株式会社デジサク がお送りするプログラミング記事、
今回はAI(機械学習)の具体的なコーディング手順を扱います。
※ 無料セミナーも開催中なので、ぜひご覧になってみて下さい。
はじめに
これまで「機械学習を仕事に使うには?」というテーマで記事をお届けしてきましたが、
第3回の今回は「Pythonのコーディング手順」をテーマに、具体的なプログラミングを紹介します。
バックナンバーも読んで頂くと機械学習の基礎からPythonのコーディングまで全体を理解できますので、ぜひご活用ください。
SNS でも色々な情報を発信しているので、記事を読んで良いなと感じて頂けたら
Twitterアカウント「Saku731」 もフォロー頂けると嬉しいです。
機械学習に必要なプログラミングスキル
まず、機械学習を習得するために必要なスキルは下記の通りです。
これらを1個ずつコーディングしていきましょう。
- 1)データの可視化 :データの全体感を掴んで前処理の方針を決める
- 2)データの前処理 :予測精度が高くなるよう、データを綺麗にする
- 3)アルゴリズムの選定:データに対して適切なアルゴリズムを決める
- 4)モデルの学習 :コンピュータにデータの法則性を学習させる
- 5)モデルの検証 :出来上がったモデルの予測精度を確認する
Python環境の構築(読み飛ばしてもOK)
Pythonでプログラミングを進めるには Jupyter Notebook が必須です。
もし手元のPCにプログラミング環境が整っていない場合は下記を参考に準備されてください。
とても丁寧な資料なので、初めての方でもご安心ください。
準備)使用するデータの入手
Kaggleをはじめ、最近はどのWebサービスを見ても「タイタニック」のデータが使用されている事が多いです。つまり勉強に困った場合でも参考記事が豊富なので、この記事でもタイタニックのデータを使用します。
データのダウンロードはこちらからどうぞ。
それでは、機械学習の一連手順をコーディングして行きましょう。
1)データの可視化
データの可視化では「データの全体感を掴んで前処理の方針を決める」ことが目的です。
データの読み込み
まずはどういった内容のデータなのか確認します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# CSVデータの読み込み
df_train = pd.read_csv('train.csv')
# 読み込んだCSVデータの確認
df_train.head()
上手く行くと下図の様に表示されます。
こういった形式のデータを DataFrame形式(データフレーム形式) と呼ぶので覚えておきましょう。

各行の説明は以下の通りです。
今回は「生存結果」を予測する問題なので「Survived」が予測の対象となります。
- PassengerID:乗客ID
- Survived:生存結果 (1: 生存, 2: 死亡)
- Pclass:乗客の階級
- Name:乗客の名前
- Sex:性別
- Age:年齢
- SibSp:兄弟、配偶者の数。
- Parch:両親、子供の数。
- Ticket:チケット番号。
- Fare:乗船料金。
- Cabin:部屋番号
- Embarked:乗船した港
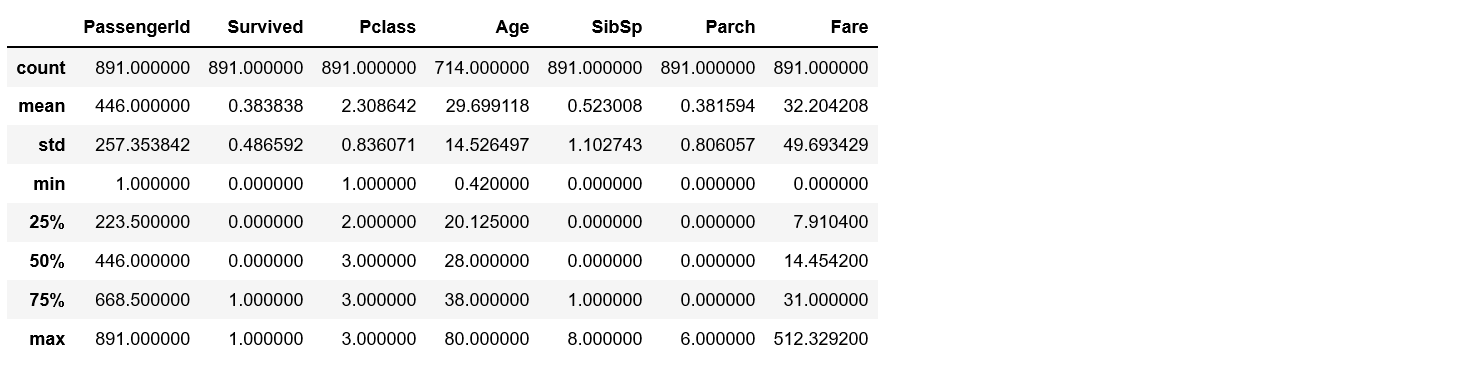
基礎統計量の確認
