1.きっかけ
顔検出、画像分類に興味がありkaggleなどを使って画像分類をしておりましたが今回このようなQiitaの記事を見つけたので自分でも作ってみようと思いました。
2.サービス概要
Reactの練習と画像分類を使用して大好きな櫻坂46のアプリを作ってみました。
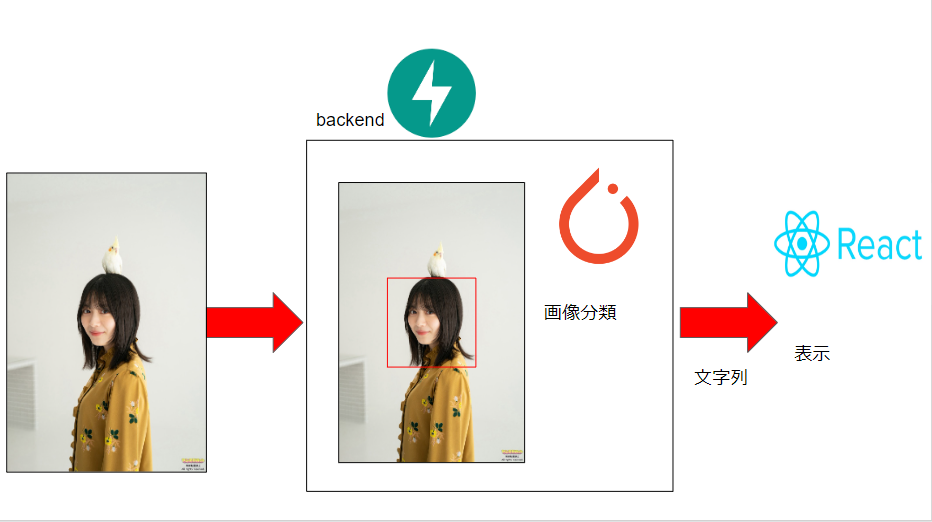
3.使用技術
バックエンドと画像分類、集め
- python
- OpenCV
- numpy
- pytorch
- FastAPI
フロントエンド
- javascript
- React
- cs
インフラ
- Heroku
4.画像分類機能作成
4.1スクレイピング
基礎知識としてはこちらをご覧ください
こちらのサイトから引用しmemberだけ変えたものは名前を一緒にしてあります。コードに追加、変更などがあった場合にはdiffで表現しています。
import glob
import os
from icrawler.builtin import BingImageCrawler
#メンバーの名前をリスト形式でまとめる
members = ['上村 莉菜', '尾関 梨香', '小池 美波', '小林 由依', '齋藤 冬優花', '菅井 友香', '土生 瑞穂', '原田 葵',
'井上 梨名', '遠藤 光莉', '大園 玲', '大沼 晶保', '幸阪 茉里乃', '関 有美子', '武元 唯衣', '田村 保乃', '藤吉 夏鈴',
'増本 綺良', '森田 ひかる', '松田 里奈', '守屋 麗奈', '山﨑 天']
dir = './data/'
for member in members:
#指定のディレクトリを作成(画像の保存場所)
crawler = BingImageCrawler(storage={"root_dir": dir + member})
# 検索内容と枚数の指定
crawler.crawl(keyword=member, max_num=500)
#ディレクトリ内の画像ファイルを取得
files = glob.glob(dir + member + '/' + '*')
for i, file in enumerate(files):
#ファイル名の変更
os.rename(file, dir + member + '/' + str(i+1) + '.jpg')
これに加え苗字と名前の間に空白を入れる写真と苗字と名前の間に空白がないものの写真も撮ってきたかったので
import glob
import os
from icrawler.builtin import BingImageCrawler
#メンバーの名前をリスト形式でまとめる
members = ['上村 莉菜', '尾関 梨香', '小池 美波', '小林 由依', '齋藤 冬優花', '菅井 友香', '土生 瑞穂', '原田 葵',
'井上 梨名', '遠藤 光莉', '大園 玲', '大沼 晶保', '幸阪 茉里乃', '関 有美子', '武元 唯衣', '田村 保乃', '藤吉 夏鈴',
'増本 綺良', '森田 ひかる', '松田 里奈', '守屋 麗奈', '山﨑 天']
members1 = ['上村莉菜', '尾関梨香', '小池美波', '小林由依', '齋藤冬優花', '菅井友香', '土生瑞穂', '原田葵',
'井上梨名', '遠藤光莉', '大園玲', '大沼晶保', '幸阪茉里乃', '関有美子', '武元唯衣', '田村保乃', '藤吉夏鈴',
'増本綺良', '森田ひかる', '松田里奈', '守屋麗奈', '山﨑天']
dir = './data/'
for member ,key in zip(members,members1):
#指定のディレクトリを作成(画像の保存場所)
crawler = BingImageCrawler(storage={"root_dir": dir + member})
# 検索内容と枚数の指定
crawler.crawl(keyword=key, max_num=500)
#ディレクトリ内の画像ファイルを取得
files = glob.glob(dir + member + '/' + '*')
for i, file in enumerate(files):
#ファイル名の変更
if not os.path.exists(dir + member):
os.rename(file, dir + member + '/' + str(i+1) + '.jpg')
も用意しました。
これで画像の量は単純に2倍です。同じ画像がありますが違う画像もあるためかの二つを実行しました。
4.2 顔認識トリミング
import glob
import os
import cv2
import numpy as np
from mtcnn.mtcnn import MTCNN
from PIL import Image
from src.japanesefile import ImWriteRead
# メンバーの名前をリスト形式でまとめる
members = [
"上村 莉菜",
"尾関 梨香",
"小池 美波",
"小林 由依",
"齋藤 冬優花",
"菅井 友香",
"土生 瑞穂",
"原田 葵",
"井上 梨名",
"遠藤 光莉",
"大園 玲",
"大沼 晶保",
"幸阪 茉里乃",
"関 有美子",
"武元 唯衣",
"田村 保乃",
"藤吉 夏鈴",
"増本 綺良",
"森田 ひかる",
"松田 里奈",
"守屋 麗奈",
"山﨑 天",
]
dir1 = "./data/"
