CycleGANsの論文を理解する
実装編です。
初めに、こちらの記事はKaggleのI’m Something of a Painter Myselfでのノートブック
Monet CycleGAN Tutorial を参考にしています。
I’m Something of a Painter Myself
まずこのコンペについてですが
We recognize the works of artists through their unique style, such as color choices or brush strokes. The “je ne sais quoi” of artists like Claude Monet can now be imitated with algorithms thanks to generative adversarial networks (GANs). In this getting started competition, you will bring that style to your photos or recreate the style from scratch!
Computer vision has advanced tremendously in recent years and GANs are now capable of mimicking objects in a very convincing way. But creating museum-worthy masterpieces is thought of to be, well, more art than science. So can (data) science, in the form of GANs, trick classifiers into believing you’ve created a true Monet? That’s the challenge you’ll take on!
とあります。
つまり分類器が本物のモネの絵画と信じるような絵画を生む生成器をGANsを用いて作ってみろってことです。
簡単に、GANsとは最低でも二つのニューラルネットワークを含んで構成されます。
生成モデルと判別モデルです。
生成モデルは判別モデルを欺こうと、判別モデルは欺かせまいと互いに競争させることでより高度なモデルが形成されるというわけです。
このコンペのタスクとして”7,000 to 10,000のモネの絵画を生成するモデルを作ること”が課せられています。
実装
実際に組み立てていきます。
*Kaggleの解説やtensorflowの基礎的なものは省くことになりますので不安な方はある程度予習して頂けるとよりこの記事を理解できるかもしれません。
セットアップ
CycleGANを用い写真をモネ風に変換するようなモデルの作成を目指します。
TFRecordというデータ形式を用います。
このフォーマットを使うと学習時に使用するデータが多い時に便利です。
プロセッサにTPUを用います。
KaggleのnotebookでTPUを扱う場合、電話認証を完了し右側のドロップダウンでの設定で『TPU』、『Internet』の設定をオンにする必要があります。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_addons as tfa
from kaggle_datasets import KaggleDatasets
import matplotlib.pyplot as plt
import numpy as np
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
except:
strategy = tf.distribute.get_strategy()
AUTOTUNE = tf.data.experimental.AUTOTUNE
主に初期化のコードです。
tpuはGoogle Cloud TPUのクラスタリングを行います。
TPUStrategyは同期分散訓練を実装します。
同期分散訓練はネットワークのコピー(レプリカ)を用意し、個別に訓練させ、iteration毎に勾配の平均を全体に同期し訓練する手法です。
データの読み込み
写真データセットとモネの絵画データセットは分けて保存します。
まずTFRecordにロードします。
GCS_PATH = KaggleDatasets().get_gcs_path()
MONET_FILENAMES = tf.io.gfile.glob(str(GCS_PATH + '/monet_tfrec/*.tfrec'))
PHOTO_FILENAMES = tf.io.gfile.glob(str(GCS_PATH + '/photo_tfrec/*.tfrec'))
コンペ用の画像は全て256x256に統一されています。
これらはRGB画像のためチャンネルを3(R、G、B3色を使ってエンコードする)に設定します。
そして画像スケールを[-1, 1]にスケーリングします。
また生成モデルの作成であるためレベルやidは不要で、TFRecordからは画像そのものだけが返ってくるようにします。
IMAGE_SIZE = [256, 256]
def decode_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = (tf.cast(image, tf.float32) / 127.5) - 1
image = tf.reshape(image, [*IMAGE_SIZE, 3])
return image
def read_tfrecord(example):
tfrecord_format = {