次に、データの平均値や、バラつきを示す標準偏差を確認します。
df_train.describe()
ここで確認するポイントは以下の通りです。
平均値・標準偏差をどの様に活用するのかは少し慣れてから覚えるスキルなので、また別の記事で紹介します。
- mean:データの平均値
- std:データの標準偏差(数値のバラつき具合)
- min:データの最小値
- 50%:データの中央値
- max:データの最大値
欠損値の処理
次に行うべき処理が欠損値の処理です。欠損値とは、何らかの理由でデータが欠けている状態です。
このままではプログラムを進めて行く中でエラーが発生するので必ず早い段階で対応しないといけないです。
詳しく知りたい方は【こちら】を参照して頂くと細かなプログラミング手順まで理解いただけます。
データに欠損値が含まれているか確認するには以下のコードを実行します。
df_train.isnull().sum()

今回は「Age」「Cabin」の列に欠損値が含まれている様です。
欠損値に対して、一般的には『除去』『補完』の2種類の対応方法があります。
- 除去:欠損値が含まれている場合、その行ごと削除してデータ自体を無かったことにする
- 補完:欠損値を何らかの数値(平均値、中央値など)で補って、欠損じゃない状態にする
除去を行う方が簡単なので、今回はdropna()を使って除去を行います。
df_train = df_train.dropna()
うまく欠損値を取り除けたか、確認してみましょう。
df_train.isnull().sum()
このように、すべての行で欠損値が0個だと確認できたので先の処理に進むことができます。

グラフを描く
ここまで完了したら様々なグラフを描いてデータの傾向を掴みます。
必ず上手く行くような決まったパターンはないのですが、機械学習で使用する手法を全公開 で紹介している「1)データの可視化」を確認いただくと必要スキルの全体像を掴んでいただけます。
例えば、グラフ化で最も頻繁に使用されるヒストグラムを使用すると以下の様なグラフを描けます。
■準備:ライブラリのインポート
import matplotlib.pyplot as plt
%matplotlib inline
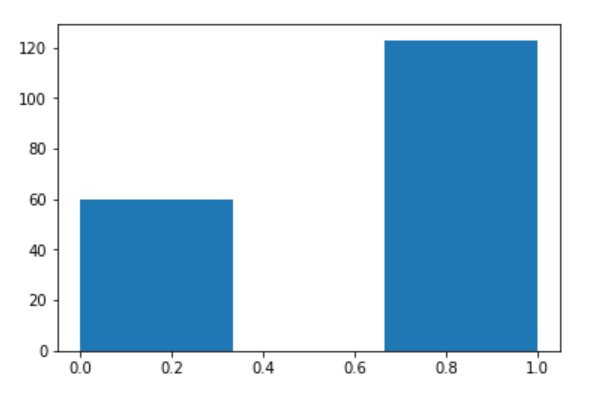
■グラフ1:乗客の生存数と死亡数を確認
まず、データから生存数・死亡数の比較を行います。
コードを実行してヒストグラムを確認すると**「生存数 60:死亡数 120」**だと分かりました。
plt.hist(df_train['Survived'], bins=3)
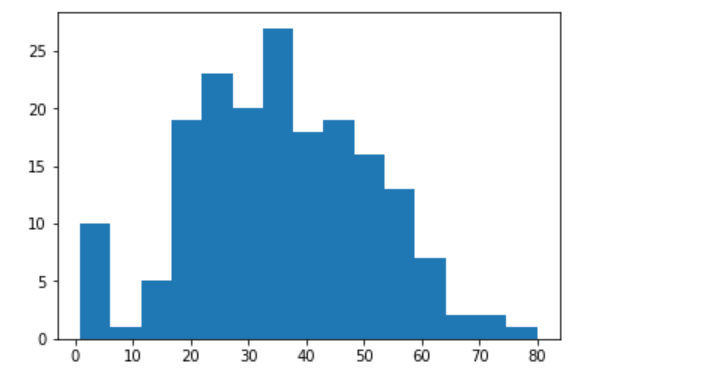
■グラフ2:年齢の分布を描く
年齢の分布を描くと35~40歳の乗者が最も多かったことが分かります。また、0~5歳の乗者が多い点を考えると「乳幼児を連れて乗船していた親が居たのだな」などの推察を得る事ができます。
plt.hist(df_train['Age'], bins=15)
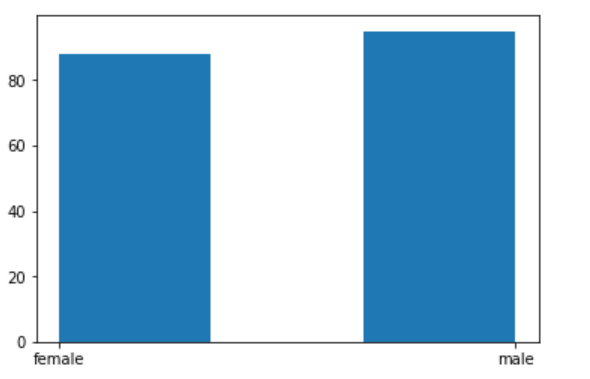
■グラフ3:性別の分布
性別の分布を描くと、ほぼ同じ人数の男女が乗船していたことが分かります。
plt.hist(df_train['Sex'], bins=3)
