この記事について
- この記事はIBMが提供する製品に関する情報やナレッジを共有する Advent Calendar 2024の12月20日分として記載しています
背景
- こちらの記事で、「SF10」「SF100」スキーマのデータは処理できましたが、「SF1000」については途中でエラーとなってしまいました
- やはり超巨大データを扱う場合に、データをひっぱってきてJOINして、最後にフィルターをかけるという処理自体、メモリ上に超巨大データを保持しながら、というところが無理あるかと思い、各データから引っ張ってきた直後に列の削除やフィルタリングを掛けて、その後でJOINするという処理に変えました
- 各ステージで、後続に渡すデータ量を必要最小限にするようにしていく感じに変えました
- 今回は、一番大きな「SF1000」を処理した後、そのフローを使ってデータソースをそれぞれ「SF100」「SF10」「SF1」と入れ替えて実施して処理時間を比べてみます
- また、データソース側で処理(Transform)してからExtractするというTETL方式でも試してみました。
実施概要
- 対象データベースはSnowflake(Azure/東京)の「SNOWFLAKE_SAMPLE_DATA」を使用します
- 「SF1000」「SF100」「SF10」「SF1」各スキーマから、「REGION」「NATION」「CUSTOMER」「ORDERS」テーブルを引っこ抜いて余計な列を削除してフィルタリングしてからJOINするフローをDatastageに実行させます
- どの程度のデータ量で、どの程度の処理時間がかかるのかを測ってみます
- Datastage は、IBMCloudの東京リージョン上のOpenshiftに建てたCloud Pak for Data v5.0.3 上のコンテナソフトウェアを使用しています
スキーマ「SF1000」の場合
処理対象
-
スキーマ「SF1000」
- 「REGION」:5行、4.0KB
- 「NATION」:25行、4.0KB
- 「CUSTOMER」:150M(1億5千万)行、10.1GB
- 「ORDERS」:1.5B(15億)行、48.6GB
-
最もレコード件数が多いテーブルが「ORDERS」
- 件数:1.5B(15億)行
- データサイズ:48.6GB

Snowflake側の設定
- XL サイズを使用しました
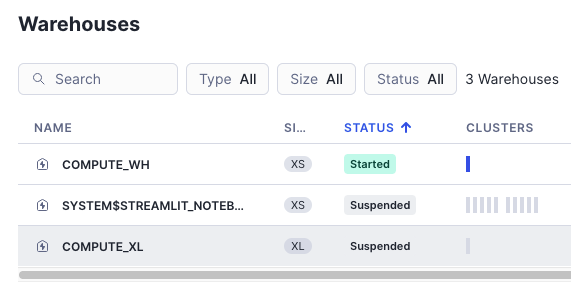
Datastage側の設定
-
インスタンスとしてLサイズを使用し、パーティションを3に設定しました
-
インスタンス設定


-
プロジェクトにおける実行環境設定

-
エフェメラルストレージを1000GB程度まで拡張
-
(社内の有識者からもらったアドバイス。ただしあくまでテスト用の一時的な処理であり、本番ではストレージを別途準備するように、とのこと)
[root@localhost ~]# oc -n ${PROJECT_CPD_INST_OPERANDS} patch pxruntime ds-px-xlarge --patch '{"spec":{"ephemeralStorageLimit": "1000Gi"}}' --type=merge
pxruntime.ds.cpd.ibm.com/ds-px-xlarge patched
[root@localhost ~]#
Snowflake の結果
- 何回か実施していて、ひょっとしてキャッシュに入ったのか、どのサイズのテーブルも1秒かかっていませんでした

Datastage の結果
フロー
- 正常終了しました

ジョブ(時間)
- 約6時間かかりました
- やはり最もサイズが大きい(48GB/15億行)のORDERSテーブルの処理に一番時間がかかっています

TETL 設定の場合
- 上記の設定のまま、データをデータソース側で処理(Transform)してExtract、一部をTransformした上でターゲットに対してLoadするTETLという方法でも実施してみました。(画面左上に「TETL」の表記有り)
- なお、ELT、またはTETLで処理する場合、Datastageはその実行エンジンとして、内部的にdbtを使っています。

