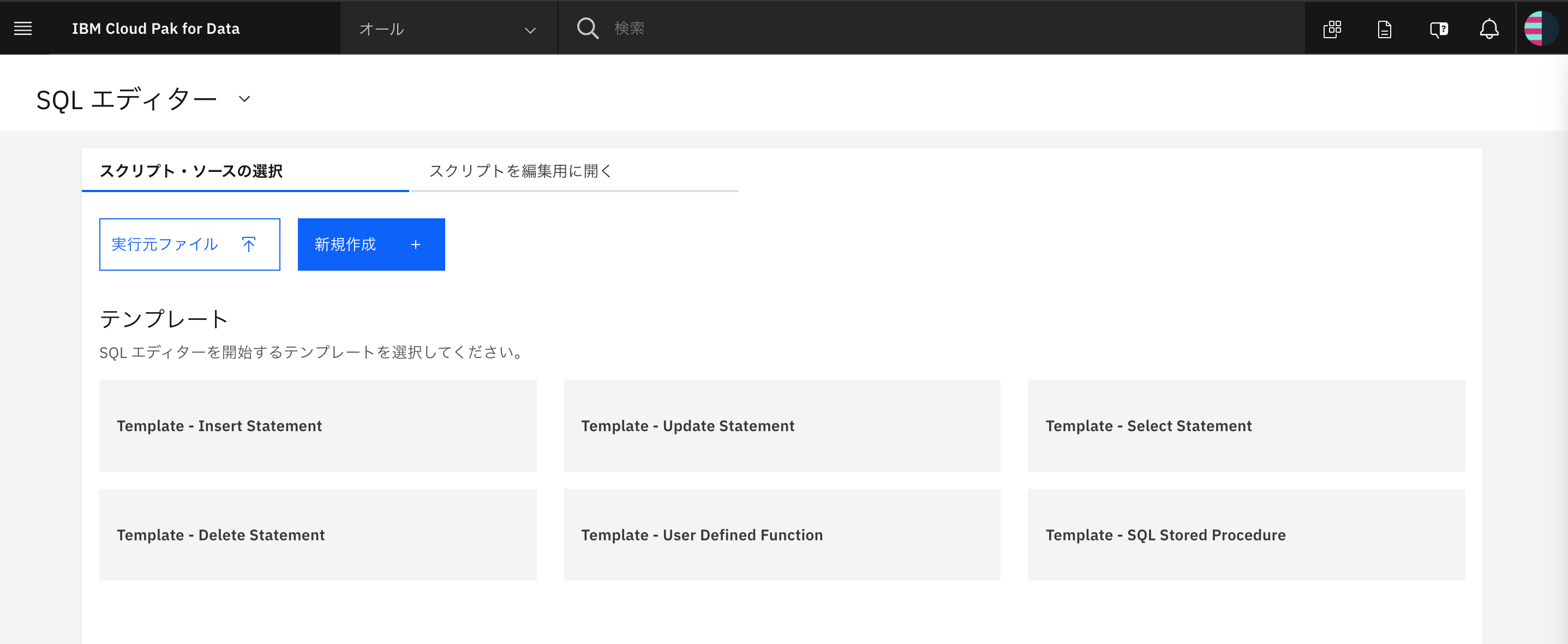
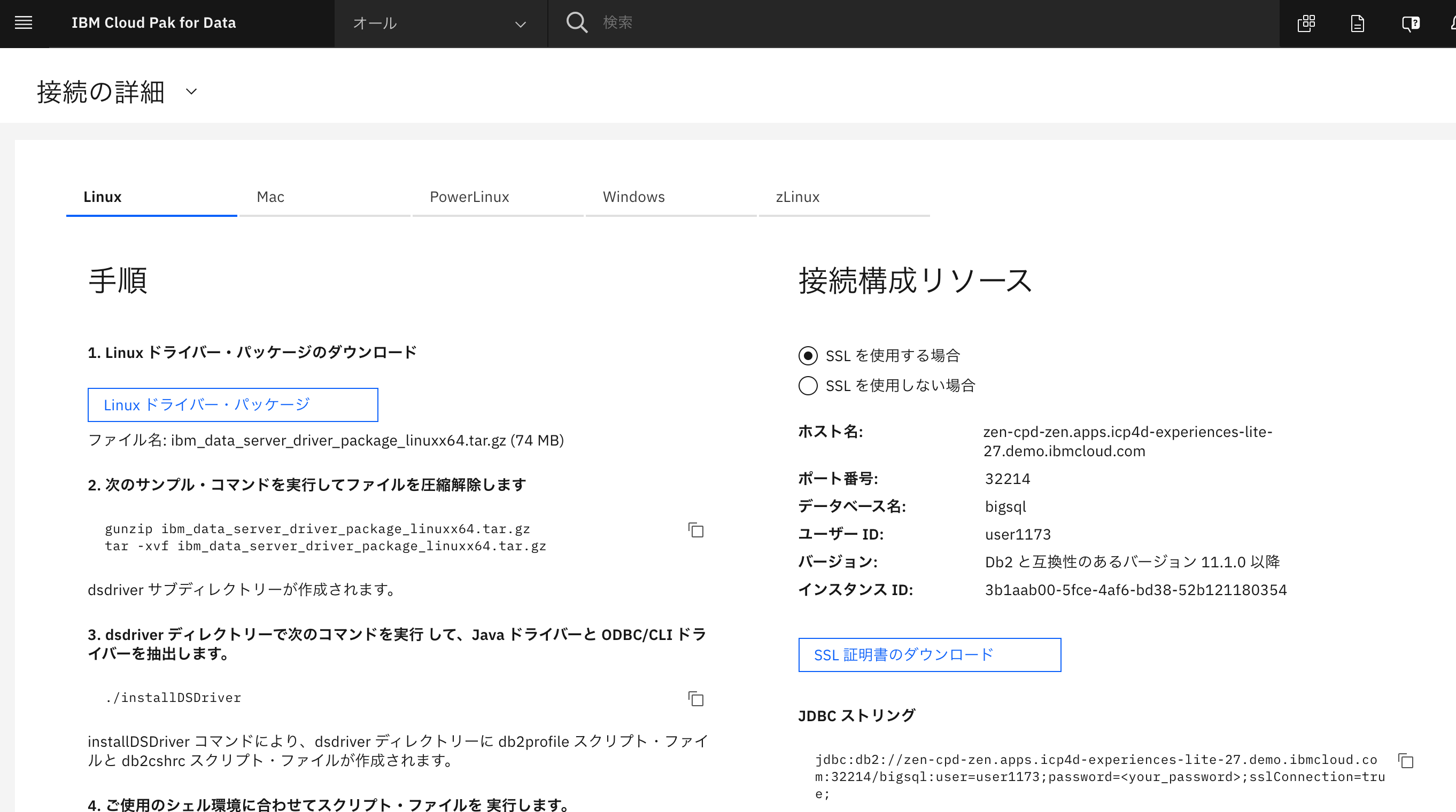
「接続の詳細」
左上のクリックダウンメニューからクリックすると、仮想化データに接続する為のドライバのインストール画面になります。
「サービス設定」
左上のクリックダウンメニューからクリックすると、アクセスしているCP4Dへの接続情報、のノードやインスタンスの情報について記載された画面になります。

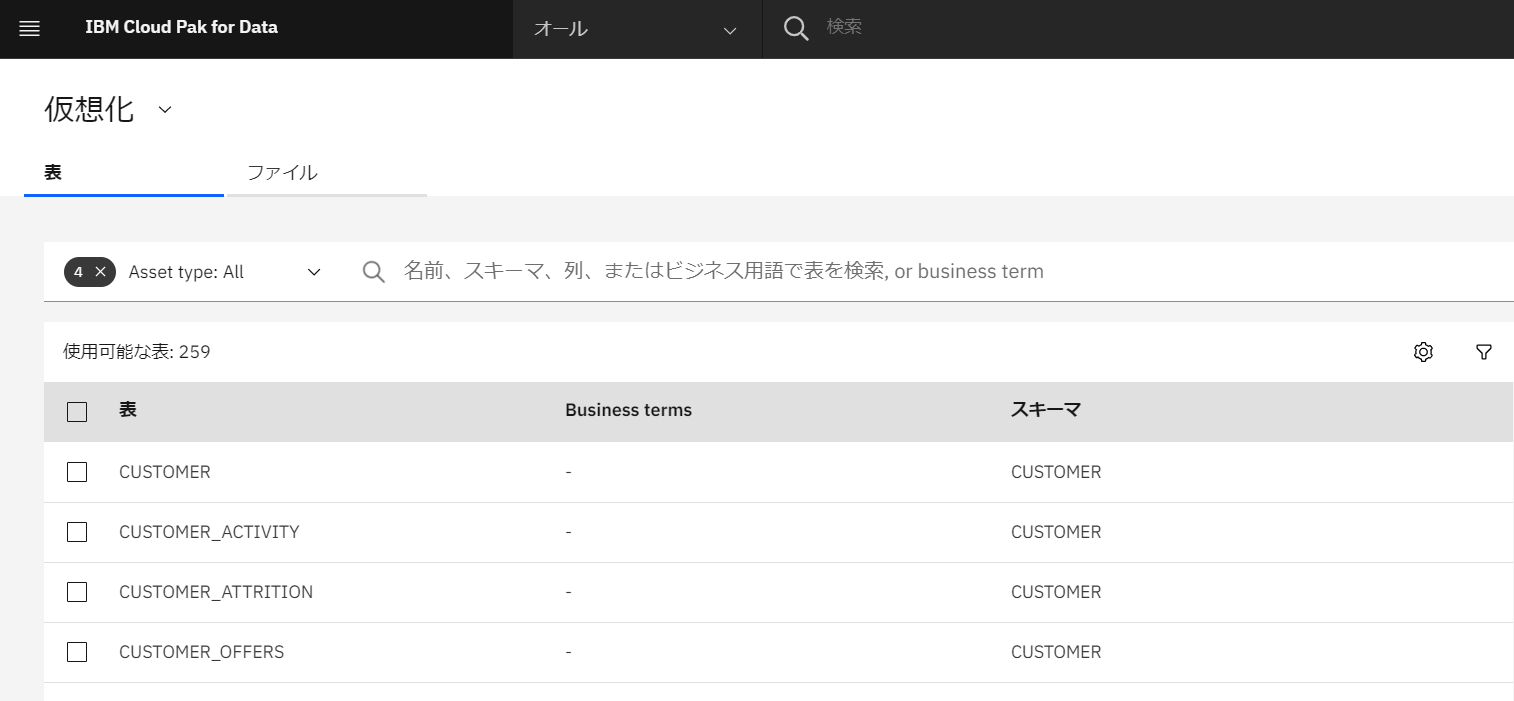
「データの仮想化」
「仮想化」(再掲)
左上のクリックダウンメニューからクリックすると、再び仮想化の対象となるデータベースが一覧できます。
列名が見づらいので、歯車のアイコンをクリックしてチェックボックスから全部チェックを外すことで、余計な列名を除外します。