■グラフ4:性別×生存率の分布を描く
ここは少し応用になりますが、グラフ化の際にはデータの集計を行うことが多いです。
どういった手法があるのか、全体感は 機械学習で使用する手法を全公開 の「1)データの可視化」で紹介してありますが、今回は クロス集計 という手法を使ってみます。
# クロス集計
df_survived = pd.crosstab(df_train['Sex'], df_train['Survived'])
df_survived
クロス集計の結果を確認いただくと、女性の方が生存数が明らかに高いことが分かります。
※Survived=1が「生存」です。
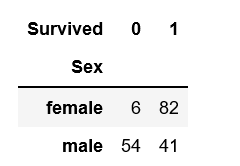
少しわかりにくいので、全体数で割って 生存率 でクロス集計しておきましょう。
# クロス集計
df_survived = pd.crosstab(df_train['Sex'], df_train['Survived'], normalize='index')
df_survived
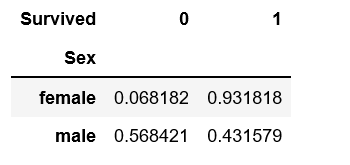
これをグラフ化すると明らかに男女間で生存率に違いがあることが見て取れます。
女性の生存率が圧倒的に高い ので女性が優先して救助されたのでしょう。
# 生存率・死亡率の男女比を取得
# 生存者の男女比
df_survived_1 = df_survived[1].values
# 死亡者の男女比
df_survived_0 = df_survived[0].values.tolist()
# 生存率の男女比
plt.bar(x=np.array(['female','male']), height=df_survived_1)
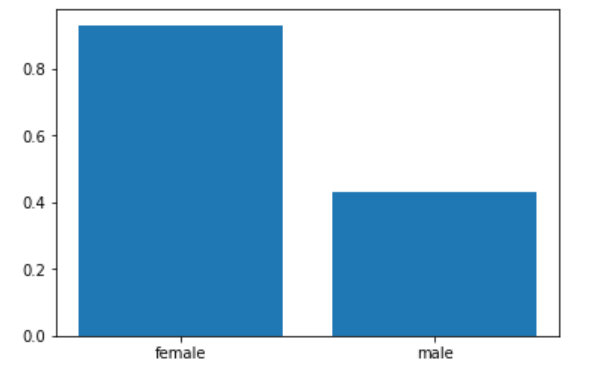
# 死亡率の男女比
plt.bar(x=np.array(['female','male']), height=df_survived_0)
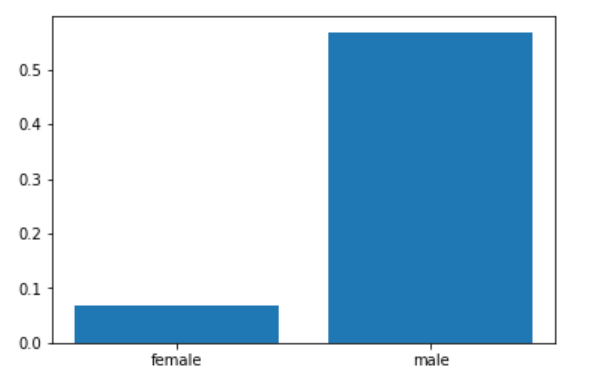
このようにして様々なグラフを描くことでデータの特性を掴んでいきます。
他にも様々な手法があるので、興味がある方は 【こちら】 で勉強されると良いです。
2)データの前処理
データを確認した後は、機械学習で使用できるデータ(良い予測精度がでるデータ)になるよう前処理を行います。
本来であれば可視化して得た情報を参考に様々なデータ加工を行うのですが、最初の勉強には難しすぎるので最も簡単かつ重要な「エンコーディング」を扱って行きます。
カテゴリカル変数のエンコーディング
続いて、 カテゴリカル変数 という変数に対して処理が必要です。
カテゴリカル変数を簡単に説明すると「文字データ」の事です。
※必ずしも文字データではない事もありますが、入門的な理解としては十分です。
最初に表示したデータをもう一度表示してみて下さい。
すると、「male」「female」といった文字データが含まれています。
df_train.head()
機械学習で使用するデータには「数値データを使用する」という制約があります。
そのため、何らかの方法で文字データを数値データに変換が必要です。
1番ポピュラーな方法として get_dummies() を用いた One-Hot エンコーディング が使用されます。
