本記事は、ランド研究所の「機械学習による航空支配」を実装する(その8)です。(その8)では、(その7)で実装した 1D 問題用の simulator を使って、ミッション・プランナー(エージェント)を強化学習します。
実装したコードは、GitHubにあります。今回使用する環境は、'myenv' フォルダ内の 'myenv.py' です。フォルダ構成がややこしいのは、OpenAi Gym に環境を登録するためです。登録せずに使うのであれば、このフォルダ構成は不要です。
なお、私の体力不足で各強化学習アルゴリズムは、復習程度にしか説明していません(ゴメンナサイ)。ネット上に優れた記事がたくさんありますので、興味がある方は各リンク先の原論文、又は気に入った記事をお読みください。
過去記事へのリンクは、最下段にあります。
1. はじめに
既存ツールを使って、ミッション・プランナーである Agent を強化学習します。既存ツールを使う理由は以下です。
強化学習は、元々、深層学習とは別の「最適制御」の流れで研究されていた学問分野です。深層学習の部分は割と薄いです。このため、深層学習とは別の部分で理論が結構複雑です。また、コーディングにかなりの技術が必要です。おまけに、学習させるのがとても難しく、学習が上手く行かなかった時に、自分が理論を正しく理解していないのか、コードにバグがあるのか、ハイパラの設定が悪いだけなのか、ネットワーク・アーキテクチャがよくないのか、報酬の与え方が悪いのか、学習時間が足りないのか、はたまた、単に運が悪かった(乱数系列が良くなかった)だけのかサッパリわからないことが普通です。おまけに、1回の run に物凄く時間がかかるので、ビンテージ・マシンしか持っていない貧者には厳しいものがあります。既存ツールを使えば、少なくとも最初の2つは除外できます。おまけに、大抵は、デフォルトでそれなりに上手く行くハイパラ設定とアーキテクチャがついてきます。さらに、(私と違って)、ちゃんとしたプログラマーが手を抜かずに作りこんで、多くの人がテストしているので、自分で作ったものより大抵学習が安定していて、オプションが多く高速です。(とはいえ、やはり自分で実装しておいた方が理解は格段に深くなって何かと応用が効くので、主要なアルゴリズムは練習で実装しているのですが、いつもとても苦労しています)。
ここでは、ランド研究所が使ったと思われる OpenAi Baselines (2017) を改良した Stable Baselines (2018) を使って強化学習します。
2. Stable Baselines と使用する強化学習アルゴリズムの概要
ランド研究所のレポートでは、1D 問題には DQN (2015) を、2D 問題には A3C (2016) と PPO (2017) を適用しています。(2D 問題は、アクション空間が連続なのでDQNは適用できません)。ここでは、DQN, A2C, PPO を適用してみます。
DQNは、次の誤差函数(以下の各式は、原論文からの抜粋です):


を、SGD(Stochastic Gradient Descent)を使って最小化することにより、最適ベルマン方程式の最適行動価値函数 Q(s,a) をニューラル・ネットで近似するアルゴリズムです。学習データを収集する振る舞い行動には、普通は ε-Greedy 政策が用いられます。更新に用いるミニバッチは、経験バッファ(Replay buffer)からサンプルします。
DQN の学習アーキテクチャは別の強化学習ライブラリである RLLIB から抜粋した下図がわかりやすいのではないかと思います。DQN の学習アーキテクチャは、図で Trainer と書いてある部分です。Replay Buffer と書いてあるメモリに経験を蓄積し、そこからサンプルをランダムに選んでバッチ処理で学習するのが特徴です。この方法を採るアルゴリズムは、Replay Bufferにデータを集める振る舞いポリシーと、最適化するポリシーが異なるため、オフ・ポリシー(off policy)のアルゴリズムと呼ばれています。DQNでは、点線部分の Rollout workers は使いません。(これらは、Ape-X や Rainbow といった発展型のアルゴリズム用です)。