-
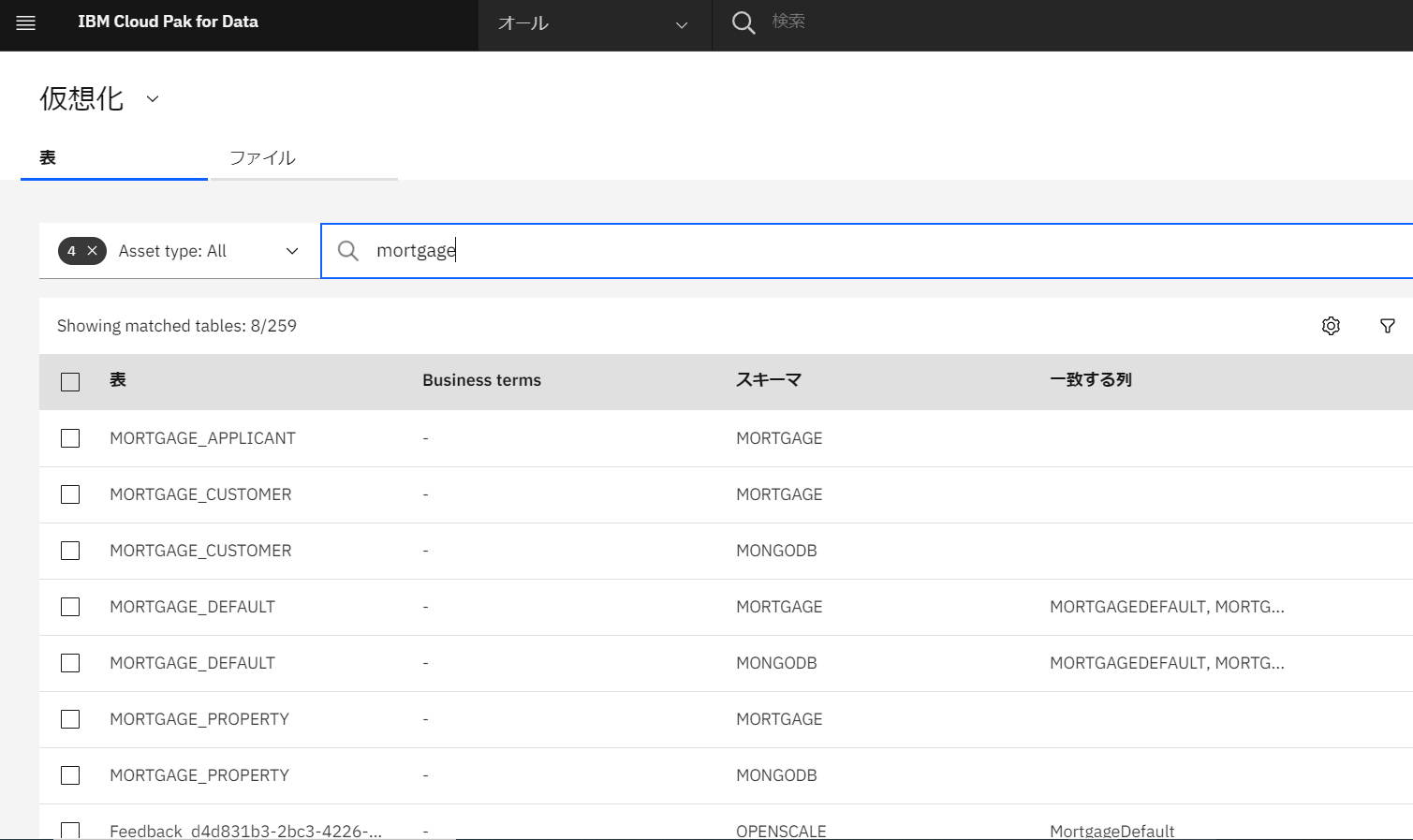
債券データを検索します。「mortgage」と入力します。
-
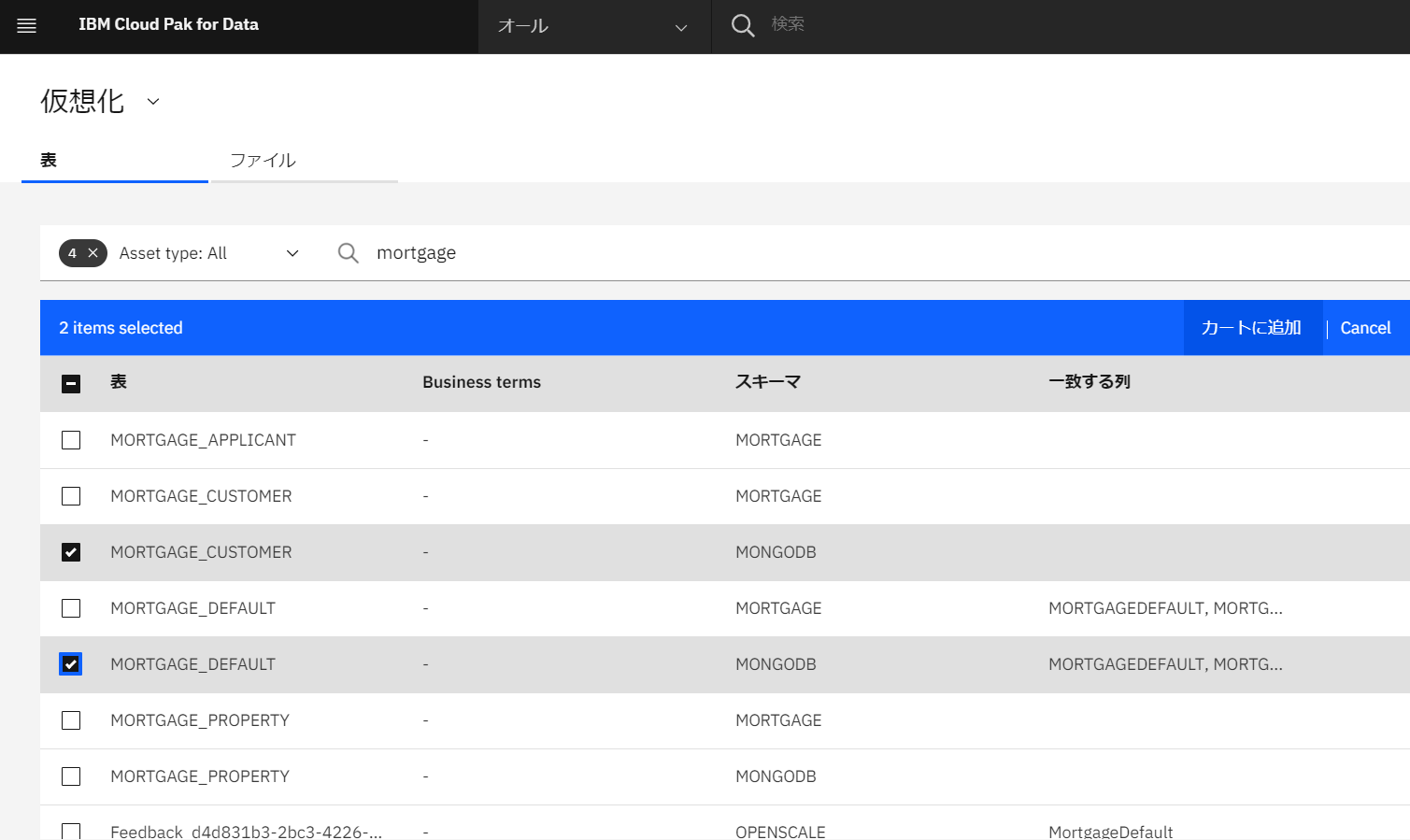
「MORTGAGE_CUSTOMER」と「MORTGAGE_DEFAULT」のチェックボックスにチェックを入れ、「カートに追加」をクリックします。
-
「カートの表示」をクリックします。

-
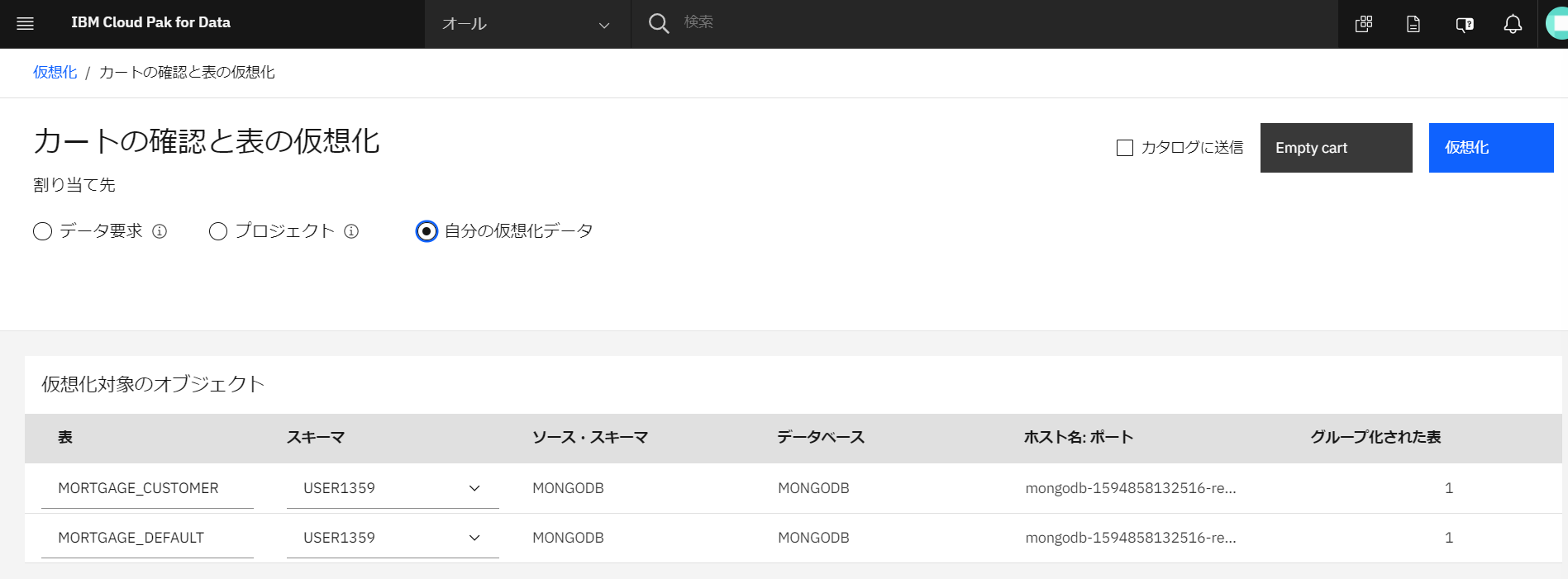
割り当て先として「自分の仮想化データ」のラジオボタンを選択し、「カタログに送信」のチェックを外して、「仮想化」をクリックします。
-
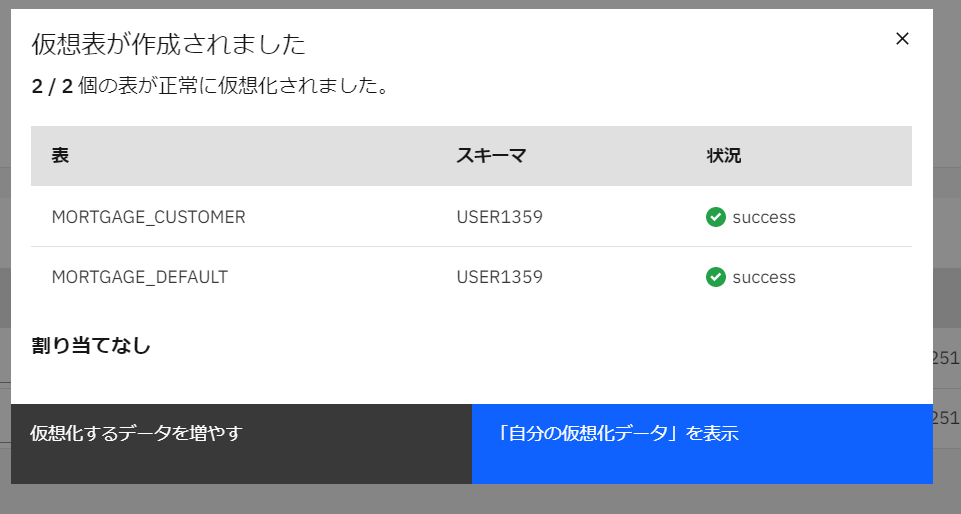
仮想表が作成されました。「自分の仮想化データを表示」をクリックします。
-
仮想化した表が表示されていることを確認します。