dir2 = "./face_cut/"
# 日本語ファイルに入れるためにこのメソッドが必要
# 画像の読み込み
for member in members:
files = glob.glob(dir1 + member + "\\" + "*.jpg")
# print(files)
for j, file in enumerate(files):
img = Image.open(file)
new_image = np.array(img, dtype=np.uint8)
img = cv2.cvtColor(new_image, cv2.COLOR_RGB2BGR)
detector = MTCNN()
facerect = detector.detect_faces(img)
if len(facerect) > 0:
x, y, w, h = facerect[0]["box"]
face_cut = img[y : y + h, x : x + w]
if not os.path.exists(dir2 + member):
os.mkdir(dir2 + member)
name = str(j + 1) + ".jpg"
ret = ImWriteRead(dir2 + member + "\\" + name).imwrite(face_cut)
print(dir2 + member + "\\" + str(j + 1) + ".jpg: " + "検出されました")
else:
print(dir2 + member + "/" + str(j + 1) + ".jpg" + "検出されませんでした")
continue
ここで日本語のファイルを使用しており二文字化けhしてエラーします。
cv2は日本語のファイルが文字化けして保存ができなくなるのでこのサイトを参考にしました。
Python OpenCV の cv2.imread 及び cv2.imwrite で日本語を含むファイルパスを取り扱う際の問題への対処について
ここから何回かこのcv2のメソッドではないimreadやimwriteが出てきます。
私はこれを今後も行うことがめんどくさかったので
import os
import cv2
import numpy as np
class ImWriteRead:
def __init__(self, filename):
self.__filename = filename
def imwrite(self, img, params=None):
try:
ext = os.path.splitext(self.__filename)[1]
result, n = cv2.imencode(ext, img, params)
if result:
with open(self.__filename, mode="w+b") as f:
n.tofile(f)
return True
else:
return False
except Exception as e:
print(e)
return False
def imread(self, flags=cv2.IMREAD_COLOR, dtype=np.uint8):
try:
n = np.fromfile(self.__filename, dtype)
img = cv2.imdecode(n, flags)
return img
except Exception as e:
print(e)
return None
にしました。
4.3画像を名前を変更していく
つぎにrename.pyを実行することでface_cut_renameフォルダに入れます。
このrename.pyをする前に自ら写真を見て顔じゃない写真を消すのもありだと思います。
import glob
import os
from sklearn.model_selection import train_test_split
# メンバーの名前をリスト形式でまとめる
members = [
"上村 莉菜",
"尾関 梨香",
"小池 美波",
"小林 由依",
"齋藤 冬優花",
"菅井 友香",
"土生 瑞穂",
"原田 葵",
"井上 梨名",
"遠藤 光莉",
"大園 玲",
"大沼 晶保",
"幸阪 茉里乃",
"関 有美子",
"武元 唯衣",
"田村 保乃",
"藤吉 夏鈴",
"増本 綺良",
"森田 ひかる",
"松田 里奈",
"守屋 麗奈",
"山﨑 天",
]
dir2 = "../face_cut/"
dir3 = "../face_cut_rename/"
dir_train = "train"
dir_test = "test"
def file_save(files, dir_test_or_train):
for i, file in enumerate(files):
# 画像を保存するフォルダーを作成
if not os.path.exists(dir3 + dir_test_or_train + "/" + member):
os.mkdir(dir3 + dir_test_or_train + "/" + member)
# ファイル名の変更
os.rename(
file, dir3 + dir_test_or_train + "/" + member + "/" + str(i + 1) + ".jpg"
)
if __name__ == "__main__":
for member in members:
files = glob.glob(dir2 + member + "/" + "*")