DQN については、オリジナルの DQN に加え、改良版である double DQN、 アーキテクチャを工夫した Dweling network (2015)、価値ある経験を優先して使用する prioritized experience replay (2015) を併用しました。
A3C は、Acotr-Critic 法を、多数ワーカーによる非同期の並列処理にしたものです。Actor(ポリシー函数)、Critic(価値函数)の更新は、それぞれ以下で与えられます。(以下の各式は、原論文からの抜粋です)。

Stable Baselines では、A3C は用意されていないので、代わりにA2C (2017)を使います。A3C と A2Cの違いは、ネットの勾配更新を非同期で行うか、同期で行うかの違いだけです。(A3C は Asyncronous Advantage Actor-Critic, A2Cは Advantage Actor-Critic の略です)。どちらが良いかは case-by-case のようですが、A2C のほうが良い性能となることが多い気がします。
PPOは、「大きすぎるポリシーの更新はしない」ことにより学習の安定性を向上したアルゴリズムです。これを実装するために、新旧のポリシー分布の比をクリップした代理目的函数(surrogate objective function):(以下の各式は、OpenAI Spinning upからの抜粋です)、

を定義し、SGD (Stochastic Gradient Descent) でポリシー・ネットワークを更新します。

価値ネットワークの更新は A3C と同じです。アドバンテージ函数 A には、普通は GAE(Generalized Advantage Estimator)を用います。
Stable Baselinesでは、PPO には、PPO1 と PPO2 の2種類が用意されていて、下記によると複数環境の処理の仕方と GPU への対応が違いのようです。
[PPO2] What’s the difference between PPO1 and PPO2 ? #485
私のビンテージ・マシンには当然 GPU はありませんが、複数環境の処理方法が PPO2 の方が良さそうだったこと、レビューによると PPO2 の方が性能が良さそうだったことから、以下では PPO2 を用いました。
PPO と A2C の学習アーキテクチャは下図 の通りで、複数 workers (と環境のコピー)でサンプル・バッチを収集し、それらを使ってトレーナー(又は、learner)で学習します。Replay buffer は使用しません。このような方法を採るアルゴリズムは、最適化するポリシーを直接更新していくので、オン・ポリシー(on policy)のアルゴリズムと呼ばれます。

3. Network Architecture
Actor-Critic 系である PPO2 と A2C で使用したネットワーク・アーキテクチャを下図に示します。Actor-Critic では、ポリシー函数 π(a|s) と価値函数 V(s) をニューラル・ネットで近似します。今回は、ネット・アーキテクチャもハイパー・パラメータも、デフォルト設定のまま使用しました。(デフォルトは、極めてシンプルな環境である 「CartPole-v0 用に最適化されている」とどこかで読んだことがあるのですが、デフォルトから変更するとハイパー・パラメータも調整しなければいけなくなって、ビンテージ・マシンでそれをするのは厳しいため、必要にならない限り手を出さないことにしました)。したがって、PPO2, A2C のいずれにおいてもネット・アーキテクチャは下図となっています。

Value iteration 系である DQN で使用したネットワーク・アーキテクチャを下図に示します。DQNでは、行動価値函数 Q(s,a) をニューラル・ネットで近似し、ポリシー・ネットワークは使いません。その代わりに、状態 s において、もっとも Q(s, a) 値の高いアクション a を高確率で選択して、データ収集に使います。今回は、Dueling Architecture と Prioritized Experience Replay の利用以外はデフォルト設定のまま使用しました。Dueling アーキテクチャを用いているので、下図に示すように、一旦、Advantage 函数 A(s,a) と状態価値函数 V(s) を求めてから、行動価値函数 Q(s,a) を出力するアーキテクチャになっています。Advantage 函数 A(s,a) と状態価値函数 V(s) を求めるネットワークは重み共有したアーキテクチャを用いることが多いのですが、Stable Baselines のデフォルトは、図のように別々のネットワークとなっています。