-
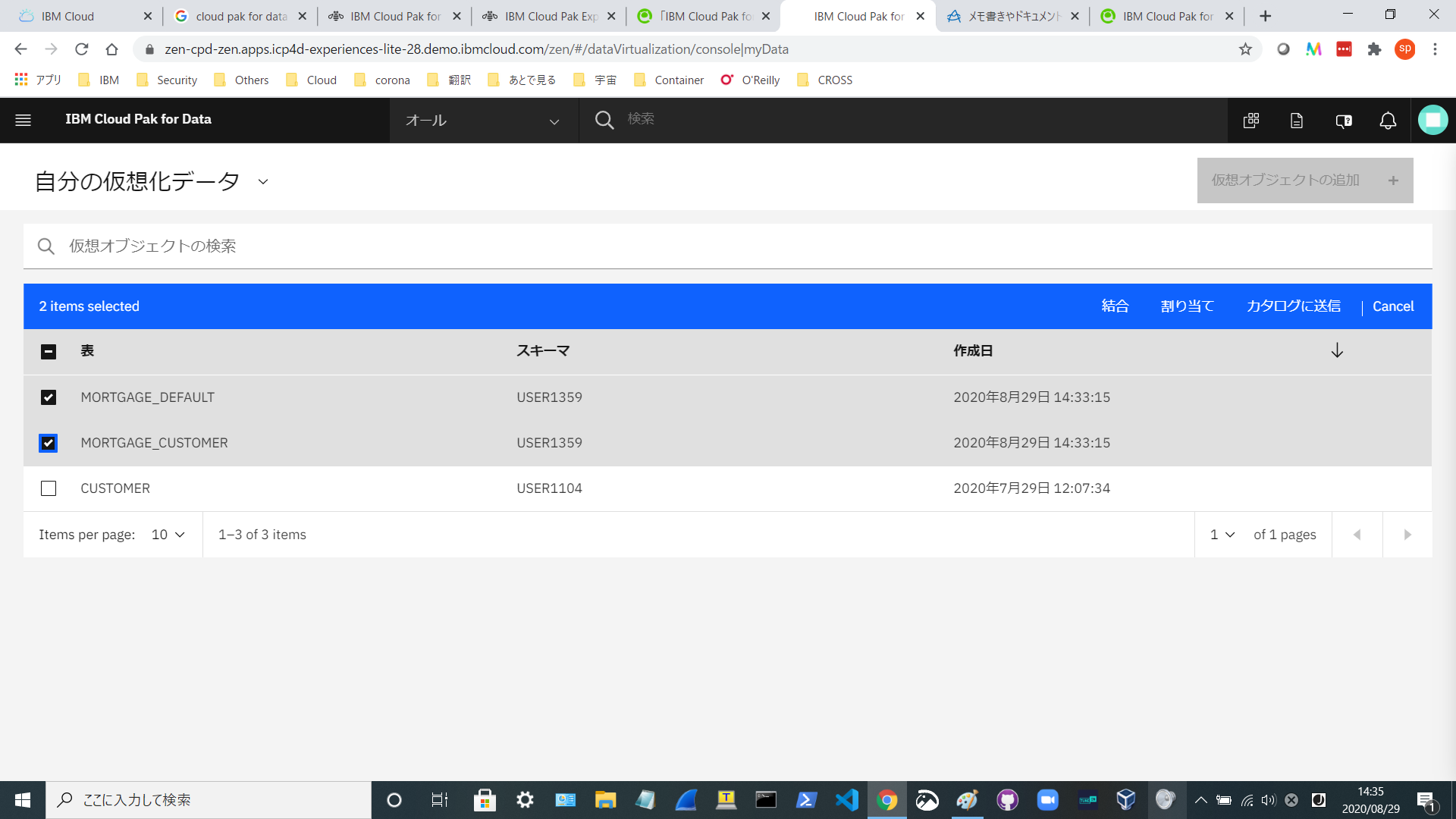
仮想化した表を選択して、「結合」をクリックします。
-
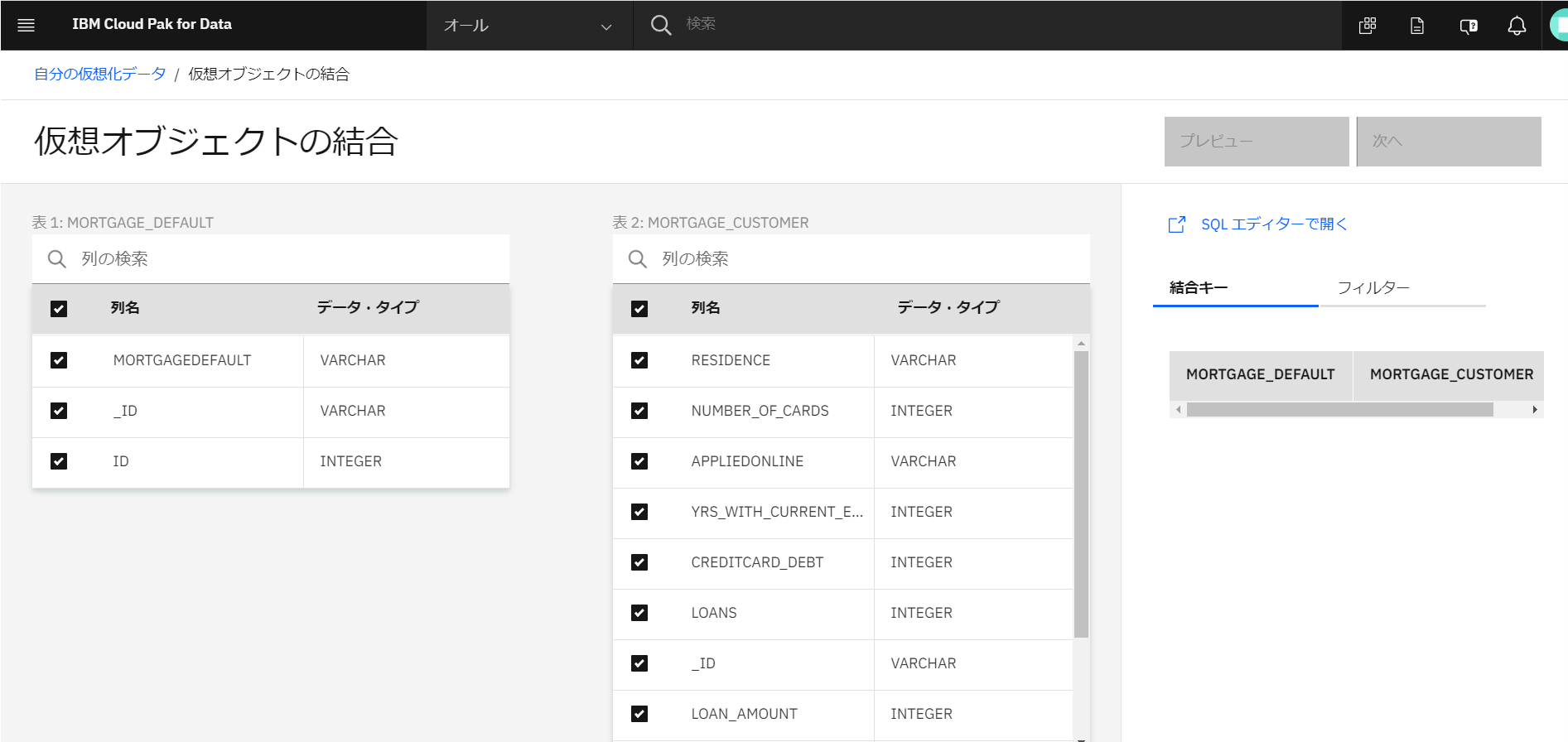
「仮想オブジェクトの結合」画面です。
-
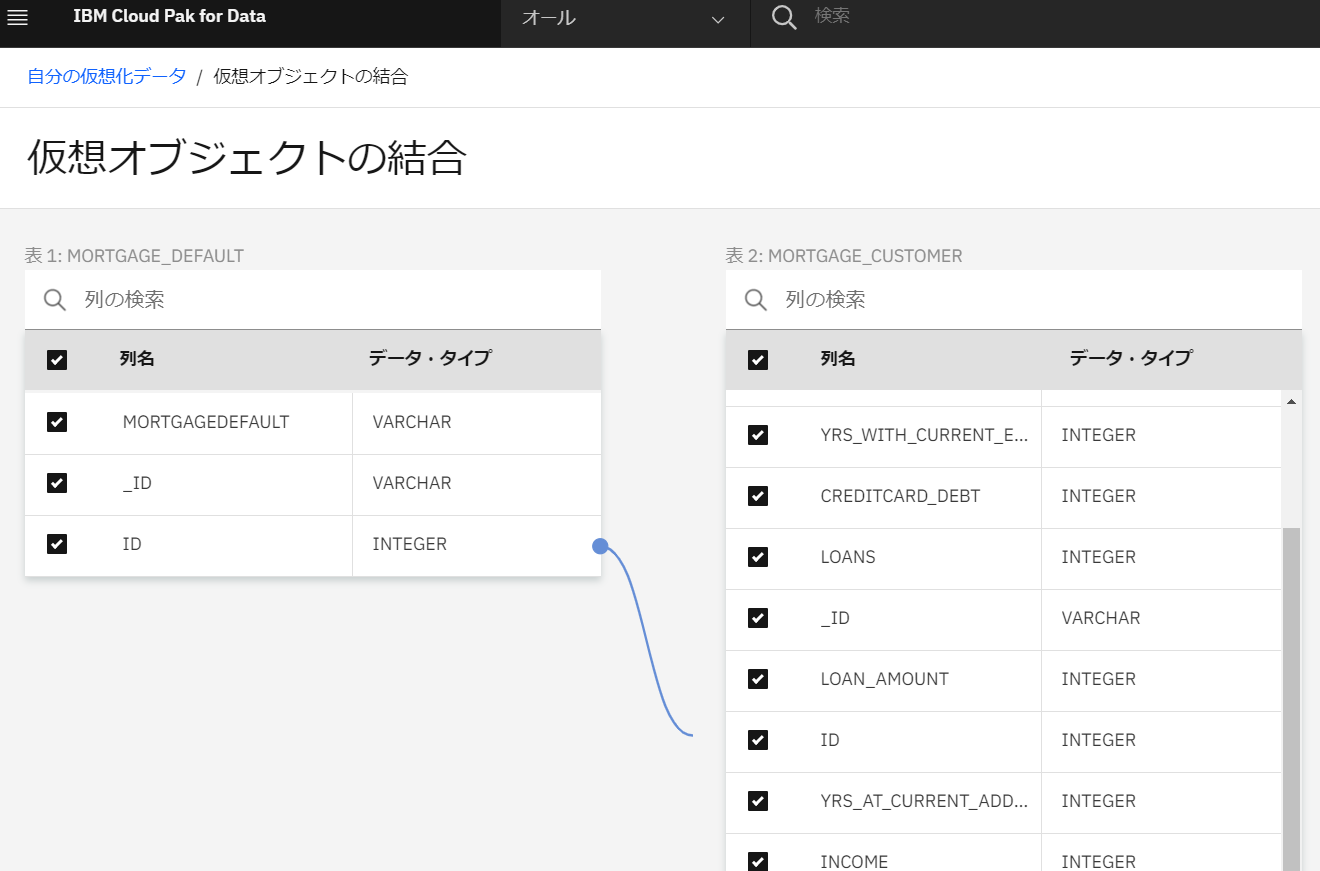
結合する為のキーとなる共通項目の列同士(今回は左側の「ID」)を選択し、右側の「ID」にドラッグアンドドロップします。
-
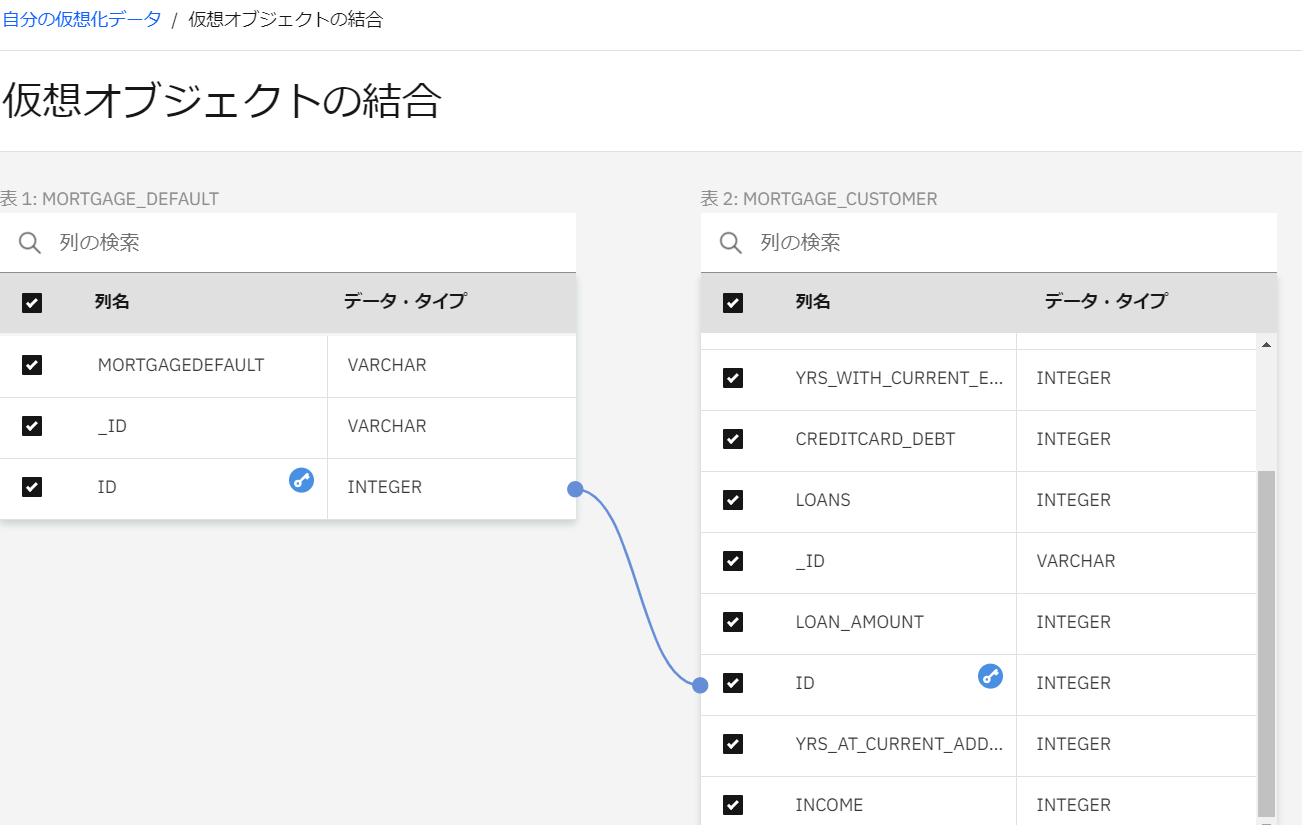
共通する項目により、表同士が結合されました。
-
ひとまずチェックを全部外します。(この操作は任意です。外さなくても構いません。)