train_file, test_file = train_test_split(files)
file_save(train_file, dir_train)
file_save(test_file, dir_test)
ホールドアウト検証でテストとtrainに画像を分けました。
4.4画像の水増し
ここでは手法を増やしていきます。表にして現します。
例として森田ひかるちゃんの画像を出します。

(ひかるちゃんかわいい...)
| 手法 | methodの中に入れる名前 | 画像 |
|---|---|---|
| 上下左右反転 | fliplrud |  |
| 画像回転 | rotate |  |
| ぼかし | Gau |  |
| モザイク処理 | resize |  |
| 収縮 | erode |  |
| などRandAugment()は様々な水増し手法使用しますがデータ量を増やすことがないので便利です。 |
コードも載せます。
import pathlib
import torchvision.transforms as T
from PIL import Image
from torch.utils.data import Dataset
members = [
"上村 莉菜",
"尾関 梨香",
"小池 美波",
"小林 由依",
"齋藤 冬優花",
"菅井 友香",
"土生 瑞穂",
"原田 葵",
"井上 梨名",
"遠藤 光莉",
"大園 玲",
"大沼 晶保",
"幸阪 茉里乃",
"関 有美子",
"武元 唯衣",
"田村 保乃",
"藤吉 夏鈴",
"増本 綺良",
"森田 ひかる",
"松田 里奈",
"守屋 麗奈",
"山﨑 天",
]
resize = 224
mean = (0.5, 0.5, 0.5)
std = (0.5, 0.5, 0.5)
class ImageTransform(object):
def __init__(self, resize, mean, std):
self.data_trasnform = {
"train": T.Compose(
[
T.RandAugment(),
T.Resize((resize, resize)),
T.ToTensor(),
T.Normalize(mean, std),
]
),
"valid": T.Compose(
[
# 画像をresize×resizeの大きさに統一する
T.Resize((resize, resize)),
# Tensor型に変換する
T.ToTensor(),
# 色情報の標準化をする
T.Normalize(mean, std),
]
),
}
def __call__(self, img, phase="train"):
return self.data_trasnform[phase](img)
class MyDataset(Dataset):
def __init__(self, file_list, classes, transform=None, phase="train"):
self.file_list = file_list
self.transform = transform
self.classes = classes
self.phase = phase
def __len__(self):
return len(self.file_list)
def __getitem__(self, index):
img_path = self.file_list[index]
img = Image.open(img_path)
img_transformed = self.transform(img, self.phase)
label = str(self.file_list[index]).split("\\")[3]
label = self.classes.index(label)
return img_transformed, label
if __name__ == "__main__":
data = MyDataset(
list(pathlib.Path("../face_cut_rename/train").glob("**/*.jpg")),
classes=members,
transform=ImageTransform(resize, mean, std),
phase="train",
)
index = 0
print(data.__getitem__(index)[1])
4.6モデル作成(pytorch)
今回はモデルをpytorchのmobilenetv2を使いました。
このモデルは精度が高くモデルとしても重くありません。
import torch
import torch.nn as nn
from torchvision.models import mobilenetv2
class mobilemodel(nn.Module):
def __init__(self) -> None:
super(mobilemodel, self).__init__()
self.mobile_net = mobilenetv2.mobilenet_v2(pretrained=True)
self.fc_1 = nn.Linear(1000, 22)
def forward(self, x):
x = self.mobile_net(x)
x = self.fc_1(x)
return x
if __name__ == "__main__":
test = torch.rand(1, 3, 224, 224)
net = mobilemodel()