4. 学習
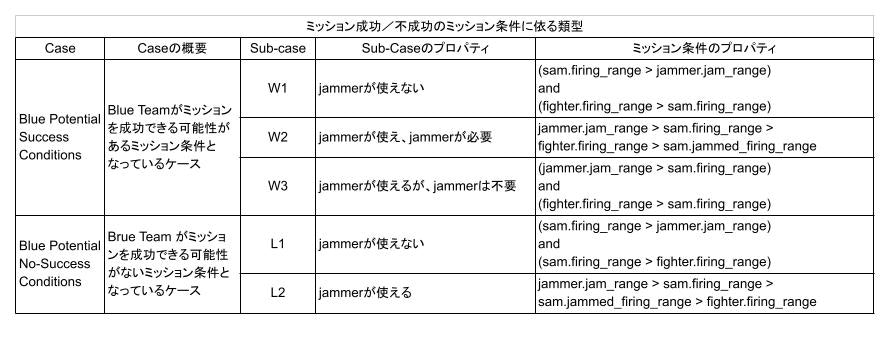
ミッション条件としては、まずは小手調べなので、GAN のトレーニングでも使用した下表の w1, w2, w3 のみを使用します。これらはプランさえうまく作ればミッションに成功できる条件です。(どう頑張っても、ミッションに成功できない条件 l1, l2 を追加したケースは(その9)で扱います)
PPO2 と A2C の学習プログラムは、GitHub の stable_baselines フォルダ内の 'training_acotr_critic-v0.py' です。学習プログラムは、ほとんど入門マニュアル通りです。
モデルは以下で定義しています。
def define_model(env, log_dir):
if DEFAULT:
policy_kwargs = dict()
else:
policy_kwargs = dict(act_fun=ACT_FUN, net_arch=NET_ARCH)
if ALGORITHM == 'ppo2':
model = PPO2(policy=MlpPolicy,
env=env,
policy_kwargs=policy_kwargs,
verbose=0,
tensorboard_log=log_dir)
elif ALGORITHM == 'a2c':
model = A2C(policy=MlpPolicy,
env=env,
policy_kwargs=policy_kwargs,
verbose=0,
tensorboard_log=log_dir)
学習は以下で定義しています。
""" Generate & Check environment """
env_name = ENV_NAME
env = gym.make(env_name)
# print(f'Observation space: {env.observation_space}')
# print(f'Action space: {env.action_space}')
# env = Monitor(env, log_dir, allow_early_resets=True)
# check_env(env)
""" Save config as pickle file """
config = summarize_config(env)
save_config(log_dir, config)
""" Vectorize environment """
num_envs = NUM_ENVS
env = DummyVecEnv([lambda: env for _ in range(num_envs)]) # For training
eval_env = DummyVecEnv([lambda: gym.make(env_name)]) # For evaluation
""" Define checkpoint callback """
checkpoint_callback = CheckpointCallback(save_freq=SAVE_FREQ,
save_path=model_name,
name_prefix=MODEL_NAME)
""" Use deterministic actions for evaluation callback """
eval_callback = EvalCallback(eval_env, best_model_save_path=model_name,
log_path=log_dir, eval_freq=EVAL_FREQ,
deterministic=True, render=False,
n_eval_episodes=N_EVAL_EPISODES)
print(f'Algorithm: {ALGORITHM}\n')
if not CONTINUAL_LEARNING:
""" Define model """
model = define_model(env, log_dir)
else:
model = load_model(env, model_dir, log_dir)
""" Evaluate model before training """
# mean_reward, std_reward = evaluate_policy(model=model,
# env=eval_env,
# n_eval_episodes=N_EVAL_EPISODES)
# print(f'Before training: mean reward: {mean_reward:.2f} +/- {std_reward:.2f}')
""" Train model """
model.learn(total_timesteps=MAX_STEPS,
callback=[checkpoint_callback, eval_callback])
評価は以下で実施しています。
""" Test trained model """
obs = eval_env.reset()
for i in range(N_EVAL_EPISODES):
action, _states = model.predict(obs)
obs, rewards, dones, info = eval_env.step(action)
eval_env.render()
DQN の学習プログラムは、同フォルダ内の 'training_dqn-v0.py' です。学習プログラムは、ほとんど入門マニュアル通りです。
モデルの定義は以下です。