-
選択したい項目を選んでチェックボックスにチェックを入れ、「プレビュ-」をクリックします。(選択項目は任意です。全部選んでも大丈夫です。)
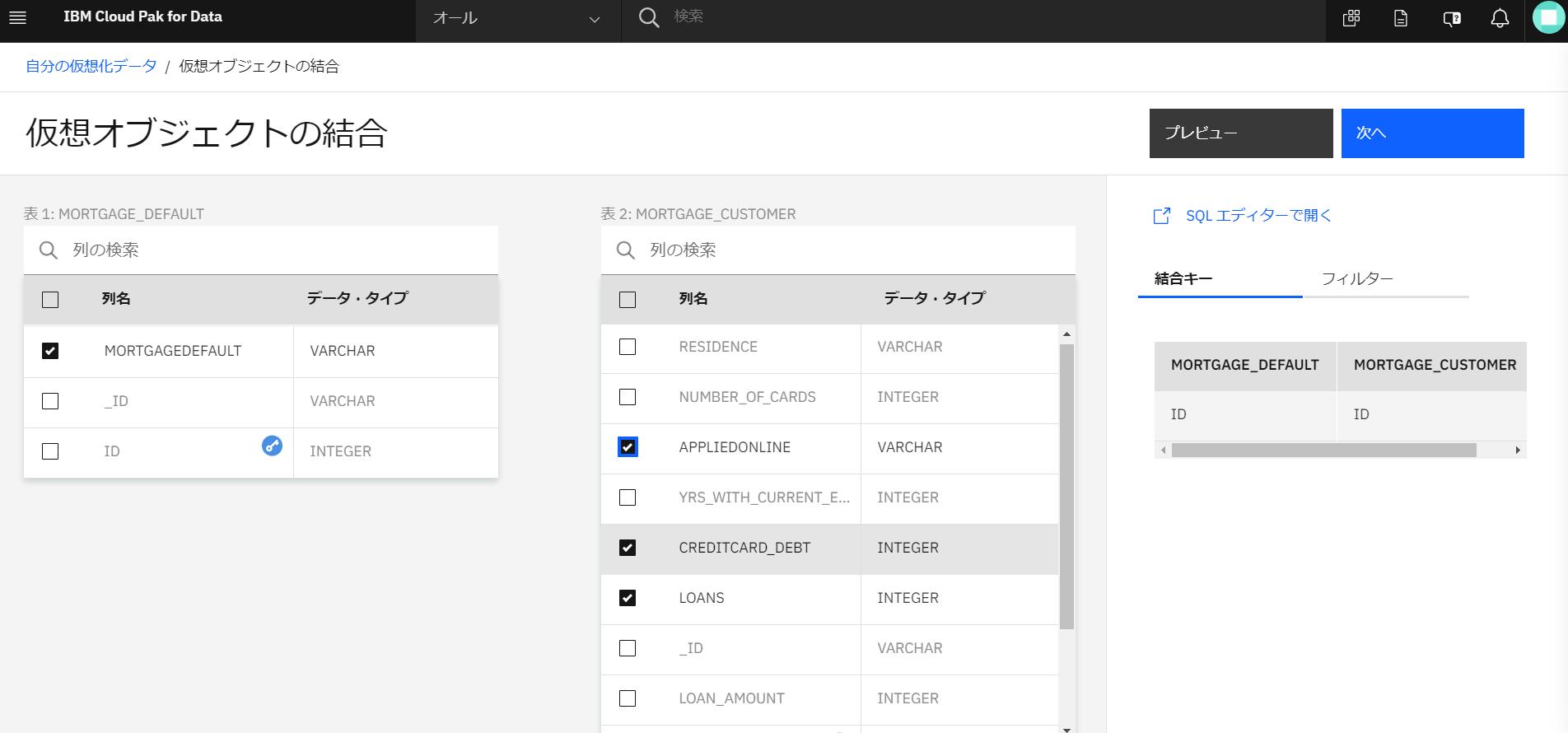
-
なお、ここで選んだ各種項目がどういう意味であるのか、については、別途3.Organizeでビジネス用語の確認ということで見ていきます
-
プレビュー画面を確認し、右上の「×」をクリックして画面を戻ります。
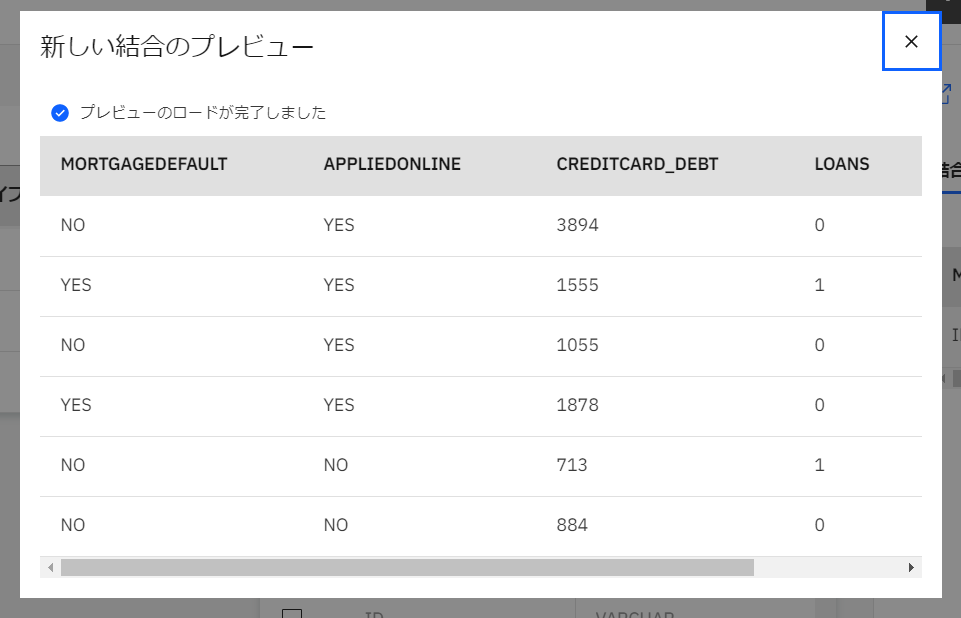
-
「次へ」をクリックします。
-
列名を編集できます。ここでは編集せずに「次へ」をクリックします。(お好きな名前に変えていただいても結構です)
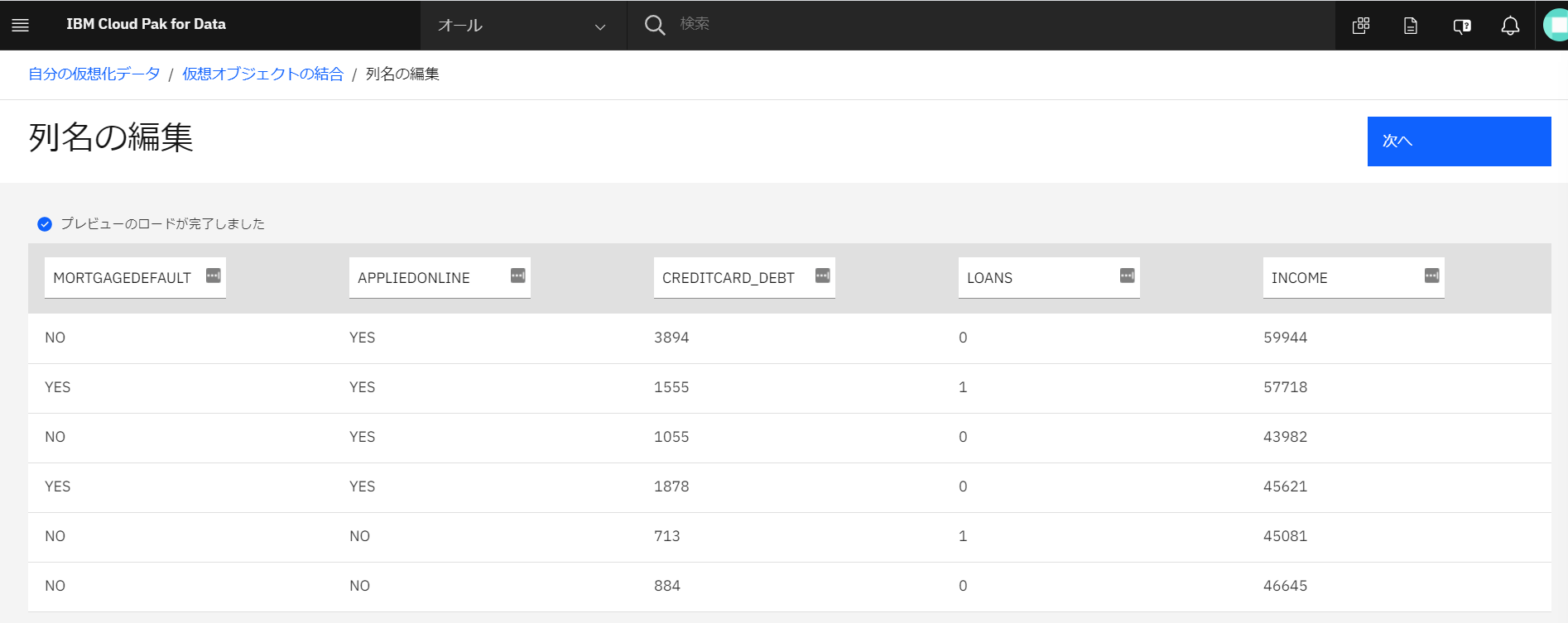
-
割り当て先として「自分の仮想化データ」を選択し、仮想表の名前を入力し、「カタログに送信」にチェックを入れたまま、「ビューの作成」をクリックします。(なお、今回の環境ではカタログへの登録を承認するデータスチュワード権限を持つユーザはいませんので、カタログ上で今登録されたデータは見られないようです。)
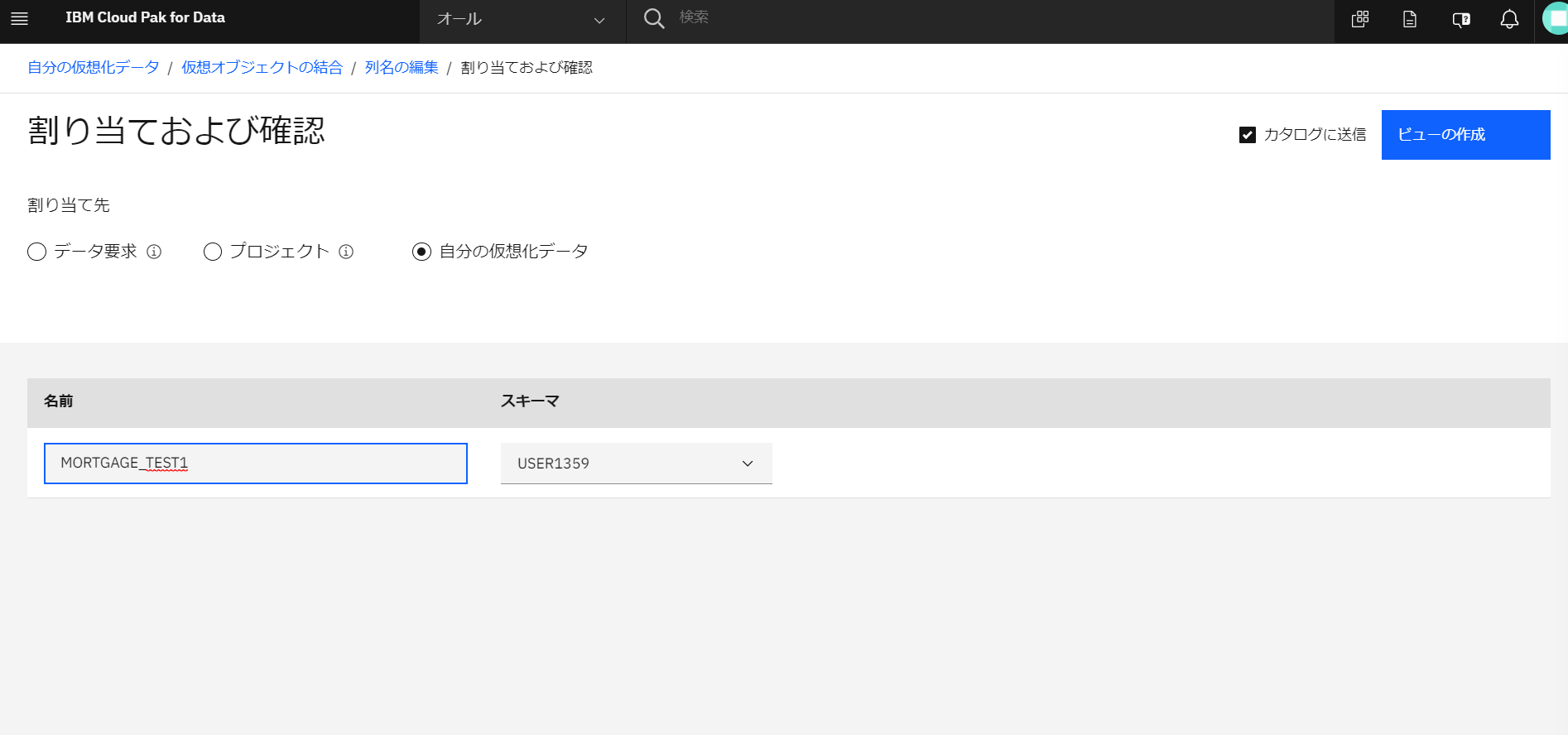
-
結合ビューが作成されました。「自分の仮想化データを表示」をクリックします。
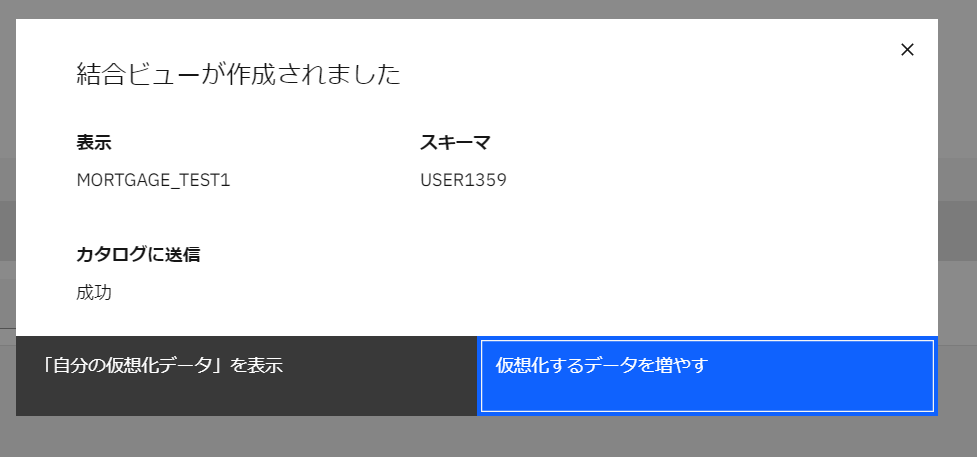
-
今回作成した仮想表の列の右端をクリックし、「プレビュー」を作成します。
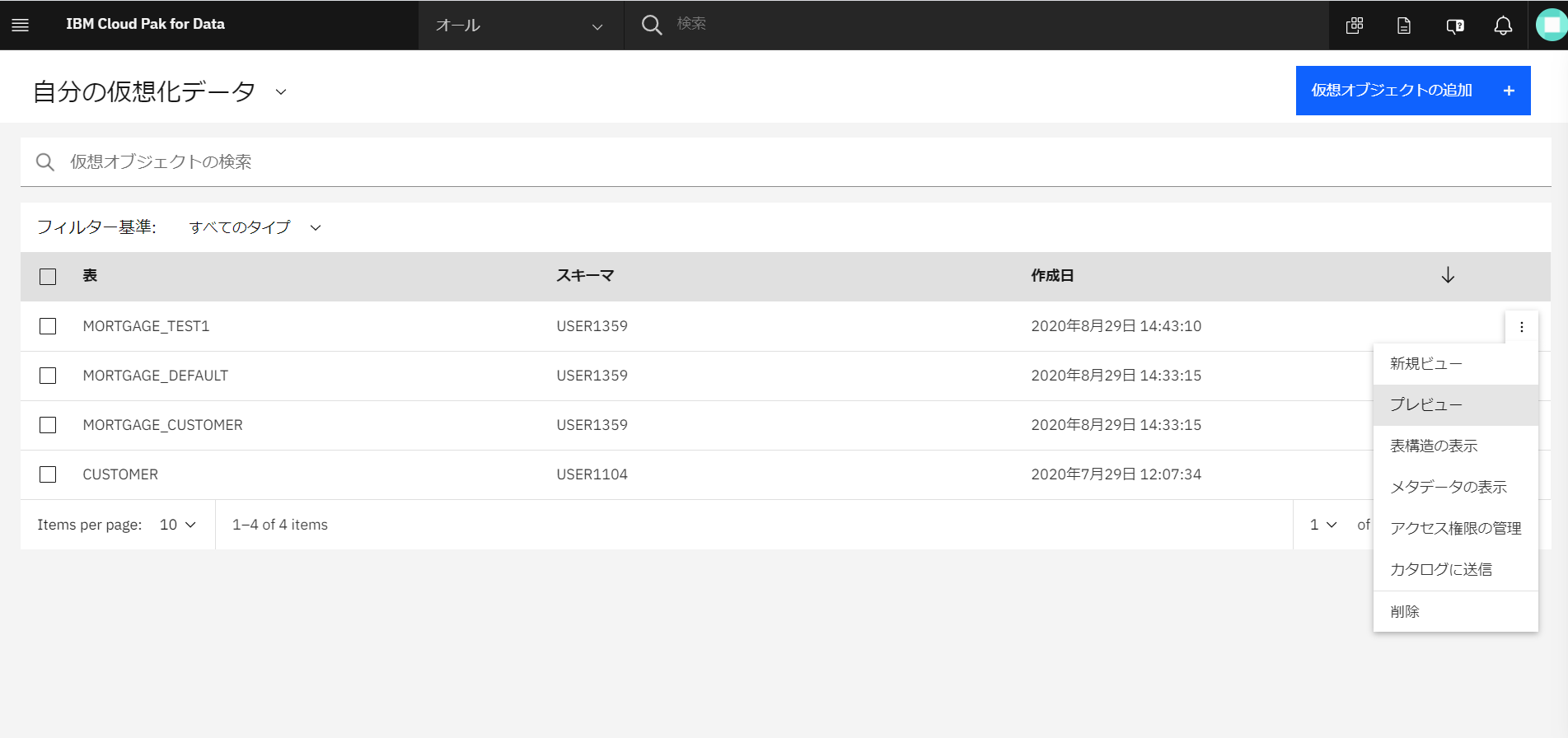
-