"image_name": tf.io.FixedLenFeature([], tf.string),
"image": tf.io.FixedLenFeature([], tf.string),
"target": tf.io.FixedLenFeature([], tf.string)
}
example = tf.io.parse_single_example(example, tfrecord_format)
image = decode_image(example['image'])
return image
ファイルから画像を取り出すファンクションを定義します。
def load_dataset(filenames, labeled=True, ordered=False):
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(read_tfrecord, num_parallel_calls=AUTOTUNE)
return dataset
早速ロードします。
monet_ds = load_dataset(MONET_FILENAMES, labeled=True).batch(1)
photo_ds = load_dataset(PHOTO_FILENAMES, labeled=True).batch(1)
example_monet = next(iter(monet_ds))
example_photo = next(iter(photo_ds))
これらの写真、画像を可視化してみます。
plt.subplot(121)
plt.title('Photo')
plt.imshow(example_photo[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Monet')
plt.imshow(example_monet[0] * 0.5 + 0.5)

こういった感じで出力されます。
生成ネットワークの実装
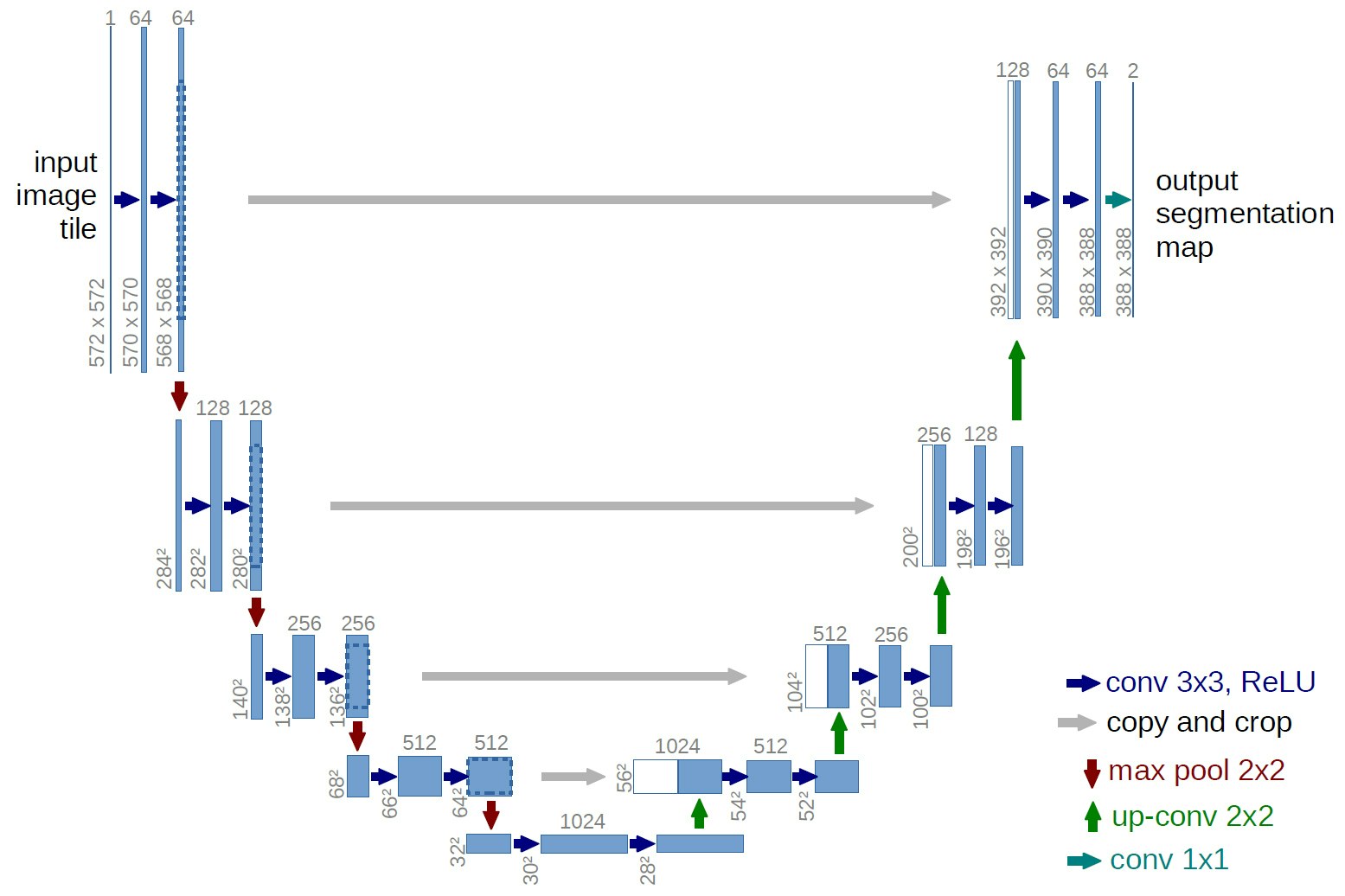
今回、CycleGANのアーキテクチャにはUNETというものを使用します。
UNETとはFCN(fully convolution network)の一種でセグメンテーションのネットワークです。
簡単に、downsampleで画像の物体の位置情報を取得し、upsampleで物体の特徴を得ようとします(この下がって上がる構造がアルファベットのUに似ているのが名前の由来っぽい)。
さてまずはこのdownsampleとupsampleを定義しましょう。
downsample
downsampleとはその名(下方にサンプリングする)の通り、ストライドに沿って、画像の高さと横幅の2次元をダウンサイズします。
ストライドはフィルター(畳み込み時の小さいエリア)がとるステップの長さになります。
今回はストライドが2なのでフィルターが全てのピクセルに適用され、高さと横幅が2ずつ減らせれ(縮小され)ていきます。
正規化(データを何らかの操作によって統一の大きさにする)にはbatch normalizationの代わりにinstance normalizationを採用します。
instance normalizationはTensorFlow APIでは標準でないのでアドオンのレイヤーを使用します。
instance normalizationでは各チャンネル毎に画像の縦横方向についてのみ平均・分散を取ります。
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_instancenorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
gamma_init = keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
result = keras.Sequential()
result.add(layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_instancenorm:
result.add(tfa.layers.InstanceNormalization(gamma_initializer=gamma_init))
result.add(layers.LeakyReLU())
return result
keras.initializers.RandomNormalで正規分布に従って重みの初期化を行います。
mean、stddevそれぞれ分布の平均、標準偏差を引数として指定できます。
upsample
downsampleとは逆に次元を増や(復元)していきます。
Conv2DTransposeは逆畳み込みを行います。
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
gamma_init = keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
result = keras.Sequential()
result.add(layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tfa.layers.InstanceNormalization(gamma_initializer=gamma_init))
if apply_dropout:
result.add(layers.Dropout(0.5))
result.add(layers.ReLU())
return result