if ALGORITHM == 'dqn':
model = DQN(policy='MlpPolicy', # 'MlpPolicy' not MlpPolicy
env=env,
verbose=0,
tensorboard_log=log_dir,
**kwargs)
学習は以下で定義しています。
""" Generate & Check environment """
env_name = ENV_NAME
env = gym.make(env_name)
# print(f'Observation space: {env.observation_space}')
# print(f'Action space: {env.action_space}')
# env = Monitor(env, log_dir, allow_early_resets=True)
# check_env(env)
""" Save config as pickle file """
config = summarize_config(env)
save_config(log_dir, config)
""" Vectorize environment """
#num_envs = NUM_ENVS
#env = DummyVecEnv([lambda: env for _ in range(num_envs)]) # For training
#eval_env = DummyVecEnv([lambda: gym.make(env_name)]) # For evaluation
eval_env = gym.make(env_name)
""" Define checkpoint callback """
checkpoint_callback = CheckpointCallback(save_freq=SAVE_FREQ,
save_path=model_name,
name_prefix=MODEL_NAME)
""" Use deterministic actions for evaluation callback """
eval_callback = EvalCallback(eval_env, best_model_save_path=model_name,
log_path=log_dir, eval_freq=EVAL_FREQ,
deterministic=True, render=False,
n_eval_episodes=N_EVAL_EPISODES)
print(f'Algorithm: {ALGORITHM}\n')
if not CONTINUAL_LEARNING:
""" Define model """
model = define_model(env, log_dir)
else:
model = load_model(env, model_dir, log_dir)
""" Evaluate model before training """
# mean_reward, std_reward = evaluate_policy(model=model,
# env=eval_env,
# n_eval_episodes=N_EVAL_EPISODES)
# print(f'Before training: mean reward: {mean_reward:.2f} +/- {std_reward:.2f}')
""" Train model """
model.learn(total_timesteps=MAX_STEPS,
callback=[checkpoint_callback, eval_callback])
評価は以下で実施しています。
""" Test trained model """
obs = eval_env.reset()
for i in range(N_EVAL_EPISODES):
action, _states = model.predict(obs)
obs, rewards, dones, info = eval_env.step(action)
eval_env.render()
ハイパー・パラメータは全てデフォルト値のまま使用しています。
PPO2 と A2C では、複数環境の並列処理がサポートされていますので、まず環境数を振って性能を比較してみました。並列処理する環境数が多いと、それだけ多くの異なる環境でのデータをバッチ処理することになるので、一般的には性能が上がります。ただし、ハイパー・パラメータも最適化する必要があります。
DQN は、経験リプレイを使うオフポリシーのアルゴリズムなので、もともとは並列環境がサポートされていません。経験リプレイにデータをため込む worker を複数にして並列環境下で使うことができる Apex-DQN のようなアルゴリズムもあるのですが、きりがないのでランド研究所のレポートに従って、(そこまで難しい問題でもないと思うので)、今回は使用を見送りました。
評価は、ランダムに選んだ 1000 のミッション条件でプランを生成し、その結果得られる平均リターン(-1 ~ 1)で評価しました。リターンは、ミッションが成功したエピソードでは +1、失敗したエピソードでは -1 です。
この例では、学習履歴は下図になりました。横軸がトレーニング・ステップ数、縦軸が平均リターンです。8つの環境を並列処理した PPO2_8 が一番高性能なように見えます。性能比較のテストに用いるモデルは、強化学習で普通行われているように、トレーニング中に callback 函数を使ってベストとなるものを保存して用いました。
図4.1