プレビューです。選択した列が表示されています。
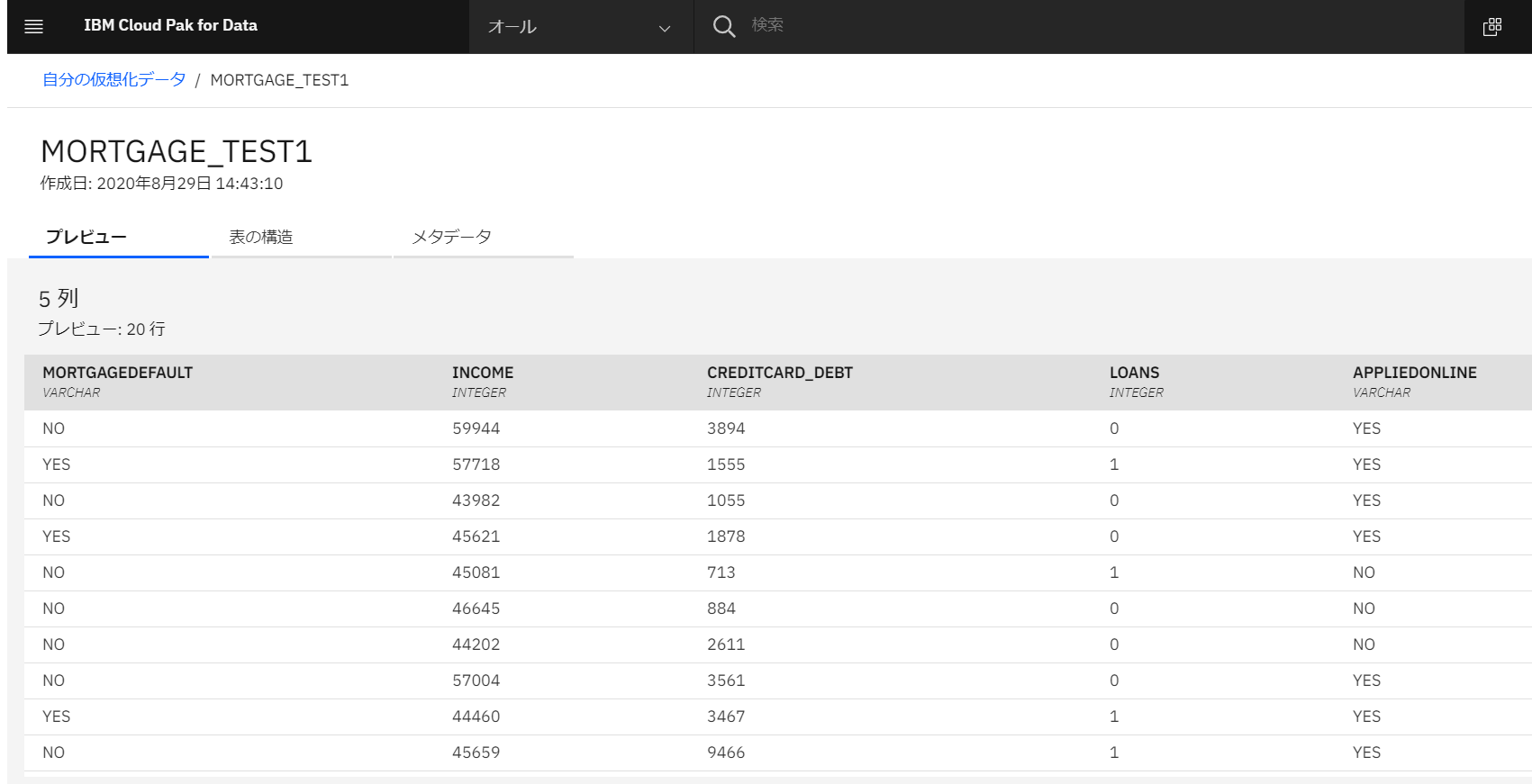
-
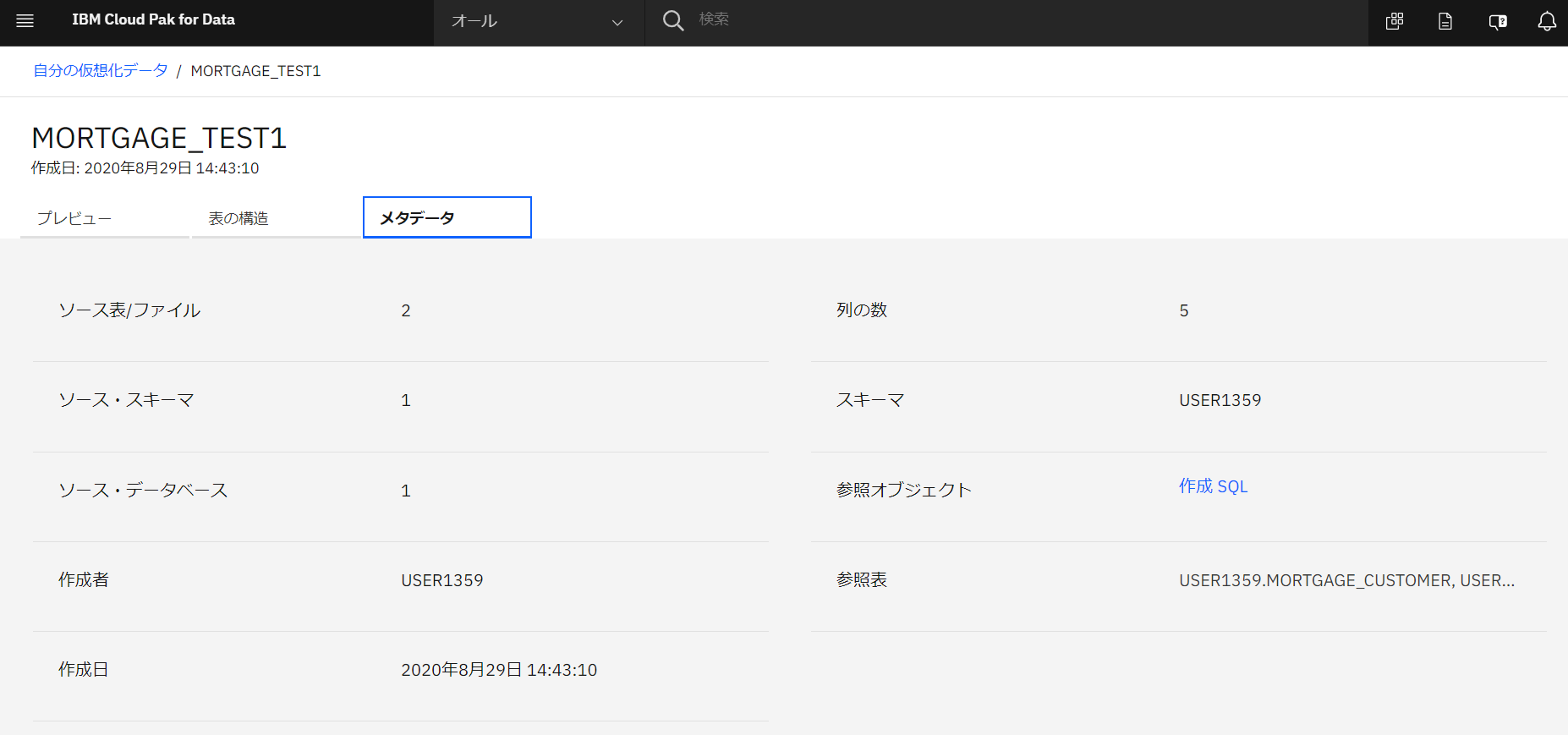
「表の構造」をクリックして確認します。
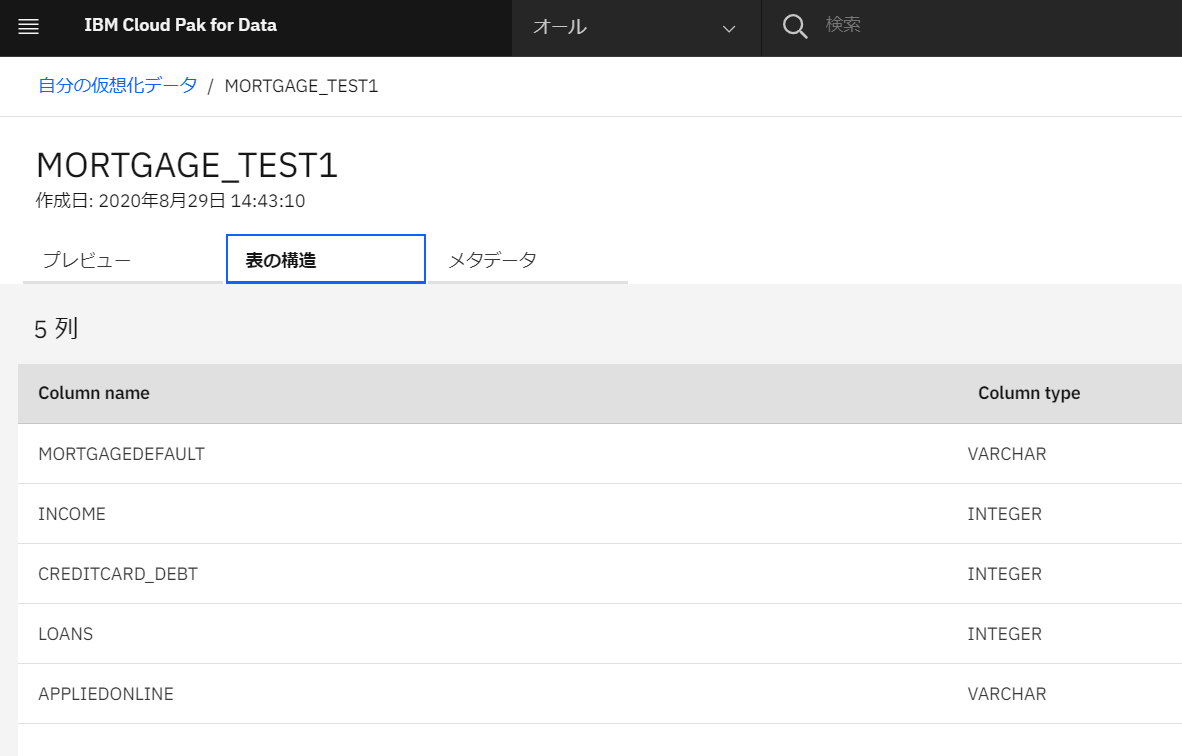
-
「メタデータ」をクリックして確認します。
3. Organize
- 以下は、Exploreボタンの箇所に記載されていた概説の文言の機械翻訳です。
「管理されたDataOpsを通じて
正しいデータを検索して見つけ、その内容を理解して信頼し、アナリティクスやAIを実行するためのプロジェクトで準備して使うことがいかに簡単かをご覧ください。」
-
「Explore」ボタンを押してポップアップしたタブでは、以下の管理画面が出力されます。今後は画面に出てくるガイドにしたがって画面を繊維していきます。「Let's go!」をクリックします。
-
「Next」をクリックしますが、ウインドウに出ている文言を機械翻訳するとこんな感じです。
-
「データを検索する 住宅ローン分析のプロジェクト チームは、信頼できる質の高い住宅ローン申請者データを必要としています。 まず、Cloud Pak for Data のグローバル検索を使用して、すべてのプロジェクト、カタログ、ビジネス用語集を横断的に検索し、住宅ローンのデータとメタデータを見つけることから始めます。」
-
「Next」をクリックします。
-
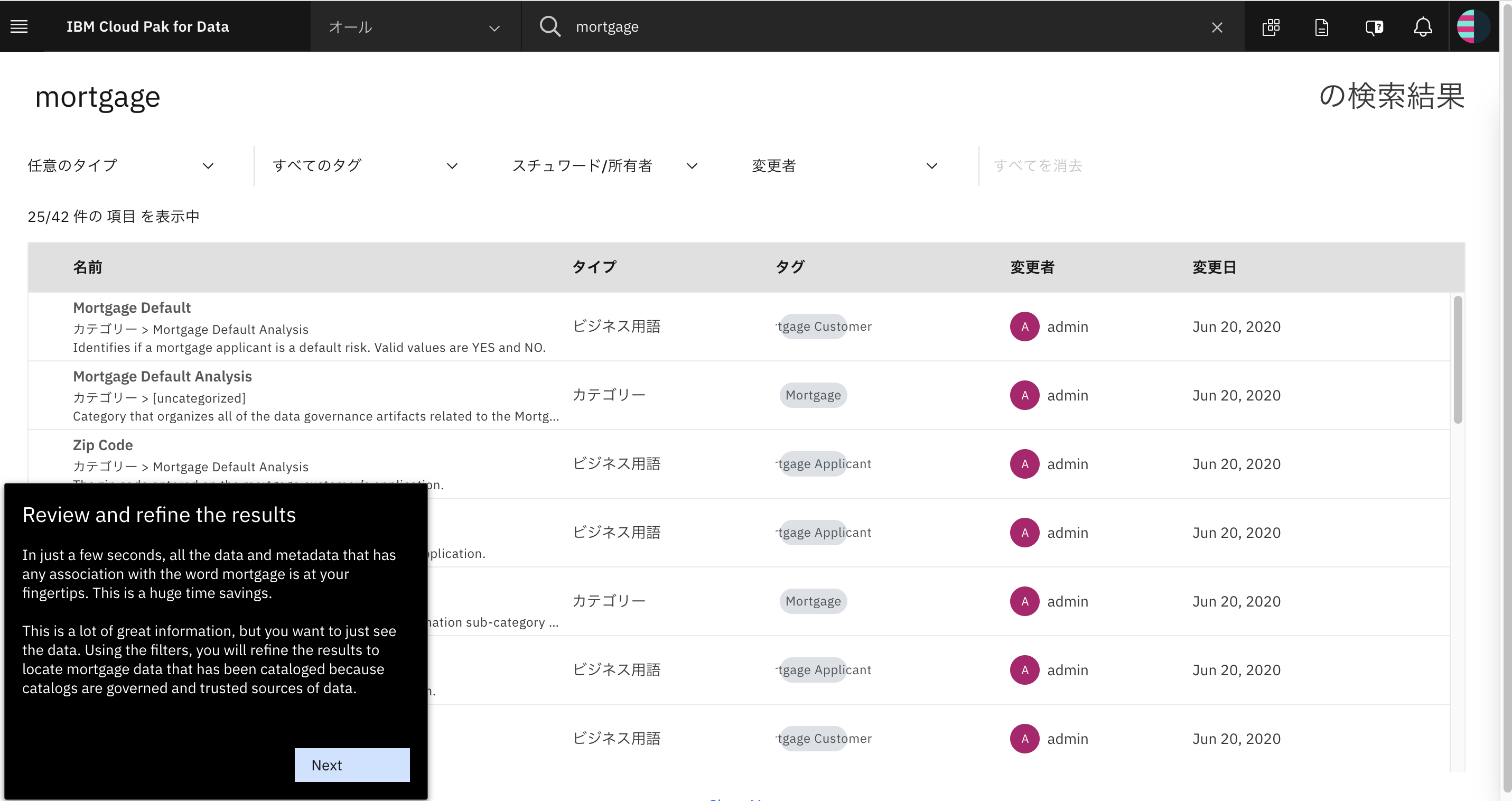
画面上部の検索バーで、「mortgage」と入力してエンターキーを押します。

