CycleGANsの論文を理解する
最近になって論文を参照することが多くなった自分ですが、誰かが要約してくれたやつを見ればそれでいいんじゃね?と思い始めてしまっています。どうなんでしょう。
Motivation
さてそんな僕がなぜ要約記事を書くのかというと
理解度が深まるのと、読んだ証拠になる
といったところでしょうか。
労力は掛かりますがこの書き起こす行為が後々役に立つと信じています。
Kaggleでの勉強の一環として
I’m Something of a Painter Myself
(https://www.kaggle.com/c/gan-getting-started)
というコンペに取り組んでいました。
そこで『CycleGANsを使うと良い結果が得られるらしい』ので調べるに至ったわけです。
Comprehension
前置きはこの辺りで、早速読み解いていきます。
※所詮浅い知識の自分ですので理解の及ばないところが多々おると思いますので、僕の疑問に答えられそうなら御助力頂けると幸いです。
Abstract
画像から画像への変換(I2I translation)はペアになった画像を使いインプットからアウトプットへのマッピング(写像)を実現するものですが、実際ペアになった画像のデータを得られる場面は多くありません。
なのでペアの画像なしでも変換を実現できるようにモデルに学ばせようというのがこの技術なわけです。
※ペアの画像とは変換前、変換後の画像のペア:
例えば同じ景色の写真、モネ風絵画やシマウマ、馬のセットなど
マッピング(写像):
〔mapping〕集合 M の任意の要素に対し,集合 N の一つの要素を対応させる規則を M から N への写像という。
ここで言う変換とは、本論文の画像をお借りして説明すると

X(Monetの画像セット)、Y(普通の写真のセット)を訓練データとして
”Monetの画像”の入力を”普通の写真”に変換し出力するよう教育するということです(”変換”より”翻訳”の方がニュアンス的に近いようですが、簡単のため今後変換を多用すると思います)。
しかもXの任意のデータに対応するY内のデータのペアなしで実現するよ。って感じです。
ペアの訓練データなしで変換パターンを学習するってのがCycleGANsの肝っぽいです。
数式だと
G:X → Y
G(X)で出力される画像群はYの画像群と区別できないように敵性損失(adversarial loss)を用いて学ばせることを目標とします。
また逆方向への変換
F:Y → X
も利用し、それぞれの出力を入力として循環させます。
F(G(X)) ≒ X
G(F(Y)) ≒ Y
といったように
x → y → x※(変換後)
と変換させxとx※が一致する、xが変換後元に戻るように訓練する。
これがCycleたる所以です。
1. Introduction
モネは上記の画像にあるように彼なりの表現で彼が見た景色を描き写したわけですが、『もし彼が港の景色を見ていたとしたらどういう絵が出来上がるだろうか』というのがこの技術のそもそもの発想です。
モネの絵画を見ていくとなんとなくその特徴が見えてくると思います。
モネの絵画とその景色の写真のセットを目にしたことはないと思いますが、我々にはモネや写真についての知識があります。
これら二つの違いについて我々は理由付けすることができます(光の表現の仕方など特徴)。ということで我々は”変換”するとしたらどうなるかを想像できるのです。
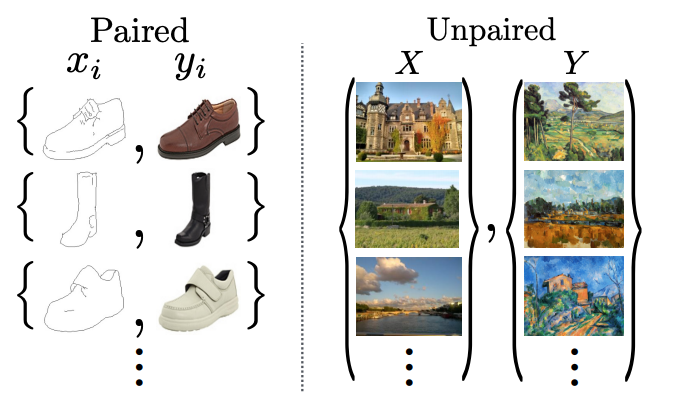