print(net(test))
import pathlib
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from dataset_my import ImageTransform, MyDataset, mean, members, resize, std
from model import mobilemodel
class TrainAndTest:
def __init__(
self, train_dataloader, test_dataloader, model, criterion=None, optimizer=None
) -> None:
self.train_dataloader = train_dataloader
self.test_dataloader = test_dataloader
self.model = model
self.criterion = criterion
self.optimizer = optimizer
def train_image(self) -> None:
self.model.load_state_dict(torch.load("model.pth"))
self.model.train()
running_loss = 0.0
for i, data in enumerate(self.train_dataloader, 0):
inputs, labels = data
self.optimizer.zero_grad()
outputs = self.model(inputs)
loss = self.criterion(outputs, labels)
loss.backward()
self.optimizer.step()
# print statistics
running_loss += loss.item()
if i % 25 == 24: # print every 2000 mini-batches
print(f"[{i + 1:5d}] loss: {running_loss / 25:.10f}")
running_loss = 0.0
torch.save(self.model.state_dict(), "model.pth")
def test_model(self) -> None:
self.model.load_state_dict(torch.load("model.pth"))
size = len(self.test_dataloader.dataset)
num_batches = len(self.test_dataloader)
self.model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for i, data in enumerate(self.test_dataloader, 0):
inputs, labels = data
pred = self.model(inputs)
test_loss += self.criterion(pred, labels).item()
correct += (pred.argmax(1) == labels).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(
f"Test Error: \\n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \\n"
)
if __name__ == "__main__":
train_dataloader = DataLoader(
MyDataset(
list(pathlib.Path("../face_cut_rename/train").glob("**/*.jpg")),
classes=members,
transform=ImageTransform(resize, mean, std),
phase="train",
),
batch_size=64,
shuffle=True,
)
test_dataloader = DataLoader(
MyDataset(
list(pathlib.Path("../face_cut_rename/test").glob("**/*.jpg")),
classes=members,
transform=ImageTransform(resize, mean, std),
phase="valid",
),
batch_size=32,
shuffle=True,
)
model = mobilemodel()
model.load_state_dict(torch.load("model.pth"))
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
train_test = TrainAndTest(
train_dataloader, test_dataloader, model, loss_fn, optimizer
)
for epoch in range(100):
train_test.train_image()
train_test.test_model()
私はローカルでやっていますが皆さんはgoogle colab をお使いください。GPUが使えるので早く学習できます。
torch.save(net.state_dict(), model_path)で重みを保存してください。
これで画像分類機能は作成完了です!!