-
検索結果の画面です。
-
ウインドウの文言を機械翻訳するとこう言う感じです。
-
「結果を見直し、洗練されたものにする ほんの数秒で、住宅ローンという言葉に関連するすべてのデータとメタデータがあなたの指先にあります。これは大きな時間の節約になります。素晴らしい情報がたくさんありますが、データだけを見たいと思っていませんか?カタログは管理されており、信頼できるデータソースであるため、フィルタを使用して、カタログ化された住宅ローンデータを見つけるために結果を絞り込むことができます。」
-
「Next」をクリックします。
-
Organizeとして自動ポップアップのガイドはこれで終了です。以降は筆者による任意のガイドです。
-
画面左上のハンバーガーメニューをクリックし、「編成」をクリックすると出てくる「すべてのカタログ」をクリックします

-
「Enterprise」をクリックします。

-
今回確認できるカタログ「Enterprise」がこちらになります。様々な概念、用語、データ資産が登録されていますので、それぞれ見てみましょう。

ビジネス用語
-
2.Collectでmortgage(住宅ローン)関連のデータを収集しました。ここでは、集めたデータ項目がそれぞれどういう意味であるのかについてみてみます。
-
画面上部の検索バーで「MORTGAGE」と入力します。大文字小文字は問いません。「MORTGAGE」に関する様々な情報が表示されます。