layers.Dropoutで行われるDropoutとはネットワークにおける一部のユニットを消す(ドロップアウト)ことで通常のBaggingなどと比べ比較的簡単にサブネットワークを作成し汎化性能を強めることができます。
generator
生成ネットワークを作っていきます。
入力画像をdownsampleしupsampleします。
この時、skip connectionsを作っておきます。
skip connectionsは勾配問題、ここではdownsample時の物体の位置情報の損失を、複数記録しておき、出力のレイヤーに繋げることで防ぎます。
下記の画像における灰色矢印の部分。
def Generator():
inputs = layers.Input(shape=[256,256,3])
# bs = batch size
down_stack = [
downsample(64, 4, apply_instancenorm=False), # (bs, 128, 128, 64)
downsample(128, 4), # (bs, 64, 64, 128)
downsample(256, 4), # (bs, 32, 32, 256)
downsample(512, 4), # (bs, 16, 16, 512)
downsample(512, 4), # (bs, 8, 8, 512)
downsample(512, 4), # (bs, 4, 4, 512)
downsample(512, 4), # (bs, 2, 2, 512)
downsample(512, 4), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)
upsample(512, 4), # (bs, 16, 16, 1024)
upsample(256, 4), # (bs, 32, 32, 512)
upsample(128, 4), # (bs, 64, 64, 256)
upsample(64, 4), # (bs, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (bs, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = layers.Concatenate()([x, skip])
x = last(x)
return keras.Model(inputs=inputs, outputs=x)
識別ネットワークの実装
識別器は入力画像を受け取り、本物と偽物(意図的に生成された画像)とを識別します。
出力は単一のノードではなく、より小さな2Dの画像として出力され、高いピクセルの画像は本物、低いピクセルの画像は偽物としての識別を示唆します。
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
gamma_init = keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
inp = layers.Input(shape=[256, 256, 3], name='input_image')
x = inp
down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256)
zero_pad1 = layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)
conv = layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (bs, 31, 31, 512)
norm1 = tfa.layers.InstanceNormalization(gamma_initializer=gamma_init)(conv)
leaky_relu = layers.LeakyReLU()(norm1)
zero_pad2 = layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)
last = layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)
return tf.keras.Model(inputs=inp, outputs=last)
LeakyReLUとはReLUの改編版で普通のReLUでは入力が0以下の場合、出力も0に固定されますが、LeakyReLUでは0未満に0未満の出力を返します。
これにより0以下の入力にも勾配が発生することになります。
with strategy.scope():
monet_generator = Generator() # transforms photos to Monet-esque paintings
photo_generator = Generator() # transforms Monet paintings to be more like photos
monet_discriminator = Discriminator() # differentiates real Monet paintings and generated Monet paintings
photo_discriminator = Discriminator() # differentiates real photos and generated photos
生成した画像を出力して見ます。
to_monet = monet_generator(example_photo)
plt.subplot(1, 2, 1)
plt.title("Original Photo")