5.バックエンド
今回はFASTAPIを使用しています。
画像分類をする部分はこのようになっています。
from io import BytesIO
import cv2
import numpy as np
import torch
from PIL import Image
from retinaface import RetinaFace
members = ['上村 莉菜', '尾関 梨香', '小池 美波', '小林 由依', '齋藤 冬優花', '菅井 友香', '土生 瑞穂', '原田 葵',
'井上 梨名', '遠藤 光莉', '大園 玲', '大沼 晶保', '幸阪 茉里乃', '関 有美子', '武元 唯衣', '田村 保乃', '藤吉 夏鈴',
'増本 綺良', '森田 ひかる', '松田 里奈', '守屋 麗奈', '山﨑 天']
def load_model():
net = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_efficientnet_b0', pretrained=True)
model_path = 'nvidia_efficientnet_b0.pth'
net.load_state_dict(torch.load(model_path))
return net
def read_image(image_encoded):
pil_image = cv2.imread(str(image_encoded))
return pil_image
def preprocess(images):
resp = RetinaFace.detect_faces(images, threshold = 0.5)
face_cut = []
faces = []
for key in resp:
p = resp[key]
facial_area = p["facial_area"]
face = images[facial_area[1]: facial_area[3], facial_area[0]: facial_area[2]]
faces.append(face)
face = np.array(cv2.resize(face, (244, 244))/255.).transpose(2, 0, 1).astype(np.float32)
#face= cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
face_cut.append(face)
face_cut = np.array(face_cut)
return face_cut
def predict(image: np.ndarray):
net = load_model()
if net is None:
net = load_model()
images = torch.tensor(image)
#print(images.shape)
response = []
with torch.no_grad():
for im in images:
#print(im.shape)
im = im.view(1,3,244,244)
outputs = net(im)
#print(outputs.data)
_, predicted = torch.max(outputs.data, 1)
#print(predicted)
response += [members[predicted]]
return response
実際のルーティングはこのようになっております。
from io import BytesIO
import cv2
import numpy as np
import torch
from PIL import Image
from retinaface import RetinaFace
import model
members = ['上村 莉菜', '尾関 梨香', '小池 美波', '小林 由依', '齋藤 冬優花', '菅井 友香', '土生 瑞穂', '原田 葵',
'井上 梨名', '遠藤 光莉', '大園 玲', '大沼 晶保', '幸阪 茉里乃', '関 有美子', '武元 唯衣', '田村 保乃', '藤吉 夏鈴',
'増本 綺良', '森田 ひかる', '松田 里奈', '守屋 麗奈', '山﨑 天']
def load_model():
net = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_efficientnet_b0', pretrained=True)
model_path = 'nvidia_efficientnet_b0.pth'
net.load_state_dict(torch.load(model_path))
return net
def read_image(image_encoded):
pil_image = cv2.imread(str(image_encoded))
return pil_image
def preprocess(images):
resp = RetinaFace.detect_faces(images, threshold = 0.5)
face_cut = []
faces = []
for key in resp:
p = resp[key]
facial_area = p["facial_area"]