- こちらも問題なく実行完了しました。

- 処理時間は5時間40分程度で、通常のETL処理と比較して20分程度短縮されています。

スキーマ「SF100」の場合
- 上記SF1000 のフローをコピーして、データソースだけスキーマSF100 のものに変えて実行してみました

処理対象
-
スキーマ「SF100」
- 「REGION」:5行、4.0KB
- 「NATION」:25行、4.0KB
- 「CUSTOMER」:15M(1500万)行、1.0GB
- 「ORDERS」:150M(1億5千万)行、4.3GB
-
最もレコード件数が多いテーブルが「ORDERS」
- 件数:1億5千万行
- データサイズ:4.3GB
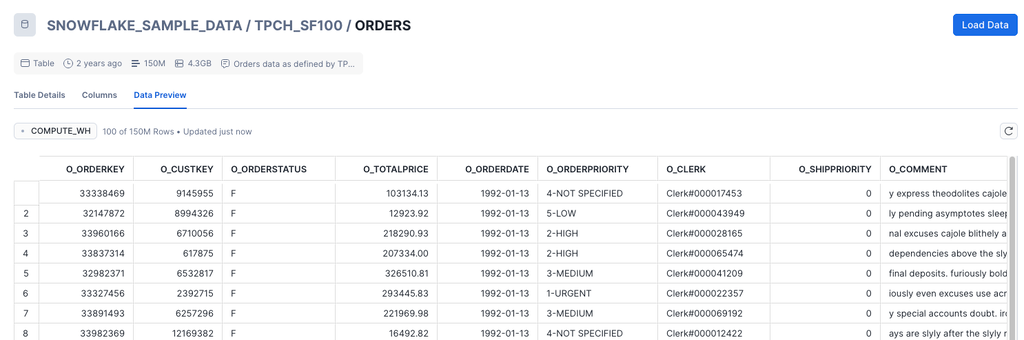
フロー
- 正常終了しました

ジョブ(時間)
- 30分程度で終了しました

TETL 設定の場合
- 上記の設定のまま、データをデータソース側で処理(Transform)してExtract、一部をTransformした上でターゲットに対してLoadするTETLという方法でも実施してみました。(画面左上に「TETL」の表記有り)
- なお、ELT、またはTETLで処理する場合、Datastageはその実行エンジンとして、内部的にdbtを使っています。

- こちらも問題なく実行完了しました。

- 処理時間は32分で、通常のETL処理と比較してあまり差はみられませんでした。

スキーマ「SF10」の場合
- 上記SF1000 のフローをコピーして、データソースだけスキーマSF10 のものに変えて実行してみました

処理対象
-
スキーマ「SF10」
- 「REGION」:5行、4.0KB
- 「NATION」:25行、4.0KB
- 「CUSTOMER」:1.5M(150万)行、103.2MB
- 「ORDERS」:15M(1500万)行、425.8MB
-
最もレコード件数が多いテーブルが「ORDERS」
- 件数:1千500万行
- データサイズ:425.8MB

フロー
- 正常終了しました

ジョブ(時間)
- 4分ちょっとで終了しました

TETL 設定の場合
-
上記の設定のまま、データをデータソース側で処理(Transform)してExtract、一部をTransformした上でターゲットに対してLoadするTETLという方法でも実施してみました。
-
なお、ELT、またはTETLで処理する場合、Datastageはその実行エンジンとして、内部的にdbtを使っています。

-
こちらも問題なく実行完了しました。(画面左上に「TETL」の表記有り)

-
処理時間は4分ちょっとで、通常のETL処理と比較してあまり差はみられませんでした。

スキーマ「SF1」の場合
- 上記SF1000 のフローをコピーして、データソースだけスキーマSF1 のものに変えて実行してみました

処理対象
- スキーマ「SF1」
- 「REGION」:5行、4.0KB
- 「NATION」:25行、4.0KB
- 「CUSTOMER」:150K(15万)行、10.3MB
- 「ORDERS」:1.5M(150万)行、40.3MB

フロー
- 正常終了しました

ジョブ(時間)
- 1分足らずで終了しました

TETL 設定の場合
-
上記の設定のまま、データをデータソース側で処理(Transform)してExtract、一部をTransformした上でターゲットに対してLoadするTETLという方法でも実施してみました。
-
なお、ELT、またはTETLで処理する場合、Datastageはその実行エンジンとして、内部的にdbtを使っています。

-
こちらも問題なく実行完了しました。(画面左上に「TETL」の表記有り)

-
処理時間は1分足らずで、通常のETL処理と比較してあまり差はみられませんでした。