plt.imshow(example_photo[0] * 0.5 + 0.5)
plt.subplot(1, 2, 2)
plt.title("Monet-esque Photo")
plt.imshow(to_monet[0] * 0.5 + 0.5)
plt.show()
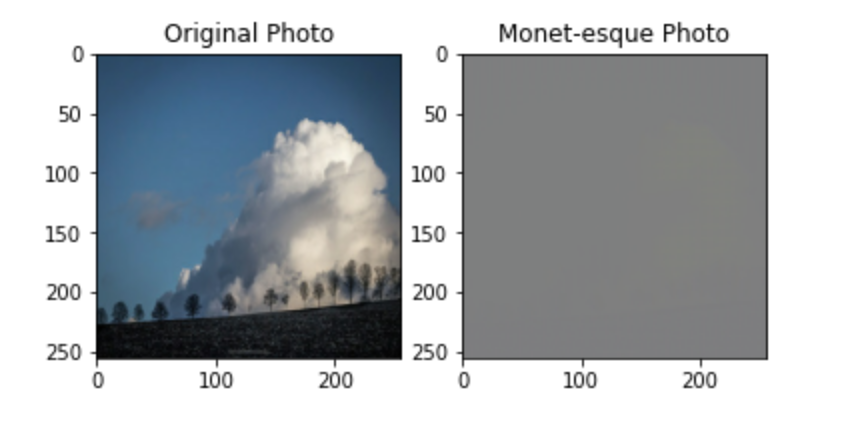
訓練を行なっていないのでこのような出力になります。
CycleGANモデルの作成
後にfit()を用い訓練を行うためにtf.keras.Modelをサブクラスとして使用します。
訓練ではモデルは写真→モネ風絵画→写真の変換を行います。
1回目のオリジナルの写真と2回目の写真との差異はcycle-consistency loss(詳しくは関連記事を参照ください)となります。
これらの差異を小さくするのが目的となります。
損失関数については後ほど実装します。
class CycleGan(keras.Model):
def __init__(
self,
monet_generator,
photo_generator,
monet_discriminator,
photo_discriminator,
lambda_cycle=10,
):
super(CycleGan, self).__init__()
self.m_gen = monet_generator
self.p_gen = photo_generator
self.m_disc = monet_discriminator
self.p_disc = photo_discriminator
self.lambda_cycle = lambda_cycle
def compile(
self,
m_gen_optimizer,
p_gen_optimizer,
m_disc_optimizer,
p_disc_optimizer,
gen_loss_fn,
disc_loss_fn,
cycle_loss_fn,
identity_loss_fn
):
super(CycleGan, self).compile()
self.m_gen_optimizer = m_gen_optimizer
self.p_gen_optimizer = p_gen_optimizer
self.m_disc_optimizer = m_disc_optimizer
self.p_disc_optimizer = p_disc_optimizer
self.gen_loss_fn = gen_loss_fn
self.disc_loss_fn = disc_loss_fn
self.cycle_loss_fn = cycle_loss_fn
self.identity_loss_fn = identity_loss_fn
def train_step(self, batch_data):
real_monet, real_photo = batch_data
with tf.GradientTape(persistent=True) as tape:
# photo to monet back to photo
fake_monet = self.m_gen(real_photo, training=True)
cycled_photo = self.p_gen(fake_monet, training=True)
# monet to photo back to monet
fake_photo = self.p_gen(real_monet, training=True)
cycled_monet = self.m_gen(fake_photo, training=True)
# generating itself
same_monet = self.m_gen(real_monet, training=True)
same_photo = self.p_gen(real_photo, training=True)
# discriminator used to check, inputing real images
disc_real_monet = self.m_disc(real_monet, training=True)
disc_real_photo = self.p_disc(real_photo, training=True)
# discriminator used to check, inputing fake images
disc_fake_monet = self.m_disc(fake_monet, training=True)
disc_fake_photo = self.p_disc(fake_photo, training=True)
# evaluates generator loss
monet_gen_loss = self.gen_loss_fn(disc_fake_monet)
photo_gen_loss = self.gen_loss_fn(disc_fake_photo)
# evaluates total cycle consistency loss
total_cycle_loss = self.cycle_loss_fn(real_monet, cycled_monet, self.lambda_cycle) + self.cycle_loss_fn(real_photo, cycled_photo, self.lambda_cycle)
# evaluates total generator loss
total_monet_gen_loss = monet_gen_loss + total_cycle_loss + self.identity_loss_fn(real_monet, same_monet, self.lambda_cycle)