コンピュータービジョン、画像処理、グラフィックスの分野に置いて長年、教師あり、つまりペア画像が用意された状態での強力な画像の変換システムが生み出されてきました。
しかし、現実の場面の多くにおいてペアのデータを得るのは難しく、敷いては高くつきます。
理由として、セマンティック セグメンテーション (Semantic Segmentation:画像内の画素にラベル付を行うアルゴリズム)などとは違い、データは大きく、出力も複雑になるためです。
だからこそ本論文では、画像の特徴を捉えそれをペアの画像の訓練データなしでどう変換するかを学習するシステムを紹介しています。
もちろんモネ以外にも適応するように。
各ドメインには関係性があると仮定し、その関係性を見つけるよう学習させます。
このアルゴリズムは教師なし学習であるため、データセットから教師を抽出するようにします。
例えば
G:X → Y
のようなマッピングの実現を目指すとして、出力y1をYの任意のデータyとを区別できないようにすることを目指し、それらy、y1を区別するモデル(discriminator)を敵対性として訓練します。
理論上、訓練されたGはドメインXの要素を、ドメインYの要素と区別できないようなYの要素に変換するわけですが、これだけでは対応する入出力x、yが理にかなったペアになっているかはわかりません(ドメインのみが変換され入出力の画像自体がペアになってるかは不確定)。更に敵対性の目標の最適化は難しく、入力画像が一つの出力に収束する、いわゆるモード崩壊を起こしやすくなります。
これらを回避するための構造を付け足す代わりに、Cycle consistent(循環一貫性←ちゃんとした訳し方わからない)に変換を行う特性を抽出します。
英語からフランス語に変換された文があるとすれば、それをフランス語から英語に変換しなおします。変換された文は元の文と一致すべきだというのがCycle consistentです。
G:X → Y と F:Y → X との2つを同時に訓練しCycle consistent loss(元に戻ってるかの損失)と敵対性損失と合わせ評価することで最終目標である”ペア化されていない画像から画像への変換”を実現します。
2. Related work
次に関連研究についてです。
Generatie Adversarial Networks(GANs)
CycleGANsの名前にもあるようにGeneratie Adversarial Networks、通称GANsという技術がこの研究には深く関わっています。この言葉を知ってる人は少なくないのではないでしょうか。
画像生成や画像編集にて大きな影響を与え、text2image(文からその内容に沿った画像を生成する技術)や画像修復、未来予知などの画像編集や画像以外の動画、3DモデルなどでもGANsの考え方が採用されています。
GANsにおいての重要な要素の一つはadversarial lossです。
Adversarialとは『敵性の』の意味で、訓練時に敵性のモデルと競わせることでモデルの精度をあげようという考え方です。
詳しくは他の方の記事などを参考にするといいと思います。
Image-to-Image Translation
I2I変換(2つのドメイン間での対応する写像を得ること)の考え方は時代に沿って変化してきました。
**Image Analogy(画像類推)**などがその走りにあたるようです。
二つの画像の変換を学習し、その変換の仕方に従って画像を変換する。
一セットのペアの訓練画像からのノンパラメトリック(母数に頼らない)なモデル。