face = images[facial_area[1]: facial_area[3], facial_area[0]: facial_area[2]]
faces.append(face)
face = np.array(cv2.resize(face, (244, 244))/255.).transpose(2, 0, 1).astype(np.float32)
#face= cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
face_cut.append(face)
face_cut = np.array(face_cut)
return face_cut
def predict(image: np.ndarray):
net = load_model()
if net is None:
net = load_model()
images = torch.tensor(image)
#print(images.shape)
response = []
with torch.no_grad():
for im in images:
#print(im.shape)
im = im.view(1,3,244,244)
outputs = net(im)
#print(outputs.data)
_, predicted = torch.max(outputs.data, 1)
#print(predicted)
response += [members[predicted]]
return response
6.フロントエンド
reactを使って行いました。
import React from "react";
import axios from "axios";
import "./FileUpload.css"
class FileUpload extends React.Component {
constructor() {
super();
this.state = {
selectedFile: "",
imagePreviewUrl: "",
name: "",
podstatus:""
};
this.handleInputChange = this.handleInputChange.bind(this);
}
handleInputChange(event) {
event.preventDefault();
let reader = new FileReader();
let file = event.target.files[0];
reader.onloadend = () => {
this.setState({
selectedFile: file,
//name: event.target.data,
imagePreviewUrl: reader.result
});
};
reader.readAsDataURL(file);
}
submit() {
const data = new FormData();
data.append("file", this.state.selectedFile);
console.warn(this.state.selectedFile);
let url = "http://127.0.0.1:8000/api/predict";
axios
.post(url, data)
.then(res => {
// then print response status
this.setState({ name: res.data });
console.log(this.name)
})
.catch(error => {
this.setState({
podstatus: 'Stop'
});
console.log("error")
})
}
render() {
return (
<div className = "main">
<div className="form-row">
<div className="form-group-col-md-6">
<label className="text-white">Select File :</label>
<input type="file" className="form-control" name="upload_file"onChange={this.handleInputChange}/>
</div>
<img src={this.state.imagePreviewUrl} alt="description"height={ 500 }width={ 500 }/>
</div>
<div className="col-md-6">
<button type="submit" className="btn btn-dark"onClick={() => this.submit()}>
名前確認
</button>
</div>
<div className = "result">
{this.state.name}
</div>
</div>
);
}
}
export default FileUpload;
実際の画面はこのようになります
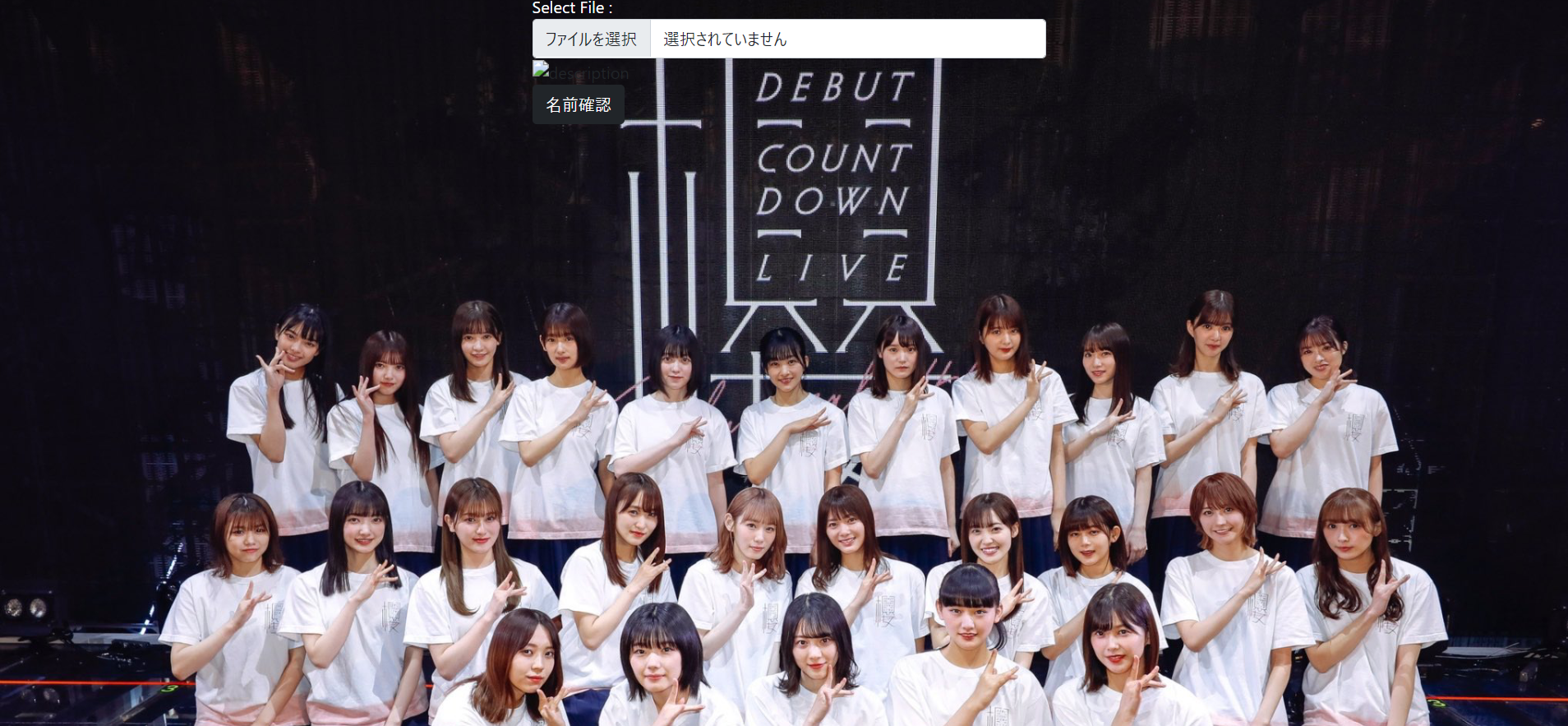
7.実際の使用映像

8.herokuのデプロイ
pytochが大きいためまだできてはいません。
これからもっと櫻坂46関係のアプリを作っていきます。
githubにも載せておりますので良ければcloneしてください!!!