total_photo_gen_loss = photo_gen_loss + total_cycle_loss + self.identity_loss_fn(real_photo, same_photo, self.lambda_cycle)
# evaluates discriminator loss
monet_disc_loss = self.disc_loss_fn(disc_real_monet, disc_fake_monet)
photo_disc_loss = self.disc_loss_fn(disc_real_photo, disc_fake_photo)
# Calculate the gradients for generator and discriminator
monet_generator_gradients = tape.gradient(total_monet_gen_loss,
self.m_gen.trainable_variables)
photo_generator_gradients = tape.gradient(total_photo_gen_loss,
self.p_gen.trainable_variables)
monet_discriminator_gradients = tape.gradient(monet_disc_loss,
self.m_disc.trainable_variables)
photo_discriminator_gradients = tape.gradient(photo_disc_loss,
self.p_disc.trainable_variables)
# Apply the gradients to the optimizer
self.m_gen_optimizer.apply_gradients(zip(monet_generator_gradients,
self.m_gen.trainable_variables))
self.p_gen_optimizer.apply_gradients(zip(photo_generator_gradients,
self.p_gen.trainable_variables))
self.m_disc_optimizer.apply_gradients(zip(monet_discriminator_gradients,
self.m_disc.trainable_variables))
self.p_disc_optimizer.apply_gradients(zip(photo_discriminator_gradients,
self.p_disc.trainable_variables))
return {
"monet_gen_loss": total_monet_gen_loss,
"photo_gen_loss": total_photo_gen_loss,
"monet_disc_loss": monet_disc_loss,
"photo_disc_loss": photo_disc_loss
}
GradientTapeは自動微分を行なってくれます。
公式ドキュメントによると
TensorFlow は、tf.GradientTape のコンテキスト内で行われる演算すべてを「テープ」に「記録」します。その後 TensorFlow は、そのテープと、そこに記録された演算ひとつひとつに関連する勾配を使い、トップダウン型自動微分(リバースモード)を使用して、「記録」された計算の勾配を計算します。
(https://www.tensorflow.org/tutorials/customization/autodiff?hl=ja)
とあります。
つまりそういうことです。
損失関数の作成
下記の判別器での損失関数は本物を1の行列、偽物を0の行列とで比較します。
つまり判別器が完璧な判別を行った時、判別器は本物には全てが1、偽物には全てが0を出力します。
また判別器の損失は本物、偽物の損失の平均値で出力されます。
with strategy.scope():
def discriminator_loss(real, generated):
real_loss = tf.keras.losses.BinaryCrossentropy(from_logits=True, reduction=tf.keras.losses.Reduction.NONE)(tf.ones_like(real), real)
generated_loss = tf.keras.losses.BinaryCrossentropy(from_logits=True, reduction=tf.keras.losses.Reduction.NONE)(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
2値分類問題であるのでBinary Cross Entropyを用いています。
前述の通り、生成器の理想は全てが1の出力の判別器(1だと判別器を騙せている)なのでそれを基準に損失を算出しまう。
with strategy.scope():
def generator_loss(generated):
return tf.keras.losses.BinaryCrossentropy(from_logits=True, reduction=tf.keras.losses.Reduction.NONE)(tf.ones_like(generated), generated)
オリジナルの写真と再変換された写真を近づけたいのでcycle consistency lossを用いて差異の平均値を計算します。