PPO2 と、A2C, DQN との性能比較をしてみます。A2C も環境の並列処理に対応しているので、環境数8つで実行しました。学習履歴は下図のようになっていて、指数移動平均(EMA: Exponential Moving Average)を見るとPPO2が一番良いようですが、平均リターンの生値(薄いライン)を見ると、どのアルゴリズムであっても、ベストは平均リターン≃1を達成しています。ただ、やはり移動平均が良いもの(PPO2)を使うほうが無難でしょう。
図4.2

5. 性能比較
保存したベスト性能のネットを使ってシミュレーションを行い、random planner, PPO, A2C, DQN の性能比較をしたのが下図表です。いずれのアルゴリズムを用いても、ランダム・プランナーよりはずっと良い成功率となっています。これらの図表からは、PPO2 が少し良いように見えます。また、DQNは少し悪いように見えます。(統計量の比較ではないので、見えます以上のことは言えません)。
ミッション条件 w2 で成功率が低いのですが、これは、w1 や w3 に比べ、ミッション成功のために許される進出タイミングと進出距離のウィンドウがずっと狭い(ミッションを成功させるには、Fighter と Jammer の動きが少し複雑になる)ことによると思われます。
表5.1

図5.1

6. PPO2 による生成プラン例
以下の動画では、濃紺の丸が Fighter、半透明で濃紺の大きな円が Fighter の射程、緑色の丸が Jammer、半透明で緑色の大きな円が Jammer の有効レンジ、赤の丸が SAM 配備位置 、半透明で赤色の大きな円が SAM の射程を表しています。SAMの射程を表す円は、ジャミングを受けると、それに対応した大きさの円に変わります。また、一次元の交戦なのに Fighter, Jammer, SAM が一直線上に並んでいませんが、これは単に見やすくするために Fighter と Jammer 位置を少しだけオフセットさせて表示しているためです。計算は、1次元上の交戦となっています。
ランダムに作ったミッション条件に対し、PPO2 で学習したプランナーが生成したプランの例を以下に示します。
6.1 ケース w1
これは、Jammer を前進させずに、Fighter だけで SAM を撃破しなければならない条件です。
ミッション結果の概要は下記のとおりです。プランとしては、動画に示すように、SAM から離隔した遠方では Fighter, Jammer を一緒に前進させますが、SAMに近づくと Fighter を素早く前進させ、Jammer はあまり前進させないようなプランを生成しています。
{
"Mission": "Success without using Jammer",
"mission_condition": "w1",
"fighter": {
"alive": 1,
"initial_ingress": -9.0,
"ingress": 51.0,
"firing_range": 35.0
},
"jammer": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 33.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 86.0,
"firing_range": 34.0,
"jammed_firing_range": 23.799999999999997
}
}

6.2 ケース w2
これは、最初に Jammer を前進させて SAM の射程を縮退させ、その後で Fighter を進出させて SAM を撃破することが必要なミッション条件です。
ミッション結果の一例は以下のようになります。動画に示すように、最初に SAM の射程を縮退させることができる位置まで Jammer を前進させてます。そして、その地点で Jammer は滞空させて、その間に Fighter を前進させて SAM を撃破するプランが生成できています。
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -7.0,
"ingress": 58.0,
"firing_range": 22.0
},
"jammer": {
"alive": 1,
"initial_ingress": -5.0,
"ingress": 53.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 80.0,
"firing_range": 24.0,
"jammed_firing_range": 16.799999999999997
}
}

別の例を以下に示します。
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 19.0,
"firing_range": 22.0
},
"jammer": {
"alive": 1,
"initial_ingress": -1.0,
"ingress": 13.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 41.0,
"firing_range": 26.0,
"jammed_firing_range": 18.2
}
}