# One-Hot エンコーディング
df_train = pd.get_dummies(df_train)
# 変換後のデータを確認
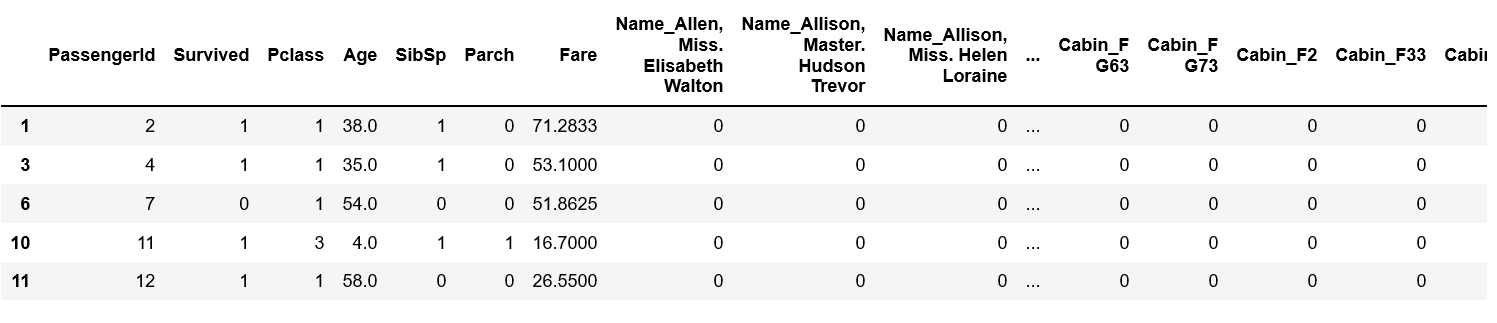
df_train.head()
下図の通り、文字データが「0」「1」に置き換わったので機械学習で使用できるデータになりました。
細かい背景を理解したい場合には【こちら】の記事を参考ください。
3)アルゴリズムの選定
アルゴリズムとは
機械学習でデータから法則性を抽出するためには、データに適した分析手法 が必要です。
その分析手法の事をアルゴリズムと呼びます。
アルゴリズムには様々な種類があり、代表的なものは以下の通りです。
個々のアルゴリズムを詳しく知りたい方は【こちら】を参照ください。
- 回帰(売上、来店数などの数値予測)
- 線形回帰(単回帰、重回帰)
- 回帰木
- ランダムフォレスト回帰
- 分類(A or B のような選択問題の予測)
- ロジステック回帰
- 決定木
- ランダムフォレスト
- サポートベクターマシン(SVM)
- どちらにも使える
- ニューラルネットワーク(ディープラーニング)
- XGBoost
- LightGBM
今回使用するアルゴリズム
使用するアルゴリズムが変わると結果も変わる点を理解する事が重要です。
なので。SVM・決定木・ランダムフォレストの3種類を使用してみましょう。
sklearn を使用すると大体のアルゴリズムは包括されているので便利です。
# サポートベクターマシン(SVM)
from sklearn.svm import SVC
# 決定木(Decision Tree)
from sklearn.tree import DecisionTreeClassifier
# ランダムフォレスト(Ramdom Forest)
from sklearn.ensemble import RandomForestClassifier
4)モデルの学習
使用するアルゴリズムが準備できたので、モデルを学習させていきましょう。
まずは、データを訓練データ・検証データに分割する必要があります。
理由としては、モデルを学習させた後に、
学習が上手く行ったのかを確認する検証フェーズが必要だからです。
データの分割には ホールドアウト法 と呼ばれる手法が有名です。
- データを「説明変数」と「目的変数」に分ける
- それぞれ訓練データ:検証データ=7:3に分割する
説明変数と目的変数への分割
まずは「説明変数」と「目的変数」に分けましょう。
- 目的変数:AIで予測を行う対象(今回は生存状況なので「Survived」の列)
- 説明変数:目的変数を予測するために使用する情報(「Survived以外」の列)
先ほど表示させたデータの列名に注目してください。
「Survived」は2列目、そのほかの列は3列目以降にあります。
※「PassengerId:乗客ID」は単なる列番号なので不要です。
DataFrame 形式のデータを説明変数・目的変数に分けるには iloc[] を使用すると便利です。
詳しくは【こちら】の記事を参照ください。
# 説明変数
X = df_train.iloc[:, 2:]
# 目的変数
t = df_train.iloc[:, 1]
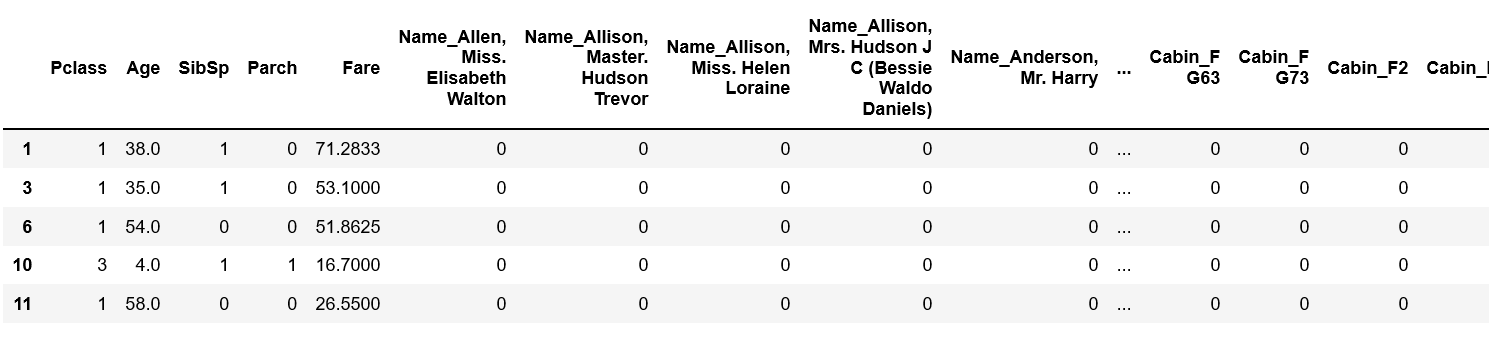