with strategy.scope():
def calc_cycle_loss(real_image, cycled_image, LAMBDA):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
identity lossはオリジナルと生成器を比較します。
つまり入力を生成器の出力を比べます。
with strategy.scope():
def identity_loss(real_image, same_image, LAMBDA):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
CycleGANの訓練
モデルをコンパイルします。
tf.keras.Modelをサブクラスにしているのでfit関数だけで訓練を行えます。
with strategy.scope():
monet_generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
photo_generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
monet_discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
photo_discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
with strategy.scope():
cycle_gan_model = CycleGan(
monet_generator, photo_generator, monet_discriminator, photo_discriminator
)
cycle_gan_model.compile(
m_gen_optimizer = monet_generator_optimizer,
p_gen_optimizer = photo_generator_optimizer,
m_disc_optimizer = monet_discriminator_optimizer,
p_disc_optimizer = photo_discriminator_optimizer,
gen_loss_fn = generator_loss,
disc_loss_fn = discriminator_loss,
cycle_loss_fn = calc_cycle_loss,
identity_loss_fn = identity_loss
)
cycle_gan_model.fit(
tf.data.Dataset.zip((monet_ds, photo_ds)),
epochs=25
)
最適化にtf.keras.optimizers.AdamいわゆるAdamというものが使われていますが局所最適解やオーバーシュートによる振動を抑えられる優れものです。
Adamに関してはこの記事がわかりやすかったです。
https://qiita.com/omiita/items/1735c1d048fe5f611f80#7-adam
モネ風に変換した写真の可視化
_, ax = plt.subplots(5, 2, figsize=(12, 12))
for i, img in enumerate(photo_ds.take(5)):
prediction = monet_generator(img, training=False)[0].numpy()
prediction = (prediction * 127.5 + 127.5).astype(np.uint8)
img = (img[0] * 127.5 + 127.5).numpy().astype(np.uint8)
ax[i, 0].imshow(img)
ax[i, 1].imshow(prediction)
ax[i, 0].set_title("Input Photo")
ax[i, 1].set_title("Monet-esque")
ax[i, 0].axis("off")
ax[i, 1].axis("off")
plt.show()

提出ファイルの作成
import PIL
! mkdir ../images
i = 1
for img in photo_ds:
prediction = monet_generator(img, training=False)[0].numpy()
prediction = (prediction * 127.5 + 127.5).astype(np.uint8)
im = PIL.Image.fromarray(prediction)
im.save("../images/" + str(i) + ".jpg")
i += 1
import shutil
shutil.make_archive("/kaggle/working/images", 'zip', "/kaggle/images")
まとめ
最後まで読んでくださってありがとうございます。
コンペのお題を見るとやる気の無くしそうなものばかりで、まだまだブラックボックス的にモデル例を見て扱ってばかりですが、一つ一つ紐解いて少しずつ理解していきたいです…。
何か修正点などあれば教えていただけるとありがたいです。
関連記事
本論文
[CycleGANsの論文を理解する(1)]
(https://qiita.com/RyugaMisono/items/a999616bda642ec28031)
[CycleGANsの論文を理解する(2)]
(https://qiita.com/RyugaMisono/items/59fd5ab7e27f03b14a89)
CycleGANsの論文を理解する(実装編)準備中…