6.3 ケース w3
これは、Jammer を使わずに Fighter のみでミッションを成功できるが、Jammer を使ってもミッションを成功できるケースです。
下記は、Jammer を使わずに Fighter のみでミッションを成功させる生成プランの例です。
{
"Mission": "Success without using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -6.0,
"ingress": 69.0,
"firing_range": 25.0
},
"jammer": {
"alive": 1,
"initial_ingress": -5.0,
"ingress": 42.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 94.0,
"firing_range": 17.0,
"jammed_firing_range": 11.899999999999999
}
}

下記は、Jammer を使ってミッションを成功させる生成プランの例です。SAM の射程を縮退させることができる位置まで Jammer を前進させて滞空させ、その後 Fighter を前進させて SAM を撃破するプランを生成しています。
{
"Mission": "Success with using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 47.0,
"firing_range": 17.0
},
"jammer": {
"alive": 1,
"initial_ingress": -2.0,
"ingress": 36.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 64.0,
"firing_range": 15.0,
"jammed_firing_range": 10.5
}
}

7. A2C による生成プラン例
説明は省きますが、A2Cでも同様の結果を得ることができています。
7.1 ケース w1
{
"Mission": "Success without using Jammer",
"mission_condition": "w1",
"fighter": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 30.0,
"firing_range": 39.0
},
"jammer": {
"alive": 1,
"initial_ingress": -5.0,
"ingress": 14.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 69.0,
"firing_range": 38.0,
"jammed_firing_range": 26.599999999999998
}
}

7.2 ケース w2
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -1.0,
"ingress": 60.0,
"firing_range": 19.0
},
"jammer": {
"alive": 1,
"initial_ingress": -7.0,
"ingress": 56.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 79.0,
"firing_range": 22.0,
"jammed_firing_range": 15.399999999999999
}
}

下記は、ミッションに成功できなかったケースです。Jammerの進出が少し遅れています。
{
"Mission": "Failed",
"mission_condition": "w2",
"fighter": {
"alive": 0,
"initial_ingress": -4.0,
"ingress": 65.0,
"firing_range": 25.0
},
"jammer": {
"alive": 1,
"initial_ingress": -6.0,
"ingress": 57.0,
"jamming": 0
},
"sam": {
"alive": 1,
"offset": 92.0,
"firing_range": 27.0,
"jammed_firing_range": 18.9
}
}

7.3 ケース w3
{
"Mission": "Success without using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -2.0,
"ingress": 42.0,
"firing_range": 29.0
},
"jammer": {
"alive": 1,
"initial_ingress": -2.0,
"ingress": 30.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 71.0,
"firing_range": 24.0,
"jammed_firing_range": 16.799999999999997
}
}

{
"Mission": "Success with using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -7.0,
"ingress": 60.0,
"firing_range": 15.0
},
"jammer": {
"alive": 1,
"initial_ingress": -6.0,
"ingress": 46.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 75.0,
"firing_range": 13.0,
"jammed_firing_range": 9.1
}
}

8. まとめ
ミッション条件 w1, w2, w3 のそれぞれに対して、ミッションを成功するために生成しなければならないプランを、強化学習したミッション・プランナー(Agent)により生成できることが判りました。
(その9)に続く
現在の強化学習のレベルからして、この環境は簡単すぎるので、(その9)では、ミッション条件に l1, l2 を追加する等して、環境を少し複雑にしてみます。
過去記事へのリンク
- ランド研究所の「機械学習による航空支配」を実装する(その1):レポートのまとめ
- ランド研究所の「機械学習による航空支配」を実装する(その2):1次元問題について
- ランド研究所の「機械学習による航空支配」を実装する(その3): 1D simulator for GAN と Random mission planner の実装)
- ランド研究所の「機械学習による航空支配」を実装する(その4): conditional GAN の実装とトレーニング
- ランド研究所の「機械学習による航空支配」を実装する(その5):トレーニング結果の分析
- ランド研究所の「機械学習による航空支配」を実装する(その6):トレーニング・データの重要性と GAN の性能向上
- ランド研究所の「機械学習による航空支配」を実装する(その7):1D simulator for RL の実装