さらに最近では、単体ではなくデータセットからCNNs(畳み込みニューラルネットワーク)を用いて、パラメトリックな変換を学習させる手法が為されている。
今回のアルゴリズムでは写像学習にConditional(条件付き)GAN(生成するクラスを指定できる。条件データとペア画像との対応関係を学習する。)を使ったpix2pixというフレームワークを元にしている。
条件画像を指定し、条件画像とGANが生成する画像、画像データとのそれぞれの真偽を判別し、それらの関係性を学習する。
(分かりやすい記事↓
https://blog.negativemind.com/2019/12/29/pix2pix-image-to-image-translation-with-conditional-adversarial-networks/)
似たような考え方で色々なドメイン間(写真からスケッチなど)の変換に応用できる。
これらと違いCycleGANsではペアになった訓練データを用いない。
Unpaired Image-to-Image Translation
ペアになった訓練データを用いない手法に関してはいくつかが試みている。
ソース画像から算出されるMarkov Random Field(マルコフ確率場:将来状態の条件付き確率分布が、現在状態のみに依存し、過去のいかなる状態にも依存しない特性を持つ確率変数の集合)、複数の種類の画像から得られるlikelihood(条件付確率)などを含むベイズの枠組みなどが提案されている。
最近ではCoupledGANsやCross modal scene networksが重み共有を用いてドメイン間の共通点を学習する手法を採用しているようです。
更に、複数のオートエンコーダー(特徴抽出)とGANsを組み合わせこれらを拡張したものも提案されていたりします。またスタイルの違う入出力に同じ”内容”を共有させたりもしているようです(よく理解できなかった)。
クラスラベル空間、ピクセル空間、特徴空間における事前に定義された”長さ”に近づけるようGANsを用いて学習させたりもするようです。
これらと違いタスクを絞ったり、事前定義された関連性を用意したり、入出力で同じ次元削減が為されていると仮定したりをCycleGANsでは必要としません。
Neural Style Transfer
Neural Style Transferでは、グラム行列統計(?)を使い、ある画像の中身(content)と別の画像のスタイル、様式を組み合わせ、新しい画像を生成することで変換を実現します。
これは特定の2つの画像間での変換で、ドメイン間での変換をと行うCycleGANsとは目的が異なります。
Cycle Consistency
Cycle Consistencyとはずばり
画像セットAとBがあるとして、Aから特定の画像t1を選択しそれに一番似た画像をBから選びます。選んだ画像をt2だとすると、次にt2に一番似た画像をAから選択します。その時にそれがt1と同一になる状態をCycle Consistencyといいます。
t1→t2
t2→t3(≒ t1)
↑ぐるっと循環する
昔からCycle Consistencyはトラッキングに使われていましたが、最近ではモーション、3D形状マッチ、深度推定など色々なものに使われています。
3. Formulation
次にCycleGANsの構成成分についてです。
CycleGANsにおいての目的は『2つのドメイン間での写像の学習』です。
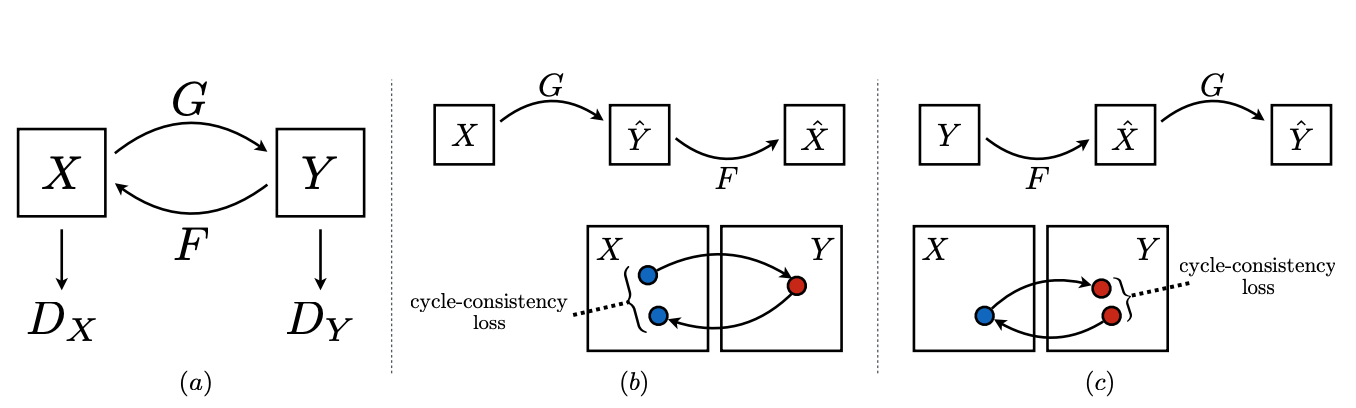