githubURL
追記
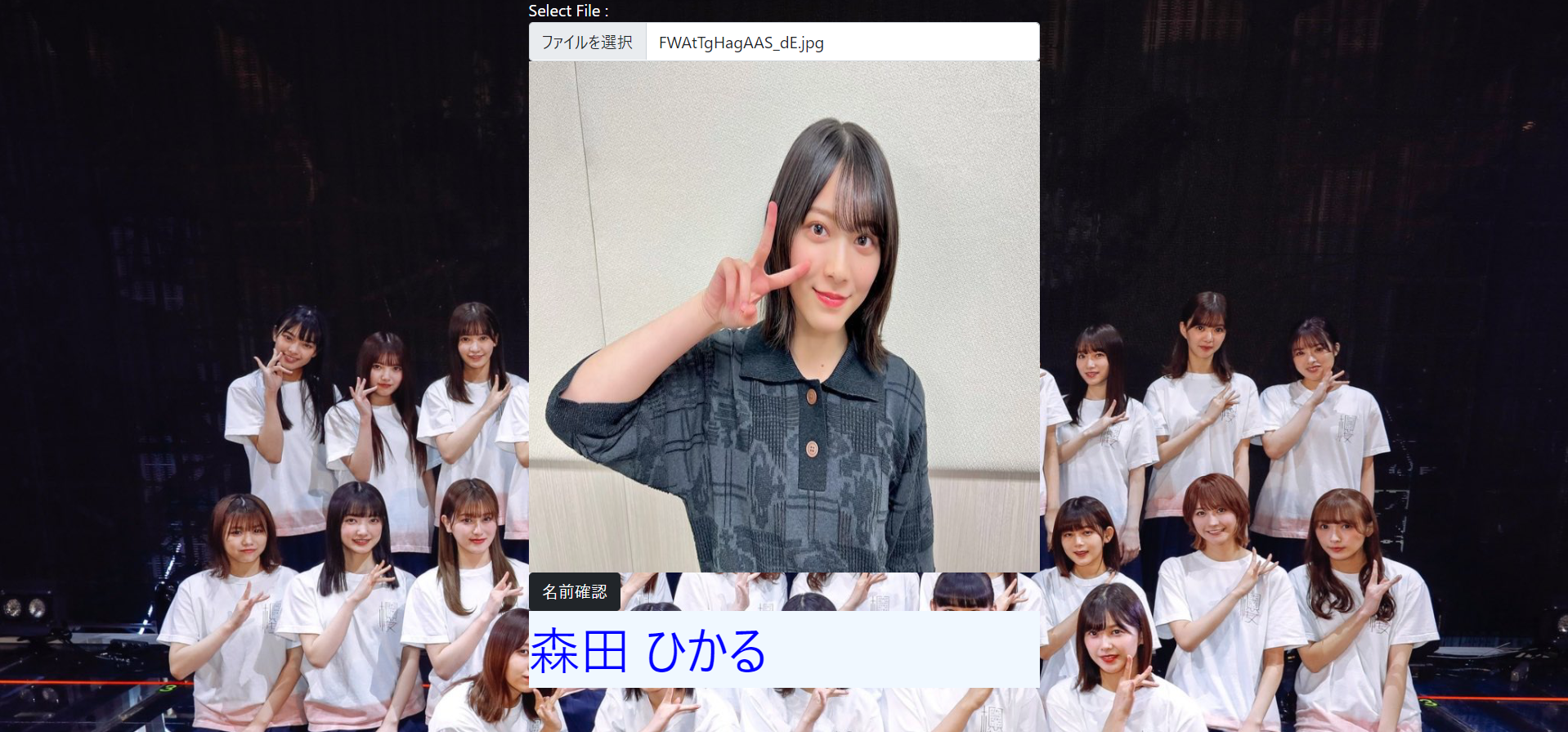