説明変数 X を確認すると以下の様に「Pclass」以降の列が正しく抽出できています。
X.head()
また、 t についても確認すると生存状況「0 / 1」が抽出できています。
t.head()

訓練データ:検証データ=7:3に分割
続いて、説明変数・目的変数を 訓練データ と 検証データ に分割して行きます。
sklearn の train_test_split を使用します。
# ライブラリのインポート
from sklearn.model_selection import train_test_split
# 7:3で分割の実行
X_train, X_valid, t_train, t_valid = train_test_split(X, t, train_size=0.7, random_state=0)
len() を使用するとデータ量を確認できるので、きちんと7:3に分割できている確認しましょう。
# 元データ
print(len(df_train))
# 分割後のデータ
print(len(X_train), len(X_valid))
ハイパーパラメータの設定
アルゴリズムとデータを用意したら、最後に ハイパーパラメータ という数値を設定する必要があります。
ハイパーパラメータとは、アルゴリズムをデータに適合させるための微調整を担う設定値です。
- アルゴリズム:データに対する 分析の切り口 を決める事が目的
- ハイパーパラメータ:アルゴリズムがデータに適合するよう 微調整 を行うことが目的
アルゴリズムとハイパーパラメータの効果が理解できるよう、各アルゴリズムに対して3つずつハイパーパラメータを設定してみましょう。つまり、「アルゴリズム3種類×ハイパーパラメータ3種類=9種類のモデル」を学習させる事になります。
# サポートベクターマシン(SVM)
model_svm_1 = SVC(C=0.1)
model_svm_2 = SVC(C=1.0)
model_svm_3 = SVC(C=10.0)
model_svm_1.fit(X_train, t_train)
model_svm_2.fit(X_train, t_train)
model_svm_3.fit(X_train, t_train)
# 決定木(Decision Tree)
model_dt_1 = DecisionTreeClassifier(max_depth=3)
model_dt_2 = DecisionTreeClassifier(max_depth=5)
model_dt_3 = DecisionTreeClassifier(max_depth=10)
model_dt_1.fit(X_train, t_train)
model_dt_2.fit(X_train, t_train)
model_dt_3.fit(X_train, t_train)
# ランダムフォレスト(Ramdom Forest)
model_rf_1 = RandomForestClassifier(max_depth=3)
model_rf_2 = RandomForestClassifier(max_depth=5)
model_rf_3 = RandomForestClassifier(max_depth=10)
model_rf_1.fit(X_train, t_train)