-
「任意のタイプ」をクリックし、「ビジネス用語」を選択します。関連するビジネス用語が表示されました。「Mortgage_Default」をクリックしてみましょう。
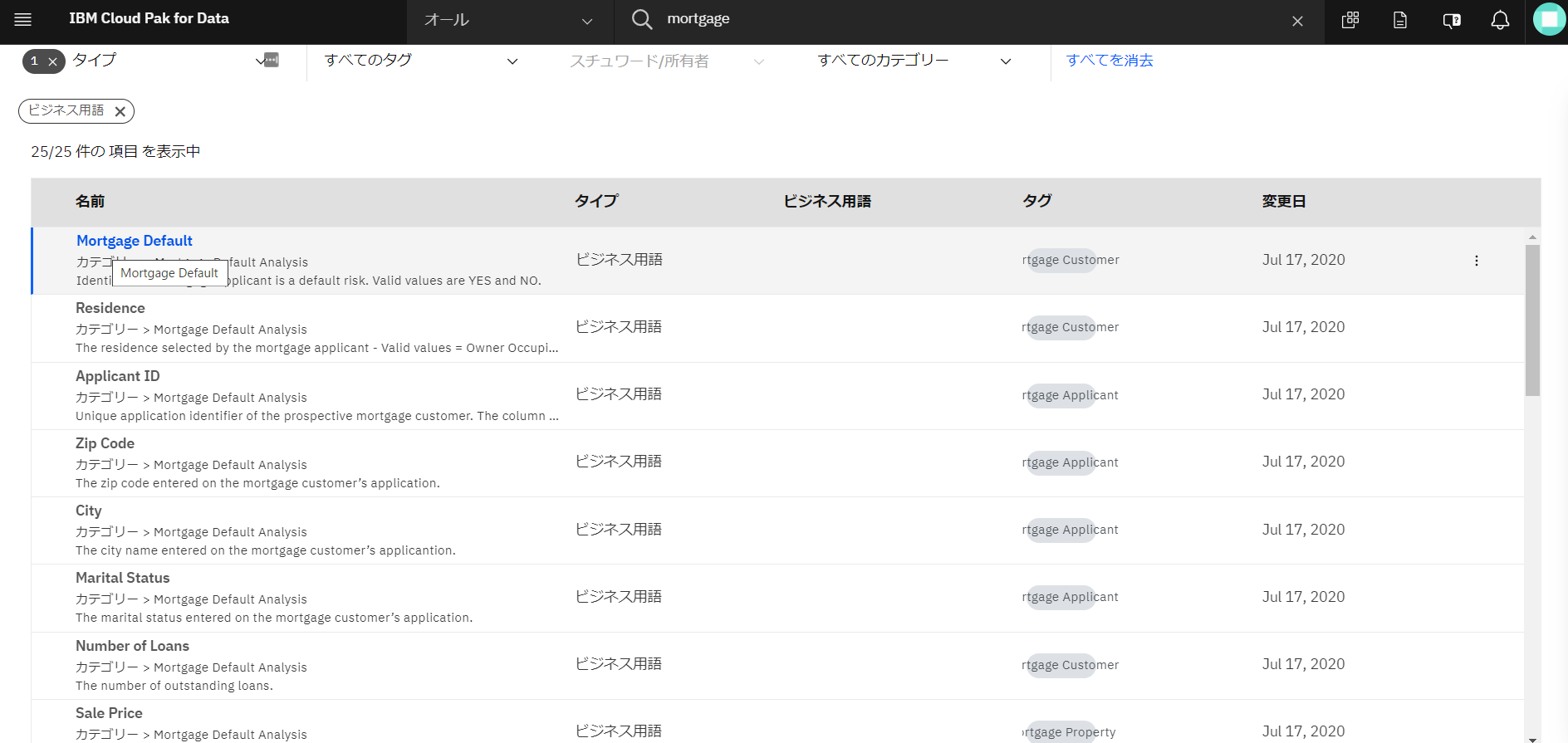
-
「Mortgage_Default」の意味は、(DeepL翻訳:「住宅ローン申請者がデフォルト・リスクであるかどうかを識別します。有効な値はYESとNOです。」)だそうです。ここで、画面左上の「ビジネス用語」をクリックしてみます。
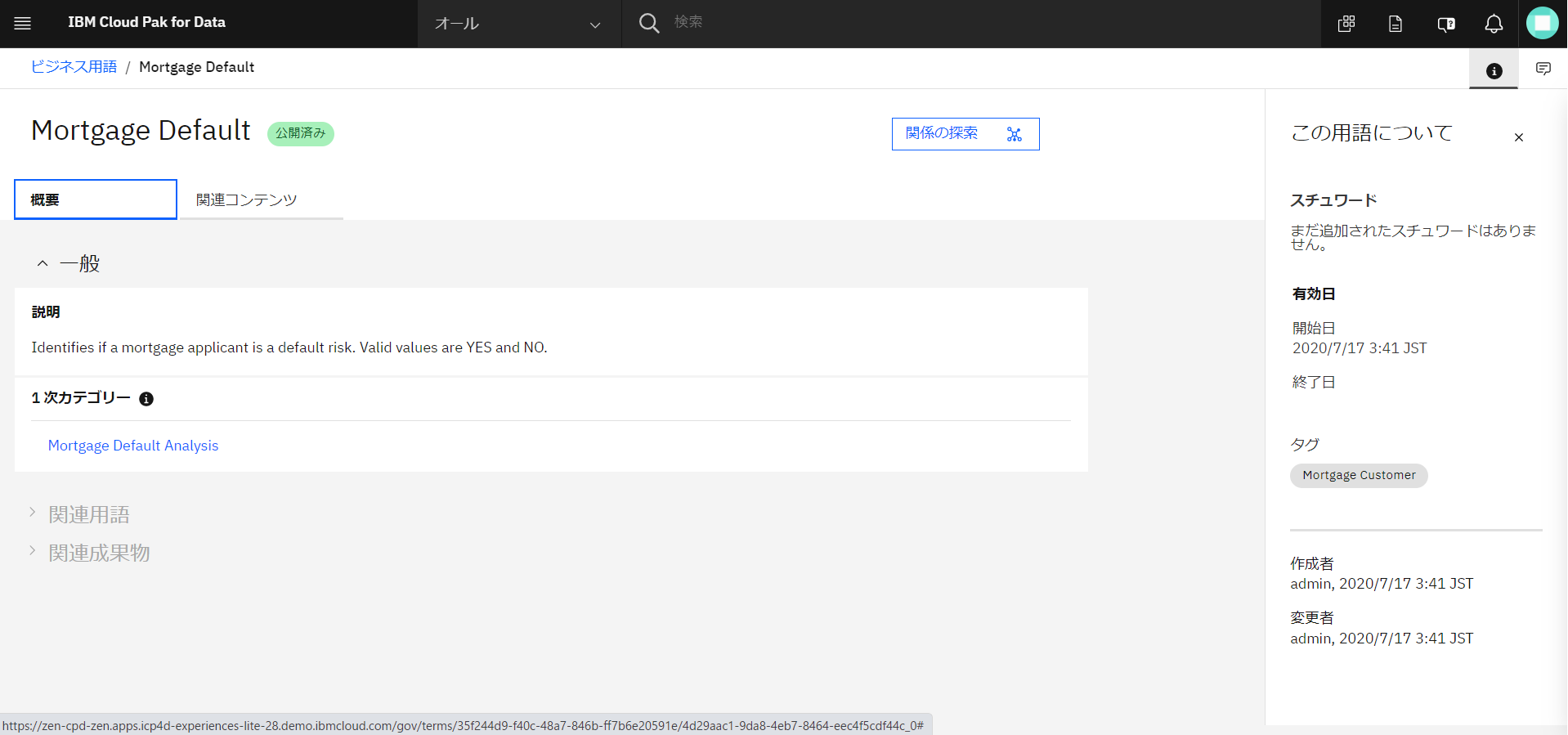
-
ビジネス用語の一覧です。先ほど選択した項目の一つ、「Applied Online」が表示されています。オンラインで申請したかどうか、を示すものだそうです。クリックしてみます。
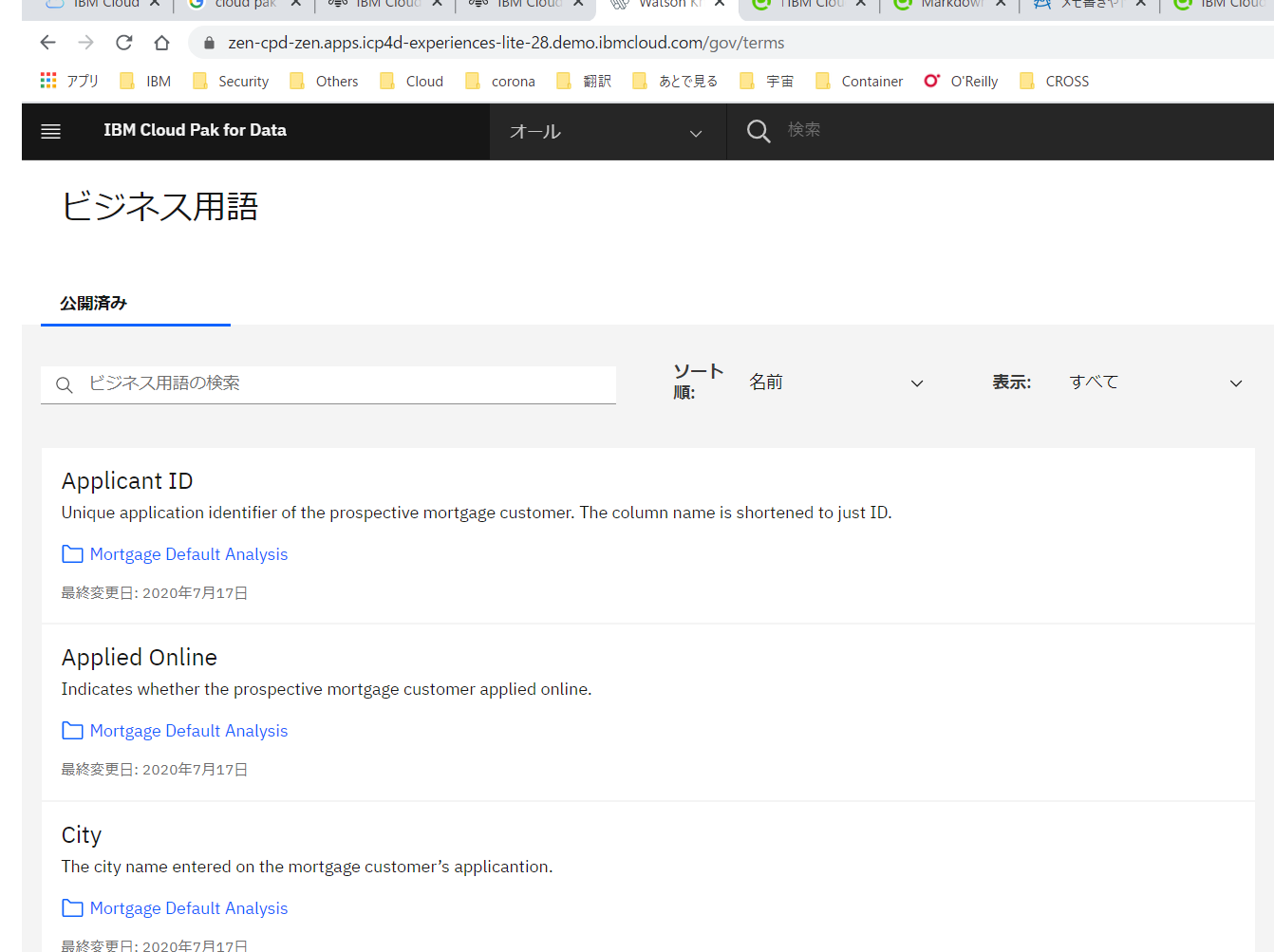
-
「Applied Online」は、オンラインで申請されたかどうか、を示すものですが、例えばこれと「Mortgage_Default」を組み合わせてその相関関係を示すことができれば、オンライン申請した場合、破綻する割合がどうなるか、と言う観点からの分析が出来そうですよね。
-
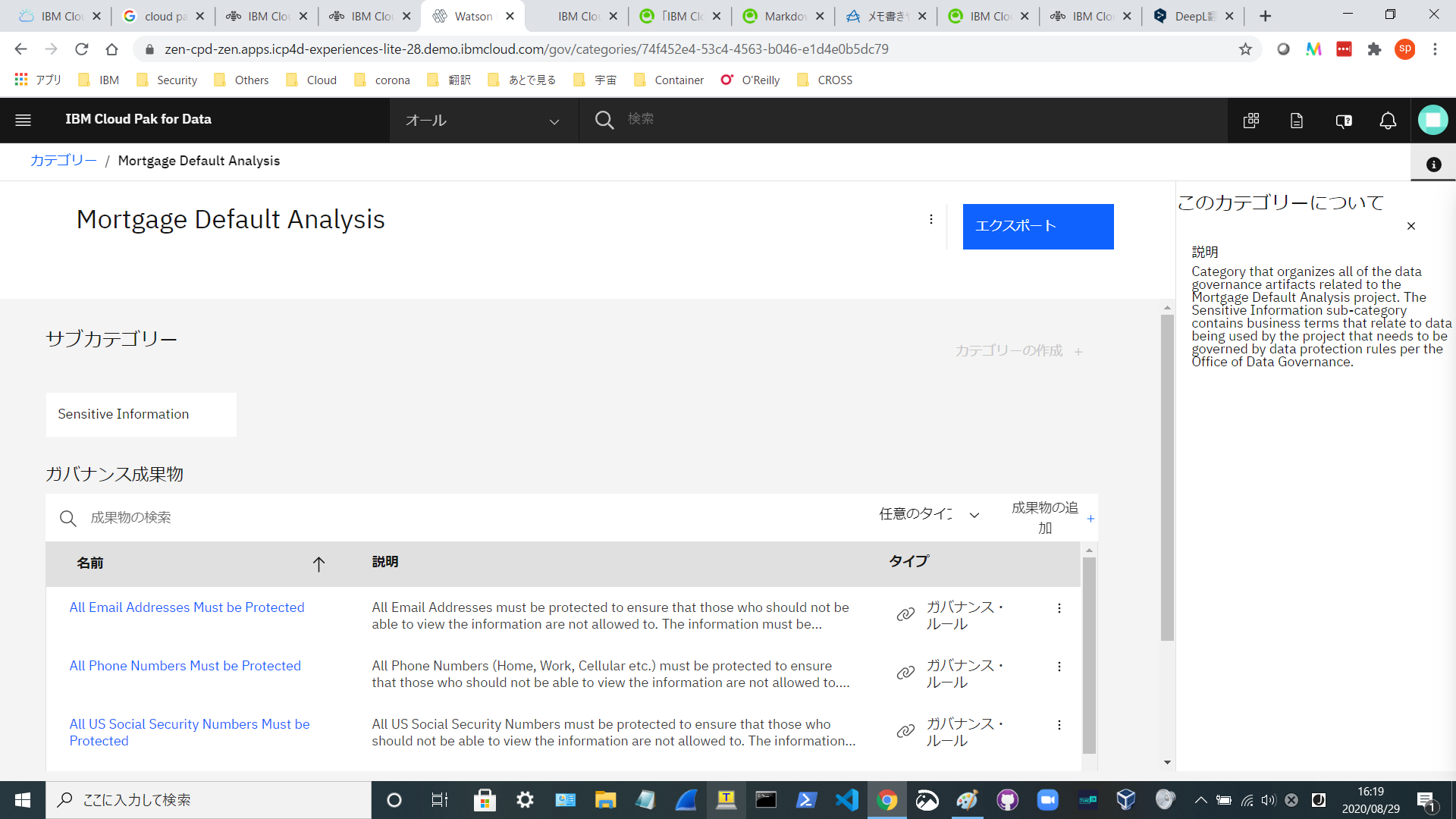
1次カテゴリーである「Mortgage Default Analysis」(左下)をクリックしてみます。
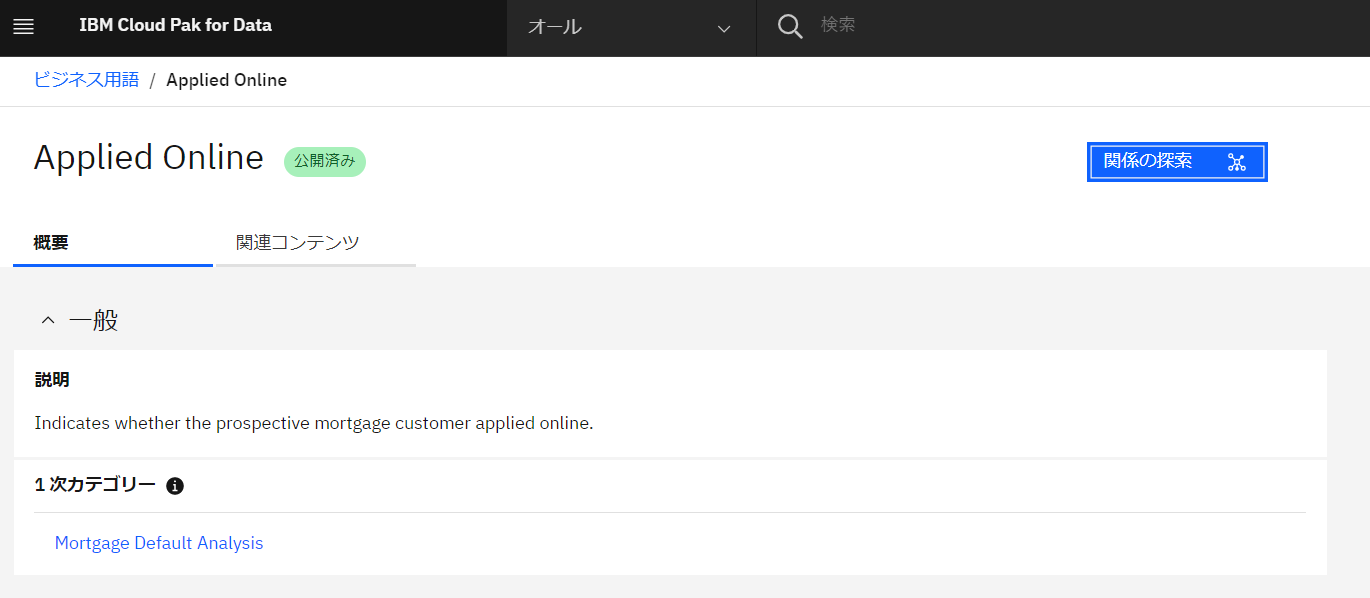
-
当該カテゴリに、いろいろなルールやビジネス用語が定義されていることがわかります。
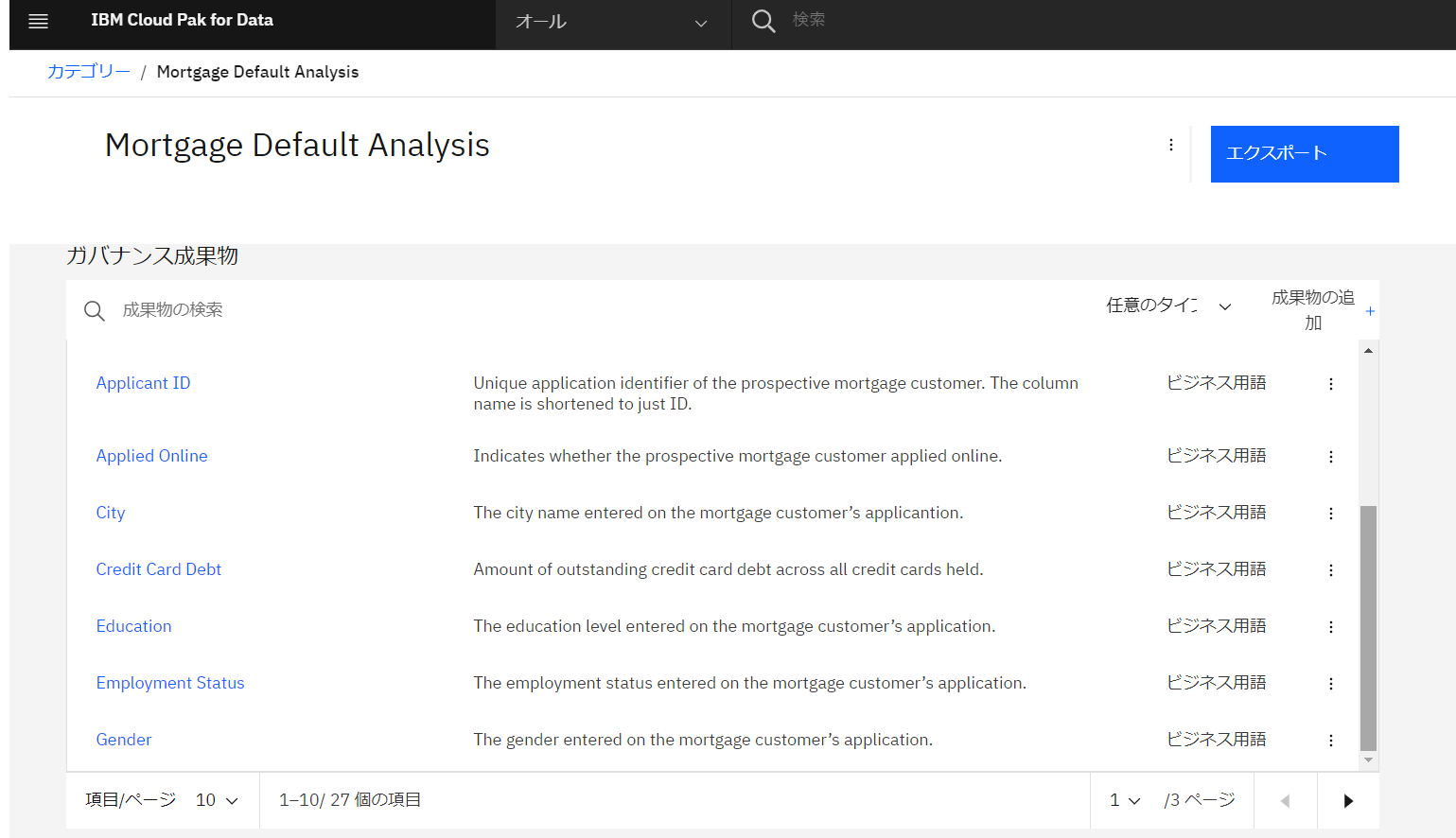
-
様々な用語の定義を調べることで、調べたいものをより正確に見つける確率があがるかもしれません。そういった内容として「正しい言葉のモノサシ、使っていますか?」というブログを公開していますので、よければご参照ください。
-
https://www.ibm.com/blogs/solutions/jp-ja/terminology_definition/
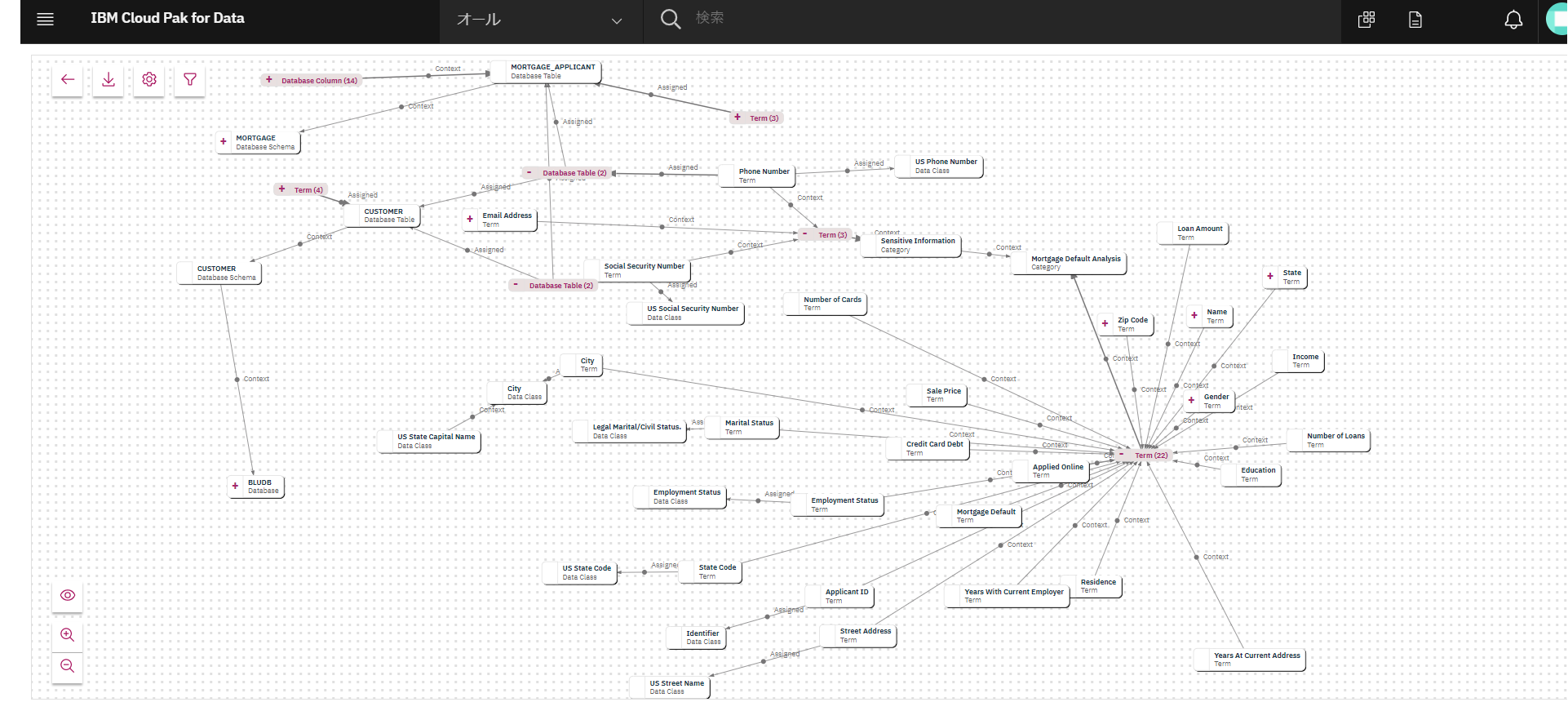
関係の探索
-
画面をBackボタンで戻って「関係の探索」をクリックしてみます。あたらしいタブが開きます。
-
用語と、カテゴリである「Mortgage Default Analysis」が関連づけられています。表示が見づらい場合はオブジェクトをドラッグして整えましょう。「Mortgage Default Analysis」の左端の「+」をクリックします。
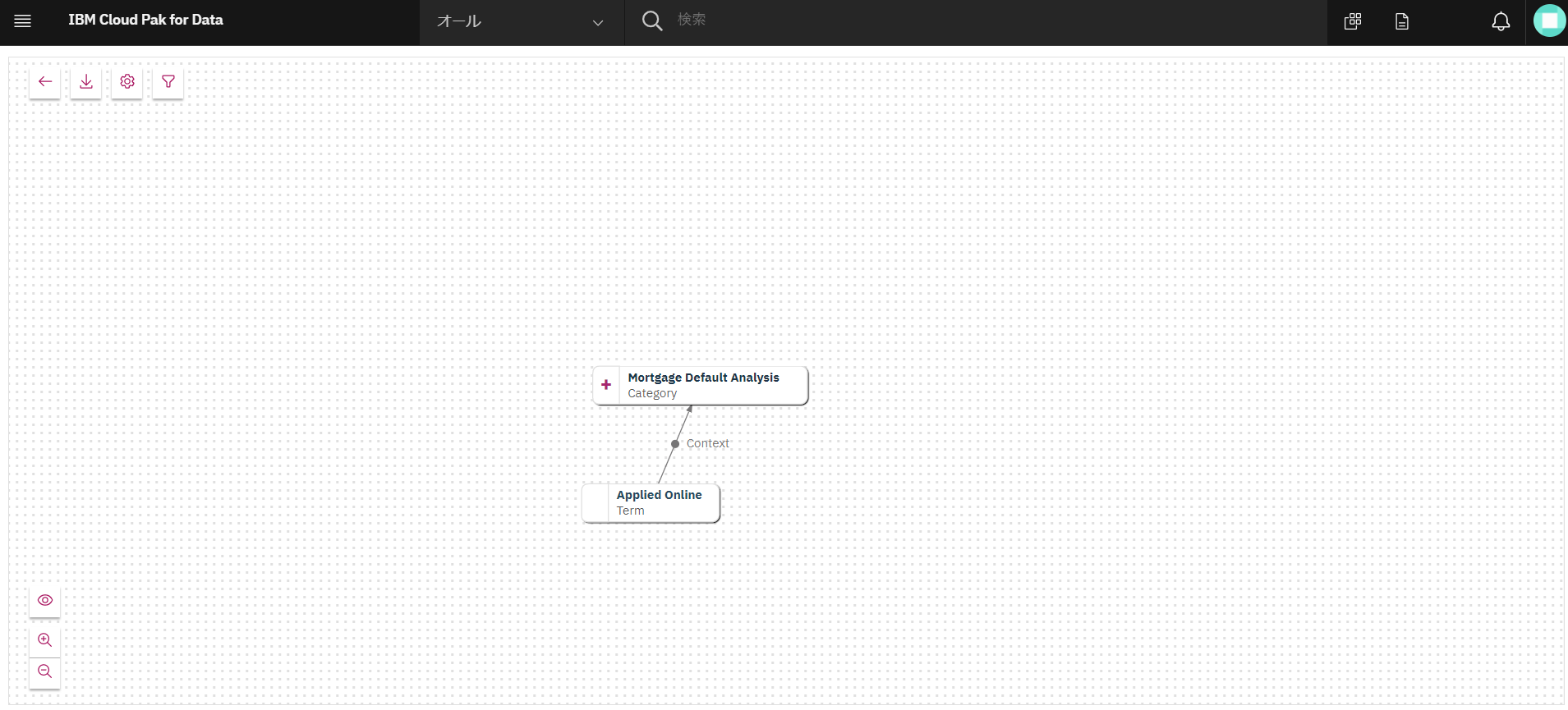
-
間に隠れていた「Term」がでてきましたので、「Term」の右側の「+」をクリックしてみましょう。
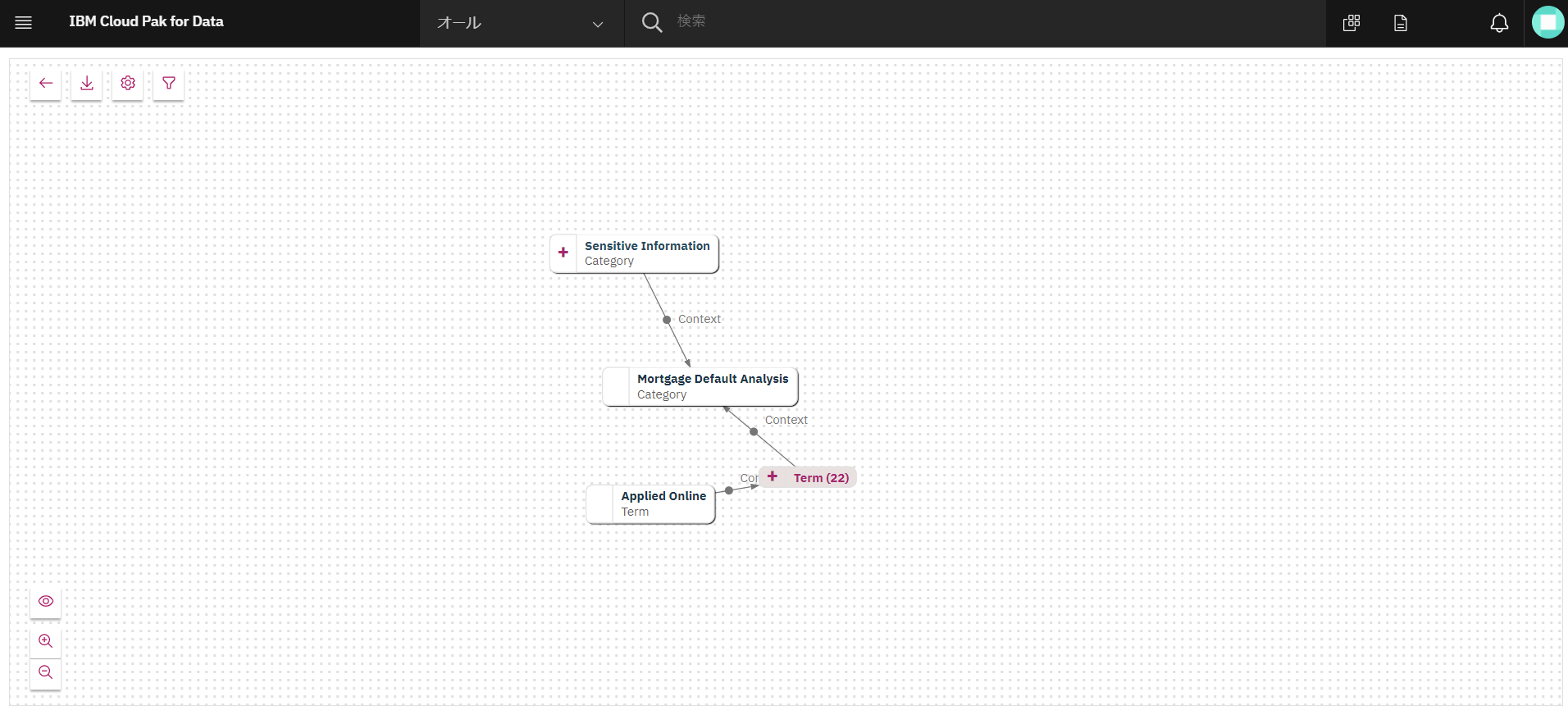
-
様々な用語の関連が表示されるようになりました。