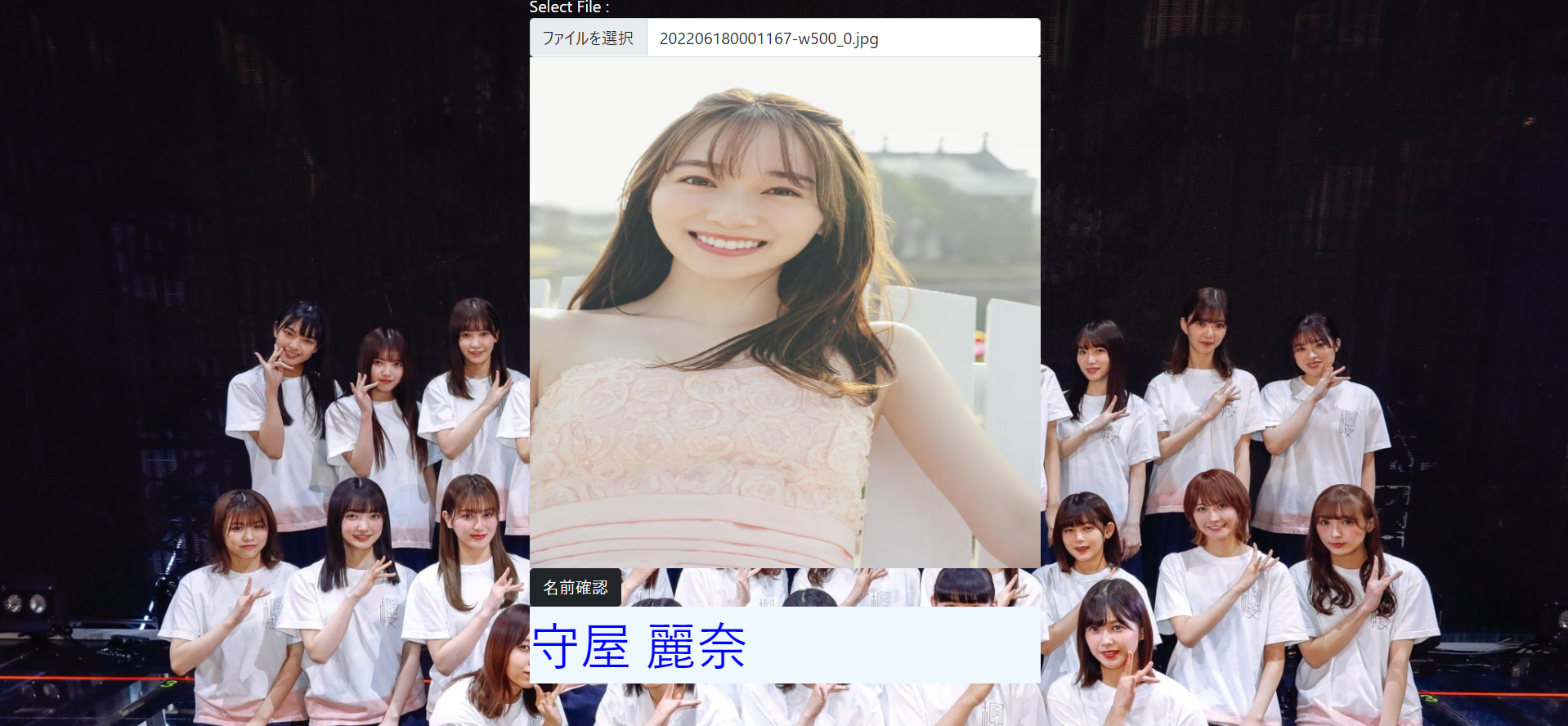
しっかり最新画像も分類できています。