図で示されたようにこのモデルはG:X → Y、F:Y → Xの2つの写像を持ちます。2つの敵対性識別者(discriminator:生成された画像と実際の画像を識別しようとする機能)を持ちます。
それぞれX(Y)の任意の画像とF(G)の写像で変換された画像を識別します。
また、生成された画像とターゲットのドメインのマッチにadversarial loss、2つの写像の矛盾を防ぐのにcycle consistency lossを利用します。
Adversarial loss
adversarial lossは2つの写像それぞれに適用されます。
写像G:X → Yと識別者(discriminator)DYを用いて
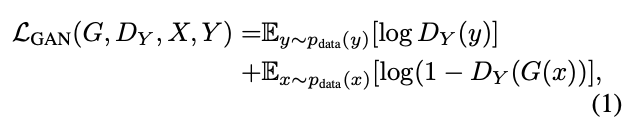
と表せられます。
GがYの画像に似た画像を生成し、DYが実際のYの画像との判別を目指します。
Gはadversarial lossを最小に、敵対性であるDYは最大にするように試みます。
写像F:Y → Xにおいても同様です。
つまりadversarial lossとは『どれだけ妨害できているかの指標』といった感じでしょうか。
Cycle consistency loss
adversarial lossを用いて理論上は、ターゲットドメインを相違のない出力を得る写像を学習することができますが、(その大きな容量から)学習した写像全てがそれぞれターゲットドメインに適した出力を出すような、同じ入力からターゲットの画像セットのあらゆる並びに対する写像を取得する可能性があります。
↑モード崩壊のことかな?ドメイン間の変換だけ成功し、入出力の画像がペアにならない
そのため、adversarial lossだけでは各々の入力画像を望んだ出力に写像(対応させる)ことは確約できない。
前述であったように写像をCycle consistencyとすることでこれに対応します。
(詳しい説明は省きますが)
Xにある画像xから写像された画像がxに戻ってくる循環をforward cycle consistency
x → G → F(G) ≒ x
逆(yからy)をbackward cycle consistencyと呼びます。
Cycle consistency lossを用いてこれを奨励(cycle consistencyを持つよう最適化)します。
Full Objective
これら二つ(adversarial lossとcycle consistency loss)を組み合わせ下記のように表現します。
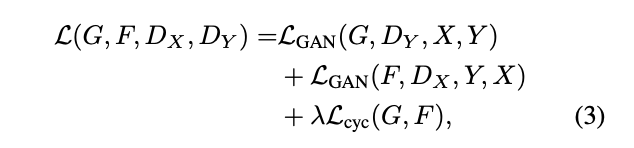
λで2つの相対的な重要度をコントロールします。
そして各写像を
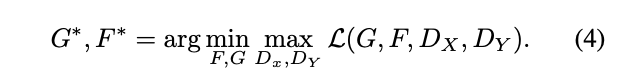
と表します。
このモデルは2つのオートエンコーダーを訓練するという見方もできます。
しかし、このモデルは中間に変換を挟み自己へ写像するという特異性を持ちます。
といったところでとりあえず区切っておきます。
次回はImplementation(実装)からはじめたいと思います。
お読み頂きありがとうございます。
次回もよろしければお願いします。
関連記事
本論文
[CycleGANsの論文を理解する(1)]
(https://qiita.com/RyugaMisono/items/a999616bda642ec28031)
[CycleGANsの論文を理解する(2)]
(https://qiita.com/RyugaMisono/items/59fd5ab7e27f03b14a89)
CycleGANsの論文を理解する(実装編)準備中…