-
オブジェクトの「+」の箇所をクリックすると、様々な用語や概念の関連が表示されるようになります。
グラフ化
-
今度は、簡単なデータのグラフ化を実施します。別なデータで、別なプロジェクトでやってみましょう。
-
まず、新しいプロジェクトを作成します。最初の画面からプロジェクトへ移動します。
-
右上側の「新しいプロジェクト」をクリックします。
-
「新規プロジェクトの作成」で「次へ」をクリックします。

-
「空のプロジェクトを作成」を選びます。
-
プロジェクト名を任意でつけます。

-
作成されました。
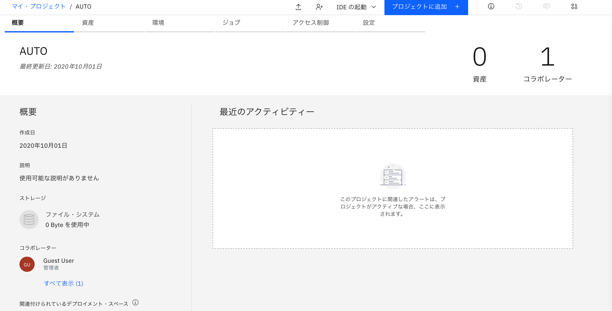
-
データ仮想化画面へ移動し、「仮想化」を選びます。
-
検索窓に「auto」と入力します。
-
歯車のアイコンをクリックして、チェックボックスを外します。
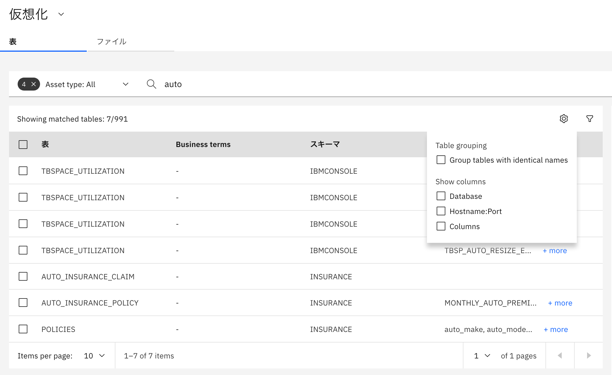
-
「AUTO_INSURANCE_CLAIM」を選んで「カートに追加」をクリックします。
-
(図ではもう一つ選んでいますが、結局使いませんでした。。。)
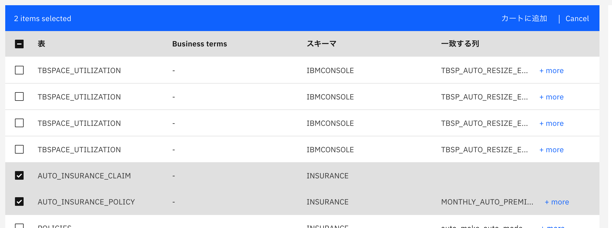
-
「カートの表示」をクリックします。

-
割り当てさきとして、先ほど作成したプロジェクトを選んで、「仮想化」をクリックします。
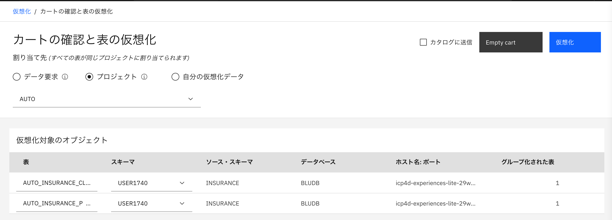
-
作成されたので、プロジェクトに移動します。
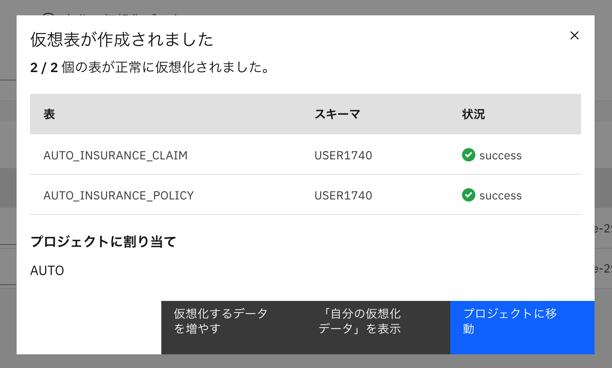
-
「AUTO_INSURANCE_CLAIM」を選んで「カートに追加」をクリックします。

-
右上の「Refine」をクリックします。
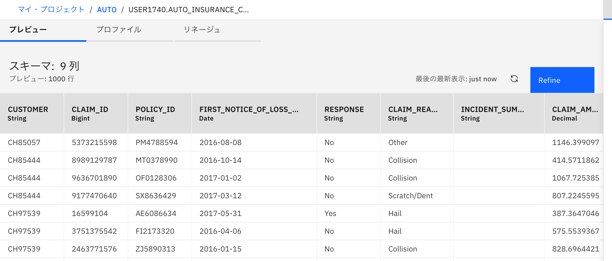
-
「Data Refinery」という、データの精製、グラフ化する為の画面になりますので、ここで「視覚化」をクリックします。
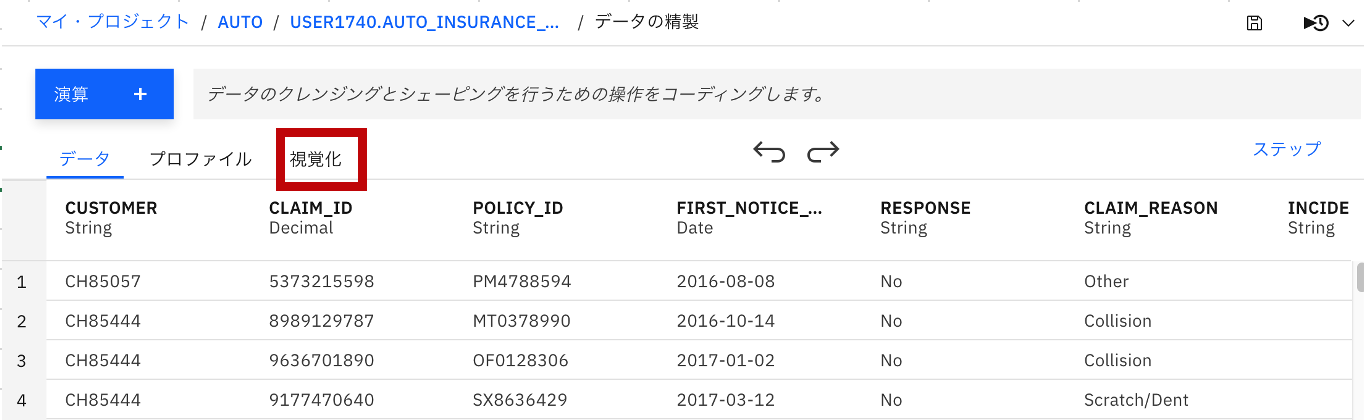
-
いろんなグラフが選べます。矢印をクリックすると、選べるグラフが出てきます。

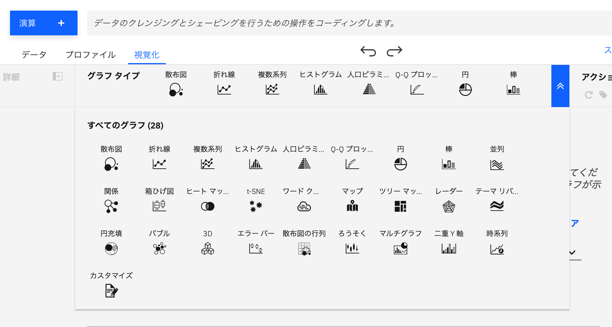
-
ここではヒストグラムを選んでみましょう。

-
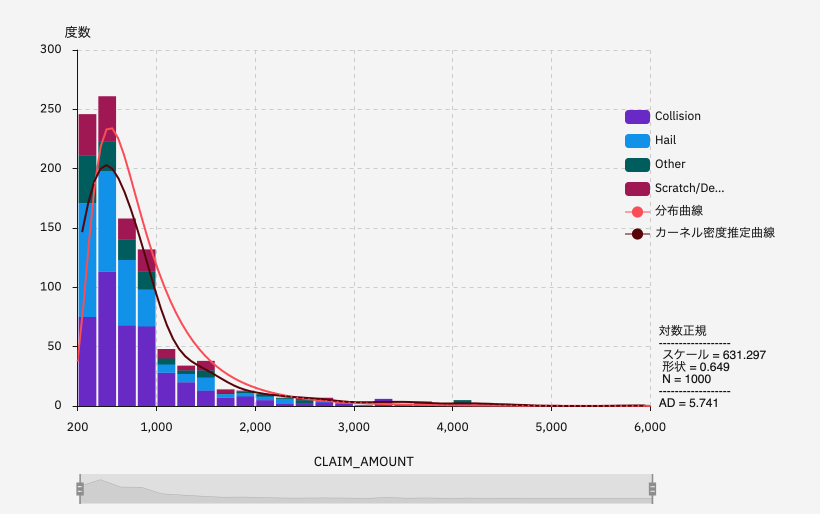
X軸にCLAIM_AMOUNT、Y軸にCLAIM_REASONを選んで、「積み上げ」などの表示オプションを選ぶと、このようにグラフ化されます。
-
グラフは画像やJSON形式(グラフの詳細)でダウンロードも可能です。
-
ダウンロードしたグラフの画像です。
まとめ
このように、様々なデータ分析の形を試せるCP4Dが、無償でお使いいただけますので、
ぜひお試しください。