model_rf_2.fit(X_train, t_train)
model_rf_3.fit(X_train, t_train)
5)モデルの検証
9種類のモデルについて学習が済んだので、各モデルの予測精度を確認してみましょう。
print('SVM_1の予測精度:', round(model_svm_1.score(X_valid, t_valid) * 100, 2), '%')
print('SVM_2の予測精度:', round(model_svm_2.score(X_valid, t_valid) * 100, 2), '%')
print('SVM_3の予測精度:', round(model_svm_3.score(X_valid, t_valid) * 100, 2), '%')
print('決定木_1の予測精度:', round(model_dt_1.score(X_valid, t_valid) * 100, 2), '%')
print('決定木_2の予測精度:', round(model_dt_2.score(X_valid, t_valid) * 100, 2), '%')
print('決定木_3の予測精度:', round(model_dt_3.score(X_valid, t_valid) * 100, 2), '%')
print('ランダムフォレスト_1の予測精度:', round(model_rf_1.score(X_valid, t_valid) * 100, 2), '%')
print('ランダムフォレスト_2の予測精度:', round(model_rf_2.score(X_valid, t_valid) * 100, 2), '%')
print('ランダムフォレスト_3の予測精度:', round(model_rf_3.score(X_valid, t_valid) * 100, 2), '%')
上記のコードを実行すると結果は以下のようになります。
アルゴリズム・ハイパーパラメータの違いで結果(予測精度)も変わることが確認できます。

今回は決定木の2番目が最も良い予測精度となりました。
実際にAI開発を行う際には、先ほどご紹介したグリッドサーチなどを使用して、もっと楽にハイパーパラメータのチューニングを行います。詳しく知りたい方は参考記事を見て頂くと実装方法を確認いただけます。
さいごに
以上がAI(学習済みモデル)の開発に必要な機械学習の基本的な一連手順となります。
この流れをベースに、もっと良い予測精度が出せる複雑な方法を理解して行くと良いです。
バックナンバーも読んで頂くと機械学習の基礎からPythonのコーディングまで全体を理解できます。
更にプログラミングを深めたい方は必要スキルを網羅した記事も書いてあるのでぜひ参照されてください。
P.S.
SNS でも色々な情報を発信しているので、記事を読んで良いなと感じて頂けたら
Twitterアカウント「Saku731」 もフォロー頂けると嬉しいです。
また、文末にはなりますが、期間限定で「チーム開発体験プロジェクト」をやってます。
もしご興味あれば【応募シート】で詳細確認してください。
(追記)
満員のため締め切らせて頂きました。
次回は2019年3月を予定しているので、ご案内を希望される方は【予約フォーム】にご記載ください。